
 développement back-end
Tutoriel Python
Comment utiliser CountVectorizer dans le sklearn de Python ?
développement back-end
Tutoriel Python
Comment utiliser CountVectorizer dans le sklearn de Python ?
Comment utiliser CountVectorizer dans le sklearn de Python ?

Introduction
Documentation officielle de CountVectorizer.
Vectorisez une collection de documents dans une matrice de comptage.
Si vous ne fournissez pas de dictionnaire a priori et n'utilisez pas d'analyseur pour effectuer une sorte de sélection de fonctionnalités, alors le nombre de fonctionnalités sera égal au vocabulaire découvert en analysant les données.
Prétraitement des données
Deux méthodes : 1. Vous pouvez les insérer directement dans le modèle sans segmentation de mots ; 2. Vous pouvez d'abord segmenter le texte chinois.
Le vocabulaire produit par les deux méthodes sera très différent. Des démonstrations spécifiques seront données ultérieurement.
import jieba
import re
from sklearn.feature_extraction.text import CountVectorizer
#原始数据
text = ['很少在公众场合手机外放',
'大部分人都还是很认真去学习的',
'他们会用行动来',
'无论你现在有多颓废,振作起来',
'只需要一点点地改变',
'你的外在和内在都能焕然一新']
#提取中文
text = [' '.join(re.findall('[\u4e00-\u9fa5]+',tt,re.S)) for tt in text]
#分词
text = [' '.join(jieba.lcut(tt)) for tt in text]
text
Construire le modèle
Entraîner le modèle
#构建模型 vectorizer = CountVectorizer() #训练模型 X = vectorizer.fit_transform(text)
Tout le vocabulaire : model.get_feature_names()
#所有文档汇集后生成的词汇 feature_names = vectorizer.get_feature_names() print(feature_names)
Vocabulaire généré sans segmentation de mots

Vocabulaire généré après la segmentation de mots

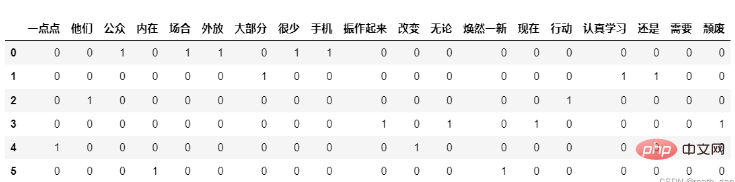
Matrice de comptage : X .toarray()
#每个文档相对词汇量出现次数形成的矩阵 matrix = X.toarray() print(matrix)

#计数矩阵转化为DataFrame df = pd.DataFrame(matrix, columns=feature_names) df
Index de vocabulaire : model.vocabulary_
print(vectorizer.vocabulary_)

Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Quelle est la raison pour laquelle PS continue de montrer le chargement?
Apr 06, 2025 pm 06:39 PM
Quelle est la raison pour laquelle PS continue de montrer le chargement?
Apr 06, 2025 pm 06:39 PM
Les problèmes de «chargement» PS sont causés par des problèmes d'accès aux ressources ou de traitement: la vitesse de lecture du disque dur est lente ou mauvaise: utilisez Crystaldiskinfo pour vérifier la santé du disque dur et remplacer le disque dur problématique. Mémoire insuffisante: améliorez la mémoire pour répondre aux besoins de PS pour les images à haute résolution et le traitement complexe de couche. Les pilotes de la carte graphique sont obsolètes ou corrompues: mettez à jour les pilotes pour optimiser la communication entre le PS et la carte graphique. Les chemins de fichier sont trop longs ou les noms de fichiers ont des caractères spéciaux: utilisez des chemins courts et évitez les caractères spéciaux. Problème du PS: réinstaller ou réparer le programme d'installation PS.
 Comment accélérer la vitesse de chargement de PS?
Apr 06, 2025 pm 06:27 PM
Comment accélérer la vitesse de chargement de PS?
Apr 06, 2025 pm 06:27 PM
La résolution du problème du démarrage lent Photoshop nécessite une approche à plusieurs volets, notamment: la mise à niveau du matériel (mémoire, lecteur à semi-conducteurs, CPU); des plug-ins désinstallés ou incompatibles; nettoyer régulièrement les déchets du système et des programmes de fond excessifs; clôture des programmes non pertinents avec prudence; Éviter d'ouvrir un grand nombre de fichiers pendant le démarrage.
 Comment résoudre le problème du chargement lorsque PS est démarré?
Apr 06, 2025 pm 06:36 PM
Comment résoudre le problème du chargement lorsque PS est démarré?
Apr 06, 2025 pm 06:36 PM
Un PS est coincé sur le "chargement" lors du démarrage peut être causé par diverses raisons: désactiver les plugins corrompus ou conflictuels. Supprimer ou renommer un fichier de configuration corrompu. Fermez des programmes inutiles ou améliorez la mémoire pour éviter une mémoire insuffisante. Passez à un entraînement à semi-conducteurs pour accélérer la lecture du disque dur. Réinstaller PS pour réparer les fichiers système corrompus ou les problèmes de package d'installation. Afficher les informations d'erreur pendant le processus de démarrage de l'analyse du journal d'erreur.
 Fonction de page suivante HTML
Apr 06, 2025 am 11:45 AM
Fonction de page suivante HTML
Apr 06, 2025 am 11:45 AM
<p> La fonction de page suivante peut être créée via HTML. Les étapes incluent: la création d'éléments de conteneur, la division du contenu, l'ajout de liens de navigation, la cachette d'autres pages et l'ajout de scripts. Cette fonctionnalité permet aux utilisateurs de parcourir du contenu segmenté, affichant une seule page à la fois et convient pour afficher de grandes quantités de données ou de contenu. </p>
 Comment résoudre le problème du chargement lorsque le PS ouvre le fichier?
Apr 06, 2025 pm 06:33 PM
Comment résoudre le problème du chargement lorsque le PS ouvre le fichier?
Apr 06, 2025 pm 06:33 PM
Le bégaiement "Chargement" se produit lors de l'ouverture d'un fichier sur PS. Les raisons peuvent inclure: un fichier trop grand ou corrompu, une mémoire insuffisante, une vitesse du disque dur lente, des problèmes de pilote de carte graphique, des conflits de version PS ou du plug-in. Les solutions sont: vérifier la taille et l'intégrité du fichier, augmenter la mémoire, mettre à niveau le disque dur, mettre à jour le pilote de carte graphique, désinstaller ou désactiver les plug-ins suspects et réinstaller PS. Ce problème peut être résolu efficacement en vérifiant progressivement et en faisant bon usage des paramètres de performances PS et en développant de bonnes habitudes de gestion des fichiers.
 Le chargement lent PS est-il lié à la configuration de l'ordinateur?
Apr 06, 2025 pm 06:24 PM
Le chargement lent PS est-il lié à la configuration de l'ordinateur?
Apr 06, 2025 pm 06:24 PM
La raison du chargement lent PS est l'impact combiné du matériel (CPU, mémoire, disque dur, carte graphique) et logiciel (système, programme d'arrière-plan). Les solutions incluent: la mise à niveau du matériel (en particulier le remplacement des disques à semi-conducteurs), l'optimisation des logiciels (nettoyage des ordures système, mise à jour des pilotes, vérification des paramètres PS) et traitement des fichiers PS. La maintenance ordinaire de l'ordinateur peut également aider à améliorer la vitesse d'exécution du PS.
 Comment résoudre le problème du chargement lorsque PS montre toujours qu'il se charge?
Apr 06, 2025 pm 06:30 PM
Comment résoudre le problème du chargement lorsque PS montre toujours qu'il se charge?
Apr 06, 2025 pm 06:30 PM
La carte PS est "Chargement"? Les solutions comprennent: la vérification de la configuration de l'ordinateur (mémoire, disque dur, processeur), nettoyage de la fragmentation du disque dur, mise à jour du pilote de carte graphique, ajustement des paramètres PS, réinstaller PS et développer de bonnes habitudes de programmation.
 Les exportations PDF peuvent-elles être exportées par lots par PS?
Apr 06, 2025 pm 04:54 PM
Les exportations PDF peuvent-elles être exportées par lots par PS?
Apr 06, 2025 pm 04:54 PM
Il existe trois façons d'exporter des PDF par lots sur PS: utilisez les fonctions d'action PS: enregistrer et ouvrir les fichiers et exporter des actions PDF, et exécuter des actions dans une boucle. À l'aide d'un logiciel tiers: utilisez des logiciels de gestion de fichiers ou des outils d'automatisation pour spécifier les dossiers d'entrée et de sortie et définir le format de nom de fichier. Utilisez des scripts: écrivez des scripts pour personnaliser la logique d'exportation par lots, mais des connaissances en programmation sont nécessaires.
