
 Périphériques technologiques
IA
Intégration des produits GPT grand modèle, nouvelle série de mises à niveau de produits WakeData
Périphériques technologiques
IA
Intégration des produits GPT grand modèle, nouvelle série de mises à niveau de produits WakeData
Intégration des produits GPT grand modèle, nouvelle série de mises à niveau de produits WakeData

Récemment, WakeData (ci-après dénommé « WakeData ») a réalisé une nouvelle série de mises à niveau des capacités du produit.
Lors de la conférence de lancement du produit en novembre 2022, les « trois déterminations » de WakeData ont été véhiculées : toujours investir fermement dans la technologie, consolider globalement les capacités scientifiques et technologiques et le taux d'auto-recherche des produits de base ; localisation, prendre en charge les puces nationales, les systèmes d'exploitation, les bases de données, les middlewares, les algorithmes secrets nationaux, etc., et réaliser la substitution locale des fabricants étrangers dans le même domaine ; embrasser toujours fermement l'écosystème et créer une situation gagnant-gagnant avec les partenaires ;
WakeData poursuit une nouvelle série de mises à niveau des capacités de ses produits. S'appuyant sur son accumulation technologique au cours des cinq dernières années et sa pratique dans l'immobilier, la vente au détail, l'automobile et d'autres industries et domaines verticaux, elle a développé conjointement des géants de l'industrie dotés de capacités de déploiement privatisées. avec des partenaires stratégiques. Le modèle WakeMind aidera davantage d'entreprises à se révolutionner, à améliorer leur efficacité et à continuer à libérer la productivité à l'ère de l'AIGC.
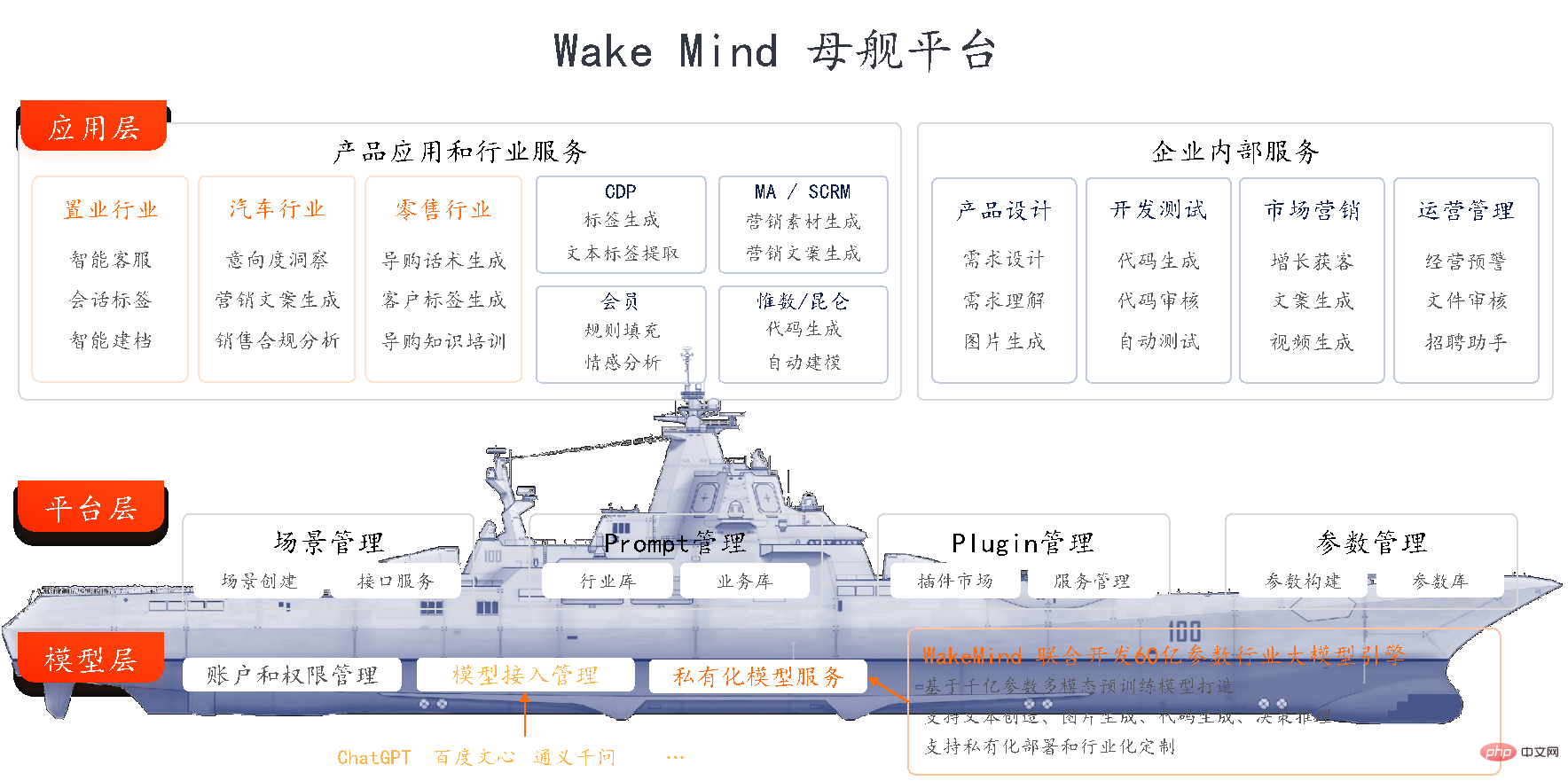
Trois couches de plate-forme principales du modèle WakeMind
Couche modèle : la plate-forme mère utilisera WakeMind avec des capacités de déploiement privatisées et de personnalisation de l'industrie comme moteur principal, et a été connectée à de grands modèles tels que ChatGPT , et prend également en charge l'accès à plusieurs capacités de grands modèles telles que Wen Xinyiyan, Tongyi Qianwen, etc.
Couche de plate-forme : WakeMind est basé sur une ingénierie rapide, un plug-in, LangChain et d'autres méthodes pour obtenir des capacités de dialogue efficaces avec accès à de grands modèles. Sur la base d'un apprentissage sans échantillon, le modèle peut mieux comprendre les informations contextuelles grâce à la gestion des invites et des plugins ; en alimentant le corpus de l'industrie, le modèle peut rapidement acquérir des connaissances sur l'industrie et avoir la capacité de réfléchir et de raisonner sur les industries et les domaines verticaux.
