
 Périphériques technologiques
IA
Meta lance un grand modèle open source polyvalent pour aider à faire un pas de plus vers l'unification visuelle
Périphériques technologiques
IA
Meta lance un grand modèle open source polyvalent pour aider à faire un pas de plus vers l'unification visuelle
Meta lance un grand modèle open source polyvalent pour aider à faire un pas de plus vers l'unification visuelle

Après l'open source du modèle SAM qui « divise tout », Meta va de plus en plus loin sur la voie du « modèle visuel de base ».
Cette fois, ils ont open source un ensemble de modèles appelé DINOv2. Ces modèles peuvent produire des représentations visuelles hautes performances qui peuvent être utilisées pour des tâches en aval telles que la classification, la segmentation, la récupération d'images et l'estimation de la profondeur sans réglage fin.
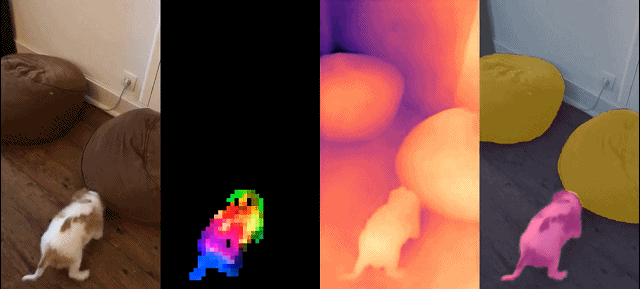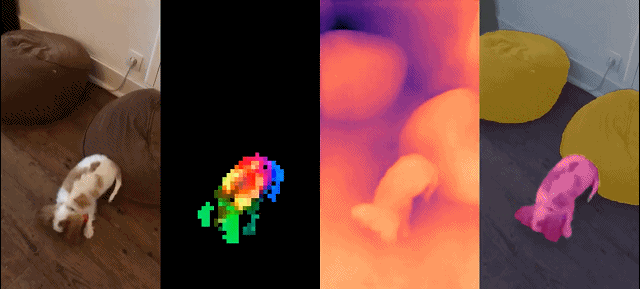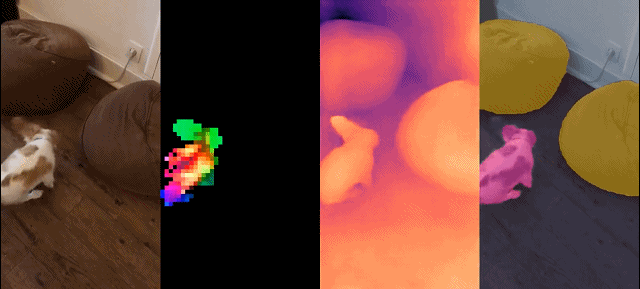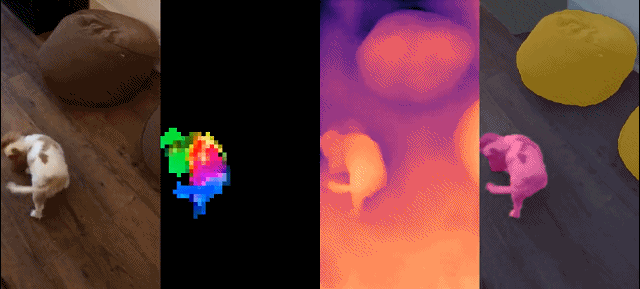
Cet ensemble de modèles présente les caractéristiques suivantes :
- est formé de manière auto-supervisée sans nécessiter une grande quantité de données étiquetées
- peut être utilisé ; comme presque n'importe quel CV L'épine dorsale des tâches qui ne nécessitent pas de réglage fin, telles que la classification d'images, la segmentation, la récupération d'images et l'estimation de la profondeur
- Apprenez les fonctionnalités directement à partir des images sans vous fier aux descriptions textuelles, ce qui permet au modèle de mieux s'améliorer ; comprendre les informations locales ;
- Peut apprendre de n'importe quelle collection d'images
- Une version pré-entraînée de DINOv2 est déjà disponible et est comparable à CLIP et OpenCLIP sur une gamme de tâches.

