
 Périphériques technologiques
IA
Exploration et application de modèles de prédiction de la conformation du génome et de méthodes de criblage génétique informatique à haut débit
Périphériques technologiques
IA
Exploration et application de modèles de prédiction de la conformation du génome et de méthodes de criblage génétique informatique à haut débit
Exploration et application de modèles de prédiction de la conformation du génome et de méthodes de criblage génétique informatique à haut débit


Figure 0
Les différences de conformation du génome dans différents types de cellules déterminent la spécificité de l'expression des gènes, qui à son tour détermine les différences fonctionnelles dans différents types de cellules. Pendant longtemps, les méthodes expérimentales de détection de la conformation du génome, de l'hybridation in situ à la détection à haut débit telle que les technologies Hi-C et micro-C, sont généralement longues, laborieuses, coûteuses et présentent de fortes limitations techniques. Ces méthodes limitent considérablement l'application généralisée de ces techniques expérimentales dans le domaine de la recherche sur la conformation du génome, notamment dans l'étude de types de cellules rares et la nécessité de vérifier la relation causale entre la régulation de la conformation du génome à grande échelle. Les limites de ces méthodes ont également limité pendant longtemps les nouvelles découvertes dans le domaine de la régulation conformationnelle du génome tridimensionnel.

Figure 1
9 janvier 2023, Le laboratoire Aristotelis Tsirigos et le Broad Institute du MIT et de Harvard, NYU Grossman School of Medicine, le laboratoire de Xia Bo ont collaboré pour publier un article "Spécifique au type de cellule la prédiction de l'organisation de la chromatine 3D permet un criblage génétique in silico à haut débit" dans Nature Biotechnology.

Adresse papier : https://www.nature.com/articles/s41587-022-01612-8
Dans cette étude, Ph.D., New York University School de médecine Sheng Tan Jimin et le Dr Xia Bo ont d'abord proposé un nouveau modèle d'apprentissage automatique multimodal C.Origami pour prédire la conformation de la chromatine de types de cellules spécifiques, et ont proposé un nouveau criblage génétique informatique à haut débit (criblage génétique in silico) basé sur sur le principe du dépistage génétique. , ISGS), utilisée pour identifier les éléments génomiques fonctionnels spécifiques d'un type cellulaire et aider à découvrir de nouveaux mécanismes de régulation de la conformation de la chromatine.
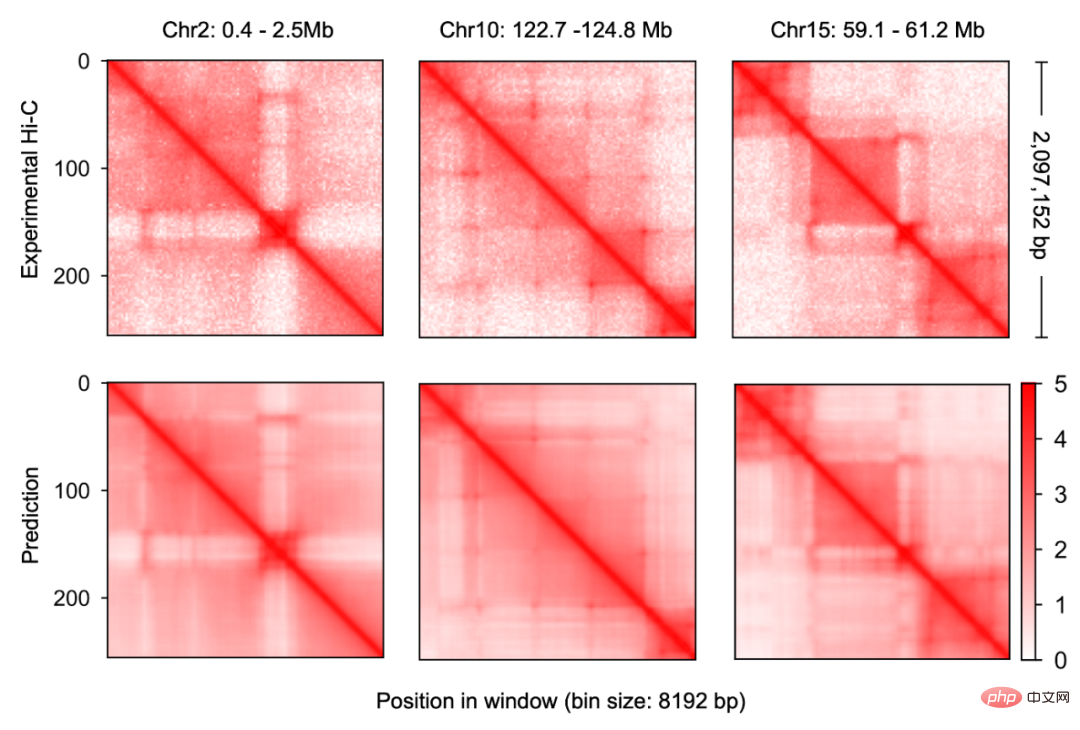
Figure 2
