
 Périphériques technologiques
IA
Le modèle psychique de l'IA décode avec succès les informations cérébrales avec une précision de 82 %
Périphériques technologiques
IA
Le modèle psychique de l'IA décode avec succès les informations cérébrales avec une précision de 82 %
Le modèle psychique de l'IA décode avec succès les informations cérébrales avec une précision de 82 %

Geoffrey Hinton, le père des réseaux de neurones, a démissionné de Google, affirmant qu'il regrette le travail de sa vie.
Maintenant, il semble que sa peur de l'IA ne soit pas déraisonnable.
Parce qu'un modèle de type ChatGPT a appris à lire dans les pensées, avec un taux de précision allant jusqu'à 82% !
Des chercheurs de l'Université du Texas à Austin ont développé un décodeur de langage basé sur GPT.
Il peut collecter des informations sur l'activité cérébrale grâce à une IRM/IRMf non invasive et convertir les pensées en langage.

Adresse papier : https://www.nature.com/articles/s41593-023-01304-9
Étonnamment, lorsque vous regardez un film muet de Pixar, les décodeurs du cerveau peuvent lire votre pensées.
Ce modèle de type ChatGPT décode les pensées humaines avec une précision sans précédent, ouvrant non seulement un nouveau potentiel pour l'imagerie cérébrale, mais soulevant également des inquiétudes en matière de confidentialité.
Dès sa sortie, l'étude a provoqué un tollé sur Internet. Les internautes se sont exclamés, c'est trop effrayant.

Nous sommes un pas de plus vers la véritable Police de la Pensée.

Lecture d'esprit GPT, avec une précision allant jusqu'à 82%
Alors, comment ce terrifiant décodeur cérébral parvient-il à « lire dans les pensées » ?
Ici, nous devons mentionner la technologie d'imagerie par résonance magnétique fonctionnelle (IRMf), qui permet d'obtenir des images des changements dynamiques dans le cerveau en surveillant les niveaux d'oxygène dans le sang dans différentes parties du cortex cérébral.
Ainsi, simplement en analysant les données IRMf, les histoires ou même les images présentes dans le cerveau des participants peuvent être décrites avec des mots de manière non invasive.
L'activité cérébrale est comme un signal crypté, et de grands modèles de langage pré-entraînés permettent de le déchiffrer.
Ici, les chercheurs ont formé un modèle de langage de réseau neuronal basé sur GPT-1.
Alexander Huth a demandé à 3 sujets d'écouter des podcasts vocaux pendant 16 heures en continu et a collecté des données IRMf pendant qu'ils écoutaient.
Ces podcasts linguistiques sont principalement des talk-shows et des conférences TED, comme Modern Love du New York Times.
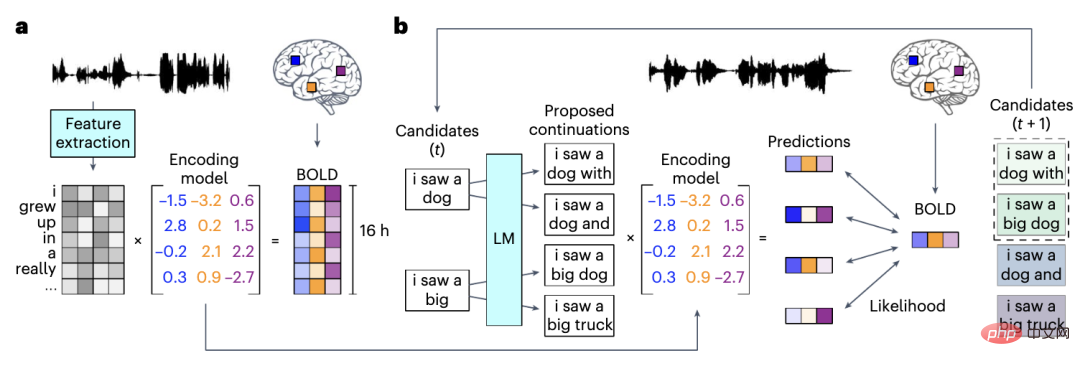
Ensuite, les chercheurs ont utilisé de grands modèles linguistiques pour traduire les ensembles de données IRMf des participants en mots et en phrases.
