

Comment l'architecture Java est appliquée à différents produits

Lorsque nous mettons en place un système, nous devons généralement réfléchir à la manière d'interagir avec d'autres systèmes. Nous devons donc d'abord savoir comment les différents systèmes interagissent les uns avec les autres et quelle technologie est utilisée pour le mettre en œuvre.
1. Interaction entre différents systèmes et différents langages
De nos jours, nos interactions communes entre différents systèmes et différents langages utilisent des requêtes WebService et Http. WebService, c'est-à-dire « service Web », en abrégé WS. Au sens littéral, il s'agit en fait d'un « service basé sur le Web ». Mais les services appartiennent aux deux parties. S’il y a un demandeur de services, il y aura un fournisseur de services. Le fournisseur de services publie des services vers le monde extérieur et le demandeur de services appelle les services publiés par le fournisseur de services. Pour le dire de manière plus professionnelle, WS est en fait un outil construit sur le protocole HTTP pour mettre en œuvre une communication système hétérogène. C'est exact! Pour parler franchement, WS est basé sur le protocole HTTP, c'est-à-dire que les données sont transmises via HTTP. Au début, nous avons utilisé CXF pour développer des services SOAP pour implémenter WS, et plus tard, nous avons utilisé les services REST pour implémenter WS (ceci est actuellement utilisé plus souvent, et c'est aussi celui que j'utilise le plus). Les services REST peuvent également être développés sur la base de CXF, mais nous utilisons généralement springMVC ou d'autres frameworks MVC directement pour implémenter les services REST.
Mais dans l’esprit de beaucoup, les services Web font généralement référence à diverses technologies interactives basées sur XML dirigées par IBM il y a plus de dix ans. De nos jours, à l’exception de certaines entreprises, peu de gens les utilisent. Au sens large, Webservice est un service Web, et tout est un service.
2. Interaction entre différents systèmes avec le même langage
Les interactions courantes entre différents systèmes avec le même langage sont implémentées à l'aide de RPC (appel de procédure à distance) ou RMI (invocation de méthode à distance), sans fournir de services externes, bien sûr. mentionné ci-dessus peut également être utilisé pour l'interaction entre les mêmes langages, mais j'utilise généralement RPC.
Architecture de différents produits
3. Evolution de l'architecture d'un seul produit
Généralement, le processus d'évolution de l'architecture lorsque nous n'avons qu'un seul produit Si nous devons fournir un service Web au monde extérieur, nous utilisons généralement REST. service pour y parvenir.
Le contenu suivant provient de Zhihu
1) Évolution de l'architecture distribuée Évolution de l'architecture du système - architecture de la phase initiale
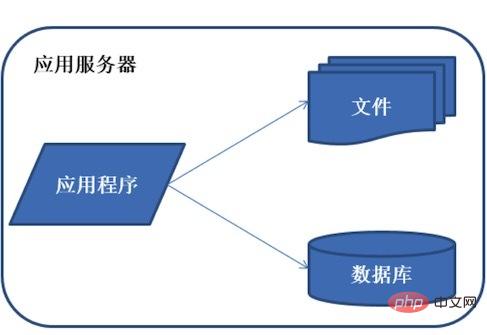
Toutes les ressources telles que les petites applications système, les bases de données, les fichiers, etc. Le tout sur un seul serveur, communément appelé LAMP
Caractéristiques : Toutes les ressources telles que les applications, les bases de données, les fichiers, etc. se trouvent sur un seul serveur.
Description : Habituellement, le système d'exploitation du serveur utilise Linux, l'application est développée en PHP, puis déployée sur Apache, et la base de données utilise Mysql. En rassemblant divers logiciels open source gratuits et un serveur bon marché, vous pouvez démarrer le développement du serveur. système.
2) Évolution de l'architecture système - séparation des services d'application et des services de données
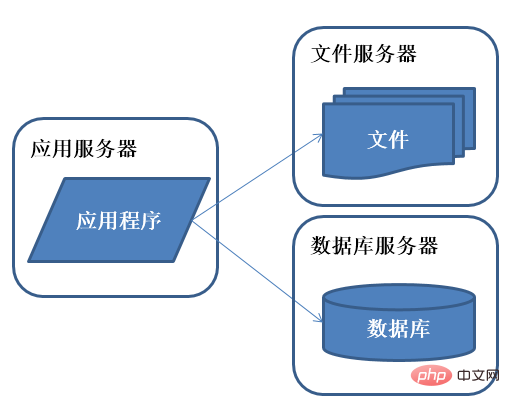
Les bons moments n'ont pas duré longtemps. Il a été constaté qu'à mesure que le nombre de visites du système augmente à nouveau, la pression sur la machine du serveur Web augmente. atteindra un niveau relativement élevé pendant les périodes de pointe. Il est temps d'envisager l'ajout d'un serveur Web
Caractéristiques : Les applications, les bases de données et les fichiers sont déployés sur des ressources indépendantes.
