

pd.MultiIndex, un index à plusieurs niveaux. Grâce à des index multi-niveaux, nous pouvons exploiter les données de l'ensemble du groupe d'index. Cet article présente principalement 6 façons de créer des index multi-niveaux dans Pandas :
pd.MultiIndex.from_arrays() : les tableaux multidimensionnels sont utilisés comme paramètres, la haute dimensionnalité spécifie les index de haut niveau et la faible dimensionnalité spécifie index de bas niveau.
pd.MultiIndex.from_tuples() : Liste de tuples en argument, chaque tuple spécifiant chaque index (index de dimension haute et basse).
pd.MultiIndex.from_product() : une liste d'objets itérables est utilisée comme paramètre et l'index est créé sur la base du produit cartésien (combinaison par paire d'éléments) de plusieurs éléments d'objet itérables.
pd.MultiIndex.from_frame : généré directement à partir du bloc de données existant
groupby() : obtenu grâce aux statistiques de regroupement de données
pivot_table() : généré en générant un tableau croisé dynamique
In [1]:
import pandas as pd import numpy as np
est généré via un tableau, spécifiant généralement les éléments de la liste :
In [2]:
# 列表元素是字符串和数字
array1 = [["xiaoming","guanyu","zhangfei"],
[22,25,27]
]
m1 = pd.MultiIndex.from_arrays(array1)
m1Out[2]:
MultiIndex([('xiaoming', 22), ( 'guanyu', 25), ('zhangfei', 27)],
)In [ 3]:
type(m1) # 查看数据类型
Affichez le type de données via la fonction type et constatez qu'il s'agit bien de : MultiIndex
Out[3]:
pandas.core.indexes.multi.MultiIndex
Vous pouvez spécifier le nom de chaque niveau lors de la création :
In [4 ] :
# 列表元素全是字符串
array2 = [["xiaoming","guanyu","zhangfei"],
["male","male","female"]
]
m2 = pd.MultiIndex.from_arrays(
array2,
# 指定姓名和性别
names=["name","sex"])
m2Out[4]:
MultiIndex([('xiaoming', 'male'), ( 'guanyu', 'male'), ('zhangfei', 'female')],
names=['name', 'sex'])L'exemple suivant génère trois niveaux d'index et spécifie des noms :
In [5]:
array3 = [["xiaoming","guanyu","zhangfei"],
["male","male","female"],
[22,25,27]
]
m3 = pd.MultiIndex.from_arrays(
array3,
names=["姓名","性别","年龄"])
m3Out[5]:
MultiIndex([('xiaoming', 'male', 22), ( 'guanyu', 'male', 25), ('zhangfei', 'female', 27)],
names=['姓名', '性别', '年龄'])Générez des index multi-niveaux sous forme de tuples :
In [6]:
# 元组的形式
array4 = (("xiaoming","guanyu","zhangfei"),
(22,25,27)
)
m4 = pd.MultiIndex.from_arrays(array4)
m4Out[6]:
MultiIndex([('xiaoming', 22), ( 'guanyu', 25), ('zhangfei', 27)],
)In [7]:
# 元组构成的3层索引
array5 = (("xiaoming","guanyu","zhangfei"),
("male","male","female"),
(22,25,27))
m5 = pd.MultiIndex.from_arrays(array5)
m5Out[7]:
MultiIndex([('xiaoming', 'male', 22), ( 'guanyu', 'male', 25), ('zhangfei', 'female', 27)],
)La couche la plus externe est une liste
Tous les intérieurs sont des tuples
In [8]:
array6 = [("xiaoming","guanyu","zhangfei"),
("male","male","female"),
(18,35,27)
]
# 指定名字
m6 = pd.MultiIndex.from_arrays(array6,names=["姓名","性别","年龄"])
m6Out[8]:
MultiIndex([('xiaoming', 'male', 18), ( 'guanyu', 'male', 35), ('zhangfei', 'female', 27)],
names=['姓名', '性别', '年龄'] # 指定名字
)prend un. liste d'objets itérables en tant que paramètres et crée un index basé sur le produit cartésien (combinaison par paire d'éléments) de plusieurs éléments d'objet itérables.
