
 Périphériques technologiques
IA
L'arbre évolutif des grands modèles de langage, il s'agit d'un guide 'd'alimentation' super détaillé de ChatGPT
Périphériques technologiques
IA
L'arbre évolutif des grands modèles de langage, il s'agit d'un guide 'd'alimentation' super détaillé de ChatGPT
L'arbre évolutif des grands modèles de langage, il s'agit d'un guide 'd'alimentation' super détaillé de ChatGPT

Dans le processus d'exploration proprement dit, les praticiens peuvent avoir du mal à trouver un modèle d'IA adapté à leur application : doivent-ils choisir un LLM ou affiner un modèle ? Si j’utilise LLM, lequel dois-je choisir ?
Récemment, des chercheurs d'Amazon, de la Texas A&M University, de la Rice University et d'autres institutions ont discuté du processus de développement de modèles de langage tels que ChatGPT, et leur article a également été retweeté par Yann LeCun.
Article : https://arxiv.org/abs/2304.13712
Ressources associées : https://github.com/Mooler0410/LLMsPracticalGuide

Cet article partira du point de vue de l'application pratique et discutera des tâches adaptées au LLM et des problèmes pratiques tels que les modèles, les données et les tâches qui doivent être pris en compte lors de la sélection d'un modèle.
1 Introduction
Ces dernières années, le développement rapide des grands modèles de langage (LLM) a déclenché une révolution dans le domaine du traitement du langage naturel (NLP). Ces modèles sont extrêmement puissants et promettent de résoudre de nombreux types de tâches de PNL – de la compréhension du langage naturel (NLU) aux tâches de génération, et même d'ouvrir la voie à l'intelligence artificielle générale (AGI). Cependant, afin d’utiliser ces modèles de manière efficace et efficiente, nous devons avoir une compréhension pratique de leurs capacités et de leurs limites, ainsi qu’une compréhension des données et des tâches impliquées dans la PNL.
Cet article se concentre sur divers aspects de l'application pratique du LLM dans les tâches de PNL en aval afin de fournir des conseils aux praticiens et aux utilisateurs finaux. L'objectif de ce guide est de fournir aux lecteurs des conseils pratiques et utiles sur l'opportunité d'utiliser un LLM pour une tâche donnée et sur la façon de choisir le LLM le plus approprié - cela prendra en compte de nombreux facteurs, tels que la taille du modèle, les exigences de calcul et domaine spécifique. S'il existe un modèle pré-entraîné, etc. Cet article présente et explique également le LLM d'un point de vue d'application pratique, ce qui peut aider les praticiens et les utilisateurs finaux à exploiter avec succès la puissance du LLM pour résoudre leurs propres tâches de PNL.
La structure de cet article est la suivante : Cet article présentera d'abord brièvement le LLM, dans lequel les architectures les plus importantes de style GPT et de style BERT seront discutées. Nous fournirons ensuite une introduction approfondie aux facteurs clés affectant les performances du modèle en termes de données, y compris les données de pré-entraînement, les données d'entraînement/données de réglage et les données de test. Dans la dernière et la plus importante partie, cet article examinera diverses tâches spécifiques du NLP, indiquera si le LLM est adapté aux tâches à forte intensité de connaissances, aux tâches NLU traditionnelles et aux tâches de génération. En outre, il décrira également les nouvelles capacités et défis qui en découlent. ces modèles continuent d’acquérir des scénarios d’application réels. Nous fournissons des exemples détaillés pour souligner l’utilité et les limites du LLM dans la pratique.
Afin d'analyser les capacités des grands modèles de langage, cet article les comparera avec des modèles affinés. Nous n'avons pas encore de norme largement acceptée pour la définition du LLM et des modèles affinés. Afin de faire une distinction pratique et efficace, la définition donnée dans cet article est la suivante : LLM fait référence à un grand modèle de langage pré-entraîné sur un ensemble de données à grande échelle et n'ajuste pas les données pour des tâches spécifiques ; les modèles sont généralement plus petits et sont pré-entraînés. Plus tard, des ajustements plus précis seront effectués sur des ensembles de données spécifiques à une tâche plus petits afin d'optimiser leurs performances sur cette tâche.
Cet article résume les conseils pratiques sur l'utilisation du LLM dans :
- Compréhension du langage naturel. Lorsque les données réelles ne se trouvent pas dans la plage de distribution des données de formation ou qu'il y a très peu de données de formation, l'excellente capacité de généralisation de LLM peut être utilisée.
- Génération de langage naturel. Utilisez la puissance du LLM pour créer un texte cohérent, contextuel et de haute qualité pour une variété d'applications.
- Tâches à forte intensité de connaissances. Tirez parti des vastes connaissances stockées dans LLM pour gérer des tâches qui nécessitent une expertise spécifique ou une connaissance générale du monde.
- Capacité de raisonnement. Comprendre et utiliser les capacités de raisonnement du LLM pour améliorer la prise de décision et la résolution de problèmes dans diverses situations.