Couche d'application : la plate-forme mère WakeMind fournit des capacités sous-jacentes, permettant d'autonomiser les applications de produits et les scénarios industriels via des avions embarqués les uns après les autres, et d'améliorer la productivité interne de l'entreprise.
Par exemple, comment la plate-forme mère permet-elle de renforcer Weishu Cloud. Dans le processus de création et d'utilisation d'actifs de données à l'aide de Weishu Cloud Platform, les entreprises doivent souvent investir un grand nombre d'ingénieurs professionnels en développement de données pour participer à l'analyse des besoins commerciaux et aux travaux de développement de données, et un grand nombre de tâches de développement fastidieuses seront nécessaires. conduire à l'allongement de l'ensemble du cycle de réalisation de la valeur des données. Basé sur l'autonomisation de WakeMind, uniquement via l'interaction textuelle, Weishu Cloud peut générer automatiquement les instructions de requête de données correspondantes et exécuter la requête en un seul clic, ce qui peut considérablement améliorer l'efficacité de la requête, de l'analyse et du développement des données, et réduire considérablement le seuil technique des données. use , pour atteindre l’objectif de rendre les données accessibles à tous.
Trois caractéristiques majeures du modèle WakeMind
1) Le nombre de paramètres est plus adapté aux scénarios de terrain industriel et vertical. Pour obtenir un contenu de niveau humain, le contenu généré par l'IA doit souvent être basé sur de grands modèles de « pré-formation + réglage fin » ; WakeData a uni ses forces avec le principal fabricant de grands modèles multimodaux pré-entraînés du secteur, avec des centaines de milliards d'euros. de paramètres pour le compresser grâce à la distillation des connaissances et à la quantification dynamique. Modèle WakeMind avec 10 milliards de paramètres dans des industries ciblées et des domaines verticaux, basé sur P-Tuning V2, les paramètres qui nécessitent un réglage fin peuvent être réduits à un millième de l'original, réduisant considérablement la quantité de calcul requise pour le réglage fin.