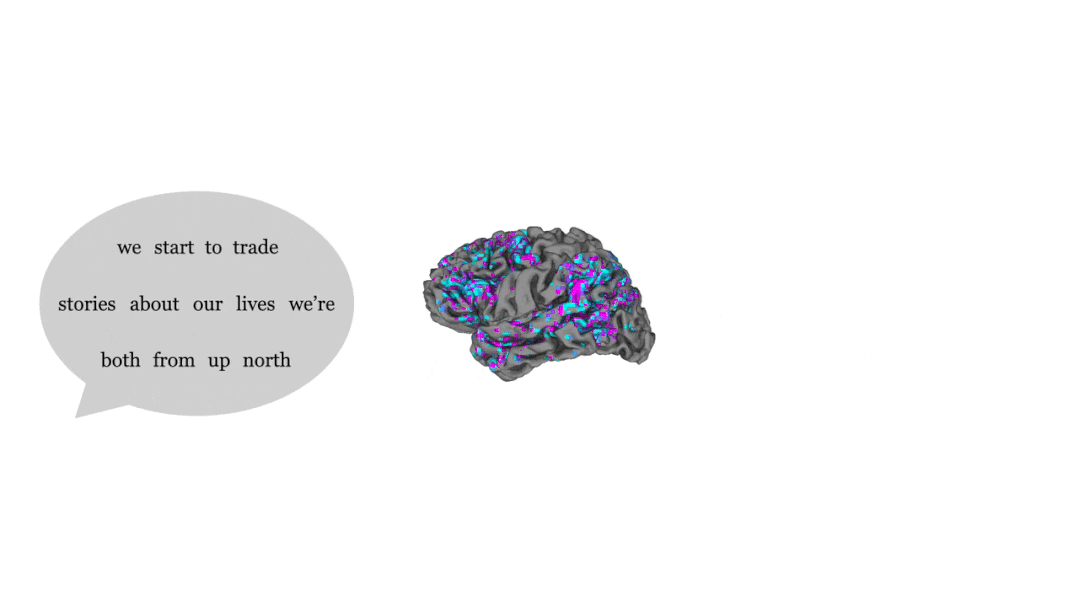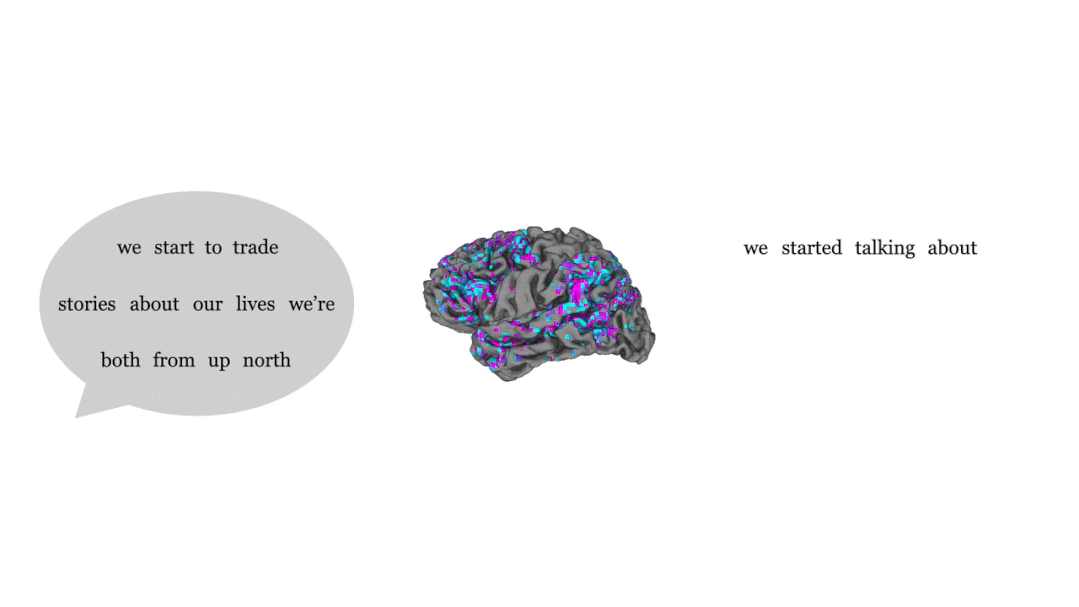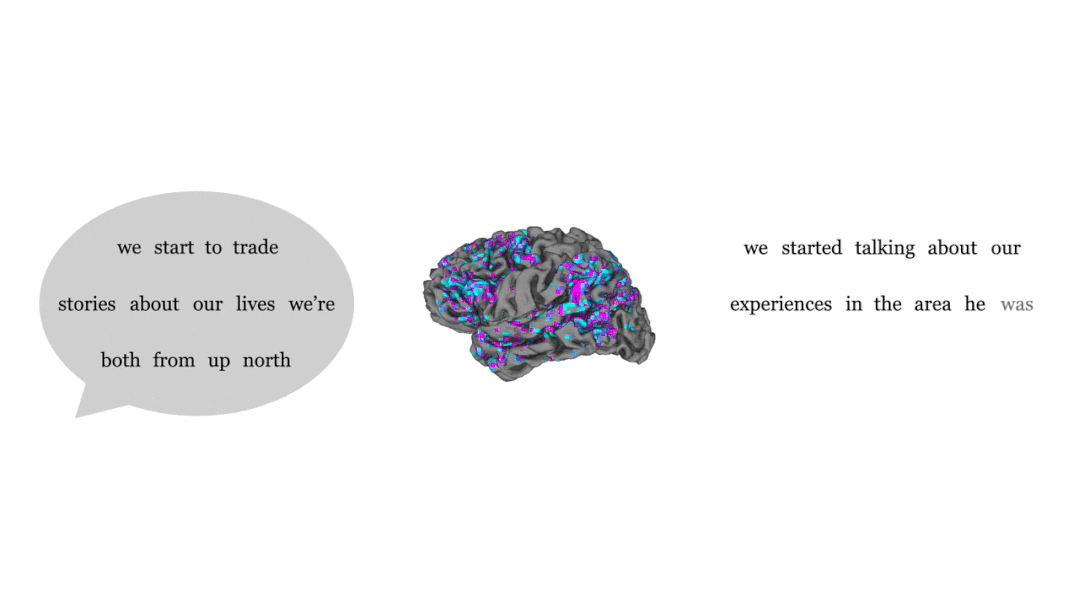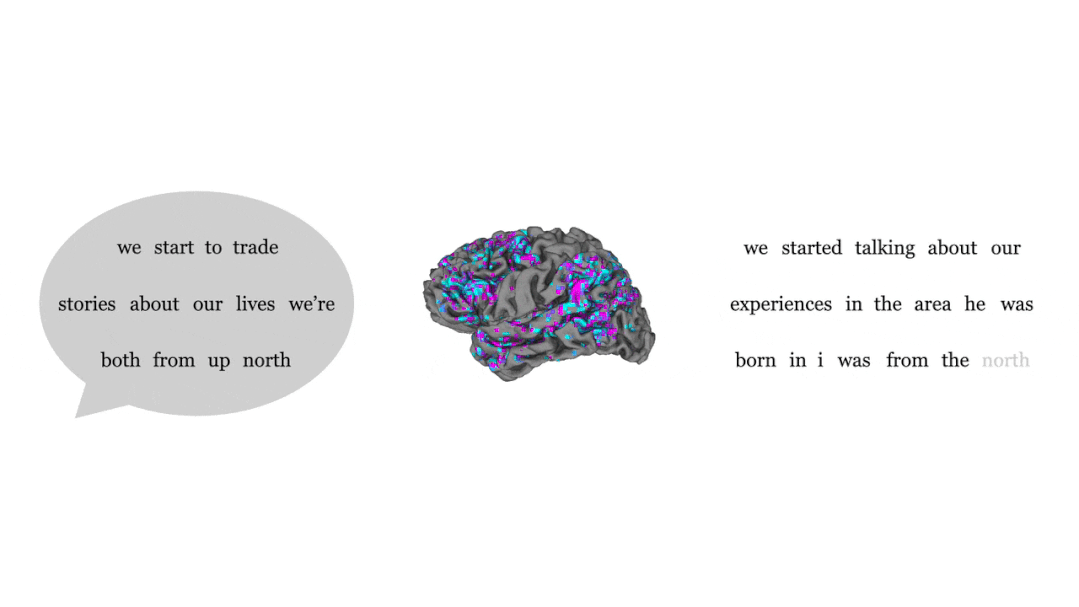
Ensuite, l'activité cérébrale des participants écoutant le nouvel enregistrement est testée. En observant la proximité du texte traduit avec le texte entendu par les participants, vous pouvez savoir si le décodeur est précis.