2 Guide pratique du modélisme
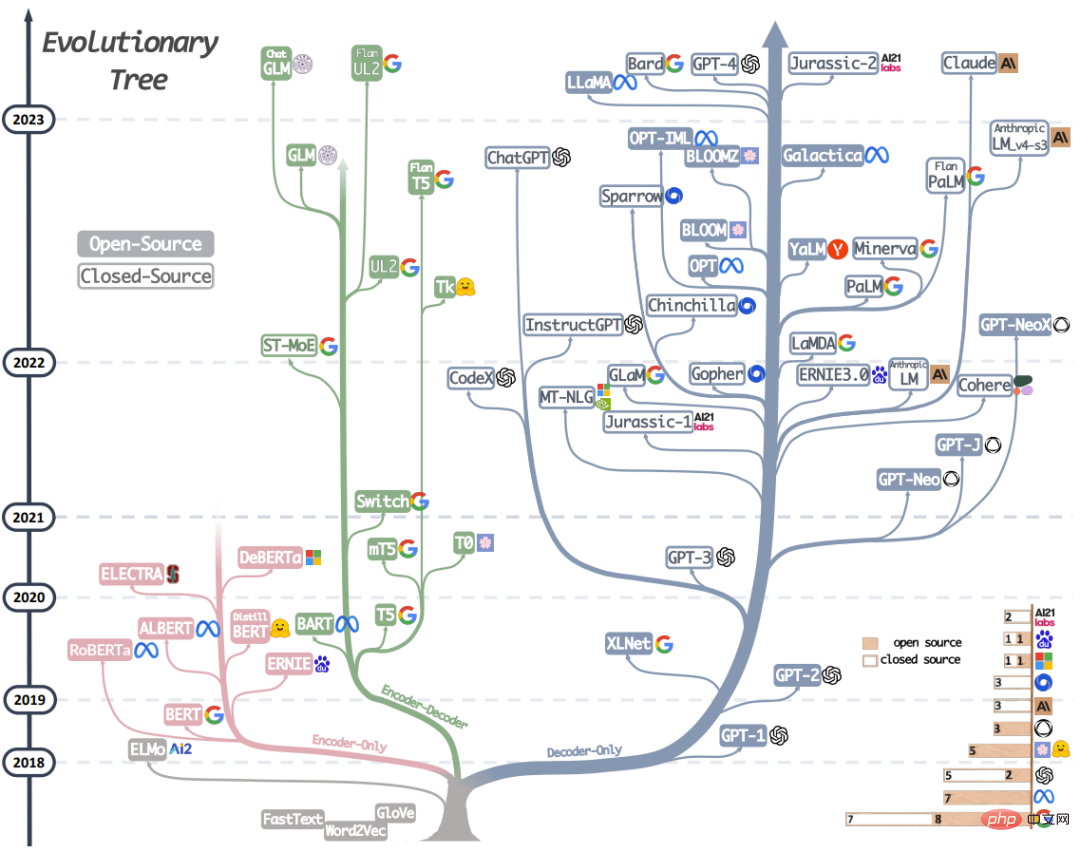
# 🎜🎜# Figure 1 : Cet arbre évolutif du LLM moderne retrace le développement des modèles de langage au cours des dernières années, mettant en évidence certains des modèles les plus connus. Les modèles sur la même branche sont plus étroitement liés. Les modèles basés sur transformateur ne sont pas représentés en gris : les modèles à décodeur uniquement sont la branche bleue, les modèles à encodeur uniquement sont la branche rose et les modèles à codeur-décodeur sont la branche verte. La position verticale d'un modèle sur la timeline indique la date de sa sortie. Les carrés pleins représentent les modèles open source et les carrés vides représentent les modèles fermés. Le graphique à barres empilées dans le coin inférieur droit fait référence au nombre de modèles pour chaque entreprise et institution.
Cette section présentera brièvement le LLM le plus performant actuel. Ces modèles ont des stratégies de formation, des architectures de modèles et des cas d'utilisation différents. Pour comprendre plus clairement l’image globale des LLM, nous pouvons les diviser en deux grandes catégories : les modèles de langage encodeur-décodeur ou encodeur uniquement et les modèles de langage encodeur uniquement. La figure 1 montre en détail l’évolution du modèle de langage. Sur la base de cet arbre évolutif, nous pouvons observer quelques conclusions intéressantes :
a) Le modèle uniquement décodeur devient progressivement le modèle dominant dans le développement du LLM. Dans les premiers stades du développement de LLM, les modèles à décodeur uniquement n'étaient pas aussi populaires que les modèles à encodeur uniquement et encodeur-décodeur. Mais après 2021, l’émergence de GPT-3 a changé la donne du secteur, et seul le modèle de décodeur a connu un développement explosif. Dans le même temps, BERT a également apporté une croissance explosive initiale au modèle à encodeur uniquement, mais après cela, le modèle à encodeur uniquement a progressivement disparu.
b) OpenAI continue de maintenir sa position de leader en direction du LLM, maintenant et probablement dans le futur. D'autres entreprises et institutions rattrapent leur retard pour développer des modèles comparables au GPT-3 et au GPT-4. La position de leader d'OpenAI peut être attribuée à son investissement continu dans la technologie, même si la technologie n'était pas largement reconnue à ses débuts.
c) Meta a apporté des contributions exceptionnelles au LLM open source et à la promotion de la recherche LLM. Meta se distingue comme l'une des sociétés commerciales les plus généreuses en ce qui concerne ses contributions à la communauté open source, en particulier en ce qui concerne les LLM, car elle a rendu open source tous les LLM qu'elle a développés.
d) Le développement LLM a une tendance au source fermé. Aux premiers stades du développement du LLM (avant 2020), la grande majorité des modèles étaient open source. Cependant, avec le lancement de GPT-3, les entreprises choisissent de plus en plus de fermer leurs modèles, tels que PaLM, LaMDA et GPT-4. Il est donc de plus en plus difficile pour les chercheurs universitaires de mener des expériences de formation LLM. Cela a pour conséquence que la recherche basée sur les API pourrait devenir l’approche dominante dans le monde universitaire.
e) Le modèle encodeur-décodeur a encore des perspectives de développement, car les entreprises et les institutions explorent encore activement ce type d'architecture, et la plupart des modèles sont open source. Google a apporté des contributions significatives aux encodeurs-décodeurs open source. Cependant, en raison de la flexibilité et de la polyvalence du modèle avec décodeur seul, les chances de succès de Google semblent plus minces en persistant dans cette direction.
