
 Périphériques technologiques
IA
Comment utiliser l'apprentissage par renforcement pour améliorer la fidélisation des utilisateurs de Kuaishou ?
Périphériques technologiques
IA
Comment utiliser l'apprentissage par renforcement pour améliorer la fidélisation des utilisateurs de Kuaishou ?
Comment utiliser l'apprentissage par renforcement pour améliorer la fidélisation des utilisateurs de Kuaishou ?

L'objectif principal du système de recommandation de vidéos courtes est de stimuler la croissance des DAU en améliorant la fidélisation des utilisateurs. Par conséquent, la rétention est l’un des principaux indicateurs d’optimisation commerciale de chaque APP. Cependant, la rétention est un retour à long terme après de multiples interactions entre les utilisateurs et le système, et il est difficile de le décomposer en un seul élément ou une seule liste. Il est donc difficile pour les modèles traditionnels par points et par listes de le faire directement. optimiser la rétention.
La méthode d'apprentissage par renforcement (RL) optimise les récompenses à long terme en interagissant avec l'environnement, et convient pour optimiser directement la fidélisation des utilisateurs. Ce travail modélise le problème d'optimisation de la rétention sous la forme d'un processus de décision markovien (MDP) avec une granularité de demande à horizon infini. Chaque fois que l'utilisateur demande au système de recommandation de décider d'une action, il est utilisé pour agréger plusieurs estimations de rétroaction différentes à court terme (durée de la surveillance, likes, attention, commentaires, retweets, etc.) notation du modèle de classement. L'objectif de ce travail est d'apprendre les politiques, de minimiser l'intervalle de temps cumulé entre plusieurs sessions utilisateur, d'augmenter la fréquence d'ouverture des applications et ainsi d'augmenter la rétention des utilisateurs.
Cependant, en raison des caractéristiques du signal retenu, l'application directe des algorithmes RL existants présente les défis suivants : 1) Incertitude : le signal retenu est non seulement déterminé par l'algorithme de recommandation, mais également perturbé par de nombreux facteurs externes. 2) Biais : le signal retenu varie selon les périodes et les groupes d'utilisateurs avec différents niveaux d'activité. 3) Instabilité : contrairement aux environnements de jeu qui renvoient les récompenses immédiatement, les signaux de rétention reviennent généralement en quelques heures ou quelques jours ; à l'instabilité dans la formation en ligne des algorithmes RL.
Ce travail propose l'algorithme d'apprentissage par renforcement pour la rétention des utilisateurs (RLUR) pour résoudre les défis ci-dessus et optimiser directement la rétention. Grâce à la vérification hors ligne et en ligne, l'algorithme RLUR peut améliorer considérablement l'indice de rétention secondaire par rapport à la référence de l'état de l'art. L'algorithme RLUR a été entièrement implémenté dans l'application Kuaishou et peut continuellement générer une rétention secondaire et des revenus DAU importants. C'est la première fois dans l'industrie que la technologie RL est utilisée pour améliorer la rétention des utilisateurs dans un environnement de production réel. Ce travail a été accepté dans le WWW 2023 Industry Track.

