

Spécifiez une colonne de référence, basée sur cette colonne, fusionnez d'autres colonnes.
import pandas as pd
df1 = pd.DataFrame({'id': ['001', '002', '003'],
'num1': [120, 101, 104],
'num2': [110, 102, 121],
'num3': [105, 120, 113]})
df2 = pd.DataFrame({'id': ['001', '002', '003'],
'num4': [80, 86, 79]})
print(df1)
print("=======================================")
print(df2)
print("=======================================")
df_merge = pd.merge(df1, df2, on='id')
print(df_merge)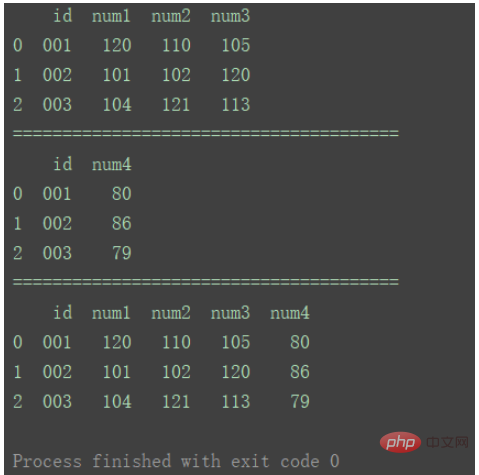
Pour réaliser cette fusion, vous pouvez également fusionner par index, c'est-à-dire en fonction de la colonne d'index. Définissez simplement left_index et right_index sur True
. (left_index et right_index sont par défaut False. left_index signifie que la table de gauche est basée sur l'index des données de la table de gauche, et right_index signifie que la table de droite est basée sur l'index des données de la table de droite.)
import pandas as pd
df1 = pd.DataFrame({'id': ['001', '002', '003'],
'num1': [120, 101, 104],
'num2': [110, 102, 121],
'num3': [105, 120, 113]})
df2 = pd.DataFrame({'id': ['001', '002', '003'],
'num4': [80, 86, 79]})
print(df1)
print("=======================================")
print(df2)
print("=======================================")
df_merge = pd.merge(df1, df2, left_index=True, right_index=True)
print(df_merge)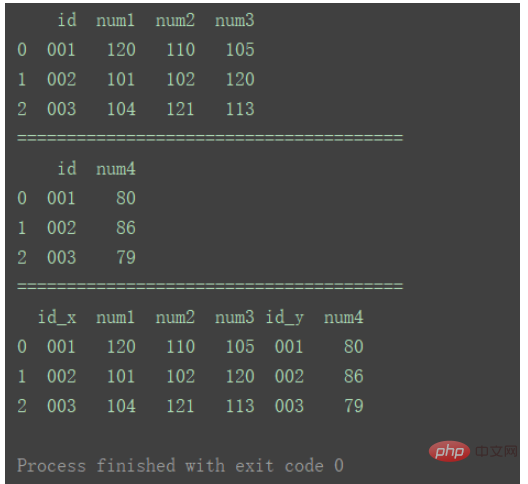
Par rapport à la méthode ①, la différence est que, comme le montre la figure, il existe des colonnes en double dans les données fusionnées par la méthode 2.
pd.merge(right,how=‘inner’, on="Aucun", left_on="Aucun", right_on="Aucun", left_index=False, right_index=False )
| Paramètres | Description |
|---|---|
| gauche | Table gauche, objet fusionné, DataFrame ou Series |
| droite | Table droite, objet fusionné, DataFrame ou Series |
| comment | Méthode de fusion, Il peut être gauche (fusion à gauche), droite (fusion à droite), externe (fusion externe), interne (fusion interne) |
| on | Le nom de la colonne de base |
| left_on | La colonne de base nom de la table de gauche |
| right_on | Colonne de base de la table de droite nom de la colonne |
| left_index | Que la colonne de gauche soit basée sur l'index, la valeur par défaut est False, non |
| right_index | Que la droite La colonne est basée sur l'index, la valeur par défaut est False, Non |
Parmi eux, left_index et right_index ne peuvent pas être spécifiés en même temps que on.
