1. Pourquoi devrions-nous maîtriser la communication inter-processus
L'efficacité du code multithread de Python est limitée par GIL et ne peut pas être accélérée par les processeurs multicœurs. Cependant, la méthode multi-processus peut contourner GIL et en tirer parti. d'accélération multi-CPU Améliore considérablement les performances du programme
, mais la communication inter-processus est un problème qui doit être pris en compte. Un processus est différent d'un thread. Un processus possède son propre espace mémoire indépendant et ne peut pas utiliser de variables globales pour transférer des données entre processus.
Dans les exigences réelles du projet, il y a souvent des tâches informatiques intensives ou en temps réel. Parfois, une grande quantité de données, telles que des images, des objets volumineux, etc., doivent être transférées entre les processus. via la sérialisation des fichiers ou l'interface réseau, il est difficile de répondre aux exigences en temps réel et le package de file d'attente de messages tiers de redis, kaffka, RabbitMQ est utilisé, ce qui complique à nouveau le système.
Le module multitraitement Python lui-même fournit diverses méthodes de communication inter-processus très efficaces telles que le mécanisme de message, le mécanisme de synchronisation et la mémoire partagée
. Comprendre et maîtriser l'utilisation de diverses méthodes de communication inter-processus Python, ainsi que les mécanismes de sécurité, peuvent contribuer à améliorer considérablement les performances d'exécution du programme.
2. Introduction aux diverses méthodes de communication entre les processus
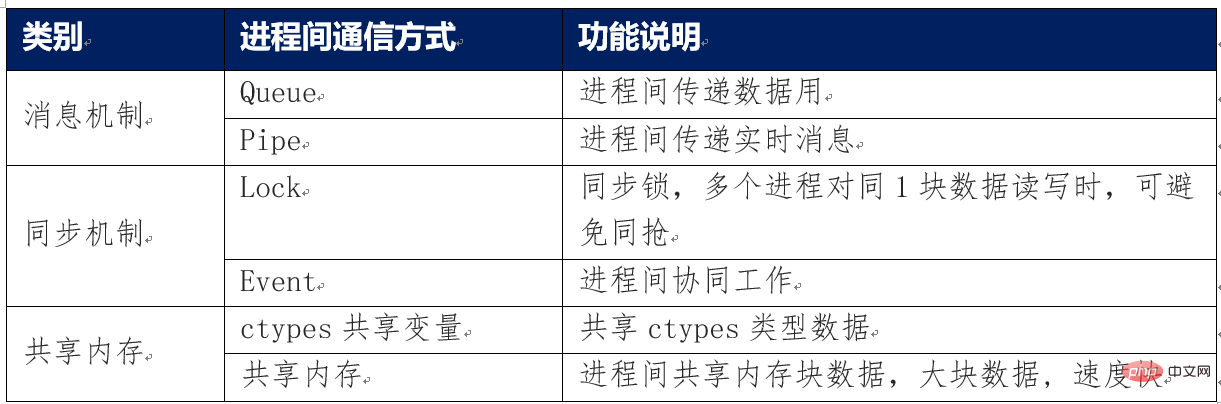
Les principales méthodes de communication inter-processus sont résumées comme suit
À propos de la sécurité de la mémoire de la communication inter-processus
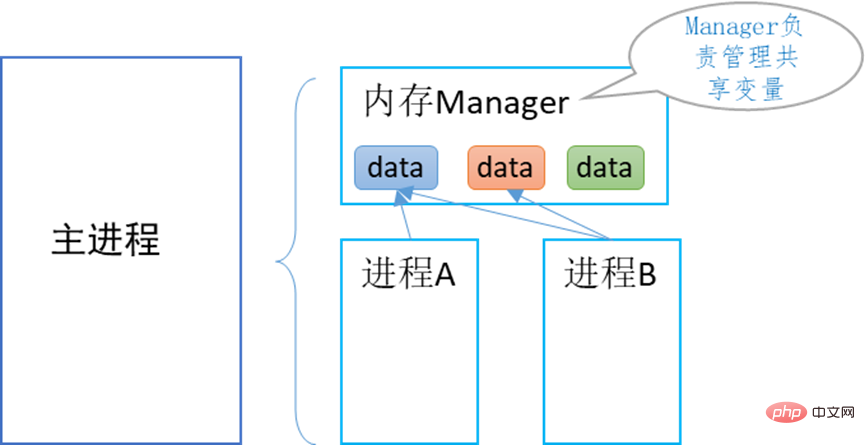
La sécurité de la mémoire signifie que plusieurs processus peuvent être en compétition pour la même raison. Des exceptions de variables partagées se produisent en raison d'une destruction accidentelle et d'autres raisons. Les objets Queue, Pipe, Lock et Event fournis par le module Multiprocessing ont tous implémenté des mécanismes de sécurité de communication inter-processus. Si vous utilisez la mémoire partagée pour communiquer, vous devez suivre et détruire vous-même ces variables de mémoire partagée dans le code, sinon elles risquent d'être brouillées ou de ne pas être détruites normalement. Causer une anomalie du système. Sauf si le développeur est très clair sur les caractéristiques d'utilisation de la mémoire partagée, il n'est pas recommandé d'utiliser cette mémoire partagée directement, mais d'utiliser la mémoire partagée via le gestionnaire Manager.