Auteurs : Cai Qingpeng, Liu Shuchang, Wang Xueliang, Zuo Tianyou, Xie Wentao, Yang Bin, Zheng Dong, Jiang Peng
Adresse papier : https://arxiv.org/ pdf/2302.01724 .pdf
Modélisation de problèmes
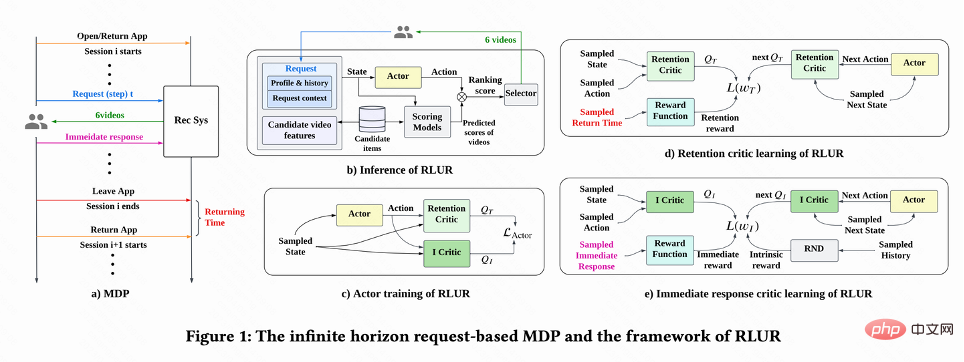
Comme le montre la figure 1(a), ce travail modélise le problème d'optimisation de la rétention dans un processus de décision de Markov basé sur des requêtes à horizon infini), où le système de recommandation est l'agent et l'utilisateur est l'environnement. Chaque fois que l'utilisateur ouvre l'application, une nouvelle session est ouverte. Comme le montre la figure 1(b), chaque fois que l'utilisateur demande  , le système de recommandation détermine un vecteur de paramètres
, le système de recommandation détermine un vecteur de paramètres  en fonction du statut de l'utilisateur
en fonction du statut de l'utilisateur  , et estime en même temps l'ordre de n différents à court terme indicateurs (durée de visionnage, likes, attention, etc.) Le modèle note chaque vidéo candidate j
, et estime en même temps l'ordre de n différents à court terme indicateurs (durée de visionnage, likes, attention, etc.) Le modèle note chaque vidéo candidate j  . Ensuite, la fonction de tri saisit l'action et le vecteur de score de chaque vidéo pour obtenir le score final de chaque vidéo, et sélectionne les 6 vidéos avec les scores les plus élevés à afficher à l'utilisateur, et l'utilisateur renvoie un retour immédiat
. Ensuite, la fonction de tri saisit l'action et le vecteur de score de chaque vidéo pour obtenir le score final de chaque vidéo, et sélectionne les 6 vidéos avec les scores les plus élevés à afficher à l'utilisateur, et l'utilisateur renvoie un retour immédiat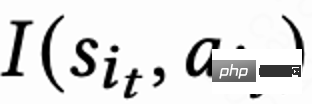 . Lorsque l'utilisateur quitte l'application, cette session se termine. La prochaine fois que l'utilisateur ouvre l'application, la session i+1 est ouverte. L'intervalle de temps entre la fin de la session précédente et le début de la session suivante est appelé temps de retour ( Heure du retour),
. Lorsque l'utilisateur quitte l'application, cette session se termine. La prochaine fois que l'utilisateur ouvre l'application, la session i+1 est ouverte. L'intervalle de temps entre la fin de la session précédente et le début de la session suivante est appelé temps de retour ( Heure du retour),  . Le but de cette recherche est de former une stratégie qui minimise la somme des temps de rappel pour plusieurs sessions.
. Le but de cette recherche est de former une stratégie qui minimise la somme des temps de rappel pour plusieurs sessions.
Algorithme RLUR
Ce travail explique d'abord comment estimer le temps cumulé de visite de retour, puis propose des méthodes pour résoudre plusieurs défis clés liés aux signaux retenus. Ces méthodes sont résumées dans l’algorithme Reinforcement Learning for User Retention, abrégé en RLUR.
Estimation du temps de visite de retour
Comme le montre la figure 1(d), puisque les actions sont continues, ce travail utilise la méthode d'apprentissage par différence temporelle (TD) de l'algorithme DDPG pour estimer le temps de visite de retour .
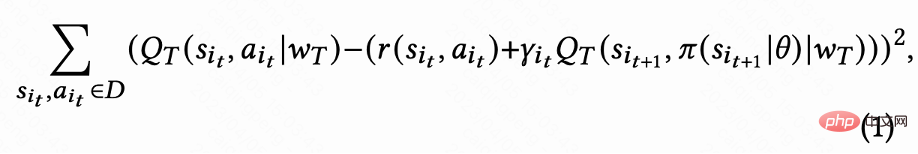
Étant donné que seule la dernière demande de chaque session a une récompense de temps de visite de retour, la récompense intermédiaire est de 0, l'auteur définit le facteur de remise  La valeur de la dernière demande de chaque session est
La valeur de la dernière demande de chaque session est 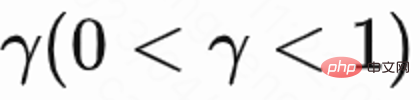 , et les autres demandes sont 1. Ce paramètre peut éviter la diminution exponentielle du temps de visite de retour. Et il peut être théoriquement prouvé que lorsque la perte (1) est égale à 0, Q estime en fait le temps de retour cumulé de plusieurs sessions,
, et les autres demandes sont 1. Ce paramètre peut éviter la diminution exponentielle du temps de visite de retour. Et il peut être théoriquement prouvé que lorsque la perte (1) est égale à 0, Q estime en fait le temps de retour cumulé de plusieurs sessions, 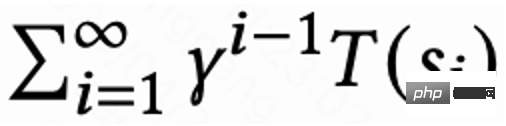 .