Description : La quantité de données augmente, les performances et l'espace de stockage d'un seul serveur sont insuffisants et les applications et les données doivent être séparées. La capacité de traitement simultané et l'espace de stockage des données ont été considérablement améliorés.
3) Evolution de l'architecture système - utilisation du cache pour améliorer les performances
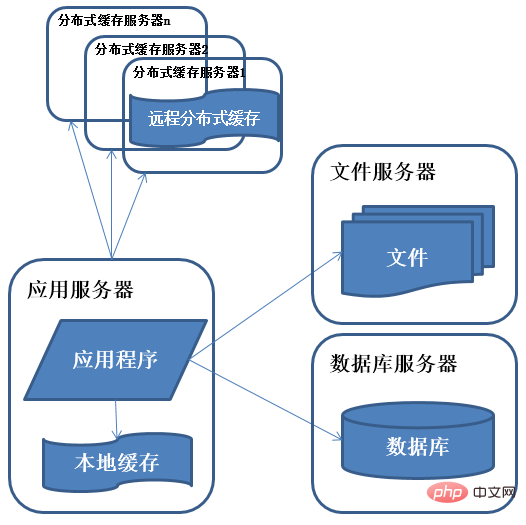
Caractéristiques : Une petite partie des données auxquelles on accède de manière plus intensive dans la base de données est stockée dans le serveur de cache, réduisant ainsi le nombre d'accès à la base de données et réduire la pression d'accès sur la base de données.
Description : Les caractéristiques d'accès au système suivent la règle des 80/20, c'est-à-dire que 80 % des accès professionnels sont concentrés sur 20 % des données. Le cache est divisé en cache local et cache distribué distant. Le cache local a une vitesse d'accès plus rapide mais la quantité de données mises en cache est limitée. En même temps, il peut rivaliser avec l'application pour la mémoire.
4) Evolution de l'architecture système - utilisation du cluster de serveurs d'applications
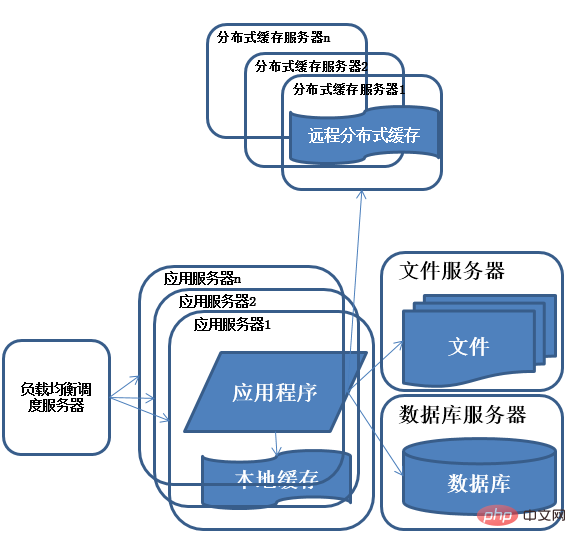
Après avoir terminé le travail de la sous-base de données et de la table, la pression sur la base de données est tombée à un niveau relativement faible, et j'ai commencé à regarder l'accès tous les jours. Soudain, un jour, j'ai constaté que l'accès au système commençait à ralentir à nouveau. À ce moment-là, j'ai d'abord vérifié la base de données et j'ai constaté que la pression était normale. Ensuite, j'ai vérifié le serveur Web et j'ai constaté qu'Apache était bloqué. Il y a beaucoup de requêtes et le serveur d'applications est également relativement rapide pour chaque requête. Il semble que le nombre de requêtes soit trop élevé, ce qui entraîne la nécessité de faire la queue et la vitesse de réponse est lente. Caractéristiques : Plusieurs serveurs fournissent. services vers l'extérieur en même temps grâce à l'équilibrage de charge, résolvant la capacité de traitement et l'espace de stockage d'un seul serveur La question de la limite supérieure.
