


Introduction : Le titre de ce partage est l'application de la technologie d'apprentissage de la représentation graphique dans les systèmes de recommandation de médicaments.
Comprend principalement les quatre parties suivantes :
La recommandation de médicaments est un sous-problème des soins médicaux intelligents. Commençons par le contexte général des soins médicaux intelligents. Il est urgent de mettre en place des soins médicaux intelligents dans notre pays. À mesure que la population augmente et vieillit, la population exige des soins de haute qualité. les services médicaux continuent d’augmenter. Deux ensembles de données dans la figure : premièrement, le nombre de visites dans les établissements médicaux à travers le pays est de 6,05 milliards, soit une augmentation d'une année sur l'autre de 22,4 %, deuxièmement, les statistiques sur les conditions médicales et sanitaires de divers pays dans The Lancet ; montrent que seulement 57,4 % des médecins chinois sont titulaires d'un baccalauréat ou plus, y compris les médecins. Le nombre de praticiens pour 10 000 habitants dans 16 catégories de professions de santé, y compris les infirmières et les agents de santé communautaires, en Chine ne représente qu'un tiers de celui de la États-Unis. Le nombre de diagnostics et de traitements dans notre pays continue d'augmenter, mais les ressources médicales et les normes médicales restent insuffisantes par rapport aux pays développés. À cela s'ajoute le problème de la répartition inégale des ressources médicales. Le niveau médical des institutions médicales primaires est relativement limité, tandis que l'offre des institutions de haut niveau dépasse la demande. Par conséquent, comment tirer pleinement parti de l’expérience en matière de diagnostic et de traitement des institutions médicales de haut niveau pour contribuer à améliorer le niveau médical des institutions médicales primaires est une question importante qui doit être résolue de toute urgence.
Avec l'accélération de la numérisation des institutions médicales ces dernières années, un grand nombre d'institutions médicales dans mon pays, en particulier les meilleures Les institutions médicales au niveau national telles que les hôpitaux tertiaires ont accumulé des données de dossiers médicaux électroniques très riches. Si la technologie de l'intelligence artificielle Big Data peut être utilisée pour exploiter pleinement ces informations et extraire des connaissances pertinentes, elle peut nous aider à comprendre certaines méthodes de diagnostic et de traitement et les idées des experts médicaux de ces institutions de haut niveau, puis soutenir un suivi intelligent. visites, analyse d’images médicales, suivi des maladies chroniques, etc. Une série d’applications médicales intelligentes en aval revêtent une importance significative.
De plus en plus de technologies d'IA médicale sont appliquées plus largement, ce qui favorise également l'équité et l'inclusivité des services médicaux. Certaines technologies d'IA, telles que l'analyse d'images médicales, ont obtenu des résultats impressionnants, mais elles sont rarement utilisées dans les systèmes de recommandation de médicaments. La raison en est que les systèmes de recommandation de médicaments sont très différents des systèmes de recommandation traditionnels et qu'il existe également de nombreux problèmes techniques. .

Le premier défi est que le scénario d'application des systèmes de recommandation traditionnels basés sur des méthodes telles que le filtrage collaboratif consiste principalement à recommander un article à un utilisateur à la fois. temps. L’entrée est la représentation d’un seul élément et d’un seul utilisateur, et la sortie est un score du degré de correspondance entre les deux. Cependant, lors de la recommandation de médicaments, les médecins doivent souvent prescrire un groupe de médicaments aux patients en même temps. Le système de recommandation de médicaments est en fait un système de recommandation de paquets, appelé système de recommandation de paquets, qui recommande simultanément un ensemble de médicaments à un utilisateur. Comment combiner la recommandation de médicaments avec le système de recommandation de paquets est le premier grand défi auquel nous sommes confrontés.