En comparant les phrases entendues par les gens (à gauche) et les phrases émises par le décodeur en fonction de l'activité cérébrale (à droite), on constate que les parties bleues et violettes représentent la grande majorité, le bleu signifie une cohérence complète, et le violet signifie que l'idée générale est exacte.

Bien que presque tous les mots n'aient pas de correspondance biunivoque, le sens de la phrase entière est conservé, ce qui signifie que le décodeur « interprète » le signal envoyé au cerveau.
Par exemple, dans la dernière phrase, le sujet a entendu "Je n'ai pas encore obtenu mon permis de conduire", et la réponse donnée par le décodeur était "Elle n'est pas encore prête à apprendre à conduire".
Comme le prétendent les chercheurs, l'intelligence artificielle ne peut pas convertir les pensées en mots ou en phrases exactes, mais les réécrit.
Ensuite, il a été demandé aux sujets de construire tranquillement une histoire dans leur esprit, puis de la raconter à haute voix pour voir la différence entre la version racontée et la version traduite par décodeur.

Vous pouvez voir que le chevauchement des significations est encore très élevé.
Enfin, les sujets ont regardé un film d'animation sans aucun son, mais en analysant leur activité cérébrale, le décodeur a pu obtenir un résumé de ce qu'ils regardaient.
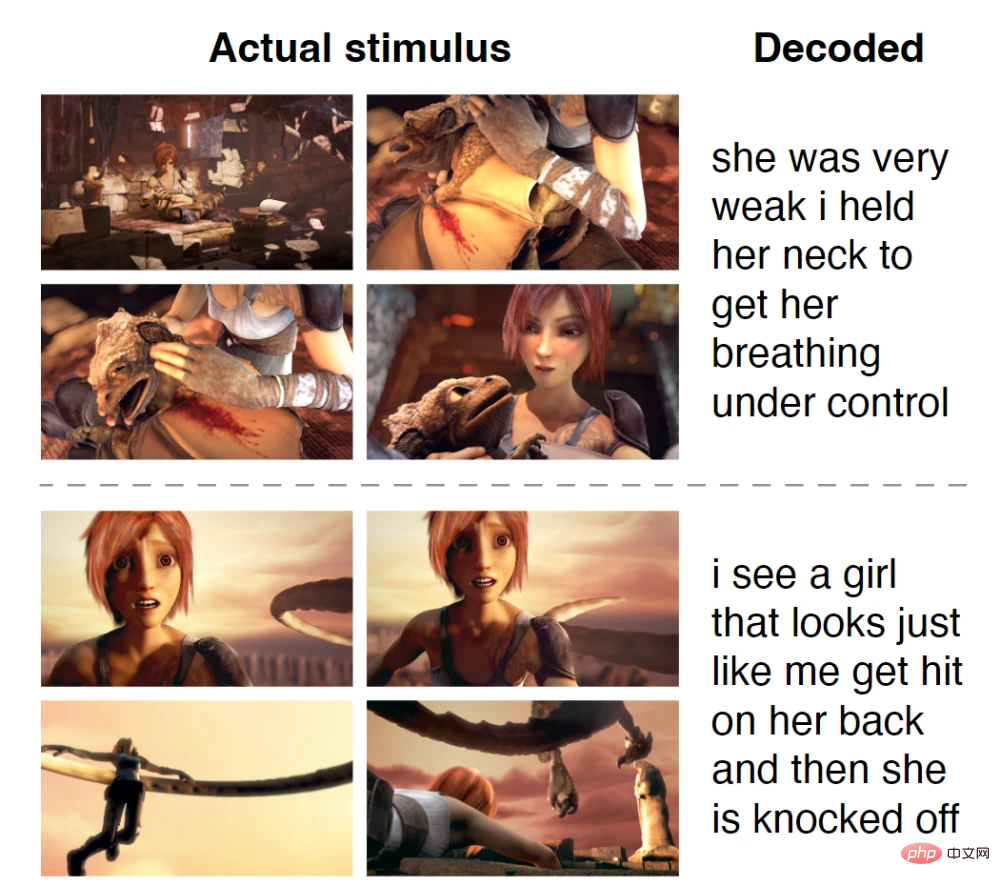
Les résultats expérimentaux ont montré que le modèle GPT génère des séquences de mots compréhensibles à partir de discours perçus, de discours imaginés et même de vidéos silencieuses, avec une précision étonnante.