Description : L'utilisation de clusters est une méthode courante permettant aux systèmes de résoudre des problèmes de concurrence élevée et de données massives. En ajoutant des ressources au cluster, les capacités de traitement simultané du système sont améliorées, de sorte que la pression de charge du serveur ne devienne plus le goulot d'étranglement de l'ensemble du système.
5) Évolution de l'architecture du système - séparation en lecture et en écriture de la base de données
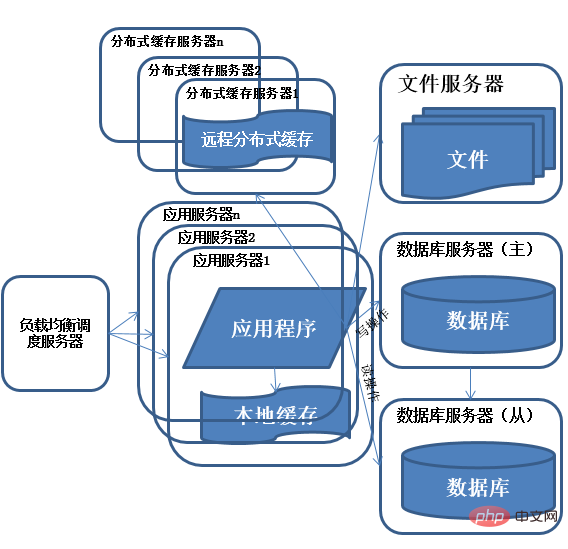
Après avoir profité de la croissance rapide des visites du système pendant un certain temps, j'ai constaté que le système commençait à ralentir à nouveau. Quelle est la situation ? temps ? Après les opérations de recherche et de mise à jour de la base de données. La concurrence pour les ressources de connexion à la base de données est très féroce, ce qui ralentit le système
Caractéristiques : Plusieurs serveurs fournissent des services à l'extérieur en même temps grâce à l'équilibrage de charge, résolvant ainsi le problème. de la puissance de traitement et du stockage d'un seul serveur Le problème de la limite d'espace.
Description : L'utilisation de clusters est une méthode courante permettant aux systèmes de résoudre des problèmes de concurrence élevée et de données massives. En ajoutant des ressources au cluster, la pression de charge sur le serveur ne devient plus le goulot d'étranglement de l'ensemble du système.
6) Évolution de l'architecture du système - proxy inverse et accélération du CDN
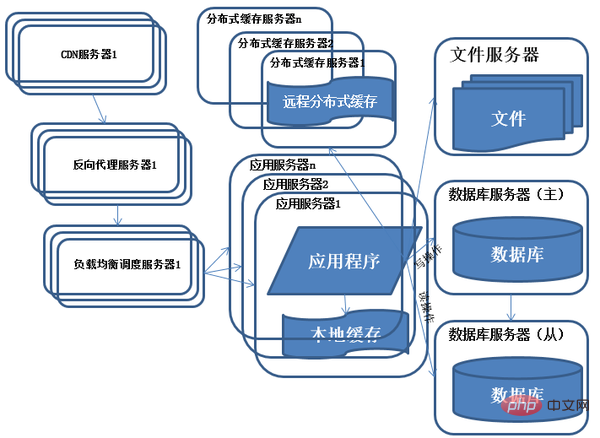
Caractéristiques : Utilisez le CDN et le proxy inverse pour accélérer l'accès au système.
Description : Afin de faire face à l'environnement réseau complexe et à l'accès des utilisateurs de différentes régions, le CDN et le proxy inverse sont utilisés pour accélérer l'accès des utilisateurs tout en réduisant la pression de charge sur le serveur back-end. Les principes de base du CDN et du proxy inverse sont la mise en cache.
