

Exemple d'analyse de table de hachage en Java

1, concept
Dans la structure séquentielle et l'arbre équilibré, il n'y a pas de relation correspondante entre le code clé de l'élément et son emplacement de stockage, donc lors de la recherche d'un élément, vous devez procéder à plusieurs comparaisons du code clé. La complexité temporelle de la recherche séquentielle est O(N). Dans un arbre équilibré, c'est la hauteur de l'arbre, c'est-à-dire O( ). L'efficacité de la recherche dépend du nombre de comparaisons d'éléments au cours du processus de recherche.
Méthode de recherche idéale : vous pouvez obtenir l'élément à rechercher directement à partir du tableau en une seule fois sans aucune comparaison. Si vous construisez une structure de stockage et utilisez une certaine fonction (hashFunc) pour établir une relation de mappage un à un entre l'emplacement de stockage de l'élément et son code clé, vous pouvez alors trouver rapidement l'élément via cette fonction pendant la recherche.
Lors de la saisie de la structure :
Insérer un élément
Selon le code clé de l'élément à insérer, cette fonction calcule l'emplacement de stockage de l'élément Et stockez-le en fonction de cet emplacement
Rechercher des éléments
Effectuer le même calcul sur le code clé de l'élément, utiliser la valeur de fonction obtenue comme emplacement de stockage de l'élément, et appuyez dans la structure Comparez les éléments à cette position. Si les codes clés sont égaux, la recherche est réussie
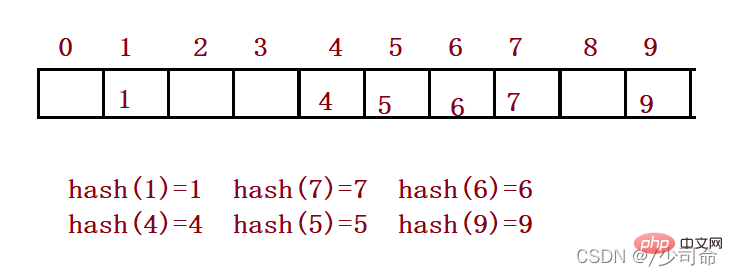
Par exemple : ensemble de données {1, 7, 6, 4, 5, 9. };
Hash La fonction est définie comme : hash(key) = key %capacité est la taille totale de l'espace sous-jacent pour stocker les éléments.
2, conflit-évitement
Tout d'abord, nous devons préciser que parce que la capacité du sous-jacent Le tableau de notre table de hachage est souvent inférieur au nombre réel de mots-clés à stocker, ce qui entraîne un problème. L'apparition de conflits est inévitable, mais ce que nous pouvons faire est de réduire autant que possible le taux de conflits.