Préparer les données‘
Préparer un nouvel ensemble de données :
import pandas as pd
df1 = pd.DataFrame({'id': ['001', '002', '003'],
'num1': [120, 101, 104],
'num2': [110, 102, 121],
'num3': [105, 120, 113]})
df2 = pd.DataFrame({'id': ['001', '004', '003'],
'num4': [80, 86, 79]})
print(df1)
print("=======================================")
print(df2)
print("=======================================")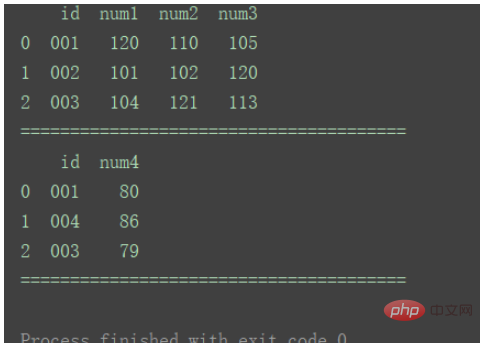
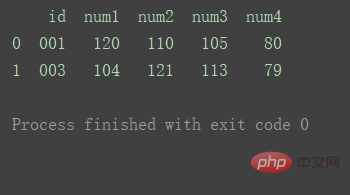
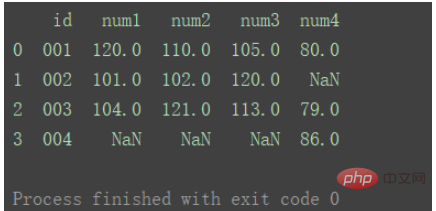
intérieur (par défaut)
Utiliser l'intersection des clés des deux ensembles de données
df_merge = pd.merge(df1, df2, on='id') print(df_merge)
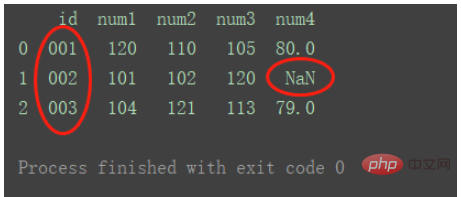
outer
Utilisation de l'union des clés des deux ensembles de données
df_merge = pd.merge(df1, df2, on='id', how="outer") print(df_merge)
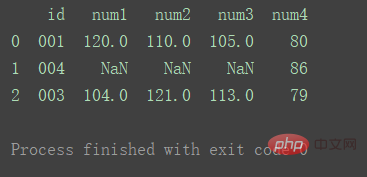
left
Utilisation des clés de l'ensemble de données de gauche
df_merge = pd.merge(df1, df2, on='id', how='left') print(df_merge)
c'est vrai
Utilisez la clé à partir du bon ensemble de données
df_merge = pd.merge(df1, df2, on='id', how='right') print(df_merge)
import pandas as pd
df1 = pd.DataFrame({'id': ['001', '002', '003'],
'num1': [120, 101, 104],
'num2': [110, 102, 121],
'num3': [105, 120, 113]})
df2 = pd.DataFrame({'id': ['001', '001', '003'],
'num4': [80, 86, 79]})
print(df1)
print("=======================================")
print(df2)
print("=======================================")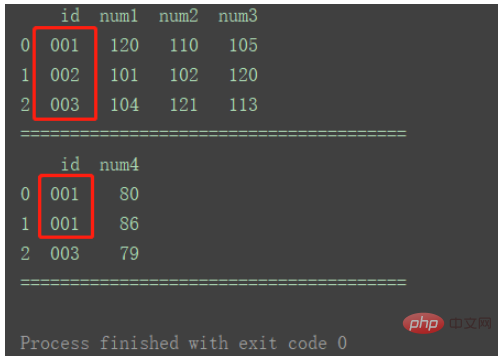
Comme le montre la figure, il y a des données id1 en double dans df2.
Merge
df_merge = pd.merge(df1, df2, on='id') print(df_merge)
Le résultat de la fusion est tel qu'indiqué dans la figure :
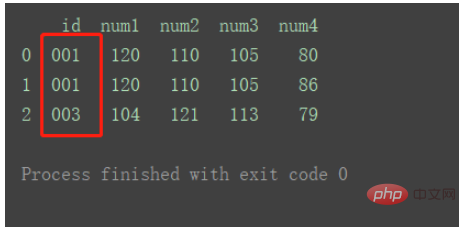
utilise toujours l'intersection des clés des deux ensembles de données selon la méthode Inner par défaut. Et les lignes avec des clés en double seront reflétées sous forme de plusieurs lignes dans le résultat fusionné.