7) Évolution de l'architecture du système - système de fichiers distribué et base de données distribuée
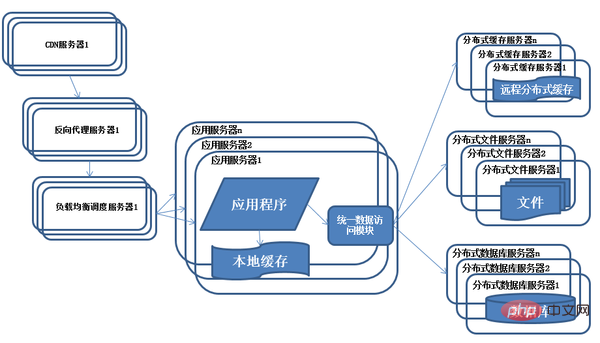
Au fur et à mesure que le système continue de fonctionner, la quantité de données commence à augmenter de manière significative. La division de la base de données est encore un peu lente. Donc, selon l'idée de sous-base de données, nous avons commencé à travailler sur le partage de table
Caractéristiques : La base de données utilise une base de données distribuée et le système de fichiers utilise un fichier distribué. système.
Description : Aucun serveur puissant ne peut répondre aux besoins commerciaux croissants des systèmes à grande échelle. La séparation de la lecture et de l'écriture des bases de données ne sera finalement pas en mesure de répondre aux besoins à mesure que l'entreprise se développe. être utilisé pour le soutenir. La base de données distribuée est la seule méthode de fractionnement de base de données système. Elle n'est utilisée que lorsque l'échelle des données d'une seule table est très grande. La méthode de fractionnement de base de données la plus couramment utilisée est la sous-base de données d'entreprise, qui déploie différentes bases de données d'entreprise sur différents serveurs physiques. supérieur.
8) Évolution de l'architecture du système - utilisation de NoSQL et des moteurs de recherche
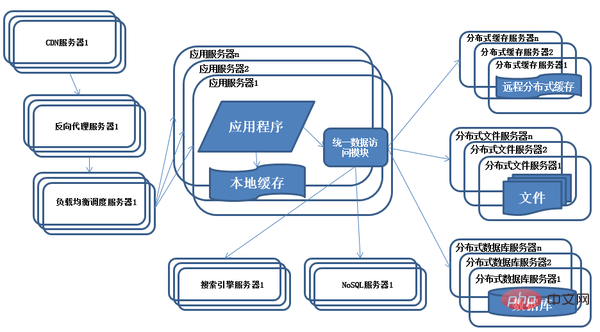
Caractéristiques : Le système introduit des bases de données NoSQL et des moteurs de recherche.
Description : À mesure que les affaires deviennent de plus en plus complexes, les exigences en matière de stockage et de récupération des données deviennent de plus en plus complexes. Le système doit utiliser certaines bases de données non relationnelles telles que NoSQL et des technologies de requête de sous-bases de données telles que les moteurs de recherche. Le serveur d'applications accède à diverses données via un module d'accès aux données unifié, réduisant ainsi les problèmes liés à la gestion de nombreuses sources de données par les applications.
9) Evolution de l'architecture système - répartition des activités
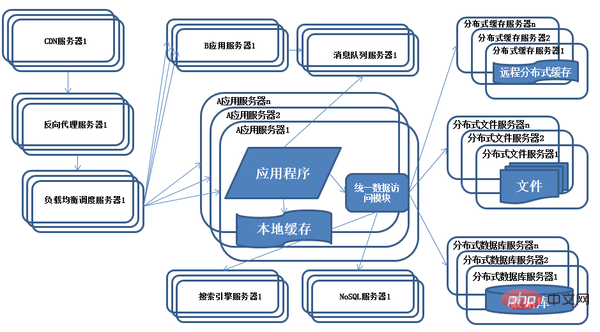
Caractéristiques : Le système est divisé et transformé selon les activités, et les serveurs d'applications sont déployés séparément selon la différenciation des activités.
Description : Afin de faire face à des scénarios commerciaux de plus en plus complexes, les méthodes diviser pour régner sont généralement utilisées pour diviser l'ensemble de l'activité du système en différentes lignes de produits. Les relations sont établies entre les applications via des hyperliens, et les données peuvent également être distribuées via des files d'attente de messages. Bien sûr, il y en a plus. Un système complet connecté est formé en accédant au même système de stockage de données. Division verticale : diviser une grande application en plusieurs petites applications. Si la nouvelle entreprise est relativement indépendante, il est relativement simple de la concevoir et de la déployer directement en tant que système d'application Web indépendant. En triant l'entreprise, les applications plus petites seront. divisé en applications plus petites. Les activités concernées peuvent être cédées. Fractionnement horizontal : divisez les entreprises réutilisables et déployez-les indépendamment en tant que services distribués. Les nouvelles entreprises n'ont qu'à appeler ces services distribués. La division horizontale nécessite l'identification des entreprises réutilisables, la conception d'interfaces de service et la normalisation des dépendances des services.