.
Résoudre le problème des récompenses retardées
Étant donné que l'heure de la visite de retour n'a lieu qu'à la fin de chaque session, cela entraînera le problème d'une faible efficacité d'apprentissage. Les auteurs utilisent donc des récompenses heuristiques pour améliorer l’apprentissage politique. Puisque la rétroaction à court terme est positivement liée à la rétention, l’auteur utilise la rétroaction à court terme comme première récompense heuristique. Et l’auteur adopte le réseau Random Network Distillation (RND) pour calculer la récompense intrinsèque de chaque échantillon comme deuxième récompense heuristique. Plus précisément, le réseau RND utilise deux structures de réseau identiques. Un réseau est initialisé de manière aléatoire sur fixe, et l'autre réseau s'adapte au réseau fixe, et la perte d'ajustement est utilisée comme récompense intrinsèque. Comme le montre la figure 1 (e), afin de réduire l'interférence des récompenses heuristiques sur les récompenses de rétention, ce travail apprend un réseau critique distinct pour estimer la somme des commentaires à court terme et des récompenses intrinsèques. C'est 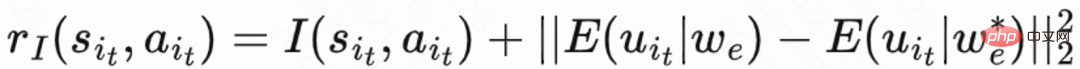 .
.
Résoudre le problème de l'incertitude
Étant donné que l'heure de la visite de retour est affectée par de nombreux facteurs autres que les recommandations, l'incertitude est élevée, ce qui affectera l'effet d'apprentissage. Ce travail propose une méthode de régularisation pour réduire la variance : estimez d'abord un modèle de classification  pour estimer la probabilité de temps de visite de retour, c'est-à-dire estimer si le temps de visite de retour est plus court que
pour estimer la probabilité de temps de visite de retour, c'est-à-dire estimer si le temps de visite de retour est plus court que  puis utiliser l'inégalité de Markov pour obtenir la valeur inférieure ; limite inférieure de l'heure de la visite de retour,
puis utiliser l'inégalité de Markov pour obtenir la valeur inférieure ; limite inférieure de l'heure de la visite de retour, 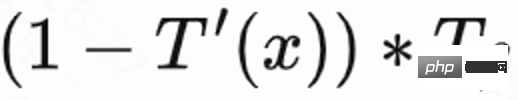 ; Enfin, la limite inférieure de l'heure de la visite de retour réelle/de l'heure de la visite de retour estimée est utilisée comme récompense régularisée de la visite de retour.
; Enfin, la limite inférieure de l'heure de la visite de retour réelle/de l'heure de la visite de retour estimée est utilisée comme récompense régularisée de la visite de retour.
