
 Périphériques technologiques
IA
Comment traiter ChatGPT de manière raisonnable : une discussion approfondie par un spécialiste du symbolisme depuis dix ans.
Périphériques technologiques
IA
Comment traiter ChatGPT de manière raisonnable : une discussion approfondie par un spécialiste du symbolisme depuis dix ans.
Comment traiter ChatGPT de manière raisonnable : une discussion approfondie par un spécialiste du symbolisme depuis dix ans.

Au cours des dix dernières années, les connexionnistes, avec le soutien de divers modèles d'apprentissage profond, ont pris la tête du symbolisme sur la voie de l'intelligence artificielle en tirant parti de la puissance du Big Data et de la puissance de calcul élevée.
Mais chaque fois qu'un nouveau grand modèle d'apprentissage profond est publié, comme le récemment populaire ChatGPT, après avoir loué ses puissantes performances, il y a une discussion féroce sur la méthode de recherche elle-même, et les failles et les défauts du modèle lui-même apparaîtront également. .
Récemment, le Dr Qian Xiaoyi du Laboratoire de Beiming, en tant que scientifique et entrepreneur ayant adhéré à l'école symbolique depuis dix ans, a publié une évaluation relativement calme et objective du modèle ChatGPT.
Dans l'ensemble, nous pensons que ChatGPT est un événement marquant.
Le modèle de pré-formation a commencé à montrer des effets puissants il y a un an. Cette fois, il a atteint un nouveau niveau et a attiré davantage d'attention et après cette étape, de nombreux modèles de travail liés au langage naturel humain commenceront à changer, et même certains ; Un grand nombre d'entre eux ont été remplacés par des machines.
Aucune technologie ne se réalise du jour au lendemain Plutôt que de constater ses lacunes, un travailleur scientifique devrait être plus sensible à son potentiel.
La frontière du symbolisme et du connexionnisme
Notre équipe accorde cette fois une attention particulière à ChatGPT, non pas à cause des effets étonnants vus par le public, car nous pouvons encore comprendre de nombreux effets apparemment étonnants au niveau technique.
Ce qui impacte réellement nos sens, c'est que certaines de ses tâches dépassent les frontières entre le genre symbolique et le genre neuronal - la capacité logique semble incarner cette capacité dans plusieurs tâches telles que l'auto-codage et l'évaluation du code.
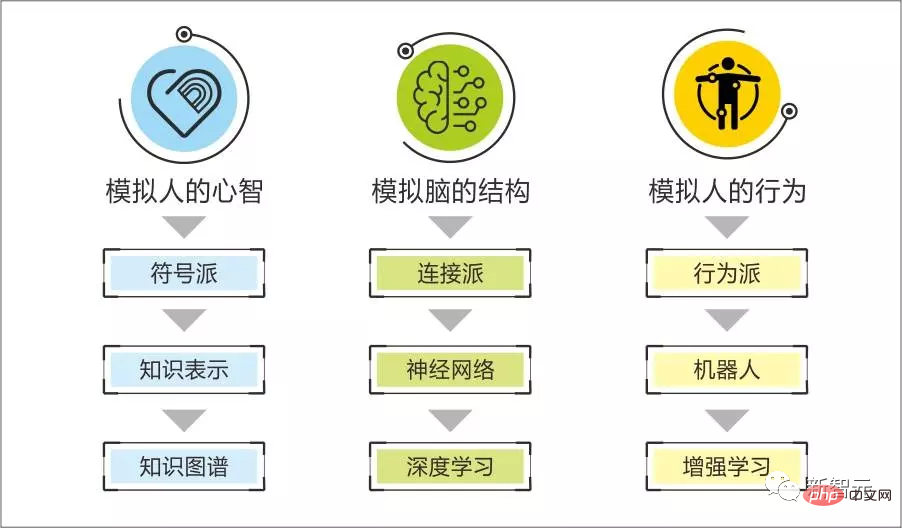
Nous avons toujours cru que l'école symbolique est douée pour reproduire la forte intelligence logique des êtres humains, comme comment résoudre un problème, analyser la cause d'un problème, créer un outil, etc. le connexionnisme est essentiellement un type statistique. Les algorithmes sont utilisés pour découvrir des modèles fluides à partir d'échantillons, comme trouver le modèle de ce qu'il faut dire dans la phrase suivante à travers suffisamment de conversations humaines ; trouver le modèle de reconnaissance et de génération d'images correspondantes à travers un texte descriptif...
Nous pouvons Comprendre ces capacités peut vous rendre exceptionnel grâce à des modèles plus grands, des données de plus haute qualité et des améliorations de la boucle d'apprentissage par renforcement.
