
 Périphériques technologiques
IA
Penn Machine Learning PhD : Comment ai-je rédigé un article de premier ordre à partir de zéro ?
Périphériques technologiques
IA
Penn Machine Learning PhD : Comment ai-je rédigé un article de premier ordre à partir de zéro ?
Penn Machine Learning PhD : Comment ai-je rédigé un article de premier ordre à partir de zéro ?

J'ai récemment terminé un article très satisfaisant. Non seulement l'ensemble du processus a été agréable et mémorable, mais il a également permis d'obtenir un véritable « impact académique et industriel ». Je pense que cet article changera le paradigme de l'apprentissage profond de la confidentialité différentielle (DP).
Parce que cette expérience est tellement "coïncidente" (le processus est plein de coïncidences et la conclusion est extrêmement intelligente), j'aimerais partager avec mon camarades de classe ce que j'ai appris de cette expérience-->Conception-->Preuves empiriques-->Théorie-->Le processus complet des expériences à grande échelle. Je vais essayer de garder cet article léger et de ne pas impliquer trop de détails techniques.

Adresse papier : arxiv.org/abs/2206.07136#🎜🎜 #
Différent de l'ordre présenté dans l'article, l'article place parfois délibérément la conclusion au début pour attirer les lecteurs, ou introduit d'abord le théorème simplifié et met le théorème complet en annexe ; dans cet article, je pense Écrire mes expériences par ordre chronologique (c'est-à-dire un compte rendu), comme les détours que j'ai faits et les situations inattendues au cours de la recherche, pour la référence des étudiants qui viennent de s'engager dans la voie scientifique recherche.
1. Lecture de littératureL'origine de l'affaire est un article de Stanford, qui a maintenant été enregistré dans ICLR : #🎜🎜 ##🎜 🎜#

#🎜🎜 ##🎜 🎜#L'article est très bien écrit. En résumé, il a trois contributions principales :
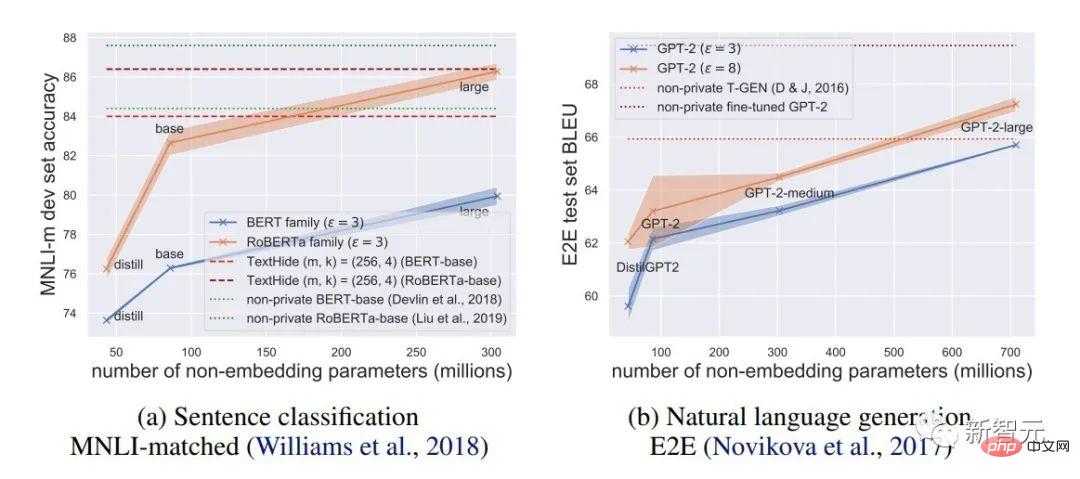
1. , la précision du modèle DP est très élevée, encourageant l'application de la confidentialité dans les modèles de langage. (En revanche, DP dans CV entraînera une très grande détérioration de la précision. Par exemple, CIFAR10 n'a actuellement qu'une précision de 80 % sans pré-entraînement en dessous de la limite DP, mais peut facilement atteindre 95 % sans prendre en compte DP ; la meilleure précision DP d'ImageNet au niveau le temps était inférieur à 50 % )
2 Sur le modèle de langage, plus le modèle est grand, meilleures seront les performances. Par exemple, l'amélioration des performances de GPT2 de 400 millions de paramètres à 800 millions de paramètres est évidente, et il a également réalisé de nombreux SOTA. (Mais dans les systèmes de CV et de recommandation, dans de nombreux cas, les performances des modèles plus grands seront très médiocres, voire proches d'une estimation aléatoire. Par exemple, la meilleure précision DP du CIFAR10 était auparavant obtenue par CNN à quatre couches, et non par ResNet.) # 🎜🎜## 🎜🎜#
Dans les tâches PNL, plus le modèle DP est grand, meilleures sont les performances [Xuechen et al. 2021]
#🎜 🎜#
#🎜🎜 #Le résumé ci-dessus est ce que j'ai compris immédiatement après avoir lu l'article. Le contenu entre parenthèses ne provient pas de cet article, mais de l'impression générée par de nombreuses lectures précédentes. Cela repose sur une accumulation de lectures à long terme et un degré élevé de capacité de généralisation pour associer et comparer rapidement.