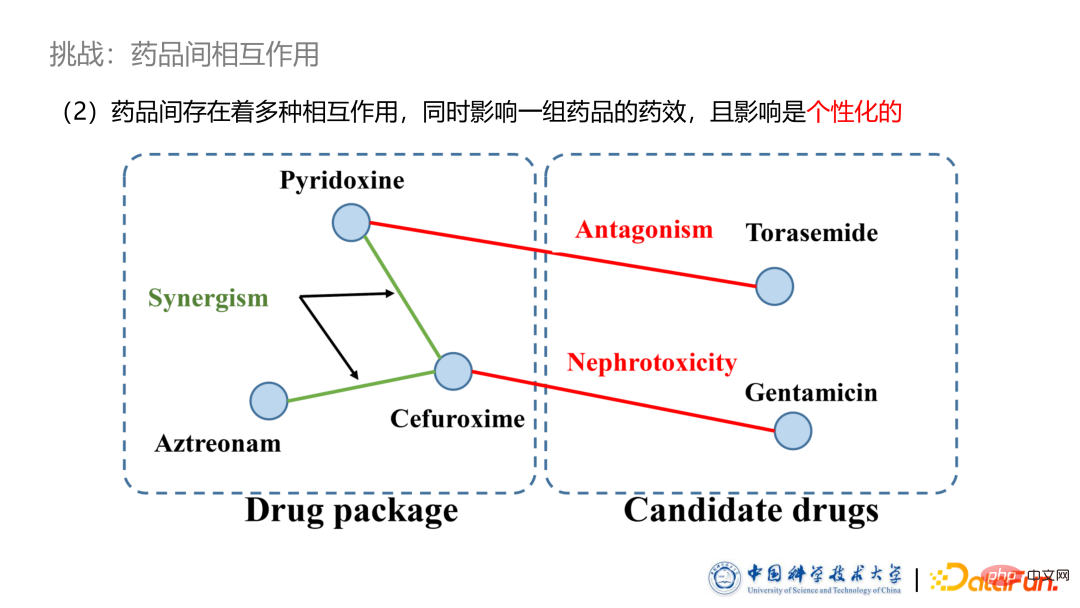
Le deuxième défi du système de recommandation de médicaments réside dans la diversité des interactions entre les médicaments. Il existe des effets synergiques entre certains médicaments qui favorisent les effets de chacun, et il existe des antagonismes entre certains médicaments qui neutralisent les effets de chacun. Même la combinaison de certains médicaments peut entraîner une toxicité ou d'autres effets secondaires. Le patient sur la photo souffre d'une sorte de maladie rénale. La partie gauche montre les médicaments prescrits par le médecin au patient. Certains médicaments ont des effets synergiques et peuvent favoriser l'efficacité du médicament. La partie droite montre les médicaments symptomatiques à haute fréquence analysés statistiquement. On peut constater que ces médicaments peuvent ne pas être sélectionnés en raison de certains effets antagonistes. Les médicaments suivants peuvent être toxiques pour certains médicaments existants et ne sont donc pas utilisés par ce patient.
De plus, les effets des interactions médicamenteuses sont individualisés. Nous avons constaté dans les statistiques qu'un grand nombre de médicaments ayant des effets antagonistes, voire toxiques, sont utilisés simultanément. Selon l'analyse, les médecins prescrivent des médicaments en fonction de l'état du patient et en tenant compte des effets d'interaction. Par exemple, certains patients dont les reins sont sains peuvent souvent tolérer une certaine néphrotoxicité médicamenteuse. Nous devons donc procéder à une modélisation et à une analyse personnalisées des interactions entre les médicaments.

En résumé, combinée aux défis ci-dessus, la technologie d'apprentissage de la représentation graphique est très appropriée pour résoudre les problèmes existants dans les systèmes de recommandation de médicaments. Avec le développement rapide des réseaux neuronaux graphiques, les gens se rendent compte que la technologie des réseaux neuronaux graphiques peut modéliser très efficacement l'effet de combinaison entre les nœuds et la relation entre les nœuds. Cela nous incite à penser que la technologie d'apprentissage de la représentation graphique peut devenir un outil utile pour créer des systèmes de recommandation de médicaments. Un outil pointu.
Par exemple, sur l'image, nous pouvons construire un paquet de médicaments dans un graphique en fonction des interactions qu'il contient, et le modéliser via le réseau neuronal graphique existant. Sur la base des idées ci-dessus, nous avons utilisé la technologie d'apprentissage profond des graphes pour réaliser deux travaux sur le système de recommandation de médicaments, qui ont été publiés respectivement dans les revues WWW et TOIS. Ce qui suit est une introduction détaillée.