Le taux de précision spécifique est le suivant :
Discours perçu (le sujet écoute l'enregistrement) : 72-82%
Discours imaginaire (le sujet raconte une histoire d'une minute en interne) : 41-74 %
Films muets (les sujets ont regardé des extraits de films muets Pixar) : 21-45%
Greta Tuckute, neuroscientifique au MIT, affirme que la perception de la parole est un processus externe et que l'imagination est un processus interne actif, et les activités cérébrales internes peuvent être affichées sous nos yeux grâce à des modèles linguistiques à grande échelle.
Pouvons-nous lire les informations du cerveau maintenant ? Oui, dans une certaine mesure.

Un jour, ce décodeur pourrait être utilisé pour aider les personnes ayant perdu la capacité de parler ou pour enquêter sur des problèmes de santé mentale.
LA VIE PRIVÉE MENTALE, GONE
Cependant, la perspective de décoder les pensées humaines soulève également des questions sur la vie privée mentale.

Le Dr Huth a souligné que cette méthode de décodage du langage présente certaines limites.
Parce que les scanners IRMf sont encombrants et coûteux, et que la formation des modèles est un processus long et fastidieux, c'est-à-dire que chaque personne doit être formée individuellement.
En réponse, l’équipe a mené une étude supplémentaire en utilisant des décodeurs entraînés sur les données d’autres sujets pour décoder les pensées de nouveaux sujets.
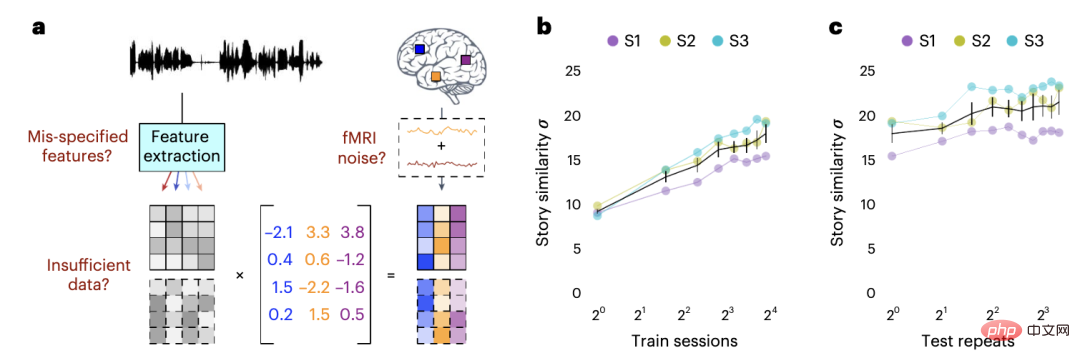
L'étude a révélé que les performances des décodeurs entraînés à l'aide de données sur différents sujets étaient presque médiocres.
En bref, ce n'est qu'en utilisant les données enregistrées par le propre cerveau des sujets pour entraîner le modèle d'IA que sa précision sera très élevée.