En fait, il est difficile pour de nombreux étudiants de commencer à rédiger des articles car ils ne peuvent voir que le contenu d'un seul article et ne peuvent pas formuler des points de connaissances dans l'ensemble du réseau. et créer des associations. D'une part, les étudiants qui débutent ne lisent pas assez et ne maîtrisent pas encore suffisamment de connaissances. C'est particulièrement le cas des étudiants qui suivent depuis longtemps des projets des enseignants et ne proposent pas de manière indépendante. D'un autre côté, bien que la quantité de lecture soit suffisante, elle n'est pas résumée de temps en temps, ce qui fait que les informations ne sont pas condensées en connaissances ou que les connaissances ne sont pas connectées.Voici les connaissances de base sur l'apprentissage profond du DP. Je vais sauter la définition du DP pour le moment et cela n'affectera pas la lecture.
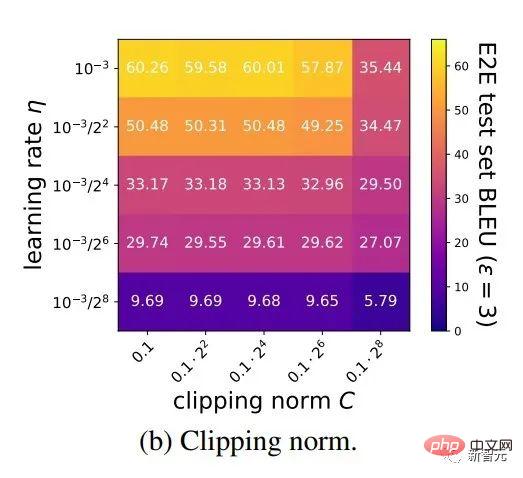
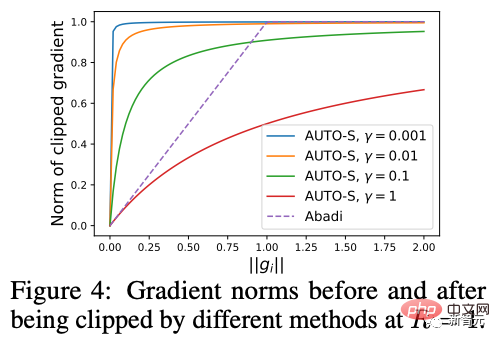
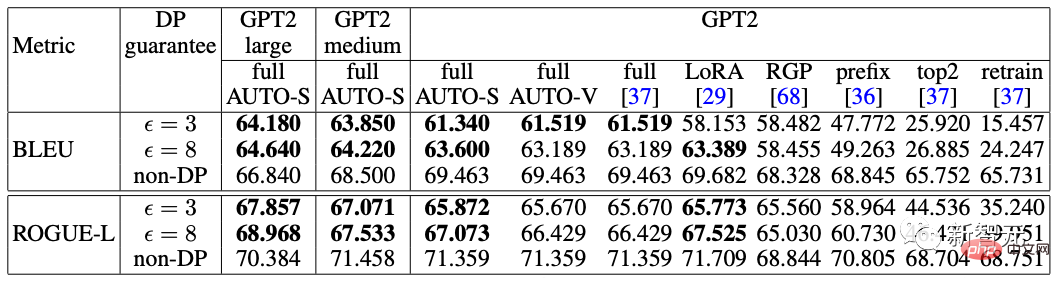
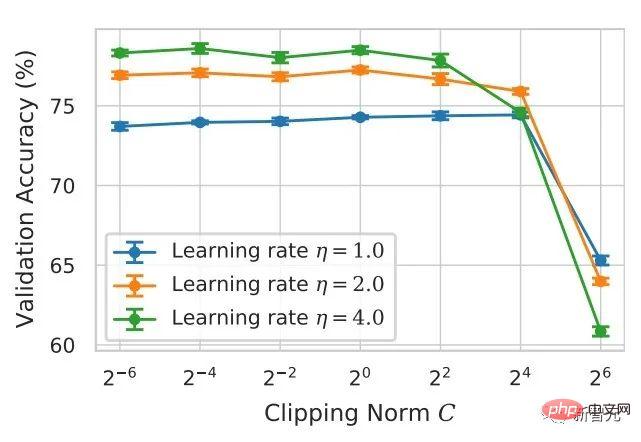
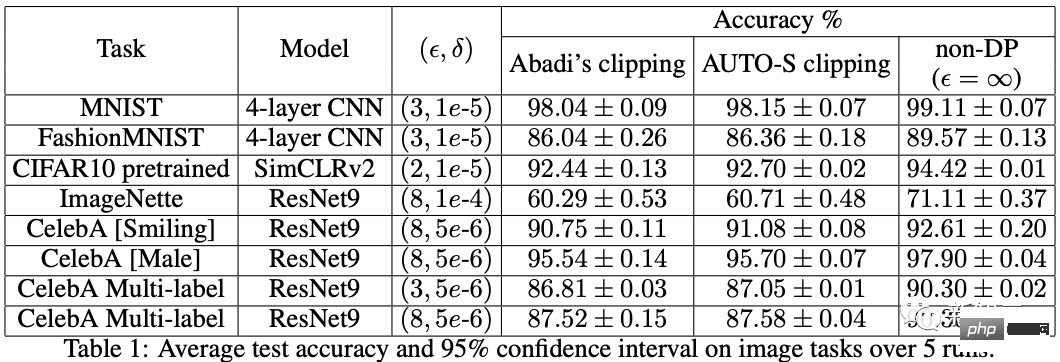
Le soi-disant apprentissage profond DP d'un point de vue algorithmique signifie en fait effectuer deux étapes supplémentaires : l'écrêtage du dégradé par échantillon et l'ajout de bruit gaussien, en d'autres termes, tant que vous traitez le dégradé selon ces deux étapes (traité) ; gradient est appelé gradient privé), vous pouvez utiliser l'optimiseur comme vous le souhaitez, y compris SGD/Adam. Quant à savoir dans quelle mesure l'algorithme final est privé, c'est une question qui relève d'un autre sous-domaine, appelé théorie de la comptabilité de confidentialité. Ce domaine est relativement mature et nécessite une base théorique solide puisque cet article se concentre sur l’optimisation, il ne sera pas mentionné ici. g_i est le gradient d'un point de données (gradient par échantillon), R est le seuil d'écrêtage et sigma est le multiplicateur de bruit. Clip est appelé fonction de découpage, tout comme le découpage de dégradé ordinaire. Si le dégradé est plus long que R, il sera coupé à R, et s'il est inférieur à R, il ne bougera pas. Par exemple, la version DP de SGD est actuellement utilisée dans tous les articles utilisant la fonction de découpage dans le travail pionnier de l'apprentissage profond en matière de confidentialité (Abadi, Martin et al. "Deep learning with différentiel Privacy"), également connu comme coupure d'Abadi : Mais cela est complètement inutile. En suivant les premiers principes et en partant de la théorie de la comptabilité de confidentialité, en fait, la fonction de découpage doit seulement satisfaire que le module de Clip(g_i)*g_i est inférieur ou égal à R. En d’autres termes, le découpage d’Abadi n’est qu’une fonction qui satisfait à cette condition, mais ce n’est en aucun cas la seule. Il y a de nombreux points brillants dans un article, mais je ne peux pas tous les utiliser. Je dois juger quelle est la plus grande contribution en fonction de mes propres besoins et expertise. Les deux premières contributions de cet article sont en réalité très empiriques et difficiles à creuser. La dernière contribution est très intéressante. J'ai regardé attentivement l'étude d'ablation des hyperparamètres et j'ai trouvé un point que l'auteur original n'a pas trouvé : lorsque le seuil d'écrêtage est suffisamment petit, en fait, le seuil d'écrêtage (c'est-à-dire la norme d'écrêtage C , dans la formule ci-dessus et R est une variable) n'a aucun effet. Longitudinalement, C=0,1, 0,4, 1,6 n'a aucune différence avec DP-Adam [Xuechen et al. Cela a éveillé mon intérêt et j'ai