Par exemple, il existe plusieurs lignes avec des identifiants en double dans le graphique 1 et le tableau 2.
import pandas as pd
df1 = pd.DataFrame({'id': ['001', '002', '002', '002', '003'],
'num1': [120, 101, 104, 114, 123],
'num2': [110, 102, 121, 113, 126],
'num3': [105, 120, 113, 124, 128]})
df2 = pd.DataFrame({'id': ['001', '001', '002', '003', '001'],
'num4': [80, 86, 79, 88, 93]})
print(df1)
print("=======================================")
print(df2)
print("=======================================")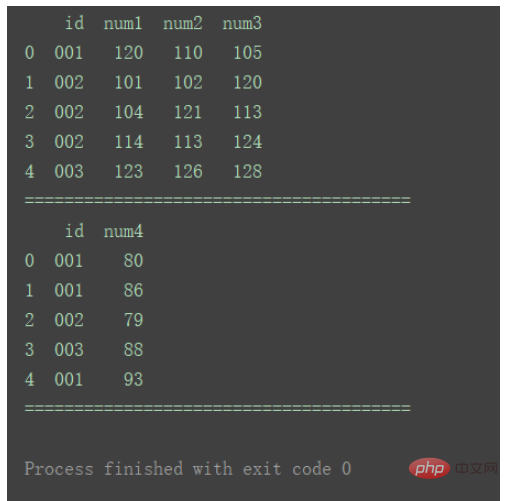
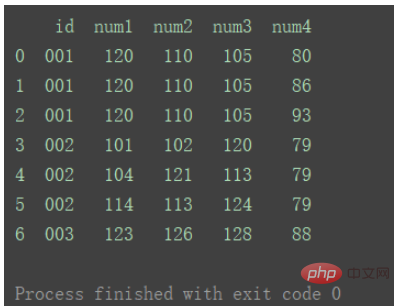
df_merge = pd.merge(df1, df2, on='id') print(df_merge)
pd.concat(objs, axis=0, join=‘outer’, ignore_index:bool=False,keys=None,levels=None,names=None , verify_integrity:bool=False,sort:bool=False,copy:bool=True)
| Parameters | Description |
|---|---|
| objs | Séquence d'objet DataFrame ou Panel ou mappage |
| axis | par défaut à 0, indiquant les colonnes. Si 1, cela signifie ligne. |
| join | La valeur par défaut est "externe", elle peut aussi être "intérieure" |
| ignore_index | La valeur par défaut est False, indiquant que l'index est conservé (non ignoré). Définissez sur True pour ignorer l’index. |
其他重要参数通过实例说明。
首先准备三组DataFrame数据:
import pandas as pd
df1 = pd.DataFrame({'id': ['001', '002', '003'],
'num1': [120, 114, 123],
'num2': [110, 102, 121],
'num3': [113, 124, 128]})
df2 = pd.DataFrame({'id': ['004', '005'],
'num1': [120, 101],
'num2': [113, 126],
'num3': [105, 128]})
df3 = pd.DataFrame({'id': ['007', '008', '009'],
'num1': [120, 101, 125],
