

Installer le module apscheduler
pip install apscheduler
APScheduler (Advanced Python Scheduler) est un framework de planification de tâches planifiées Python léger (bibliothèque Python).
APScheduler dispose de trois systèmes de planification intégrés, qui incluent :
planification de style cron (heures de début/fin facultatives)
Exécution basée sur des intervalles (exécuter des tâches à intervalles réguliers, heures de début/fin facultatives selon eh bien) )
Exécution de tâche différée unique (exécuter le travail une fois à une date/heure spécifiée)
APScheduler peut arbitrairement mélanger et faire correspondre les systèmes de planification et les backends de stockage de tâches, lorsque pris en charge Les tâches de stockage back-end incluent :
Memory
SQLAlchemy
MongoDB
Redis
RethinkDB
ZooKee par
Les déclencheurs contiennent une planification logique, et chaque tâche a son propre déclencheur pour déterminer la prochaine durée d'exécution. Hormis leur propre configuration initiale, les déclencheurs sont totalement apatrides. Les magasins d'emplois (magasins d'emplois) stockent les tâches planifiées. Le magasin d'emplois par défaut enregistre simplement le travail dans la mémoire, et les autres magasins d'emplois enregistrent le travail dans la base de données. Lorsqu'une tâche est enregistrée dans un magasin de tâches persistant, les données de la tâche sont sérialisées et désérialisées lors du chargement. Le stockage des tâches ne peut pas partager le planificateur.
Les exécuteurs gèrent l'exécution des tâches. Ils le font généralement en soumettant des objets appelables spécifiés à un thread ou à un pool de processus dans la tâche. Une fois le travail terminé, l'exécuteur en informera le planificateur.
planificateurs (planificateurs) La configuration du stockage des tâches et des exécuteurs peut être effectuée dans le planificateur, comme l'ajout, la modification et la suppression de tâches. Différents planificateurs peuvent être sélectionnés en fonction de différents scénarios d'application. Il existe 7 options disponibles : BlockingScheduler, BackgroundScheduler, AsyncIOScheduler, GeventScheduler, TornadoScheduler, TwistedScheduler et QtScheduler.
Introduction à chaque composant
date. : Date spécifiée une fois ;
intervalle : à quelle fréquence d'exécution dans une certaine plage de temps ;
cron : compatible avec le format crontab Linux, le plus puissant.
date est le type de planification le plus basique, et le travail ne sera exécuté qu'une seule fois. Ses paramètres sont les suivants :
(datetime.tzinfo|str) – stockage
si votre application recréera des tâches à chaque démarrage, utilisez donc le magasin de tâches par défaut (MemoryJobStore), mais si vous devez conserver la tâche même si le planificateur redémarre ou si l'application plante, vous devez utiliser Select la mémoire de travail spécifique en fonction de votre environnement d'application. Par exemple : utilisez Mongo ou SQLAlchemy JobStore (utilisé pour prendre en charge la plupart des SGBDR)
Executor
Le choix de l'exécuteur dépend du framework ci-dessus que vous utilisez. Dans la plupart des cas, l'utilisation de ThreadPoolExecutor par défaut peut déjà répondre à vos besoins. Si votre application implique desopérations gourmandes en CPU
, vous pouvez envisager d'utiliser ProcessPoolExecutor pour utiliser plus de cœurs de CPU. Vous pouvez également utiliser les deux en même temps, en utilisant ProcessPoolExecutor comme deuxième exécuteur. "Choisissez le bon planificateur" app Utilisé lors de l'exécution.AsyncIOScheduler : Utilisé lorsque votre programme utilise asyncio (un framework asynchrone).
GeventScheduler : utilisé lorsque votre programme utilise gevent (un framework de concurrence Python hautes performances).
TornadoScheduler : Utilisé lorsque votre programme est basé sur Tornado (un framework web).