senti qu'il devait y avoir un principe derrière cela. J'ai donc écrit à la main le DP-Adam qu'ils utilisaient pour voir pourquoi. En fait, c'est très simple : Si R est suffisamment petit, l'écrêtage équivaut en fait à une normalisation ! En le remplaçant simplement par le gradient privé (1.1), R peut être extrait respectivement de la partie découpage et de la partie bruitage : Et la forme d'Adam fait apparaître R à la fois dans le dégradé et dans la taille du pas adaptatif, le numérateur Une fois les dénominateurs annulés, R disparaît et l'idée est là ! M et v dépendent tous deux du dégradé, et leur remplacement par des dégradés privés donne lieu à DP-AdamW. Une substitution aussi simple prouve mon premier théorème : dans DP-AdamW, des seuils d'écrêtage suffisamment petits sont équivalents les uns aux autres, et aucun ajustement de paramètre n'est requis. Il s’agit sans aucun doute d’une observation concise et intéressante, mais elle n’a pas assez de sens, je dois donc réfléchir à l’utilité pratique de cette observation. En fait, cela signifie que la formation DP réduit le travail d'ajustement des paramètres d'un ordre de grandeur : en supposant que le taux d'apprentissage et R soient ajustés à 5 valeurs chacun (comme indiqué ci-dessus), puis 25 les combinaisons doivent être testées pour trouver les hyperparamètres optimaux. Il ne vous reste plus qu'à ajuster le taux d'apprentissage selon 5 possibilités, et l'efficacité du réglage des paramètres a été améliorée à plusieurs reprises. Il s'agit d'un problème très précieux pour l'industrie. L'intention est suffisamment élevée, les mathématiques sont suffisamment concises et une bonne idée a commencé à prendre forme. S'il n'est établi que pour Adam/AdamW, les limites de ce travail sont encore trop grandes, donc je rapidement Extensions à AdamW et à d'autres optimiseurs adaptatifs, tels qu'AdaGrad. En fait, pour tous les optimiseurs adaptatifs, il peut être prouvé que le seuil d’écrêtage sera décalé, il n’est donc pas nécessaire d’ajuster les paramètres, ce qui augmente considérablement la richesse du théorème. Il y a un autre petit détail intéressant ici. Comme nous le savons tous, Adam avec une perte de poids est différent d'AdamW. Ce dernier utilise une perte de poids découplée, et un article de l'ICLR a été publié sur cette différence 🎜# Cette différence existe également dans l'optimiseur DP. La même chose est vraie pour Adam. Si la perte de poids découplée est utilisée, la mise à l’échelle de R n’affecte pas l’ampleur de la perte de poids. Cependant, si la perte de poids ordinaire est utilisée, agrandir R de deux fois équivaut à réduire la perte de poids de deux fois. 4. Il existe un autre monde Les étudiants intelligents ont peut-être découvert que je continue de mettre l'accent sur l'optimiseur adaptatif, pourquoi n'en parlerais-je pas SGD ? Quoi ? La réponse est qu'après avoir fini d'écrire la théorie de l'optimiseur adaptatif DP, Google a publié un article sur DP-SGD utilisé dans CV et a également réalisé une étude sur l'ablation, mais les règles étaient complètement différentes de celles trouvées dans Adam I. il me restait j'ai fait une impression diagonale Pour DP-SGD et R est assez petit, Une augmentation de 10 fois de lr équivaut à une augmentation de 10 fois de R [https://arxiv.org/abs/2201.12328]. J'étais très excité quand j'ai vu cet article, car c'était un autre article qui prouvait l'efficacité du petit seuil d'écrêtage. Remplacez-le simplement et constatez que SGD est plus facile à analyser qu'Adam (1.3) peut être approximé comme : . #🎜 🎜# Évidemment R peut être proposé à nouveau et combiné avec le