

Comment fonctionne le plugin ChatGPT

Traducteur | Cui Hao
Reviewer | Chonglou
OpenAI vient d'annoncer le plug-in ChatGPT - un moyen de permettre à ChatGPT d'effectuer des opérations sur le Web. Cela signifie non seulement que ChatGPT peut accéder à Internet et parcourir les derniers contenus et actualités, mais il peut également effectuer certaines opérations en notre nom, telles que faire des courses, réserver des vols, etc.

Le processus de mise en œuvre est très simple :
Le fournisseur de plug-in écrit la spécification de l'API en utilisant la norme OpenAPI. Il s'agit d'une norme qui existe depuis un certain temps et qui est un partisan des outils de documentation API comme Swagger.
Ensuite, compilez cette spécification dans une invite qui explique à ChatGPT comment il utilise l'API pour améliorer les réponses. Imaginez une invite détaillée comprenant une description de chaque point de terminaison disponible.
Enfin, les utilisateurs posent de nouvelles questions. Si ChatGPT a besoin d'informations de l'API, il fera la demande et l'ajoutera au contexte avant de répondre.
Bien que ce processus soit documenté dans la documentation officielle d'OpenAI au moment de la rédaction, l'accès est restreint. Comme je n'y ai pas encore accès, j'ai décidé de mettre en œuvre mon propre mécanisme basé sur ce qui précède. Voici donc ma tentative d'implémenter mon propre mécanisme de plugin ChatGPT.
déclare solennellement : Je ne peut être connu que par le biais d'informations publiquesPlug-in ChatGPT , il n'y a pas d'autre chaîne à connaître Informations supplémentaires . La démonstration dans cet article est d'illustrer le concept de mise en œuvre, ne représente pas à quoi elle ressemblera après la mise en œuvre. Choisissez la spécification de l'API
La première étape consiste à comprendre comment spécifier l'API. OpenAI fournit quelques exemples de spécifications d'API, j'ai donc décidé d'implémenter ma propre solution en utilisant les mêmes entrées et j'ai écrit une spécification simple pour un seul point de terminaison.
J'utilise DummyJSON, une API simple spécifiquement pour les tests, en particulier le point de terminaison "get all to-do". J'ai écrit le fichier YAML suivant comme spécification.
openapi: 3.0.1
info:
title: TODO Plugin
description: A plugin that allows the user to create and manage a TODO list using ChatGPT.
version: 'v1'
servers:
- url: https://dummyjson.com/todos
paths:
/todos:
get:
operationId: getTodos
summary: Get the list of todos
parameters:
- in: query
name: limit
schema:
type: integer
description: Number of todos to return
- in: query
name: skip
schema:
type: integer
description: Number of todos to skip from the beginning of the list
responses:
"200":
description: OK
content:
application/json:
schema:
$ref: '#/components/schemas/getTodosResponse'
components:
schemas:
getTodosResponse:
type: object
properties:
todos:
type: array
items:
type: object
properties:
id:
type: int
todo:
type: string
completed:
type: bool
userId:
type: string
description: The list of todos.