En Python, nous utilisons la fonction isinstance() pour déterminer si un objet python est itérable :
# 导入 collections 模块的 Iterable 对比对象 from collections import Iterable


À travers l'exemple ci-dessus, nous résumons : les chaînes, listes, ensembles, tuples et dictionnaires courants sont tous itérables Objet
Ce qui suit est un exemple pour illustrer :
In [18]:
names = ["xiaoming","guanyu","zhangfei"]
numbers = [22,25]
m7 = pd.MultiIndex.from_product(
[names, numbers],
names=["name","number"]) # 指定名字
m7Out[18]:
MultiIndex([('xiaoming', 22), ('xiaoming', 25), ( 'guanyu', 22), ( 'guanyu', 25), ('zhangfei', 22), ('zhangfei', 25)],
names=['name', 'number'])In [19]:
# 需要展开成列表形式
strings = list("abc")
lists = [1,2]
m8 = pd.MultiIndex.from_product(
[strings, lists],
names=["alpha","number"])
m8Out[19]:
MultiIndex([('a', 1), ('a', 2), ('b', 1), ('b', 2), ('c', 1), ('c', 2)],
names=['alpha', 'number'])In [20]:
# 使用元组形式
strings = ("a","b","c")
lists = [1,2]
m9 = pd.MultiIndex.from_product(
[strings, lists],
names=["alpha","number"])
m9Out[20]:
MultiIndex([('a', 1), ('a', 2), ('b', 1), ('b', 2), ('c', 1), ('c', 2)],
names=['alpha', 'number'])In [21]:
# 使用range函数
strings = ("a","b","c") # 3个元素
lists = range(3) # 0,1,2 3个元素
m10 = pd.MultiIndex.from_product(
[strings, lists],
names=["alpha","number"])
m10Out[21]:
MultiIndex([('a', 0), ('a', 1), ('a', 2), ('b', 0), ('b', 1), ('b', 2), ('c', 0), ('c', 1), ('c', 2)],
names=['alpha', 'number'])In [22]:
# 使用range函数
strings = ("a","b","c")
list1 = range(3) # 0,1,2
list2 = ["x","y"]
m11 = pd.MultiIndex.from_product(
[strings, list1, list2],
names=["name","l1","l2"]
)
m11 # 总个数 3*3*2=18Le nombre total est ``332=18`:
Out[ 22 ]:
MultiIndex([('a', 0, 'x'), ('a', 0, 'y'), ('a', 1, 'x'), ('a', 1, 'y'), ('a', 2, 'x'), ('a', 2, 'y'), ('b', 0, 'x'), ('b', 0, 'y'), ('b', 1, 'x'), ('b', 1, 'y'), ('b', 2, 'x'), ('b', 2, 'y'), ('c', 0, 'x'), ('c', 0, 'y'), ('c', 1, 'x'), ('c', 1, 'y'), ('c', 2, 'x'), ('c', 2, 'y')],
