
 Périphériques technologiques
IA
Accélérer le développement et la vérification des véhicules autonomes : examen plus approfondi de la technologie de génération de données synthétiques DRIVE Replicator
Périphériques technologiques
IA
Accélérer le développement et la vérification des véhicules autonomes : examen plus approfondi de la technologie de génération de données synthétiques DRIVE Replicator
Accélérer le développement et la vérification des véhicules autonomes : examen plus approfondi de la technologie de génération de données synthétiques DRIVE Replicator

Lors de la conférence GTC qui s'est tenue en septembre, Gautham Sholingar, chef de produit NVIDIA, a donné une introduction complète aux derniers progrès et développements de NVIDIA en matière de formation aux scénarios à longue traîne au cours de l'année écoulée avec le titre « Génération de données synthétiques : accélérer le développement et la vérification de l'auto-évaluation. Conduite de véhicules" Des expériences pertinentes, en particulier, explorent comment les développeurs peuvent utiliser DRIVE Replicator pour générer divers ensembles de données synthétiques et des étiquettes de données précises sur le terrain afin d'accélérer le développement et la vérification des véhicules autonomes. La conférence était pleine d'informations utiles et a suscité une large attention et de nombreux débats dans l'industrie. Cet article résume et organise l'essentiel de ce partage pour aider chacun à mieux comprendre DRIVE Replicator et la génération de données synthétiques des algorithmes de perception de la conduite autonome.

Figure 1
Au cours de l'année écoulée, NVIDIA a réalisé des progrès positifs dans l'utilisation de DRIVE Replicator pour générer des ensembles de données synthétiques destinés à entraîner des algorithmes de perception de la conduite autonome. La figure 1 montre certains des défis des scénarios à longue traîne que NVIDIA résout actuellement :
- L'image de gauche dans la première rangée, les usagers vulnérables de la route (VRU) près de la caméra de recul. VRU est une classe d'objets importante pour tout algorithme de perception de la conduite autonome. Dans ce cas, nous nous concentrons sur la détection des enfants à proximité de la caméra fisheye de recul. Étant donné que la collecte et l’étiquetage des données dans le monde réel sont assez difficiles, il s’agit d’un cas d’utilisation important en matière de sécurité.
- L'image du milieu dans la première rangée, détection de véhicule accidenté. Les algorithmes de perception de la conduite autonome doivent être exposés à des scènes rares et inhabituelles pour contribuer à fiabiliser les algorithmes de détection d'objets. Il existe très peu de véhicules accidentés dans les ensembles de données du monde réel. DRIVE Replicator aide à former de tels réseaux en aidant les développeurs à créer des événements inattendus (tels que des renversements de voiture) dans diverses conditions environnementales.
- L'image à droite de la première rangée, détection des panneaux de signalisation. Dans d’autres cas, l’étiquetage manuel des données prend du temps et est sujet aux erreurs. DRIVE Replicator aide les développeurs à générer des ensembles de données de centaines de panneaux de signalisation et de feux de circulation dans diverses conditions environnementales et à former rapidement les réseaux pour résoudre divers problèmes du monde réel.
- Enfin, il existe de nombreux objets qui ne sont pas courants en milieu urbain, comme les accessoires de circulation spécifiques et certains types de véhicules. DRIVE Replicator aide les développeurs à augmenter la fréquence de ces objets rares dans les ensembles de données et à augmenter la collecte de données réelles avec des données synthétiques ciblées.
Les fonctions ci-dessus sont implémentées via NVIDIA DRIVE Replicator.
Comprenez DRIVE Replicator et son écosystème associé
DRIVE Replicator fait partie de la suite d'outils DRIVE Sim et peut être utilisé pour la simulation de conduite autonome.
DRIVE Sim est un simulateur de voiture autonome de pointe construit par NVIDIA basé sur Omniverse, qui peut effectuer une simulation de capteur physiquement précise à grande échelle. Les développeurs peuvent exécuter des simulations reproductibles sur un poste de travail, puis passer en mode batch dans le centre de données ou le cloud. DRIVE Sim est une plate-forme modulaire construite sur de puissants standards ouverts tels que USD, permettant aux utilisateurs d'introduire leurs propres fonctionnalités via les extensions Omniverse.