3, conception de la fonction de hachage pour éviter les conflits
Fonction de hachage commune
Méthode de personnalisation directe--(couramment utilisée)
# 🎜🎜# Prendre une fonction linéaire du mot-clé comme adresse de hachage : Hash (Clé) = A*Key + B Avantages : Simple et uniforme Inconvénients : Besoin de connaître la distribution des mots-clés à l'avance Scénario d'utilisation : Adapté à une recherche petite et continue case Méthode de reste en laissant la division--(couramment utilisée)Supposons que le nombre d'adresses autorisées dans la table de hachage soit m, choisissez-en une qui n'est pas supérieure à m, mais est le plus proche ou égal à Le nombre premier p de m est utilisé comme diviseur, et selon la fonction de hachage : Hash(key) = key% p(pMéthode de mise au carré--(Comprendre)Supposons que le mot-clé soit 1234, le carré est 1522756, extrayez les 3 chiffres du milieu 227 comme adresse de hachage ; un autre exemple est le mot-clé ; 4321, carré c'est 18671041, extraire les 3 bits du milieu 671 (ou 710) est plus adapté comme méthode de hachage d'adresse au carré : la distribution des mots-clés n'est pas connue, et le nombre de bits n'est pas très grand
#🎜 🎜#4, ajustement du facteur de charge pour éviter les conflits Démonstration approximative de la relation entre le facteur de charge et le taux de conflit
Donc, lorsque le taux de conflits atteint un niveau intolérable, nous devons réduire le taux de conflits déguisés en réduisant le facteur de charge. , On sait que le nombre de mots-clés dans la table de hachage est immuable, alors tout ce que nous pouvons ajuster est la taille du tableau dans la table de hachage. 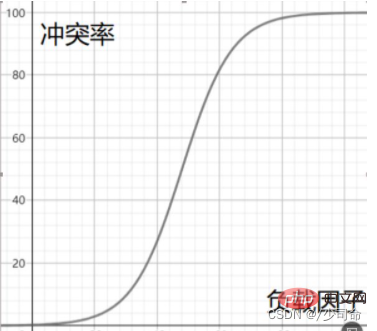
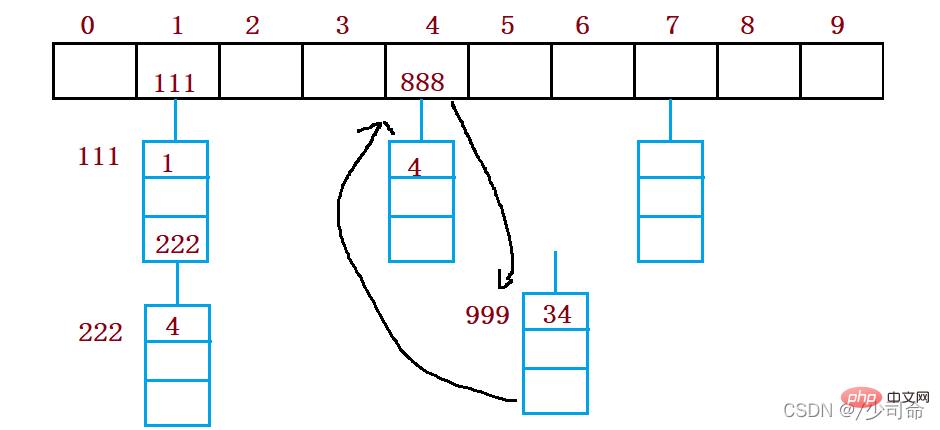
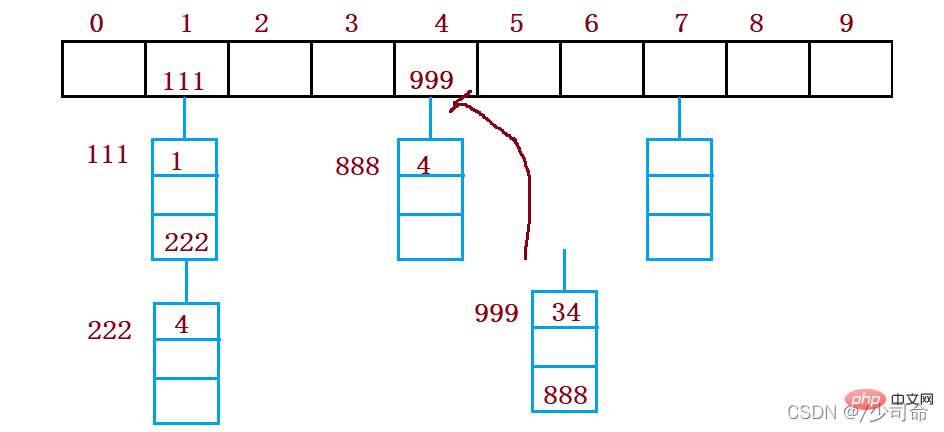
When en utilisant le hachage fermé pour gérer les conflits de hachage, vous ne pouvez pas le faire avec désinvolture. Supprimer les éléments existants dans la table de hachage La suppression directe des éléments affectera la recherche d'autres éléments. Par exemple, si vous supprimez directement l'élément 4, la recherche de 44 peut être affectée. Par conséquent, le sondage linéaire utilise une pseudo-suppression marquée pour supprimer un élément. 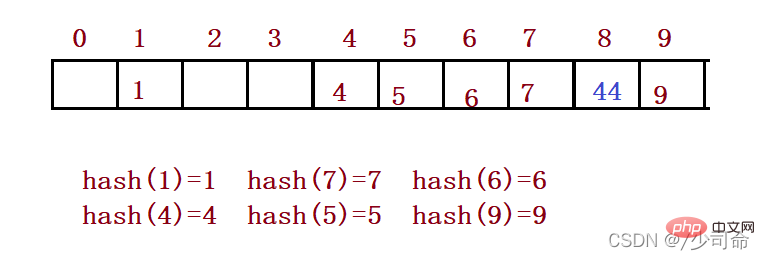
