
 Périphériques technologiques
IA
Une ligne de texte génère une scène dynamique 3D : le modèle « one step » de Meta est assez puissant
Périphériques technologiques
IA
Une ligne de texte génère une scène dynamique 3D : le modèle « one step » de Meta est assez puissant
Une ligne de texte génère une scène dynamique 3D : le modèle « one step » de Meta est assez puissant

Il suffit de saisir une ligne de texte pour générer une scène dynamique 3D ?
Oui, certains chercheurs l'ont déjà fait. On voit que l'effet de génération actuel en est encore à ses balbutiements et ne peut générer que quelques objets simples. Cependant, cette méthode « en une étape » a quand même attiré l'attention d'un grand nombre de chercheurs :

Dans un article récent, des chercheurs de Meta ont proposé pour la première fois que des images 3D puissent être générées à partir de texte. descriptions Méthode de scène dynamique MAV3D (Make-A-Video3D).

- Lien papier : https://arxiv.org/abs/2301.11280
- Lien du projet : https://make-a-video3d.github.io/
Plus précisément, cette méthode utilise des champs de rayonnement neuronal dynamiques 4D (NeRF) pour optimiser la cohérence de l'apparence, de la densité et du mouvement de la scène en interrogeant un modèle basé sur la diffusion texte-vidéo (T2V). La sortie vidéo dynamique générée par le texte fourni peut être visualisée sous n'importe quel angle ou angle de caméra et peut être synthétisée dans n'importe quel environnement 3D.
MAV3D ne nécessite aucune donnée 3D ou 4D, le modèle T2V est uniquement entraîné sur des paires texte-image et des vidéos non étiquetées.

Jetons un coup d'oeil à l'effet de MAV3D générant des scènes dynamiques 4D à partir du texte :

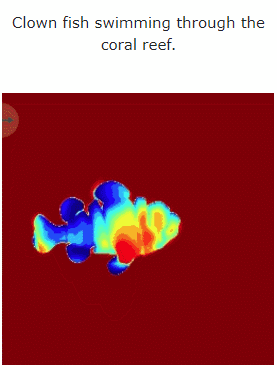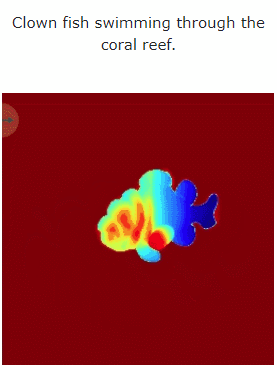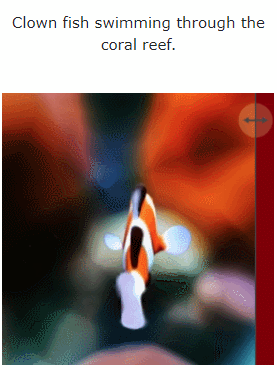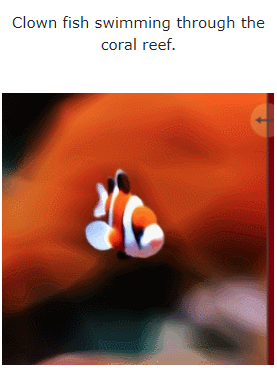
De plus, il peut passer également directement de l'image à 4D , l'effet est le suivant :