DRIVE Sim comprend plusieurs applications telles que DRIVE Replicator. DRIVE Replicator fournit principalement une série de fonctions axées sur la génération de données synthétiques pour la formation et la vérification des algorithmes des véhicules autonomes. DRIVE Sim et DRIVE Constellation prennent également en charge la simulation de conduite autonome complète à tous les niveaux, y compris les tests logiciels dans la boucle, matériel dans la boucle et d'autres tests de simulation dans la boucle (modèles, usines, humains, et plus).
La différence entre DRIVE Sim et les outils de simulation de conduite autonome traditionnels est que lors de la création d'ensembles de données synthétiques, les outils de simulation de conduite autonome traditionnels sont souvent combinés avec des moteurs de jeux professionnels pour restituer des scènes suffisamment réalistes. Cependant, pour la simulation de conduite autonome, cela est loin d’être suffisant et des exigences fondamentales, notamment la précision physique, la répétabilité et l’échelle, doivent être satisfaites.

Figure 2
Avant de présenter davantage DRIVE Replicator, permettez-moi d'abord de vous présenter plusieurs concepts connexes (Figure 2), en particulier Omniverse, pour vous aider à mieux comprendre la technologie sous-jacente liée à la prise en charge de DRIVE Replicator.
Tout d’abord, découvrez Omniverse, le moteur de simulation à grande échelle de NVIDIA. Omniverse est construit sur USD (Universal Scene Description, un langage universel extensible pour décrire des mondes virtuels) développé par Pixar. USD est une source unique de données de valeur de vérité pour l'ensemble de la simulation et tous les aspects de la simulation (y compris les capteurs et l'environnement 3D). Ces scènes entièrement construites via USD permettent aux développeurs d'avoir un accès hiérarchique à chaque élément de la simulation et de générer divers éléments. Les données pour la génération ultérieure jettent les bases d’un ensemble de données synthétiques spécialisées.
Deuxièmement, Omniverse fournit des effets de traçage de rayons en temps réel pour prendre en charge les capteurs dans DRIVE Sim. RTX est l'une des avancées importantes de NVIDIA en matière de graphisme informatique, tirant parti d'une API de traçage de rayons optimisée qui se concentre sur la précision physique pour garantir un comportement complexe des caméras, du lidar, du radar à ondes millimétriques et des capteurs à ultrasons tels que les réflexions multiples, les effets de trajets multiples, l'obturateur roulant et distorsion de l'objectif) sont modélisés nativement.
Troisièmement, NVIDIA Omniverse est une plate-forme ouverte facilement évolutive conçue pour la collaboration virtuelle et la simulation en temps réel physiquement précise. Elle peut exécuter des flux de travail dans le cloud ou dans un centre de données, et peut réaliser un rendu et une génération de données parallèles multi-GPU et nœuds.
Quatrièmement, Omniverse et DRIVE Sim adoptent des conceptions ouvertes et modulaires, et un vaste écosystème de partenaires s'est formé autour de cette plateforme. Ces partenaires peuvent fournir des matériaux 3D, des capteurs, des modèles de véhicules et de trafic, des outils de vérification, etc.
Cinquièmement, le cœur de la collaboration Omniverse est que Nucleus dispose de fonctions de stockage de données et de contrôle d'accès, et il peut servir d'entrepôt de contenu centralisé. plusieurs utilisateurs. , prend en charge DRIVE Sim pour découpler l'exécution du contenu, améliorer le contrôle de version et créer un point de référence unique pour toutes les séquences, scènes et métadonnées.
DRIVE Sim est une plateforme NVIDIA adopte une démarche de coopération écologique pour construire cette plateforme, permettant aux partenaires de contribuer à cette plateforme universelle. À l'heure actuelle, DRIVE Sim a établi un vaste écosystème de partenaires, couvrant les actifs 3D, les modèles de capteurs environnementaux, la vérification et d'autres domaines. Avec le SDK DRIVE Sim, les partenaires peuvent facilement introduire leurs propres modèles de capteurs, de trafic et de dynamique des véhicules et étendre leurs capacités de simulation de base. Les développeurs peuvent non seulement écrire des extensions dans Omniverse et ajouter facilement de nouvelles fonctionnalités, mais également profiter des avantages du développement sur une plate-forme commune. Omniverse a mis en relation plusieurs partenaires clés qui fournissent un travail important lié au flux de développement de la conduite autonome.
Comment utiliser DRIVE Replicator pour générer des ensembles de données synthétiques et des données de vérité terrain
Ensuite, j'expliquerai comment le contenu ci-dessus est combiné et les cinq principales étapes de travail de DRIVE Replicator pour générer des données synthétiques (Figure 3) : Contenu ( Contenu) — DRIVE Sim Runtime — Détection — Randomisation — Écrivains de données.