2) Création de texte et génération de code avec des capacités de champ spécifiques à l'industrie et verticales.
3) Accompagner le déploiement privatisé et la personnalisation industrielle. Les entreprises leaders dans des secteurs ou des domaines verticaux espèrent avoir la possibilité de privatiser le déploiement et la personnalisation de grands modèles spécifiques à l'industrie. Comment organiser une pré-formation efficace avec un apprentissage sur petits échantillons et une faible consommation d'énergie de calcul est devenu le seuil technique pour les modèles industriels personnalisés. L'accumulation des données industrielles et des données de champ vertical de WakeData permettra aux grands modèles industriels de disposer d'un savoir-faire industriel et de constituer des avantages concurrentiels uniques.
Dans le même temps, WakeMind utilise l'architecture Transformer pour générer des dizaines de milliers d'échantillons de données de conformité aux instructions de manière auto-instructive. Il utilise SFT (Supervised Fine-Tuning), RLHF et d'autres technologies pour réaliser l'alignement des intentions après quantification. Grâce à INT8, il peut réduire considérablement le coût de l'inférence. Rendre le modèle réalisable pour un déploiement privé
Grand modèle et grand modèle industriel pré-entraîné
Depuis qu'OpneAI a publié ChatGPT, il a eu un impact énorme sur le monde. Le Large Language Model (LLM) qui le sous-tend et le RLHF (Reinforcement Learning from Human Feedback), un modèle de langage optimisé sur la base du feedback humain utilisant l'apprentissage par renforcement, ont reçu une large attention.
WakeData a publié 11 modèles d'IA dans les domaines de la PNL, du CV, de la parole et d'autres domaines depuis ses débuts. Parmi eux, le grand modèle d'analyse sémantique de la PNL possède les scénarios d'application les plus abondants. Par exemple, dans l'immobilier, l'automobile, la vente au détail de marques et d'autres secteurs à faible fréquence et à prix unitaire élevé par client, le SCRM est l'un des moyens les plus efficaces de gérer les clients potentiels et les clients existants. Grâce à l'accumulation de corpus industriels et à une pré-formation spécifique, WakeData permet à l'IA de développer une compréhension approfondie du secteur. Elle peut répondre rapidement aux questions des clients 24 heures sur 24 pendant la conversation et peut extraire automatiquement les balises des clients en fonction des informations de la conversation. améliorer la résolution des portraits clients.
Chez WakeData, les capacités de grands modèles d'IA ont couvert tout, de la construction d'actifs de données clients sous-jacents, aux parcours commerciaux et règles commerciales des clients de niveau intermédiaire, en passant par les liens marketing multi-points de niveau supérieur ; qui peut fonctionner pour l'ensemble du client numérique. La capacité de « réduire les coûts, d'améliorer l'efficacité et de responsabiliser ». Par exemple, dans le domaine de la plate-forme de données clients CDP, les opérateurs avaient auparavant besoin d'une conception de règles lourdes pour sélectionner les groupes de clients cibles appropriés. Désormais, grâce à une description et un dialogue simples, l'IA peut aider à trouver les groupes de clients cibles correspondants, réduisant ainsi considérablement le nombre de clients. coût de la plate-forme. Le coût d'utilisation et d'apprentissage est réduit, et l'efficacité d'utilisation et l'expérience interactive sont améliorées à pas de géant.
Dans le domaine de l'automatisation du marketing MA, les produits de WakeData ont été connectés à l'écosystème WeChat, Douyin, Xiaohongshu et d'autres points de contact, et prennent en charge la construction automatisée de parcours marketing, fournissant une riche bibliothèque de modèles de parcours, qui peut atteindre " contact utilisateur en temps réel, individuel et personnalisé. Une partie importante de ceci est la génération de supports marketing personnalisés, comprenant du texte, des images, des graphiques et du texte mixtes, etc. Les grands modèles d'IA peuvent considérablement améliorer l'efficacité et la qualité de cette partie tout en réduisant les coûts.
