
 Périphériques technologiques
IA
Comment utiliser de grands modèles visuels pour accélérer la formation et l'inférence ?
Périphériques technologiques
IA
Comment utiliser de grands modèles visuels pour accélérer la formation et l'inférence ?
Comment utiliser de grands modèles visuels pour accélérer la formation et l'inférence ?

Bonjour à tous, je m'appelle Tao Li de l'équipe d'experts en calcul NVIDIA GPU et je suis très heureux d'avoir l'opportunité de partager avec vous aujourd'hui la formation de modèles et l'optimisation d'inférence de Swin Transformer, un grand modèle visuel, que moi et mon. collègue Chen Yu a fait du travail. Certaines de ces méthodes et stratégies peuvent être utilisées dans d'autres formations de modèles et optimisations d'inférence pour améliorer le débit du modèle, améliorer l'efficacité de l'utilisation du GPU et accélérer l'itération du modèle.
Je présenterai l'optimisation de la partie formation du modèle Swin Transformer. Le travail sur la partie optimisation de l'inférence sera présenté en détail par mes collègues
Voici le répertoire que nous avons. partagé aujourd'hui, principalement divisé en quatre parties Puisqu'il est optimisé pour un modèle spécifique, nous présenterons d'abord brièvement le modèle Swin Transformer. Ensuite, je combinerai l'outil de profilage, à savoir nsight system, pour analyser et optimiser le processus de formation. Dans la partie inférence, mes collègues donneront des stratégies et des méthodes d'optimisation d'inférence, y compris une optimisation plus détaillée au niveau CUDA. Enfin, voici un résumé du contenu d’optimisation d’aujourd’hui.