'num2': [113, 126, 163],
'num3': [105, 128, 114]})
print(df1)
print("=======================================")
print(df2)
print("=======================================")
print(df3)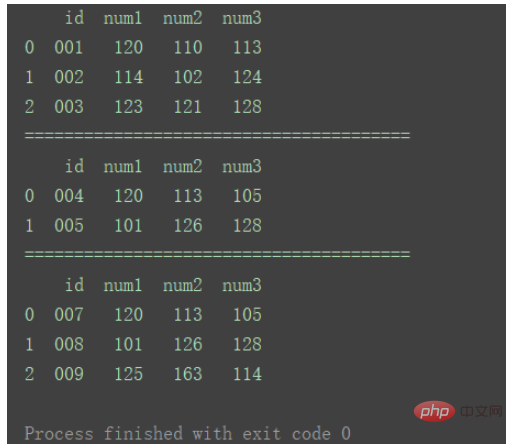
合并
dfs = [df1, df2, df3] result = pd.concat(dfs) print(result)
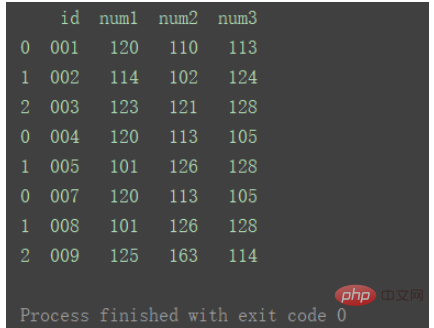
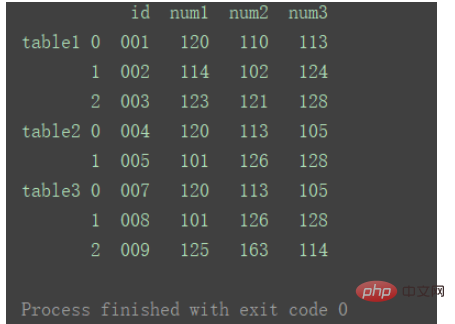
如果想要在合并后,标记一下数据都来自于哪张表或者数据的某类别,则也可以给concat加上 参数keys 。
result = pd.concat(dfs, keys=['table1', 'table2', 'table3']) print(result)
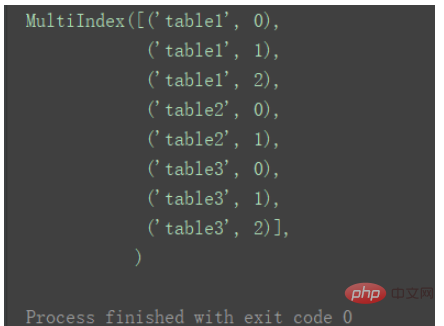
此时,添加的keys与原来的index组成元组,共同成为新的index。
print(result.index)
准备两组DataFrame数据:
import pandas as pd
df1 = pd.DataFrame({'num1': [120, 114, 123],
'num2': [110, 102, 121],
'num3': [113, 124, 128]}, index=['001', '002', '003'])
df2 = pd.DataFrame({'num3': [117, 120, 101, 126],
'num5': [113, 125, 126, 133],
'num6': [105, 130, 128, 128]}, index=['002', '003', '004', '005'])
print(df1)
print("=======================================")
print(df2)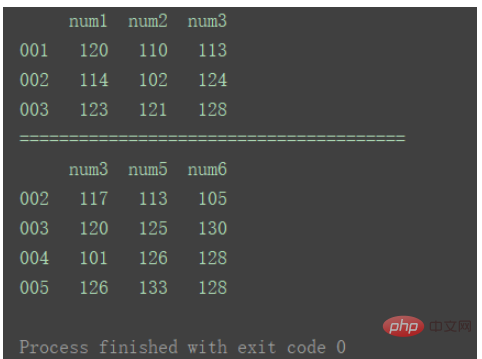
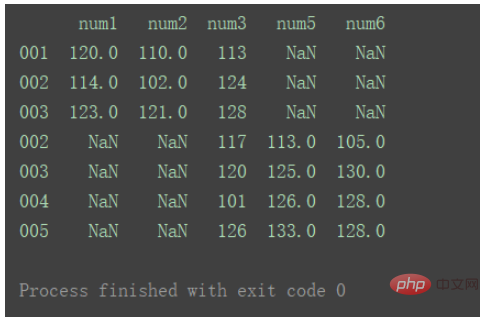
当axis为默认值0时:
result = pd.concat([df1, df2]) print(result)
横向合并需要将axis设置为1 :
result = pd.concat([df1, df2], axis=1) print(result)
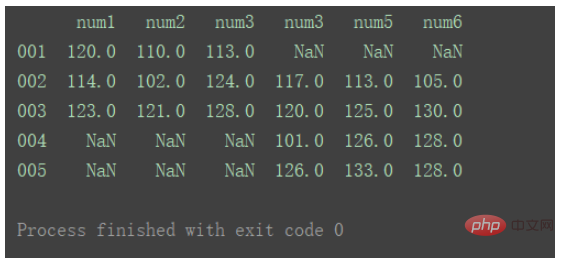
对比以上输出差异。
axis=0时,即默认纵向合并时,如果出现重复的行,则会同时体现在结果中
axis=1时,即横向合并时,如果出现重复的列,则会同时体现在结果中。
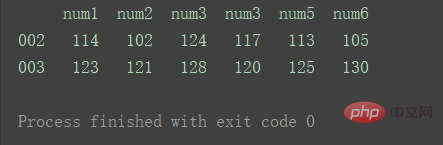
result = pd.concat([df1, df2], axis=1, join='inner') print(result)
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
















![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