Tout d'abord, présentons l'article sur la recommandation sur le paquet de médicaments que nous avons publié sur WWW2021. Cet article adopte la méthode de définition de modèle discriminante largement utilisée dans les systèmes de recommandation de packages pour la modélisation, et utilise également la technologie d'apprentissage de la représentation graphique comme partie technologique de base.

Présentez d'abord la description des données utilisée dans le travail.
Les dossiers médicaux électroniques que nous avons utilisés dans nos travaux de recherche proviennent d'une véritable base de données de dossiers médicaux électroniques d'un grand hôpital tertiaire. Chaque dossier médical électronique comprend les types d'informations suivants : Premièrement, les informations de base du patient, y compris les informations de base. du patient L'âge, le sexe, l'assurance médicale, etc. ; le deuxième concerne les informations de laboratoire du patient, y compris les anomalies des résultats de laboratoire qui préoccupent le médecin, et les types d'anomalies : élevées, faibles, positives, etc. ; est la description de l'état du patient rédigée par le médecin : elle comprend des informations telles que la raison pour laquelle le patient a été admis à l'hôpital, ainsi qu'un examen physique préliminaire et enfin, un ensemble de médicaments prescrits par le médecin au patient ;
Ces données du dossier médical électronique sont des données hétérogènes, comprenant des informations structurées telles que l'âge, le sexe, les tests de laboratoire et des informations textuelles non structurées telles que la description de la maladie.

Afin d'étudier les interactions entre les médicaments, nous avons collecté certains attributs des médicaments et données d'interaction à partir de deux grandes bases de connaissances en ligne sur les médicaments open source, DrugBank et Pharmaceutical Network. Les interactions médicamenteuses sont des descriptions en langage naturel basées sur certains modèles. Comme le montre l'image ci-dessus, la colonne de description explique comment un certain médicament peut augmenter ou affaiblir le métabolisme, etc. Le mot du milieu est le modèle, et le recto et le verso sont le modèle. noms de médicaments remplis. Par conséquent, tant que la classification du modèle est claire, toutes les interactions médicamenteuses contenues dans la base de données peuvent être marquées.
Par conséquent, sous la direction de médecins professionnels, nous avons considéré les interactions médicamenteuses en trois catégories : aucune interaction, synergie et antagonisme, marqué le modèle et obtenu la classification des interactions médicamenteuses.
2. Prétraitement des données et définition du problèmePour le prétraitement des données, pour les données du dossier médical électronique, nous les divisons en deux parties : les informations de base du patient et les informations de laboratoire, que nous traitons en un seul vecteur One-hot ; partie du texte de description de la condition, nous la convertissons en texte de longueur fixe via un remplissage et une coupure. Pour les données sur les interactions médicamenteuses : nous les convertissons en une matrice d’interactions médicamenteuses.
Dans le même temps, le problème est défini comme suit : étant donné un ensemble de descriptions de patients et les packages de médicaments de vérité terrain correspondants, nous formerons une fonction de notation personnalisée qui peut saisir le patient donné et le package d'échantillons et le sortir. une notation de diplôme correspondante. C’est clairement ainsi qu’est défini un modèle discriminant.