Nous pensons que les humains ont les caractéristiques des voies techniques symboliques et neuronales, telles que tous les processus cognitifs réflexifs, les processus d'apprentissage et d'application des connaissances, un grand nombre de pensées réflexives, de comportements, de modèles d'expression, de motivations réflexives et d'émotions. facile à interpréter et à reproduire systématiquement sur la base d’une représentation symbolique.
Lorsque vous verrez suffisamment de visages étrangers, vous aurez la capacité de reconnaître des visages étrangers, et vous ne pourrez pas expliquer pourquoi ;
Vous aurez naturellement la capacité d'imiter le discours du protagoniste masculin après avoir regardé la première série télévisée ; Être capable de discuter sans réfléchir après avoir vécu suffisamment de conversations sont toutes des caractéristiques neurologiques.
Nous pouvons comparer la partie logique forte à la croissance des os, et la « capacité illogique à saisir les lois » à la croissance de la chair.
Il est difficile de « faire pousser de la chair » avec la capacité du symbole « faire grandir le squelette », et il est également difficile pour les nerfs de « faire grandir le squelette » avec la capacité de « faire grandir la chair ».
Tout comme nous accompagnons le processus de construction de l'IA, le système de symboles est efficace pour saisir les dimensions spécifiques des informations de l'interlocuteur, analyser les intentions qui se cachent derrière, déduire des événements liés et donner des suggestions précises, mais il n'est pas bon pour créer conversations fluides et naturelles.
Nous avons également vu que bien que le modèle de génération de dialogue représenté par GPT puisse créer un dialogue fluide, il utilise la mémoire à long terme pour créer une camaraderie cohérente, générer des motivations émotionnelles raisonnables et compléter un raisonnement logique avec une certaine profondeur pour donner des suggestions d'analyse. il est difficile de se rendre compte de ces aspects.
La « grandeur » d'un grand modèle n'est pas un avantage, mais le prix payé par les algorithmes statistiques pour tenter de saisir une partie des règles logiques fortes inhérentes aux données de surface. Il incarne la frontière entre les symboles et les nerfs.
Après avoir acquis une compréhension plus approfondie des principes de ChatGPT, nous avons constaté qu'il ne considère que les opérations logiques relativement simples comme une génération d'entraînement régulière et ne dépasse pas la portée de l'algorithme statistique d'origine, c'est-à-dire la consommation du système. . Il continuera de croître géométriquement à mesure que la profondeur des tâches logiques augmente.
Mais pourquoi ChatGPT peut-il dépasser les limites du grand modèle original ?
Comment ChatGPT dépasse les limites techniques des grands modèles ordinaires
Expliquons dans un langage non technique les principes qui sous-tendent la façon dont ChatGPT dépasse les limites des autres grands modèles.
GPT3 a démontré une expérience qui a surpassé les autres grands modèles lors de son apparition. Ceci est lié à l’auto-supervision, c’est-à-dire à l’auto-étiquetage des données.
Toujours en prenant comme exemple la génération de dialogue : un grand modèle a été entraîné avec des données massives pour maîtriser les règles de 60 tours de dialogue et la phrase suivante.
Pourquoi avez-vous besoin de autant de données ? Pourquoi les humains peuvent-ils imiter le discours du protagoniste masculin après avoir regardé une série télévisée ?
Parce que les humains n'utilisent pas les cycles de dialogue précédents comme entrée pour saisir les règles de ce qu'il faut dire dans la phrase suivante, ils forment plutôt une compréhension du contexte au cours du processus de dialogue subjectif : la personnalité de l'orateur, quel genre de dialogue. les émotions et les motivations actuelles qu'il a, le type de connaissances qui peuvent y être associées, ainsi que plusieurs cycles de dialogue précédents pour comprendre les règles de ce qu'il faut dire dans la phrase suivante.
Nous pouvons imaginer que si le grand modèle identifie d'abord les éléments contextuels du dialogue puis les utilise pour générer les règles de la phrase suivante, par rapport à l'utilisation du dialogue original, les besoins en données pour obtenir le même effet peuvent être considérablement réduits. . Par conséquent, la qualité de l’auto-supervision est un facteur important affectant « l’efficacité du modèle » des grands modèles.
Pour examiner si un service de grand modèle a auto-étiqueté certains types d'informations contextuelles lors de la formation, vous pouvez examiner si la génération de dialogue est sensible à ce type d'informations contextuelles (si le dialogue généré reflète ces informations contextuelles) pour juger.
L'écriture humaine du résultat souhaité est le deuxième point qui entre en jeu.
ChatGPT utilise des sorties écrites manuellement dans plusieurs types de tâches pour affiner le grand modèle de GPT3.5 qui a appris les règles générales de génération de dialogue.