Les chercheurs ont prouvé l'efficacité de la méthode grâce à des expériences quantitatives et qualitatives complètes, et la base de référence interne précédemment établie a également été améliorée. Il est rapporté qu'il s'agit de la première méthode permettant de générer des scènes dynamiques 3D basées sur des descriptions textuelles.
Méthode
Le but de cette recherche est de développer une méthode capable de générer des représentations dynamiques de scènes 3D à partir de descriptions en langage naturel. C'est extrêmement difficile car il n'y a ni texte, ni paires 3D, ni données de scène 3D dynamiques pour la formation. Par conséquent, nous avons choisi de nous appuyer sur un modèle de diffusion texte-vidéo (T2V) pré-entraîné comme scène préalable, qui a appris à modéliser l'apparence et le mouvement réalistes de la scène grâce à un entraînement sur des images, des textes et des images à grande échelle. données vidéo.
À partir d'un niveau supérieur, étant donné une invite textuelle p, l'étude peut s'adapter à une représentation 4D, qui simule une représentation 4D qui correspond à l'invite à tout moment dans l'espace et dans le temps. . Sans données d'entraînement appariées, l'étude ne peut cependant pas superviser directement la sortie de 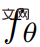 , étant donné une séquence de poses de caméra #🎜🎜 ; #
, étant donné une séquence de poses de caméra #🎜🎜 ; # 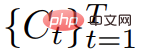 # 🎜🎜#Vous pouvez restituer une séquence d'images de et les empiler dans une vidéo V. L'invite textuelle p et la vidéo V sont ensuite transmises au modèle de diffusion T2V gelé et pré-entraîné, qui évalue l'authenticité et l'alignement rapide de la vidéo et utilise le SDS (Score Distillation Sampling) pour calculer la direction de mise à jour du paramètre de scène θ.
# 🎜🎜#Vous pouvez restituer une séquence d'images de et les empiler dans une vidéo V. L'invite textuelle p et la vidéo V sont ensuite transmises au modèle de diffusion T2V gelé et pré-entraîné, qui évalue l'authenticité et l'alignement rapide de la vidéo et utilise le SDS (Score Distillation Sampling) pour calculer la direction de mise à jour du paramètre de scène θ. 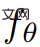
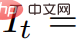
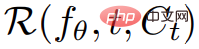 Le pipeline ci-dessus peut être considéré comme une extension de DreamFusion, ajoutant une dimension temporelle au modèle de scène et utilisant le modèle T2V au lieu du texte en image (T2I ) pour la supervision. Cependant, parvenir à une génération de texte en 4D de haute qualité nécessite davantage d'innovation :
Le pipeline ci-dessus peut être considéré comme une extension de DreamFusion, ajoutant une dimension temporelle au modèle de scène et utilisant le modèle T2V au lieu du texte en image (T2I ) pour la supervision. Cependant, parvenir à une génération de texte en 4D de haute qualité nécessite davantage d'innovation :
Première, nouvelle représentation 4D flexible de la modélisation du mouvement de la scène ;#🎜 🎜#
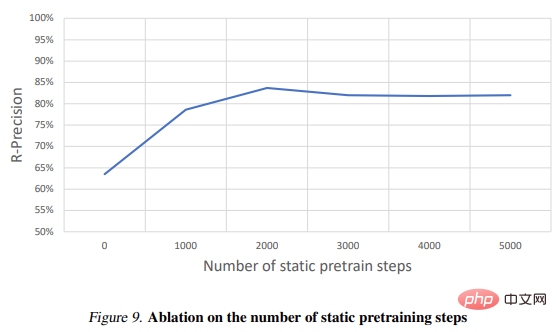
Deuxièmement, un schéma d'optimisation statique à dynamique à plusieurs niveaux est nécessaire pour améliorer la qualité de la vidéo et améliorer la convergence des modèles, qui utilise plusieurs Un régularisateur de mouvement est utilisé pour générer un mouvement réel ;- Voir l'image ci-dessous pour des instructions spécifiques :
- #🎜 🎜# Experiment
Dans l'expérience, les chercheurs ont évalué la capacité de MAV3D à générer des scènes dynamiques à partir de descriptions textuelles. Tout d’abord, les chercheurs ont évalué l’efficacité de la méthode sur la tâche Text-To-4D. Il est rapporté que MAV3D est la première solution à cette tâche, la recherche a donc développé trois méthodes alternatives comme référence. Deuxièmement, nous évaluons les versions simplifiées des modèles de sous-tâches T2V et Text-To-3D et les comparons aux références existantes dans la littérature. Troisièmement, des études approfondies sur l’ablation justifient la conception de la méthode. Quatrièmement, les expériences décrivent le processus de conversion du NeRF dynamique en maillages dynamiques, étendant finalement le modèle aux tâches Image-to-4D. L'étude utilise CLIP R-Precision pour évaluer la génération. de vidéo, qui mesure la cohérence entre le texte et les scènes générées. La métrique rapportée est la précision de la récupération de l'invite de saisie à partir de l'image rendue. Nous avons utilisé la variante ViT-B/32 de CLIP et extrait les images à différentes vues et pas de temps, et avons également utilisé quatre mesures qualitatives en demandant aux évaluateurs humains leurs préférences sur deux vidéos générées, respectivement : (i) la qualité vidéo (). ii) fidélité aux invites textuelles ; (iii) quantité d'activité (iv) réalisme du mouvement ; Nous avons évalué toutes les lignes de base et ablations utilisées dans la segmentation des invites de texte.
Les figures 1 et 2 sont des exemples. Pour des visualisations plus détaillées, consultez make-a-video3d.github.io.