La première partie est la première partie, qui est l'introduction de Swin Transformer.
1. Introduction à Swin Transformer
D'après le nom du modèle, nous pouvons voir qu'il s'agit d'un modèle basé sur Transformer.
Après que le modèle Transformer ait été proposé dans l'article, l'attention est tout ce dont vous avez besoin, il a brillé sur de nombreuses tâches dans le domaine du traitement du langage naturel.
Le cœur du modèle Transformer est ce qu'on appelle le mécanisme d'attention, qui est le mécanisme d'attention. Pour le module attention, les entrées habituelles sont les tenseurs de requête, de clé et de valeur. Grâce à la fonction de requête et de clé, ainsi qu'au calcul de softmax, le résultat d'attention généralement appelé carte d'attention peut être obtenu. Selon la valeur de la carte d'attention, le modèle peut apprendre à quelles zones de la valeur doivent prêter plus d'attention. ou On dit que le modèle peut apprendre quelles valeurs en valeur sont d'une grande aide pour notre tâche. Il s’agit du modèle d’attention à tête unique le plus basique.
En augmentant le nombre de ces modules d'attention à tête unique, nous pouvons former un module d'attention multi-tête commun. Les encodeurs et décodeurs courants sont construits sur la base de ces modules d'attention multi-têtes.
De nombreux modèles comprennent généralement deux modules d'attention, l'auto-attention et l'attention croisée, ou une pile d'un ou plusieurs modules. Par exemple, le célèbre BERT est composé de plusieurs modules d'encodeurs. Le modèle de diffusion populaire inclut généralement à la fois l'attention personnelle et l'attention croisée.
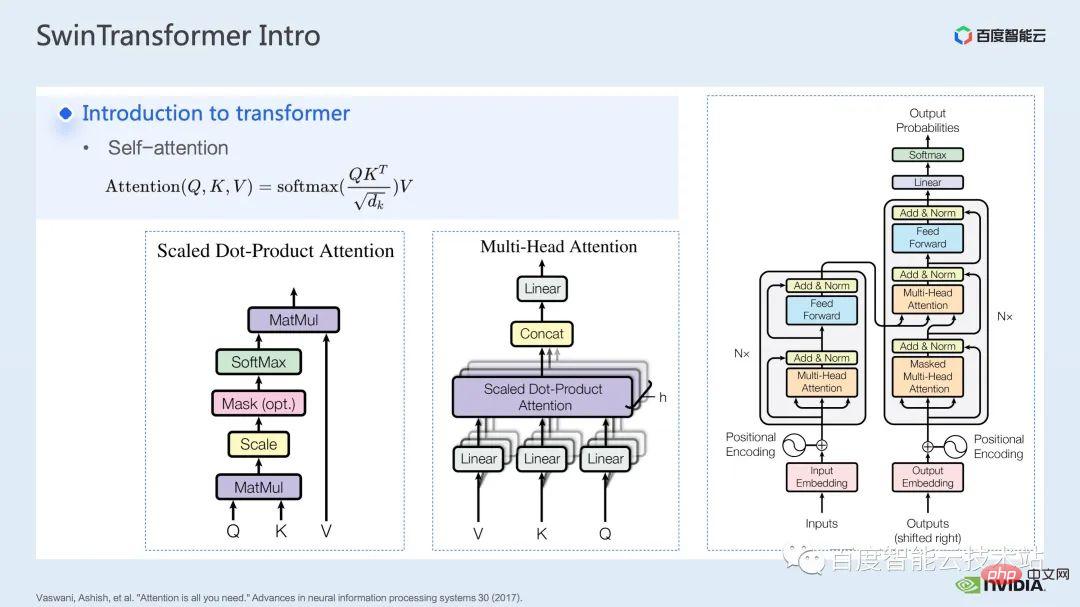
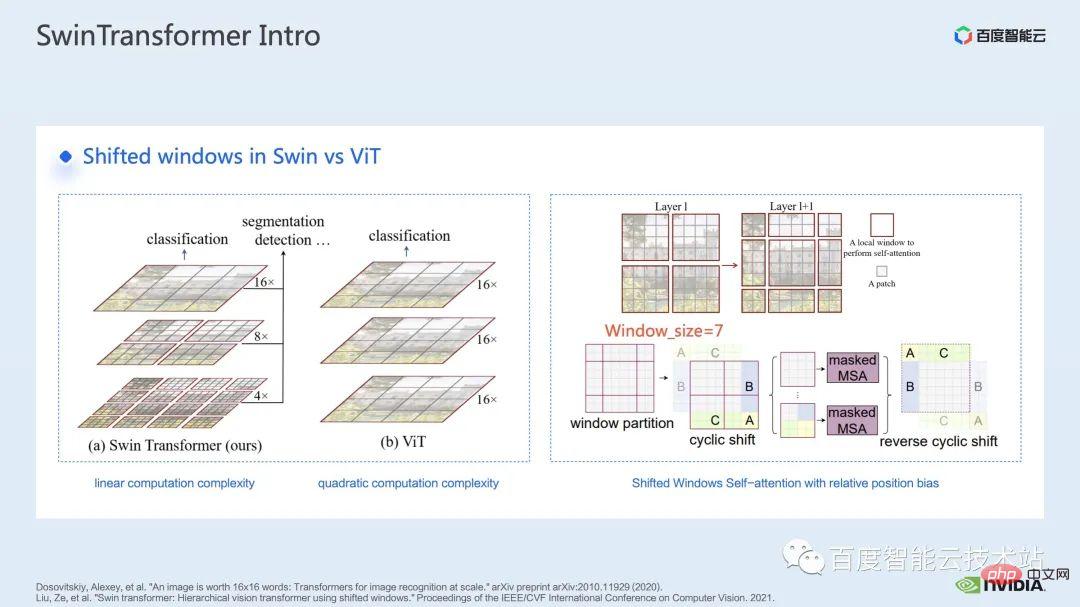
Avant Swin Transformer, Vision Transformer (ViT) a d'abord appliqué les transformateurs au domaine de la vision par ordinateur. La structure du modèle de ViT est illustrée sur le côté gauche de la figure ci-dessous. ViT divisera une image en une série de correctifs. Chaque correctif est analogue à un jeton dans le traitement du langage naturel, puis codera cette série de correctifs via un transformateur. encodeur basé sur , et enfin obtenir des fonctionnalités qui peuvent être utilisées pour des tâches telles que la classification.
En venant dans Swin Transformer, il introduit le concept d'attention à la fenêtre. Contrairement à ViT, qui prête attention à l'image entière, Swin Transformer divisera d'abord l'image en plusieurs fenêtres, puis ne fera attention qu'aux correctifs à l'intérieur. la fenêtre, réduisant ainsi la quantité de calcul.
Afin de compenser le problème de limite causé par la fenêtre, Swin Transformer introduit en outre l'opération de décalage de fenêtre. Dans le même temps, afin que le modèle ait des informations de position plus riches, un biais de position relative est également introduit dans l'attention. En fait, l'attention de la fenêtre et le décalage de la fenêtre sont ici à l'origine du nom Swin dans Swin Transformer.
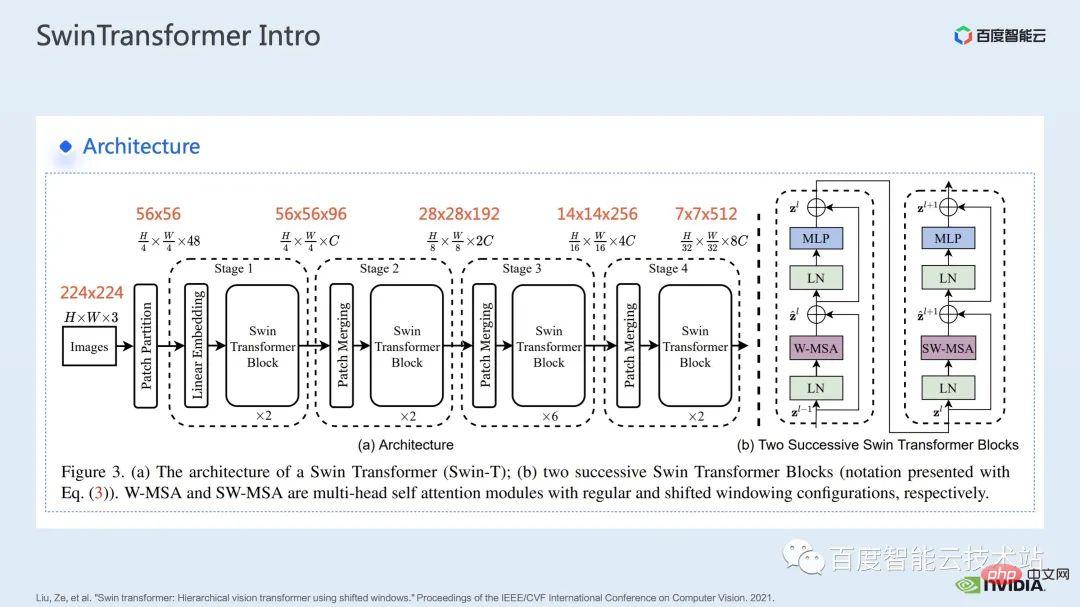
Voici la structure du réseau de Swin Transformer. La structure générale du réseau est très similaire à celle d'un CNN traditionnel tel que ResNet.
Vous pouvez voir que l'ensemble de la structure du réseau est divisé en plusieurs étapes, et au milieu des différentes étapes, il y aura un processus de sous-échantillonnage correspondant. La résolution de chaque étape est différente, formant une pyramide de résolution, ce qui réduit également progressivement la complexité informatique de chaque étape.
Ensuite il y aura plusieurs blocs transformateurs dans chaque étage. Dans chaque bloc transformateur, le module d'attention aux fenêtres mentionné ci-dessus sera utilisé.
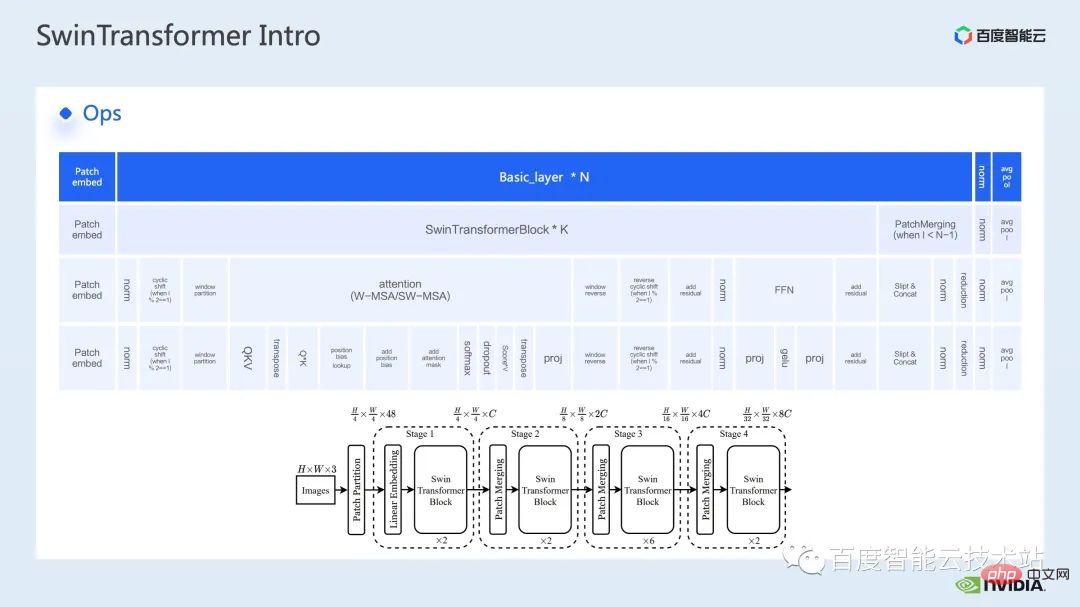
Ensuite, déconstruisons Swin Transformer du point de vue d'opérations spécifiques.
Comme vous pouvez le voir, un bloc transformateur comprend trois parties. La première partie concerne les opérations de décalage/partition/inversion de fenêtre, la deuxième partie est le calcul de l'attention et la troisième partie est le FFN. calcul ; et Les parties attention et FFN peuvent être subdivisées en plusieurs opérations, et enfin nous pouvons subdiviser l'ensemble du modèle en une combinaison de dizaines d'opérations.
Une telle division des opérateurs est très importante pour nous car elle permet d'analyser les performances, de localiser les goulots d'étranglement des performances et d'optimiser l'accélération.
Ce qui précède est l'introduction de la première partie. Présentons ensuite certains des travaux d'optimisation que nous avons effectués en formation. En particulier, nous combinons l'outil de profilage, c'est-à-dire le système nsight, pour analyser et optimiser le processus de formation global.
2. Optimisation de la formation Swin Transformer
Pour la formation de grands modèles, des ressources informatiques multi-cartes et multi-nœuds sont généralement utilisées. Pour Swin Transformer, nous avons constaté que la surcharge de communication entre les cartes sera relativement faible. À mesure que le nombre de cartes augmente, la vitesse globale augmente de manière presque linéaire. Nous donnons donc ici la priorité à l'analyse des goulots d'étranglement informatiques sur un seul GPU. optimisation.
