
 Périphériques technologiques
IA
Le Shanghai Digital Brain Research Institute lance DB1, le premier grand modèle de prise de décision multimodal de Chine, capable de permettre une prise de décision rapide sur des problèmes ultra-complexes
Périphériques technologiques
IA
Le Shanghai Digital Brain Research Institute lance DB1, le premier grand modèle de prise de décision multimodal de Chine, capable de permettre une prise de décision rapide sur des problèmes ultra-complexes
Le Shanghai Digital Brain Research Institute lance DB1, le premier grand modèle de prise de décision multimodal de Chine, capable de permettre une prise de décision rapide sur des problèmes ultra-complexes

Récemment, l'Institut de recherche sur le cerveau numérique de Shanghai (ci-après dénommé « Institut de recherche sur le cerveau numérique ») a lancé le premier modèle de prise de décision multimodale de cerveau numérique à grande échelle (appelé DB1), remplissant l'écart dans cet aspect en Chine et au-delà Le potentiel du modèle pré-entraîné dans la prise de décision de texte, d'image-texte, d'apprentissage par renforcement et de prise de décision d'optimisation des opérations a été vérifié. Actuellement, nous avons open source le code DB1 sur Github, lien du projet : https://github.com/Shanghai-Digital-Brain-Laboratory/BDM-DB1.
Auparavant, l'Institut des Sciences Mathématiques proposait MADT (https://arxiv.org/abs/2112.02845)/MAT (https://arxiv.org/abs /2205.14953 ) et d'autres modèles multi-agents, via la modélisation de séquences dans certains grands modèles hors ligne, en utilisant le modèle Transformer pour obtenir des résultats remarquables sur certaines tâches mono/multi-agents, et continuer à mener des recherches et des explorations dans cette direction.
Au cours des dernières années, avec la montée en puissance des grands modèles pré-entraînés, le monde universitaire et l'industrie ont continué à faire de nouveaux progrès dans le nombre de paramètres et les tâches multimodales. de modèles pré-entraînés. Ces dernières années, les modèles de pré-entraînement à grande échelle ont été considérés comme l'une des voies importantes vers l'intelligence artificielle générale grâce à une modélisation approfondie de données et de connaissances massives. L'Institut de recherche numérique, qui se concentre sur la recherche sur l'intelligence décisionnelle, a tenté de manière innovante de copier le succès du modèle pré-entraîné dans les tâches de prise de décision et a réalisé une percée.
Grand modèle de prise de décision multimodale DB1
Auparavant, DeepMind avait lancé Gato, qui combinait des tâches de prise de décision à agent unique, multi -conversations rondes et images- La tâche de génération de texte a été unifiée en un problème autorégressif basé sur Transformer et a obtenu de bonnes performances sur 604 tâches différentes, montrant que certains problèmes simples de prise de décision d'apprentissage par renforcement peuvent être résolus grâce à la prédiction de séquence. direction de recherche de grands modèles de prise de décision.
Cette fois, la DB1 lancée par l'Institut des sciences mathématiques a principalement reproduit et vérifié Gato, et analysé la structure du réseau et le nombre de paramètres, le type de tâche et le numéro de tâche. ont été tentées :
-
Volume des paramètres et structure du réseau : le volume des paramètres DB1 atteint 1,21 milliard. Essayez d'être aussi proche que possible de Gato en termes de paramètres. Globalement, l'Institut de Recherche Numérique utilise une structure similaire à Gato (même nombre de blocs décodeurs, taille de couche cachée, etc.), mais dans FeedForwardNetwork, puisque la fonction d'activation GeGLU introduira 1/3 supplémentaire du nombre de paramètres, l'Institut des sciences mathématiques veut que la quantité de paramètres soit proche de Gato, et l'état de la couche cachée de 4 * n_embed dimensions est transformé en 2 * n_embed caractéristiques dimensionnelles grâce à la fonction d'activation GeGLU. Sinon, nous partageons les paramètres d'intégration du côté de l'encodage d'entrée et de sortie avec l'implémentation de Gato. Différent de Gato, nous adoptons la solution PostNorm pour sélectionner la normalisation des couches et nous utilisons des calculs de précision mixte dans Attention pour améliorer la stabilité numérique.
- Type de tâche et nombre de tâches : Le nombre de tâches expérimentales dans DB1 a atteint 870, soit une augmentation de 44,04 % par rapport à Gato Par rapport à Gato, les performances de l'expert sont améliorées de 2,23 % >=50 %. En termes de types de tâches spécifiques, DB1 hérite principalement des tâches de prise de décision, d'image et de texte de Gato, et le nombre de tâches diverses reste fondamentalement le même. Mais en termes de tâches de prise de décision, DB1 a également introduit plus de 200 tâches de scénarios réels, à savoir le problème du voyageur de commerce (TSP) à l'échelle de 100 et 200 nœuds. Ce type de tâche sélectionne aléatoirement 100 à 200 emplacements géographiques. (représentation dans toutes les grandes villes de Chine).