3. Présentation du modèle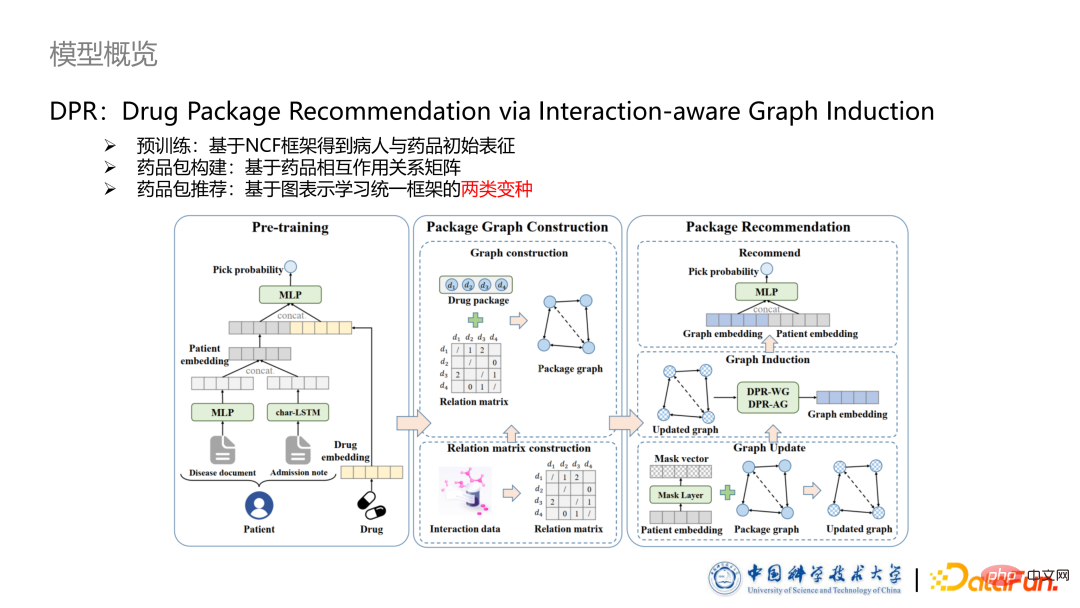 Le titre de l'article proposé dans cet article est DPR : Drug Package Recommendation via Interaction-aware Graph Induction. Le modèle se compose de trois parties :
Le titre de l'article proposé dans cet article est DPR : Drug Package Recommendation via Interaction-aware Graph Induction. Le modèle se compose de trois parties :
Partie pré-formation Nous obtenons la représentation initiale des patients et des médicaments basée sur le cadre NCF.
Dans la partie construction d'un emballage de médicament, nous proposons une méthode pour construire un emballage de médicament dans un graphe de médicament basé sur le type de relation d'interaction médicamenteuse.
La dernière partie est un cadre de recommandation pour les packages de médicaments basés sur des graphiques, dans lequel deux variantes différentes sont conçues pour comprendre comment modéliser l'interaction entre les médicaments sous deux perspectives différentes.

Tout d'abord, la partie pré-formation se déroule selon la méthode traditionnelle de recommandation individuelle. Dans un cas donné, les médicaments que le médecin a utilisés pour le patient sont des cas positifs et les médicaments qui n'ont pas été utilisés sont des cas négatifs. Pré-entraînés par BPRLoss, les médicaments consommés obtiennent des scores plus élevés que ceux qui n’ont pas été consommés.
La partie pré-formation consiste principalement à capturer des informations de base sur les effets des médicaments, fournissant une base pour capturer des interactions plus complexes ultérieurement. Pour la partie One-hot, nous utilisons MLP pour extraire les fonctionnalités ; pour la partie texte, nous utilisons LSTM pour extraire les fonctionnalités du texte.

Par rapport à la recommandation traditionnelle, la question centrale de la recommandation de médicaments est de savoir comment prendre en compte l'interaction entre les médicaments et obtenir la caractérisation de l'emballage du médicament. Sur cette base, cet article propose une méthode de modélisation d'emballages pharmaceutiques basée sur un modèle graphique. Tout d'abord, les relations d'interaction médicamenteuse étiquetées seront converties en une matrice d'interaction médicamenteuse, où différentes valeurs représentent différents types d'interactions. Ensuite, sur la base de ce moment, n'importe quel paquet de médicaments donné peut être converti en un graphique de médicaments hétérogène. Les nœuds du graphique correspondent aux médicaments dans le paquet de médicaments, et les attributs des nœuds sont que les nœuds correspondent à l'intégration pré-entraînée dans le paquet de médicaments. étape précédente. Dans le même temps, afin d'éviter des calculs excessifs, nous n'avons pas construit le graphique des médicaments dans un graphique complet, c'est-à-dire que nous n'avons pas autorisé de limite entre deux médicaments, mais nous les avons sélectionnés de manière sélective, plus précisément ceux étiquetés Les bords. des paires de médicaments qui ont été transmises et des bords dont la fréquence dépasse un certain seuil. Afin de caractériser efficacement le graphe des médicaments, nous proposons deux manières de formaliser les attributs de bord sur le graphe des médicaments. Le premier formulaire est le DPR-WG, qui utilise un graphique pondéré pour représenter le graphique des