Résoudre le problème de biais
En raison des grandes différences dans les habitudes comportementales des différents groupes actifs, le taux de rétention des utilisateurs très actifs est élevé et le nombre d'échantillons de formation est nettement supérieur à celui de utilisateurs peu actifs, ce qui conduira à une surestimation de l'apprentissage du modèle dirigé par l'utilisateur en direct. Pour résoudre ce problème, ce travail apprend 2 stratégies indépendantes pour différents groupes de haute et de faible activité, et utilise différents flux de données pour la formation. L'acteur minimise le temps de visite de retour tout en maximisant la récompense auxiliaire. Comme le montre la figure 1(c), en prenant le groupe très actif comme exemple, la perte d'acteur est :
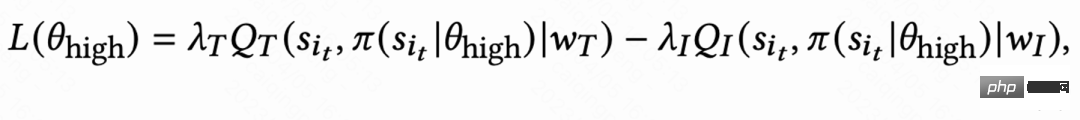
Résoudre le problème d'instabilité
En raison du retard du signal de l'heure de la visite de retour, elle revient généralement dans quelques heures à plusieurs jours, ce qui rendra la formation en ligne RL instable. L’utilisation directe des méthodes de clonage de comportement existantes limite considérablement la vitesse d’apprentissage ou ne peut garantir un apprentissage stable. Ce travail propose donc une nouvelle méthode de régularisation douce, qui consiste à multiplier la perte d'acteur par un coefficient de régularisation douce :
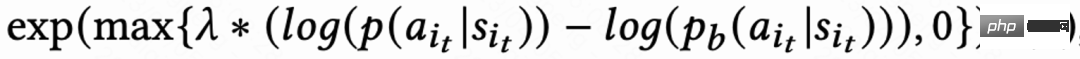
Cette méthode de régularisation est essentiellement un effet de freinage : si l'apprentissage actuel Si l'écart entre la stratégie et la stratégie d'échantillonnage est importante, la perte deviendra plus petite et l'apprentissage deviendra stable ; si la vitesse d'apprentissage devient stable, la perte deviendra à nouveau plus importante et la vitesse d'apprentissage s'accélérera. Lorsque  signifie qu’il n’y a aucune restriction sur le processus d’apprentissage.
signifie qu’il n’y a aucune restriction sur le processus d’apprentissage.
Expérience hors ligne
Ce travail compare RLUR avec l'algorithme d'apprentissage par renforcement de pointe TD3 et la méthode d'optimisation par boîte noire Cross Entropy Method (CEM) sur l'ensemble de données publiques KuaiRand. Ce travail construit d'abord un simulateur de rétention basé sur l'ensemble de données KuaiRand : comprenant trois modules : retour immédiat de l'utilisateur, utilisateur quittant la session et visite de retour de l'utilisateur sur l'application, puis utilisant cette méthode d'évaluation du simulateur de rétention.
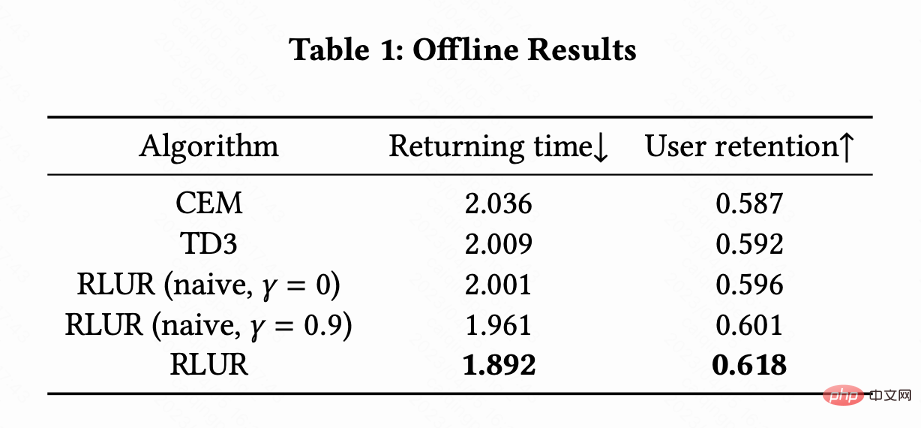
Le tableau 1 montre que RLUR est nettement meilleur que CEM et TD3 en termes de temps de visite de retour et d'indicateurs de rétention secondaires. Cette étude mène des expériences d'ablation pour comparer le RLUR avec uniquement la partie apprentissage de la rétention (RLUR (naïf)), ce qui peut illustrer l'efficacité de l'approche de cette étude pour résoudre les problèmes de rétention. Et à travers la comparaison entre  et
et  , il est montré que l'algorithme de minimisation du temps de visite retour de plusieurs sessions est meilleur que de minimiser le temps de visite retour d'une seule session.
, il est montré que l'algorithme de minimisation du temps de visite retour de plusieurs sessions est meilleur que de minimiser le temps de visite retour d'une seule session.