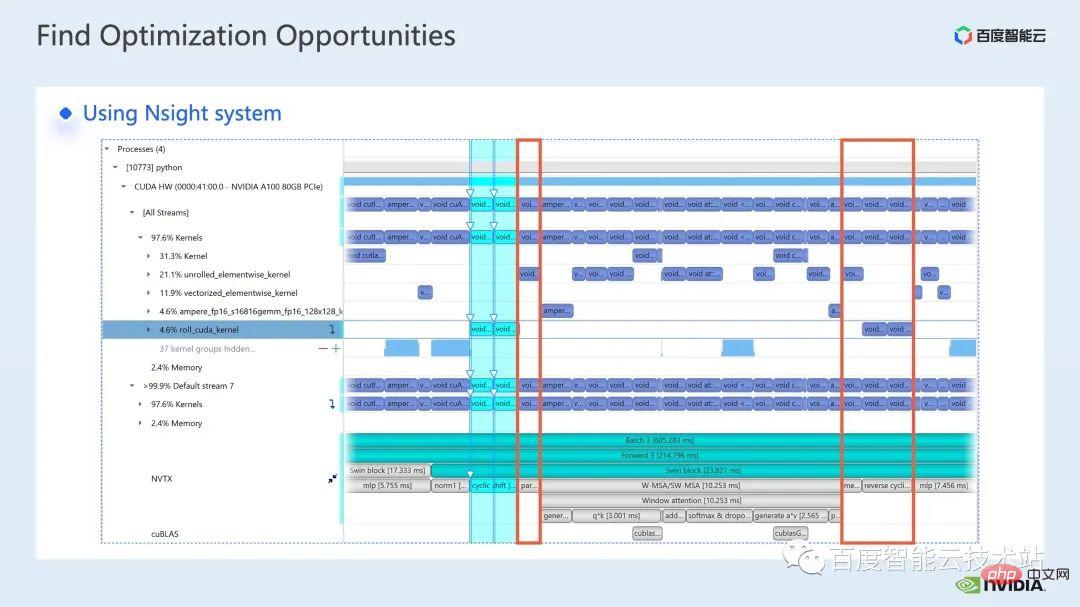
nsight system est un outil d'analyse des performances au niveau du système. Grâce à cet outil, nous pouvons facilement voir l'utilisation du GPU de chaque module du modèle, s'il existe d'éventuels goulots d'étranglement des performances et des optimisations telles que l'attente de données, etc. L'espace peut nous aider à planifier raisonnablement la charge entre le CPU et le GPU. Le système
nsight peut capturer l'état d'appel et d'exécution des fonctions du noyau appelées par CUDA et certaines bibliothèques informatiques GPU telles que cublas, cudnn, tensorRT, etc., et peut permettre aux utilisateurs d'ajouter des marqueurs pour compter la plage de marqueurs correspondant au fonctionnement du GPU.
Un processus d'optimisation de modèle standard est présenté dans la figure ci-dessous. Nous profilons le modèle, obtenons le rapport d'analyse des performances, découvrons les points d'optimisation des performances, puis effectuons un réglage ciblé des performances.
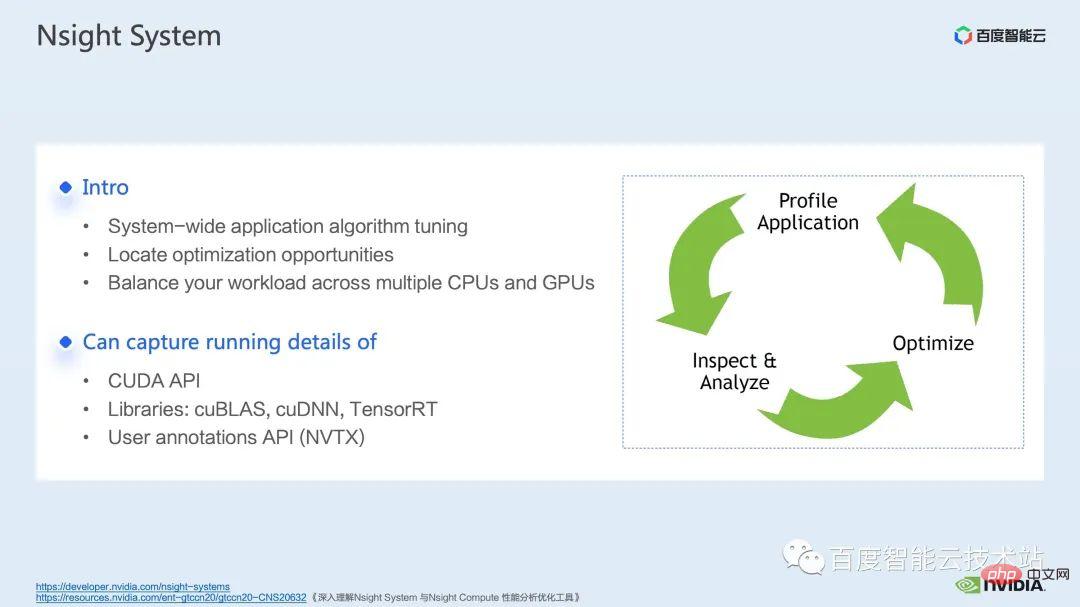
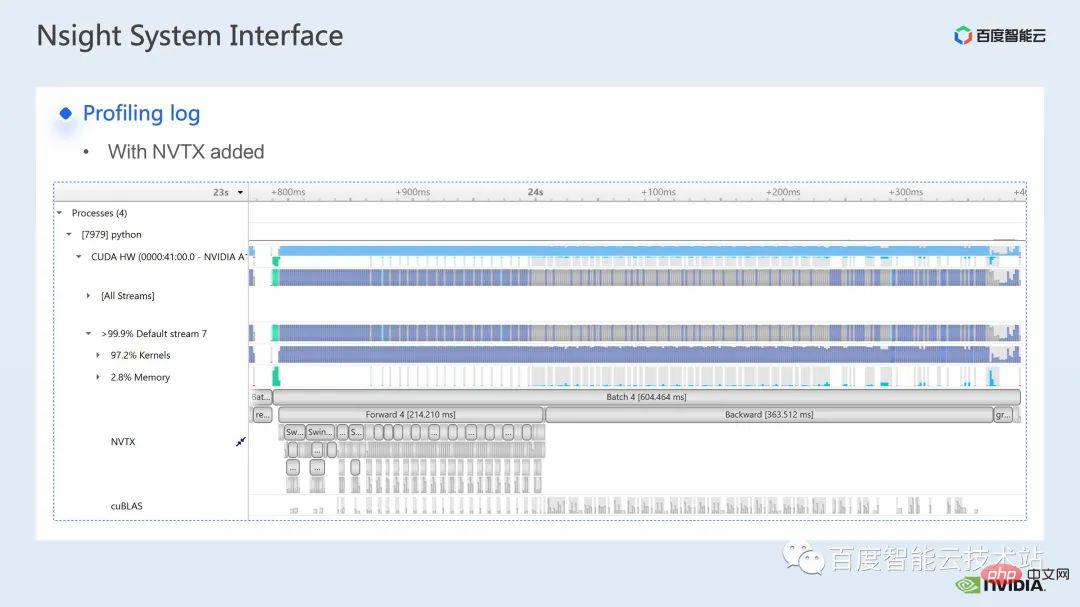
Voici une interface du système nsight. Nous pouvons clairement voir le lancement de la fonction noyau, qui est le lancement du noyau ; l'exécution de la fonction noyau, qui est ici la partie runtime. Pour des fonctions spécifiques du noyau, nous pouvons voir la proportion de temps dans l'ensemble du processus, ainsi que des informations telles que si le GPU est inactif. Après avoir ajouté la balise nvtx, nous pouvons voir le temps nécessaire au modèle pour avancer et reculer.
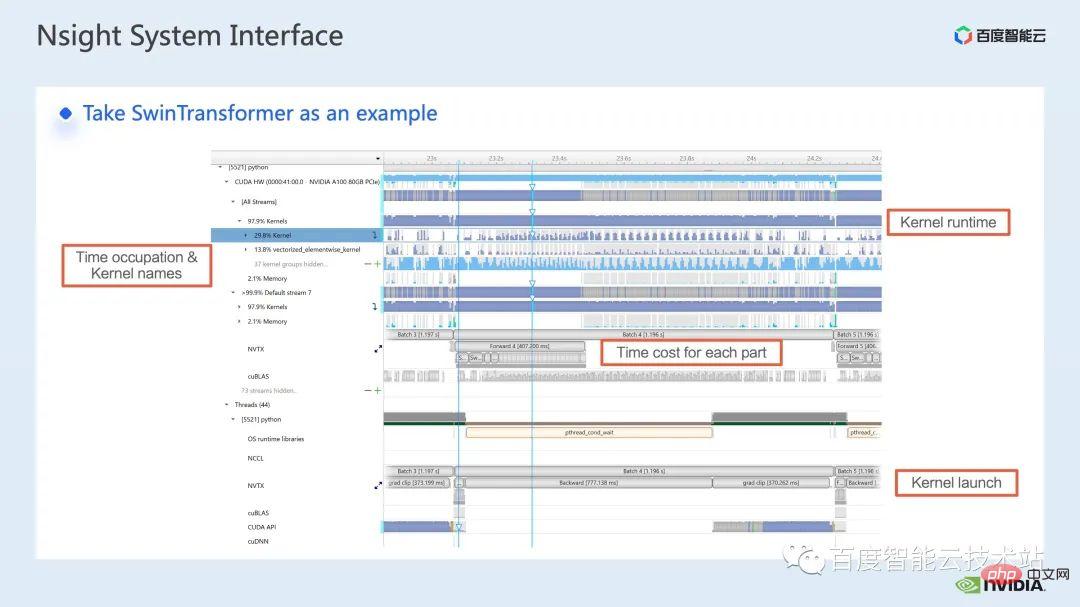
Dans la partie avant, si nous zoomons, nous pouvons également voir clairement le temps spécifique requis pour le calcul de chaque bloc SwinTransformer.
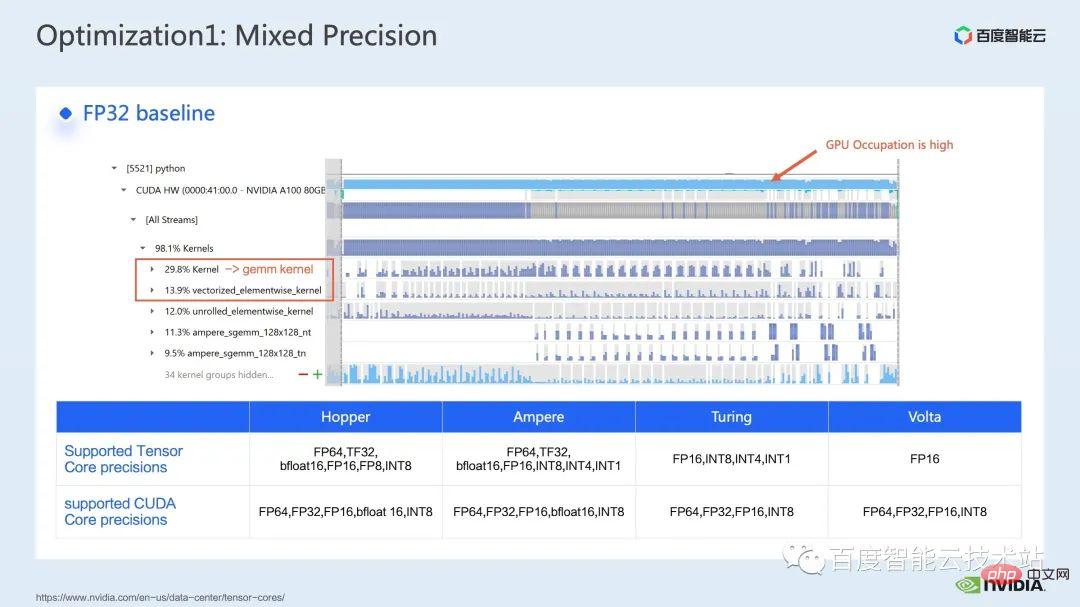
Nous examinons d'abord les performances de l'ensemble de la ligne de base via l'outil d'analyse des performances du système nsight. L'image ci-dessous montre la ligne de base FP32. Vous pouvez voir que son utilisation du GPU est très élevée et la proportion la plus élevée. l'un d'eux est le noyau de multiplication matricielle.
Donc, pour la multiplication matricielle, l'une de nos méthodes d'optimisation consiste à utiliser pleinement le noyau tensoriel pour l'accélération.
Nous savons que le GPU de NVIDIA dispose de ressources matérielles telles que le cuda core et le Tensor Core, un module spécialement conçu pour accélérer la multiplication matricielle. Nous pouvons envisager d'utiliser le noyau tenseur tf32 directement ou d'utiliser le noyau tenseur fp16 en précision mixte. Il faut savoir que le débit de multiplication matricielle du noyau tensoriel utilisant fp16 sera supérieur à celui de tf32, et la multiplication matricielle de fp32 pur aura également un effet d'accélération élevé.
Ici, nous adoptons une solution de précision mixte. En utilisant le mode de précision mixte de torch.cuda.amp, nous pouvons obtenir une amélioration du débit de 1,63x.
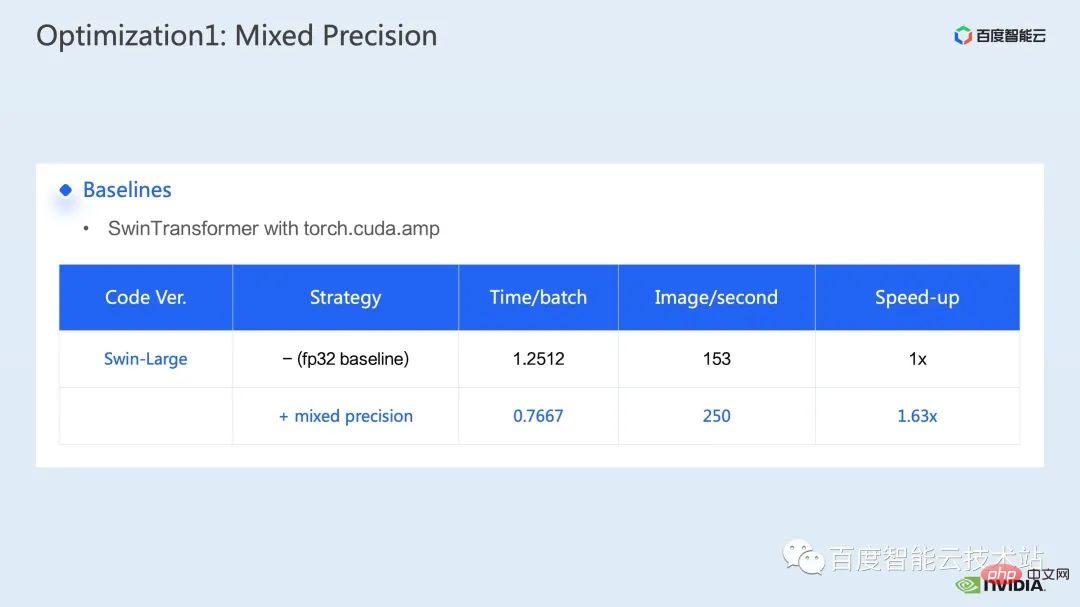
Vous pouvez également voir clairement dans les résultats du profilage que la multiplication matricielle, qui représentait à l'origine la proportion la plus élevée, a été optimisée et sa proportion dans l'ensemble de la chronologie est tombée à 11,9 %. Jusqu’à présent, les noyaux avec une proportion relativement élevée sont des noyaux élémentaires.
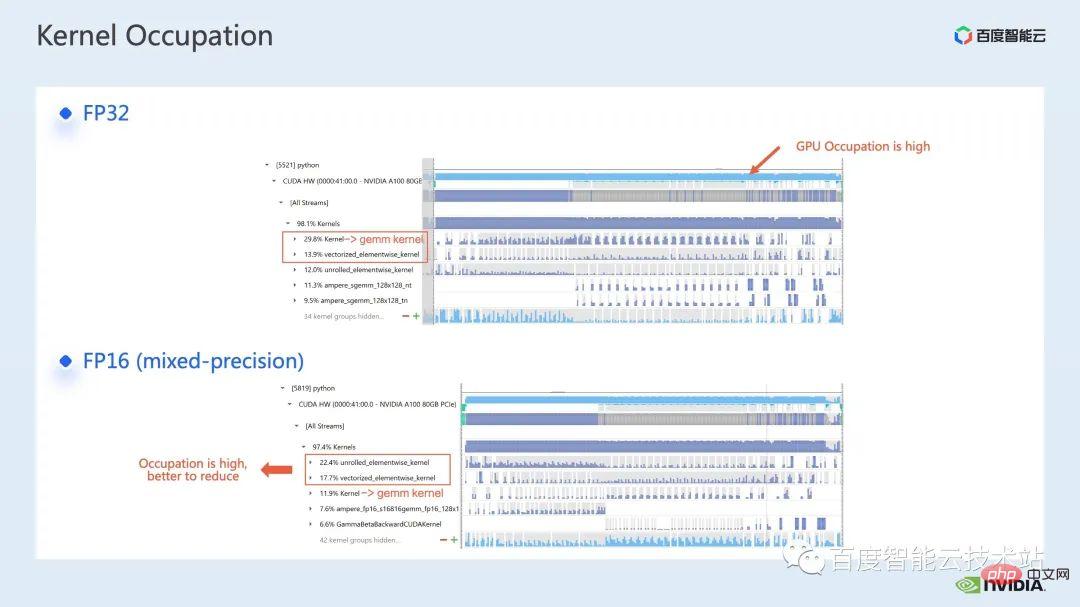
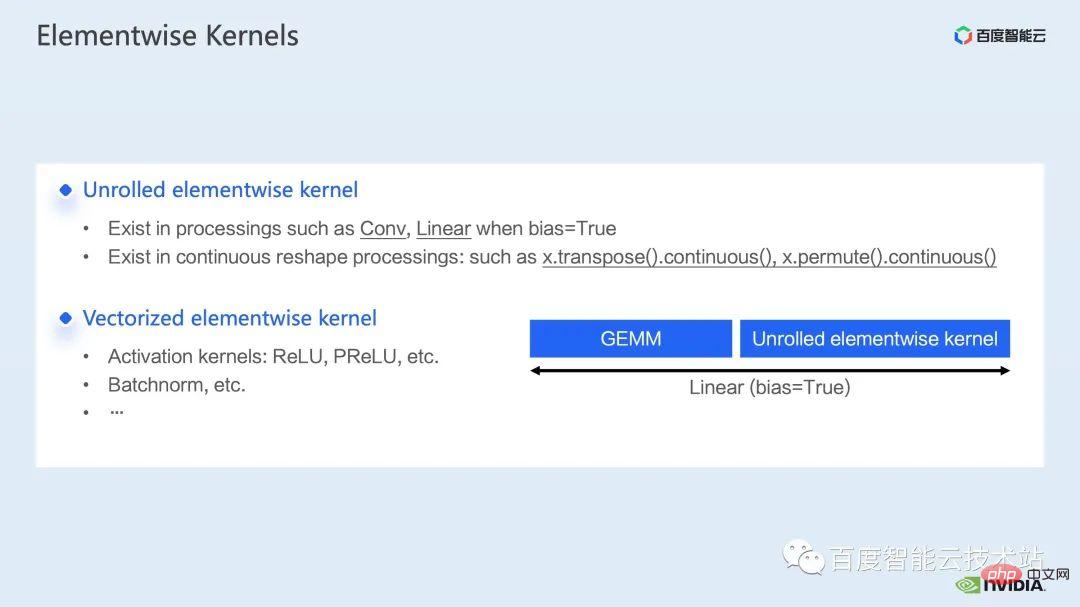
Pour le noyau élémentaire, nous devons d'abord comprendre où le noyau élémentaire sera utilisé.
Noyau Elementwise, le noyau élémentaire déroulé le plus courant et le noyau élémentaire vectorisé. Parmi eux, le noyau élément par élément déroulé est largement présent dans certaines convolutions biaisées ou couches linéaires, ainsi que dans certaines opérations qui assurent la continuité des données en mémoire.
Le noyau élémentaire vectorisé apparaît souvent dans le calcul de certaines fonctions d'activation, telles que ReLU. Si vous souhaitez réduire le grand nombre de noyaux élément par élément ici, une approche courante consiste à effectuer une fusion d'opérateurs. Par exemple, dans la multiplication matricielle, nous pouvons réduire cette partie du temps supplémentaire en fusionnant l'opération élément par élément avec l'opérateur de multiplication matricielle.
D'une manière générale, la fusion d'opérateurs peut nous apporter deux avantages :
L'un est de réduire le coût de lancement du noyau, comme le montre la figure ci-dessous, deux noyaux cuda L'exécution nécessite deux lancements , ce qui peut provoquer un écart entre les noyaux et rendre le GPU inactif. Si nous fusionnons deux noyaux cuda en un seul noyau cuda, d'une part, nous enregistrons un lancement, et en même temps, nous pouvons éviter la génération d'intervalles.
Un autre avantage est que cela réduit l'accès à la mémoire globale, car l'accès à la mémoire globale prend beaucoup de temps et le transfert des résultats entre deux noyaux cuda indépendants nécessite une fusion dans un noyau, nous pouvons transférer les résultats dans des registres ou une mémoire partagée, évitant ainsi une écriture et une lecture de mémoire globale et améliorant les performances.