Le tableau 1 résume brièvement les caractéristiques des différents LLM représentatifs. Tableau 1 : Modèle de langage étendu encodeur-décodeur ou Encodeur uniquement
Le développement de l'apprentissage non supervisé du langage naturel a fait de grands progrès ces derniers temps car les données en langage naturel sont facilement disponibles et les paradigmes de formation non supervisés peuvent être utilisés pour mieux utiliser des ensembles de données à très grande échelle. Une approche courante consiste à prédire les mots masqués dans une phrase en fonction du contexte. Ce paradigme de formation est appelé modèle de langage masqué. Cette méthode de formation permet au modèle d'acquérir une compréhension plus approfondie de la relation entre les mots et leur contexte. Ces modèles sont formés sur de grands corpus de textes, à l'aide de techniques telles que l'architecture Transformer, et ont atteint des performances de pointe sur de nombreuses tâches NLP, telles que l'analyse des sentiments et la reconnaissance d'entités nommées. Les modèles de langage masqué célèbres incluent BERT, RoBERTa et T5. En raison de leur exécution réussie dans une variété de tâches, les modèles de langage masqué sont devenus un outil important dans le domaine du traitement du langage naturel.
2.2 Modèle de langage de style GPT : décodeur uniquement
Bien que les architectures de modèles de langage soient souvent indépendantes des tâches, ces méthodes nécessitent un réglage fin basé sur des ensembles de données pour des tâches spécifiques en aval. Les chercheurs ont découvert qu’augmenter la taille d’un modèle de langage peut améliorer considérablement ses performances avec peu ou pas d’échantillons. Le modèle le plus efficace pour améliorer les performances avec peu ou aucun échantillon est le modèle de langage autorégressif, qui est entraîné pour générer le mot suivant en fonction des mots précédents dans une séquence donnée. Ces modèles ont été largement utilisés dans des tâches en aval telles que la génération de texte et la réponse à des questions. Les modèles de langage autorégressifs incluent GPT-3, OPT, PaLM et BLOOM. Le révolutionnaire GPT-3 a montré pour la première fois que l'apprentissage à l'aide d'indices et du contexte peut donner des résultats raisonnables avec peu ou pas d'échantillons, et a ainsi démontré la supériorité des modèles de langage autorégressifs.
Il existe également des modèles optimisés pour des tâches spécifiques, comme CodeX pour la génération de code et BloombergGPT pour le domaine financier. Une avancée majeure récente est ChatGPT, un modèle de GPT-3 optimisé pour les tâches conversationnelles qui génère des conversations plus interactives, cohérentes et contextuelles pour une variété d'applications du monde réel.
3 Guide pratique des données
Cette section présentera le rôle critique des données dans le choix du bon modèle pour les tâches en aval. L'impact des données sur l'efficacité du modèle commence dès la phase de pré-formation et se poursuit tout au long des phases de formation et d'inférence.
Points clés 1
(1) Lorsque les tâches en aval utilisent des données en dehors de la distribution, comme lors de l'utilisation d'échantillons contradictoires ou de changements de domaine de données, la capacité de généralisation du LLM est meilleure que le modèle de réglage fin.
(2) Lorsque les données étiquetées sont limitées, le LLM est meilleur que le modèle affiné ; lorsque les données étiquetées sont abondantes, les deux sont des choix raisonnables, en fonction des exigences spécifiques de la tâche.
(3) Il est recommandé de choisir un modèle dont le domaine de données utilisé pour la pré-formation est similaire au domaine de données de la tâche en aval.
4 Guide pratique des tâches PNL
Cette section expliquera en détail si le LLM est utile sur diverses tâches PNL en aval et les capacités du modèle correspondantes. La figure 2 est un diagramme de flux de décision résumant toutes les discussions. Face à une certaine tâche, des décisions rapides peuvent être prises sur la base de ce processus.