un point de terminaison a deux paramètres : "limit" et "skip". Maintenant, je dois convertir ce qui précède
Après des discussions répétées, j'ai finalement obtenu les résultats suivants :
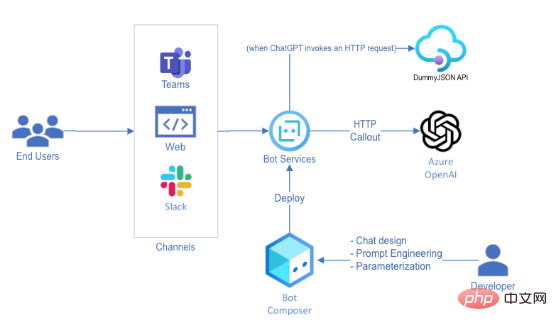
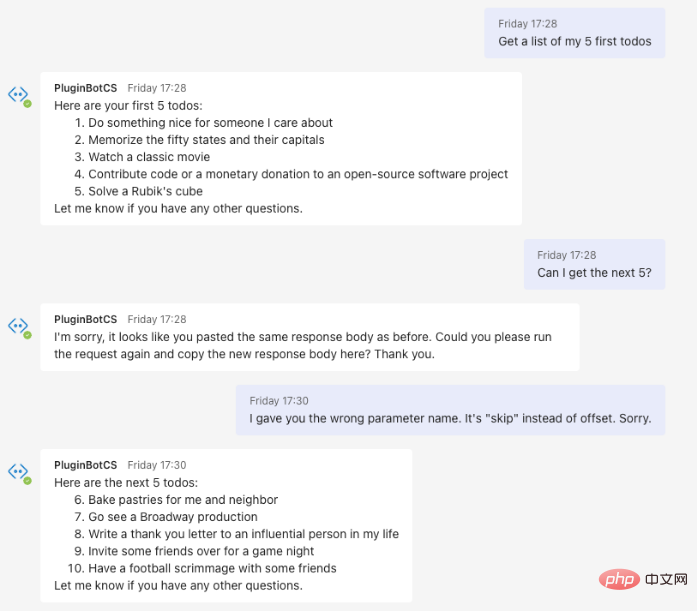
我会告诉ChatGPT以特定的语法回应,并告诉它用户将提供响应。这是因为AI模型不会执行任何API调用——它必须将该操作委托给不同的系统。由于我们无法访问ChatGPT的内部组件,于是要求它将HTTP请求委托给用户。只要隐藏对话转换对最终用户不可见就行了,用户甚至感知不到HTTP请求,就万事大吉了。 ChatGPT是一个通过REST API公开的AI模型。向OpenAI模型发出请求只是端到端聊天机器人体验中的一步。这意味着可以设置模型传递的信息,以及向最终用户显示的信息。 为了使用ChatGPT实现虚拟助手的功能,我使用了Bot Framework Composer,这是一种基于UI的工具,允许我们构建对话体验并将其发布到不同的渠道。以下是高级别的解决方案架构: 我用Bot Framework Composer构建了这个虚拟助手,因为它可以快速部署到多个终端用户渠道,且只需要很少的代码。如果您想要复制这个解决方案,您可能还需要考虑使用Power Virtual Agents,尤其是在生产中使用。 以下是对话流程的构建方式: 1. 用户提问 2.ChatGPT用预格式化的消息进行回复: 3.Azure Bot检测到这种格式,并将请求提交给DummyJSON API,而不会牵扯到最终用户。 4.Azure Bot代表用户向ChatGPT发出新请求,以获取响应正文。 5.ChatGPT格式化响应:"这是你的前5个待办事项:..." 6.Azure Bot回复给用户。 Une chose qui a immédiatement attiré mon attention le produit peut l'empêcher d'appeler d'autres sites Web ou applications en générant du code. Pour cette raison, j'ai appliqué une simple liste d'autorisation de domaine, Cela garantit que toutes les demandes ne peuvent être envoyées qu'à l'API DummyJSON, et une seule à la fois – Ceci assure la sécurité de l'envoi des messages. Ce qui précède est l'idée générale de la définition du plan partie points . Les ci-dessus ont sauté une certaine mise en œuvre jusqu'à ce que l'expérience soit parfaite. Il s'agit d'un outil statistique, alors attendez-vous à quelques essais et erreurs jusqu'à ce que vous trouviez les bons indices. Mais finalement, c'est la conversation que j'ai eue avec la version finale du robot. Plugin ChatGPTimplémentation des fonctionnalitésque la démo rapide ci-dessus C'est plus compliqué. Le but de ce demo est de montrer comment terminer l'intégration Chatgpt de - croyez-moi, je suis aussi familier avec l'implémentation Processus comme tu es très curieux . Cette démo donne à ChatGPT la possibilité d'intégrer HTTP offre possibilités, j'ai hâte de voir ce que la communauté peut lancer Frais Fleurs. En même temps, en tant qu'utilisateurs de technologie, nous avons également un sens des responsabilités : si une invite malveillante permet à Azure Bot de faire une requête à un serveur inconnu, ce sera Que s'est-il passé ? Quels nouveaux vecteurs d’attaque existe-t-il désormais ? Dans le bot que j'ai écrit , une simple liste blanche de domaines est appliquée - est-ce suffisant alors que de nouveaux cas d'utilisation continuent d'émerger ? J'ai également réussi à réécrire la spécification de l'API dans un conseil de suivi : y a-t-il des risques associés à cela ? Il existe de nombreux problèmes de sécurité à prendre en compte liés à AI, et OpenAI en est certainement conscient. Dans l'ensemble, J'ai été profondément impressionné par cette démo. Les possibilités de de ChatGPT sont vraiment infinies et je garderai certainement un œil sur cette fonctionnalité pour voir comment elle évoluera dans les semaines et les mois à venir. J’espère le voir bientôt dans Azure OpenAI aussi ! Introduction au traducteur Titre original : Comment les plugins ChatGPT (pourraient) fonctionner, auteur : Marco Cardoso You are a virtual assistant that helps users with their questions by relying on