Expérience en ligne
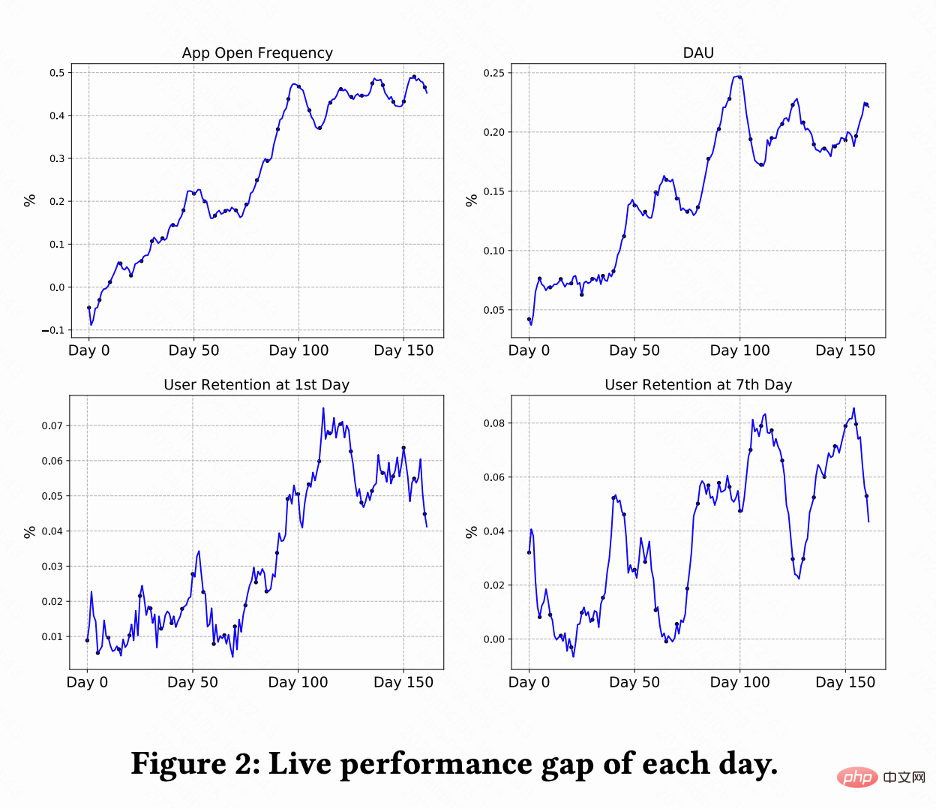
Ce travail effectue des tests A/B sur le système de recommandation de vidéos courtes Kuaishou pour comparer les méthodes RLUR et CEM. La figure 2 montre les pourcentages d'amélioration de la fréquence d'ouverture des applications, du DAU, de la première rétention et de la 7e rétention par rapport au RLUR et au CEM respectivement. On constate que la fréquence d’ouverture des applications augmente progressivement et converge même de 0 à 100 jours. Cela entraîne également des améliorations des indicateurs de deuxième rétention, de 7 rétention et de DAU (0,1 % de DAU et 0,01 % d'amélioration de deuxième rétention sont considérés comme statistiquement significatifs).
Résumé et travaux futurs
Cet article étudie comment améliorer la rétention des utilisateurs des systèmes de recommandation grâce à la technologie RL. Ce travail modélise l'optimisation de la rétention en tant que processus décisionnel de Markov avec une granularité de demande d'horizon infini. Ce travail propose l'algorithme RLUR pour. optimiser directement la rétention et relever efficacement plusieurs défis clés de la rétention du signal. L'algorithme RLUR a été entièrement implémenté dans l'application Kuaishou et peut générer une rétention secondaire et des revenus DAU importants. En ce qui concerne les travaux futurs, la manière d'utiliser l'apprentissage par renforcement hors ligne, Decision Transformer et d'autres méthodes pour améliorer plus efficacement la fidélisation des utilisateurs est une direction prometteuse.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 CLIP-BEVFormer : superviser explicitement la structure BEVFormer pour améliorer les performances de détection à longue traîne
Mar 26, 2024 pm 12:41 PM
CLIP-BEVFormer : superviser explicitement la structure BEVFormer pour améliorer les performances de détection à longue traîne
Mar 26, 2024 pm 12:41 PM
Écrit ci-dessus et compréhension personnelle de l'auteur : À l'heure actuelle, dans l'ensemble du système de conduite autonome, le module de perception joue un rôle essentiel. Le véhicule autonome roulant sur la route ne peut obtenir des résultats de perception précis que via le module de perception en aval. dans le système de conduite autonome, prend des jugements et des décisions comportementales opportuns et corrects. Actuellement, les voitures dotées de fonctions de conduite autonome sont généralement équipées d'une variété de capteurs d'informations de données, notamment des capteurs de caméra à vision panoramique, des capteurs lidar et des capteurs radar à ondes millimétriques pour collecter des informations selon différentes modalités afin d'accomplir des tâches de perception précises. L'algorithme de perception BEV basé sur la vision pure est privilégié par l'industrie en raison de son faible coût matériel et de sa facilité de déploiement, et ses résultats peuvent être facilement appliqués à diverses tâches en aval.