②Deuxième détection
Le défaut de la détection linéaire est que des données contradictoires sont empilées, ce qui est lié à la recherche de la prochaine position vide, car la façon de trouver la position vide est de revenir en arrière. Trouvez-les un par un, donc afin d'éviter ce problème de détection secondaire, la méthode pour trouver la prochaine position vide est : = ( + )% m, ou : = ( - )% m. Parmi eux : i = 1,2,3..., est la position calculée par la fonction de hachage Hash(x) sur le code clé de l'élément, et m est la taille du tableau. Pour la version 2.1, si vous souhaitez insérer 44, un conflit se produit. La situation résolue est la suivante :
La recherche montre que lorsque la longueur de la table est un. nombre premier et la table est chargée. Lorsque le facteur a ne dépasse pas 0,5, de nouvelles entrées peuvent définitivement être insérées, et aucune position ne sera sondée deux fois. Par conséquent, tant qu’il y aura des positions à moitié vides dans la table, il n’y aura pas de problème de table pleine. Lors de la recherche, vous n'avez pas besoin de considérer que la table est pleine, mais lors de l'insertion, vous devez vous assurer que le facteur de charge a de la table ne dépasse pas 0,5. S'il dépasse, vous devez envisager d'augmenter la capacité.
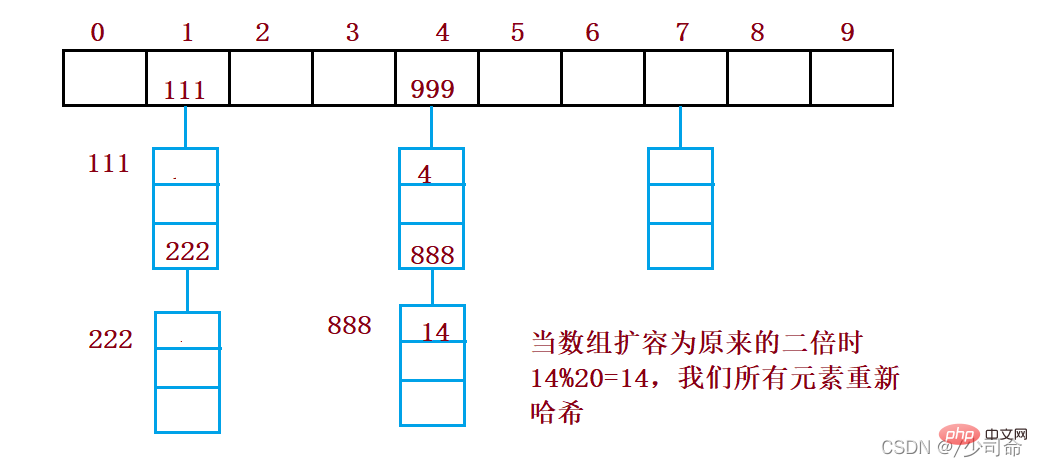
6, conflit-résolution-open hash/hash bucket
La méthode de hachage ouvert est également appelée méthode d'adresse de chaîne (méthode de chaîne ouverte). Tout d'abord, utilisez le code clé. set La fonction de hachage calcule l'adresse de hachage. Les codes clés avec la même adresse appartiennent au même sous-ensemble. Chaque sous-ensemble est appelé un compartiment. Les éléments de chaque compartiment sont liés via une seule liste chaînée. la liste chaînée est stockée dans la table de hachage.