C'est l'esprit du modèle de pré-formation : les règles de dialogue d'une scène fermée peuvent en fait refléter plus de 99 % des règles générales de génération de dialogue humain, tandis que les règles spécifiques à une scène sont inférieures à 1 %. Par conséquent, un grand modèle qui a été entraîné pour comprendre les règles générales du dialogue humain et un petit modèle supplémentaire pour les scènes fermées peuvent être utilisés pour obtenir l'effet, et les échantillons utilisés pour entraîner les règles spécifiques de la scène peuvent être très petits.

Le prochain mécanisme qui entre en jeu est que ChatGPT intègre l'apprentissage par renforcement. L'ensemble du processus ressemble à peu près à ceci :
Préparation de départ : un modèle pré-entraîné (GPT-3.5), un groupe de labers formés, un. Une série d'invites (commandes ou questions, collectées à partir du processus d'utilisation d'un grand nombre d'utilisateurs et de la conception du laber).
Étape 1 : échantillonnez et obtenez au hasard un grand nombre d'invites, et le personnel chargé des données (laber) fournit des réponses standardisées basées sur les invites. Les data scientists peuvent saisir des invites dans GPT-3.5 et se référer au résultat du modèle pour aider à fournir des réponses canoniques.
Les données peuvent être collectées grâce à cette méthode
Le modèle GPT-3.5 est affiné grâce à un apprentissage supervisé basé sur cet ensemble de données. Le modèle obtenu après ajustement est temporairement appelé GPT-3.X.
Étape 2 : échantillonnez au hasard certaines invites (la plupart d'entre elles ont été échantillonnées à l'étape 1) et générez K réponses (K>=2) via GPT-3.X pour chaque invite.
Laber trie les K réponses. Une grande quantité de données de comparaison triées peut former un ensemble de données, et un modèle de notation peut être formé sur la base de cet ensemble de données.
Étape 3 : Utilisez la stratégie d'apprentissage par renforcement PPO pour mettre à jour de manière itérative GPT-3.X et le modèle de notation, et enfin obtenir le modèle de politique. GPT-3.X initialise les paramètres du modèle de politique, échantillonne certaines invites qui n'ont pas été échantillonnées aux étapes 1 et 2, génère une sortie via le modèle de politique et note la sortie par le modèle de notation.
Mettez à jour les paramètres du modèle de politique en fonction du gradient de politique généré par la notation pour obtenir un modèle de politique plus performant.
Laissez un modèle politique solide participer à l'étape 2, obtenez un nouvel ensemble de données grâce au tri et à l'annotation laber, et mettez-le à jour pour obtenir un modèle de notation plus raisonnable.
Lorsque le modèle de notation mis à jour participe à l'étape 3, un modèle de stratégie mis à jour sera obtenu. Effectuez les étapes 2 et 3 de manière itérative, et le modèle de politique final est ChatGPT.
Si vous n'êtes pas familier avec le langage ci-dessus, voici une métaphore facile à comprendre : c'est comme demander à ChatGPT d'apprendre les arts martiaux. La réponse humaine est la routine du maître. GPT3.5 est la routine d'un passionné d'arts martiaux. et le réseau neuronal de notation C'est un évaluateur qui indique à ChatGPT qui a obtenu les meilleurs résultats dans chaque jeu.
Ainsi, ChatGPT peut observer pour la première fois la comparaison entre les maîtres humains et GPT3.5, l'améliorer un peu en direction des maîtres humains sur la base de GPT3.5, puis laisser le ChatGPT évolué participer en tant que passionnés d'arts martiaux. Par rapport aux maîtres humains, le réseau neuronal de notation lui indique à nouveau où se trouve l'écart, afin qu'il puisse s'améliorer à nouveau.
Quelle est la différence entre ce réseau et le réseau neuronal traditionnel ?
Le réseau de neurones traditionnel permet directement à un réseau de neurones d'imiter un maître humain, et ce nouveau modèle doit permettre au réseau de neurones de saisir la différence entre un déjà bon passionné d'arts martiaux et un maître, afin qu'il puisse s'appuyer sur l'existant. base en direction d'un maître humain Petits ajustements, amélioration continue.
Il ressort du principe ci-dessus que le grand modèle généré de cette manière prend des échantillons étiquetés par des humains comme limite de performance.
En d'autres termes, il maîtrise uniquement à la limite les modèles de réponse des échantillons humains étiquetés, mais il n'a pas la capacité de créer de nouveaux modèles de réponse ; deuxièmement, en tant qu'algorithme statistique, la qualité de l'échantillon affectera la précision du modèle ; sortie C'est le défaut fatal de ChatGPT dans les scénarios de recherche et de consultation.
Les exigences en matière de consultation de santé similaire sont rigoureuses, ce qui ne convient pas à ce type de modèle à réaliser en autonomie.
Les capacités de codage et d'évaluation de code incarnées par ChatGPT proviennent d'un grand nombre de codes, d'annotations de description de code et d'enregistrements de modifications sur github. Ceci est toujours à la portée des algorithmes statistiques.