Dans le domaine de l'adhésion de fidélité, lorsque le système d'adhésion couvre différents secteurs et formats d'entreprise, il sera difficile d'unifier les règles d'adhésion et les actifs des membres. Le grand modèle d'IA de WakeData est basé sur le moteur Prompt formé par une grande expérience du secteur. et la formation du corpus, grâce à une simple conversation, décrivant les caractéristiques et les exigences commerciales des différents membres de l'entreprise, la logique de cartographie et le schéma de combinaison des différentes règles d'adhésion peuvent être automatiquement générés.
La pratique des grands modèles dans les industries et les domaines verticaux a prouvé son intérêt.
Trois étapes du parcours commercial de WakeMind
1) 2018-2021, période d'application du modèle autonome et d'exploration de la commercialisation. Basé sur les trois gammes de produits de base de WakeData, Weishu Cloud, Weike Cloud et Kunlun Platform, le grand modèle NLP auto-développé sera exploré et mis en pratique de manière approfondie dans des domaines verticaux tels que l'immobilier, le nouveau commerce de détail, l'automobile et le marketing numérique.
2) 2022-2023, sortie de WakeMind et période de construction de la plateforme du vaisseau mère. WakeData collabore avec des partenaires stratégiques pour accélérer la recherche et le développement de WakeMind, un grand modèle industriel. Grâce à la plate-forme mère, WakeMind a la capacité de personnaliser l'industrie et les domaines verticaux, a la capacité de privatiser le déploiement et dispose des capacités d'accès et de gestion de. Grands modèles généraux pour réaliser des ajouts avantageux au scénario qui ne peuvent pas être couverts par nos propres modèles.
3) En 2023 et au-delà, la période de candidature du modèle WakeMind sera pleinement inscrite. Basé sur les capacités de la plate-forme mère, WakeMind est entièrement connecté à des gammes de produits telles que Weike Cloud, Weishu Cloud et Kunlun Platform. Grâce à l'accumulation de connaissances industrielles, à l'optimisation de scénarios industriels et à une formation en ingénierie rapide, WakeMind améliore encore les capacités industrielles de. le modèle et lancera des applications commerciales à plus grande échelle dans l'immobilier, les nouveaux commerces de détail, l'automobile et d'autres secteurs. Dans le même temps, WakeData elle-même a commencé à réaliser sa propre révolution de productivité basée sur les capacités de la plate-forme mère WakeMind.
Comment WakeData utilise l'IA pour libérer la productivité
La mission de WakeData est définie comme « réveiller les données » et est présente dans le domaine des plateformes Big Data depuis de nombreuses années. En tant que société de services d'entreprise TOB, WakeData voit d'énormes opportunités dans « comment utiliser les grands modèles » et couvre l'utilisation des grands modèles sous deux aspects : d'une part, elle intègre les grands modèles dans les produits, et d'autre part, elle aide les entreprises composées en interne de concepteurs, de programmeurs et autres utilisent de grands modèles pour le développement de produits et la livraison de projets clients.
Il existe deux éléments de base pour l'accès et l'application de grands modèles, des scénarios plus applicables et des capacités d'IA Big Data. Les deux principaux produits de WakeData, « Weike Cloud » et « Weishu Cloud », constituent l'interface fournie par Entry. commodité. Weike Cloud peut accéder plus facilement et de manière transparente à de grands outils de modèles basés sur les applications numériques de l'industrie, et les clients n'ont pas à se soucier de la configuration complexe et de l'optimisation technique derrière l'application ; Weishu Cloud peut appliquer des projets d'invite d'optimisation et des modèles verticaux basés sur des scénarios d'aide de l'industrie. C'est aussi l'avantage de la solution produit auquel WakeData a toujours adhéré : plateforme + application.
Dans le même temps, WakeData divise les produits d'accès aux grands modèles en deux catégories. L'une est basée sur l'accès aux flux commerciaux des produits et du secteur. L'objectif de ce type d'accès est d'optimiser l'expérience et la connaissance du secteur pour aider les clients rapidement et facilement. application efficace ; la deuxième catégorie consiste à optimiser en profondeur les scénarios verticaux basés sur l'architecture du produit et les grands modèles open source. Ce type de produit est plus conforme aux besoins des grands clients en matière de lutte contre les risques et de sécurité des données. compréhension de l'industrie, le modèle peut être continuellement optimisé et maintenu. La compétitivité continue de ces clients dans les industries verticales.