taux d'apprentissage, prouvant théoriquement l'observation de Google. C'est dommage que Google n'ait vu que le phénomène et ne se soit pas élevé au niveau de la théorie. Il y a aussi une coïncidence ici, c'est-à-dire qu'ils ont dessiné une étude d'ablation de deux échelles en même temps dans l'image ci-dessus. Seule l'échelle de gauche peut voir la ligne diagonale. Il n'y a pas de conclusion en regardant simplement le côté droit. Comme il n'y a pas de taille de pas adaptative, SGD n'ignore pas R comme Adam, mais considère R comme faisant partie du taux d'apprentissage, il n'est donc pas nécessaire de l'ajuster séparément Quoi qu'il en soit, le taux d'apprentissage doit être ajusté ensemble. Ensuite, étendez la théorie de SGD à l'élan, et tous les optimiseurs pris en charge par Pytorch ont été analysés. 5. De l'intuition à la rigueur Selon le principe d'Iron Man Corps de Doraemon, j'ai directement nommé la normalisation comme la nouvelle fonction de découpage de gradient par échantillon, qui a remplacé le découpage Abadi utilisé dans tout le domaine depuis 6 ans. C'est mon deuxième point d'innovation. Après la preuve de tout à l'heure, le nouveau détourage ne nécessite strictement pas de R, on l'appelle donc détourage automatique (AUTO-V ; V pour vanille). Étant donné que la forme est différente du découpage d'Abadi, la précision sera différente et mon découpage peut présenter des inconvénients. Je dois donc écrire du code pour tester ma nouvelle méthode, et cela ne nécessite de changer qu'une seule ligne de code (après tout, c'est juste En fait, il existe principalement trois fonctions de découpage dans le sens du découpage de dégradé DP par échantillon. En plus du découpage d'Abadi, les deux sont proposées par moi, et l'autre est ce découpage automatique. Dans mon travail précédent, je savais déjà comment modifier le découpage dans diverses bibliothèques populaires. J'ai mis la méthode de modification en annexe à la fin de l'article. Après mes tests, j'ai découvert que dans l'article de Stanford, pendant tout le processus de formation de GPT2, toutes les itérations et tous les gradients par échantillon étaient tronqués. En d'autres termes, au moins dans cette expérience, le découpage d'Abadi est tout à fait équivalent au découpage automatique. Bien que les expériences ultérieures aient perdu face à SOTA, cela a montré que ma nouvelle méthode a suffisamment de valeur : une fonction d'écrêtage qui n'a pas besoin d'ajuster le seuil d'écrêtage, et parfois la précision ne sera pas sacrifiée. L'article de Stanford présente deux principaux types d'expériences de modèles de langage, l'une est la tâche générative où GPT2 est le modèle, et l'autre est la tâche de classification où RoBERTa est le modèle. Bien que le découpage automatique soit équivalent au découpage d'Abadi sur les tâches de génération, la précision des tâches de classification est toujours inférieure de quelques points. En raison de mes propres habitudes académiques, je ne modifierai pas l'ensemble de données pour le moment, puis sélectionnerai nos expériences dominantes à publier, et encore moins ajouterai des astuces (telles que l'amélioration des données et la modification du modèle magique). J'espère que dans une comparaison tout à fait équitable, je ne pourrai comparer que le découpage de dégradé par échantillon et obtenir le meilleur effet sans humidité possible. En fait, lors de discussions avec nos collaborateurs, nous avons constaté que la normalisation pure et le découpage d'Abadi éliminent complètement les informations sur la taille du dégradé, c'est-à-dire que pour le découpage automatique, quelle