 Implémentation d'algorithmes d'apprentissage automatique en C++ : défis et solutions courants
Jun 03, 2024 pm 01:25 PM
Implémentation d'algorithmes d'apprentissage automatique en C++ : défis et solutions courants
Jun 03, 2024 pm 01:25 PM
Les défis courants rencontrés par les algorithmes d'apprentissage automatique en C++ incluent la gestion de la mémoire, le multithread, l'optimisation des performances et la maintenabilité. Les solutions incluent l'utilisation de pointeurs intelligents, de bibliothèques de threads modernes, d'instructions SIMD et de bibliothèques tierces, ainsi que le respect des directives de style de codage et l'utilisation d'outils d'automatisation. Des cas pratiques montrent comment utiliser la bibliothèque Eigen pour implémenter des algorithmes de régression linéaire, gérer efficacement la mémoire et utiliser des opérations matricielles hautes performances.
 Apprentissage par renforcement Deep Q-learning utilisant la simulation de bras robotique de Panda-Gym
Oct 31, 2023 pm 05:57 PM
Apprentissage par renforcement Deep Q-learning utilisant la simulation de bras robotique de Panda-Gym
Oct 31, 2023 pm 05:57 PM
L'apprentissage par renforcement (RL) est une méthode d'apprentissage automatique qui permet à un agent d'apprendre comment se comporter dans son environnement par essais et erreurs. Les agents sont récompensés ou punis pour avoir pris des mesures qui conduisent aux résultats souhaités. Au fil du temps, l'agent apprend à prendre des mesures qui maximisent la récompense attendue. Les agents RL sont généralement formés à l'aide d'un processus de décision markovien (MDP), un cadre mathématique pour modéliser des problèmes de décision séquentielle. Le MDP se compose de quatre parties : État : un ensemble d'états possibles de l'environnement. Action : un ensemble d'actions qu'un agent peut entreprendre. Fonction de transition : fonction qui prédit la probabilité de transition vers un nouvel état en fonction de l'état et de l'action actuels. Fonction de récompense : fonction qui attribue une récompense à l'agent pour chaque conversion. L'objectif de l'agent est d'apprendre une fonction politique,
 Explorez les principes sous-jacents et la sélection d'algorithmes de la fonction de tri C++
Apr 02, 2024 pm 05:36 PM
Explorez les principes sous-jacents et la sélection d'algorithmes de la fonction de tri C++
Apr 02, 2024 pm 05:36 PM
La couche inférieure de la fonction de tri C++ utilise le tri par fusion, sa complexité est O(nlogn) et propose différents choix d'algorithmes de tri, notamment le tri rapide, le tri par tas et le tri stable.
 L'intelligence artificielle peut-elle prédire la criminalité ? Explorez les capacités de CrimeGPT
Mar 22, 2024 pm 10:10 PM
L'intelligence artificielle peut-elle prédire la criminalité ? Explorez les capacités de CrimeGPT
Mar 22, 2024 pm 10:10 PM
La convergence de l’intelligence artificielle (IA) et des forces de l’ordre ouvre de nouvelles possibilités en matière de prévention et de détection de la criminalité. Les capacités prédictives de l’intelligence artificielle sont largement utilisées dans des systèmes tels que CrimeGPT (Crime Prediction Technology) pour prédire les activités criminelles. Cet article explore le potentiel de l’intelligence artificielle dans la prédiction de la criminalité, ses applications actuelles, les défis auxquels elle est confrontée et les éventuelles implications éthiques de cette technologie. Intelligence artificielle et prédiction de la criminalité : les bases CrimeGPT utilise des algorithmes d'apprentissage automatique pour analyser de grands ensembles de données, identifiant des modèles qui peuvent prédire où et quand les crimes sont susceptibles de se produire. Ces ensembles de données comprennent des statistiques historiques sur la criminalité, des informations démographiques, des indicateurs économiques, des tendances météorologiques, etc. En identifiant les tendances qui pourraient échapper aux analystes humains, l'intelligence artificielle peut donner du pouvoir aux forces de l'ordre.