Les chercheurs ont d'abord construit un nouveau cadre d'apprentissage profond multimodal pour les données génomiques, Origami, afin qu'il puisse intégrer efficacement les informations sur les séquences d'ADN et les cellules génomiques fonctionnelles spécifiques informations, puis prédire de nouvelles informations génomiques. Grâce à un débogage répété et à une formation de modèles, les chercheurs ont découvert que l'intégration de la séquence d'ADN, de l'état de liaison du CTCF (CTCF ChIP-seq) et des signaux ATAC-seq comme informations d'entrée permet de prédire avec précision la conformation de la chromatine et d'utiliser la matrice bidimensionnelle Hi-C comme Prédisez l’objectif de sortie (Figure 1-2). Les informations d'entrée étaient de 2 millions de paires de bases d'ADN, CTCF ChIP-seq et ATAC-seq. Les chercheurs utilisent le codage Onehot pour coder des séquences d'ADN discrètes, tandis que CTCF ChIP-seq et ATAC-seq codent des caractéristiques non discrètes.

C.Le modèle Origami est divisé en trois parties, l'encodeur qui traite et compresse les informations sur l'ADN et le génome, la couche intermédiaire du transformateur et le décodeur Hi-C de sortie#🎜 🎜 #. L'encodeur se compose d'une série de ResNet 1D et de convolution striée pour encoder et compresser les informations d'entrée de 2 millions de paires de bases. À la fin de l'encodeur, le message d'une longueur de 2 millions est compressé à une longueur de 256 et utilisé comme message d'entrée pour le transformateur. Le mécanisme d'auto-attention de Transformer peut gérer l'interdépendance entre différentes régions génomiques et améliorer les performances globales du modèle. La matrice d'attention dans Transformer peut également améliorer l'interprétabilité du modèle. Les chercheurs ont converti le poids de l'attention en un « score d'attention » pour mesurer l'accent mis par le modèle sur différents domaines lors de la prédiction. Enfin, les chercheurs ont converti la sortie 1D du module Transformer en une matrice de contact/adjacence 2D en utilisant la « concaténation externe », qui a été utilisée comme information d'entrée pour le décodeur Hi-C. Le décodeur est un ResNet 2D dilaté. Les chercheurs ont ajusté les facteurs de dilatation des différentes couches afin que le champ récepteur à chaque position de pixel de la couche finale puisse couvrir toutes les informations d'entrée.
Ce modèle de prédiction de la conformation de la chromatine s'appelle C.Origami. Les chercheurs appellent C.Origami le premier modèle d’apprentissage profond multimodal en génomique. En raison de sa nature multimodale, C.Origami est capable de prédire avec précision (prédiction de novo) la conformation de la chromatine dans de nouveaux types de cellules qui n’y ont jamais été exposés. Par exemple, un modèle formé sur des cellules IMR-90 (fibroblastes pulmonaires) a pu prédire avec précision les conformations spécifiques de la chromatine dans les cellules GM12878 (lymphocytes B) (Figure 3).