10) Évolution de l'architecture système - Services distribués
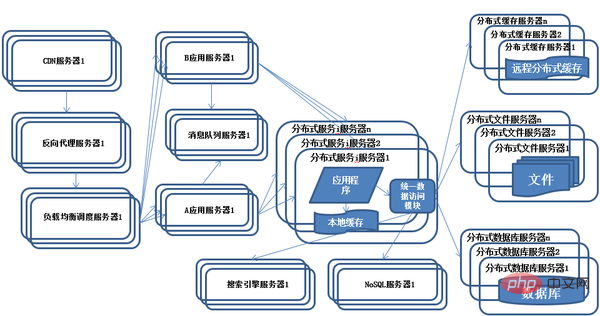
Q : À quels problèmes les applications de services distribués seront-elles confrontées ?
(1) Lorsqu'il y a de plus en plus de services, la gestion de la configuration des URL de service devient très difficile et la pression d'un point unique sur l'équilibreur de charge matériel F5 augmente également.
(2) Au fur et à mesure du développement, les dépendances entre les services deviennent si compliquées qu'il est même difficile de savoir quelle application doit être démarrée avant quelle application, et l'architecte ne peut pas décrire complètement la relation architecturale de l'application.
(3) Ensuite, à mesure que le nombre d'appels vers le service augmente, le problème de capacité du service est exposé. Combien de machines ce service doit-il prendre en charge ? Quand dois-je ajouter une machine ?
(4) Avec l'augmentation des services, les coûts de communication ont commencé à augmenter. Qui dois-je contacter si l'ajustement d'un certain service échoue ? Quelles sont les conventions pour les paramètres de service ?
(5) Un service a plusieurs consommateurs professionnels, comment garantir la qualité du service ?
(6) Avec la mise à niveau continue des services, des choses inattendues se produisent toujours. Par exemple, le cache est mal écrit, provoquant un débordement de mémoire. Chaque fois qu'un service principal tombe en panne, cela affecte une grande zone et provoque la panique. . Comment le contrôler ? Quel est l'impact de la panne ? Les services peuvent-ils être fonctionnellement dégradés ? Ou une dégradation des ressources ?
Cela semble être le début des principes fondamentaux et de l'analyse de cas de l'architecture technique des sites Web à grande échelle, mais l'auteur l'a bien résumé, je vais donc le réimprimer.
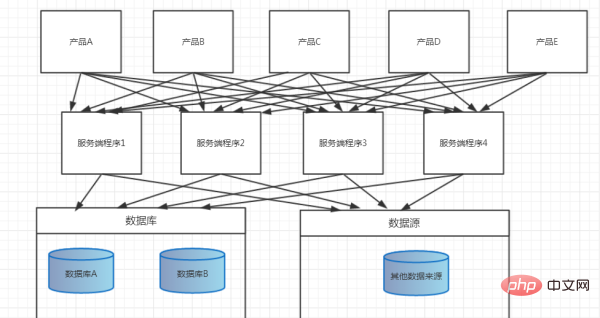
4. Structure de la gamme de produits
Une autre option est la répartition des activités mentionnée ci-dessus. Nous devons maintenant créer une gamme de produits. Nous n'avons besoin que d'une couche de données, d'une couche de logique métier générale et de diverses couches d'application et d'interface. Nous n'avons pas besoin de fournir de services à des systèmes externes (systèmes d'entreprises externes). Dans le passé, nous choisissions généralement d'utiliser EJB pour créer des applications distribuées, mais nous pouvons désormais utiliser des frameworks RPC tels que dobbo, thrift, avro et hessian pour créer des applications distribuées afin d'obtenir une interaction entre différentes applications et sources de données. Dans ce modèle structurel, nous devons fournir des services à d'autres entreprises et nous pouvons écrire une application dédiée pour fournir des services de repos aux systèmes externes. Généralement, la plupart des services Internet doivent accéder à une douzaine, voire des centaines de services internes, et la méthode de communication entre eux est généralement RPC : tout comme pour accéder à une méthode distante, saisissez des paramètres et attendez que le résultat soit renvoyé. Il s’agit de la manière la plus simple à comprendre de créer des systèmes complexes.