Pour la fusion d'opérateurs, notre première étape consiste à utiliser la bibliothèque apex prête à l'emploi pour fusionner les opérations dans Layernorm et Adam. On peut voir que grâce à un simple remplacement d'instructions, nous pouvons activer la layernorm fusionnée. du sommet et Adam fusionné, augmentant ainsi l'accélération de 1,63x à 2,11x.

Nous pouvons également voir dans le journal de profilage qu'après la fusion des opérateurs, la proportion de noyau élément par élément dans cette chronologie a été considérablement réduite et la multiplication matricielle est redevenue le noyau avec la plus grande proportion de temps. .
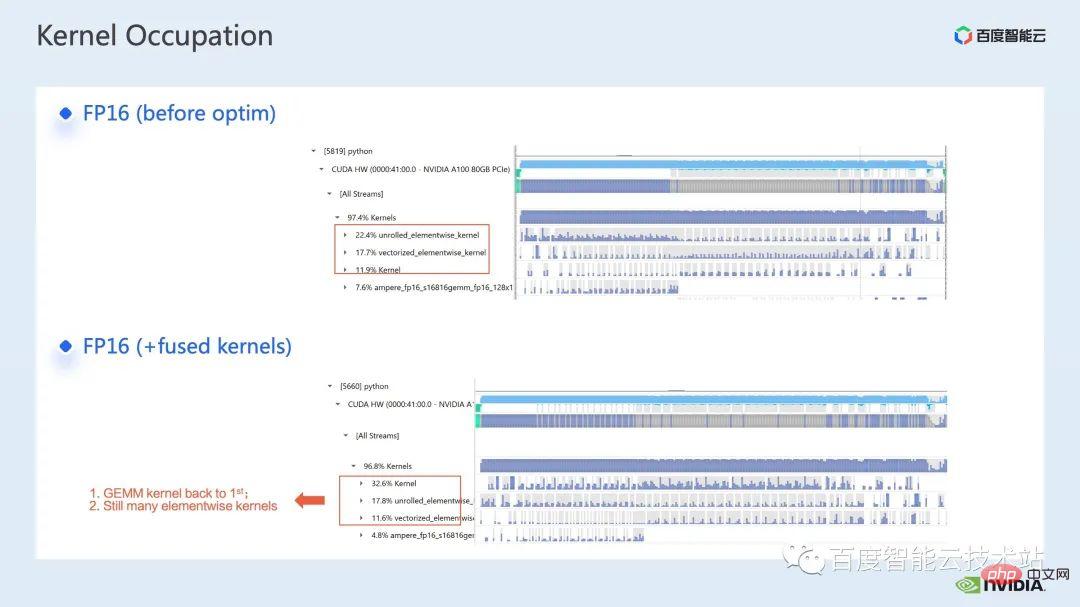
En plus d'utiliser la bibliothèque apex existante, nous avons également développé des opérateurs de fusion manuels.
En observant la chronologie et en comprenant le modèle, nous avons constaté qu'il existe des opérations uniques liées aux fenêtres dans Swin Transformer, telles que la partition/le décalage/la fusion de fenêtre, etc. Un décalage de fenêtre nécessite ici l'appel de deux noyaux, et Le noyau élément par élément est appelé une fois le décalage terminé. De plus, si une telle opération doit être effectuée avant le module d'attention, il y aura ensuite une opération inverse correspondante. Ici, le roll_cuda_kernel appelé par window shift représente à lui seul 4,6% de la timeline totale.
Les opérations que nous venons de mentionner consistent en fait à diviser les données, c'est-à-dire que les données correspondantes seront divisées dans une fenêtre. Le code original correspondant est tel qu'indiqué dans la figure ci-dessous.

Nous avons constaté que cette partie de l'opération n'est en fait qu'un simple mappage d'index, nous avons donc développé l'opérateur de fusion pour cette partie. Au cours du processus de développement, nous devons maîtriser les connaissances pertinentes de la programmation CUDA et écrire des codes pertinents pour le calcul direct et le calcul inverse des opérateurs.
Comment introduire des opérateurs personnalisés dans pytorch, le tutoriel officiel est donné Nous pouvons suivre le tutoriel pour écrire du code CUDA, et après compilation, nous pouvons introduire le modèle original en tant que module. On peut voir qu’en introduisant notre opérateur de fusion personnalisé, nous pouvons encore augmenter la vitesse jusqu’à 2,19 fois.

La prochaine chose que nous montrons est notre travail de fusion sur la partie mha.
La partie Mha est un grand module dans le modèle de transformateur, donc son optimisation peut souvent entraîner des effets d'accélération plus importants. Comme le montre la figure, avant que la fusion des opérateurs ne soit effectuée, la proportion d'opérations dans la partie mha est de 37,69 %, ce qui inclut de nombreux noyaux élémentaires. Si nous pouvons fusionner les opérations associées dans un noyau séparé avec une vitesse plus rapide, l'accélération peut être encore améliorée.
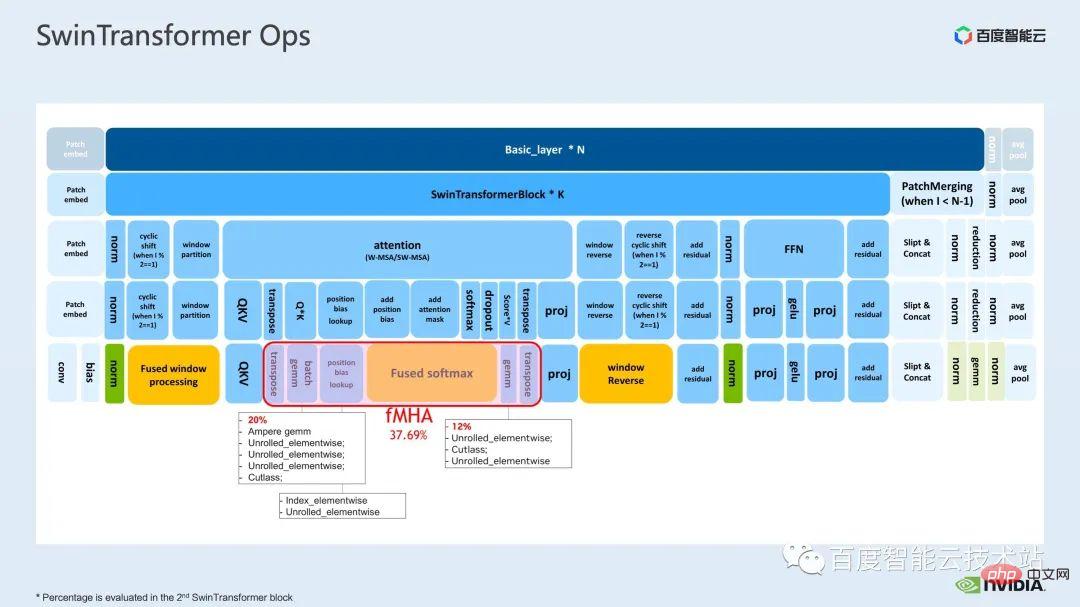
Pour Swin Transformer, en plus de la requête, de la clé et de la valeur, du masque et du biais sont tous transmis sous forme de tenseur. Nous avons développé un module comme fMHA, qui peut intégrer plusieurs noyaux originaux. À en juger par les calculs impliqués dans le module fMHA, ce module a considérablement amélioré certaines formes rencontrées dans Swin Transformer.

Après avoir utilisé le module fMHA dans le modèle, nous pouvons encore augmenter le taux d'accélération de 2, 85 fois. Ce qui précède est l'effet d'accélération de la formation que nous avons obtenu sur une seule carte. Jetons un coup d'œil à la situation de formation avec 8 cartes sur une seule machine. Nous pouvons voir que grâce à l'optimisation ci-dessus, nous pouvons augmenter le débit de formation de 1612 à 3733. atteignant une accélération de 2,32 fois.

