

Ces dernières années, une formation multimodale à grande échelle basée sur Transformer a conduit à des améliorations technologiques de pointe dans différents domaines, notamment la vision, le langage et l'audio. En particulier en matière de vision par ordinateur et de compréhension du langage des images, un seul grand modèle pré-entraîné peut surpasser un modèle expert pour une tâche spécifique.
Cependant, les grands modèles multimodaux utilisent souvent des encodeurs et des décodeurs spécifiques à une modalité ou à un ensemble de données, et aboutissent à des protocoles impliqués en conséquence. Par exemple, de tels modèles impliquent souvent différentes étapes de formation de différentes parties du modèle sur leurs ensembles de données respectifs, avec un prétraitement spécifique à l'ensemble de données, ou le transfert de différentes parties d'une manière spécifique à une tâche. Ce modèle et ces composants spécifiques à une tâche peuvent entraîner une complexité et des défis d'ingénierie supplémentaires lors de l'introduction de nouvelles pertes de pré-formation ou de nouvelles tâches en aval.
Par conséquent, développer un modèle unique de bout en bout capable de gérer n'importe quelle modalité ou combinaison de modalités sera une étape importante vers l'apprentissage multimodal. Dans cet article, les chercheurs de Google Research (équipe Google Brain) à Zurich se concentreront principalement sur les images et le texte.

Adresse papier : https://arxiv.org/pdf/2212.08045.pdf
De nombreuses unifications clés accélèrent le processus d'apprentissage multimodal. Premièrement, il a été prouvé que l'architecture Transformer peut servir de colonne vertébrale générale et fonctionner correctement dans les domaines du texte, des visuels, de l'audio et dans d'autres domaines. Deuxièmement, de nombreux articles explorent la cartographie de différentes modalités dans un seul espace d'intégration partagé afin de simplifier les interfaces d'entrée/sortie ou de développer une interface unique pour plusieurs tâches. Troisièmement, des représentations alternatives des modalités permettent l'utilisation dans un domaine d'architectures neuronales ou de procédures de formation conçues dans un autre domaine. Par exemple, [54] et [26,48] représentent respectivement le texte et l'audio, qui sont traités en rendant ces formes sous forme d'images (spectrogrammes dans le cas de l'audio).
Cet article explorera l'apprentissage multimodal du texte et des images à l'aide de modèles purement basés sur les pixels. Le modèle est un transformateur visuel distinct qui traite les entrées visuelles ou le texte, ou les deux ensemble, le tout rendu sous forme d'images RVB. Toutes les modalités utilisent les mêmes paramètres de modèle, y compris le traitement des fonctionnalités de bas niveau ; c'est-à-dire qu'il n'y a pas de convolutions initiales, d'algorithmes de tokenisation ou de tables d'intégration d'entrée spécifiques aux modalités. Le modèle est formé avec une seule tâche : l'apprentissage contrastif, tel que popularisé par CLIP et ALIGN. Le modèle est donc appelé CLIP-Pixels Only (CLIPPO).
Sur les tâches principales pour lesquelles CLIP est conçu pour la classification d'images et la récupération de texte/image, CLIPPO fonctionne également de manière similaire à CLIP (avec une similarité de 1 à 2 %) bien qu'il n'ait pas de modalité de tour spécifique. Étonnamment, CLIPPO peut effectuer des tâches complexes de compréhension du langage sans nécessiter de modélisation linguistique de gauche à droite, de modélisation linguistique masquée ou de pertes explicites au niveau des mots. Surtout sur le benchmark GLUE, CLIPPO surpasse les bases de référence NLP classiques telles que ELMO+BiLSTM+attention. De plus, CLIPPO surpasse également les modèles de langage de masque basés sur les pixels et se rapproche du score de BERT.
Fait intéressant, CLIPPO obtient également de bonnes performances sur VQA lors du simple rendu d'images et de texte ensemble, bien qu'il n'ait jamais été pré-entraîné sur de telles données. Un avantage immédiat des modèles basés sur les pixels par rapport aux modèles de langage conventionnels est qu'aucun vocabulaire prédéterminé n'est requis. De ce fait, les performances de récupération multilingue sont améliorées par rapport aux modèles équivalents utilisant des tokenizers classiques. Enfin, l’étude a également révélé que dans certains cas, les écarts modaux précédemment observés étaient réduits lors de la formation CLIPPO.