On constate que la performance globale de DB1 a atteint le même niveau que celle de Gato, et a commencé à évoluer vers un champ de demande plus proche de Il résout très bien le problème NP-hard TSP, mais Gato n'a jamais exploré cette direction auparavant.
 Comparaison des indicateurs DB1 (droite) et GATO (gauche)
Comparaison des indicateurs DB1 (droite) et GATO (gauche)
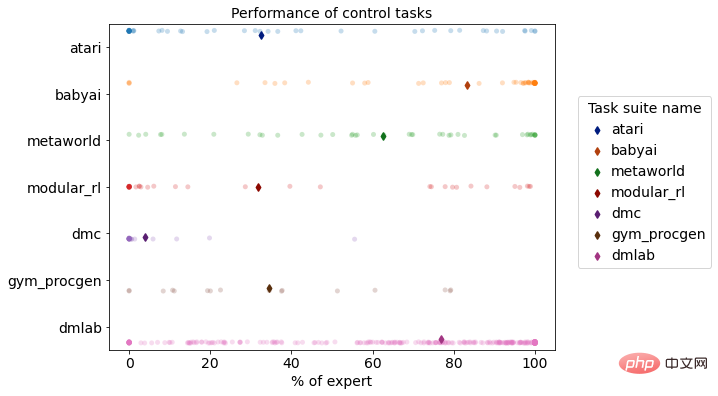
Distribution des performances multi-tâches de DB1 sur environnement de simulation d'apprentissage par renforcement
Par rapport aux algorithmes de prise de décision traditionnels, DB1 présente de bonnes performances en termes de capacités de prise de décision multitâches et de capacités de migration rapide. En termes de capacités de prise de décision inter-tâches et de quantités de paramètres, il est passé de dizaines de millions de paramètres pour une seule tâche complexe à des milliards de paramètres pour plusieurs tâches complexes, et continue de croître et a la capacité de résoudre problèmes dans des environnements commerciaux complexes. Capacité adéquate à résoudre des problèmes pratiques. En termes de capacités de migration, DB1 a franchi le pas de la prédiction intelligente à la prise de décision intelligente, et du mono-agent au multi-agent, compensant les lacunes des méthodes traditionnelles de migration multi-tâches, permettant de construire de grands modèles. au sein de l'entreprise.
Il est indéniable que DB1 a également rencontré de nombreuses difficultés dans le processus de développement. L'Institut de recherche numérique a fait de nombreuses tentatives pour fournir des solutions standard à l'industrie en matière de formation de modèles à grande échelle et de stockage de données de formation multitâches. . Étant donné que les paramètres du modèle ont atteint 1 milliard de paramètres et que l'échelle des tâches est énorme, et qu'il doit être formé sur plus de 100 T (300 B+ de jetons) de données expertes, le cadre de formation ordinaire d'apprentissage par renforcement profond ne peut plus répondre aux besoins de formation rapide en cette situation. À cette fin, d'une part, pour la formation distribuée, l'Institut de recherche en mathématiques considère pleinement la structure informatique de l'apprentissage par renforcement, de l'optimisation opérationnelle et de la formation de grands modèles dans un environnement multi-cartes mono-machine ou multi-machines. , il utilise pleinement les ressources matérielles et conçoit intelligemment les modules. Le mécanisme de communication entre les deux modèles maximise l'efficacité de la formation du modèle et réduit le temps de formation de 870 tâches à une semaine. D'un autre côté, pour l'échantillonnage aléatoire distribué, l'indexation, le stockage, le chargement et le prétraitement des données requis dans le processus de formation sont également devenus des goulots d'étranglement correspondants. L'Institut de recherche en mathématiques a adopté un mode de chargement différé lors du chargement de l'ensemble de données pour résoudre le problème. des limitations de mémoire et maximiser l'utilisation complète de la mémoire disponible. De plus, après le prétraitement des données chargées, les données traitées seront mises en cache sur le disque dur, de sorte que les données prétraitées puissent être directement chargées ultérieurement, réduisant ainsi le temps et les coûts en ressources causés par un prétraitement répété.