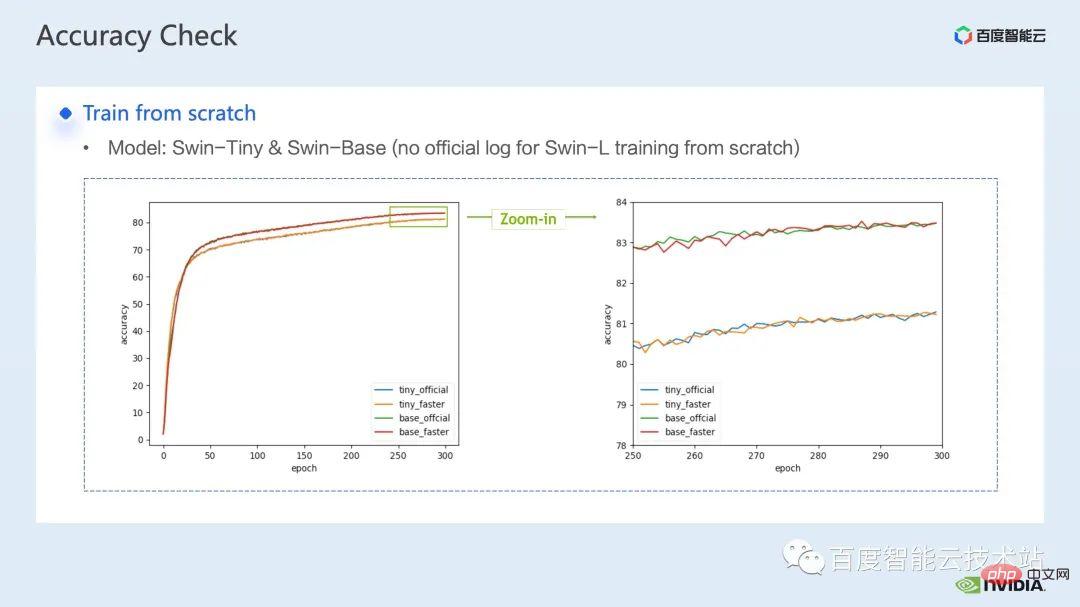
Pour l'optimisation de l'entraînement, nous espérons que le taux d'accélération sera aussi élevé que possible. En conséquence, nous espérons également que les performances après l'accélération pourront être cohérentes avec celles avant l'accélération.
Après avoir superposé les plusieurs solutions d'accélération ci-dessus, nous pouvons voir que la convergence du modèle est cohérente avec la ligne de base d'origine. La convergence et la précision du modèle avant et après l'optimisation sont cohérentes dans Swin-Tiny, Swin-. Base et All éprouvés sur Swin-Large.
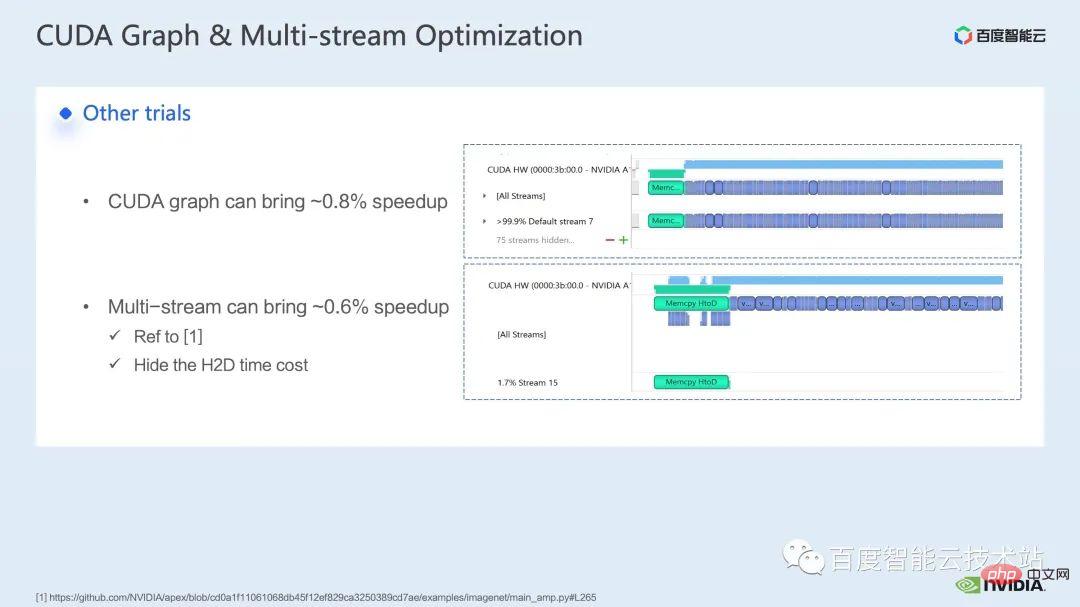
Concernant la partie formation, certaines autres stratégies d'accélération, notamment le graphe CUDA, le multi-stream, etc. peuvent encore améliorer les performances de Swin Transformer dans d'autres aspects, nous introduisons actuellement l'utilisation de la précision mixte ; La solution est la stratégie adoptée par le dépôt officiel de Swin Transformer ; l'utilisation de la solution fp16 pure (c'est-à-dire le mode apex O2) peut obtenir une accélération plus rapide.
Bien que Swin n'ait pas d'exigences de communication élevées, pour la formation de grands modèles multi-nœuds, par rapport à la formation distribuée originale, l'utilisation de stratégies raisonnables pour masquer la surcharge de communication peut obtenir de meilleurs résultats dans la formation multi-cartes. gains.
Ensuite, j'aimerais demander à mes collègues de présenter nos solutions d'accélération et nos effets en inférence.
3. Optimisation de l'inférence Swin Transformer
Bonjour à tous, je suis Chen Yu de l'équipe d'experts en calcul GPU NVIDIA Merci beaucoup pour l'introduction de Tao Li sur l'accélération de la formation. Introduisons l'accélération du raisonnement.
Semblable à la formation, l'accélération de l'inférence est indissociable de la solution de fusion d'opérateurs. Cependant, par rapport à la formation, la fusion d'opérateurs dans l'inférence a une meilleure flexibilité, ce qui se reflète principalement sur deux points :
- La fusion d'opérateurs dans l'inférence n'a pas besoin de prendre en compte la direction inverse, donc le processus de développement du noyau Il n'y a pas il faut envisager de sauvegarder les résultats intermédiaires nécessaires au calcul du gradient ;
- Le processus d'inférence permet un prétraitement. Nous pouvons calculer certaines opérations qui ne nécessitent qu'un seul calcul et peuvent être réutilisées à l'avance, conserver les résultats et effectuer une inférence à chaque fois. temps. Appelez-le directement pour éviter le double calcul.
Du côté de l'inférence, nous pouvons effectuer de nombreuses fusions d'opérateurs. Voici quelques modèles de fusion d'opérateurs courants que nous utilisons dans le modèle Transformer et les outils nécessaires pour implémenter les modèles associés.
Tout d'abord, nous listons séparément la multiplication matricielle et la convolution car il existe une grande classe d'opérateurs de fusion qui tourne autour d'eux. Pour la fusion liée à la multiplication matricielle, nous pouvons envisager d'utiliser trois bibliothèques : cublas, cutlass et cudnn ; convolution, on peut utiliser du cudnn ou du coutelas. Ainsi pour la fusion d'opérateurs de multiplication matricielle, dans le modèle Transformer, nous la résumons comme des opérations gemm + élément par élément, telles que gemm + biais, gemm + biais + fonction d'activation, etc. Pour ce type de fusion d'opérateurs, nous pouvons considérer directement Appeler cublas ou coutelas pour y parvenir.
De plus, si les opérations op après notre gemm sont plus complexes, comme layernorm, transpose, etc., nous pouvons envisager de séparer gemm et biais, puis d'intégrer le biais dans l'opération suivante, afin qu'elle puisse être appelé plus facilement cublas est utilisé pour implémenter une multiplication matricielle simple. Bien sûr, ce modèle d'intégration du biais avec l'opération suivante nous oblige généralement à écrire un noyau cuda manuscrit pour l'implémenter.
Enfin, certaines opérations spécifiques nous obligent également à les fusionner en écrivant à la main le noyau cuda, comme layernorm + shift + window partition.
Étant donné que la fusion d'opérateurs nous oblige à concevoir le noyau cuda avec plus d'habileté, nous recommandons généralement d'analyser d'abord le pipeline global via l'outil d'analyse des performances du système nsight, et de donner la priorité à l'optimisation de la fusion d'opérateurs pour les modules hotspot afin d'atteindre les performances et l'équilibre de la charge de travail.

Ainsi, parmi les nombreuses optimisations de fusion d'opérateurs, nous avons sélectionné deux opérateurs avec des effets d'accélération évidents à introduire.
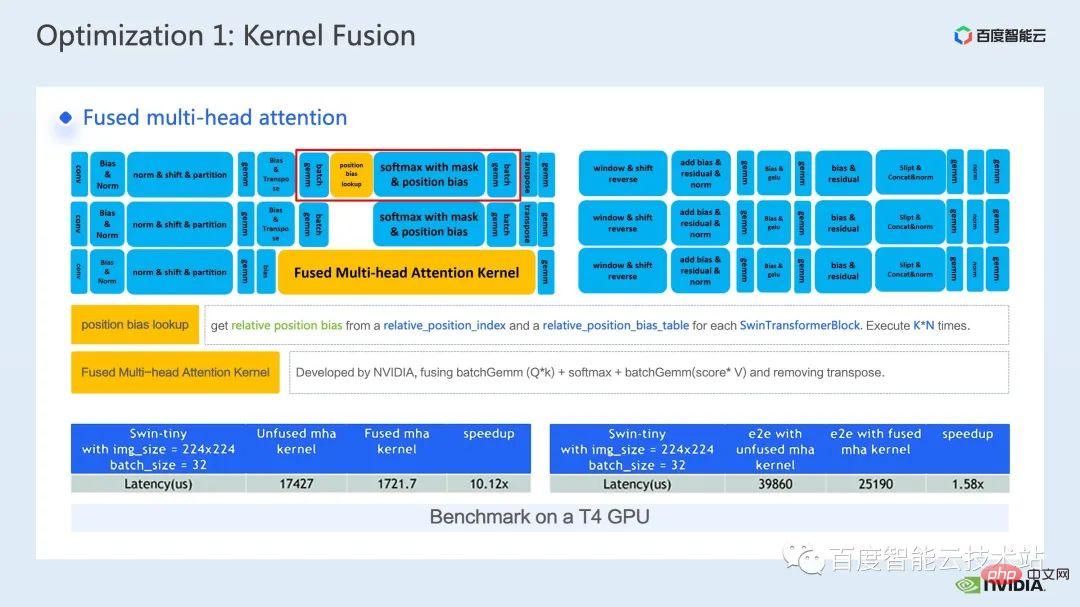
Le premier est la fusion opérateur de la partie mha. Nous avançons l'opération de recherche de biais de position vers la partie de prétraitement pour éviter d'effectuer une recherche à chaque fois que nous déduisons.
Ensuite, nous intégrons batch gemm, softmax et batch gemm dans un noyau fMHA indépendant. En même temps, nous intégrons les opérations liées à la transposition dans les opérations d'E/S du noyau fMHA et les évitons grâce à certains modèles de lecture et d'écriture de données. Opérations de transposition explicites.
On peut voir qu'après la fusion, cette pièce a atteint une accélération de 10x, et l'accélération de bout en bout a également été atteinte de 1,58x.
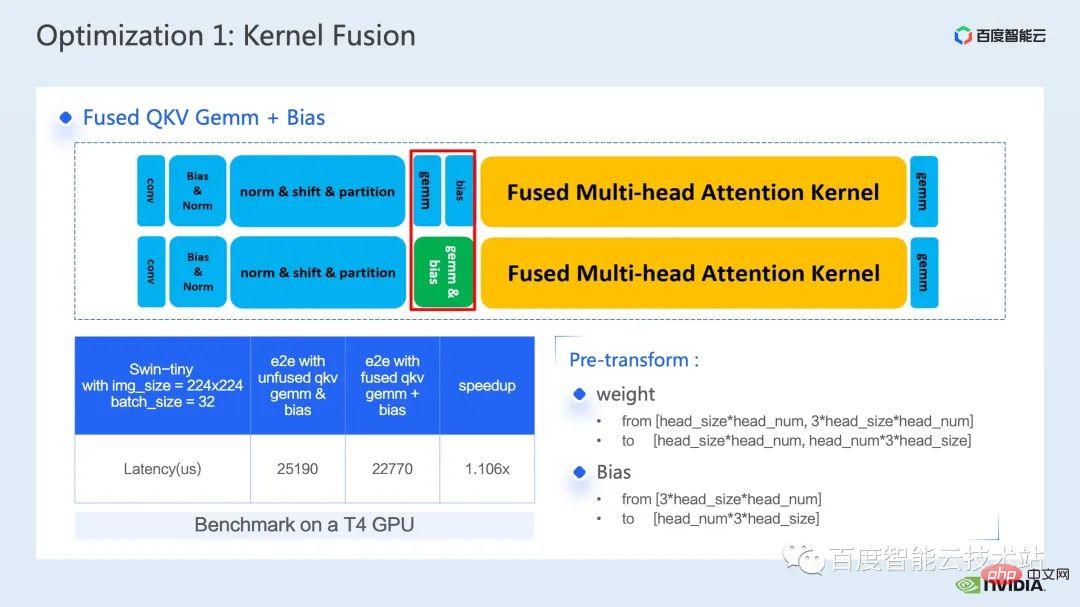
Une autre fusion d'opérateurs que je souhaite présenter est la fusion de QKV gemm + biais.
La fusion de gemm et de biais est une méthode de fusion très courante. Ici, afin de coopérer avec le noyau fMHA que nous avons mentionné plus tôt, nous devons formater le poids et le biais à l'avance.
La raison pour laquelle j'ai choisi d'introduire cette fusion d'opérateurs ici est précisément parce que cette transformation avancée reflète la flexibilité de la fusion d'opérateurs dans le raisonnement comme nous l'avons mentionné plus tôt, et nous pouvons raisonner sur le modèle. Le processus apporte quelques changements qui font n'affecte pas sa précision, afin d'obtenir de meilleurs modèles de fusion d'opérateur et d'obtenir de meilleurs effets d'accélération.
Enfin, grâce à l'intégration de QKV gemm+bias, nous pouvons atteindre une accélération de bout en bout de 1,1 fois.
La prochaine méthode d'optimisation est le remplissage par multiplication matricielle.
Dans le calcul de Swin Transformer, nous rencontrons parfois une multiplication matricielle avec une dimension principale impaire. À l'heure actuelle, il n'est pas propice à notre noyau de multiplication matricielle pour effectuer une lecture et une écriture vectorisées, de sorte que cela réduit l'efficacité de fonctionnement du noyau. À ce stade, nous pouvons envisager de remplir les principales dimensions de la matrice participant à l'opération pour en faire un multiple de 8. De cette façon, le noyau de multiplication matricielle peut utiliser l'alignement = 8 et lire et écrire 8 à la fois. Chaque élément est utilisé pour effectuer une lecture et une écriture vectorisées pour améliorer les performances.
Comme le montre le tableau ci-dessous, après avoir complété n de 49 à 56, la latence de multiplication matricielle est passée de 60,54us à 40,38us, atteignant un rapport d'accélération de 1,5 fois.