Photo 3#🎜🎜 #
Les variantes structurelles - telles que les translocations chromosomiques - sont très courantes dans les tumeurs et modifient souvent les modèles d'interaction chromatine, ce qui peut affecter l'expression d'oncogènes ou de gènes suppresseurs de tumeurs. L'étude des effets de ces variations structurelles sur la conformation de la chromatine et l'expression des gènes est importante pour comprendre les mécanismes d'apparition et de progression des tumeurs. Ce type de recherche nécessite généralement l'utilisation d'expériences telles que 4C-seq ou Hi-C pour analyser la conformation chromatine des sites de variation structurelle, mais est souvent limitée par les ressources et le temps et est difficile à mener à grande échelle.Dans cette étude, C. Origami peut simuler des variations de séquences d'ADN dans des variables d'entrée, puis prédire de nouvelles interactions chromatiniennes dans le génome du cancer muté. Des études antérieures ont révélé que le modèle cellulaire CUTLL1 de leucémie lymphoblastique aiguë à cellules T (T-ALL) présentait une translocation chromosomique chr7-chr9 (Figure 4). En simulant informatiquement les variantes de translocation chromosomique, C. Origami a prédit avec précision la nouvelle structure TAD au niveau du site variante et a détecté une structure de « bande de chromatine » s'étendant de chr9 à chr7 (Figure 4).

Photo 4#🎜🎜 # Compte tenu de l'effet de prédiction précis de C.Origami et inspirés par le principe du dépistage génétique inverse, les chercheurs ont proposé une nouvelle méthode de dépistage génétique informatique à haut débit (criblage génétique in silico, ISGS) pour identifier systématiquement le type de cellules. -des éléments génomiques fonctionnels spécifiques et facilitent la découverte de nouvelles molécules régulatrices de coloration (Figure 5). Les chercheurs ont développé un cadre de criblage génétique informatique ISGS basé sur le modèle C. Origami pour l'identification systématique des éléments cis-régulateurs requis pour la conformation de la chromatine. En utilisant l’ISGS d’une résolution de 1 Ko à l’échelle du génome, les auteurs ont isolé des éléments cis-régulateurs (environ 1 % du génome) qui ont des effets importants sur la conformation de la chromatine. Ces séquences régulatrices de conformation de la chromatine présentent une dépendance différentielle sur la liaison CTCF et les signaux ATAC-seq (Fig. 5).

ISGS permet le criblage à haut débit des conformations de chromatine spécifiques à une cellule ou à une maladie. Les chercheurs ont réalisé l'ISGS dans les cellules CUTLL1, Jurkat et T normales et ont découvert qu'un élément cis-régulateur (CHD4-insu) proche du gène CHD4 était spécifiquement perdu dans les cellules T-ALL. Les résultats du dépistage indiquent que la perte isolante de CHD4-insu dans les cellules T-ALL pourrait permettre au gène CHD4 d'établir de nouvelles interactions chromatiniennes, régulant ainsi positivement l'expression de CHD4 et favorisant la prolifération des cellules leucémiques. ISGS peut également être utilisé pour découvrir systématiquement de nouveaux facteurs agissant en trans qui régulent la conformation de la chromatine. Grâce à l'analyse d'enrichissement d'importantes séquences régulatrices spécifiques au type de cellule et des sites de liaison aux facteurs de transcription, les chercheurs ont identifié les facteurs de régulation qui contribuent à la conformation du génome spécifique au type cellulaire. Il est intéressant de noter que des études antérieures ont montré que MAZ pouvait réguler la conformation de la chromatine avec le CTCF. Grâce à l'ISGS et à l'analyse de l'enrichissement en facteurs de transcription, les auteurs ont découvert que MAZ est considérablement enrichi dans les régions de chromatine ouvertes, tout en ne montrant qu'une faible liaison dans les régions de chromatine non ouvertes où se lie le CTCF. Ce résultat suggère que MAZ pourrait réguler la conformation du génome indépendamment du CTCF. Les chercheurs voient un grand potentiel dans les modèles d'apprentissage automatique multimodaux qui combinent la séquence d'ADN et les informations sur la chromatine dans la prédiction de la structure de la chromatine. L'architecture multimodale sous-jacente du