que soit la taille du dégradé d'origine, le découpage est R. Si grand, et Abadi conserve les informations de taille pour les gradients plus petits que R. Sur la base de cette idée, nous avons apporté un changement petit mais extrêmement intelligent, appelé AUTO-S clipping (S signifie stable) La fusion de R et du taux d'apprentissage devient Un simple dessin peut révéler que ce petit (généralement réglé à 0,01, en fait, il peut être réglé à n'importe quel autre nombre positif, très robuste) peut retenir l'information de la taille du dégradé : Basé sur ceci , ou changez simplement une ligne, réexécutez le code de Stanford et vous obtiendrez le SOTA de six ensembles de données NLP. AUTO-S surpasse toutes les autres fonctions de découpage sur la tâche de génération E2E, ainsi que sur la tâche de classification SST2/MNLI/QNLI/QQP. Une des limites de l'article de Stanford est qu'il se concentre uniquement sur la PNL. Ce qui est une coïncidence, c'est que deux mois après que Google ait brossé le DP SOTA d'ImageNet, la filiale de Google, DeepMind, a publié un article L'article dans lequel DP brille. CV augmente directement la précision d'ImageNet de 48 % à 84 % ! Adresse papier : https://arxiv.org/abs/2204.13650 Dans cet article, j'ai d'abord regardé le choix de l'optimiseur et du seuil d'écrêtage jusqu'à ce que l'annexe se tourne vers cette image : Le SOTA de DP-SGD sur ImageNet nécessite également que le seuil d'écrêtage soit suffisamment petit. Pourtant, le petit seuil d'écrêtage fonctionne mieux ! Avec trois articles de haute qualité prenant en charge le détourage automatique, j'ai déjà une forte motivation, et je suis de plus en plus sûr que mon travail sera remarquable. Par coïncidence, cet article de DeepMind est aussi une pure expérience sans théorie, qui les a également amenés à presque se rendre compte qu'ils peuvent théoriquement ne pas avoir besoin de R. En fait, ils sont vraiment très proches de mon idée, et ils ont même déjà Il a été découvert que R peut être extrait et intégré au taux d'apprentissage (les étudiants intéressés peuvent consulter leurs formules (2) et (3)). Mais l'inertie de la coupure d'Abadi était trop grande... Même s'ils ont compris les règles, ils ne sont pas allés plus loin. DeepMind a également constaté qu'un petit seuil d'écrêtage fonctionne mieux, mais n'a pas compris pourquoi. Inspiré par ce nouveau travail, j'ai commencé à expérimenter le CV afin que mon algorithme puisse être utilisé par tous les chercheurs DP, au lieu d'utiliser un ensemble de méthodes pour la PNL et un autre pour le CV. Un bon algorithme doit être universel et facile à utiliser. Les faits ont également prouvé que le découpage automatique peut également atteindre SOTA sur des ensembles de données CV. En regardant tous les articles ci-dessus, SOTA a été considérablement amélioré et les effets d'ingénierie sont complets, mais la théorie est complètement vide. Une fois toutes les expériences terminées, la contribution de ce travail a dépassé les exigences d'une conférence de haut niveau : j'ai grandement simplifié l'impact des paramètres de DP-SGD et DP-Adam provoqué par un petit seuil d'écrêtage dans l'expérience ; la fonction d'écrêtage sans sacrifier l'efficacité du calcul, la confidentialité et sans ajustement des paramètres ; a réparé les dommages causés aux informations sur la taille du gradient par l'écrêtage et la normalisation d'Abadi. Des expériences PNL et CV suffisantes ont atteint le taux de précision SOTA ; Je ne suis pas encore satisfait. Un optimiseur sans support théorique n’est toujours pas en mesure d’apporter une contribution substantielle au