- Lien papier : https://arxiv.org/pdf/2304.07193.pdf
- Lien du projet : https://dinov2.metademolab.com/
Présentation de l'article
L'apprentissage de représentations pré-entraînées qui ne sont pas spécifiques à une tâche est devenue une norme dans le traitement du langage naturel. Vous pouvez utiliser ces fonctionnalités « telles quelles » (aucun réglage fin requis) et elles fonctionneront nettement mieux sur les tâches en aval que les modèles spécifiques à des tâches. Ce succès est dû à une pré-formation sur de grandes quantités de texte brut utilisant des objectifs auxiliaires, comme la modélisation du langage ou les vecteurs de mots, qui ne nécessitent pas de supervision.
Alors que ce changement de paradigme se produit dans le domaine de la PNL, on s'attend à ce que des modèles « de base » similaires apparaissent dans la vision par ordinateur. Ces modèles doivent générer des fonctionnalités visuelles qui fonctionnent « immédiatement » sur n'importe quelle tâche, que ce soit au niveau de l'image (par exemple, la classification d'images) ou au niveau des pixels (par exemple, la segmentation).
Ces modèles de base ont de grands espoirs de se concentrer sur la pré-formation guidée par texte, c'est-à-dire l'utilisation d'une forme de supervision de texte pour guider la formation des fonctionnalités. Cette forme de pré-formation guidée par texte limite les informations sur l'image qui peuvent être conservées, car la légende ne fait que se rapprocher des informations riches de l'image, et des informations plus fines et complexes au niveau des pixels peuvent ne pas être découvertes avec cette supervision. De plus, ces encodeurs d’images nécessitent des corpus texte-image déjà alignés et n’offrent pas la flexibilité de leurs homologues textuels, c’est-à-dire qu’ils ne peuvent pas apprendre uniquement à partir des données brutes.
Une alternative à la pré-formation guidée par texte est l'apprentissage auto-supervisé, où les fonctionnalités sont apprises uniquement à partir d'images. Ces méthodes sont conceptuellement plus proches des tâches frontales telles que la modélisation du langage et peuvent capturer des informations au niveau de l'image et du pixel. Cependant, malgré leur potentiel d'apprentissage de fonctionnalités générales, la plupart des améliorations en matière d'apprentissage auto-supervisé ont été réalisées dans le contexte d'une pré-formation sur le petit ensemble de données raffinées ImageNet1k. Certains chercheurs ont déployé des efforts pour étendre ces méthodes au-delà d'ImageNet-1k, mais ils se sont concentrés sur des ensembles de données non filtrés, ce qui a souvent entraîné une dégradation significative de la qualité des performances. Cela est dû à un manque de contrôle sur la qualité et la diversité des données, qui sont essentielles à l’obtention de bons résultats.
Dans ce travail, les chercheurs explorent si l'apprentissage auto-supervisé est possible pour apprendre des caractéristiques visuelles générales s'il est pré-entraîné sur une grande quantité de données raffinées. Ils revisitent les méthodes discriminantes auto-supervisées existantes qui apprennent des fonctionnalités au niveau des images et des correctifs, telles que iBOT, et reconsidèrent certains de leurs choix de conception dans des ensembles de données plus vastes. La plupart de nos contributions techniques sont conçues pour stabiliser et accélérer l'apprentissage auto-supervisé discriminant lors de la mise à l'échelle des tailles de modèles et de données. Ces améliorations ont rendu leur méthode environ 2 fois plus rapide et ont nécessité 1/3 de mémoire en moins que des méthodes discriminantes auto-supervisées similaires, leur permettant ainsi de profiter d'une formation plus longue et de lots plus grands.
Concernant les données de pré-formation, ils ont construit un pipeline automatisé pour filtrer et rééquilibrer l'ensemble de données à partir d'une large collection d'images non filtrées. Ceci s'inspire des pipelines utilisés en PNL, où la similarité des données est utilisée à la place des métadonnées externes et où l'annotation manuelle n'est pas requise. Une difficulté majeure lors du traitement d’images est de rééquilibrer les concepts et d’éviter le surajustement dans certains modes dominants. Dans ce travail, la méthode de regroupement naïf peut bien résoudre ce problème, et les chercheurs ont collecté un corpus petit mais diversifié composé de 142 millions d’images pour valider leur méthode.
Enfin, les chercheurs fournissent divers modèles de vision pré-entraînés, appelés DINOv2, sur leurs données en utilisant différentes architectures de transformateur visuel (ViT). Ils ont publié tous les modèles et codes pour recycler DINOv2 sur n'importe quelle donnée. Une fois étendus, ils ont validé la qualité de DINOv2 sur une variété de tests de vision par ordinateur au niveau de l'image et des pixels, comme le montre la figure 2. Nous concluons que la pré-formation auto-supervisée à elle seule est un bon candidat pour l'apprentissage de fonctionnalités gelées transférables, comparable aux meilleurs modèles faiblement supervisés disponibles publiquement.