information from HTTP APIs. When the user asks a question, you should determine whether
you need to fetch information from the API to properly answer it. If so, you will
request the user to provide all the parameters you need, and then ask them to run the
request for you. When you are ready to ask for a request, you should specify it using
the following syntax:
<http_request>{
"url": "<request URL>",
"method": "<method>",
"body": {<json request body>},
"headers": {<json request headers>}
}</http_request>
Replace in all the necessary values the user provides during the interaction, and do not
use placeholders. The user will then provide the response body, which you may use to
formulate your answer. You should not respond with code, but rather provide an answer
directly.
The following APIs are available to you:
---
<OpenAPI Specification goes here>编排
2.<http_request>{
"url": "https://dummyjson.com/todos?limit=5",
"method": "GET",
"body": "",
"headers": {}
}</http_request>Résultat final
Conclusion
Cui Hao, rédacteur de la communauté 51CTO, architecte senior, a 18 ans d'expérience en développement logiciel et en architecture, et 10 ans d'expérience en architecture distribuée.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 ChatGPT permet désormais aux utilisateurs gratuits de générer des images en utilisant DALL-E 3 avec une limite quotidienne
Aug 09, 2024 pm 09:37 PM
ChatGPT permet désormais aux utilisateurs gratuits de générer des images en utilisant DALL-E 3 avec une limite quotidienne
Aug 09, 2024 pm 09:37 PM
Le DALL-E 3 a été officiellement introduit en septembre 2023 en tant que modèle considérablement amélioré par rapport à son prédécesseur. Il est considéré comme l’un des meilleurs générateurs d’images IA à ce jour, capable de créer des images avec des détails complexes. Cependant, au lancement, c'était exclu
 Bytedance Cutting lance le super abonnement SVIP : 499 yuans pour un abonnement annuel continu, offrant une variété de fonctions d'IA
Jun 28, 2024 am 03:51 AM
Bytedance Cutting lance le super abonnement SVIP : 499 yuans pour un abonnement annuel continu, offrant une variété de fonctions d'IA
Jun 28, 2024 am 03:51 AM
Ce site a rapporté le 27 juin que Jianying est un logiciel de montage vidéo développé par FaceMeng Technology, une filiale de ByteDance. Il s'appuie sur la plateforme Douyin et produit essentiellement du contenu vidéo court pour les utilisateurs de la plateforme. Il est compatible avec iOS, Android et. Windows, MacOS et autres systèmes d'exploitation. Jianying a officiellement annoncé la mise à niveau de son système d'adhésion et a lancé un nouveau SVIP, qui comprend une variété de technologies noires d'IA, telles que la traduction intelligente, la mise en évidence intelligente, l'emballage intelligent, la synthèse humaine numérique, etc. En termes de prix, les frais mensuels pour le clipping SVIP sont de 79 yuans, les frais annuels sont de 599 yuans (attention sur ce site : équivalent à 49,9 yuans par mois), l'abonnement mensuel continu est de 59 yuans par mois et l'abonnement annuel continu est de 59 yuans par mois. est de 499 yuans par an (équivalent à 41,6 yuans par mois) . En outre, le responsable de Cut a également déclaré que afin d'améliorer l'expérience utilisateur, ceux qui se sont abonnés au VIP d'origine