deep learning. Des dizaines de nouveaux optimiseurs sont proposés chaque année, et tous sont abandonnés la deuxième année. Il n’en existe encore que quelques-uns officiellement pris en charge par Pytorch et réellement utilisés par l’industrie. Pour cette raison, mes collaborateurs et moi avons passé deux mois supplémentaires à faire une analyse automatique de convergence DP-SGD. Le processus était difficile mais la preuve finale a été simplifiée à l'extrême. La conclusion est également très simple : l'impact de la taille du lot, du taux d'apprentissage, de la taille du modèle, de la taille de l'échantillon et d'autres variables sur la convergence est exprimé quantitativement et est cohérent avec tous les comportements de formation DP connus. En particulier, nous avons prouvé que bien que DP-SGD converge plus lentement que le SGD standard, lorsque l'itération tend vers l'infini, la vitesse de convergence est d'un ordre de grandeur. Cela donne confiance dans le calcul de la confidentialité : le modèle DP converge, quoique tardivement. Enfin, l'article que j'écris depuis 7 mois est terminé. De façon inattendue, les coïncidences ne se sont pas encore arrêtées. NeurIPS a soumis l'article en mai et les modifications internes ont été achevées le 14 juin et publiées sur arXiv. En conséquence, le 27 juin, j'ai vu que Microsoft Research Asia (MSRA) avait publié un article qui entrait en collision avec le nôtre. exactement le même que notre détourage automatique : Exactement le même que notre AUTO-S. En regardant attentivement, même la preuve de convergence est presque la même. Et nos deux groupes n'ont pas d'intersection. On peut dire qu'une coïncidence est née de l'autre côté de l'océan Pacifique. Parlons un peu de la différence entre les deux articles : l'autre article est plus théorique, par exemple, il analyse en plus la convergence d'Abadi DP-SGD (je n'ai prouvé que le détourage automatique, qui est DP-NSGD en leur article, peut-être que je ne sais pas non plus comment ajuster DP-SGD) ; les hypothèses utilisées sont également quelque peu différentes et nos expériences sont de plus en plus vastes (plus d'une douzaine d'ensembles de données) et la relation d'équivalence entre le découpage d'Abadi ; et la normalisation est établie plus explicitement, comme les théorèmes 1 et 2 expliquent pourquoi R peut être utilisé sans ajustement des paramètres. Comme nous travaillons en même temps, je suis très heureux qu'il y ait des gens qui sont d'accord les uns avec les autres et peuvent se compléter et promouvoir conjointement cet algorithme, afin que toute la communauté puisse croire en ce résultat et en bénéficier le plus tôt possible. Bien sûr, égoïstement, je me rappelle aussi que le prochain article sera accéléré ! En repensant au processus créatif de cet article, depuis le point de départ, les compétences de base doivent être la condition préalable, et une autre condition préalable importante est que j'ai toujours pensé au problème de l'ajustement des paramètres. La sécheresse a été longue, alors lire le bon article peut vous aider à trouver du nectar. Quant au processus, le cœur réside dans l’habitude de théoriser mathématiquement l’observation. Dans ce travail, la capacité à implémenter du code n’est pas la plus importante. J'écrirai une autre chronique axée sur un autre travail de codage intensif ; l'analyse finale de la convergence repose également sur mes collaborateurs et sur ma propre indomptabilité. Heureusement, vous n’avez pas peur d’être en retard pour un bon repas, alors continuez ! 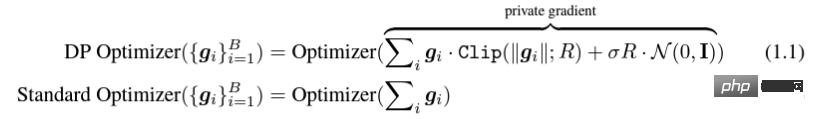
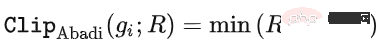 .