Comme le montre la figure ci-dessous, le modèle, le système de fichiers et le cache ne sont pas affichés, afin que tout le monde puisse les comprendre.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Nombre parfait en Java
Aug 30, 2024 pm 04:28 PM
Nombre parfait en Java
Aug 30, 2024 pm 04:28 PM
Guide du nombre parfait en Java. Nous discutons ici de la définition, comment vérifier le nombre parfait en Java ?, des exemples d'implémentation de code.
 Weka en Java
Aug 30, 2024 pm 04:28 PM
Weka en Java
Aug 30, 2024 pm 04:28 PM
Guide de Weka en Java. Nous discutons ici de l'introduction, de la façon d'utiliser Weka Java, du type de plate-forme et des avantages avec des exemples.
 Numéro de Smith en Java
Aug 30, 2024 pm 04:28 PM
Numéro de Smith en Java
Aug 30, 2024 pm 04:28 PM
Guide du nombre de Smith en Java. Nous discutons ici de la définition, comment vérifier le numéro Smith en Java ? exemple avec implémentation de code.
 Questions d'entretien chez Java Spring
Aug 30, 2024 pm 04:29 PM
Questions d'entretien chez Java Spring
Aug 30, 2024 pm 04:29 PM
Dans cet article, nous avons conservé les questions d'entretien Java Spring les plus posées avec leurs réponses détaillées. Pour que vous puissiez réussir l'interview.
 Break or Return of Java 8 Stream Forach?
Feb 07, 2025 pm 12:09 PM
Break or Return of Java 8 Stream Forach?
Feb 07, 2025 pm 12:09 PM
Java 8 présente l'API Stream, fournissant un moyen puissant et expressif de traiter les collections de données. Cependant, une question courante lors de l'utilisation du flux est: comment se casser ou revenir d'une opération FOREAK? Les boucles traditionnelles permettent une interruption ou un retour précoce, mais la méthode Foreach de Stream ne prend pas directement en charge cette méthode. Cet article expliquera les raisons et explorera des méthodes alternatives pour la mise en œuvre de terminaison prématurée dans les systèmes de traitement de flux. Lire plus approfondie: Améliorations de l'API Java Stream Comprendre le flux Forach La méthode foreach est une opération terminale qui effectue une opération sur chaque élément du flux. Son intention de conception est
 Horodatage à ce jour en Java
Aug 30, 2024 pm 04:28 PM
Horodatage à ce jour en Java
Aug 30, 2024 pm 04:28 PM
Guide de TimeStamp to Date en Java. Ici, nous discutons également de l'introduction et de la façon de convertir l'horodatage en date en Java avec des exemples.
 Programme Java pour trouver le volume de la capsule
Feb 07, 2025 am 11:37 AM
Programme Java pour trouver le volume de la capsule
Feb 07, 2025 am 11:37 AM
Les capsules sont des figures géométriques tridimensionnelles, composées d'un cylindre et d'un hémisphère aux deux extrémités. Le volume de la capsule peut être calculé en ajoutant le volume du cylindre et le volume de l'hémisphère aux deux extrémités. Ce tutoriel discutera de la façon de calculer le volume d'une capsule donnée en Java en utilisant différentes méthodes. Formule de volume de capsule La formule du volume de la capsule est la suivante: Volume de capsule = volume cylindrique volume de deux hémisphères volume dans, R: Le rayon de l'hémisphère. H: La hauteur du cylindre (à l'exclusion de l'hémisphère). Exemple 1 entrer Rayon = 5 unités Hauteur = 10 unités Sortir Volume = 1570,8 unités cubes expliquer Calculer le volume à l'aide de la formule: Volume = π × r2 × h (4
 Créer l'avenir : programmation Java pour les débutants absolus
Oct 13, 2024 pm 01:32 PM
Créer l'avenir : programmation Java pour les débutants absolus
Oct 13, 2024 pm 01:32 PM
Java est un langage de programmation populaire qui peut être appris aussi bien par les développeurs débutants que par les développeurs expérimentés. Ce didacticiel commence par les concepts de base et progresse vers des sujets avancés. Après avoir installé le kit de développement Java, vous pouvez vous entraîner à la programmation en créant un simple programme « Hello, World ! ». Une fois que vous avez compris le code, utilisez l'invite de commande pour compiler et exécuter le programme, et « Hello, World ! » s'affichera sur la console. L'apprentissage de Java commence votre parcours de programmation et, à mesure que votre maîtrise s'approfondit, vous pouvez créer des applications plus complexes.