Traitement des données
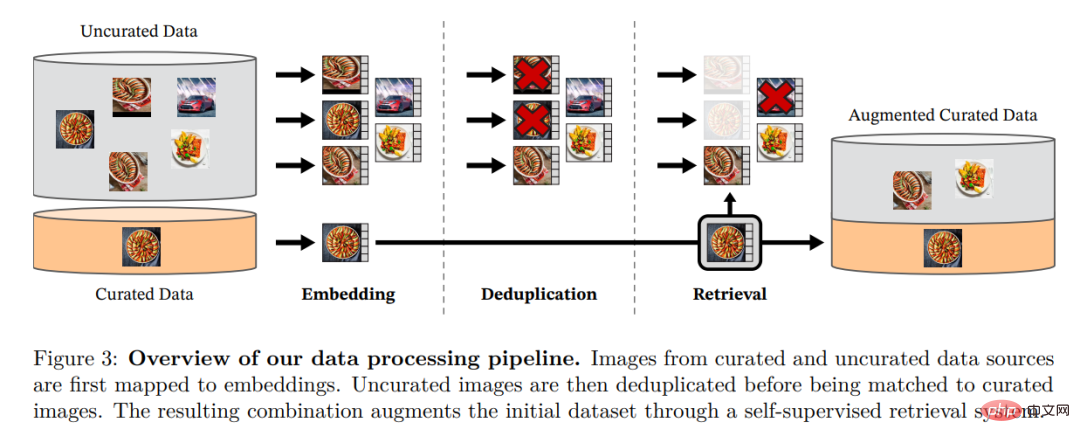
Les chercheurs ont récupéré des images à partir de grandes quantités de données non filtrées qui étaient proches des images dans plusieurs ensembles de données raffinés. -142 millions de données. Dans leur article, ils décrivent les principaux composants du pipeline de données, notamment les sources de données organisées/non filtrées, les étapes de déduplication d'images et les systèmes de récupération. L'ensemble du pipeline ne nécessite aucune métadonnée ni texte et traite directement les images, comme le montre la figure 3. Le lecteur est invité à consulter l'annexe A pour plus de détails sur la méthodologie du modèle. Figure 3 : Aperçu du pipeline de traitement des données. Les images provenant de sources de données raffinées et non raffinées sont d'abord mappées aux intégrations. L'image non raffinée est ensuite dédupliquée avant d'être mise en correspondance avec l'image standard. La combinaison résultante enrichit davantage l’ensemble de données initial grâce à un système de récupération auto-supervisé.
 Pré-formation auto-supervisée discriminante
Pré-formation auto-supervisée discriminante
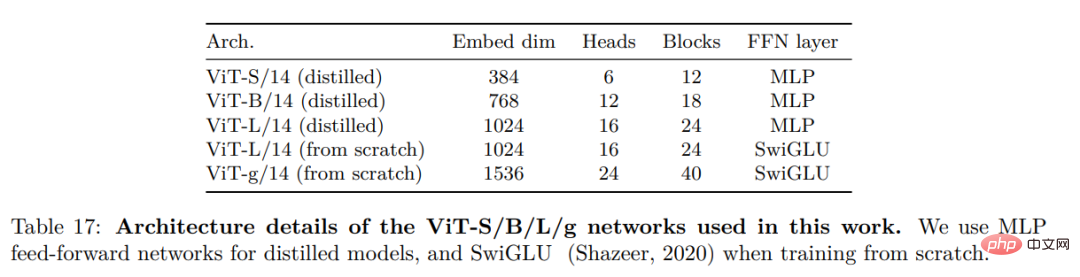
Les chercheurs apprennent grâce à une approche auto-supervisée discriminante Leurs caractéristiques , la méthode peut être vue comme une combinaison de pertes DINO et iBOT et centrée sur SwAV. Ils ont également ajouté un régulariseur pour propager les fonctionnalités et une brève phase de formation haute résolution. Ils ont envisagé plusieurs améliorations pour entraîner le modèle à plus grande échelle. Le modèle est entraîné sur un GPU A100 à l'aide de PyTorch 2.0, et le code peut également être utilisé avec un modèle pré-entraîné pour l'extraction de fonctionnalités. Les détails du modèle se trouvent dans le tableau 17 en annexe. Sur le même matériel, le code DINOv2 n'utilise que 1/3 de la mémoire et s'exécute 2 fois plus vite que l'implémentation iBOT.