. 2. Point d'entrée
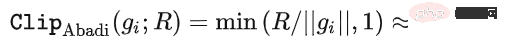
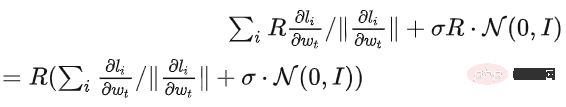
3. Expansion simple

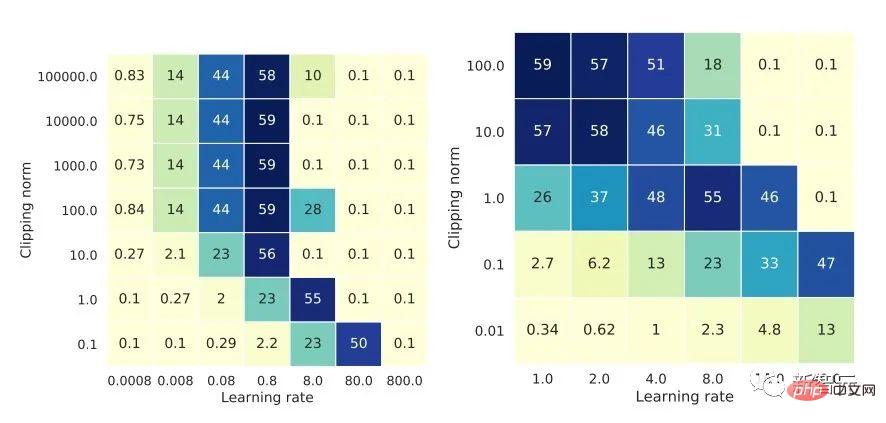
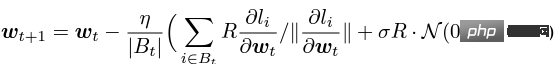 「Plus précisément, lorsque la norme d'écrêtage est diminuée k fois, le taux d'apprentissage doit être augmenté k fois pour maintenir une précision similaire.」
「Plus précisément, lorsque la norme d'écrêtage est diminuée k fois, le taux d'apprentissage doit être augmenté k fois pour maintenir une précision similaire.」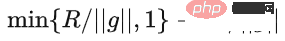 ).
). 6. Retour à la pensée abstraite
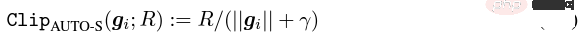
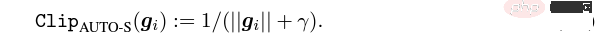
7. Créez un algorithme général


8. La théorie est l'os et l'expérience est les ailes
9. Accident de voiture...

10. Résumé
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Ligne de commande de l'arrêt CentOS
Apr 14, 2025 pm 09:12 PM
Ligne de commande de l'arrêt CentOS
Apr 14, 2025 pm 09:12 PM
La commande de fermeture CENTOS est arrêtée et la syntaxe est la fermeture de [options] le temps [informations]. Les options incluent: -H Arrêtez immédiatement le système; -P éteignez l'alimentation après l'arrêt; -r redémarrer; -t temps d'attente. Les temps peuvent être spécifiés comme immédiats (maintenant), minutes (minutes) ou une heure spécifique (HH: mm). Des informations supplémentaires peuvent être affichées dans les messages système.
 Quelles sont les méthodes de sauvegarde pour Gitlab sur Centos
Apr 14, 2025 pm 05:33 PM
Quelles sont les méthodes de sauvegarde pour Gitlab sur Centos
Apr 14, 2025 pm 05:33 PM
La politique de sauvegarde et de récupération de GitLab dans le système CentOS afin d'assurer la sécurité et la récupérabilité des données, Gitlab on CentOS fournit une variété de méthodes de sauvegarde. Cet article introduira plusieurs méthodes de sauvegarde courantes, paramètres de configuration et processus de récupération en détail pour vous aider à établir une stratégie complète de sauvegarde et de récupération de GitLab. 1. MANUEL BACKUP Utilisez le Gitlab-RakegitLab: Backup: Créer la commande pour exécuter la sauvegarde manuelle. Cette commande sauvegarde des informations clés telles que le référentiel Gitlab, la base de données, les utilisateurs, les groupes d'utilisateurs, les clés et les autorisations. Le fichier de sauvegarde par défaut est stocké dans le répertoire / var / opt / gitlab / backups. Vous pouvez modifier / etc / gitlab
 Comment vérifier la configuration de CentOS HDFS
Apr 14, 2025 pm 07:21 PM
Comment vérifier la configuration de CentOS HDFS
Apr 14, 2025 pm 07:21 PM
Guide complet pour vérifier la configuration HDFS dans les systèmes CentOS Cet article vous guidera comment vérifier efficacement la configuration et l'état de l'exécution des HDF sur les systèmes CentOS. Les étapes suivantes vous aideront à bien comprendre la configuration et le fonctionnement des HDF. Vérifiez la variable d'environnement Hadoop: Tout d'abord, assurez-vous que la variable d'environnement Hadoop est correctement définie. Dans le terminal, exécutez la commande suivante pour vérifier que Hadoop est installé et configuré correctement: HadoopVersion Check HDFS Fichier de configuration: Le fichier de configuration de base de HDFS est situé dans le répertoire / etc / hadoop / conf / le répertoire, où Core-site.xml et hdfs-site.xml sont cruciaux. utiliser
 Comment est la prise en charge du GPU pour Pytorch sur Centos
Apr 14, 2025 pm 06:48 PM
Comment est la prise en charge du GPU pour Pytorch sur Centos
Apr 14, 2025 pm 06:48 PM