"Les entreprises doivent intégrer de grands modèles dans la transformation numérique et la gestion numérique des clients. Le Big data et les scénarios sont deux éléments clés." a déclaré Li Kechen, fondateur et PDG de WakeData.
Dans des circonstances normales, les grands modèles nécessitent une grande quantité de données pour une formation efficace, il est donc crucial de disposer des capacités d'une plateforme de données industrielles. Récemment, l'Administration chinoise du cyberespace a publié les « Mesures pour la gestion des services d'intelligence artificielle générative (projet pour commentaires) », qui mettent particulièrement l'accent sur la conformité juridique des sources de données de formation et de pré-formation, ainsi que sur l'authenticité, l'exactitude et l'objectivité. et la diversité des données. Les scénarios d'application de valeur des grands modèles sont un facteur important dans le développement et la commercialisation des grands modèles ; les soi-disant scénarios font référence à l'objectif des modèles que nous formons et à leur capacité à créer une valeur fondamentale pour l'entreprise dans le cadre de la conformité légale. .
Li Kechen estime que les scénarios sont des environnements dans lesquels de grands modèles sont utilisés, et que la base du Big Data et de la technologie de l'IA repose sur les capacités ; les entreprises disposant de scénarios et de données industrielles seront plus rapides, plus efficaces et plus agiles lors de l'acquisition de capacités de grands modèles.
Les deux gammes de produits principales de WakeData sont l'accumulation de ces deux éléments : Weishu Cloud, en tant que plate-forme de données de nouvelle génération, dispose de puissantes capacités de traitement de données Big Data de l'Eed à la fin, et Weishu Cloud, en tant que nouvelle plate-forme numérique de première génération. La plate-forme de gestion client, qui comprend CDP, MA, SCRM, Loyalty et d'autres suites, propose un grand nombre de scénarios d'applications commerciales et, grâce à des stratégies de développement approfondies de l'industrie verticale, elle dispose d'un savoir-faire industriel plus solide et d'échantillons de formation plus précieux. Weishu Cloud publiera la version 5.0 en 2022. Ses capacités d'intégration de données, de calcul de données, d'analyse et de gouvernance des données, de visualisation des données et d'actif des données présentent toutes des avantages de pointe. Ces avantages côté données sont également devenus des obstacles à la concurrence pour les applications industrialisées d’intelligence artificielle à l’ère des grands modèles.
« Une atmosphère de travail favorisant la libération de la productivité a été initialement créée au sein de WakeData. Les capacités de WakeMind ont été utilisées dans des domaines tels que la conception de produits, les tests de développement et les opérations de marketing. L'application initiale a permis d'améliorer de 20 % l'efficacité humaine. Dans le cadre du développement accéléré de produits, cela améliore également l’efficacité de la livraison des projets clients et permet d’économiser du temps et des coûts pour la mise en œuvre des projets numériques des clients », a déclaré Qian Yong, CTO de WakeData.
La plate-forme Kunlun se compose de trois parties : le cloud de base, le cloud de développement et le cloud intégré. Il s'agit d'une base technologique native cloud très importante dans le processus de développement et de mise en œuvre des produits WakeData. Kunlun Platform Development Cloud s'appuie sur WakeMind. Les ingénieurs explorent déjà des applications telles que « basées sur la documentation du produit, aidant à générer la conception d'architecture et la conception de modèles de données correspondantes, puis aidant à générer du code et à détecter l'exactitude du code ». Par exemple, dans le processus de promotion de la conception axée sur le domaine, WakeMind peut aider à l'apprentissage du DDD et aider les ingénieurs dans la modélisation de domaine, les modèles de données peuvent être créés, modifiés, automatiquement complétés et améliorés grâce à l'interaction en langage naturel ; et une production rapide peut être obtenue des instructions SQL ; pendant le processus de développement du produit, en saisissant des documents sur le produit, en extrayant et en générant un glossaire du produit, et en fournissant des explications détaillées, etc.