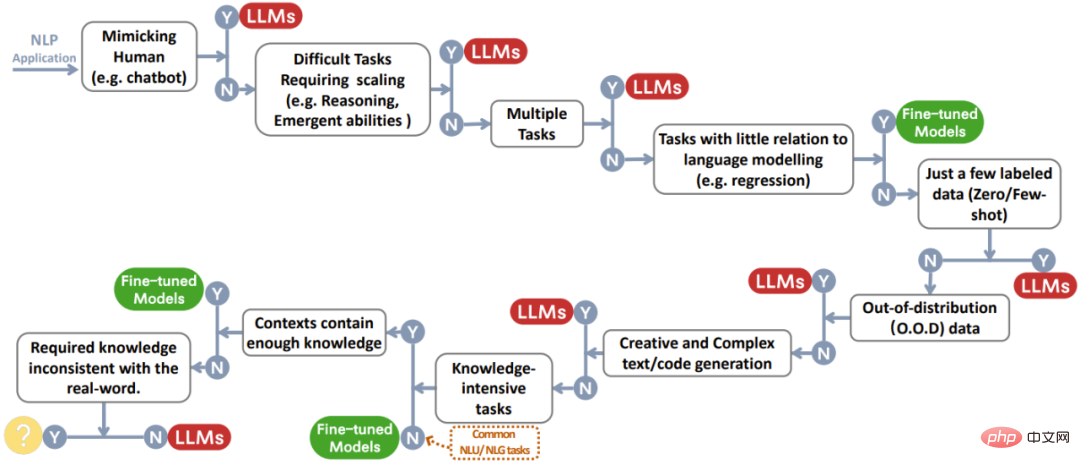
Figure 2 : Processus de prise de décision de l'utilisateur lors du choix d'un LLM ou d'un modèle affiné pour l'application de la PNL. Cet organigramme décisionnel aide les utilisateurs à évaluer si la tâche NLP en aval répond à des critères spécifiques et à déterminer si un LLM ou un modèle affiné est le mieux adapté à leur application en fonction des résultats de l'évaluation. Dans le processus de prise de décision illustré dans la figure, Y indique que les conditions sont remplies et N indique que les conditions ne sont pas remplies. Le cercle jaune à côté de Y pour la dernière condition indique qu’il n’existe actuellement aucun modèle bien adapté à ce type d’application.
4.1 Tâches NLU traditionnelles
Les tâches NLU traditionnelles sont des tâches de base dans le domaine de la PNL, notamment la classification de texte, la reconnaissance d'entités nommées (NER), la prédiction d'implication, etc. Beaucoup de ces tâches peuvent être utilisées comme étapes intermédiaires dans des systèmes d’IA plus vastes, comme l’utilisation du NER pour la construction de graphes de connaissances.
Non applicable au LLM : pour la plupart des tâches de compréhension du langage naturel, telles que celles de GLUE et SuperGLUE, si la tâche contient déjà de nombreuses données bien annotées et que très peu de données dans l'ensemble de test sont en dehors de la distribution, alors affinez le modèle Les performances sont encore meilleures. L'écart entre les petits modèles affinés et les LLM diffère également lorsque les tâches et les ensembles de données varient.
Convient pour LLM : Cependant, il existe également certaines tâches NLU qui sont mieux adaptées pour être traitées par LLM. Deux tâches représentatives sont les problèmes complexes de classification de texte et le raisonnement contradictoire en langage naturel.
Point 2
Pour les tâches traditionnelles de compréhension du langage naturel, les modèles affinés sont généralement un meilleur choix que le LLM, mais si la tâche nécessite de fortes capacités de généralisation, alors le LLM peut vous aider.
4.2 Tâches de génération
Le but de la génération de langage naturel est de créer des séquences de symboles cohérentes, significatives et contextuelles, qui comprennent grosso modo deux grandes catégories de tâches. La première catégorie de tâches se concentre sur la conversion du texte saisi en de nouvelles séquences de symboles. Les exemples incluent le résumé de paragraphes et la traduction automatique. La deuxième catégorie de tâches est la « génération ouverte », où l'objectif est de générer du texte ou des symboles à partir de zéro afin qu'ils correspondent précisément à la description saisie, comme la rédaction d'e-mails, la rédaction de nouveaux articles, la création d'histoires fictives et l'écriture de code.
Applicable au LLM : La tâche de génération nécessite que le modèle comprenne pleinement le contenu ou les exigences d'entrée et nécessite également un certain degré de créativité. C’est dans cela que LLM excelle.
Non applicable LLM : sur la plupart des tâches de traduction avec des ressources riches et des tâches de traduction avec peu de ressources, les modèles affinés fonctionnent mieux, comme DeltaLM+Zcode. Pour la traduction automatique dotée de ressources riches, les modèles affinés surpassent légèrement les LLM. Pour la traduction automatique avec très peu de ressources, comme la traduction anglais-kazakh, les modèles affinés ont largement surpassé le LLM.
Point 3
Grâce à ses fortes capacités de génération et sa créativité, LLM présente des avantages dans la plupart des tâches de génération.
4.3 Tâches à forte intensité de connaissances
Les tâches de PNL à forte intensité de connaissances font référence à la catégorie de tâches qui reposent fortement sur des connaissances de base, une expertise spécifique à un domaine ou des connaissances générales du monde réel. Ces tâches nécessitent plus que la reconnaissance de formes ou l’analyse syntaxique. Ils s'appuient fortement sur la mémoire et sur l'utilisation appropriée des connaissances liées à des entités, des événements et du bon sens spécifiques dans notre monde réel.
Applicable au LLM : d'une manière générale, s'il existe des milliards de jetons et de paramètres de formation, la quantité de connaissances du monde réel contenues dans le LLM peut dépasser de loin celle d'un modèle affiné.
Non applicable au LLM : Certaines autres tâches nécessitent des connaissances différentes de celles apprises en LLM. Les connaissances requises ne sont pas celles que le LLM apprend sur le monde réel. Dans une telle tâche, LLM n’a aucun avantage évident.
Point 4
(1) Grâce à l'énorme connaissance du monde réel, LLM est doué pour gérer des tâches à forte intensité de connaissances. (2) LLM rencontrera des difficultés lorsque les exigences de connaissances ne correspondent pas aux connaissances acquises ou lorsque la tâche ne nécessite que des connaissances contextuelles, le modèle de réglage fin peut atteindre les mêmes performances que LLM.