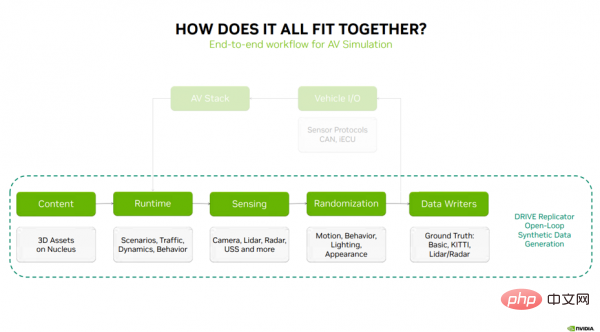
Figure 3
La première étape du processus de simulation est le contenu et les matériaux 3D stockés sur le serveur Nucleus. Ces actifs sont transmis à DRIVE Sim Runtime, la technologie de base pour l'exécution de scénarios, de modèles de trafic, de dynamique et de comportement des véhicules. DRIVE Sim Runtime peut être utilisé avec des caméras basées sur le traçage de rayons RTX, un lidar, un radar à ondes millimétriques et la technologie de perception de l'USS. L'étape suivante consiste à introduire de la variété dans les données grâce à la randomisation du mouvement, du comportement, de l'éclairage et de l'apparence. Pour la simulation en boucle fermée, l'étape suivante consiste à connecter la simulation à la pile de conduite autonome via les E/S du véhicule, qui se composent généralement de protocoles de capteurs, de messages CAN et d'un ECU virtuel (qui envoie des informations importantes à la pile de conduite autonome pour boucler la boucle).
Pour la génération de données synthétiques, il s'agit d'un processus en boucle ouverte qui envoie des données aléatoires de capteurs aux rédacteurs de données, qui peuvent produire une vérité terrain pour la formation des algorithmes de perception de la conduite autonome Label. Les étapes ci-dessus représentent un flux de travail complet pour la génération de données synthétiques.
- Contenu (contenu)
Comme mentionné ci-dessus, la première étape du processus de simulation est le contenu et les matériaux 3D stockés sur le serveur Nucleus. D'où vient ce contenu ? Comment l'obtenir ? Quelles sont les normes ou exigences ?
Au cours des dernières années, NVIDIA a travaillé avec plusieurs partenaires de contenu pour créer un vaste écosystème de fournisseurs d'actifs 3D, comprenant des véhicules, des accessoires, des piétons, de la végétation et des environnements 3D, prêts à être utilisés dans DRIVE Sim.
Une chose à noter est que même si vous obtenez ces actifs sur le marché, cela ne signifie pas que vous pouvez commencer le travail de simulation. Vous devez également préparer ces actifs pour la simulation, et c'est là qu'intervient SimReady.
Une partie importante de l'expansion consiste à travailler avec les fournisseurs d'actifs 3D et à leur fournir les outils dont ils ont besoin pour garantir que certaines conventions, dénominations, gréements d'actifs sont respectés lors de l'importation d'actifs dans DRIVE Sim, étiquettes sémantiques et propriétés physiques.
SimReady Studio aide les fournisseurs de contenu à convertir leurs actifs existants en actifs USD prêts pour la simulation qui peuvent être chargés sur DRIVE Sim, y compris des environnements 3D, des actifs dynamiques et des accessoires statiques.
Alors, qu'est-ce que SimReady ? Vous pouvez le considérer comme un convertisseur qui permet de garantir que les ressources 3D dans DRIVE Sim et Replicator sont prêtes à prendre en charge les flux de travail de simulation de bout en bout. SimReady comporte plusieurs éléments clés, notamment : 🎜🎜#Des balises sémantiques et une ontologie bien définie pour annoter chaque élément d'un actif. Ceci est essentiel pour générer des étiquettes de vérité terrain pour la perception ;
- prend en charge la physique et la dynamique des corps rigides, rendant les ensembles de données générés réalistes et comblant le fossé entre la simulation et la réalité d'un point de vue cinématique. Gap ;#🎜🎜 #
- L'étape suivante consiste à s'assurer que l'actif respecte des matériaux et des conventions de dénomination spécifiques pour garantir qu'il est prêt pour le traçage de rayons RTX et génère des données pour les capteurs actifs tels que le lidar, le radar à ondes millimétriques et les capteurs à ultrasons ;# 🎜🎜# Un autre aspect courant consiste à configurer des actifs 3D pour permettre les changements d'éclairage, l'actionnement des portes, le fonctionnement des piétons et bien plus encore ;
- La dernière partie concerne les capteurs haute fidélité en temps réel. Optimisation des performances de simulations.