Actuellement, de grandes entreprises et instituts de recherche internationaux et nationaux tels que OpenAI, Google, Meta, Huawei, Baidu et DAMO Academy ont mené des recherches sur les grands modèles multimodaux et ont fait certaines tentatives de commercialisation, notamment Appliquer ou fournir un modèle API et solutions industrielles associées dans vos propres produits. En revanche, l'Institut des sciences mathématiques se concentre davantage sur les problèmes de prise de décision et soutient les tentatives d'application dans les tâches de prise de décision de l'IA de jeu, les tâches de résolution de TSP d'optimisation de recherche opérationnelle, les tâches de contrôle de prise de décision de robot, les tâches de résolution d'optimisation de boîte noire et les tâches multi- tâches de dialogue rondes. "Performance des tâches"
Le modèle DB1 est en cours terminé Après l'apprentissage hors ligne de 870 tâches de prise de décision différentes, les résultats de l'évaluation ont montré que 76,67 % des tâches atteignaient ou dépassaient le niveau d'expert de 50 %. Ce qui suit est une démonstration des effets de certaines tâches.Scène de jeu vidéo : DB1 peut recevoir une entrée d'image 2D/3D et peut bien compléter des jeux de pixels 2D tels que Atari et Procgen. En même temps, il convient également à DMLab, une tâche de saisie d'image 3D similaire. dans le monde réel, DB1 a également montré de bonnes performances.
Atari Breakout
- DMLab Explorer les emplacements des objets

Procgen DogBall

Scènes de contrôle continu : Pour les tâches de contrôle continu dans le domaine de la robotique, DB1 peut également modéliser le résultat politique des actions continues et bien accomplir les tâches de simulation.
Metaworld PlateSlide

ModularRL Cheetah
文本 - 图像任务
- 文本生成:给出一段文字提示,生成长文本描述
- 输入提示:Digital Brain Laboratory est basé à Shanghai
-
生成结果:Digital Brain Laboratory est une entreprise basée à Shanghai et nous recherchons une personne hautement qualifiée et expérimentée pour rejoindre notre équipe à Shanghai, en Chine.
nous sommes un laboratoire de cerveau numérique et nous recherchons une personne hautement qualifiée et expérimentée pour rejoindre notre équipe à Shanghai, en Chine.
c'est une opportunité de travailler pour une entreprise bien connue et en croissance qui traverse une phase de croissance rapide et avoir un impact sur le marché.
Il s'agit d'un poste permanent à temps plein.
Nous recherchons un ingénieur logiciel hautement qualifié, motivé et expérimenté, capable de diriger une équipe de 5 à 10 personnes dans un environnement hautement compétitif. environnement前决策大模型的局限性与未来方向 - 虽然当前多模态决策预训练模型DB1 produit专家数据强依赖等。虽然存在众多挑战,但现阶段看来,态环境中进行自主感觉与决策,最终实现更加通用人工智能的关键探索方向之一。未来"任务,结合离线 / 线训练与微调,实现跨域、跨模态、跨任务的知识泛化与迁移,最终在现实应用场景下提供更通用、更高效、更低成本的决策智能决策解决方案。
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

Video Face Swap
Échangez les visages dans n'importe quelle vidéo sans effort grâce à notre outil d'échange de visage AI entièrement gratuit !
Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)
Sujets chauds



 Bytedance Cutting lance le super abonnement SVIP : 499 yuans pour un abonnement annuel continu, offrant une variété de fonctions d'IA
Jun 28, 2024 am 03:51 AM
Bytedance Cutting lance le super abonnement SVIP : 499 yuans pour un abonnement annuel continu, offrant une variété de fonctions d'IA
Jun 28, 2024 am 03:51 AM
Ce site a rapporté le 27 juin que Jianying est un logiciel de montage vidéo développé par FaceMeng Technology, une filiale de ByteDance. Il s'appuie sur la plateforme Douyin et produit essentiellement du contenu vidéo court pour les utilisateurs de la plateforme. Il est compatible avec iOS, Android et. Windows, MacOS et autres systèmes d'exploitation. Jianying a officiellement annoncé la mise à niveau de son système d'adhésion et a lancé un nouveau SVIP, qui comprend une variété de technologies noires d'IA, telles que la traduction intelligente, la mise en évidence intelligente, l'emballage intelligent, la synthèse humaine numérique, etc. En termes de prix, les frais mensuels pour le clipping SVIP sont de 79 yuans, les frais annuels sont de 599 yuans (attention sur ce site : équivalent à 49,9 yuans par mois), l'abonnement mensuel continu est de 59 yuans par mois et l'abonnement annuel continu est de 59 yuans par mois. est de 499 yuans par an (équivalent à 41,6 yuans par mois) . En outre, le responsable de Cut a également déclaré que afin d'améliorer l'expérience utilisateur, ceux qui se sont abonnés au VIP d'origine
 Assistant de codage d'IA augmenté par le contexte utilisant Rag et Sem-Rag
Jun 10, 2024 am 11:08 AM
Assistant de codage d'IA augmenté par le contexte utilisant Rag et Sem-Rag
Jun 10, 2024 am 11:08 AM
Améliorez la productivité, l’efficacité et la précision des développeurs en intégrant une génération et une mémoire sémantique améliorées par la récupération dans les assistants de codage IA. Traduit de EnhancingAICodingAssistantswithContextUsingRAGandSEM-RAG, auteur JanakiramMSV. Bien que les assistants de programmation d'IA de base soient naturellement utiles, ils ne parviennent souvent pas à fournir les suggestions de code les plus pertinentes et les plus correctes, car ils s'appuient sur une compréhension générale du langage logiciel et des modèles d'écriture de logiciels les plus courants. Le code généré par ces assistants de codage est adapté à la résolution des problèmes qu’ils sont chargés de résoudre, mais n’est souvent pas conforme aux normes, conventions et styles de codage des équipes individuelles. Cela aboutit souvent à des suggestions qui doivent être modifiées ou affinées pour que le code soit accepté dans l'application.