4.4 Capacité à évoluer
Élargir l'échelle du LLM (comme les paramètres, les calculs d'entraînement, etc.) peut grandement aider à pré-entraîner les modèles linguistiques. En augmentant la taille du modèle, la capacité du modèle à gérer plusieurs tâches est souvent améliorée. Reflétée sur certains indicateurs, la performance du modèle montre une relation de loi de puissance avec la taille du modèle. Par exemple, la perte d'entropie croisée utilisée pour mesurer les performances de modélisation du langage diminue linéairement avec la croissance exponentielle de la taille du modèle, également connue sous le nom de « loi d'échelle ». Pour certaines capacités clés, comme le raisonnement, la mise à l’échelle du modèle peut progressivement améliorer ces capacités d’un niveau très bas à un niveau utilisable, voire proche des niveaux humains. Cette sous-section présentera l'utilisation de LLM en termes d'impact de l'échelle sur les capacités et le comportement de LLM.
Cas d'utilisation du LLM dans le raisonnement : le raisonnement implique de comprendre des informations, de faire des déductions et de prendre des décisions, et constitue une capacité essentielle de l'intelligence humaine. Pour la PNL, le raisonnement est extrêmement difficile. De nombreuses tâches de raisonnement existantes peuvent être divisées en deux catégories : le raisonnement de bon sens et le raisonnement arithmétique. L'élargissement du modèle peut grandement améliorer la capacité de raisonnement arithmétique du LLM. Le raisonnement de bon sens exige que le LLM non seulement se souvienne des connaissances factuelles, mais également qu'il effectue certaines étapes de raisonnement sur les faits. Les capacités de raisonnement de bon sens s’améliorent progressivement à mesure que la taille du modèle augmente. Comparé aux modèles affinés, LLM fonctionne mieux sur la plupart des ensembles de données.
Cas d'utilisation du LLM dans les capacités émergentes : augmenter la taille du modèle peut également donner au modèle des capacités sans précédent et merveilleuses qui vont au-delà des règles de la loi de puissance. Ces capacités sont appelées « capacités émergentes ». Comme défini dans l'article « Capacités émergentes des modèles linguistiques à grande échelle » : la capacité émergente du LLM fait référence à la capacité que les modèles à petite échelle n'ont pas mais apparaissent dans les modèles à grande échelle. (Pour plus d'interprétations de cet article, veuillez vous référer à « Nouveaux travaux de Jeff Dean et autres : examen des modèles de langage sous un angle différent, impossible de découvrir si l'échelle n'est pas suffisante »). Cela signifie que nous ne pouvons pas déduire et prédire cette capacité. basé sur l'amélioration des performances des modèles à petite échelle ; Sur certaines tâches, une fois que la taille du modèle dépasse un certain niveau, il peut soudainement atteindre d'excellentes performances. Les capacités émergentes sont souvent imprévisibles et inattendues, ce qui peut empêcher un modèle de gérer des tâches aléatoires ou inattendues.
Non applicable au LLM et à la compréhension de l'émergence : Bien que dans la plupart des cas, le modèle soit plus grand et plus performant, il existe encore des exceptions.
Sur certaines tâches, à mesure que l'échelle du LLM augmente, les performances du modèle commenceront à décliner. Ceci est également connu sous le nom de phénomène de mise à l’échelle inverse. De plus, les chercheurs ont également observé un autre phénomène intéressant lié à l’échelle, à savoir le phénomène en forme de U. Comme son nom l'indique, ce phénomène signifie qu'à mesure que le modèle LLM grandit, ses performances sur une tâche spécifique s'amélioreront d'abord, puis commenceront à décliner, puis à s'améliorer à nouveau.
Pour faire progresser la recherche dans ce domaine, nous devons avoir une compréhension plus approfondie des capacités émergentes, des phénomènes de contre-échelle et des phénomènes en forme de U.
Points clés 5
(1) À mesure que la taille du modèle augmente de façon exponentielle, les capacités de raisonnement arithmétique et de bon sens du LLM augmenteront également. (2) À mesure que l'échelle du LLM augmente, les capacités émergentes peuvent découvrir de nouvelles utilisations par hasard, telles que les capacités de traitement de texte et les capacités logiques. (3) Les capacités des modèles n'augmentent pas toujours avec l'échelle, et notre compréhension de la relation entre les capacités des grands modèles de langage et l'échelle est encore limitée.
4.5 Tâches diverses
Afin de mieux comprendre les forces et les faiblesses du LLM, parlons d'autres tâches non couvertes ci-dessus.
Non applicable au LLM : Si les objectifs du modèle sont différents des données d'entraînement, alors LLM rencontrera souvent des difficultés sur ces tâches.
Convient au LLM : LLM est particulièrement adapté à certaines tâches spécifiques. Pour donner quelques exemples, LLM est très efficace pour imiter les humains. LLM peut également être utilisé pour évaluer la qualité de certaines tâches NLG telles que le résumé et la traduction. Certaines fonctionnalités de LLM peuvent également apporter des avantages autres que l'amélioration des performances, comme l'interprétabilité.
Point 6
(1) Il y a encore de la place pour des modèles affinés et des modèles spécifiques à un domaine pour des tâches qui sont loin des cibles et des données pré-entraînées du LLM. (2) LLM est doué pour imiter les humains, l'annotation et la génération de données. Ils peuvent également être utilisés pour évaluer la qualité des tâches de PNL et présentent des avantages tels que l’interprétabilité.