- Sur la base de ce qui précède, examinons le processus d'utilisation de SimReady studio pour obtenir des actifs pouvant être utilisés dans DRIVE Sim.
- Supposons que le processus commence par l'achat d'actifs sur le marché 3D. La première étape consiste à importer cet actif dans SimReady Studio. Cela peut également être effectué en masse ou en important par lots plusieurs actifs pour terminer cette étape.
- Après l'importation, les noms de matériaux de ces actifs de contenu seront mis à jour, et leurs propriétés matérielles seront également mises à jour, en s'étendant pour inclure des attributs tels que la réflectivité et la rugosité.
Retour à la création de contenu de simulation de véhicule autonome, à partir de données cartographiques Là Il existe généralement plusieurs façons de créer un environnement (voir Figure 4). Une option consiste à utiliser l'outil Roadrunner de MathWorks pour créer un environnement 3D sur une carte NVIDIA DRIVE ouverte (plateforme cartographique multimodale). Le résultat de cette étape, ainsi que les informations de carte sémantique, la synchronisation du signal, etc., sont ensuite transférés vers SimReady Studio, où l'environnement 3D peut être converti en un actif USD pouvant être chargé sur DRIVE Sim. 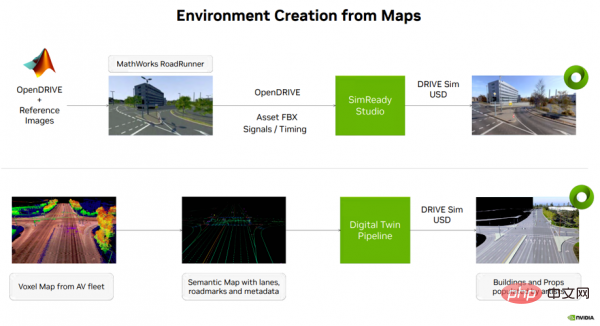
Les deux types d'environnements USD ci-dessus seront utilisés pour prendre en charge les tests de simulation de bout en bout (E2E) des véhicules autonomes et les flux de travail de génération de données synthétiques.
DRIVE Sim Runtime Ensuite, je présenterai la deuxième étape de la simulation-DRIVE Sim Runtime, qui constitue la base de toutes les fonctionnalités que nous utilisons dans DRIVE Replicator pour générer des ensembles de données synthétiques.- Sensing(Perception)
- Randomisation
- Data Writers Writer)
DRIVE Sim Runtime est un composant ouvert, modulaire et extensible. Qu’est-ce que cela signifie en pratique (voir Figure 5) ?
Tout d'abord, il est construit sur des scènes, où les développeurs peuvent définir la position, le mouvement et l'interaction spécifiques des objets dans la scène. Ces scénarios peuvent être définis en Python ou à l'aide de l'interface utilisateur de l'éditeur de scénarios et enregistrés pour une utilisation ultérieure.
Deuxièmement, il prend en charge l'intégration avec des packages de dynamique de véhicule personnalisés via le SDK DRIVE Sim, soit en tant qu'étape du processus, soit en co-simulation avec DRIVE Sim 2.0.
Troisièmement, le modèle de trafic. DRIVE Sim dispose d'une interface de modèle de véhicule riche et, avec l'aide du Runtime, les développeurs peuvent introduire leur propre dynamique de véhicule ou configurer des modèles de trafic existants basés sur des règles.
Quatrièmement, le système d'action, qui contient une riche bibliothèque d'actions prédéfinies (comme les changements de voie), des déclencheurs temporels pouvant être utilisés pour créer des scènes d'interactions entre différents objets, etc.