médicaments. La première étape consiste à initialiser les valeurs de bord complètes en fonction des interactions médicamenteuses marquées, où -1 représente l'antagonisme, +1 représente la synergie et 0 représente l'absence d'interaction ou une inconnue. Le vecteur de masque est ensuite utilisé pour effectuer des mises à jour personnalisées des poids de bord dans le graphique des médicaments. Ce vecteur de masque reflète l'interaction de différents médicaments et le degré d'impact personnalisé sur chaque patient. Sa méthode de calcul consiste à utiliser une couche non linéaire plus une fonction sigmoïde afin que la valeur de chaque dimension soit comprise entre 0 et 1, réalisant ainsi. la fonction de sélection des fonctionnalités et d'ajustements personnalisés de l'interaction des médicaments. Le processus de mise à jour du graphique des médicaments consiste d'abord à calculer un facteur de mise à jour dans DPR-WG, puis à mettre à jour le facteur de mise à jour en multipliant ou en ajoutant le poids du bord correspondant. Lors d'expériences ultérieures, il a été constaté que la méthode de mise à jour avait peu d'impact sur les résultats. Dans le processus de représentation graphique des médicaments, nous avons conçu une méthode pour représenter les médicaments basée sur des graphiques pondérés. Pour résumer, nous avons d'abord conçu un processus de mise à jour des informations pour les graphiques pondérés : agréger les informations des voisins Au cours du processus d'agrégation, le degré d'agrégation est ajusté individuellement en fonction du poids du bord. Nous avons ensuite utilisé un mécanisme d'auto-attention pour calculer les poids entre les différents nœuds, et utilisé un MLP d'agrégation pour agréger le graphique afin d'obtenir la représentation finale de l'ensemble du graphique des médicaments. Par la suite, la représentation du patient et la représentation de l'image du médicament sont entrées dans la fonction de notation, et le résultat peut être obtenu à des fins de recommandation. De plus, cet article utilise BPRLoss pour entraîner le modèle et présente une méthode d'échantillonnage négatif, correspondant à 1 échantillon positif et 10 échantillons négatifs. De même, nous pouvons utiliser BPRLoss pour l'entraînement, mais la différence est que nous introduisons en outre une fonction de perte d'entropie croisée pour la classification des bords, en espérant que le vecteur de bord puisse contenir des informations de catégorie d'interactions médicamenteuses. Comme le signe initialisé dans la variante précédente conserve naturellement cette information, mais pas le graphe de cette variante, cette information est complétée par l'introduction d'une fonction de perte.
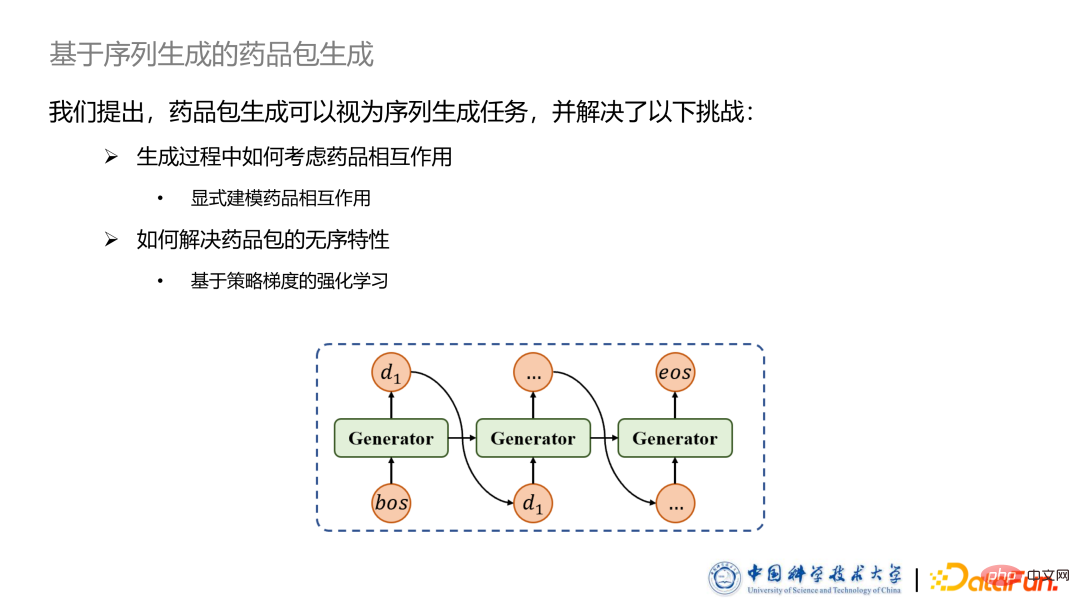
D'après les résultats expérimentaux, nos deux modèles ont dépassé les autres modèles discriminants dans différents indicateurs d'évaluation. Parallèlement, nous avons également mené une analyse de cas : en utilisant la méthode t-SNE pour projeter le vecteur masque mentionné précédemment sur un espace bidimensionnel. Comme le montre la figure, par exemple, les médicaments utilisés par les femmes enceintes, les nourrissons et les patients atteints du foie ont une tendance très évidente à se regrouper en grappes, ce qui prouve l’efficacité de notre méthode. Le discriminant ci-dessus Le modèle ne peut sélectionner