ChatGPT envoie un bon signal selon lequel nous pouvons effectivement utiliser davantage d'idées telles que la « concentration humaine » et « l'apprentissage par renforcement » pour améliorer « l'efficacité du modèle ».
"Big" n'est plus le seul indicateur lié aux capacités du modèle. Par exemple, InstructGPT avec 1,3 milliard de paramètres est meilleur que GPT-3 avec 17,5 milliards de paramètres.
Malgré cela, parce que la consommation de ressources informatiques par la formation n'est qu'un des seuils pour les grands modèles, suivis de données de haute qualité et à grande échelle, nous pensons que le premier paysage commercial est encore : les grands fabricants proposent de grands modèles Construction d'infrastructures, sur la base desquelles les petites usines réalisent de super applications. Les petites usines devenues géantes formeront alors leurs propres grands modèles.
La combinaison des symboles et des nerfs
Nous pensons que le potentiel de la combinaison des symboles et des nerfs se reflète en deux points : entraîner la « viande » sur les « os » et utiliser "os" "Viande".
Si les échantillons de surface contiennent un contexte logique fort (os), comme dans l'exemple précédent d'entraînement au dialogue, les éléments contextuels sont des os, alors simplement entraîner les règles contenant les os à partir des échantillons de surface est très coûteux se reflète dans la demande d'échantillons et le coût d'une formation plus élevée des modèles, c'est-à-dire la « grandeur » des grands modèles.
Si nous utilisons un système symbolique pour générer un contexte et l'utiliser comme exemple d'entrée pour le réseau neuronal, cela équivaut à trouver des modèles dans les conditions de fond d'une forte reconnaissance logique et à entraîner de la « viande » sur le "os".
Si un grand modèle est entraîné de cette manière, alors sa sortie sera sensible à des conditions logiques fortes.
Par exemple, dans la tâche de génération de dialogue, nous saisissons les émotions actuelles, les motivations, les connaissances associées et les événements associés des deux parties participant au dialogue. Le dialogue généré par le grand modèle peut refléter ces contextes. informations avec une certaine probabilité de réaction. Il s’agit d’utiliser de la « viande » sur les « os » d’une logique forte.
Auparavant, nous avons rencontré le problème selon lequel les symboles ne peuvent pas créer de conversations fluides dans le développement de l'IA au niveau du compagnon si l'utilisateur n'est pas disposé à parler à l'IA, toutes les capacités logiques et émotionnelles derrière l'IA. ne peut pas être affiché et il n'y a pas de possibilité d'optimiser en continu les conditions d'itération, nous avons résolu la fluidité du dialogue grâce à une combinaison similaire à celle ci-dessus et au modèle pré-entraîné.
Du point de vue des grands modèles, la simple création d'IA avec de grands modèles manque d'intégrité et de tridimensionnalité.
La « holisticité » se reflète principalement dans la prise en compte de la mémoire à long terme liée au contexte dans la génération du dialogue.
Par exemple, dans la conversation entre l'IA et l'utilisateur la veille, ils ont parlé du fait que l'utilisateur avait un rhume, qu'il était allé à l'hôpital, qu'il avait divers symptômes et combien de temps cela avait duré. ..; le lendemain, l'utilisateur a soudainement exprimé "J'ai mal à la gorge". Ça fait tellement mal.
Dans un grand modèle simple, l'IA répondra avec le contenu dans le contexte, et exprimera "Pourquoi as-tu mal à la gorge ?"... Ces expressions sont immédiat et à long terme. La mémoire est contradictoire, reflétant des incohérences de la mémoire à long terme.
Grâce à la combinaison de l'IA et des systèmes de symboles, l'IA peut associer "l'utilisateur a encore mal à la gorge le lendemain" à "l'utilisateur a eu un rhume hier" à "l'utilisateur est allé au hôpital" et "les autres symptômes de l'utilisateur"… Mettez ces informations en contexte, afin que la capacité de cohérence contextuelle du grand modèle puisse être utilisée pour refléter la cohérence de la mémoire à long terme.
Le « sens tridimensionnel » se reflète dans le fait que l'IA soit obsédée.
Serez-vous obsédé par vos propres émotions, motivations et idées comme les humains ? L'IA créée par un simple grand modèle rappellera au hasard à une personne de boire moins lorsqu'elle socialise, mais lorsqu'elle est combinée avec le système de symboles, elle saura que le foie de l'utilisateur n'est pas bon dans la mémoire à long terme, et combinée avec le commun Si vous sentez que le foie de l'utilisateur n'est pas bon et ne peut pas boire, un message fort et continu sera généré pour empêcher l'utilisateur de boire. Il est recommandé de vérifier si l'utilisateur boit de l'alcool après avoir socialisé, et le manque d'autodiscipline de l'utilisateur le fera. affecter l'humeur, affectant ainsi la conversation ultérieure. C'est un reflet du sens tridimensionnel.