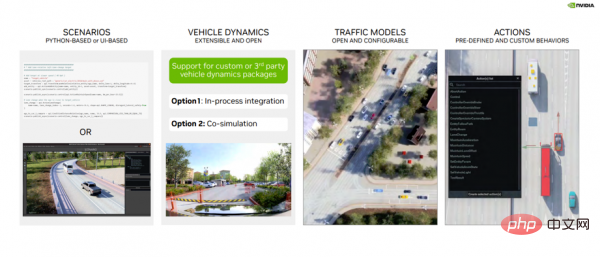
Image 5
Revoyons brièvement le contenu précédent ici : Processus de simulation, chapitre 5 Dans la première étape, le contenu 3D prêt pour la simulation et les matériaux convertis par SimReady sont stockés sur le serveur Nucleus. Dans la deuxième étape, ces matériaux sont transmis à DRIVE Sim Runtime, qui constitue la technologie de base pour l'exécution de scénarios, de modèles de trafic, de dynamique et de comportement des véhicules, jetant ainsi les bases de toutes les fonctions ultérieures permettant de générer des ensembles de données synthétiques.
Avant de générer des données, des capteurs doivent être utilisés pour configurer la cible véhicule d'essai. À l'aide de l'outil Ego Configurator, les développeurs peuvent sélectionner des véhicules spécifiques et les ajouter à la scène.
De plus, les développeurs peuvent également déplacer des véhicules dans la scène et ajouter des capteurs aux véhicules. L'outil de configuration Ego prend en charge les capteurs universels et Hyperion 8.
Après avoir ajouté le capteur au véhicule, les développeurs peuvent également modifier des paramètres tels que le champ de vision, la résolution, le nom du capteur et configurer intuitivement les emplacements des capteurs sur le véhicule.
Les utilisateurs peuvent également visualiser des aperçus du POV du capteur et visualiser le champ de vision dans un environnement 3D avant de créer des scènes de génération de données.
Cet outil peut aider les développeurs à prototyper rapidement différentes configurations et à visualiser la couverture obtenue par les tâches de détection.
Présentons maintenant brièvement la quatrième étape du processus de simulation, la randomisation du domaine, comment introduisez de la variété dans vos données en randomisant les mouvements, les comportements, l'éclairage et l'apparence.
Cela impliquera une autre façon de créer des scènes, en utilisant Python. L'API Python de DRIVE Replicator permet aux développeurs d'interroger la carte NVIDIA DRIVE ouverte et de placer une gamme d'actifs statiques et dynamiques en fonction du contexte. Certains randomiseurs se concentreront sur la manière de téléporter un véhicule autonome d'un point à un autre, sur la manière de générer des objets autour du véhicule autonome et de générer différents ensembles de données synthétiques à partir de ceux-ci. Ces opérations qui semblent complexes sont faciles à réaliser car l'utilisateur a un contrôle direct sur la scène USD et tous les objets de cet environnement.
Une autre étape importante lors de la création d'ensembles de données synthétiques pour la formation est la possibilité d'introduire des changements dans l'apparence de la scène 3D. Les puissantes fonctions de l'USD ont également été mentionnées ci-dessus. Par exemple, les scénarios créés via l'USD permettent aux développeurs d'avoir un accès hiérarchique à chaque élément de la simulation. L'API de SimReady utilise USD pour configurer rapidement des fonctionnalités dans une scène.
Regardons un exemple (voir Figure 6) : la surface de la route est un peu humide, mais lorsque nous définissons différents paramètres, le niveau d'humidité de la surface de la route changera. Nous pouvons apporter des modifications similaires à des aspects tels que l’azimut solaire et l’altitude solaire pour produire des ensembles de données réalistes dans diverses conditions environnementales.
Un autre point fort est la possibilité d'activer les modifications d'éclairage et d'apparence, qui sont toutes disponibles via l'API SimReady et USD. L'un des principaux avantages de DRIVE Sim est le flux de travail des capteurs RTX. Il prend en charge une variété de capteurs (voir Figure 7), y compris des modèles génériques et disponibles dans le commerce pour les caméras, le lidar, le radar conventionnel et l'USS. De plus, DRIVE Sim fournit une prise en charge complète de la suite de capteurs NVIDIA DRIVE Hyperion, permettant aux utilisateurs de commencer le travail de développement et de validation d'algorithmes dans un environnement virtuel.
De plus, DRIVE Sim dispose d'un SDK puissant et polyvalent qui permet aux partenaires d'utiliser l'API de traçage de rayons de NVIDIA pour implémenter des modèles de capteurs complexes tout en protégeant leur adresse IP et leurs algorithmes propriétaires. Cet écosystème s'est développé au fil des années et NVIDIA travaille avec des partenaires pour intégrer de nouveaux types de capteurs, tels que le radar d'imagerie, le lidar FMCW, etc., dans DRIVE Sim.