La prochaine méthode d'optimisation consiste à utiliser des types de données tels que half2 ou char4 .
Le code suivant est un exemple d'optimisation half2. Il implémente un calcul simple d'ajout de biais et d'ajout de résidu pour le sous-. opération de fusion, nous pouvons voir qu'en utilisant le type de données half2, par rapport à la classe de données half, nous pouvons réduire la latence de 20,96us à 10,78us, soit une accélération de 1,94 fois.
Alors, quels sont les avantages généraux de l'utilisation du type de données half2 ? Il y a trois points principaux :
Le premier avantage est que la lecture et l'écriture vectorisées peuvent améliorer l'efficacité d'utilisation de la bande passante de la mémoire et réduire le nombre d'instructions d'accès à la mémoire. ; Comme le montre le côté droit de la figure ci-dessous, grâce à l'utilisation de half2, les instructions d'accès à la mémoire sont réduites de moitié et le SOL de la mémoire est également considérablement amélioré 🎜#Le deuxième avantage est que ; combiné aux instructions mathématiques à haut débit propriétaires de half2, la latence du noyau peut être réduite. Ces deux points ont été reflétés dans cet exemple de programme ; l'utilisation du type de données half2 signifie qu'un thread CUDA traite deux éléments en même temps, ce qui peut réduire efficacement le nombre de threads inactifs et la latence de synchronisation des threads.
La prochaine méthode d'optimisation consiste à utiliser intelligemment le tableau de registres.
Lorsque nous optimisons les opérateurs courants des modèles Transformer tels que layernorm ou softmax, nous devons souvent les utiliser plusieurs fois dans un noyau. les mêmes données d'entrée, au lieu de lire à chaque fois dans la mémoire globale, nous pouvons utiliser un tableau de registres pour mettre les données en cache, évitant ainsi une lecture répétée de la mémoire globale.

Étant donné que le registre est exclusif à chaque thread cuda, lors de la conception du noyau, nous devons définir chaque cuda à l'avance Le nombre de éléments que le thread doit mettre en cache, afin d'ouvrir un tableau de registres de taille correspondante, et lors de l'allocation des éléments responsables de chaque thread cuda, nous devons nous assurer que nous pouvons obtenir un accès combiné, comme indiqué dans le coin supérieur droit de la figure ci-dessous, quand on a 8 Lorsqu'il y a des threads, le thread n°0 peut traiter l'élément n°0. Quand on a 4 threads, le thread n°0 peut traiter les éléments n°0 et n°4, et ainsi de suite.
Nous recommandons généralement d'utiliser des fonctions de modèle pour contrôler la taille du tableau de registres de chaque thread cuda via les paramètres du modèle.
De plus, lorsque vous utilisez le tableau de registres, vous Nous devons nous assurer que notre indice est une constante.Si une variable de boucle est utilisée comme indice, nous devons essayer de nous assurer que la boucle peut être étendue, afin d'éviter que le compilateur ne place des données dans la mémoire locale avec une latence élevée. Dans la figure ci-dessous, nous sommes dans la condition de boucle Ajouter des restrictions, visibles via le rapport ncu, pour éviter l'utilisation de la mémoire locale.
La dernière méthode d'optimisation que je souhaite présenter est la quantification INT8.
La quantification INT8 est une méthode d'accélération très importante pour l'accélération d'inférence. Pour les modèles basés sur Transformer, la quantification INT8 peut réduire la consommation de mémoire tout en apportant de meilleures performances.
Pour Swin, en combinant un schéma de quantification PTQ ou QAT approprié, vous pouvez obtenir une bonne accélération tout en garantissant la précision de la quantification. Généralement, nous effectuons la quantification int8, principalement pour quantifier la multiplication matricielle ou la convolution. Par exemple, dans la multiplication matricielle int8, nous quantifierons d'abord l'entrée FP32 ou FP16 d'origine et la pondérerons dans INT8, puis effectuerons la multiplication matricielle INT8 et accumulerons les données de type INT32. -c'est ici que nous effectuerions une opération de quantification inverse et obtiendrons le résultat de FP32 ou FP16.

L'outil le plus courant pour appeler la multiplication matricielle INT8 est cublasLt. Afin d'obtenir de meilleures performances, nous devons avoir une compréhension approfondie de certaines fonctionnalités de l'API cublasLt.
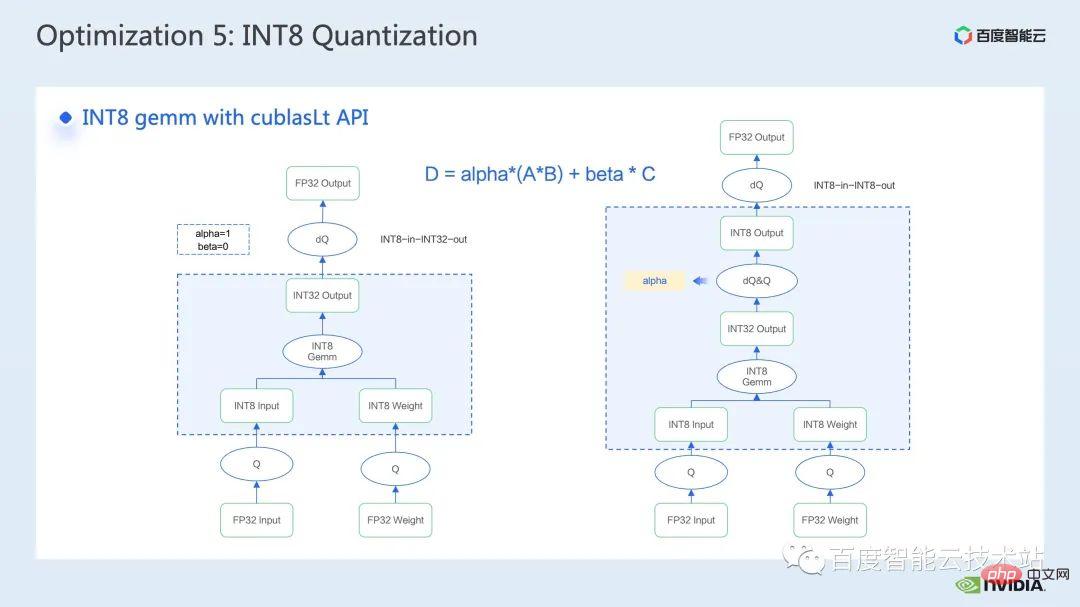
cublasLt Pour la multiplication matricielle int8, deux types de sortie sont fournis, qui sont comme indiqué sur le côté gauche de la figure ci-dessous, sortie comme INT32, ou comme indiqué sur le côté droit de la figure ci-dessous, sortie comme INT8 , comme le montre l'encadré bleu de la figure L'opération de calcul de cublasLt.
Vous pouvez voir que par rapport à la sortie INT32, la sortie INT8 aura une paire supplémentaire d'opérations de quantification inverse et de quantification, ce qui entraînera généralement plus de pertes de précision, cependant, en raison de la sortie INT8, lors de l'écriture lors du passage au global. mémoire, la quantité de données produites est 3/4 inférieure à celle de INT32, et les performances seront meilleures, il y a donc un compromis entre précision et performances.
Donc, pour Swin Transformer, nous avons constaté qu'en conjonction avec QAT, la sortie en INT8 garantira la précision dans le but d'atteindre un bon rapport d'accélération, car nous avons adopté la solution de sortie INT8.
De plus, concernant la multiplication matricielle INT8 dans cublasLt, vous devez également considérer la disposition des données cublasLt prend en charge deux mises en page, une mise en page spécifique à IMMA, qui implique des formats plus complexes. De plus, cette mise en page ne prend en charge que NT-gemm, et l'autre est une mise en page conventionnelle en première colonne, qui prend en charge TN-gemm.
De manière générale, l'utilisation de la disposition en première colonne sera plus propice au développement de l'ensemble du code du pipeline, car si nous utilisons une disposition spécifique à IMMA, nous pourrions avoir besoin de beaucoup d'opérations supplémentaires pour être compatible avec cette disposition, comme ainsi qu'en amont et en aval. Le noyau doit également être compatible avec cette disposition spéciale. Cependant, la disposition spécifique à IMMA peut avoir de meilleures performances sur la multiplication matricielle de certaines tailles, donc si nous voulons essayer de construire un raisonnement int8, il est recommandé de faire d'abord quelques tests pour mieux comprendre les performances et la facilité de développement. .
Dans FasterTransformer, nous utilisons une mise en page spécifique à IMMA. Nous prenons donc ensuite la disposition spécifique à IMMA comme exemple pour présenter brièvement le processus de construction de base de la multiplication matricielle cublasLt int8, ainsi que certaines techniques de développement.