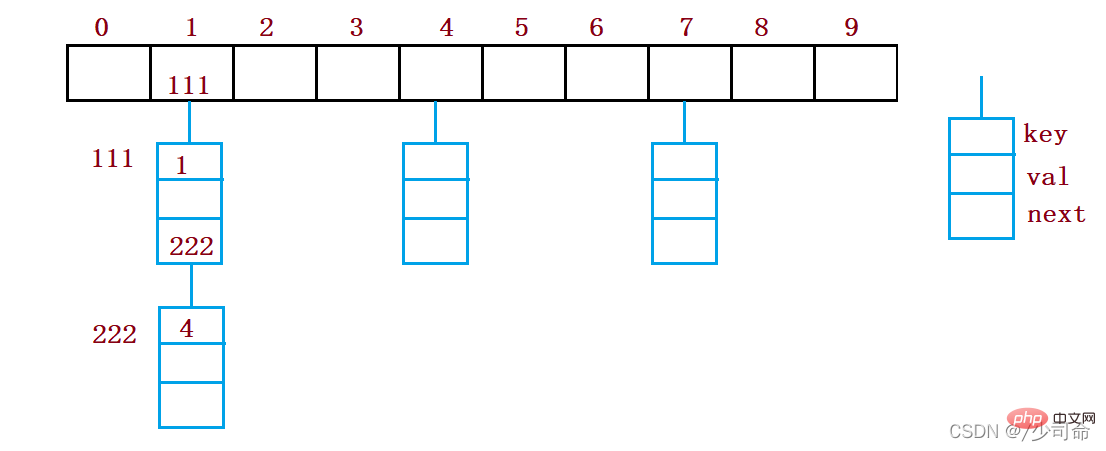
static class Node {
public int key;
public int val;
public Node next;
public Node(int key, int val) {
this.key = key;
this.val = val;
}
}
private Node[] array;
public int usedSize;
public HashBucket() {
this.array = new Node[10];
this.usedSize = 0;
}
#🎜🎜 # # 🎜🎜#
public void put(int key,int val){
int index = key % this.array.length;
Node cur = array[index];
while (cur != null){
if(cur.val == key){
cur.val = val;
return;
}
cur = cur.next;
}
//头插法
Node node = new Node(key,val);
node.next = array[index];
array[index] = node;
this.usedSize++;
if(loadFactor() >= 0.75){
resize();
}
}public int get(int key) {
//以什么方式存储的 那就以什么方式取
int index = key % this.array.length;
Node cur = array[index];
while (cur != null) {
if(cur.key == key) {
return cur.val;
}
cur = cur.next;
}
return -1;//
}
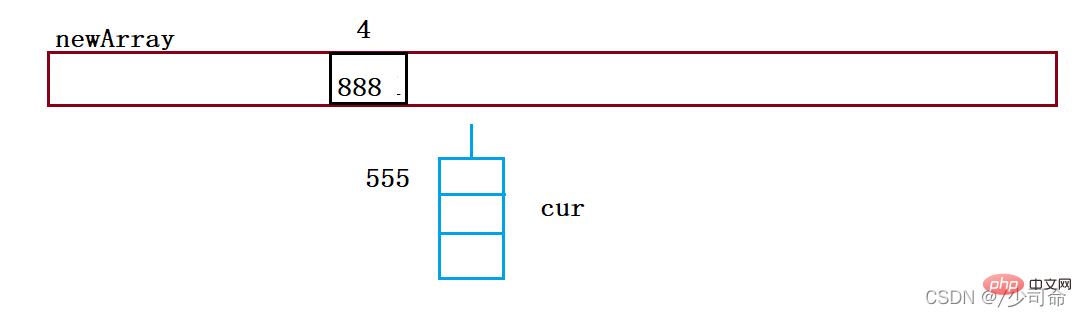
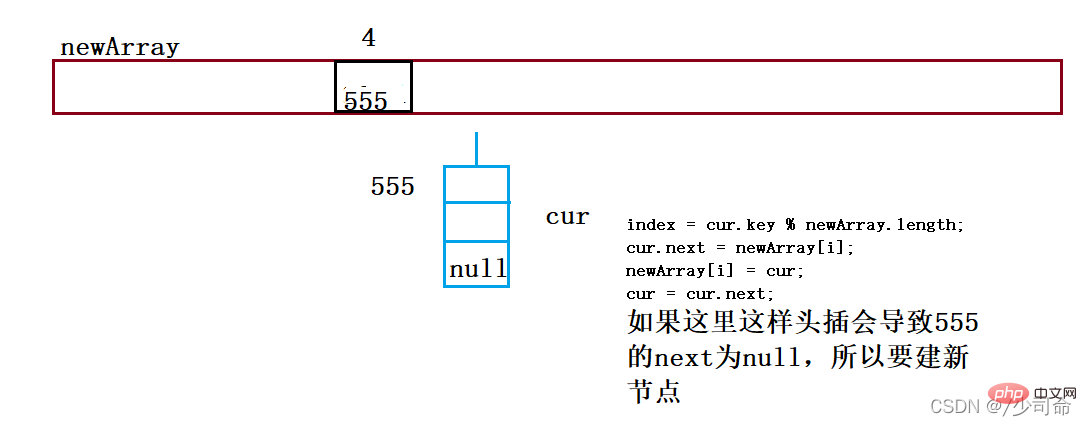
public void resize(){
Node[] newArray = new Node[2*this.array.length];
for (int i = 0; i < this.array.length; i++){
Node cur = array[i];
Node curNext = null;
while (cur != null){
curNext = cur.next;
int index = cur.key % newArray.length;
cur.next = newArray[i];
newArray[i] = cur;
cur = curNext.next;
cur = curNext;
}
}
this.array = newArray;
} 7 , code complet # 🎜🎜 #
7 , code complet # 🎜🎜 # class HashBucket {
static class Node {
public int key;
public int val;
public Node next;
public Node(int key, int val) {
this.key = key;
this.val = val;
}
}
private Node[] array;
public int usedSize;
public HashBucket() {
this.array = new Node[10];