Résultats expérimentaux
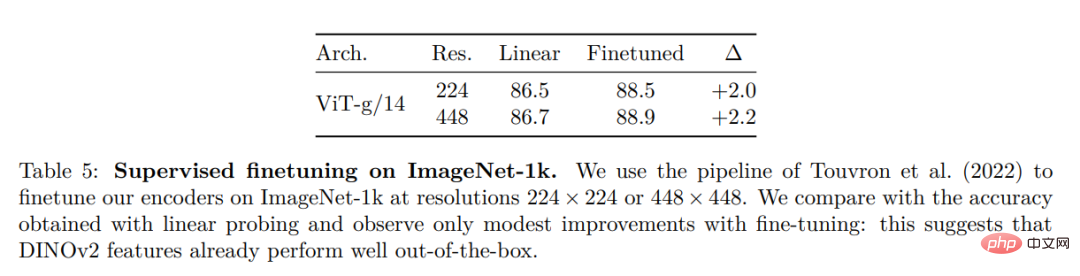
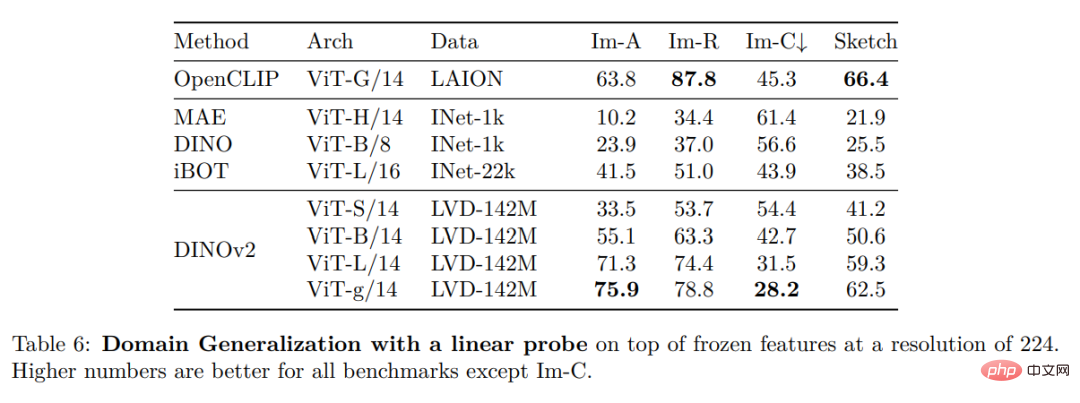
Dans cette section, les chercheurs présenteront l'évaluation empirique du nouveau modèle sur un certain nombre de tâches de compréhension d'images. Ils ont évalué les représentations d'images globales et locales, y compris la reconnaissance au niveau des catégories et des instances, la segmentation sémantique, la prédiction de la profondeur monoculaire et la reconnaissance des actions.ImageNet Catégorie
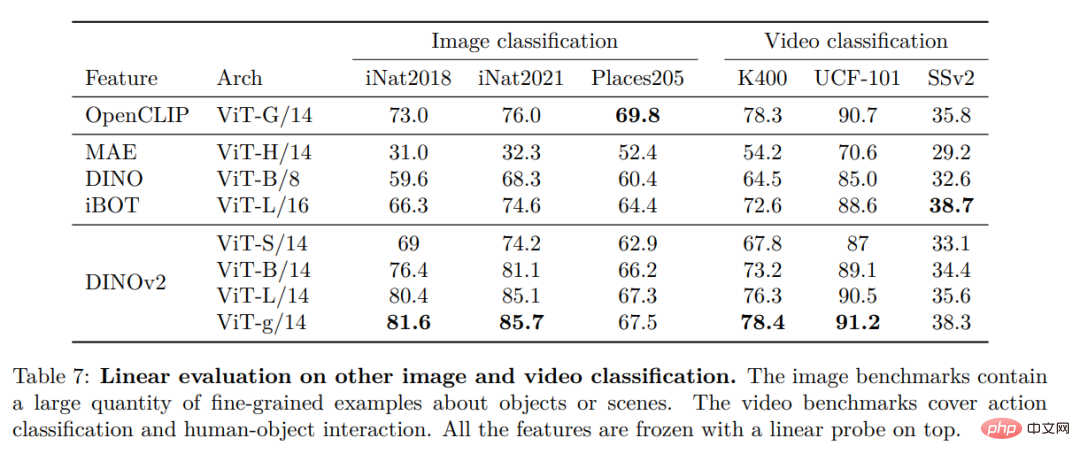
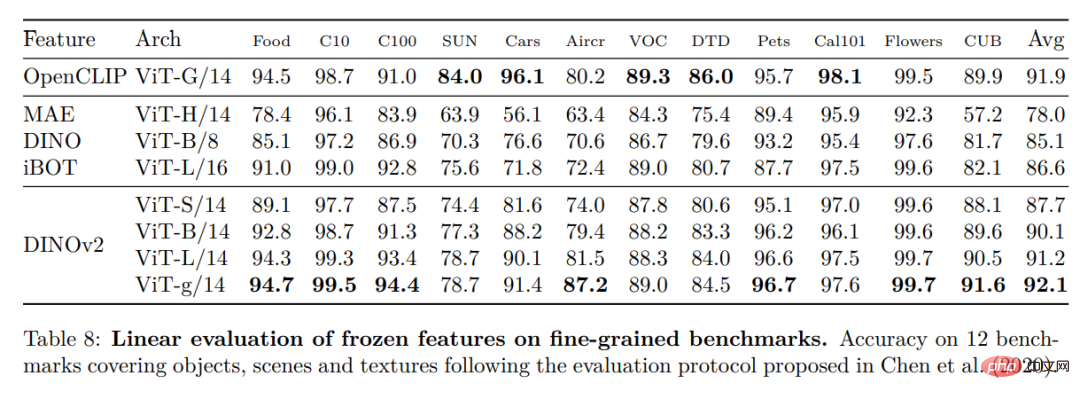
Autres repères de classification d'images et de vidéos
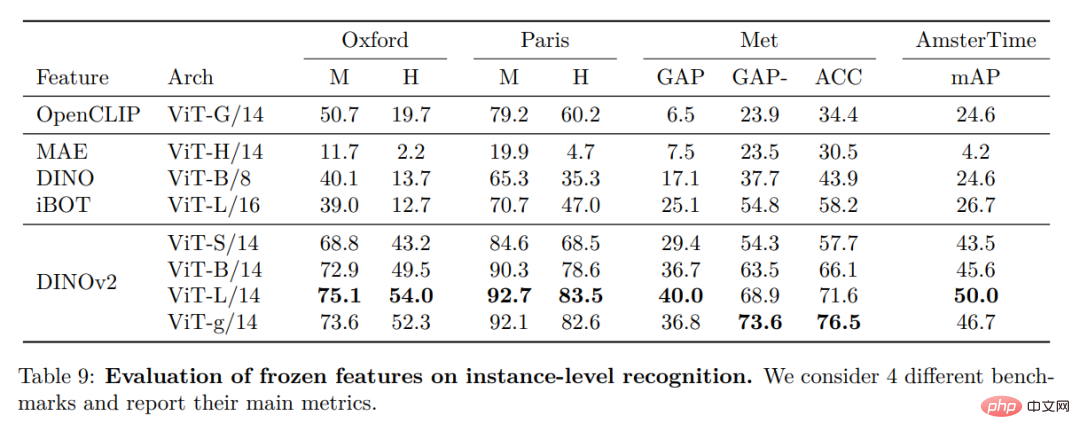
Reconnaissance d'instance
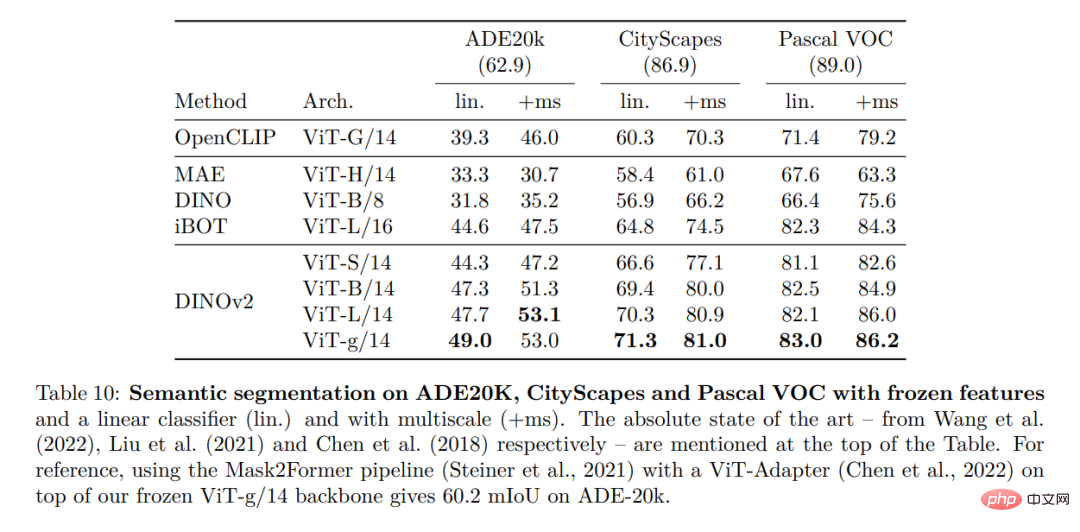
Reconnaissance dense Tâche