Image 7
Maintenant, l'accent est mis sur la génération de données de vérité terrain et sur la manière de visualiser ces informations. Cela implique la dernière étape du processus de simulation, le rédacteur de données. Dans ce processus, les données randomisées des capteurs sont envoyées aux rédacteurs de données, qui génèrent des étiquettes de vérité terrain utilisées pour entraîner des algorithmes de perception de la conduite autonome.
Le rédacteur de données est un script Python utilisé pour générer les étiquettes de vérité terrain nécessaires à la formation des algorithmes de perception de la conduite autonome.
NVIDIA DRIVE Replicator est livré avec des rédacteurs de modèles tels que le rédacteur de base et le rédacteur KITTI.
L'écrivain de base couvre un large éventail d'étiquettes de données du monde réel, y compris les classes d'objets, les cadres de délimitation serrés et lâches en 2D et 3D, les masques sémantiques et d'instance, la sortie de profondeur, les occlusions, l'attente normale.
De même, il existe des rédacteurs lidar/radar normaux qui peuvent être utilisés pour exporter des données de nuages de points laser vers des tableaux numpy, ou vers toute personnalisation pertinente avec des cadres de délimitation, la sémantique et les étiquettes d'objet. Définissez le format.
Ces rédacteurs fournissent des exemples permettant aux développeurs de configurer leurs propres rédacteurs en fonction de formats de balisage personnalisés et d'étendre leurs efforts de génération de données.
Enfin, j'aimerais vous présenter un logiciel passionnant, Replicator Insight, créé par l'équipe Omniverse.
Replicator Insight est une application autonome construite sur Omniverse Kit qui peut être utilisée pour inspecter des ensembles de données synthétiques rendus et superposer diverses étiquettes de vérité terrain pour la formation.
Replicator Insight prend en charge tous les cas d'utilisation de génération de données synthétiques, notamment DRIVE, Isaac et Omniverse Replicator.
Regardons un exemple (voir Figure 8) : les utilisateurs peuvent charger les données générées par DRIVE Replicator dans cet outil de visualisation et activer et désactiver différentes étiquettes de vérité pour différentes catégories d'objets dans la scène.
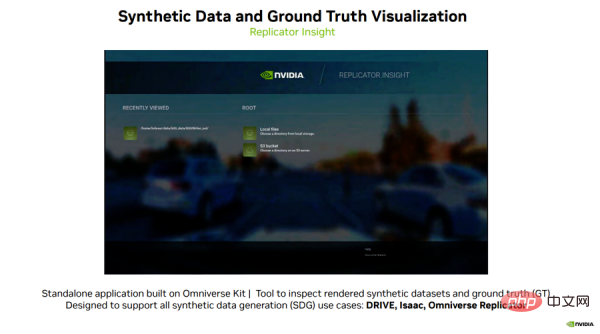
Photo 8
Avec cet outil de visualisation, les utilisateurs peuvent lire des vidéos et trier Les ensembles de données peuvent même être comparés entre différentes vues telles que les données de profondeur et RVB.
Les utilisateurs peuvent également modifier des paramètres tels que la fréquence d'images de lecture et la plage de profondeur, ou visualiser rapidement des ensembles de données avant un entraînement en voiture autonome.
Cela aidera les développeurs à comprendre facilement les nouveaux types d'étiquettes de vérité terrain et à analyser des ensembles de données complexes.
Dans l'ensemble, il s'agit d'un outil puissant qui permet aux utilisateurs d'acquérir de nouvelles informations à chaque fois qu'ils examinent des données, qu'elles soient réelles ou synthétiques.
Résumé
Ce qui précède résume le dernier développement de DRIVE Replicator au cours de l'année écoulée et explique comment les développeurs peuvent utiliser DRIVE Replicator pour générer divers ensembles de données synthétiques et mettre à la terre avec précision- des étiquettes de données de vérité pour accélérer le développement et la vérification des véhicules autonomes. NVIDIA a réalisé des progrès passionnants dans la génération d'ensembles de données de capteurs de haute qualité pour une variété de cas d'utilisation réels, et nous sommes impatients de poursuivre la communication avec vous !
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Comment résoudre le problème de la longue traîne dans les scénarios de conduite autonome ?
Jun 02, 2024 pm 02:44 PM
Comment résoudre le problème de la longue traîne dans les scénarios de conduite autonome ?