Cela montre que chaque cerveau a une manière unique de représenter le sens.

De plus, les participants sont capables de bloquer leur monologue intérieur et d'échapper au décodeur en pensant à autre chose. Comme compter jusqu'à sept, énumérer les animaux de la ferme ou raconter une histoire complètement différente.
En d'autres termes, si ce décodeur veut obtenir des résultats précis, il doit nécessiter la coopération de bénévoles.
Cependant, les scientifiques reconnaissent que les futurs décodeurs pourraient surmonter ces limitations et pourraient être utilisés à mauvais escient à l'avenir, un peu comme les détecteurs de mensonge.
Les chercheurs concluent qu'un meilleur des mondes est en train d'arriver pour ces raisons et d'autres raisons imprévues.
Il est essentiel de sensibiliser aux risques liés à la technologie de décodage cérébral et d’élaborer des politiques qui protègent la vie privée mentale de chacun.
Il y a une scène dans "Black Mirror" où un agent d'assurance utilise une machine (équipée de moniteurs visuels et de capteurs cérébraux) pour lire les souvenirs des gens afin d'enquêter sur une mort accidentelle.

Cependant, cet avenir pourrait être maintenant.
Cette percée réalisée par des chercheurs de l'Université du Texas favorise directement les applications potentielles dans les domaines des neurosciences, des communications et de l'interaction homme-machine.

Bien que le « décodeur cérébral » en soit encore aux premiers stades de la recherche, il pourrait un jour être utilisé pour enregistrer les rêves des gens et fournir de l'énergie pour le développement ultérieur des interfaces cerveau-ordinateur.
Le Dr Alexander Huth, le neuroscientifique qui a dirigé l'étude, a déclaré : "Nous avons été choqués par la façon dont cela fonctionne." Je travaillais là-dessus depuis 15 ans... alors j'ai été choqué et excité quand cela a finalement fonctionné.
Il semble que nous soyons un pas de plus vers la technologie de scanner cérébral de Charles, professeur X dans "X-Men".

Internautes : IA médium
Après avoir lu cette étude, de nombreuses personnes ont instantanément « explosé le cerveau ». Certains internautes ont déclaré que
l'intelligence artificielle peut non seulement communiquer 10 000 fois plus vite que nous, mais qu'elle peut désormais même lire nos pensées. Il y a une ligne fine entre « C'est cool » et « Attendez, allons-nous être éliminés ? »
L'IA peut désormais lire dans les pensées comme un médium. "Gardez à l'esprit", ce n'est que la version 1.0. À l’avenir, la vie privée ne sera plus une préoccupation dans nos esprits. Le rapport La Quatrième révolution industrielle du Forum économique mondial le montre très clairement.
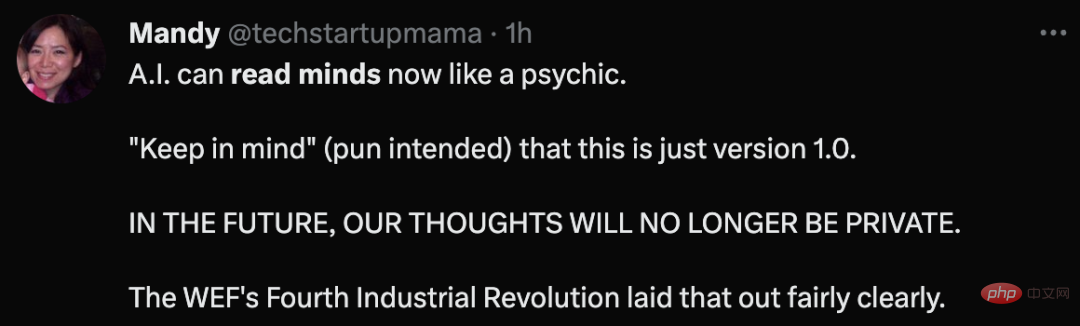
C'est la première fois qu'un langage continu est reconstruit de manière non invasive à partir de l'activité cérébrale humaine

À propos de cette étude, le bioéthicien Rodriguez-Arias Vailhen a déclaré que jusqu'à présent, le cerveau humain était le gardien de notre vie privée.