4.6 "Tâches" du monde réel
Cette section aborde enfin l'application du LLM et la mise au point des modèles sur des "tâches" du monde réel. Le terme « tâche » est utilisé ici de manière vague car, contrairement aux contextes universitaires, les contextes du monde réel manquent souvent de définitions bien formées. De nombreuses exigences relatives aux modèles ne peuvent même pas être considérées comme des tâches de PNL. Les défis concrets auxquels est confronté le modèle proviennent des trois aspects suivants :
- Entrée bruyante/non structurée. Les contributions du monde réel proviennent de personnes réelles, dont la plupart ne sont pas des experts. Ils ne comprennent pas comment interagir de manière appropriée avec les modèles et peuvent même ne pas être capables d’utiliser le texte couramment. Par conséquent, les données d'entrée du monde réel peuvent être désordonnées, avec des fautes d'orthographe, du texte familier et un fouillis multilingue, contrairement aux données formatées bien définies utilisées pour la pré-formation ou le réglage fin.
- Tâches qui n'ont pas été formalisées par le milieu universitaire. Les tâches dans des scénarios du monde réel ne sont souvent pas bien définies par le monde universitaire, et la diversité s'étend bien au-delà de la définition des scénarios de recherche universitaire. Les utilisateurs effectuent souvent des requêtes ou des requêtes qui ne correspondent pas parfaitement aux catégories prédéfinies, et parfois une seule requête englobe plusieurs tâches.
- Suivez les instructions d'utilisation. La demande de l'utilisateur peut contenir plusieurs intentions implicites (telles que des exigences spécifiques concernant le format de sortie), ou il peut ne pas être clair ce que l'utilisateur s'attend à prédire sans questions de suivi. Le modèle doit comprendre les intentions de l'utilisateur et fournir un résultat cohérent avec ces intentions.
Essentiellement, ces énigmes du monde réel provenant des demandes des utilisateurs sont causées par des écarts par rapport à la distribution de tout ensemble de données PNL conçu pour une tâche spécifique. Les ensembles de données PNL publics ne reflètent pas la manière dont ces modèles sont utilisés.
Point 7
Par rapport aux modèles de réglage fin, LLM est plus adapté au traitement du monde réel scénarios. Cependant, l’évaluation de l’efficacité des modèles dans le monde réel reste une question ouverte.
5 Autres aspects
Bien que le LLM soit adapté à une variété de tâches en aval, il existe également d'autres facteurs à prendre en compte, tels que l'efficacité et fiabilité . Les problèmes impliqués dans l'efficacité incluent le coût de formation du LLM, la latence d'inférence et les stratégies de réglage pour une utilisation efficace des paramètres. En termes de fiabilité, la robustesse du LLM et les capacités d'étalonnage, l'équité et les biais, les corrélations d'erreurs potentielles et les défis de sécurité doivent être pris en compte. Point clé 8(1) Si la tâche est sensible aux coûts ou a des exigences de latence strictes, alors les modèles légers de réglage fin local doivent être prioritaires. Lors du déploiement et de la livraison de votre modèle, envisagez de le régler pour utiliser efficacement les paramètres. (2) L’approche zéro-shot de LLM l’empêche d’apprendre des raccourcis à partir d’ensembles de données spécifiques à des tâches, ce qui est courant pour les modèles affinés. Néanmoins, LLM présente encore certains problèmes d'apprentissage raccourci. (3) Étant donné que les problèmes de sortie et d’hallucinations potentiellement nocifs ou biaisés de LLM peuvent entraîner de graves conséquences, les questions de sécurité liées à LLM devraient recevoir la plus grande attention. Des méthodes telles que la rétroaction humaine promettent d’atténuer ces problèmes.
6 Résumé et défis futurs
Ce guide pratique fournit un aperçu du LLM et des meilleures pratiques d'utilisation du LLM sur diverses tâches de PNL. . Espérons que cela aidera les chercheurs et les praticiens à exploiter le potentiel du LLM et à stimuler l’innovation dans les technologies linguistiques.
Bien sûr, le LLM a aussi quelques défis à résoudre :
- Évaluez le modèle sur des ensembles de données du monde réel. Bien que les modèles d’apprentissage profond existants soient principalement évalués sur des ensembles de données académiques standards tels qu’ImageNet, les ensembles de données académiques standards sont limités et ne reflètent pas avec précision les performances du modèle dans le monde réel. À mesure que les modèles progressent, il sera nécessaire de les évaluer sur la base de données plus diverses, plus complexes et plus réalistes, reflétant les besoins réels. L'évaluation des modèles sur des ensembles de données académiques et réels permet de tester les modèles de manière plus rigoureuse et de mieux comprendre leur efficacité dans les applications du monde réel. Cela garantit que le modèle a la capacité de résoudre des problèmes du monde réel et de fournir des solutions pratiques et utilisables.
- Alignement du modèle. Il est important de veiller à ce que les modèles de plus en plus puissants et automatisés soient alignés sur les valeurs et priorités humaines. Nous devons trouver comment nous assurer que le modèle se comporte comme prévu et ne pas l'optimiser pour obtenir des résultats que nous ne souhaitons pas. Il est important d’intégrer des techniques précises dès le début du processus de développement du modèle. La transparence et l’interprétabilité des modèles sont également importantes pour évaluer et garantir l’exactitude. En outre, en regardant vers l’avenir, un défi encore plus difficile se profile : l’exécution précise de systèmes surhumains. Bien que cette tâche dépasse actuellement nos besoins, il est important d’envisager et de se préparer à des systèmes avancés tels que Hezhun, car ils peuvent poser des complexités et des problèmes éthiques uniques.