names=['name', 'l1', 'l2'])Générez directement un index multi-niveaux via le DataFrame existant :
df = pd.DataFrame({"name":["xiaoming","guanyu","zhaoyun"],
"age":[23,39,34],
"sex":["male","male","female"]})
df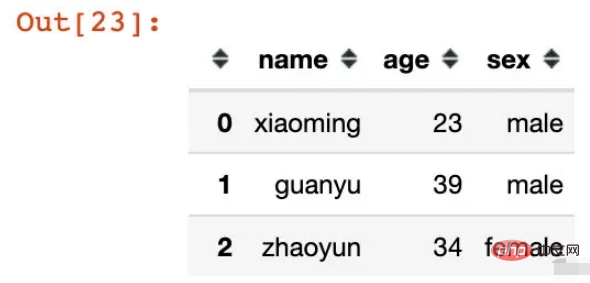
génèrez directement un index multi-niveaux, le nom est le champ de colonne de l'existant trame de données :
In [24]:
pd.MultiIndex.from_frame(df)
Out[24]:
MultiIndex([('xiaoming', 23, 'male'), ( 'guanyu', 39, 'male'), ( 'zhaoyun', 34, 'female')],
names=['name', 'age', 'sex'])Spécifiez le nom via le paramètre noms :
In [25]:
# 可以自定义名字 pd.MultiIndex.from_frame(df,names=["col1","col2","col3"])
Out[25]:
MultiIndex([('xiaoming', 23, 'male'), ( 'guanyu', 39, 'male'), ( 'zhaoyun', 34, 'female')],
names=['col1', 'col2', 'col3'])via la fonction groupby La fonction de regroupement est calculée comme suit :
In [26]:
df1 = pd.DataFrame({"col1":list("ababbc"),
"col2":list("xxyyzz"),
"number1":range(90,96),
"number2":range(100,106)})
df1Out[26]:
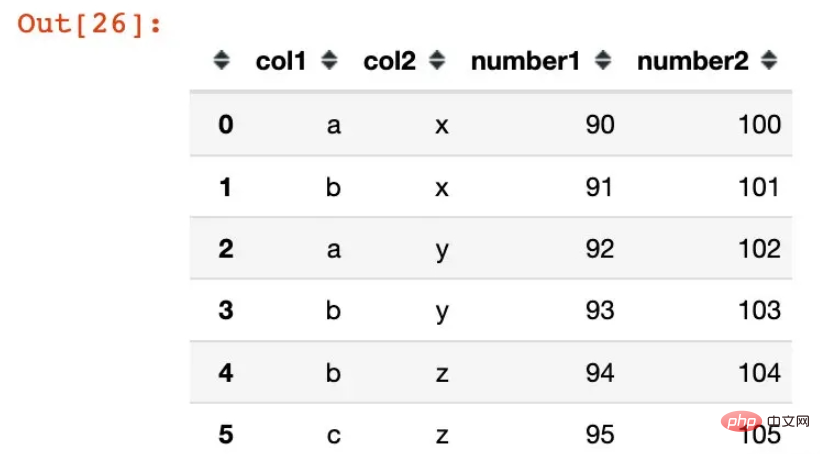
df2 = df1.groupby(["col1","col2"]).agg({"number1":sum,
"number2":np.mean})
df2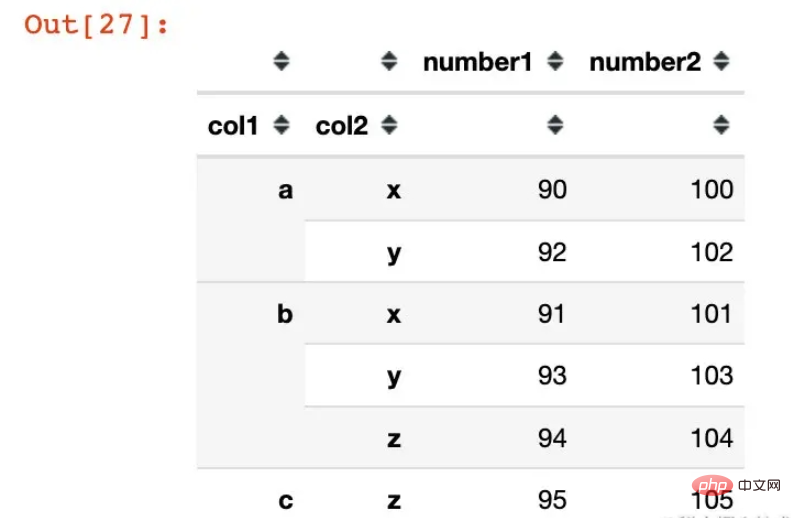
Voir l'index des données :
In [28] :
df2.index
Out[28] :
MultiIndex([('a', 'x'), ('a', 'y'), ('b', 'x'), ('b', 'y'), ('b', 'z'), ('c', 'z')],
names=['col1', 'col2'])est obtenu grâce à la fonction pivot :
In [29]:
df3 = df1.pivot_table(values=["col1","col2"],index=["col1","col2"]) df3

In [30]:
df3.index
Out[30] :
MultiIndex([('a', 'x'), ('a', 'y'), ('b', 'x'), ('b', 'y'), ('b', 'z'), ('c', 'z')],
names=['col1', 'col2'])Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
















![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