cublasLt int8 Le processus de construction de base de la multiplication matricielle peut être divisé en 5 étapes :
- Nous devons d'abord créer des poignées et des descripteurs de multiplication ;
- Ensuite, nous créons un descripteur de matrice pour chaque matrice
- Par conséquent, nous devons ; effectuer une conversion de mise en page sur la matrice de mise en page conventionnelle pour en faire une mise en page spécifique à IMMA ;
- puis effectuer une multiplication matricielle int8. Après avoir obtenu le résultat, nous pouvons envisager de continuer à utiliser ce résultat pour le calcul de multiplication en aval, cela peut. évitez les frais généraux liés à la conversion en mise en page normale ;
- Seul le résultat de la dernière multiplication matricielle, nous devons le convertir en mise en page normale pour la sortie.
Ce qui précède présente le processus de construction sous une disposition spécifique à l'IMMA. Vous pouvez voir qu'il existe de nombreuses restrictions. Afin d'éviter l'impact de ces limitations sur les performances, nous avons adopté les techniques suivantes dans Faster Transformer :
- Tout d'abord, la mise en page spécifique à IMMA a des exigences de taille spécifiques pour la matrice, afin d'éviter la nécessité d'une allocation d'espace supplémentaire pendant le processus d'inférence Pour le fonctionnement, nous allouerons à l'avance un tampon conforme à la taille de mise en page spécifique à IMMA
- Ensuite, puisque le poids peut être traité et réutilisé une fois, nous le ferons effectuez une transformation de mise en page sur le poids (équivalent à la matrice B en multiplication) à l'avance, pour éviter de changer le poids à plusieurs reprises pendant le processus de raisonnement
- Le troisième conseil est celui pour A et C qui doivent subir une transformation de mise en page spéciale ; , nous effectuerons une fusion d'opérateur de la transformation avec l'op amont ou aval afin de masquer le surcoût de cette partie
- Le dernier point n'a rien à voir avec la mise en page, mais les opérations de quantification et de quantification inverse qui sont nécessaires à la multiplication de la matrice int8. Nous utiliserons également l'opérateur fusion pour masquer sa latence.

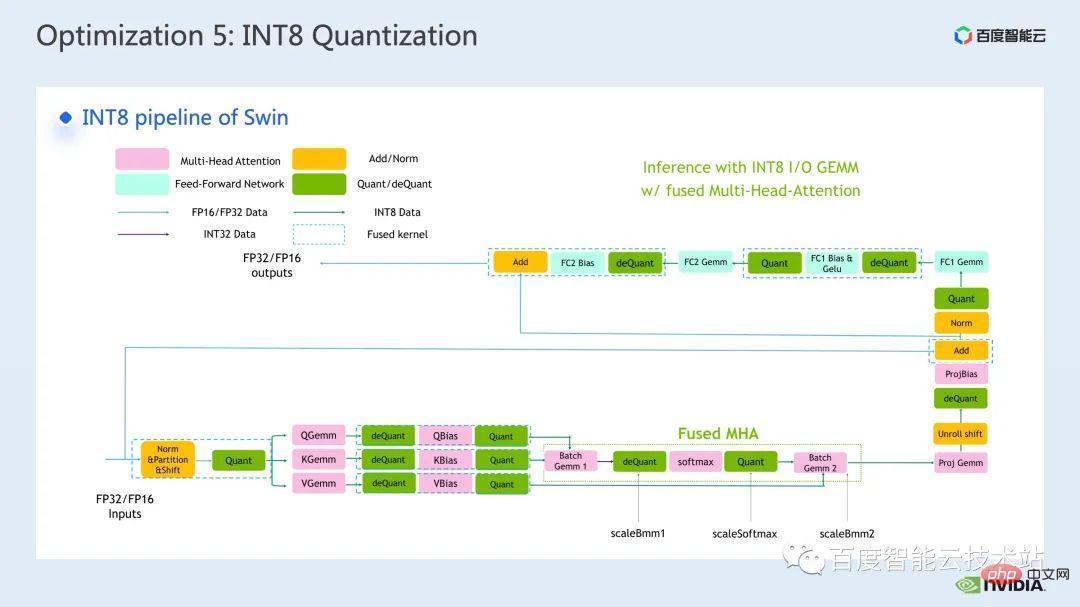
Ce qui suit est un diagramme schématique du processus INT8 que nous utilisons dans Faster Transformer. Vous pouvez voir que toutes les multiplications matricielles sont devenues des types de données int8 et que la quantification correspondante sera insérée avant et après chaque int8. la multiplication matricielle et les nœuds de quantification inverse, et pour les opérations telles que l'ajout de biais, l'ajout de résidus ou la norme de couche, nous conservons toujours le type de données d'origine FP32 ou FP16. Bien sûr, ses E/S peuvent être int8, qui aura de meilleures E/S. performances que FP16 ou FP32 Soyez bon.
Ce qui est montré ici est la précision de la quantification Swin Transformer int8 Grâce à QAT, nous pouvons garantir que la perte de précision est inférieure à 5 millièmes.
Dans la colonne PTQ, on peut voir que la chute de points de Swin-Large est plus grave. Généralement, correspondant au problème de chute de points sérieuse, on peut envisager de réduire certains nœuds de quantification pour améliorer la précision de la quantification. Bien entendu, cela peut conduire à un affaiblissement de l'effet d'accélération.
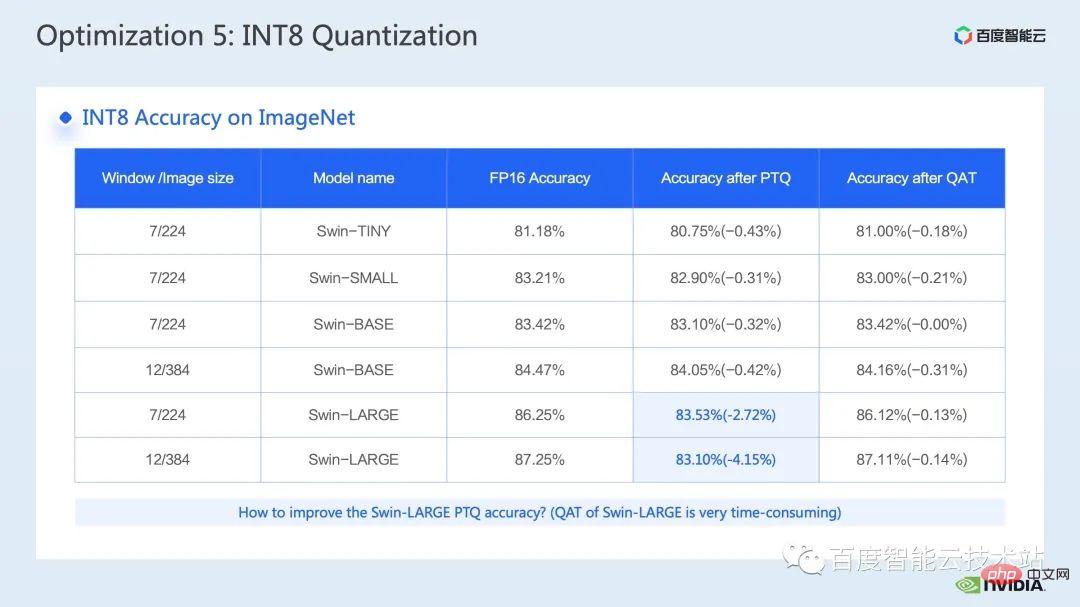
Dans FT, nous pouvons encore améliorer la précision de la quantification en désactivant la quantification inverse et les nœuds de quantification avant la sortie int8 de la multiplication matricielle int 8 dans FC2 et PatchMerge (c'est-à-dire en utilisant la sortie int32), vous On peut voir que dans le cadre de cette opération d'optimisation, la précision PTQ de swin-large a également été considérablement améliorée.

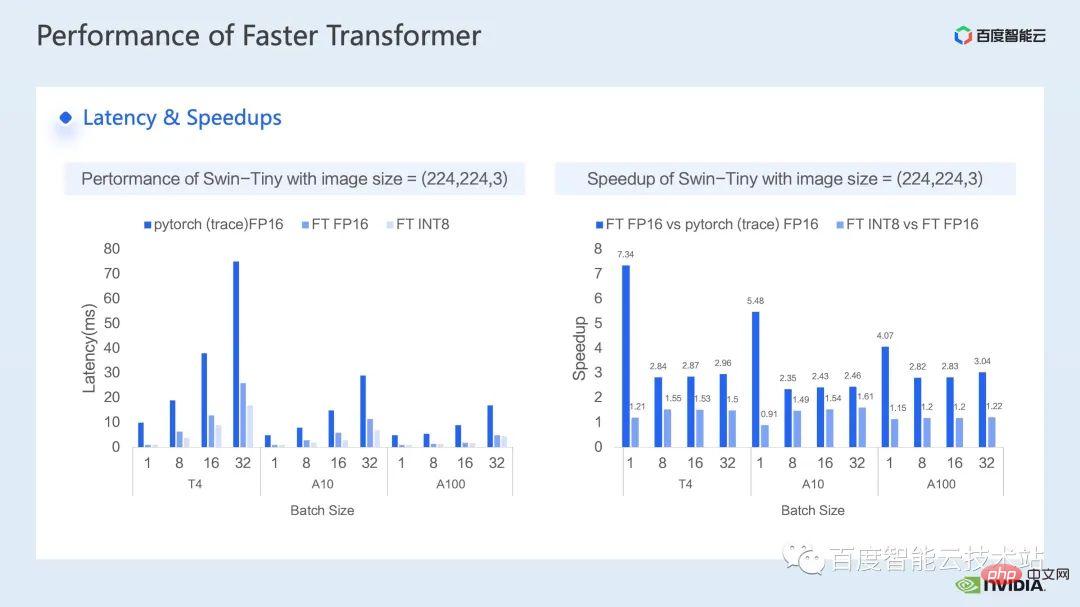
Le prochain est l'effet d'accélération que nous avons obtenu du côté de l'inférence. Nous avons comparé les performances avec pytorch FP16 sur différents modèles de GPU T4, A10 et A100.
Le côté gauche de la figure ci-dessous montre la comparaison de latence entre l'optimisation et pytorch, et la figure de droite montre le rapport d'accélération entre FP16 et pytorch après optimisation, et le rapport d'accélération entre l'optimisation INT8 et l'optimisation FP16. On peut voir que grâce à l'optimisation, nous pouvons obtenir une accélération de 2,82x ~ 7,34x par rapport à pytorch en termes de précision FP16. En combinaison avec la quantification INT8, nous pouvons en outre atteindre une accélération de 1,2x ~ 1,5x sur cette base.
4. Résumé de l'optimisation de Swin Transformer
Enfin, résumons dans ce partage, nous avons présenté comment trouver les goulots d'étranglement des performances via l'outil d'analyse des performances du système nsight, puis cibler. performance Bottleneck, présente une série de techniques d'accélération de l'inférence de formation, notamment 1. Entraînement de précision mixte/inférence de faible précision, 2. Fusion d'opérateurs, 3. Techniques d'optimisation du noyau cuda : telles que le remplissage nul matriciel, la lecture et l'écriture vectorisées et l'utilisation intelligente de tableaux de registres, etc., 4. Certains prétraitements sont utilisés pour l'optimisation de l'inférence afin d'améliorer notre processus de calcul, nous avons également introduit certaines applications de graphe multi-flux et cuda ;
En combinaison avec l'optimisation ci-dessus, nous avons utilisé le modèle Swin-Large comme exemple pour obtenir un rapport d'accélération de 2,85x pour une seule carte et de 2,32x pour un modèle à 8 cartes pour l'inférence, nous avons utilisé le ; Modèle Swin-tiny à titre d'exemple. Par exemple, avec la précision FP16, un rapport d'accélération de 2,82x ~ 7,34x a été obtenu. En combinaison avec la quantification INT8, un rapport d'accélération supplémentaire de 1,2x ~ 1,5x a été obtenu.