modèle, Origami, peut être étendue à l'application d'autres données génomiques, telles que les modifications épigénétiques, l'expression des gènes, le criblage fonctionnel des mutations, etc. Les chercheurs prédisent que les futures recherches en génomique s’orienteront davantage vers l’utilisation de modèles d’apprentissage profond comme outils de dépistage génétique informatique primaire, complétés par une nouvelle génération de méthodes de recherche à haut débit validées par des expériences biologiques. Dans cette étude, Tan Jimin, doctorant à la faculté de médecine de l'Université de New York, est le premier auteur, et le Dr Aristotelis Tsirigos et le Dr Xia Bo sont les auteurs co-correspondants. Cette recherche a commencé avec le brainstorming de Xia Bo et Tan Jimin lors du confinement épidémique en octobre 2020. Après deux ans et demi d’amélioration et de peaufinage, elle a été officiellement publiée dans Nature Biotechnology en janvier 2023. Le code et les données de formation de ce projet ont été open source sur GitHub et Zenodo, et sont équipés de Google Colab pour une démonstration fonctionnelle. Adresse du projet : https://github.com/tanjimin/C.Origami Page d'accueil du laboratoire du Dr Xia Bo (Broad Institute du MIT et Harvard) : www.boxialab.org Tsirigos Lab (École de médecine Grossman de l'Université de New York) Page d'accueil : http://www.tsirigos.com
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

Video Face Swap
Échangez les visages dans n'importe quelle vidéo sans effort grâce à notre outil d'échange de visage AI entièrement gratuit !

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)
Sujets chauds
 1662
1662
 14
1418
52
1311
25
1261
29
1234
24
14
1418
52
1311
25
1261
29
1234
24

 Le modèle MoE open source le plus puissant au monde est ici, avec des capacités chinoises comparables à celles du GPT-4, et le prix ne représente que près d'un pour cent de celui du GPT-4-Turbo.
May 07, 2024 pm 04:13 PM
Le modèle MoE open source le plus puissant au monde est ici, avec des capacités chinoises comparables à celles du GPT-4, et le prix ne représente que près d'un pour cent de celui du GPT-4-Turbo.
May 07, 2024 pm 04:13 PM
Imaginez un modèle d'intelligence artificielle qui non seulement a la capacité de surpasser l'informatique traditionnelle, mais qui permet également d'obtenir des performances plus efficaces à moindre coût. Ce n'est pas de la science-fiction, DeepSeek-V2[1], le modèle MoE open source le plus puissant au monde est ici. DeepSeek-V2 est un puissant mélange de modèle de langage d'experts (MoE) présentant les caractéristiques d'une formation économique et d'une inférence efficace. Il est constitué de 236B paramètres, dont 21B servent à activer chaque marqueur. Par rapport à DeepSeek67B, DeepSeek-V2 offre des performances plus élevées, tout en économisant 42,5 % des coûts de formation, en réduisant le cache KV de 93,3 % et en augmentant le débit de génération maximal à 5,76 fois. DeepSeek est une entreprise explorant l'intelligence artificielle générale
 L'IA bouleverse la recherche mathématique ! Le lauréat de la médaille Fields et mathématicien sino-américain a dirigé 11 articles les mieux classés | Aimé par Terence Tao
Apr 09, 2024 am 11:52 AM
L'IA bouleverse la recherche mathématique ! Le lauréat de la médaille Fields et mathématicien sino-américain a dirigé 11 articles les mieux classés | Aimé par Terence Tao
Apr 09, 2024 am 11:52 AM
L’IA change effectivement les mathématiques. Récemment, Tao Zhexuan, qui a prêté une attention particulière à cette question, a transmis le dernier numéro du « Bulletin de l'American Mathematical Society » (Bulletin de l'American Mathematical Society). En se concentrant sur le thème « Les machines changeront-elles les mathématiques ? », de nombreux mathématiciens ont exprimé leurs opinions. L'ensemble du processus a été plein d'étincelles, intense et passionnant. L'auteur dispose d'une équipe solide, comprenant Akshay Venkatesh, lauréat de la médaille Fields, le mathématicien chinois Zheng Lejun, l'informaticien de l'Université de New York Ernest Davis et de nombreux autres universitaires bien connus du secteur. Le monde de l’IA a radicalement changé. Vous savez, bon nombre de ces articles ont été soumis il y a un an.