this.usedSize = 0;
}
public void put(int key,int val) {
//1、确定下标
int index = key % this.array.length;
//2、遍历这个下标的链表
Node cur = array[index];
while (cur != null) {
//更新val
if(cur.key == key) {
cur.val = val;
return;
}
cur = cur.next;
}
//3、cur == null 当前数组下标的 链表 没要key
Node node = new Node(key,val);
node.next = array[index];
array[index] = node;
this.usedSize++;
//4、判断 当前 有没有超过负载因子
if(loadFactor() >= 0.75) {
//扩容
resize();
}
}
public int get(int key) {
//以什么方式存储的 那就以什么方式取
int index = key % this.array.length;
Node cur = array[index];
while (cur != null) {
if(cur.key == key) {
return cur.val;
}
cur = cur.next;
}
return -1;//
}
public double loadFactor() {
return this.usedSize*1.0 / this.array.length;
}
public void resize(){
Node[] newArray = new Node[2*this.array.length];
for (int i = 0; i < this.array.length; i++){
Node cur = array[i];
Node curNext = null;
while (cur != null){
curNext = cur.next;
int index = cur.key % newArray.length;
cur.next = newArray[i];
newArray[i] = cur;
cur = curNext.next;
cur = curNext;
}
}
this.array = newArray;
}
}Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

Video Face Swap
Échangez les visages dans n'importe quelle vidéo sans effort grâce à notre outil d'échange de visage AI entièrement gratuit !

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Nombre parfait en Java
Aug 30, 2024 pm 04:28 PM
Nombre parfait en Java
Aug 30, 2024 pm 04:28 PM
Guide du nombre parfait en Java. Nous discutons ici de la définition, comment vérifier le nombre parfait en Java ?, des exemples d'implémentation de code.