que parmi les packages de médicaments existants et n'a pas la capacité de générer de nouveaux packages de médicaments, ce qui affectera l'effet de recommandation. Ensuite, nous présenterons les travaux d'extension des travaux précédents publiés dans la revue TOIS, dans le but d'espérer. que le modèle Capacité à générer des packages de médicaments entièrement nouveaux adaptés aux nouveaux patients. Ce travail conserve l'idée centrale de l'apprentissage de la représentation graphique dans l'article précédent, tout en changeant complètement la définition du problème et en définissant le modèle Le modèle génératif introduit une technologie de génération de séquences et d'apprentissage par renforcement, ce qui améliore considérablement l'effet de recommandation. 2. Méthode de génération heuristique 3. Aperçu du modèle Ce modèle contient principalement trois parties, à savoir la diffusion d'informations sur le diagramme d'interactions médicamenteuses, la représentation des patients et le module de génération de paquets de médicaments, le plus grand La différence par rapport à ce qui précède réside dans le module de génération de paquets de médicaments. tableau des interactions médicamenteuses Après plusieurs tours (généralement 2) de transmission de messages, nous extrayons le nœud Embedding comme médicament Embedding à utiliser. La partie représentation du patient utilise également MLP et LSTM pour extraire le vecteur de représentation du patient, et calcule également le vecteur de masque, qui est ensuite utilisé pour capturer le vecteur de représentation personnalisé du patient. La tâche de génération de paquets de médicaments peut être considérée comme une tâche de génération de séquence, mise en œuvre à l'aide d'un réseau neuronal récurrent RNN. Mais cette méthode apporte également deux défis majeurs : Le premier défi est de savoir comment considérer les médicaments générés au cours du processus de génération. Interactions avec les interactions existantes. médicaments. Pour cela, nous proposons une méthode basée sur des vecteurs d’interactions médicamenteuses pour modéliser explicitement les interactions entre médicaments. Le deuxième défi est que l'exemple de package est un ensemble et est essentiellement non ordonné, mais les tâches de génération de séquences visent souvent des séquences ordonnées. Méthode séquentielle. À cette fin, nous avons proposé une méthode d'apprentissage par renforcement basée sur le gradient politique, et ajouté une méthode basée sur SCST pour améliorer l'effet et la stabilité de cet algorithme. Afin de prendre en compte les interactions entre médicaments sans apporter trop de charge de calcul au modèle, nous proposons de À cette étape, le vecteur d'interaction entre le médicament nouvellement généré et le médicament précédent est explicitement calculé. Cette méthode de calcul vectoriel provient d'une couche du réseau neuronal graphique précédent. En même temps, on ajoute le vecteur masque et le vecteur interaction pour multiplier les éléments correspondants pour introduire les informations personnalisées du patient. Enfin, additionnez les vecteurs d'interaction de tous les médicaments et utilisez le MLP pour les fusionner afin d'obtenir un vecteur d'interaction complet. L'intégration ultérieure de ce vecteur dans le modèle de séquence classique pour la génération résout le premier défi.