Les méthodes d'accélération ci-dessus pour la formation et l'inférence de grands modèles visuels ont été implémentées dans la fonction d'accélération AIAK de la plate-forme informatique hétérogène Baidu Baige AI.

Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Le modèle MoE open source le plus puissant au monde est ici, avec des capacités chinoises comparables à celles du GPT-4, et le prix ne représente que près d'un pour cent de celui du GPT-4-Turbo.
May 07, 2024 pm 04:13 PM
Le modèle MoE open source le plus puissant au monde est ici, avec des capacités chinoises comparables à celles du GPT-4, et le prix ne représente que près d'un pour cent de celui du GPT-4-Turbo.
May 07, 2024 pm 04:13 PM
Imaginez un modèle d'intelligence artificielle qui non seulement a la capacité de surpasser l'informatique traditionnelle, mais qui permet également d'obtenir des performances plus efficaces à moindre coût. Ce n'est pas de la science-fiction, DeepSeek-V2[1], le modèle MoE open source le plus puissant au monde est ici. DeepSeek-V2 est un puissant mélange de modèle de langage d'experts (MoE) présentant les caractéristiques d'une formation économique et d'une inférence efficace. Il est constitué de 236B paramètres, dont 21B servent à activer chaque marqueur. Par rapport à DeepSeek67B, DeepSeek-V2 offre des performances plus élevées, tout en économisant 42,5 % des coûts de formation, en réduisant le cache KV de 93,3 % et en augmentant le débit de génération maximal à 5,76 fois. DeepSeek est une entreprise explorant l'intelligence artificielle générale
 L'IA bouleverse la recherche mathématique ! Le lauréat de la médaille Fields et mathématicien sino-américain a dirigé 11 articles les mieux classés | Aimé par Terence Tao
Apr 09, 2024 am 11:52 AM
L'IA bouleverse la recherche mathématique ! Le lauréat de la médaille Fields et mathématicien sino-américain a dirigé 11 articles les mieux classés | Aimé par Terence Tao
Apr 09, 2024 am 11:52 AM
L’IA change effectivement les mathématiques. Récemment, Tao Zhexuan, qui a prêté une attention particulière à cette question, a transmis le dernier numéro du « Bulletin de l'American Mathematical Society » (Bulletin de l'American Mathematical Society). En se concentrant sur le thème « Les machines changeront-elles les mathématiques ? », de nombreux mathématiciens ont exprimé leurs opinions. L'ensemble du processus a été plein d'étincelles, intense et passionnant. L'auteur dispose d'une équipe solide, comprenant Akshay Venkatesh, lauréat de la médaille Fields, le mathématicien chinois Zheng Lejun, l'informaticien de l'Université de New York Ernest Davis et de nombreux autres universitaires bien connus du secteur. Le monde de l’IA a radicalement changé. Vous savez, bon nombre de ces articles ont été soumis il y a un an.
 KAN, qui remplace MLP, a été étendu à la convolution par des projets open source
Jun 01, 2024 pm 10:03 PM
KAN, qui remplace MLP, a été étendu à la convolution par des projets open source
Jun 01, 2024 pm 10:03 PM
Plus tôt ce mois-ci, des chercheurs du MIT et d'autres institutions ont proposé une alternative très prometteuse au MLP – KAN. KAN surpasse MLP en termes de précision et d’interprétabilité. Et il peut surpasser le MLP fonctionnant avec un plus grand nombre de paramètres avec un très petit nombre de paramètres. Par exemple, les auteurs ont déclaré avoir utilisé KAN pour reproduire les résultats de DeepMind avec un réseau plus petit et un degré d'automatisation plus élevé. Plus précisément, le MLP de DeepMind compte environ 300 000 paramètres, tandis que le KAN n'en compte qu'environ 200. KAN a une base mathématique solide comme MLP est basé sur le théorème d'approximation universelle, tandis que KAN est basé sur le théorème de représentation de Kolmogorov-Arnold. Comme le montre la figure ci-dessous, KAN a
 Bonjour, Atlas électrique ! Le robot Boston Dynamics revient à la vie, des mouvements étranges à 180 degrés effraient Musk
Apr 18, 2024 pm 07:58 PM
Bonjour, Atlas électrique ! Le robot Boston Dynamics revient à la vie, des mouvements étranges à 180 degrés effraient Musk
Apr 18, 2024 pm 07:58 PM
Boston Dynamics Atlas entre officiellement dans l’ère des robots électriques ! Hier, l'Atlas hydraulique s'est retiré "en larmes" de la scène de l'histoire. Aujourd'hui, Boston Dynamics a annoncé que l'Atlas électrique était au travail. Il semble que dans le domaine des robots humanoïdes commerciaux, Boston Dynamics soit déterminé à concurrencer Tesla. Après la sortie de la nouvelle vidéo, elle a déjà été visionnée par plus d’un million de personnes en seulement dix heures. Les personnes âgées partent et de nouveaux rôles apparaissent. C'est une nécessité historique. Il ne fait aucun doute que cette année est l’année explosive des robots humanoïdes. Les internautes ont commenté : Les progrès des robots ont fait ressembler la cérémonie d'ouverture de cette année à des êtres humains, et le degré de liberté est bien plus grand que celui des humains. Mais n'est-ce vraiment pas un film d'horreur ? Au début de la vidéo, Atlas est allongé calmement sur le sol, apparemment sur le dos. Ce qui suit est à couper le souffle
 Au-delà d'ORB-SLAM3 ! SL-SLAM : les scènes de faible luminosité, de gigue importante et de texture faible sont toutes gérées
May 30, 2024 am 09:35 AM
Au-delà d'ORB-SLAM3 ! SL-SLAM : les scènes de faible luminosité, de gigue importante et de texture faible sont toutes gérées
May 30, 2024 am 09:35 AM
Écrit précédemment, nous discutons aujourd'hui de la manière dont la technologie d'apprentissage profond peut améliorer les performances du SLAM (localisation et cartographie simultanées) basé sur la vision dans des environnements complexes. En combinant des méthodes d'extraction de caractéristiques approfondies et de correspondance de profondeur, nous introduisons ici un système SLAM visuel hybride polyvalent conçu pour améliorer l'adaptation dans des scénarios difficiles tels que des conditions de faible luminosité, un éclairage dynamique, des zones faiblement texturées et une gigue importante. Notre système prend en charge plusieurs modes, notamment les configurations étendues monoculaire, stéréo, monoculaire-inertielle et stéréo-inertielle. En outre, il analyse également comment combiner le SLAM visuel avec des méthodes d’apprentissage profond pour inspirer d’autres recherches. Grâce à des expériences approfondies sur des ensembles de données publiques et des données auto-échantillonnées, nous démontrons la supériorité du SL-SLAM en termes de précision de positionnement et de robustesse du suivi.
 La version Kuaishou de Sora 'Ke Ling' est ouverte aux tests : génère plus de 120 s de vidéo, comprend mieux la physique et peut modéliser avec précision des mouvements complexes
Jun 11, 2024 am 09:51 AM
La version Kuaishou de Sora 'Ke Ling' est ouverte aux tests : génère plus de 120 s de vidéo, comprend mieux la physique et peut modéliser avec précision des mouvements complexes
Jun 11, 2024 am 09:51 AM
Quoi? Zootopie est-elle concrétisée par l’IA domestique ? Avec la vidéo est exposé un nouveau modèle de génération vidéo domestique à grande échelle appelé « Keling ». Sora utilise une voie technique similaire et combine un certain nombre d'innovations technologiques auto-développées pour produire des vidéos qui comportent non seulement des mouvements larges et raisonnables, mais qui simulent également les caractéristiques du monde physique et possèdent de fortes capacités de combinaison conceptuelle et d'imagination. Selon les données, Keling prend en charge la génération de vidéos ultra-longues allant jusqu'à 2 minutes à 30 ips, avec des résolutions allant jusqu'à 1080p, et prend en charge plusieurs formats d'image. Un autre point important est que Keling n'est pas une démo ou une démonstration de résultats vidéo publiée par le laboratoire, mais une application au niveau produit lancée par Kuaishou, un acteur leader dans le domaine de la vidéo courte. De plus, l'objectif principal est d'être pragmatique, de ne pas faire de chèques en blanc et de se mettre en ligne dès sa sortie. Le grand modèle de Ke Ling est déjà sorti à Kuaiying.
 La vitalité de la super intelligence s'éveille ! Mais avec l'arrivée de l'IA qui se met à jour automatiquement, les mères n'ont plus à se soucier des goulots d'étranglement des données.
Apr 29, 2024 pm 06:55 PM
La vitalité de la super intelligence s'éveille ! Mais avec l'arrivée de l'IA qui se met à jour automatiquement, les mères n'ont plus à se soucier des goulots d'étranglement des données.
Apr 29, 2024 pm 06:55 PM
Je pleure à mort. Le monde construit à la folie de grands modèles. Les données sur Internet ne suffisent pas du tout. Le modèle de formation ressemble à « The Hunger Games », et les chercheurs en IA du monde entier se demandent comment nourrir ces personnes avides de données. Ce problème est particulièrement important dans les tâches multimodales. À une époque où rien ne pouvait être fait, une équipe de start-up du département de l'Université Renmin de Chine a utilisé son propre nouveau modèle pour devenir la première en Chine à faire de « l'auto-alimentation des données générées par le modèle » une réalité. De plus, il s’agit d’une approche à deux volets, du côté compréhension et du côté génération, les deux côtés peuvent générer de nouvelles données multimodales de haute qualité et fournir un retour de données au modèle lui-même. Qu'est-ce qu'un modèle ? Awaker 1.0, un grand modèle multimodal qui vient d'apparaître sur le Forum Zhongguancun. Qui est l'équipe ? Moteur Sophon. Fondé par Gao Yizhao, doctorant à la Hillhouse School of Artificial Intelligence de l’Université Renmin.
 L'US Air Force présente son premier avion de combat IA de grande envergure ! Le ministre a personnellement effectué l'essai routier sans intervenir pendant tout le processus, et 100 000 lignes de code ont été testées 21 fois.
May 07, 2024 pm 05:00 PM
L'US Air Force présente son premier avion de combat IA de grande envergure ! Le ministre a personnellement effectué l'essai routier sans intervenir pendant tout le processus, et 100 000 lignes de code ont été testées 21 fois.
May 07, 2024 pm 05:00 PM
Récemment, le milieu militaire a été submergé par la nouvelle : les avions de combat militaires américains peuvent désormais mener des combats aériens entièrement automatiques grâce à l'IA. Oui, tout récemment, l’avion de combat IA de l’armée américaine a été rendu public pour la première fois, dévoilant ainsi son mystère. Le nom complet de ce chasseur est Variable Stability Simulator Test Aircraft (VISTA). Il a été personnellement piloté par le secrétaire de l'US Air Force pour simuler une bataille aérienne en tête-à-tête. Le 2 mai, le secrétaire de l'US Air Force, Frank Kendall, a décollé à bord d'un X-62AVISTA à la base aérienne d'Edwards. Notez que pendant le vol d'une heure, toutes les actions de vol ont été effectuées de manière autonome par l'IA ! Kendall a déclaré : "Au cours des dernières décennies, nous avons réfléchi au potentiel illimité du combat air-air autonome, mais cela a toujours semblé hors de portée." Mais maintenant,