 Le réglage fin peut-il vraiment permettre au LLM d'apprendre de nouvelles choses : l'introduction de nouvelles connaissances peut amener le modèle à produire davantage d'hallucinations
Jun 11, 2024 pm 03:57 PM
Le réglage fin peut-il vraiment permettre au LLM d'apprendre de nouvelles choses : l'introduction de nouvelles connaissances peut amener le modèle à produire davantage d'hallucinations
Jun 11, 2024 pm 03:57 PM
Les grands modèles linguistiques (LLM) sont formés sur d'énormes bases de données textuelles, où ils acquièrent de grandes quantités de connaissances du monde réel. Ces connaissances sont intégrées à leurs paramètres et peuvent ensuite être utilisées en cas de besoin. La connaissance de ces modèles est « réifiée » en fin de formation. À la fin de la pré-formation, le modèle arrête effectivement d’apprendre. Alignez ou affinez le modèle pour apprendre à exploiter ces connaissances et répondre plus naturellement aux questions des utilisateurs. Mais parfois, la connaissance du modèle ne suffit pas, et bien que le modèle puisse accéder à du contenu externe via RAG, il est considéré comme bénéfique de l'adapter à de nouveaux domaines grâce à un réglage fin. Ce réglage fin est effectué à l'aide de la contribution d'annotateurs humains ou d'autres créations LLM, où le modèle rencontre des connaissances supplémentaires du monde réel et les intègre.
 Aucune donnée OpenAI requise, rejoignez la liste des grands modèles de code ! UIUC publie StarCoder-15B-Instruct
Jun 13, 2024 pm 01:59 PM
Aucune donnée OpenAI requise, rejoignez la liste des grands modèles de code ! UIUC publie StarCoder-15B-Instruct
Jun 13, 2024 pm 01:59 PM
À la pointe de la technologie logicielle, le groupe de l'UIUC Zhang Lingming, en collaboration avec des chercheurs de l'organisation BigCode, a récemment annoncé le modèle de grand code StarCoder2-15B-Instruct. Cette réalisation innovante a permis une percée significative dans les tâches de génération de code, dépassant avec succès CodeLlama-70B-Instruct et atteignant le sommet de la liste des performances de génération de code. Le caractère unique de StarCoder2-15B-Instruct réside dans sa stratégie d'auto-alignement pur. L'ensemble du processus de formation est ouvert, transparent et complètement autonome et contrôlable. Le modèle génère des milliers d'instructions via StarCoder2-15B en réponse au réglage fin du modèle de base StarCoder-15B sans recourir à des annotations manuelles coûteuses.
 Afin de fournir un nouveau système de référence et d'évaluation de questions-réponses scientifiques et complexes pour les grands modèles, l'UNSW, Argonne, l'Université de Chicago et d'autres institutions ont lancé conjointement le cadre SciQAG.
Jul 25, 2024 am 06:42 AM
Afin de fournir un nouveau système de référence et d'évaluation de questions-réponses scientifiques et complexes pour les grands modèles, l'UNSW, Argonne, l'Université de Chicago et d'autres institutions ont lancé conjointement le cadre SciQAG.