Le grand modèle est-il une intelligence artificielle généraliste ?
À en juger par le mécanisme de mise en œuvre du modèle de pré-formation, il ne dépasse pas la capacité de l'algorithme statistique à « saisir le modèle d'échantillons ». Il utilise simplement l'avantage porteur des ordinateurs pour apporter cette capacité. à un niveau très élevé, et reflète même l'illusion qu'il possède une certaine capacité logique et capacité de résolution.
Un simple modèle pré-entraîné n'aura pas de créativité humaine, de capacités de raisonnement logique approfondies et la capacité de résoudre des tâches complexes.
Par conséquent, le modèle pré-entraîné a une certaine polyvalence en raison d'une migration à faible coût vers des scénarios spécifiques, mais il n'a pas la polyvalence des humains pour « généraliser les représentations intelligentes en constante évolution de la couche supérieure » grâce à des mécanismes de renseignement sous-jacents limités" intelligents.
Deuxièmement, nous voulons parler d'"émergence". Dans l'étude des grands modèles, les chercheurs découvriront que lorsque l'échelle des paramètres du modèle et l'échelle des données dépassent certaines valeurs critiques, certains indicateurs de capacité augmentent rapidement, montrant Effet d'émergence.
En fait, tout système doté de capacités d'apprentissage abstrait montrera une "émergence".
Cela est lié à la nature des opérations abstraites - "non obsédées par l'exactitude d'échantillons individuels ou de suppositions, mais basées sur l'exactitude statistique de l'échantillon global ou de la supposition".
Ainsi, lorsque la taille de l'échantillon est suffisante et que le modèle peut prendre en charge la découverte de modèles détaillés dans les échantillons, une certaine capacité se formera soudainement.
Dans les projets de pensée semi-symbolique, nous voyons que le processus d'apprentissage du langage de l'IA symbolique "émergera" également comme l'acquisition du langage des enfants humains Après avoir écouté et lu dans une certaine mesure, écouter la lecture. la compréhension et la capacité d’expression orale s’amélioreront à pas de géant.
En bref, il est normal que nous considérions l'émergence comme un phénomène, mais il n'est pas correct d'interpréter toutes les mutations de la fonction du système avec des mécanismes peu clairs comme de l'émergence, et d'espérer qu'un algorithme simple puisse émerger avec l'intelligence globale des êtres humains à un moment donné. certaine ampleur. Une attitude scientifique rigoureuse.
Intelligence artificielle générale
Le concept d'intelligence artificielle est apparu presque avec la naissance des ordinateurs. À cette époque, c'était une idée simple de transplanter l'intelligence humaine dans les ordinateurs. C'était le point de départ de l'intelligence artificielle. L’intelligence à laquelle on fait référence est « l’intelligence artificielle générale ».
L'intelligence humaine est l'intelligence générale, et transplanter ce modèle d'intelligence sur un ordinateur est l'intelligence artificielle générale.
Après cela, de nombreuses écoles sont apparues qui ont tenté de reproduire le mécanisme de l'intelligence humaine, mais aucune de ces écoles n'a donné de résultats exceptionnels. Rich Sutton, l'éminent scientifique de Deepmind et fondateur de l'apprentissage par renforcement, a exprimé avec force son point de vue :
Des 70 dernières années La plus grande leçon que l'on peut tirer des années de recherche en intelligence artificielle est que pour chercher à obtenir des résultats à court terme, les chercheurs sont plus enclins à utiliser l'expérience humaine et la connaissance du domaine (imitant les mécanismes humains ), tandis qu'à long terme, l'utilisation de ce qui peut être La méthode générale de calcul étendue s'avère finalement efficace.
Les réalisations exceptionnelles du grand modèle d'aujourd'hui prouvent l'exactitude de sa proposition d'« algorithmisme », mais cela ne signifie pas que la voie consistant à créer des agents intelligents en « suivant l'exemple de la création et en créant des humains » est nécessairement fausse.
Alors pourquoi les écoles précédentes d'imitation des êtres humains ont-elles subi des revers les uns après les autres ? Ceci est lié à l’intégrité du noyau de l’intelligence humaine.
En termes simples, les sous-systèmes formés par le langage humain, la cognition, la prise de décision émotionnelle et les capacités d'apprentissage se soutiennent mutuellement dans la réalisation de la plupart des tâches, et aucun sous-système ne peut fonctionner de manière indépendante.
En tant que système hautement intégré, une apparence de niveau supérieur provient de la coopération de nombreux mécanismes sous-jacents. Tant que l'un d'eux est défectueux, cela affectera l'apparence de cet effet de surface.
Tout comme le corps humain, c'est aussi un système très complexe. Il peut y avoir de légères différences entre une personne en bonne santé et une personne malade, mais cette subtile différence pathologique inhibe les fonctions d'une personne dans toutes les dimensions.