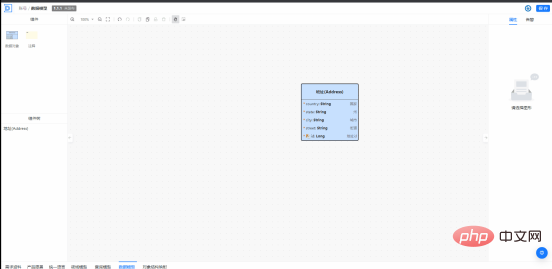
Pour les ingénieurs ordinaires, l'efficacité du développement peut être considérablement améliorée dans des domaines tels que la génération de code de règles, la génération automatique de tests unitaires, la révision et l'optimisation du code.
WakeMind propose un assistant de génération de rédaction accessible à tous.
Le service marketing a rapidement construit une matrice de croissance marketing grâce au Text to Video de l'IA.
L'autonomisation des industries et des domaines verticaux par l'AIGC est une tendance inévitable, et c'est également la voie de développement principale de WakeData depuis sa création. WakeData a toujours maintenu une attitude ouverte et inclusive envers les technologies et services de type ChatGPT, et y a activement participé. Sur la base de la stratégie de concentration sur les opérations industrialisées, WakeData a fermement saisi son chemin vers la valeur et la commercialisation. Le vaste modèle industriel de WakeMind aidera davantage d'entreprises à se révolutionner, à améliorer leur efficacité et à continuer de libérer leur productivité à l'ère de l'AIGC.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 L'application de grands modèles Tencent Yuanbao est en ligne ! Hunyuan est mis à niveau pour créer un assistant IA complet pouvant être transporté n'importe où
Jun 09, 2024 pm 10:38 PM
L'application de grands modèles Tencent Yuanbao est en ligne ! Hunyuan est mis à niveau pour créer un assistant IA complet pouvant être transporté n'importe où
Jun 09, 2024 pm 10:38 PM
Le 30 mai, Tencent a annoncé une mise à niveau complète de son modèle Hunyuan. L'application « Tencent Yuanbao » basée sur le modèle Hunyuan a été officiellement lancée et peut être téléchargée sur les magasins d'applications Apple et Android. Par rapport à la version de l'applet Hunyuan lors de la phase de test précédente, Tencent Yuanbao fournit des fonctionnalités de base telles que la recherche IA, le résumé IA et l'écriture IA pour les scénarios d'efficacité du travail ; pour les scénarios de la vie quotidienne, le gameplay de Yuanbao est également plus riche et fournit de multiples fonctionnalités d'application IA. , et de nouvelles méthodes de jeu telles que la création d'agents personnels sont ajoutées. « Tencent ne s'efforcera pas d'être le premier à créer un grand modèle. » Liu Yuhong, vice-président de Tencent Cloud et responsable du grand modèle Tencent Hunyuan, a déclaré : « Au cours de l'année écoulée, nous avons continué à promouvoir les capacités de Tencent. Grand modèle Tencent Hunyuan. Dans la technologie polonaise riche et massive dans des scénarios commerciaux tout en obtenant un aperçu des besoins réels des utilisateurs.
 Lancement du grand modèle Bytedance Beanbao, le service d'IA complet Volcano Engine aide les entreprises à se transformer intelligemment
Jun 05, 2024 pm 07:59 PM
Lancement du grand modèle Bytedance Beanbao, le service d'IA complet Volcano Engine aide les entreprises à se transformer intelligemment
Jun 05, 2024 pm 07:59 PM
Tan Dai, président de Volcano Engine, a déclaré que les entreprises qui souhaitent bien mettre en œuvre de grands modèles sont confrontées à trois défis clés : l'effet de modèle, le coût d'inférence et la difficulté de mise en œuvre : elles doivent disposer d'un bon support de base de grands modèles pour résoudre des problèmes complexes, et elles doivent également avoir une inférence à faible coût. Les services permettent d'utiliser largement de grands modèles, et davantage d'outils, de plates-formes et d'applications sont nécessaires pour aider les entreprises à mettre en œuvre des scénarios. ——Tan Dai, président de Huoshan Engine 01. Le grand modèle de pouf fait ses débuts et est largement utilisé. Le polissage de l'effet de modèle est le défi le plus critique pour la mise en œuvre de l'IA. Tan Dai a souligné que ce n'est que grâce à une utilisation intensive qu'un bon modèle peut être poli. Actuellement, le modèle Doubao traite 120 milliards de jetons de texte et génère 30 millions d'images chaque jour. Afin d'aider les entreprises à mettre en œuvre des scénarios de modèles à grande échelle, le modèle à grande échelle beanbao développé indépendamment par ByteDance sera lancé à travers le volcan.