"Cette découverte pourrait être la première étape vers le sacrifice de cette liberté dans le futur."

Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Géospatial de Laravel: optimisation des cartes interactives et de grandes quantités de données
Apr 08, 2025 pm 12:24 PM
Géospatial de Laravel: optimisation des cartes interactives et de grandes quantités de données
Apr 08, 2025 pm 12:24 PM
Traiter efficacement 7 millions d'enregistrements et créer des cartes interactives avec la technologie géospatiale. Cet article explore comment traiter efficacement plus de 7 millions d'enregistrements en utilisant Laravel et MySQL et les convertir en visualisations de cartes interactives. Exigences initiales du projet de défi: extraire des informations précieuses en utilisant 7 millions d'enregistrements dans la base de données MySQL. Beaucoup de gens considèrent d'abord les langages de programmation, mais ignorent la base de données elle-même: peut-il répondre aux besoins? La migration des données ou l'ajustement structurel est-il requis? MySQL peut-il résister à une charge de données aussi importante? Analyse préliminaire: les filtres et les propriétés clés doivent être identifiés. Après analyse, il a été constaté que seuls quelques attributs étaient liés à la solution. Nous avons vérifié la faisabilité du filtre et établi certaines restrictions pour optimiser la recherche. Recherche de cartes basée sur la ville
 Comment résoudre MySQL ne peut pas être démarré
Apr 08, 2025 pm 02:21 PM
Comment résoudre MySQL ne peut pas être démarré
Apr 08, 2025 pm 02:21 PM
Il existe de nombreuses raisons pour lesquelles la startup MySQL échoue, et elle peut être diagnostiquée en vérifiant le journal des erreurs. Les causes courantes incluent les conflits de port (vérifier l'occupation du port et la configuration de modification), les problèmes d'autorisation (vérifier le service exécutant les autorisations des utilisateurs), les erreurs de fichier de configuration (vérifier les paramètres des paramètres), la corruption du répertoire de données (restaurer les données ou reconstruire l'espace de la table), les problèmes d'espace de la table InNODB (vérifier les fichiers IBDATA1), la défaillance du chargement du plug-in (vérification du journal des erreurs). Lors de la résolution de problèmes, vous devez les analyser en fonction du journal d'erreur, trouver la cause profonde du problème et développer l'habitude de sauvegarder régulièrement les données pour prévenir et résoudre des problèmes.
 Comment utiliser MySQL après l'installation
Apr 08, 2025 am 11:48 AM
Comment utiliser MySQL après l'installation
Apr 08, 2025 am 11:48 AM
L'article présente le fonctionnement de la base de données MySQL. Tout d'abord, vous devez installer un client MySQL, tel que MySQLWorkBench ou le client de ligne de commande. 1. Utilisez la commande MySQL-UROot-P pour vous connecter au serveur et connecter avec le mot de passe du compte racine; 2. Utilisez Createdatabase pour créer une base de données et utilisez Sélectionner une base de données; 3. Utilisez CreateTable pour créer une table, définissez des champs et des types de données; 4. Utilisez InsertInto pour insérer des données, remettre en question les données, mettre à jour les données par mise à jour et supprimer les données par Supprimer. Ce n'est qu'en maîtrisant ces étapes, en apprenant à faire face à des problèmes courants et à l'optimisation des performances de la base de données que vous pouvez utiliser efficacement MySQL.