De même, pour l'intelligence artificielle générale, l'effet des 99 premières étapes peut être très limité. Lorsque nous aurons terminé la dernière pièce du puzzle, les fonctions des 99 premières étapes deviendront évidentes.
Les écoles précédentes ont vu une partie de l'intelligence humaine globale de leur propre point de vue et ont obtenu certains résultats en imitant les humains, mais ce n'est qu'une fraction par rapport à l'énergie que le système global peut libérer.
Intelligence des processus et civilisation humaine
Chaque intelligence locale des êtres humains a été ou est de loin dépassée par les ordinateurs, mais même lorsque toutes les intelligences locales sont dépassées par les ordinateurs, nous pouvons toujours affirmer que seuls les humains peuvent créer la civilisation, et que les ordinateurs sont juste un outil.
Pourquoi ?
Parce que derrière la création de la civilisation se cache le processus de diverses activités intelligentes humaines, ce qui signifie que la civilisation humaine provient de « l'intelligence des processus ». C’est une direction qui est actuellement gravement négligée.
Le « processus cognitif » n'est pas une tâche, c'est l'organisation de nombreuses tâches dans un processus.
Par exemple, si l'IA veut guérir les symptômes des patients, il s'agit d'une tâche de « résolution d'objectifs ».
Tout d'abord, nous devons passer à la résolution d'attribution, qui est considérée comme une tâche cognitive. Après avoir trouvé les causes possibles, il s'agit de « résoudre des événements spécifiques » pour déterminer si une éventuelle maladie s'est produite. être décomposé et transféré à d'autres tâches, s'il y a un manque de connaissances au cours du processus, cela deviendra une tâche de « résolution de connaissances ».
Vous pouvez obtenir des connaissances existantes par l'enquête, la recherche et la lecture, ou vous pouvez utiliser la « cognition statistique » ; une fois que la cognition statistique a découvert des corrélations, vous pouvez mieux comprendre la chaîne causale qui la sous-tend pour obtenir une meilleure intervention. il est souvent difficile de En raison du manque de connaissances, cela se transformera en solution de connaissance. Afin de vérifier la conjecture, il est nécessaire de concevoir des expériences pour résoudre l'occurrence d'événements spécifiques...
Après avoir la causalité. chaîne, vous pouvez essayer d'atteindre à nouveau l'objectif, intervenir dans la chaîne causale et transformer l'objectif initial en création, mettre fin, prévenir et maintenir les événements dans la chaîne causale, ce qui revient au processus de « résolution d'objectifs »...

De ce point de vue, des technologies similaires à ChatGPT sont utilisées pour réaliser des tâches. Le cadre symbolique général de l'intelligence artificielle organise ces capacités de tâches locales pour prendre en charge le processus d'activités intelligentes de type humain.
L'intelligence artificielle générale est l'ontologie de « l'humain ». Elle peut utiliser des capacités intériorisées et des outils externalisés pour accomplir des tâches, et organiser ces tâches pour soutenir le processus d'activités intelligentes.
Les êtres humains ont un fort effet grégaire, et une école en période de forte productivité attirera la grande majorité des chercheurs.
Il est rare de réfléchir de manière indépendante aux limites naturelles des capacités d'un parcours technique et de rechercher de manière indépendante des orientations de recherche de plus grande valeur au niveau macro.
Nous pouvons imaginer que si nous parvenons à reproduire l'intelligence globale des êtres humains sur des ordinateurs, afin que les machines puissent prendre en charge le processus d'exploration indépendante de la cognition, de création d'outils, de résolution de problèmes et d'atteinte d'objectifs, avec l'aide des avantages porteurs de les ordinateurs, l'intelligence globale des êtres humains Ce n'est que lorsque l'intelligence des processus sera amplifiée comme avant que nous pourrons véritablement libérer la puissance de l'intelligence artificielle et soutenir la civilisation humaine vers de nouveaux sommets.
À propos de l'auteur

L'auteur, le Dr Qian Xiaoyi est un scientifique en intelligence artificielle symbolique, un ingénieur principal et un haut- niveau certifié par Hangzhou City Talent, l'un des premiers explorateurs du cadre logique bionique et le créateur de la première version du système de symboles du langage M. Fondateur, PDG et président de Bei Mingxing Mou.