CLIP est devenu un paradigme puissant et évolutif pour former des modèles de vision polyvalents sur des ensembles de données. Plus précisément, cette approche repose sur des paires image/texte alternatif, qui peuvent être automatiquement collectées à grande échelle sur le Web. En conséquence, les descriptions textuelles sont souvent bruitées et peuvent consister en des mots-clés uniques, des ensembles de mots-clés ou des descriptions potentiellement longues. À l’aide de ces données, deux encodeurs sont entraînés conjointement, à savoir un encodeur de texte embarquant du texte alternatif et un encodeur d’image embarquant l’image correspondante dans un espace latent partagé. Les deux encodeurs sont entraînés à l'aide d'une perte contrastive qui encourage les intégrations des images et des textes alternatifs correspondants à être similaires tout en étant différentes des intégrations de toutes les autres images et textes alternatifs.
Une fois entraînée, une telle paire d'encodeurs peut être utilisée de plusieurs manières : elle peut classer un ensemble fixe de concepts visuels par des descriptions textuelles (classification zéro-shot) ; l'intégration peut être utilisée pour récupérer des images à partir de descriptions textuelles, et vice versa ; Cependant, l'encodeur visuel peut également être transféré aux tâches en aval de manière supervisée en affinant un ensemble de données étiquetées ou en entraînant la tête sur une représentation d'encodeur d'image figée. En principe, l'encodeur de texte peut être utilisé comme intégration de texte indépendante. Cependant, il a été signalé que personne n'a mené de recherches approfondies sur cette application. Certaines études ont cité un texte alternatif de mauvaise qualité, ce qui a entraîné de faibles performances de modélisation du langage. l'encodeur de texte.
Des travaux antérieurs ont montré que les encodeurs d'images et de texte peuvent être implémentés avec un modèle de transformateur partagé (également connu sous le nom de modèle à tour unique, ou 1T-CLIP), dans lequel les images sont intégrées à l'aide de l'intégration de correctifs et le texte tokenisé est intégré à l'aide de intégration de mots. À l'exception des intégrations spécifiques à une modalité, tous les paramètres du modèle sont partagés entre les deux modalités. Bien que ce type de partage entraîne généralement une dégradation des performances sur les tâches image/image vers langage, il réduit également de moitié le nombre de paramètres du modèle.
CLIPPO va encore plus loin dans cette idée : la saisie de texte est rendue sur une image vierge et est ensuite entièrement traitée comme une image, y compris l'intégration initiale du patch (voir Figure 1). Grâce à une formation comparative avec des travaux antérieurs, un modèle de transformateur visuel unique est généré, capable de comprendre les images et le texte via une interface visuelle unique, et fournit une solution qui peut être utilisée pour résoudre des tâches de compréhension d'image, de langage d'image et de langage pur.
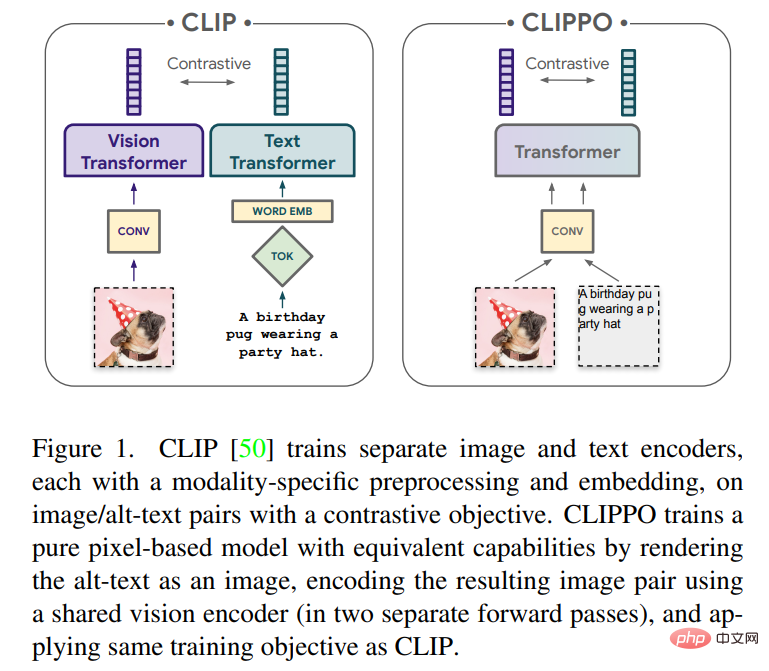
En plus de sa polyvalence multimodale, CLIPPO atténue les difficultés courantes du traitement de texte, à savoir le développement de tokeniseurs et de vocabulaires appropriés. Ceci est particulièrement intéressant dans le contexte de paramètres multilingues massifs, où les encodeurs de texte doivent gérer des dizaines de langues.