Activer l'accélération du GPU Pytorch sur le système CentOS nécessite l'installation de versions CUDA, CUDNN et GPU de Pytorch. Les étapes suivantes vous guideront tout au long du processus: CUDA et CUDNN Installation détermineront la compatibilité de la version CUDA: utilisez la commande NVIDIA-SMI pour afficher la version CUDA prise en charge par votre carte graphique NVIDIA. Par exemple, votre carte graphique MX450 peut prendre en charge CUDA11.1 ou plus. Téléchargez et installez Cudatoolkit: visitez le site officiel de Nvidiacudatoolkit et téléchargez et installez la version correspondante selon la version CUDA la plus élevée prise en charge par votre carte graphique. Installez la bibliothèque CUDNN:
 Explication détaillée du principe docker
Apr 14, 2025 pm 11:57 PM
Explication détaillée du principe docker
Apr 14, 2025 pm 11:57 PM
Docker utilise les fonctionnalités du noyau Linux pour fournir un environnement de fonctionnement d'application efficace et isolé. Son principe de travail est le suivant: 1. Le miroir est utilisé comme modèle en lecture seule, qui contient tout ce dont vous avez besoin pour exécuter l'application; 2. Le Système de fichiers Union (UnionFS) empile plusieurs systèmes de fichiers, ne stockant que les différences, l'économie d'espace et l'accélération; 3. Le démon gère les miroirs et les conteneurs, et le client les utilise pour l'interaction; 4. Les espaces de noms et les CGROUP implémentent l'isolement des conteneurs et les limitations de ressources; 5. Modes de réseau multiples prennent en charge l'interconnexion du conteneur. Ce n'est qu'en comprenant ces concepts principaux que vous pouvez mieux utiliser Docker.
 CentOS installe MySQL
Apr 14, 2025 pm 08:09 PM
CentOS installe MySQL
Apr 14, 2025 pm 08:09 PM
L'installation de MySQL sur CENTOS implique les étapes suivantes: Ajout de la source MySQL YUM appropriée. Exécutez la commande YUM Install MySQL-Server pour installer le serveur MySQL. Utilisez la commande mysql_secure_installation pour créer des paramètres de sécurité, tels que la définition du mot de passe de l'utilisateur racine. Personnalisez le fichier de configuration MySQL selon les besoins. Écoutez les paramètres MySQL et optimisez les bases de données pour les performances.
 CentOS8 redémarre SSH
Apr 14, 2025 pm 09:00 PM
CentOS8 redémarre SSH
Apr 14, 2025 pm 09:00 PM
La commande pour redémarrer le service SSH est: SystemCTL Redémarrer SSHD. Étapes détaillées: 1. Accédez au terminal et connectez-vous au serveur; 2. Entrez la commande: SystemCTL Restart SSHD; 3. Vérifiez l'état du service: SystemCTL Status Sshd.
 Comment faire fonctionner la formation distribuée de Pytorch sur CentOS
Apr 14, 2025 pm 06:36 PM
Comment faire fonctionner la formation distribuée de Pytorch sur CentOS
Apr 14, 2025 pm 06:36 PM
La formation distribuée par Pytorch sur le système CentOS nécessite les étapes suivantes: Installation de Pytorch: La prémisse est que Python et PIP sont installés dans le système CentOS. Selon votre version CUDA, obtenez la commande d'installation appropriée sur le site officiel de Pytorch. Pour la formation du processeur uniquement, vous pouvez utiliser la commande suivante: pipinstalltorchtorchVisionTorChaudio Si vous avez besoin d'une prise en charge du GPU, assurez-vous que la version correspondante de CUDA et CUDNN est installée et utilise la version Pytorch correspondante pour l'installation. Configuration de l'environnement distribué: la formation distribuée nécessite généralement plusieurs machines ou des GPU multiples uniques. Lieu