 Google est ravi : les performances de JAX surpassent Pytorch et TensorFlow ! Cela pourrait devenir le choix le plus rapide pour la formation à l'inférence GPU
Apr 01, 2024 pm 07:46 PM
Google est ravi : les performances de JAX surpassent Pytorch et TensorFlow ! Cela pourrait devenir le choix le plus rapide pour la formation à l'inférence GPU
Apr 01, 2024 pm 07:46 PM
Les performances de JAX, promu par Google, ont dépassé celles de Pytorch et TensorFlow lors de récents tests de référence, se classant au premier rang sur 7 indicateurs. Et le test n’a pas été fait sur le TPU présentant les meilleures performances JAX. Bien que parmi les développeurs, Pytorch soit toujours plus populaire que Tensorflow. Mais à l’avenir, des modèles plus volumineux seront peut-être formés et exécutés sur la base de la plate-forme JAX. Modèles Récemment, l'équipe Keras a comparé trois backends (TensorFlow, JAX, PyTorch) avec l'implémentation native de PyTorch et Keras2 avec TensorFlow. Premièrement, ils sélectionnent un ensemble de
 KAN, qui remplace MLP, a été étendu à la convolution par des projets open source
Jun 01, 2024 pm 10:03 PM
KAN, qui remplace MLP, a été étendu à la convolution par des projets open source
Jun 01, 2024 pm 10:03 PM
Plus tôt ce mois-ci, des chercheurs du MIT et d'autres institutions ont proposé une alternative très prometteuse au MLP – KAN. KAN surpasse MLP en termes de précision et d’interprétabilité. Et il peut surpasser le MLP fonctionnant avec un plus grand nombre de paramètres avec un très petit nombre de paramètres. Par exemple, les auteurs ont déclaré avoir utilisé KAN pour reproduire les résultats de DeepMind avec un réseau plus petit et un degré d'automatisation plus élevé. Plus précisément, le MLP de DeepMind compte environ 300 000 paramètres, tandis que le KAN n'en compte qu'environ 200. KAN a une base mathématique solide comme MLP est basé sur le théorème d'approximation universelle, tandis que KAN est basé sur le théorème de représentation de Kolmogorov-Arnold. Comme le montre la figure ci-dessous, KAN a
 Bonjour, Atlas électrique ! Le robot Boston Dynamics revient à la vie, des mouvements étranges à 180 degrés effraient Musk
Apr 18, 2024 pm 07:58 PM
Bonjour, Atlas électrique ! Le robot Boston Dynamics revient à la vie, des mouvements étranges à 180 degrés effraient Musk
Apr 18, 2024 pm 07:58 PM
Boston Dynamics Atlas entre officiellement dans l’ère des robots électriques ! Hier, l'Atlas hydraulique s'est retiré "en larmes" de la scène de l'histoire. Aujourd'hui, Boston Dynamics a annoncé que l'Atlas électrique était au travail. Il semble que dans le domaine des robots humanoïdes commerciaux, Boston Dynamics soit déterminé à concurrencer Tesla. Après la sortie de la nouvelle vidéo, elle a déjà été visionnée par plus d’un million de personnes en seulement dix heures. Les personnes âgées partent et de nouveaux rôles apparaissent. C'est une nécessité historique. Il ne fait aucun doute que cette année est l’année explosive des robots humanoïdes. Les internautes ont commenté : Les progrès des robots ont fait ressembler la cérémonie d'ouverture de cette année à des êtres humains, et le degré de liberté est bien plus grand que celui des humains. Mais n'est-ce vraiment pas un film d'horreur ? Au début de la vidéo, Atlas est allongé calmement sur le sol, apparemment sur le dos. Ce qui suit est à couper le souffle
