

ChatGPT d'OpenAI est capable de comprendre une grande variété d'instructions humaines et de bien performer dans différentes tâches linguistiques. Ceci est possible grâce à une nouvelle méthode de réglage fin du modèle de langage à grande échelle appelée RLHF (Aligned Human Feedback via Reinforcement Learning).
La méthode RLHF libère la capacité du modèle de langage à suivre les instructions humaines, rendant les capacités du modèle de langage cohérentes avec les besoins et les valeurs humains.
Actuellement, les travaux de recherche du RLHF utilisent principalement l'algorithme PPO pour optimiser les modèles de langage. Cependant, l'algorithme PPO contient de nombreux hyperparamètres et nécessite que plusieurs modèles indépendants coopèrent les uns avec les autres pendant le processus d'itération de l'algorithme, de sorte que des détails d'implémentation erronés peuvent conduire à de mauvais résultats de formation.
En même temps, Les algorithmes d'apprentissage par renforcement ne sont pas nécessaires du point de vue de l'alignement humain.

Adresse papier : https://arxiv.org/abs/2304.05302v1
Adresse du projet : https://github.com/GanjinZero/RRHF
À cette fin, des auteurs de l'Alibaba Damo Academy et de l'Université Tsinghua ont proposé une méthode appelée alignement des préférences humaines basé sur le classement - RRHF.
RRHF Aucun apprentissage par renforcement n'est requis et les réponses générées par différents modèles de langage peuvent être exploitées, notamment ChatGPT, GPT-4 ou les modèles de formation actuels. RRHF fonctionne en notant les réponses et en les alignant sur les préférences humaines via une perte de classement.
Contrairement au PPO, le processus de formation du RRHF peut utiliser les résultats d'experts humains ou du GPT-4 à titre de comparaison. Le modèle RRHF formé peut être utilisé à la fois comme modèle de langage génératif et comme modèle de récompense.
Le PDG de Playgound AI a déclaré que c'était l'article le plus intéressant récemment
La figure suivante compare la différence entre l'algorithme PPO et l'algorithme RRHF.
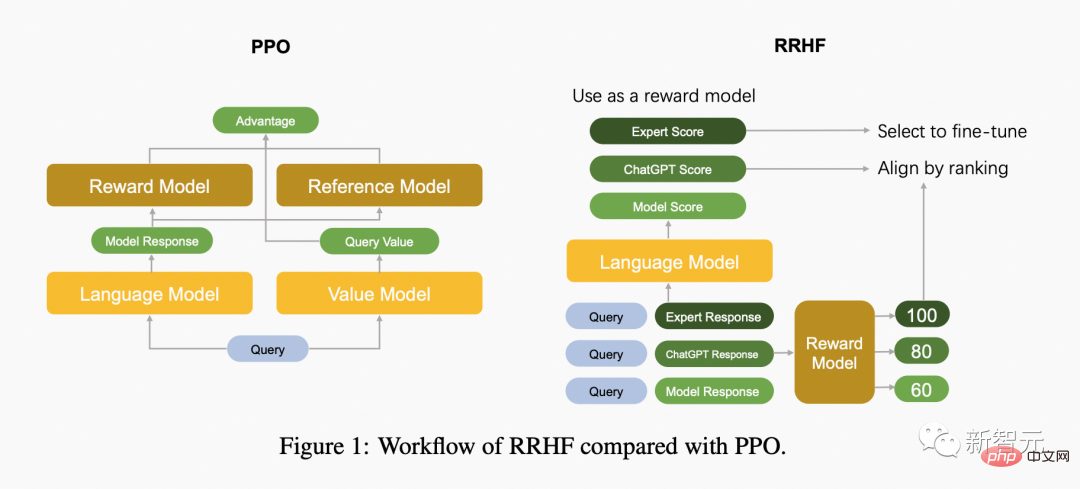
RRHF obtient d'abord k réponses via différentes méthodes pour la requête d'entrée, puis utilise le modèle de récompense pour noter ces k réponses respectivement. Chaque réponse est notée en utilisant une probabilité logarithmique :
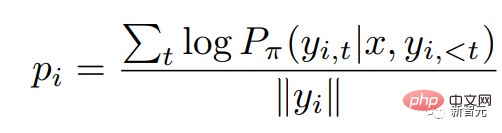
où est la distribution de probabilité du modèle linguistique autorégressif.
Nous espérons donner une plus grande probabilité aux réponses avec des scores élevés du modèle de récompense, c'est-à-dire que nous espérons égaler le score de récompense. Nous optimisons cet objectif grâce à la perte de classement :