On peut constater que CLIPPO formé sur les paires image/texte alternatif fonctionne à égalité avec 1T-CLIP sur les benchmarks d'image publique et de langage d'image, et est en concurrence avec de puissants modèles de langage de base sur le benchmark GLUE. Cependant, étant donné que les textes alternatifs sont de moindre qualité et ne sont généralement pas des phrases grammaticales, l’apprentissage de la compréhension d’une langue à partir des seuls textes alternatifs est fondamentalement limité. Par conséquent, une formation sur le contraste basée sur la langue peut être ajoutée à la pré-formation sur le contraste des images/textes alternatifs. Plus précisément, les paires de phrases consécutives échantillonnées à partir d'un corpus de texte, les paires de phrases traduites dans différentes langues, les paires de phrases post-traduites et les paires de phrases avec des mots manquants doivent être prises en compte.
Compréhension visuelle et visuo-linguistique
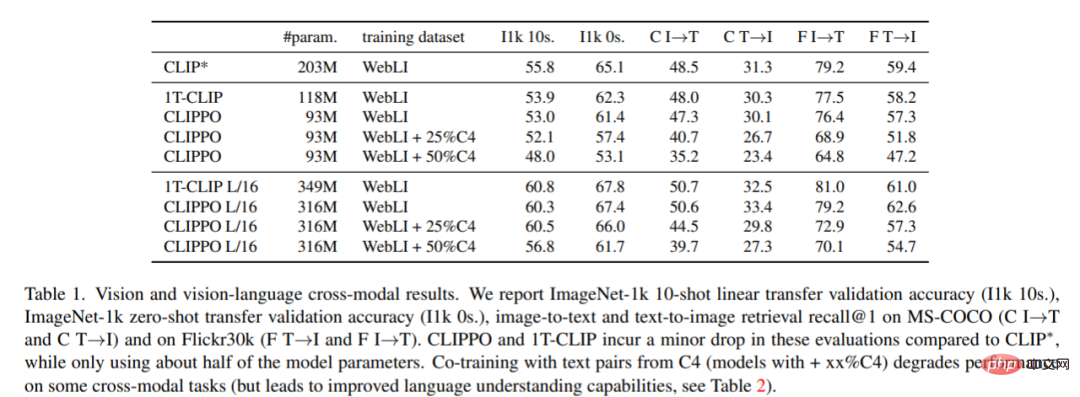
Classification et récupération d'images. Le tableau 1 montre les performances de CLIPPO, et on peut voir que CLIPPO et 1T-CLIP produisent une diminution absolue de 2 à 3 points de pourcentage par rapport à CLIP*.
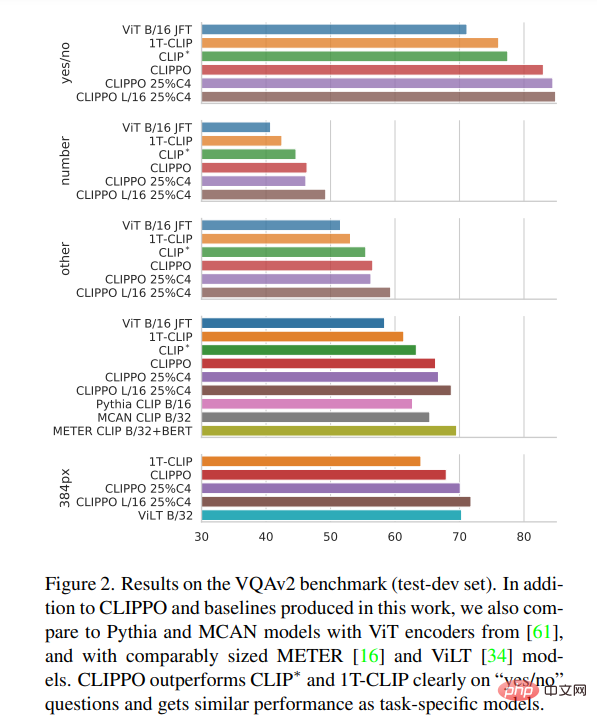
VQA. Les scores VQAv2 du modèle et de la ligne de base sont présentés dans la figure 2. On peut voir que CLIPPO surpasse CLIP∗, 1T-CLIP et ViT-B/16, atteignant un score de 66,3.