Jun 02, 2024 pm 02:44 PM
Hier, lors de l'entretien, on m'a demandé si j'avais posé des questions à longue traîne, j'ai donc pensé faire un bref résumé. Le problème à longue traîne de la conduite autonome fait référence aux cas extrêmes dans les véhicules autonomes, c'est-à-dire à des scénarios possibles avec une faible probabilité d'occurrence. Le problème perçu de la longue traîne est l’une des principales raisons limitant actuellement le domaine de conception opérationnelle des véhicules autonomes intelligents à véhicule unique. L'architecture sous-jacente et la plupart des problèmes techniques de la conduite autonome ont été résolus, et les 5 % restants des problèmes à longue traîne sont progressivement devenus la clé pour restreindre le développement de la conduite autonome. Ces problèmes incluent une variété de scénarios fragmentés, de situations extrêmes et de comportements humains imprévisibles. La « longue traîne » des scénarios limites dans la conduite autonome fait référence aux cas limites dans les véhicules autonomes (VA). Les cas limites sont des scénarios possibles avec une faible probabilité d'occurrence. ces événements rares
 CLIP-BEVFormer : superviser explicitement la structure BEVFormer pour améliorer les performances de détection à longue traîne
Mar 26, 2024 pm 12:41 PM
CLIP-BEVFormer : superviser explicitement la structure BEVFormer pour améliorer les performances de détection à longue traîne
Mar 26, 2024 pm 12:41 PM
Écrit ci-dessus et compréhension personnelle de l'auteur : À l'heure actuelle, dans l'ensemble du système de conduite autonome, le module de perception joue un rôle essentiel. Le véhicule autonome roulant sur la route ne peut obtenir des résultats de perception précis que via le module de perception en aval. dans le système de conduite autonome, prend des jugements et des décisions comportementales opportuns et corrects. Actuellement, les voitures dotées de fonctions de conduite autonome sont généralement équipées d'une variété de capteurs d'informations de données, notamment des capteurs de caméra à vision panoramique, des capteurs lidar et des capteurs radar à ondes millimétriques pour collecter des informations selon différentes modalités afin d'accomplir des tâches de perception précises. L'algorithme de perception BEV basé sur la vision pure est privilégié par l'industrie en raison de son faible coût matériel et de sa facilité de déploiement, et ses résultats peuvent être facilement appliqués à diverses tâches en aval.
 Cet article vous suffit pour en savoir plus sur la conduite autonome et la prédiction de trajectoire !
Feb 28, 2024 pm 07:20 PM
Cet article vous suffit pour en savoir plus sur la conduite autonome et la prédiction de trajectoire !
Feb 28, 2024 pm 07:20 PM
La prédiction de trajectoire joue un rôle important dans la conduite autonome. La prédiction de trajectoire de conduite autonome fait référence à la prédiction de la trajectoire de conduite future du véhicule en analysant diverses données pendant le processus de conduite du véhicule. En tant que module central de la conduite autonome, la qualité de la prédiction de trajectoire est cruciale pour le contrôle de la planification en aval. La tâche de prédiction de trajectoire dispose d'une riche pile technologique et nécessite une connaissance de la perception dynamique/statique de la conduite autonome, des cartes de haute précision, des lignes de voie, des compétences en architecture de réseau neuronal (CNN&GNN&Transformer), etc. Il est très difficile de démarrer ! De nombreux fans espèrent se lancer dans la prédiction de trajectoire le plus tôt possible et éviter les pièges. Aujourd'hui, je vais faire le point sur quelques problèmes courants et des méthodes d'apprentissage introductives pour la prédiction de trajectoire ! Connaissances introductives 1. Existe-t-il un ordre d'entrée pour les épreuves de prévisualisation ? R : Regardez d’abord l’enquête, p
 Implémentation d'algorithmes d'apprentissage automatique en C++ : défis et solutions courants
Jun 03, 2024 pm 01:25 PM
Implémentation d'algorithmes d'apprentissage automatique en C++ : défis et solutions courants
Jun 03, 2024 pm 01:25 PM
Les défis courants rencontrés par les algorithmes d'apprentissage automatique en C++ incluent la gestion de la mémoire, le multithread, l'optimisation des performances et la maintenabilité. Les solutions incluent l'utilisation de pointeurs intelligents, de bibliothèques de threads modernes, d'instructions SIMD et de bibliothèques tierces, ainsi que le respect des directives de style de codage et l'utilisation d'outils d'automatisation. Des cas pratiques montrent comment utiliser la bibliothèque Eigen pour implémenter des algorithmes de régression linéaire, gérer efficacement la mémoire et utiliser des opérations matricielles hautes performances.