result# 🎜🎜#
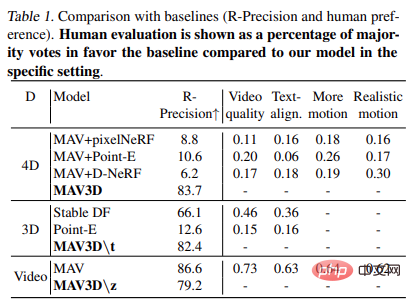
Le tableau 1 montre la comparaison avec la ligne de base (R - précision et préférence humaine). Les évaluations humaines sont présentées sous forme de pourcentage de votes en faveur de la majorité de base par rapport au modèle dans un environnement spécifique.
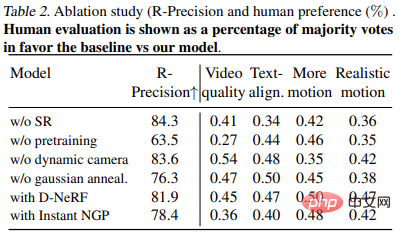
Le tableau 2 présente les résultats de l'expérience d'ablation : # 🎜🎜#
rendu en temps réel#🎜 🎜## 🎜🎜# Les applications telles que la réalité virtuelle et les jeux utilisant des moteurs graphiques traditionnels nécessitent des formats standards tels que les maillages de texture. Les modèles HexPlane peuvent être facilement convertis en maillages animés comme indiqué ci-dessous. Tout d’abord, un simple maillage est extrait du champ d’opacité généré à chaque instant t à l’aide de l’algorithme du marching cube, suivi d’une extraction de maillage (pour plus d’efficacité) et de la suppression des petits composants connectés bruyants. L'algorithme XATLAS est utilisé pour mapper les sommets du maillage sur un atlas de textures, la texture étant initialisée à l'aide de la couleur HexPlane moyennée dans une petite sphère centrée sur chaque sommet. Enfin, les textures sont encore optimisées pour mieux correspondre à certains exemples d'images rendues par HexPlane à l'aide de maillages différenciables. Cela produira une collection de maillages de textures pouvant être lus dans n'importe quel moteur 3D standard.
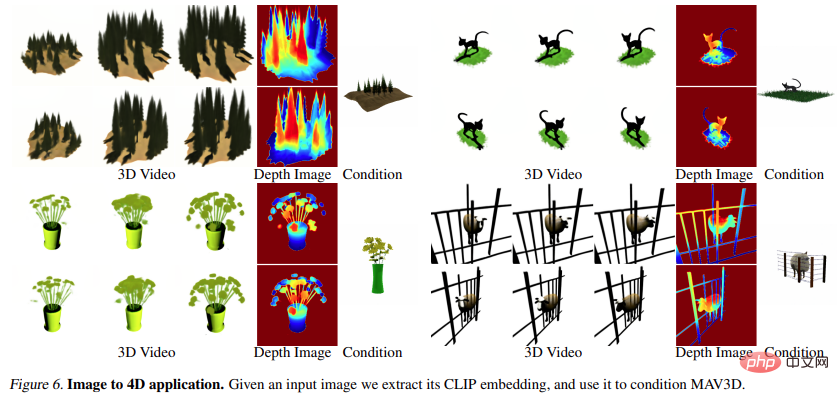
Image to 4D
La figure 6 et la figure 10 montrent ceci La méthode est capable de générer de la profondeur et du mouvement à partir d’une image d’entrée donnée, générant ainsi des ressources 4D.
# 🎜 🎜#


Pour plus de détails sur la recherche, veuillez vous référer à l'original papier.

Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Utilisez ddrescue pour récupérer des données sous Linux
Mar 20, 2024 pm 01:37 PM
Utilisez ddrescue pour récupérer des données sous Linux
Mar 20, 2024 pm 01:37 PM
DDREASE est un outil permettant de récupérer des données à partir de périphériques de fichiers ou de blocs tels que des disques durs, des SSD, des disques RAM, des CD, des DVD et des périphériques de stockage USB. Il copie les données d'un périphérique bloc à un autre, laissant derrière lui les blocs corrompus et ne déplaçant que les bons blocs. ddreasue est un puissant outil de récupération entièrement automatisé car il ne nécessite aucune interruption pendant les opérations de récupération. De plus, grâce au fichier map ddasue, il peut être arrêté et repris à tout moment. Les autres fonctionnalités clés de DDREASE sont les suivantes : Il n'écrase pas les données récupérées mais comble les lacunes en cas de récupération itérative. Cependant, il peut être tronqué si l'outil est invité à le faire explicitement. Récupérer les données de plusieurs fichiers ou blocs en un seul
 Open source! Au-delà de ZoeDepth ! DepthFM : estimation rapide et précise de la profondeur monoculaire !
Apr 03, 2024 pm 12:04 PM
Open source! Au-delà de ZoeDepth ! DepthFM : estimation rapide et précise de la profondeur monoculaire !
Apr 03, 2024 pm 12:04 PM
0. À quoi sert cet article ? Nous proposons DepthFM : un modèle d'estimation de profondeur monoculaire génératif de pointe, polyvalent et rapide. En plus des tâches traditionnelles d'estimation de la profondeur, DepthFM démontre également des capacités de pointe dans les tâches en aval telles que l'inpainting en profondeur. DepthFM est efficace et peut synthétiser des cartes de profondeur en quelques étapes d'inférence. Lisons ce travail ensemble ~ 1. Titre des informations sur l'article : DepthFM : FastMonocularDepthEstimationwithFlowMatching Auteur : MingGui, JohannesS.Fischer, UlrichPrestel, PingchuanMa, Dmytr
 Google est ravi : les performances de JAX surpassent Pytorch et TensorFlow ! Cela pourrait devenir le choix le plus rapide pour la formation à l'inférence GPU
Apr 01, 2024 pm 07:46 PM
Google est ravi : les performances de JAX surpassent Pytorch et TensorFlow ! Cela pourrait devenir le choix le plus rapide pour la formation à l'inférence GPU
Apr 01, 2024 pm 07:46 PM
Les performances de JAX, promu par Google, ont dépassé celles de Pytorch et TensorFlow lors de récents tests de référence, se classant au premier rang sur 7 indicateurs. Et le test n’a pas été fait sur le TPU présentant les meilleures performances JAX. Bien que parmi les développeurs, Pytorch soit toujours plus populaire que Tensorflow. Mais à l’avenir, des modèles plus volumineux seront peut-être formés et exécutés sur la base de la plate-forme JAX. Modèles Récemment, l'équipe Keras a comparé trois backends (TensorFlow, JAX, PyTorch) avec l'implémentation native de PyTorch et Keras2 avec TensorFlow. Premièrement, ils sélectionnent un ensemble de
 Vitesse Internet lente des données cellulaires sur iPhone : correctifs
May 03, 2024 pm 09:01 PM
Vitesse Internet lente des données cellulaires sur iPhone : correctifs
May 03, 2024 pm 09:01 PM
Vous êtes confronté à un décalage et à une connexion de données mobile lente sur iPhone ? En règle générale, la puissance de l'Internet cellulaire sur votre téléphone dépend de plusieurs facteurs tels que la région, le type de réseau cellulaire, le type d'itinérance, etc. Vous pouvez prendre certaines mesures pour obtenir une connexion Internet cellulaire plus rapide et plus fiable. Correctif 1 – Forcer le redémarrage de l'iPhone Parfois, le redémarrage forcé de votre appareil réinitialise simplement beaucoup de choses, y compris la connexion cellulaire. Étape 1 – Appuyez simplement une fois sur la touche d’augmentation du volume et relâchez-la. Ensuite, appuyez sur la touche de réduction du volume et relâchez-la à nouveau. Étape 2 – La partie suivante du processus consiste à maintenir le bouton sur le côté droit. Laissez l'iPhone finir de redémarrer. Activez les données cellulaires et vérifiez la vitesse du réseau. Vérifiez à nouveau Correctif 2 – Changer le mode de données Bien que la 5G offre de meilleures vitesses de réseau, elle fonctionne mieux lorsque le signal est plus faible
 La vitalité de la super intelligence s'éveille ! Mais avec l'arrivée de l'IA qui se met à jour automatiquement, les mères n'ont plus à se soucier des goulots d'étranglement des données.
Apr 29, 2024 pm 06:55 PM
La vitalité de la super intelligence s'éveille ! Mais avec l'arrivée de l'IA qui se met à jour automatiquement, les mères n'ont plus à se soucier des goulots d'étranglement des données.
Apr 29, 2024 pm 06:55 PM