- Alignement de sécurité. S’il est important de discuter des risques existentiels posés par l’IA, nous avons besoin de recherches pratiques pour garantir que l’IA avancée puisse être développée en toute sécurité. Cela inclut des techniques d'interprétabilité, de supervision et de gouvernance évolutives, ainsi que de vérification formelle des propriétés du modèle. Dans la construction du modèle, la sécurité ne doit pas être considérée comme un ajout mais comme une partie intégrante d’un tout.
- Prédisez les performances du modèle à mesure que sa taille change. Lorsque la taille et la complexité du modèle augmentent considérablement, il est difficile de prédire ses performances. Des techniques devraient être développées pour mieux prédire les performances des modèles à mesure qu'ils évoluent ou utilisent de nouvelles architectures, ce qui nous permettra d'utiliser les ressources plus efficacement et d'accélérer le développement. Il existe quelques possibilités : former un modèle « graine » plus petit et prédire sa croissance par extrapolation, simuler les effets de la mise à l'échelle ou de l'ajustement du modèle, et itérer sur un banc de test de modèles de différentes tailles pour construire une loi de mise à l'échelle. Cela nous donne une idée des performances du modèle avant de le construire.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 ChatGPT permet désormais aux utilisateurs gratuits de générer des images en utilisant DALL-E 3 avec une limite quotidienne
Aug 09, 2024 pm 09:37 PM
ChatGPT permet désormais aux utilisateurs gratuits de générer des images en utilisant DALL-E 3 avec une limite quotidienne
Aug 09, 2024 pm 09:37 PM
Le DALL-E 3 a été officiellement introduit en septembre 2023 en tant que modèle considérablement amélioré par rapport à son prédécesseur. Il est considéré comme l’un des meilleurs générateurs d’images IA à ce jour, capable de créer des images avec des détails complexes. Cependant, au lancement, c'était exclu
 Le modèle MoE open source le plus puissant au monde est ici, avec des capacités chinoises comparables à celles du GPT-4, et le prix ne représente que près d'un pour cent de celui du GPT-4-Turbo.
May 07, 2024 pm 04:13 PM
Le modèle MoE open source le plus puissant au monde est ici, avec des capacités chinoises comparables à celles du GPT-4, et le prix ne représente que près d'un pour cent de celui du GPT-4-Turbo.
May 07, 2024 pm 04:13 PM
Imaginez un modèle d'intelligence artificielle qui non seulement a la capacité de surpasser l'informatique traditionnelle, mais qui permet également d'obtenir des performances plus efficaces à moindre coût. Ce n'est pas de la science-fiction, DeepSeek-V2[1], le modèle MoE open source le plus puissant au monde est ici. DeepSeek-V2 est un puissant mélange de modèle de langage d'experts (MoE) présentant les caractéristiques d'une formation économique et d'une inférence efficace. Il est constitué de 236B paramètres, dont 21B servent à activer chaque marqueur. Par rapport à DeepSeek67B, DeepSeek-V2 offre des performances plus élevées, tout en économisant 42,5 % des coûts de formation, en réduisant le cache KV de 93,3 % et en augmentant le débit de génération maximal à 5,76 fois. DeepSeek est une entreprise explorant l'intelligence artificielle générale
 KAN, qui remplace MLP, a été étendu à la convolution par des projets open source
Jun 01, 2024 pm 10:03 PM
KAN, qui remplace MLP, a été étendu à la convolution par des projets open source
Jun 01, 2024 pm 10:03 PM
Plus tôt ce mois-ci, des chercheurs du MIT et d'autres institutions ont proposé une alternative très prometteuse au MLP – KAN. KAN surpasse MLP en termes de précision et d’interprétabilité. Et il peut surpasser le MLP fonctionnant avec un plus grand nombre de paramètres avec un très petit nombre de paramètres. Par exemple, les auteurs ont déclaré avoir utilisé KAN pour reproduire les résultats de DeepMind avec un réseau plus petit et un degré d'automatisation plus élevé. Plus précisément, le MLP de DeepMind compte environ 300 000 paramètres, tandis que le KAN n'en compte qu'environ 200. KAN a une base mathématique solide comme MLP est basé sur le théorème d'approximation universelle, tandis que KAN est basé sur le théorème de représentation de Kolmogorov-Arnold. Comme le montre la figure ci-dessous, KAN a
 Bonjour, Atlas électrique ! Le robot Boston Dynamics revient à la vie, des mouvements étranges à 180 degrés effraient Musk
Apr 18, 2024 pm 07:58 PM
Bonjour, Atlas électrique ! Le robot Boston Dynamics revient à la vie, des mouvements étranges à 180 degrés effraient Musk
Apr 18, 2024 pm 07:58 PM
Boston Dynamics Atlas entre officiellement dans l’ère des robots électriques ! Hier, l'Atlas hydraulique s'est retiré "en larmes" de la scène de l'histoire. Aujourd'hui, Boston Dynamics a annoncé que l'Atlas électrique était au travail. Il semble que dans le domaine des robots humanoïdes commerciaux, Boston Dynamics soit déterminé à concurrencer Tesla. Après la sortie de la nouvelle vidéo, elle a déjà été visionnée par plus d’un million de personnes en seulement dix heures. Les personnes âgées partent et de nouveaux rôles apparaissent. C'est une nécessité historique. Il ne fait aucun doute que cette année est l’année explosive des robots humanoïdes. Les internautes ont commenté : Les progrès des robots ont fait ressembler la cérémonie d'ouverture de cette année à des êtres humains, et le degré de liberté est bien plus grand que celui des humains. Mais n'est-ce vraiment pas un film d'horreur ? Au début de la vidéo, Atlas est allongé calmement sur le sol, apparemment sur le dos. Ce qui suit est à couper le souffle
 Les robots Tesla travaillent dans les usines, Musk : Le degré de liberté des mains atteindra 22 cette année !