 Assistant de codage d'IA augmenté par le contexte utilisant Rag et Sem-Rag
Jun 10, 2024 am 11:08 AM
Assistant de codage d'IA augmenté par le contexte utilisant Rag et Sem-Rag
Jun 10, 2024 am 11:08 AM
Améliorez la productivité, l’efficacité et la précision des développeurs en intégrant une génération et une mémoire sémantique améliorées par la récupération dans les assistants de codage IA. Traduit de EnhancingAICodingAssistantswithContextUsingRAGandSEM-RAG, auteur JanakiramMSV. Bien que les assistants de programmation d'IA de base soient naturellement utiles, ils ne parviennent souvent pas à fournir les suggestions de code les plus pertinentes et les plus correctes, car ils s'appuient sur une compréhension générale du langage logiciel et des modèles d'écriture de logiciels les plus courants. Le code généré par ces assistants de codage est adapté à la résolution des problèmes qu’ils sont chargés de résoudre, mais n’est souvent pas conforme aux normes, conventions et styles de codage des équipes individuelles. Cela aboutit souvent à des suggestions qui doivent être modifiées ou affinées pour que le code soit accepté dans l'application.
 Le réglage fin peut-il vraiment permettre au LLM d'apprendre de nouvelles choses : l'introduction de nouvelles connaissances peut amener le modèle à produire davantage d'hallucinations
Jun 11, 2024 pm 03:57 PM
Le réglage fin peut-il vraiment permettre au LLM d'apprendre de nouvelles choses : l'introduction de nouvelles connaissances peut amener le modèle à produire davantage d'hallucinations
Jun 11, 2024 pm 03:57 PM
Les grands modèles linguistiques (LLM) sont formés sur d'énormes bases de données textuelles, où ils acquièrent de grandes quantités de connaissances du monde réel. Ces connaissances sont intégrées à leurs paramètres et peuvent ensuite être utilisées en cas de besoin. La connaissance de ces modèles est « réifiée » en fin de formation. À la fin de la pré-formation, le modèle arrête effectivement d’apprendre. Alignez ou affinez le modèle pour apprendre à exploiter ces connaissances et répondre plus naturellement aux questions des utilisateurs. Mais parfois, la connaissance du modèle ne suffit pas, et bien que le modèle puisse accéder à du contenu externe via RAG, il est considéré comme bénéfique de l'adapter à de nouveaux domaines grâce à un réglage fin. Ce réglage fin est effectué à l'aide de la contribution d'annotateurs humains ou d'autres créations LLM, où le modèle rencontre des connaissances supplémentaires du monde réel et les intègre.
 Afin de fournir un nouveau système de référence et d'évaluation de questions-réponses scientifiques et complexes pour les grands modèles, l'UNSW, Argonne, l'Université de Chicago et d'autres institutions ont lancé conjointement le cadre SciQAG.
Jul 25, 2024 am 06:42 AM
Afin de fournir un nouveau système de référence et d'évaluation de questions-réponses scientifiques et complexes pour les grands modèles, l'UNSW, Argonne, l'Université de Chicago et d'autres institutions ont lancé conjointement le cadre SciQAG.