# -*- coding:utf-8 -*-
from apscheduler.schedulers.blocking import BlockingScheduler
import datetime
def my_job1():
print('my_job1 is running, Now is %s' % datetime.datetime.now().strftime("%Y-%m-%d %H:%M:%S"))
def my_job2():
print('my_job2 is running, Now is %s' % datetime.datetime.now().strftime("%Y-%m-%d %H:%M:%S"))
sched = BlockingScheduler()
# 每隔5秒运行一次my_job1
sched.add_job(my_job1, 'interval', seconds=5, id='my_job1')
# 每隔5秒运行一次my_job2
sched.add_job(my_job2, 'cron', second='*/5', id='my_job2')
sched.start()# -*- coding:utf-8 -*-
from apscheduler.schedulers.blocking import BlockingScheduler
import datetime
sched = BlockingScheduler()
# 每隔5秒运行一次my_job1
@sched.scheduled_job('interval', seconds=5, id='my_job1')
def my_job1():
print('my_job1 is running, Now is %s' % datetime.datetime.now().strftime("%Y-%m-%d %H:%M:%S"))
# 每隔5秒运行一次my_job2
@sched.scheduled_job('cron', second='*/5', id='my_job2')
def my_job2():
print('my_job2 is running, Now is %s' % datetime.datetime.now().strftime("%Y-%m-%d %H:%M:%S"))
sched.start()Travail de suppression
# -*- coding:utf-8 -*-
from apscheduler.schedulers.blocking import BlockingScheduler
import datetime
def my_job(text=""):
print(text, 'my_job1 is running, Now is %s' % datetime.datetime.now().strftime("%Y-%m-%d %H:%M:%S"))
sched = BlockingScheduler()
job = sched.add_job(my_job, 'interval', seconds=2, args=['第一个作业'])
# #如果有多个任务序列的话可以给每个任务设置ID号,可以根据ID号选择清除对象,且remove放到start前才有效
sched.add_job(my_job, 'interval', seconds=2, id='my_job_id', args=['第二个作业'])
sched.start()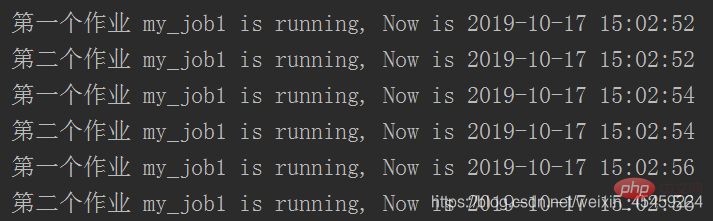
使用remove() 移除作业
# -*- coding:utf-8 -*-
from apscheduler.schedulers.blocking import BlockingScheduler
import datetime
def my_job(text=""):
print(text, 'my_job1 is running, Now is %s' % datetime.datetime.now().strftime("%Y-%m-%d %H:%M:%S"))
sched = BlockingScheduler()
job = sched.add_job(my_job, 'interval', seconds=2, args=['第一个作业'])
job.remove()
# #如果有多个任务序列的话可以给每个任务设置ID号,可以根据ID号选择清除对象,且remove放到start前才有效
sched.add_job(my_job, 'interval', seconds=2, id='my_job_id', args=['第二个作业'])
sched.start()代码执行结果:

使用remove_job()移除作业
# -*- coding:utf-8 -*-
from apscheduler.schedulers.blocking import BlockingScheduler
import datetime
def my_job(text=""):
print(text, 'my_job1 is running, Now is %s' % datetime.datetime.now().strftime("%Y-%m-%d %H:%M:%S"))
sched = BlockingScheduler()
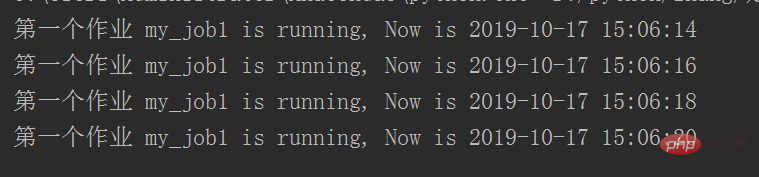
job = sched.add_job(my_job, 'interval', seconds=2, args=['第一个作业'])
# #如果有多个任务序列的话可以给每个任务设置ID号,可以根据ID号选择清除对象,且remove放到start前才有效
sched.add_job(my_job, 'interval', seconds=2, id='my_job_id', args=['第二个作业'])
sched.remove_job('my_job_id')
sched.start()代码执行结果:
APScheduler有3中内置的触发器类型:
新建一个调度器(scheduler);
添加一个调度任务(job store);
运行调度任务。
代码实现
# -*- coding:utf-8 -*-
import time
import datetime
from apscheduler.schedulers.blocking import BlockingScheduler
def my_job(text="默认值"):
print(text, time.strftime('%Y-%m-%d %H:%M:%S', time.localtime(time.time())))
sched = BlockingScheduler()
sched.add_job(my_job, 'interval', seconds=3, args=['3秒定时'])
# 2018-3-17 00:00:00 执行一次,args传递一个text参数
sched.add_job(my_job, 'date', run_date=datetime.date(2019, 10, 17), args=['根据年月日定时执行'])
# 2018-3-17 13:46:00 执行一次,args传递一个text参数
sched.add_job(my_job, 'date', run_date=datetime.datetime(2019, 10, 17, 14, 10, 0), args=['根据年月日时分秒定时执行'])
# sched.start()
"""
interval 间隔调度,参数如下:
weeks (int) – 间隔几周
days (int) – 间隔几天
hours (int) – 间隔几小时
minutes (int) – 间隔几分钟
seconds (int) – 间隔多少秒
start_date (datetime|str) – 开始日期
end_date (datetime|str) – 结束日期
timezone (datetime.tzinfo|str) – 时区
"""
"""