Jul 25, 2024 am 06:42 AM
L'ensemble de données ScienceAI Question Answering (QA) joue un rôle essentiel dans la promotion de la recherche sur le traitement du langage naturel (NLP). Des ensembles de données d'assurance qualité de haute qualité peuvent non seulement être utilisés pour affiner les modèles, mais également évaluer efficacement les capacités des grands modèles linguistiques (LLM), en particulier la capacité à comprendre et à raisonner sur les connaissances scientifiques. Bien qu’il existe actuellement de nombreux ensembles de données scientifiques d’assurance qualité couvrant la médecine, la chimie, la biologie et d’autres domaines, ces ensembles de données présentent encore certaines lacunes. Premièrement, le formulaire de données est relativement simple, et la plupart sont des questions à choix multiples. Elles sont faciles à évaluer, mais limitent la plage de sélection des réponses du modèle et ne peuvent pas tester pleinement la capacité du modèle à répondre aux questions scientifiques. En revanche, les questions et réponses ouvertes
 Yolov10 : explication détaillée, déploiement et application en un seul endroit !
Jun 07, 2024 pm 12:05 PM
Yolov10 : explication détaillée, déploiement et application en un seul endroit !
Jun 07, 2024 pm 12:05 PM
1. Introduction Au cours des dernières années, les YOLO sont devenus le paradigme dominant dans le domaine de la détection d'objets en temps réel en raison de leur équilibre efficace entre le coût de calcul et les performances de détection. Les chercheurs ont exploré la conception architecturale de YOLO, les objectifs d'optimisation, les stratégies d'expansion des données, etc., et ont réalisé des progrès significatifs. Dans le même temps, le recours à la suppression non maximale (NMS) pour le post-traitement entrave le déploiement de bout en bout de YOLO et affecte négativement la latence d'inférence. Dans les YOLO, la conception de divers composants manque d’une inspection complète et approfondie, ce qui entraîne une redondance informatique importante et limite les capacités du modèle. Il offre une efficacité sous-optimale et un potentiel d’amélioration des performances relativement important. Dans ce travail, l'objectif est d'améliorer encore les limites d'efficacité des performances de YOLO à la fois en post-traitement et en architecture de modèle. à cette fin
 Les performances de SOTA, la méthode d'IA de prédiction d'affinité protéine-ligand multimodale de Xiamen, combinent pour la première fois des informations sur la surface moléculaire
Jul 17, 2024 pm 06:37 PM
Les performances de SOTA, la méthode d'IA de prédiction d'affinité protéine-ligand multimodale de Xiamen, combinent pour la première fois des informations sur la surface moléculaire
Jul 17, 2024 pm 06:37 PM
Editeur | KX Dans le domaine de la recherche et du développement de médicaments, il est crucial de prédire avec précision et efficacité l'affinité de liaison des protéines et des ligands pour le criblage et l'optimisation des médicaments. Cependant, les études actuelles ne prennent pas en compte le rôle important des informations sur la surface moléculaire dans les interactions protéine-ligand. Sur cette base, des chercheurs de l'Université de Xiamen ont proposé un nouveau cadre d'extraction de caractéristiques multimodales (MFE), qui combine pour la première fois des informations sur la surface des protéines, la structure et la séquence 3D, et utilise un mécanisme d'attention croisée pour comparer différentes modalités. alignement. Les résultats expérimentaux démontrent que cette méthode atteint des performances de pointe dans la prédiction des affinités de liaison protéine-ligand. De plus, les études d’ablation démontrent l’efficacité et la nécessité des informations sur la surface des protéines et de l’alignement des caractéristiques multimodales dans ce cadre. Les recherches connexes commencent par "S
 SK Hynix présentera de nouveaux produits liés à l'IA le 6 août : HBM3E à 12 couches, NAND à 321 hauteurs, etc.
Aug 01, 2024 pm 09:40 PM
SK Hynix présentera de nouveaux produits liés à l'IA le 6 août : HBM3E à 12 couches, NAND à 321 hauteurs, etc.
Aug 01, 2024 pm 09:40 PM
Selon les informations de ce site le 1er août, SK Hynix a publié un article de blog aujourd'hui (1er août), annonçant sa participation au Global Semiconductor Memory Summit FMS2024 qui se tiendra à Santa Clara, Californie, États-Unis, du 6 au 8 août, présentant de nombreuses nouvelles technologies de produit. Introduction au Future Memory and Storage Summit (FutureMemoryandStorage), anciennement Flash Memory Summit (FlashMemorySummit) principalement destiné aux fournisseurs de NAND, dans le contexte de l'attention croissante portée à la technologie de l'intelligence artificielle, cette année a été rebaptisée Future Memory and Storage Summit (FutureMemoryandStorage) pour invitez les fournisseurs de DRAM et de stockage et bien d’autres joueurs. Nouveau produit SK hynix lancé l'année dernière