Je pleure à mort. Le monde construit à la folie de grands modèles. Les données sur Internet ne suffisent pas du tout. Le modèle de formation ressemble à « The Hunger Games », et les chercheurs en IA du monde entier se demandent comment nourrir ces personnes avides de données. Ce problème est particulièrement important dans les tâches multimodales. À une époque où rien ne pouvait être fait, une équipe de start-up du département de l'Université Renmin de Chine a utilisé son propre nouveau modèle pour devenir la première en Chine à faire de « l'auto-alimentation des données générées par le modèle » une réalité. De plus, il s’agit d’une approche à deux volets, du côté compréhension et du côté génération, les deux côtés peuvent générer de nouvelles données multimodales de haute qualité et fournir un retour de données au modèle lui-même. Qu'est-ce qu'un modèle ? Awaker 1.0, un grand modèle multimodal qui vient d'apparaître sur le Forum Zhongguancun. Qui est l'équipe ? Moteur Sophon. Fondé par Gao Yizhao, doctorant à la Hillhouse School of Artificial Intelligence de l’Université Renmin.
 L'US Air Force présente son premier avion de combat IA de grande envergure ! Le ministre a personnellement effectué l'essai routier sans intervenir pendant tout le processus, et 100 000 lignes de code ont été testées 21 fois.
May 07, 2024 pm 05:00 PM
L'US Air Force présente son premier avion de combat IA de grande envergure ! Le ministre a personnellement effectué l'essai routier sans intervenir pendant tout le processus, et 100 000 lignes de code ont été testées 21 fois.
May 07, 2024 pm 05:00 PM
Récemment, le milieu militaire a été submergé par la nouvelle : les avions de combat militaires américains peuvent désormais mener des combats aériens entièrement automatiques grâce à l'IA. Oui, tout récemment, l’avion de combat IA de l’armée américaine a été rendu public pour la première fois, dévoilant ainsi son mystère. Le nom complet de ce chasseur est Variable Stability Simulator Test Aircraft (VISTA). Il a été personnellement piloté par le secrétaire de l'US Air Force pour simuler une bataille aérienne en tête-à-tête. Le 2 mai, le secrétaire de l'US Air Force, Frank Kendall, a décollé à bord d'un X-62AVISTA à la base aérienne d'Edwards. Notez que pendant le vol d'une heure, toutes les actions de vol ont été effectuées de manière autonome par l'IA ! Kendall a déclaré : "Au cours des dernières décennies, nous avons réfléchi au potentiel illimité du combat air-air autonome, mais cela a toujours semblé hors de portée." Mais maintenant,
 Le premier robot capable d'accomplir de manière autonome des tâches humaines apparaît, avec cinq doigts flexibles et rapides, et de grands modèles prennent en charge l'entraînement dans l'espace virtuel
Mar 11, 2024 pm 12:10 PM
Le premier robot capable d'accomplir de manière autonome des tâches humaines apparaît, avec cinq doigts flexibles et rapides, et de grands modèles prennent en charge l'entraînement dans l'espace virtuel
Mar 11, 2024 pm 12:10 PM
Cette semaine, FigureAI, une entreprise de robotique investie par OpenAI, Microsoft, Bezos et Nvidia, a annoncé avoir reçu près de 700 millions de dollars de financement et prévoit de développer un robot humanoïde capable de marcher de manière autonome au cours de la prochaine année. Et l’Optimus Prime de Tesla a reçu à plusieurs reprises de bonnes nouvelles. Personne ne doute que cette année sera celle de l’explosion des robots humanoïdes. SanctuaryAI, une entreprise canadienne de robotique, a récemment lancé un nouveau robot humanoïde, Phoenix. Les responsables affirment qu’il peut accomplir de nombreuses tâches de manière autonome, à la même vitesse que les humains. Pheonix, le premier robot au monde capable d'accomplir des tâches de manière autonome à la vitesse d'un humain, peut saisir, déplacer et placer avec élégance chaque objet sur ses côtés gauche et droit. Il peut identifier des objets de manière autonome
 Le document multimodal Alibaba 7B comprenant le grand modèle remporte le nouveau SOTA
Apr 02, 2024 am 11:31 AM
Le document multimodal Alibaba 7B comprenant le grand modèle remporte le nouveau SOTA
Apr 02, 2024 am 11:31 AM
Nouveau SOTA pour des capacités de compréhension de documents multimodaux ! L'équipe Alibaba mPLUG a publié le dernier travail open source mPLUG-DocOwl1.5, qui propose une série de solutions pour relever les quatre défis majeurs que sont la reconnaissance de texte d'image haute résolution, la compréhension générale de la structure des documents, le suivi des instructions et l'introduction de connaissances externes. Sans plus tarder, examinons d’abord les effets. Reconnaissance et conversion en un clic de graphiques aux structures complexes au format Markdown : Des graphiques de différents styles sont disponibles : Une reconnaissance et un positionnement de texte plus détaillés peuvent également être facilement traités : Des explications détaillées sur la compréhension du document peuvent également être données : Vous savez, « Compréhension du document " est actuellement un scénario important pour la mise en œuvre de grands modèles linguistiques. Il existe de nombreux produits sur le marché pour aider à la lecture de documents. Certains d'entre eux utilisent principalement des systèmes OCR pour la reconnaissance de texte et coopèrent avec LLM pour le traitement de texte.