cron参数如下:
year (int|str) – 年,4位数字
month (int|str) – 月 (范围1-12)
day (int|str) – 日 (范围1-31)
week (int|str) – 周 (范围1-53)
day_of_week (int|str) – 周内第几天或者星期几 (范围0-6 或者 mon,tue,wed,thu,fri,sat,sun)
hour (int|str) – 时 (范围0-23)
minute (int|str) – 分 (范围0-59)
second (int|str) – 秒 (范围0-59)
start_date (datetime|str) – 最早开始日期(包含)
end_date (datetime|str) – 最晚结束时间(包含)
timezone (datetime.tzinfo|str) – 指定时区
"""
# my_job将会在6,7,8,11,12月的第3个周五的1,2,3点运行
sched.add_job(my_job, 'cron', month='6-8,11-12', day='3rd fri', hour='0-3')
# 截止到2018-12-30 00:00:00,每周一到周五早上五点半运行job_function
sched.add_job(my_job, 'cron', day_of_week='mon-fri', hour=5, minute=30, end_date='2018-12-31')
# 表示2017年3月22日17时19分07秒执行该程序
sched.add_job(my_job, 'cron', year=2017, month=3, day=22, hour=17, minute=19, second=7)
# 表示任务在6,7,8,11,12月份的第三个星期五的00:00,01:00,02:00,03:00 执行该程序
sched.add_job(my_job, 'cron', month='6-8,11-12', day='3rd fri', hour='0-3')
# 表示从星期一到星期五5:30(AM)直到2014-05-30 00:00:00
sched.add_job(my_job, 'cron', day_of_week='mon-fri', hour=5, minute=30, end_date='2014-05-30')
# 表示每5秒执行该程序一次,相当于interval 间隔调度中seconds = 5
sched.add_job(my_job, 'cron', second='*/5', args=['5秒定时'])
sched.start()| cron表达式 | 参数 | 描述 |
|---|---|---|
| * | any | Fire on every value |
| */a | any | Fire every a values, starting from the minimum |
| a-b | any | Fire on any value within the a-b range (a must be smaller than b) |
| a-b/c | any | Fire every c values within the a-b range |
| xth y | day | Fire on the x -th occurrence of weekday y within the month |
| last x | day | Fire on the last occurrence of weekday x within the month |
| last | day | Fire on the last day within the month |
| x,y,z | any | Fire on any matching expression; can combine any number of any of the above expressions |
使用SQLAlchemy作业存储器存放作业
# -*- coding:utf-8 -*-
from apscheduler.schedulers.blocking import BlockingScheduler
from datetime import datetime
import logging
sched = BlockingScheduler()
def my_job():
print('my_job is running, Now is %s' % datetime.now().strftime("%Y-%m-%d %H:%M:%S"))
# 使用sqlalchemy作业存储器
# 根据自己电脑安装的库选择用什么连接 ,如pymysql 其中:scrapy表示数据库的名称,操作数据库之前应创建对应的数据库
url = 'mysql+pymysql://root:123456@localhost:3306/scrapy?charset=utf8'
sched.add_jobstore('sqlalchemy', url=url)
# 添加作业
sched.add_job(my_job, 'interval', id='myjob', seconds=5)
log = logging.getLogger('apscheduler.executors.default')
log.setLevel(logging.INFO) # DEBUG
# 设定日志格式
fmt = logging.Formatter('%(levelname)s:%(name)s:%(message)s')
h = logging.StreamHandler()
h.setFormatter(fmt)
log.addHandler(h)
sched.start()暂停和恢复作业
# 暂停作业: apsched.job.Job.pause() apsched.schedulers.base.BaseScheduler.pause_job() # 恢复作业: apsched.job.Job.resume() apsched.schedulers.base.BaseScheduler.resume_job()
获得job列表
get_jobs(),它会返回所有的job实例;
使用print_jobs()来输出所有格式化的作业列表;
get_job(job_id=“任务ID”)获取指定任务的作业列表。
代码实现:
# -*- coding:utf-8 -*-
from apscheduler.schedulers.blocking import BlockingScheduler
import datetime
def my_job(text=""):
print(text, 'my_job1 is running, Now is %s' % datetime.datetime.now().strftime("%Y-%m-%d %H:%M:%S"))
sched = BlockingScheduler()
job = sched.add_job(my_job, 'interval', seconds=2, args=['第一个作业'])
sched.add_job(my_job, 'interval', seconds=2, id='my_job_id', args=['第二个作业'])
print(sched.get_jobs())
print(sched.get_job(job_id="my_job_id"))
sched.print_jobs()
sched.start()关闭调度器
默认情况下调度器会等待所有正在运行的作业完成后,关闭所有的调度器和作业存储。如果你不想等待,可以将wait选项设置为False。
sched.shutdown() sched.shutdown(wait=False)
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
















![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