 Grâce à la technologie Shengteng AI, le modèle de transport Qinling·Qinchuan aide Xi'an à construire un centre d'innovation en matière de transport intelligent
Oct 15, 2023 am 08:17 AM
Grâce à la technologie Shengteng AI, le modèle de transport Qinling·Qinchuan aide Xi'an à construire un centre d'innovation en matière de transport intelligent
Oct 15, 2023 am 08:17 AM
« Une complexité élevée, une fragmentation élevée et des domaines interdomaines » ont toujours été les principaux problèmes sur la voie de la mise à niveau numérique et intelligente du secteur des transports. Récemment, le « modèle de trafic Qinling·Qinchuan » avec une échelle de paramètres de 100 milliards, construit conjointement par China Science Vision, le gouvernement du district de Xi'an Yanta et le centre informatique d'intelligence artificielle du futur de Xi'an, est orienté vers le domaine des transports intelligents. et fournit des services à Xi'an et ses environs. La région créera un pivot pour l'innovation en matière de transport intelligent. Le « modèle de trafic Qinling·Qinchuan » combine les données écologiques massives du trafic local de Xi'an dans des scénarios ouverts, l'algorithme avancé original développé indépendamment par China Science Vision et la puissante puissance de calcul de l'IA Shengteng du futur centre informatique d'intelligence artificielle de Xi'an pour fournir la surveillance du réseau routier, les scénarios de transport intelligents tels que la commande d'urgence, la gestion de la maintenance et les déplacements publics entraînent des changements numériques et intelligents. La gestion du trafic présente des caractéristiques différentes selon les villes, et le trafic sur différentes routes
 Découverte du framework d'inférence de grands modèles NVIDIA : TensorRT-LLM
Feb 01, 2024 pm 05:24 PM
Découverte du framework d'inférence de grands modèles NVIDIA : TensorRT-LLM
Feb 01, 2024 pm 05:24 PM
1. Positionnement du produit TensorRT-LLM TensorRT-LLM est une solution d'inférence évolutive développée par NVIDIA pour les grands modèles de langage (LLM). Il crée, compile et exécute des graphiques de calcul basés sur le cadre de compilation d'apprentissage en profondeur TensorRT et s'appuie sur l'implémentation efficace des noyaux dans FastTransformer. De plus, il utilise NCCL pour la communication entre les appareils. Les développeurs peuvent personnaliser les opérateurs pour répondre à des besoins spécifiques en fonction du développement technologique et des différences de demande, comme le développement de GEMM personnalisés basés sur le coutelas. TensorRT-LLM est la solution d'inférence officielle de NVIDIA, engagée à fournir des performances élevées et à améliorer continuellement sa praticité. TensorRT-LL
 Référence GPT-4 ! Le grand modèle Jiutian de China Mobile a passé le double enregistrement
Apr 04, 2024 am 09:31 AM
Référence GPT-4 ! Le grand modèle Jiutian de China Mobile a passé le double enregistrement
Apr 04, 2024 am 09:31 AM
Selon des informations du 4 avril, l'Administration du cyberespace de Chine a récemment publié une liste de grands modèles enregistrés, et le « Grand modèle d'interaction du langage naturel Jiutian » de China Mobile y a été inclus, indiquant que le grand modèle Jiutian AI de China Mobile peut officiellement fournir des informations artificielles génératives. services de renseignement vers le monde extérieur. China Mobile a déclaré qu'il s'agit du premier modèle à grande échelle développé par une entreprise centrale à avoir réussi à la fois le double enregistrement national « Enregistrement du service d'intelligence artificielle générative » et le double enregistrement « Enregistrement de l'algorithme de service de synthèse profonde domestique ». Selon les rapports, le grand modèle d'interaction en langage naturel de Jiutian présente les caractéristiques de capacités, de sécurité et de crédibilité améliorées de l'industrie, et prend en charge la localisation complète. Il a formé plusieurs versions de paramètres telles que 9 milliards, 13,9 milliards, 57 milliards et 100 milliards. et peut être déployé de manière flexible dans le Cloud, la périphérie et la fin sont des situations différentes