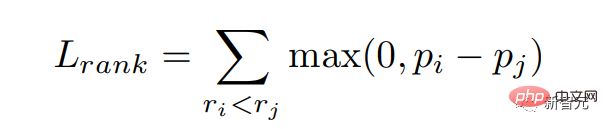
De plus, nous donnons également au modèle un objectif pour apprendre directement la réponse avec le score le plus élevé :
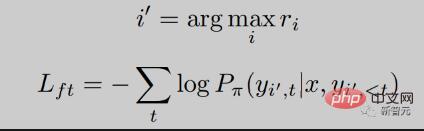
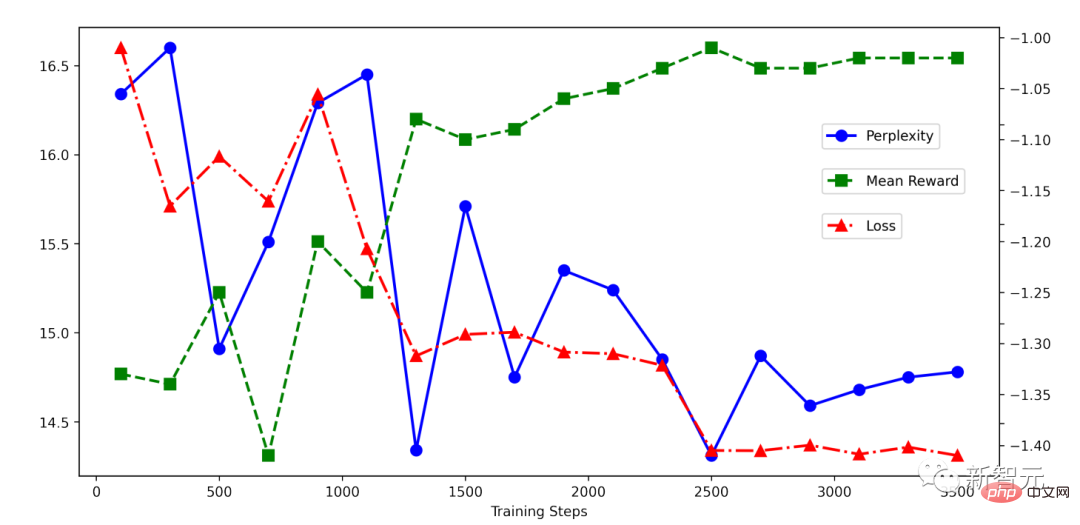
Vous pouvez voir que le RRHF Le processus de formation est très simple, ce qui suit est une diminution de la perte au cours de la formation RRHF. On peut voir que la diminution est très stable et que le score de récompense augmente régulièrement à mesure que la perte diminue.
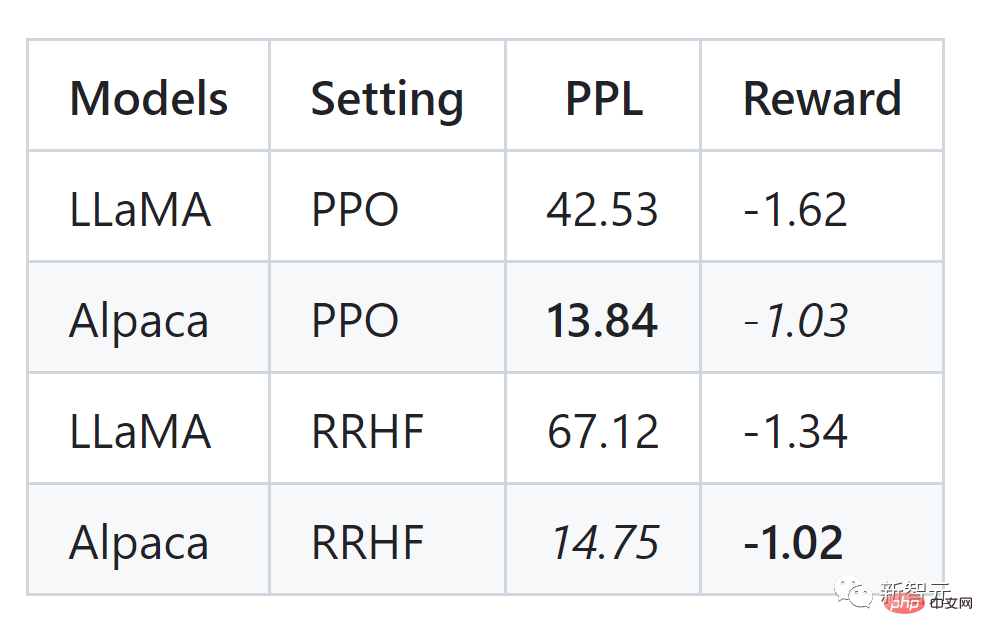
L'auteur de l'article a mené des expériences sur l'ensemble de données HH et peut également voir des résultats comparables à PPO :
L'algorithme RRHF peut efficacement faire correspondre la probabilité de sortie du modèle de langage avec celle de l'humain. Alignement des préférences, son idée de formation est très simple, et le modèle entraîné a plusieurs caractéristiques :
RRHF utilise chatGPT ou GPT-4 d'OpenAI comme modèle de notation et la sortie de ChatGPT, Alpaca et d'autres modèles comme échantillons de formation pour développer deux nouveaux modèles de langage, à savoir Wombat-7B et Wombat-7B -GPT4 . La durée de la formation varie de 2 à 4 heures et est très légère.
Wombat, en tant que nouveau modèle de pré-formation open source, peut mieux s'aligner sur les préférences humaines par rapport à LLaMA, Alpaca, etc. Les auteurs ont découvert expérimentalement que Wombat-7B possède des capacités complexes telles que le jeu de rôle et la conduite du raisonnement contrefactuel.
Si vous demandez à Wombat de présenter la future technologie de l'an 3000, Wombat répondra ainsi (traduit de l'anglais) :
J'espère que notre avenir s'améliorera de plus en plus comme le prédit Wombat.

Référence :
https://github.com/GanjinZero/RRHF
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Comment flasher le téléphone Xiaomi
Comment flasher le téléphone Xiaomi
 Comment centrer un div en CSS
Comment centrer un div en CSS
 Comment ouvrir un fichier rar
Comment ouvrir un fichier rar
 Méthodes de lecture et d'écriture de fichiers Java DBF
Méthodes de lecture et d'écriture de fichiers Java DBF
 Comment résoudre le problème de l'absence du fichier msxml6.dll
Comment résoudre le problème de l'absence du fichier msxml6.dll
 Formules de permutation et de combinaison couramment utilisées
Formules de permutation et de combinaison couramment utilisées
 Numéro de téléphone mobile virtuel pour recevoir le code de vérification
Numéro de téléphone mobile virtuel pour recevoir le code de vérification
 album photo dynamique
album photo dynamique








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