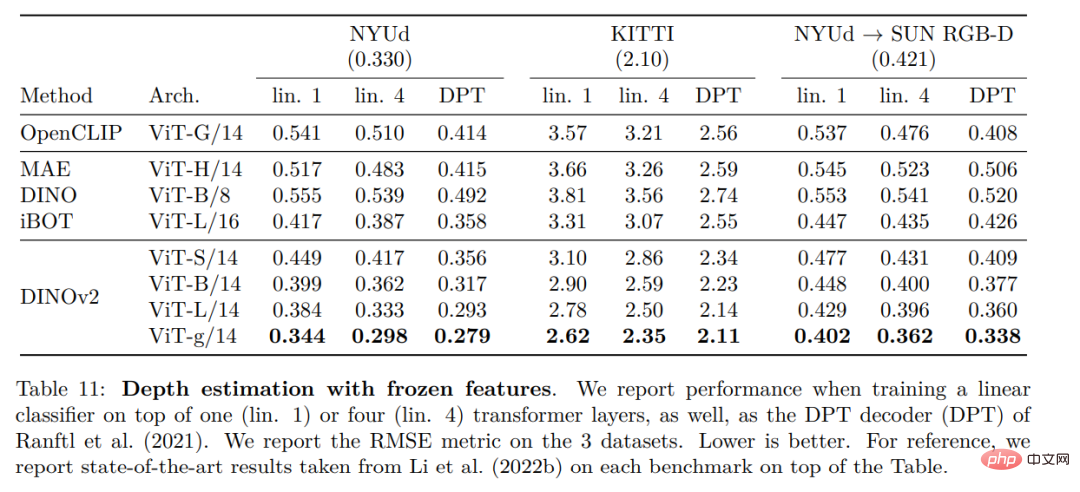
Résultats qualitatifs



Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

Video Face Swap
Échangez les visages dans n'importe quelle vidéo sans effort grâce à notre outil d'échange de visage AI entièrement gratuit !

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)
Sujets chauds



 Comment terminer la mission du couloir d'horreur dans Goat Simulator 3
Feb 25, 2024 pm 03:40 PM
Comment terminer la mission du couloir d'horreur dans Goat Simulator 3
Feb 25, 2024 pm 03:40 PM
Le Terror Corridor est une mission dans Goat Simulator 3. Comment pouvez-vous accomplir cette mission ? Maîtriser les méthodes de dédouanement détaillées et les processus correspondants, et être capable de relever les défis correspondants de cette mission. Ce qui suit vous apportera Goat Simulator 3 Horror Corridor. Guide pour apprendre les informations connexes. Goat Simulator 3 Terror Corridor Guide 1. Tout d’abord, les joueurs doivent se rendre à Silent Hill dans le coin supérieur gauche de la carte. 2. Ici vous pouvez voir une maison avec RESTSTOP écrit sur le toit. Les joueurs doivent faire fonctionner la chèvre pour entrer dans cette maison. 3. Après être entré dans la pièce, nous allons d'abord tout droit, puis tournons à droite. Il y a une porte au bout ici, et nous entrons directement à partir d'ici. 4. Après être entré, nous devons également d'abord avancer, puis tourner à droite. Lorsque nous atteignons la porte ici, la porte sera fermée. Nous devons faire demi-tour et la trouver.