 Algorithme de détection amélioré : pour la détection de cibles dans des images de télédétection optique haute résolution
Jun 06, 2024 pm 12:33 PM
Algorithme de détection amélioré : pour la détection de cibles dans des images de télédétection optique haute résolution
Jun 06, 2024 pm 12:33 PM
01Aperçu des perspectives Actuellement, il est difficile d'atteindre un équilibre approprié entre efficacité de détection et résultats de détection. Nous avons développé un algorithme YOLOv5 amélioré pour la détection de cibles dans des images de télédétection optique haute résolution, en utilisant des pyramides de caractéristiques multicouches, des stratégies de têtes de détection multiples et des modules d'attention hybrides pour améliorer l'effet du réseau de détection de cibles dans les images de télédétection optique. Selon l'ensemble de données SIMD, le mAP du nouvel algorithme est 2,2 % meilleur que YOLOv5 et 8,48 % meilleur que YOLOX, permettant ainsi d'obtenir un meilleur équilibre entre les résultats de détection et la vitesse. 02 Contexte et motivation Avec le développement rapide de la technologie de télédétection, les images de télédétection optique à haute résolution ont été utilisées pour décrire de nombreux objets à la surface de la Terre, notamment des avions, des voitures, des bâtiments, etc. Détection d'objets dans l'interprétation d'images de télédétection
 Application d'algorithmes dans la construction de 58 plateformes de portraits
May 09, 2024 am 09:01 AM
Application d'algorithmes dans la construction de 58 plateformes de portraits
May 09, 2024 am 09:01 AM
1. Contexte de la construction de la plateforme 58 Portraits Tout d'abord, je voudrais partager avec vous le contexte de la construction de la plateforme 58 Portraits. 1. La pensée traditionnelle de la plate-forme de profilage traditionnelle ne suffit plus. La création d'une plate-forme de profilage des utilisateurs s'appuie sur des capacités de modélisation d'entrepôt de données pour intégrer les données de plusieurs secteurs d'activité afin de créer des portraits d'utilisateurs précis. Elle nécessite également l'exploration de données pour comprendre le comportement et les intérêts des utilisateurs. et besoins, et fournir des capacités côté algorithmes ; enfin, il doit également disposer de capacités de plate-forme de données pour stocker, interroger et partager efficacement les données de profil utilisateur et fournir des services de profil. La principale différence entre une plate-forme de profilage d'entreprise auto-construite et une plate-forme de profilage de middle-office est que la plate-forme de profilage auto-construite dessert un seul secteur d'activité et peut être personnalisée à la demande. La plate-forme de mid-office dessert plusieurs secteurs d'activité et est complexe ; modélisation et offre des fonctionnalités plus générales. 2.58 Portraits d'utilisateurs de l'arrière-plan de la construction du portrait sur la plate-forme médiane 58
 Ajoutez SOTA en temps réel et montez en flèche ! FastOcc : un algorithme Occ plus rapide et convivial pour le déploiement est là !
Mar 14, 2024 pm 11:50 PM
Ajoutez SOTA en temps réel et montez en flèche ! FastOcc : un algorithme Occ plus rapide et convivial pour le déploiement est là !
Mar 14, 2024 pm 11:50 PM
Écrit ci-dessus & La compréhension personnelle de l'auteur est que dans le système de conduite autonome, la tâche de perception est un élément crucial de l'ensemble du système de conduite autonome. L'objectif principal de la tâche de perception est de permettre aux véhicules autonomes de comprendre et de percevoir les éléments environnementaux environnants, tels que les véhicules circulant sur la route, les piétons au bord de la route, les obstacles rencontrés lors de la conduite, les panneaux de signalisation sur la route, etc., aidant ainsi en aval modules Prendre des décisions et des actions correctes et raisonnables. Un véhicule doté de capacités de conduite autonome est généralement équipé de différents types de capteurs de collecte d'informations, tels que des capteurs de caméra à vision panoramique, des capteurs lidar, des capteurs radar à ondes millimétriques, etc., pour garantir que le véhicule autonome peut percevoir et comprendre avec précision l'environnement environnant. éléments , permettant aux véhicules autonomes de prendre les bonnes décisions pendant la conduite autonome. Tête