 NuScenes dernier SOTA SparseAD : les requêtes clairsemées contribuent à une conduite autonome efficace de bout en bout !
Apr 17, 2024 pm 06:22 PM
NuScenes dernier SOTA SparseAD : les requêtes clairsemées contribuent à une conduite autonome efficace de bout en bout !
Apr 17, 2024 pm 06:22 PM
Écrit à l'avant et point de départ Le paradigme de bout en bout utilise un cadre unifié pour réaliser plusieurs tâches dans les systèmes de conduite autonome. Malgré la simplicité et la clarté de ce paradigme, les performances des méthodes de conduite autonome de bout en bout sur les sous-tâches sont encore loin derrière les méthodes à tâche unique. Dans le même temps, les fonctionnalités de vue à vol d'oiseau (BEV) denses, largement utilisées dans les méthodes de bout en bout précédentes, rendent difficile l'adaptation à davantage de modalités ou de tâches. Un paradigme de conduite autonome de bout en bout (SparseAD) centré sur la recherche clairsemée est proposé ici, dans lequel la recherche clairsemée représente entièrement l'ensemble du scénario de conduite, y compris l'espace, le temps et les tâches, sans aucune représentation BEV dense. Plus précisément, une architecture clairsemée unifiée est conçue pour la connaissance des tâches, notamment la détection, le suivi et la cartographie en ligne. De plus, lourd
 Parlons des systèmes de conduite autonome de bout en bout et de nouvelle génération, ainsi que de quelques malentendus sur la conduite autonome de bout en bout ?
Apr 15, 2024 pm 04:13 PM
Parlons des systèmes de conduite autonome de bout en bout et de nouvelle génération, ainsi que de quelques malentendus sur la conduite autonome de bout en bout ?
Apr 15, 2024 pm 04:13 PM
Au cours du mois dernier, pour des raisons bien connues, j'ai eu des échanges très intensifs avec divers professeurs et camarades de classe du secteur. Un sujet inévitable dans l'échange est naturellement le populaire Tesla FSDV12 de bout en bout. Je voudrais profiter de cette occasion pour trier certaines de mes pensées et opinions en ce moment pour votre référence et votre discussion. Comment définir un système de conduite autonome de bout en bout et quels problèmes devraient être résolus de bout en bout ? Selon la définition la plus traditionnelle, un système de bout en bout fait référence à un système qui saisit les informations brutes des capteurs et génère directement les variables pertinentes pour la tâche. Par exemple, en reconnaissance d'images, CNN peut être appelé de bout en bout par rapport à la méthode traditionnelle d'extraction de caractéristiques + classificateur. Dans les tâches de conduite autonome, saisir les données de divers capteurs (caméra/LiDAR
 FisheyeDetNet : le premier algorithme de détection de cible basé sur une caméra fisheye
Apr 26, 2024 am 11:37 AM
FisheyeDetNet : le premier algorithme de détection de cible basé sur une caméra fisheye
Apr 26, 2024 am 11:37 AM
La détection de cibles est un problème relativement mature dans les systèmes de conduite autonome, parmi lesquels la détection des piétons est l'un des premiers algorithmes à être déployés. Des recherches très complètes ont été menées dans la plupart des articles. Cependant, la perception de la distance à l’aide de caméras fisheye pour une vue panoramique est relativement moins étudiée. En raison de la distorsion radiale importante, la représentation standard du cadre de délimitation est difficile à mettre en œuvre dans les caméras fisheye. Pour alléger la description ci-dessus, nous explorons les conceptions étendues de boîtes englobantes, d'ellipses et de polygones généraux dans des représentations polaires/angulaires et définissons une métrique de segmentation d'instance mIOU pour analyser ces représentations. Le modèle fisheyeDetNet proposé avec une forme polygonale surpasse les autres modèles et atteint simultanément 49,5 % de mAP sur l'ensemble de données de la caméra fisheye Valeo pour la conduite autonome.
 Explorez les principes sous-jacents et la sélection d'algorithmes de la fonction de tri C++
Apr 02, 2024 pm 05:36 PM
Explorez les principes sous-jacents et la sélection d'algorithmes de la fonction de tri C++
Apr 02, 2024 pm 05:36 PM
La couche inférieure de la fonction de tri C++ utilise le tri par fusion, sa complexité est O(nlogn) et propose différents choix d'algorithmes de tri, notamment le tri rapide, le tri par tas et le tri stable.