 Correctif : erreur de demande refusée par l'opérateur dans le Planificateur de tâches Windows
Aug 01, 2023 pm 08:43 PM
Correctif : erreur de demande refusée par l'opérateur dans le Planificateur de tâches Windows
Aug 01, 2023 pm 08:43 PM
Pour automatiser les tâches et gérer plusieurs systèmes, un logiciel de planification de mission est un outil précieux dans votre arsenal, notamment en tant qu'administrateur système. Le Planificateur de tâches Windows fait parfaitement le travail, mais dernièrement, de nombreuses personnes ont signalé des erreurs de demande rejetée par l'opérateur. Ce problème existe dans toutes les itérations du système d’exploitation, et même s’il a été largement signalé et couvert, il n’existe pas de solution efficace. Continuez à lire pour découvrir ce qui pourrait réellement fonctionner pour d’autres personnes ! Quelle est la demande dans le Planificateur de tâches 0x800710e0 qui a été refusée par l'opérateur ou l'administrateur ? Le planificateur de tâches permet d'automatiser diverses tâches et applications sans intervention de l'utilisateur. Vous pouvez l'utiliser pour planifier et organiser des applications spécifiques, configurer des notifications automatiques, aider à transmettre des messages, et bien plus encore. il
 Comment réussir la mission Imperial Tomb dans Goat Simulator 3
Mar 11, 2024 pm 01:10 PM
Comment réussir la mission Imperial Tomb dans Goat Simulator 3
Mar 11, 2024 pm 01:10 PM
Goat Simulator 3 est un jeu avec un gameplay de simulation classique, permettant aux joueurs de profiter pleinement du plaisir de la simulation d'action occasionnelle. Parmi elles, la tâche Goat Simulator 3 Imperial Tomb oblige les joueurs à trouver le clocher. Certains joueurs ne savent pas comment faire fonctionner les trois horloges en même temps. Voici le guide de la mission Tomb of the Tomb dans Goat Simulator 3. Le guide de la mission Tomb of the Tomb dans Goat Simulator 3 consiste à faire sonner les cloches ! en ordre. Extension détaillée des étapes 1. Tout d'abord, les joueurs doivent ouvrir la carte et se rendre au cimetière de Wuqiu. 2. Montez ensuite au clocher. Il y aura trois cloches à l'intérieur. 3. Ensuite, du plus grand au plus petit, suivez 222312312 pour vous familiariser avec les tapotements colériques. 4. Après avoir frappé, vous pouvez terminer la mission et ouvrir la porte pour obtenir le sabre laser.
 Comment faire la mission de sauvetage de Steve dans Goat Simulator 3
Feb 25, 2024 pm 03:34 PM
Comment faire la mission de sauvetage de Steve dans Goat Simulator 3
Feb 25, 2024 pm 03:34 PM
Rescue Steve est une tâche unique dans Goat Simulator 3. Que faut-il faire exactement pour la terminer ? Cette tâche est relativement simple, mais nous devons faire attention à ne pas mal comprendre le sens. Ici, nous allons vous amener à sauver Steve dans Goat Simulator. 3 stratégies de mission peuvent vous aider à mieux accomplir les tâches connexes. Goat Simulator 3 Rescue Steve Mission Stratégie 1. Arrivez d’abord à la source chaude dans le coin inférieur droit de la carte. 2. Après être arrivé à la source chaude, vous pouvez déclencher la tâche de sauvetage de Steve. 3. Notez qu'il y a un homme dans la source chaude. Bien qu'il s'appelle Steve, il n'est pas la cible de cette mission. 4. Trouvez un poisson nommé Steve dans cette source chaude et ramenez-le à terre pour accomplir cette tâche.
 Où puis-je trouver les tâches du groupe de fans Douyin ? Le fan club de Douyin va-t-il perdre du niveau ?
Mar 07, 2024 pm 05:25 PM
Où puis-je trouver les tâches du groupe de fans Douyin ? Le fan club de Douyin va-t-il perdre du niveau ?