Le plus gros inconvénient de la méthode ci-dessus basée sur la probabilité maximale est que l'emballage des médicaments a un ordre strict, et certaines méthodes spécifient manuellement l'ordre des médicaments, comme le tri par fréquence, le tri par première lettre, etc. Cela détruira les caractéristiques de la collection de paquets de médicaments et perdra également une partie des performances du modèle. Par conséquent, nous proposons un modèle de génération de paquets de médicaments basé sur l'apprentissage par renforcement. L'objectif du modèle dans l'apprentissage par renforcement est de maximiser la fonction de récompense définie artificiellement. Une fois que le modèle a généré un ensemble complet de médicaments, donner une fonction de perte de récompense indépendante de l'ordre peut réduire la dépendance du modèle à l'égard de l'ordre. Cet article utilise la valeur F comme récompense, qui est une fonction indépendante de l'ordre et est l'indice d'évaluation qui nous préoccupe. . Cet article utilise la valeur F comme indice d'évaluation et adopte une méthode de formation basée sur le gradient politique dans la méthode de formation, et ne sera pas déduit en détail ici. Parmi les méthodes de formation basées sur le gradient politique, une des plus bien -méthodes connues est Il utilise une ligne de base pour réduire la variance des estimations de gradient, augmentant ainsi la stabilité de la formation. Nous avons donc utilisé une méthode de formation basée sur SCST, à savoir la méthode de formation en séquence autocritique. La ligne de base provient également de la récompense obtenue par le package de médicaments généré par le modèle lui-même. La façon dont je le génère est la méthode normale de génération de séquences de recherche gourmande. Nous espérons que la récompense du paquet de médicaments échantillonné par le modèle basé sur le gradient politique sera supérieure à celle du paquet de médicaments généré par le Recherche gourmande traditionnelle. Sur cette base, cet article conçoit une fonction de perte pour l'apprentissage par renforcement, comme le montre la figure. Le processus de dérivation ne sera pas présenté en détail ici. De plus, l'une des caractéristiques de l'apprentissage par renforcement est que la formation est difficile, nous combinons donc les deux méthodes de formation ci-dessus .Tout d'abord, le modèle est pré-entraîné à l'aide de la méthode d'estimation extrêmement naturelle, puis la méthode d'apprentissage par renforcement est utilisée pour affiner les paramètres du modèle. Viennent ensuite les résultats expérimentaux du modèle. Dans le tableau ci-dessus, tous les paquets de médicaments sont recherchés à l'aide de Greedy Generated. Tout d’abord, les performances des méthodes basées sur des modèles génératifs sont généralement meilleures que celles basées sur des modèles discriminatifs. Cette expérience prouve que les modèles génératifs seront un meilleur choix. Ce modèle surpasse toutes les autres lignes de base en valeur F. De plus, les performances du modèle basé sur l’apprentissage par renforcement ont largement dépassé celles du modèle basé sur le maximum de vraisemblance, prouvant l’efficacité de la méthode d’apprentissage par renforcement. Par la suite, nous avons également mené une série d'expériences d'ablation. Nous avons supprimé le graphique d'interaction, y compris le vecteur de masque d'interaction et le module d'apprentissage par renforcement pour l'ablation, et les résultats ont prouvé que chacun de nos modules est efficace. Dans le même temps, on constate que si le module SCST est supprimé, l'effet de modèle diminue considérablement, ce qui prouve que l'apprentissage par renforcement est effectivement difficile à entraîner. Sans restrictions de base, l’ensemble du processus de formation sera très nerveux. Enfin, nous avons également fait beaucoup d'analyses de cas, et nous pouvons constater que les femmes enceintes et les bébés ont des préférences personnalisées évidentes. Dans le même temps, nous avons ajouté quelques maladies courantes supplémentaires telles que les maladies de l’estomac, les maladies cardiaques, etc. Les masques vecteurs de ces maladies sont très dispersés et ne forment pas de clusters. Les conditions des patients atteints de maladies courantes sont diverses et il n'y aura pas de situations particulièrement personnalisées. Contrairement aux femmes enceintes et aux nourrissons, il existe des dépistages très évidents de médicaments. Par exemple, certains médicaments pédiatriques doivent être désignés et certains médicaments ne peuvent pas être utilisés. par les femmes enceintes. En même temps, nous avons projeté le vecteur d'interaction du médicament, et nous pouvons voir que l'interaction entre les deux médicaments, Une synergie et un antagonisme se forment. Deux situations opposées différentes sont présentées, indiquant que le modèle capture les différents effets provoqués par deux interactions différentes. En résumé, nous la recherche se concentre sur les recommandations personnalisées de paquets de médicaments tenant compte des interactions, y compris les recommandations discriminantes sur les paquets de médicaments et les recommandations génératives sur les paquets de médicaments. Les deux ont en commun d'utiliser la technologie d'apprentissage de la représentation graphique pour modéliser les interactions entre les médicaments, et tous deux utilisent des masques que les vecteurs prennent en compte l'état du patient pour une perception personnalisée de l'interaction. La plus grande différence entre les deux travaux est la différence de définition du problème. Pour le modèle discriminant, ce que nous voulons, c'est une fonction de notation. , donc pour le modèle génératif, ce que nous voulons, c'est un générateur. Les expériences ont prouvé que le modèle génératif est en fait une meilleure définition du problème. 