Ph.D. en économie appliquée de l'Université Jiao Tong de Shanghai, Master en ingénierie financière de la CGU Drucker School of Business, États-Unis, double licence en mathématiques et finance de Yau Shing-tung Mathematics Elite Class of Collège Zhu Kezhen de l'Université du Zhejiang. Il fait des recherches dans le domaine général de l'IA depuis 11 ans et dirige l'équipe de pratique d'ingénierie depuis 7 ans.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 ChatGPT permet désormais aux utilisateurs gratuits de générer des images en utilisant DALL-E 3 avec une limite quotidienne
Aug 09, 2024 pm 09:37 PM
ChatGPT permet désormais aux utilisateurs gratuits de générer des images en utilisant DALL-E 3 avec une limite quotidienne
Aug 09, 2024 pm 09:37 PM
Le DALL-E 3 a été officiellement introduit en septembre 2023 en tant que modèle considérablement amélioré par rapport à son prédécesseur. Il est considéré comme l’un des meilleurs générateurs d’images IA à ce jour, capable de créer des images avec des détails complexes. Cependant, au lancement, c'était exclu
 Bytedance Cutting lance le super abonnement SVIP : 499 yuans pour un abonnement annuel continu, offrant une variété de fonctions d'IA
Jun 28, 2024 am 03:51 AM
Bytedance Cutting lance le super abonnement SVIP : 499 yuans pour un abonnement annuel continu, offrant une variété de fonctions d'IA
Jun 28, 2024 am 03:51 AM
Ce site a rapporté le 27 juin que Jianying est un logiciel de montage vidéo développé par FaceMeng Technology, une filiale de ByteDance. Il s'appuie sur la plateforme Douyin et produit essentiellement du contenu vidéo court pour les utilisateurs de la plateforme. Il est compatible avec iOS, Android et. Windows, MacOS et autres systèmes d'exploitation. Jianying a officiellement annoncé la mise à niveau de son système d'adhésion et a lancé un nouveau SVIP, qui comprend une variété de technologies noires d'IA, telles que la traduction intelligente, la mise en évidence intelligente, l'emballage intelligent, la synthèse humaine numérique, etc. En termes de prix, les frais mensuels pour le clipping SVIP sont de 79 yuans, les frais annuels sont de 599 yuans (attention sur ce site : équivalent à 49,9 yuans par mois), l'abonnement mensuel continu est de 59 yuans par mois et l'abonnement annuel continu est de 59 yuans par mois. est de 499 yuans par an (équivalent à 41,6 yuans par mois) . En outre, le responsable de Cut a également déclaré que afin d'améliorer l'expérience utilisateur, ceux qui se sont abonnés au VIP d'origine
 Le réglage fin peut-il vraiment permettre au LLM d'apprendre de nouvelles choses : l'introduction de nouvelles connaissances peut amener le modèle à produire davantage d'hallucinations
Jun 11, 2024 pm 03:57 PM
Le réglage fin peut-il vraiment permettre au LLM d'apprendre de nouvelles choses : l'introduction de nouvelles connaissances peut amener le modèle à produire davantage d'hallucinations
Jun 11, 2024 pm 03:57 PM
Les grands modèles linguistiques (LLM) sont formés sur d'énormes bases de données textuelles, où ils acquièrent de grandes quantités de connaissances du monde réel. Ces connaissances sont intégrées à leurs paramètres et peuvent ensuite être utilisées en cas de besoin. La connaissance de ces modèles est « réifiée » en fin de formation. À la fin de la pré-formation, le modèle arrête effectivement d’apprendre. Alignez ou affinez le modèle pour apprendre à exploiter ces connaissances et répondre plus naturellement aux questions des utilisateurs. Mais parfois, la connaissance du modèle ne suffit pas, et bien que le modèle puisse accéder à du contenu externe via RAG, il est considéré comme bénéfique de l'adapter à de nouveaux domaines grâce à un réglage fin. Ce réglage fin est effectué à l'aide de la contribution d'annotateurs humains ou d'autres créations LLM, où le modèle rencontre des connaissances supplémentaires du monde réel et les intègre.
 Afin de fournir un nouveau système de référence et d'évaluation de questions-réponses scientifiques et complexes pour les grands modèles, l'UNSW, Argonne, l'Université de Chicago et d'autres institutions ont lancé conjointement le cadre SciQAG.
Jul 25, 2024 am 06:42 AM
Afin de fournir un nouveau système de référence et d'évaluation de questions-réponses scientifiques et complexes pour les grands modèles, l'UNSW, Argonne, l'Université de Chicago et d'autres institutions ont lancé conjointement le cadre SciQAG.