Mar 07, 2024 pm 05:25 PM
En tant que l’une des plateformes de médias sociaux les plus populaires du moment, TikTok a attiré un grand nombre d’utilisateurs. Sur Douyin, il existe de nombreuses tâches de groupe de fans que les utilisateurs peuvent accomplir pour obtenir certaines récompenses et avantages. Alors, où puis-je trouver les tâches du fan club Douyin ? 1. Où puis-je consulter les tâches du fan club Douyin ? Afin de trouver les tâches du groupe de fans de Douyin, vous devez visiter la page d'accueil personnelle de Douyin. Sur la page d'accueil, vous verrez une option appelée « Fan Club ». Cliquez sur cette option et vous pourrez parcourir les groupes de fans que vous avez rejoints et les tâches associées. Dans la colonne des tâches du fan club, vous verrez différents types de tâches, telles que les likes, les commentaires, le partage, le transfert, etc. Chaque tâche a des récompenses et des exigences correspondantes. De manière générale, après avoir terminé la tâche, vous recevrez une certaine quantité de pièces d'or ou de points d'expérience.
 Au-delà d'ORB-SLAM3 ! SL-SLAM : les scènes de faible luminosité, de gigue importante et de texture faible sont toutes gérées
May 30, 2024 am 09:35 AM
Au-delà d'ORB-SLAM3 ! SL-SLAM : les scènes de faible luminosité, de gigue importante et de texture faible sont toutes gérées
May 30, 2024 am 09:35 AM
Écrit précédemment, nous discutons aujourd'hui de la manière dont la technologie d'apprentissage profond peut améliorer les performances du SLAM (localisation et cartographie simultanées) basé sur la vision dans des environnements complexes. En combinant des méthodes d'extraction de caractéristiques approfondies et de correspondance de profondeur, nous introduisons ici un système SLAM visuel hybride polyvalent conçu pour améliorer l'adaptation dans des scénarios difficiles tels que des conditions de faible luminosité, un éclairage dynamique, des zones faiblement texturées et une gigue importante. Notre système prend en charge plusieurs modes, notamment les configurations étendues monoculaire, stéréo, monoculaire-inertielle et stéréo-inertielle. En outre, il analyse également comment combiner le SLAM visuel avec des méthodes d’apprentissage profond pour inspirer d’autres recherches. Grâce à des expériences approfondies sur des ensembles de données publiques et des données auto-échantillonnées, nous démontrons la supériorité du SL-SLAM en termes de précision de positionnement et de robustesse du suivi.
 Qu'est-ce que le NeRF ? La reconstruction 3D basée sur NeRF est-elle basée sur des voxels ?
Oct 16, 2023 am 11:33 AM
Qu'est-ce que le NeRF ? La reconstruction 3D basée sur NeRF est-elle basée sur des voxels ?
Oct 16, 2023 am 11:33 AM
1 Introduction Les champs de rayonnement neuronal (NeRF) constituent un paradigme relativement nouveau dans le domaine de l'apprentissage profond et de la vision par ordinateur. Cette technologie a été introduite dans l'article ECCV2020 « NeRF : Representing Scenes as Neural Radiation Fields for View Synthesis » (qui a remporté le prix du meilleur article) et est depuis devenue extrêmement populaire, avec près de 800 citations à ce jour [1 ]. Cette approche marque un changement radical dans la manière traditionnelle dont l’apprentissage automatique traite les données 3D. Représentation de la scène du champ de rayonnement neuronal et processus de rendu différenciable : compositer des images en échantillonnant des coordonnées 5D (position et direction de visualisation) le long des rayons de la caméra ; introduire ces positions dans un MLP pour produire des densités de couleur et volumétriques et composer ces valeurs à l'aide de techniques de rendu volumétrique ; ; la fonction de rendu est différentiable, elle peut donc être transmise
 Comment arrêter les mises à jour du processus du Gestionnaire des tâches et supprimer des tâches plus facilement dans Windows 11
Aug 20, 2023 am 11:05 AM
Comment arrêter les mises à jour du processus du Gestionnaire des tâches et supprimer des tâches plus facilement dans Windows 11
Aug 20, 2023 am 11:05 AM
Comment suspendre les mises à jour du processus du Gestionnaire des tâches dans Windows 11 et Windows 10 Appuyez sur CTRL + Touche Fenêtre + Suppr pour ouvrir le Gestionnaire des tâches. Par défaut, le Gestionnaire des tâches ouvrira la fenêtre Processus. Comme vous pouvez le voir ici, toutes les applications se déplacent sans cesse et il peut être difficile de les indiquer lorsque vous souhaitez les sélectionner. Alors, appuyez sur CTRL et maintenez-le enfoncé, cela mettra le gestionnaire de tâches en pause. Vous pouvez toujours sélectionner des applications et même faire défiler vers le bas, mais vous devez maintenir le bouton CTRL enfoncé à tout moment.