 La deuxième variante consiste à utiliser des graphiques d'attributs pour représenter les graphiques de médicaments. La première étape consiste à initialiser le vecteur de bord en fusionnant les vecteurs de nœuds aux deux extrémités du bord via un MLP. Ensuite, le vecteur de masque est également utilisé pour mettre à jour le vecteur de bord. À ce stade, la méthode de mise à jour n'est plus un facteur de mise à jour, mais calcule un vecteur de mise à jour qui est multiplié élément par élément avec le vecteur de bord du médicament pour obtenir. les attributs de bord mis à jour. Nous avons spécialement conçu un GNN pour les graphes d'attributs. Le processus de transmission du message calcule d'abord le message en fonction du vecteur de bord et de l'intégration de nœuds aux deux extrémités pour la propagation, et obtient l'intégration du graphique grâce à des méthodes d'auto-attention et d'agrégation.
La deuxième variante consiste à utiliser des graphiques d'attributs pour représenter les graphiques de médicaments. La première étape consiste à initialiser le vecteur de bord en fusionnant les vecteurs de nœuds aux deux extrémités du bord via un MLP. Ensuite, le vecteur de masque est également utilisé pour mettre à jour le vecteur de bord. À ce stade, la méthode de mise à jour n'est plus un facteur de mise à jour, mais calcule un vecteur de mise à jour qui est multiplié élément par élément avec le vecteur de bord du médicament pour obtenir. les attributs de bord mis à jour. Nous avons spécialement conçu un GNN pour les graphes d'attributs. Le processus de transmission du message calcule d'abord le message en fonction du vecteur de bord et de l'intégration de nœuds aux deux extrémités pour la propagation, et obtient l'intégration du graphique grâce à des méthodes d'auto-attention et d'agrégation. 3. Forfait de médecine générative recommandé
1. 🎜#
La différence fondamentale entre le modèle discriminant et le modèle génératif est que le modèle discriminant évalue la correspondance entre un patient donné et un paquet de médicaments donné, tandis que le modèle génératif génère des médicaments candidats pour le pack patient. et choisissez le meilleur pack de médicaments. 
# 🎜🎜#Compte tenu des lacunes du modèle discriminant proposé ci-dessus, nous avons conçu des méthodes de génération heuristique : en ajoutant et en supprimant certains médicaments dans les paquets de médicaments de patients similaires, des enregistrements historiques sont formés. -des packs de médicaments vus pour les modèles parmi lesquels choisir. Les résultats expérimentaux prouvent que cette méthode simple est très efficace et constitue une base pour les méthodes ultérieures.

#🎜 🎜# Vient ensuite l'article Interaction-aware Drug Package Recommendation via Policy Gradient publié dans TOIS. Le modèle proposé dans cet article s'appelle DPG, ce qui est différent du DPR de l'article précédent G ici c'est Generation.





Génération de paquets de médicaments basée sur l'apprentissage par renforcement



4. Résumé et perspectives
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Application de l'intelligence artificielle dans la vie
Application de l'intelligence artificielle dans la vie
 Quel est le concept de base de l'intelligence artificielle
Quel est le concept de base de l'intelligence artificielle
 Le concept m2m dans l'Internet des objets
Le concept m2m dans l'Internet des objets
 emplacement.hash
emplacement.hash
 Pourquoi le stockage local échoue-t-il si rapidement ?
Pourquoi le stockage local échoue-t-il si rapidement ?
 Que signifie utiliser une imprimante hors ligne
Que signifie utiliser une imprimante hors ligne
 Comment vérifier la mémoire
Comment vérifier la mémoire
 Quelle est la différence entre Dubbo et Zookeeper
Quelle est la différence entre Dubbo et Zookeeper








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