 Pratique avancée du graphe de connaissances industrielles
Jun 13, 2024 am 11:59 AM
Pratique avancée du graphe de connaissances industrielles
Jun 13, 2024 am 11:59 AM
1. Introduction au contexte Tout d’abord, présentons l’historique du développement de la technologie Yunwen. Yunwen Technology Company... 2023 est la période où les grands modèles prédominent. De nombreuses entreprises pensent que l'importance des graphiques a été considérablement réduite après les grands modèles et que les systèmes d'information prédéfinis étudiés précédemment ne sont plus importants. Cependant, avec la promotion du RAG et la prévalence de la gouvernance des données, nous avons constaté qu'une gouvernance des données plus efficace et des données de haute qualité sont des conditions préalables importantes pour améliorer l'efficacité des grands modèles privatisés. Par conséquent, de plus en plus d'entreprises commencent à y prêter attention. au contenu lié à la construction des connaissances. Cela favorise également la construction et le traitement des connaissances à un niveau supérieur, où de nombreuses techniques et méthodes peuvent être explorées. On voit que l'émergence d'une nouvelle technologie ne détruit pas toutes les anciennes technologies, mais peut également intégrer des technologies nouvelles et anciennes.
 Nouveau benchmark de test publié, le Llama 3 open source le plus puissant est gêné
Apr 23, 2024 pm 12:13 PM
Nouveau benchmark de test publié, le Llama 3 open source le plus puissant est gêné
Apr 23, 2024 pm 12:13 PM
Si les questions du test sont trop simples, les meilleurs étudiants et les mauvais étudiants peuvent obtenir 90 points, et l'écart ne peut pas être creusé... Avec la sortie plus tard de modèles plus puissants tels que Claude3, Llama3 et même GPT-5, l'industrie est en besoin urgent d'un modèle de référence plus difficile et différencié. LMSYS, l'organisation à l'origine du grand modèle Arena, a lancé la référence de nouvelle génération, Arena-Hard, qui a attiré une large attention. Il existe également la dernière référence pour la force des deux versions affinées des instructions Llama3. Par rapport à MTBench, qui avait des scores similaires auparavant, la discrimination Arena-Hard est passée de 22,6 % à 87,4 %, ce qui est plus fort et plus faible en un coup d'œil. Arena-Hard est construit à partir de données humaines en temps réel provenant de l'arène et a un taux de cohérence de 89,1 % avec les préférences humaines.
 Xiaomi Byte unit ses forces ! Un grand modèle de l'accès de Xiao Ai à Doubao : déjà installé sur les téléphones mobiles et SU7
Jun 13, 2024 pm 05:11 PM
Xiaomi Byte unit ses forces ! Un grand modèle de l'accès de Xiao Ai à Doubao : déjà installé sur les téléphones mobiles et SU7
Jun 13, 2024 pm 05:11 PM
Selon les informations du 13 juin, selon le compte public « Volcano Engine » de Byte, l'assistant d'intelligence artificielle de Xiaomi « Xiao Ai » a conclu une coopération avec Volcano Engine. Les deux parties réaliseront une expérience interactive d'IA plus intelligente basée sur le grand modèle beanbao. . Il est rapporté que le modèle beanbao à grande échelle créé par ByteDance peut traiter efficacement jusqu'à 120 milliards de jetons de texte et générer 30 millions de contenus chaque jour. Xiaomi a utilisé le grand modèle Doubao pour améliorer les capacités d'apprentissage et de raisonnement de son propre modèle et créer un nouveau « Xiao Ai Classmate », qui non seulement saisit plus précisément les besoins des utilisateurs, mais offre également une vitesse de réponse plus rapide et des services de contenu plus complets. Par exemple, lorsqu'un utilisateur pose une question sur un concept scientifique complexe, &ldq