Jul 25, 2024 am 06:42 AM
L'ensemble de données ScienceAI Question Answering (QA) joue un rôle essentiel dans la promotion de la recherche sur le traitement du langage naturel (NLP). Des ensembles de données d'assurance qualité de haute qualité peuvent non seulement être utilisés pour affiner les modèles, mais également évaluer efficacement les capacités des grands modèles linguistiques (LLM), en particulier la capacité à comprendre et à raisonner sur les connaissances scientifiques. Bien qu’il existe actuellement de nombreux ensembles de données scientifiques d’assurance qualité couvrant la médecine, la chimie, la biologie et d’autres domaines, ces ensembles de données présentent encore certaines lacunes. Premièrement, le formulaire de données est relativement simple, et la plupart sont des questions à choix multiples. Elles sont faciles à évaluer, mais limitent la plage de sélection des réponses du modèle et ne peuvent pas tester pleinement la capacité du modèle à répondre aux questions scientifiques. En revanche, les questions et réponses ouvertes
 Les performances de SOTA, la méthode d'IA de prédiction d'affinité protéine-ligand multimodale de Xiamen, combinent pour la première fois des informations sur la surface moléculaire
Jul 17, 2024 pm 06:37 PM
Les performances de SOTA, la méthode d'IA de prédiction d'affinité protéine-ligand multimodale de Xiamen, combinent pour la première fois des informations sur la surface moléculaire
Jul 17, 2024 pm 06:37 PM
Editeur | KX Dans le domaine de la recherche et du développement de médicaments, il est crucial de prédire avec précision et efficacité l'affinité de liaison des protéines et des ligands pour le criblage et l'optimisation des médicaments. Cependant, les études actuelles ne prennent pas en compte le rôle important des informations sur la surface moléculaire dans les interactions protéine-ligand. Sur cette base, des chercheurs de l'Université de Xiamen ont proposé un nouveau cadre d'extraction de caractéristiques multimodales (MFE), qui combine pour la première fois des informations sur la surface des protéines, la structure et la séquence 3D, et utilise un mécanisme d'attention croisée pour comparer différentes modalités. alignement. Les résultats expérimentaux démontrent que cette méthode atteint des performances de pointe dans la prédiction des affinités de liaison protéine-ligand. De plus, les études d’ablation démontrent l’efficacité et la nécessité des informations sur la surface des protéines et de l’alignement des caractéristiques multimodales dans ce cadre. Les recherches connexes commencent par "S
 Préparant des marchés tels que l'IA, GlobalFoundries acquiert la technologie du nitrure de gallium de Tagore Technology et les équipes associées
Jul 15, 2024 pm 12:21 PM
Préparant des marchés tels que l'IA, GlobalFoundries acquiert la technologie du nitrure de gallium de Tagore Technology et les équipes associées
Jul 15, 2024 pm 12:21 PM
Selon les informations de ce site Web du 5 juillet, GlobalFoundries a publié un communiqué de presse le 1er juillet de cette année, annonçant l'acquisition de la technologie de nitrure de gallium (GaN) et du portefeuille de propriété intellectuelle de Tagore Technology, dans l'espoir d'élargir sa part de marché dans l'automobile et Internet. des objets et des domaines d'application des centres de données d'intelligence artificielle pour explorer une efficacité plus élevée et de meilleures performances. Alors que des technologies telles que l’intelligence artificielle générative (GenerativeAI) continuent de se développer dans le monde numérique, le nitrure de gallium (GaN) est devenu une solution clé pour une gestion durable et efficace de l’énergie, notamment dans les centres de données. Ce site Web citait l'annonce officielle selon laquelle, lors de cette acquisition, l'équipe d'ingénierie de Tagore Technology rejoindrait GF pour développer davantage la technologie du nitrure de gallium. g
 SK Hynix présentera de nouveaux produits liés à l'IA le 6 août : HBM3E à 12 couches, NAND à 321 hauteurs, etc.
Aug 01, 2024 pm 09:40 PM
SK Hynix présentera de nouveaux produits liés à l'IA le 6 août : HBM3E à 12 couches, NAND à 321 hauteurs, etc.
Aug 01, 2024 pm 09:40 PM
Selon les informations de ce site le 1er août, SK Hynix a publié un article de blog aujourd'hui (1er août), annonçant sa participation au Global Semiconductor Memory Summit FMS2024 qui se tiendra à Santa Clara, Californie, États-Unis, du 6 au 8 août, présentant de nombreuses nouvelles technologies de produit. Introduction au Future Memory and Storage Summit (FutureMemoryandStorage), anciennement Flash Memory Summit (FlashMemorySummit) principalement destiné aux fournisseurs de NAND, dans le contexte de l'attention croissante portée à la technologie de l'intelligence artificielle, cette année a été rebaptisée Future Memory and Storage Summit (FutureMemoryandStorage) pour invitez les fournisseurs de DRAM et de stockage et bien d’autres joueurs. Nouveau produit SK hynix lancé l'année dernière
 SearchGPT : Open AI affronte Google avec son propre moteur de recherche IA
Jul 30, 2024 am 09:58 AM
SearchGPT : Open AI affronte Google avec son propre moteur de recherche IA
Jul 30, 2024 am 09:58 AM
L’Open AI fait enfin son incursion dans la recherche. La société de San Francisco a récemment annoncé un nouvel outil d'IA doté de capacités de recherche. Rapporté pour la première fois par The Information en février de cette année, le nouvel outil s'appelle à juste titre SearchGPT et propose un c