Jul 25, 2024 am 06:42 AM
L'ensemble de données ScienceAI Question Answering (QA) joue un rôle essentiel dans la promotion de la recherche sur le traitement du langage naturel (NLP). Des ensembles de données d'assurance qualité de haute qualité peuvent non seulement être utilisés pour affiner les modèles, mais également évaluer efficacement les capacités des grands modèles linguistiques (LLM), en particulier la capacité à comprendre et à raisonner sur les connaissances scientifiques. Bien qu’il existe actuellement de nombreux ensembles de données scientifiques d’assurance qualité couvrant la médecine, la chimie, la biologie et d’autres domaines, ces ensembles de données présentent encore certaines lacunes. Premièrement, le formulaire de données est relativement simple, et la plupart sont des questions à choix multiples. Elles sont faciles à évaluer, mais limitent la plage de sélection des réponses du modèle et ne peuvent pas tester pleinement la capacité du modèle à répondre aux questions scientifiques. En revanche, les questions et réponses ouvertes
 Les performances de SOTA, la méthode d'IA de prédiction d'affinité protéine-ligand multimodale de Xiamen, combinent pour la première fois des informations sur la surface moléculaire
Jul 17, 2024 pm 06:37 PM
Les performances de SOTA, la méthode d'IA de prédiction d'affinité protéine-ligand multimodale de Xiamen, combinent pour la première fois des informations sur la surface moléculaire
Jul 17, 2024 pm 06:37 PM
Editeur | KX Dans le domaine de la recherche et du développement de médicaments, il est crucial de prédire avec précision et efficacité l'affinité de liaison des protéines et des ligands pour le criblage et l'optimisation des médicaments. Cependant, les études actuelles ne prennent pas en compte le rôle important des informations sur la surface moléculaire dans les interactions protéine-ligand. Sur cette base, des chercheurs de l'Université de Xiamen ont proposé un nouveau cadre d'extraction de caractéristiques multimodales (MFE), qui combine pour la première fois des informations sur la surface des protéines, la structure et la séquence 3D, et utilise un mécanisme d'attention croisée pour comparer différentes modalités. alignement. Les résultats expérimentaux démontrent que cette méthode atteint des performances de pointe dans la prédiction des affinités de liaison protéine-ligand. De plus, les études d’ablation démontrent l’efficacité et la nécessité des informations sur la surface des protéines et de l’alignement des caractéristiques multimodales dans ce cadre. Les recherches connexes commencent par "S
 SK Hynix présentera de nouveaux produits liés à l'IA le 6 août : HBM3E à 12 couches, NAND à 321 hauteurs, etc.
Aug 01, 2024 pm 09:40 PM
SK Hynix présentera de nouveaux produits liés à l'IA le 6 août : HBM3E à 12 couches, NAND à 321 hauteurs, etc.
Aug 01, 2024 pm 09:40 PM
Selon les informations de ce site le 1er août, SK Hynix a publié un article de blog aujourd'hui (1er août), annonçant sa participation au Global Semiconductor Memory Summit FMS2024 qui se tiendra à Santa Clara, Californie, États-Unis, du 6 au 8 août, présentant de nombreuses nouvelles technologies de produit. Introduction au Future Memory and Storage Summit (FutureMemoryandStorage), anciennement Flash Memory Summit (FlashMemorySummit) principalement destiné aux fournisseurs de NAND, dans le contexte de l'attention croissante portée à la technologie de l'intelligence artificielle, cette année a été rebaptisée Future Memory and Storage Summit (FutureMemoryandStorage) pour invitez les fournisseurs de DRAM et de stockage et bien d’autres joueurs. Nouveau produit SK hynix lancé l'année dernière
 Préparant des marchés tels que l'IA, GlobalFoundries acquiert la technologie du nitrure de gallium de Tagore Technology et les équipes associées
Jul 15, 2024 pm 12:21 PM
Préparant des marchés tels que l'IA, GlobalFoundries acquiert la technologie du nitrure de gallium de Tagore Technology et les équipes associées
Jul 15, 2024 pm 12:21 PM
Selon les informations de ce site Web du 5 juillet, GlobalFoundries a publié un communiqué de presse le 1er juillet de cette année, annonçant l'acquisition de la technologie de nitrure de gallium (GaN) et du portefeuille de propriété intellectuelle de Tagore Technology, dans l'espoir d'élargir sa part de marché dans l'automobile et Internet. des objets et des domaines d'application des centres de données d'intelligence artificielle pour explorer une efficacité plus élevée et de meilleures performances. Alors que des technologies telles que l’intelligence artificielle générative (GenerativeAI) continuent de se développer dans le monde numérique, le nitrure de gallium (GaN) est devenu une solution clé pour une gestion durable et efficace de l’énergie, notamment dans les centres de données. Ce site Web citait l'annonce officielle selon laquelle, lors de cette acquisition, l'équipe d'ingénierie de Tagore Technology rejoindrait GF pour développer davantage la technologie du nitrure de gallium. g