 Comprendre les propriétés acides: les piliers d'une base de données fiable
Apr 08, 2025 pm 06:33 PM
Comprendre les propriétés acides: les piliers d'une base de données fiable
Apr 08, 2025 pm 06:33 PM
Une explication détaillée des attributs d'acide de base de données Les attributs acides sont un ensemble de règles pour garantir la fiabilité et la cohérence des transactions de base de données. Ils définissent comment les systèmes de bases de données gérent les transactions et garantissent l'intégrité et la précision des données même en cas de plantages système, d'interruptions d'alimentation ou de plusieurs utilisateurs d'accès simultanément. Présentation de l'attribut acide Atomicité: une transaction est considérée comme une unité indivisible. Toute pièce échoue, la transaction entière est reculée et la base de données ne conserve aucune modification. Par exemple, si un transfert bancaire est déduit d'un compte mais pas augmenté à un autre, toute l'opération est révoquée. BeginTransaction; UpdateAccountSsetBalance = Balance-100Wh
 Les ingénieurs de backend senior à distance (plates-formes) ont besoin de cercles
Apr 08, 2025 pm 12:27 PM
Les ingénieurs de backend senior à distance (plates-formes) ont besoin de cercles
Apr 08, 2025 pm 12:27 PM
Ingénieur backend à distance Emploi Vacant Société: Emplacement du cercle: Bureau à distance Type d'emploi: Salaire à temps plein: 130 000 $ - 140 000 $ Description du poste Participez à la recherche et au développement des applications mobiles Circle et des fonctionnalités publiques liées à l'API couvrant l'intégralité du cycle de vie de développement logiciel. Les principales responsabilités complètent indépendamment les travaux de développement basés sur RubyOnRails et collaborent avec l'équipe frontale React / Redux / Relay. Créez les fonctionnalités de base et les améliorations des applications Web et travaillez en étroite collaboration avec les concepteurs et le leadership tout au long du processus de conception fonctionnelle. Promouvoir les processus de développement positifs et hiérarchiser la vitesse d'itération. Nécessite plus de 6 ans de backend d'applications Web complexe
 Mysql peut-il renvoyer JSON
Apr 08, 2025 pm 03:09 PM
Mysql peut-il renvoyer JSON
Apr 08, 2025 pm 03:09 PM
MySQL peut renvoyer les données JSON. La fonction JSON_Extract extrait les valeurs de champ. Pour les requêtes complexes, envisagez d'utiliser la clause pour filtrer les données JSON, mais faites attention à son impact sur les performances. Le support de MySQL pour JSON augmente constamment, et il est recommandé de faire attention aux dernières versions et fonctionnalités.
 MySQL ne peut pas être installé après le téléchargement
Apr 08, 2025 am 11:24 AM
MySQL ne peut pas être installé après le téléchargement
Apr 08, 2025 am 11:24 AM
Les principales raisons de la défaillance de l'installation de MySQL sont les suivantes: 1. Problèmes d'autorisation, vous devez s'exécuter en tant qu'administrateur ou utiliser la commande sudo; 2. Des dépendances sont manquantes et vous devez installer des packages de développement pertinents; 3. Conflits du port, vous devez fermer le programme qui occupe le port 3306 ou modifier le fichier de configuration; 4. Le package d'installation est corrompu, vous devez télécharger et vérifier l'intégrité; 5. La variable d'environnement est mal configurée et les variables d'environnement doivent être correctement configurées en fonction du système d'exploitation. Résolvez ces problèmes et vérifiez soigneusement chaque étape pour installer avec succès MySQL.
 Solutions au service qui ne peuvent pas être démarrées après l'installation de MySQL
Apr 08, 2025 am 11:18 AM
Solutions au service qui ne peuvent pas être démarrées après l'installation de MySQL
Apr 08, 2025 am 11:18 AM
MySQL a refusé de commencer? Ne paniquez pas, vérifions-le! De nombreux amis ont découvert que le service ne pouvait pas être démarré après avoir installé MySQL, et ils étaient si anxieux! Ne vous inquiétez pas, cet article vous emmènera pour le faire face calmement et découvrez le cerveau derrière! Après l'avoir lu, vous pouvez non seulement résoudre ce problème, mais aussi améliorer votre compréhension des services MySQL et vos idées de problèmes de dépannage, et devenir un administrateur de base de données plus puissant! Le service MySQL n'a pas réussi et il y a de nombreuses raisons, allant des erreurs de configuration simples aux problèmes système complexes. Commençons par les aspects les plus courants. Connaissances de base: une brève description du processus de démarrage du service MySQL Service Startup. Autrement dit, le système d'exploitation charge les fichiers liés à MySQL, puis démarre le démon mysql. Cela implique la configuration