 Nouveaux travaux sur la prédiction de séries chronologiques + grand modèle NLP : générer automatiquement des invites implicites pour la prédiction de séries chronologiques
Mar 18, 2024 am 09:20 AM
Nouveaux travaux sur la prédiction de séries chronologiques + grand modèle NLP : générer automatiquement des invites implicites pour la prédiction de séries chronologiques
Mar 18, 2024 am 09:20 AM
Aujourd'hui, j'aimerais partager un travail de recherche récent de l'Université du Connecticut qui propose une méthode pour aligner les données de séries chronologiques avec de grands modèles de traitement du langage naturel (NLP) sur l'espace latent afin d'améliorer les performances de prévision des séries chronologiques. La clé de cette méthode consiste à utiliser des indices spatiaux latents (invites) pour améliorer la précision des prévisions de séries chronologiques. Titre de l'article : S2IP-LLM : SemanticSpaceInformedPromptLearningwithLLMforTimeSeriesForecasting Adresse de téléchargement : https://arxiv.org/pdf/2403.05798v1.pdf 1. Modèle de fond de problème important
 Les robots Tesla travaillent dans les usines, Musk : Le degré de liberté des mains atteindra 22 cette année !
May 06, 2024 pm 04:13 PM
Les robots Tesla travaillent dans les usines, Musk : Le degré de liberté des mains atteindra 22 cette année !
May 06, 2024 pm 04:13 PM
La dernière vidéo du robot Optimus de Tesla est sortie, et il peut déjà fonctionner en usine. À vitesse normale, il trie les batteries (les batteries 4680 de Tesla) comme ceci : Le responsable a également publié à quoi cela ressemble à une vitesse 20 fois supérieure - sur un petit "poste de travail", en sélectionnant et en sélectionnant et en sélectionnant : Cette fois, il est publié L'un des points forts de la vidéo est qu'Optimus réalise ce travail en usine, de manière totalement autonome, sans intervention humaine tout au long du processus. Et du point de vue d'Optimus, il peut également récupérer et placer la batterie tordue, en se concentrant sur la correction automatique des erreurs : concernant la main d'Optimus, le scientifique de NVIDIA Jim Fan a donné une évaluation élevée : la main d'Optimus est l'un des robots à cinq doigts du monde. le plus adroit. Ses mains ne sont pas seulement tactiles
 DualBEV : dépassant largement BEVFormer et BEVDet4D, ouvrez le livre !
Mar 21, 2024 pm 05:21 PM
DualBEV : dépassant largement BEVFormer et BEVDet4D, ouvrez le livre !
Mar 21, 2024 pm 05:21 PM
Cet article explore le problème de la détection précise d'objets sous différents angles de vue (tels que la perspective et la vue à vol d'oiseau) dans la conduite autonome, en particulier comment transformer efficacement les caractéristiques de l'espace en perspective (PV) en vue à vol d'oiseau (BEV). implémenté via le module Visual Transformation (VT). Les méthodes existantes sont globalement divisées en deux stratégies : la conversion 2D en 3D et la conversion 3D en 2D. Les méthodes 2D vers 3D améliorent les caractéristiques 2D denses en prédisant les probabilités de profondeur, mais l'incertitude inhérente aux prévisions de profondeur, en particulier dans les régions éloignées, peut introduire des inexactitudes. Alors que les méthodes 3D vers 2D utilisent généralement des requêtes 3D pour échantillonner des fonctionnalités 2D et apprendre les poids d'attention de la correspondance entre les fonctionnalités 3D et 2D via un transformateur, ce qui augmente le temps de calcul et de déploiement.