May 06, 2024 pm 04:13 PM
Les robots Tesla travaillent dans les usines, Musk : Le degré de liberté des mains atteindra 22 cette année !
May 06, 2024 pm 04:13 PM
La dernière vidéo du robot Optimus de Tesla est sortie, et il peut déjà fonctionner en usine. À vitesse normale, il trie les batteries (les batteries 4680 de Tesla) comme ceci : Le responsable a également publié à quoi cela ressemble à une vitesse 20 fois supérieure - sur un petit "poste de travail", en sélectionnant et en sélectionnant et en sélectionnant : Cette fois, il est publié L'un des points forts de la vidéo est qu'Optimus réalise ce travail en usine, de manière totalement autonome, sans intervention humaine tout au long du processus. Et du point de vue d'Optimus, il peut également récupérer et placer la batterie tordue, en se concentrant sur la correction automatique des erreurs : concernant la main d'Optimus, le scientifique de NVIDIA Jim Fan a donné une évaluation élevée : la main d'Optimus est l'un des robots à cinq doigts du monde. le plus adroit. Ses mains ne sont pas seulement tactiles
 FisheyeDetNet : le premier algorithme de détection de cible basé sur une caméra fisheye
Apr 26, 2024 am 11:37 AM
FisheyeDetNet : le premier algorithme de détection de cible basé sur une caméra fisheye
Apr 26, 2024 am 11:37 AM
La détection de cibles est un problème relativement mature dans les systèmes de conduite autonome, parmi lesquels la détection des piétons est l'un des premiers algorithmes à être déployés. Des recherches très complètes ont été menées dans la plupart des articles. Cependant, la perception de la distance à l’aide de caméras fisheye pour une vue panoramique est relativement moins étudiée. En raison de la distorsion radiale importante, la représentation standard du cadre de délimitation est difficile à mettre en œuvre dans les caméras fisheye. Pour alléger la description ci-dessus, nous explorons les conceptions étendues de boîtes englobantes, d'ellipses et de polygones généraux dans des représentations polaires/angulaires et définissons une métrique de segmentation d'instance mIOU pour analyser ces représentations. Le modèle fisheyeDetNet proposé avec une forme polygonale surpasse les autres modèles et atteint simultanément 49,5 % de mAP sur l'ensemble de données de la caméra fisheye Valeo pour la conduite autonome.
 Une seule carte exécute Llama 70B plus rapidement que deux cartes, Microsoft vient de mettre le FP6 dans l'Open source A100 |
Apr 29, 2024 pm 04:55 PM
Une seule carte exécute Llama 70B plus rapidement que deux cartes, Microsoft vient de mettre le FP6 dans l'Open source A100 |
Apr 29, 2024 pm 04:55 PM
Le FP8 et la précision de quantification inférieure en virgule flottante ne sont plus le « brevet » du H100 ! Lao Huang voulait que tout le monde utilise INT8/INT4, et l'équipe Microsoft DeepSpeed a commencé à exécuter FP6 sur A100 sans le soutien officiel de NVIDIA. Les résultats des tests montrent que la quantification FP6 de la nouvelle méthode TC-FPx sur A100 est proche ou parfois plus rapide que celle de INT4, et a une précision supérieure à celle de cette dernière. En plus de cela, il existe également une prise en charge de bout en bout des grands modèles, qui ont été open source et intégrés dans des cadres d'inférence d'apprentissage profond tels que DeepSpeed. Ce résultat a également un effet immédiat sur l'accélération des grands modèles : dans ce cadre, en utilisant une seule carte pour exécuter Llama, le débit est 2,65 fois supérieur à celui des cartes doubles. un
 Les dernières nouvelles de l'Université d'Oxford ! Mickey : correspondance d'images 2D en 3D SOTA ! (CVPR\'24)
Apr 23, 2024 pm 01:20 PM
Les dernières nouvelles de l'Université d'Oxford ! Mickey : correspondance d'images 2D en 3D SOTA ! (CVPR\'24)
Apr 23, 2024 pm 01:20 PM
Lien du projet écrit devant : https://nianticlabs.github.io/mickey/ Étant donné deux images, la pose de la caméra entre elles peut être estimée en établissant la correspondance entre les images. En règle générale, ces correspondances sont 2D à 2D et nos poses estimées sont à échelle indéterminée. Certaines applications, telles que la réalité augmentée instantanée, à tout moment et en tout lieu, nécessitent une estimation de pose des métriques d'échelle, elles s'appuient donc sur des estimateurs de profondeur externes pour récupérer l'échelle. Cet article propose MicKey, un processus de correspondance de points clés capable de prédire les correspondances métriques dans l'espace d'une caméra 3D. En apprenant la correspondance des coordonnées 3D entre les images, nous sommes en mesure de déduire des métriques relatives.