 Weka en Java
Aug 30, 2024 pm 04:28 PM
Weka en Java
Aug 30, 2024 pm 04:28 PM
Guide de Weka en Java. Nous discutons ici de l'introduction, de la façon d'utiliser Weka Java, du type de plate-forme et des avantages avec des exemples.
 Numéro de Smith en Java
Aug 30, 2024 pm 04:28 PM
Numéro de Smith en Java
Aug 30, 2024 pm 04:28 PM
Guide du nombre de Smith en Java. Nous discutons ici de la définition, comment vérifier le numéro Smith en Java ? exemple avec implémentation de code.
 Questions d'entretien chez Java Spring
Aug 30, 2024 pm 04:29 PM
Questions d'entretien chez Java Spring
Aug 30, 2024 pm 04:29 PM
Dans cet article, nous avons conservé les questions d'entretien Java Spring les plus posées avec leurs réponses détaillées. Pour que vous puissiez réussir l'interview.
 Break or Return of Java 8 Stream Forach?
Feb 07, 2025 pm 12:09 PM
Break or Return of Java 8 Stream Forach?
Feb 07, 2025 pm 12:09 PM
Java 8 présente l'API Stream, fournissant un moyen puissant et expressif de traiter les collections de données. Cependant, une question courante lors de l'utilisation du flux est: comment se casser ou revenir d'une opération FOREAK? Les boucles traditionnelles permettent une interruption ou un retour précoce, mais la méthode Foreach de Stream ne prend pas directement en charge cette méthode. Cet article expliquera les raisons et explorera des méthodes alternatives pour la mise en œuvre de terminaison prématurée dans les systèmes de traitement de flux. Lire plus approfondie: Améliorations de l'API Java Stream Comprendre le flux Forach La méthode foreach est une opération terminale qui effectue une opération sur chaque élément du flux. Son intention de conception est
 Horodatage à ce jour en Java
Aug 30, 2024 pm 04:28 PM
Horodatage à ce jour en Java
Aug 30, 2024 pm 04:28 PM
Guide de TimeStamp to Date en Java. Ici, nous discutons également de l'introduction et de la façon de convertir l'horodatage en date en Java avec des exemples.
 Programme Java pour trouver le volume de la capsule
Feb 07, 2025 am 11:37 AM
Programme Java pour trouver le volume de la capsule
Feb 07, 2025 am 11:37 AM
Les capsules sont des figures géométriques tridimensionnelles, composées d'un cylindre et d'un hémisphère aux deux extrémités. Le volume de la capsule peut être calculé en ajoutant le volume du cylindre et le volume de l'hémisphère aux deux extrémités. Ce tutoriel discutera de la façon de calculer le volume d'une capsule donnée en Java en utilisant différentes méthodes. Formule de volume de capsule La formule du volume de la capsule est la suivante: Volume de capsule = volume cylindrique volume de deux hémisphères volume dans, R: Le rayon de l'hémisphère. H: La hauteur du cylindre (à l'exclusion de l'hémisphère). Exemple 1 entrer Rayon = 5 unités Hauteur = 10 unités Sortir Volume = 1570,8 unités cubes expliquer Calculer le volume à l'aide de la formule: Volume = π × r2 × h (4
 Créer l'avenir : programmation Java pour les débutants absolus
Oct 13, 2024 pm 01:32 PM
Créer l'avenir : programmation Java pour les débutants absolus
Oct 13, 2024 pm 01:32 PM
Java est un langage de programmation populaire qui peut être appris aussi bien par les développeurs débutants que par les développeurs expérimentés. Ce didacticiel commence par les concepts de base et progresse vers des sujets avancés. Après avoir installé le kit de développement Java, vous pouvez vous entraîner à la programmation en créant un simple programme « Hello, World ! ». Une fois que vous avez compris le code, utilisez l'invite de commande pour compiler et exécuter le programme, et « Hello, World ! » s'affichera sur la console. L'apprentissage de Java commence votre parcours de programmation et, à mesure que votre maîtrise s'approfondit, vous pouvez créer des applications plus complexes.