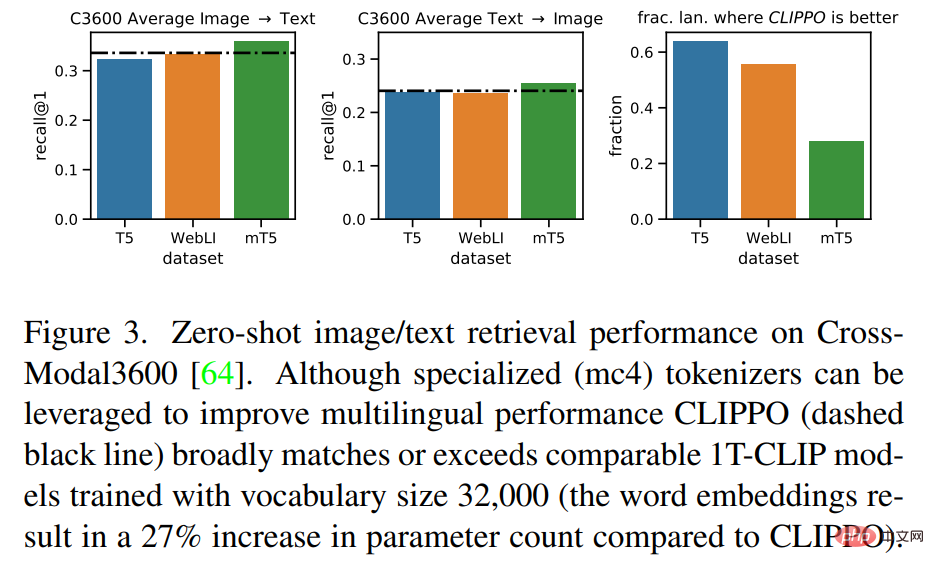
Vision multilingue - Compréhension du langage
La figure 3 montre que CLIPPO atteint des performances de récupération comparables à ces lignes de base. Dans le cas de mT5, l’utilisation de données supplémentaires peut améliorer les performances ; exploiter ces paramètres et données supplémentaires dans un contexte multilingue constituera une orientation future intéressante pour CLIPPO.
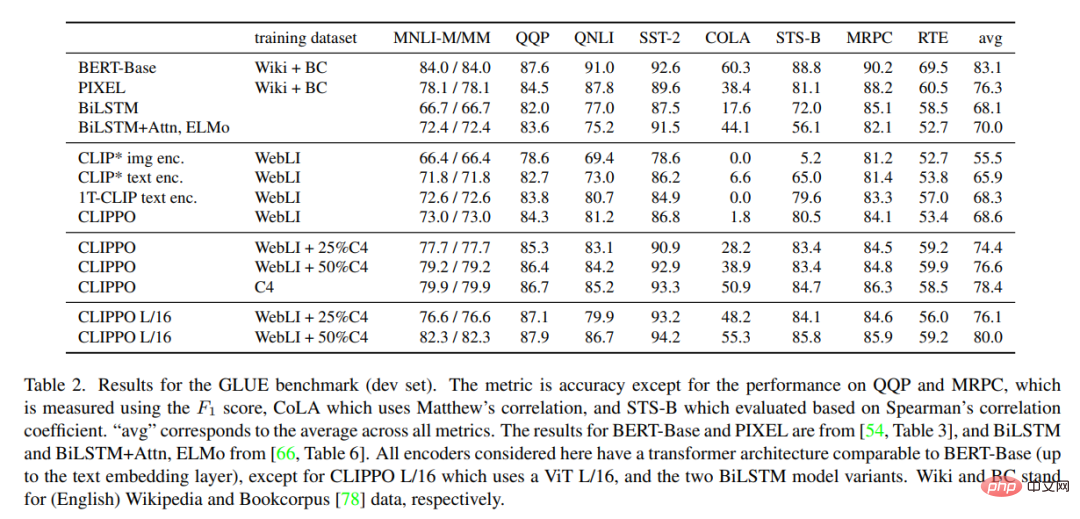
Le tableau 2 montre les résultats du test GLUE pour CLIPPO et la ligne de base. On peut observer que CLIPPO formé sur WebLI est compétitif avec la base de référence BiLSTM+Attn+ELMo qui comporte des intégrations de mots profondes formées sur un grand corpus linguistique. De plus, nous pouvons voir que CLIPPO et 1T-CLIP surpassent les encodeurs de langage formés à l’aide d’une pré-formation standard en vision contrastive du langage.
Pour plus de détails sur la recherche, veuillez vous référer à l'article original.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Quels sont les quatre principaux modèles d'E/S en Java ?
Quels sont les quatre principaux modèles d'E/S en Java ?
 Comment utiliser le stockage cloud
Comment utiliser le stockage cloud
 Quelle est l'adresse du site Internet de Ouyi ?
Quelle est l'adresse du site Internet de Ouyi ?
 Linux ajoute une méthode de source de mise à jour
Linux ajoute une méthode de source de mise à jour
 que signifie la concentration
que signifie la concentration
 html définir la taille de la couleur de la police
html définir la taille de la couleur de la police
 Python est-il front-end ou back-end ?
Python est-il front-end ou back-end ?
 méthode d'ouverture du fichier cdr
méthode d'ouverture du fichier cdr








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