Memory Manager Manager
Multiprocessing fournit la classe Manager du gestionnaire de mémoire, qui peut résoudre uniformément les problèmes de sécurité de la mémoire liés à la communication des processus. Diverses données partagées peuvent être ajoutées au gestionnaire, notamment une liste, un dict, une file d'attente, un verrouillage, un événement, un partage. La mémoire, etc., est suivie et détruite de manière uniforme. 3. Communication du mécanisme de message
1) La méthode de communication par canal
est similaire au simple canal socket en 1, les deux extrémités peuvent envoyer et recevoir des messages.
Méthode de construction de l'objet Pipe :
parent_conn, child_conn = Pipe(duplex=True/False)
Copier après la connexion
Description du paramètre
duplex=Vrai, le pipeline est une communication bidirectionnelle
duplex=False, le pipeline est une communication unidirectionnelle, seul child_conn peut envoyer des messages, parent_conn peut seulement recevoir.
Exemple de code :
from multiprocessing import Process, Pipe
def myfunction(conn):
conn.send(['hi!! I am Python'])
conn.close()
if __name__ == '__main__':
parent_conn, child_conn = Pipe()
p = Process(target=myfunction, args=(child_conn,))
p.start()
print (parent_conn.recv() )
p.join()
Copier après la connexion
2) Méthode de communication de la file d'attente de messages
La classe Queue de Multiprocessing est modifiée sur la version Python Queue 3.0, qui peut facilement réaliser la transmission de données entre les producteurs et les messagers, et Multiprocessing Le module Queue implémente le mécanisme de sécurité de verrouillage.
Le module Queue fournit un total de 3 types de files d'attente.
(1) File d'attente FIFO, premier entré, premier sorti,
class queue.Queue(maxsize=0)
Copier après la connexion
(2) File d'attente LIFO, dernier entré, premier sorti, en fait une pile
class queue.LifoQueue(maxsize=0)
Copier après la connexion
(3) Avec la file d'attente prioritaire, la valeur d'entrée la plus basse est mise en file d'attente en premier
class queue.PriorityQueue(maxsize=0)
Copier après la connexion
Méthode principale de la classe Multiprocessing.Queue :
method
Description
queue.qsize()
renvoie la longueur de la file d'attente
queue .full()
file d'attente Si elle est pleine, renvoie True, sinon renvoie False
queue.empty()
si la file d'attente est vide, renvoie True, sinon renvoie False
import multiprocessing
def producer(numbers, q):
for x in numbers:
if x % 2 == 0:
if q.full():
print("queue is full")
break
q.put(x)
print(f"put {x} in queue by producer")
return None
def consumer(q):
while not q.empty():
print(f"take data {q.get()} from queue by consumer")
return None
if __name__ == "__main__":
# 设置1个queue对象,最大长度为5
qu = multiprocessing.Queue(maxsize=5,)
# 创建producer子进程,把queue做为其中1个参数传给它,该进程负责写
p5 = multiprocessing.Process(
name="producer-1",
target=producer,
args=([random.randint(1, 100) for i in range(0, 10)], qu)
)
p5.start()
p5.join()
#创建consumer子进程,把queue做为1个参数传给它,该进程中队列中读
p6 = multiprocessing.Process(
name="consumer-1",
target=consumer,
args=(qu,)
)
p6.start()
p6.join()
print(qu.qsize())
>>> from multiprocessing import shared_memory
>>> shm_a = shared_memory.SharedMemory(create=True, size=10)
>>> type(shm_a.buf)
<class 'memoryview'>
>>> buffer = shm_a.buf
>>> len(buffer)
10
>>> buffer[:4] = bytearray([22, 33, 44, 55]) # Modify multiple at once
>>> buffer[4] = 100 # Modify single byte at a time
>>> # Attach to an existing shared memory block
>>> shm_b = shared_memory.SharedMemory(shm_a.name)
>>> import array
>>> array.array('b', shm_b.buf[:5]) # Copy the data into a new array.array
array('b', [22, 33, 44, 55, 100])
>>> shm_b.buf[:5] = b'howdy' # Modify via shm_b using bytes
>>> bytes(shm_a.buf[:5]) # Access via shm_a
b'howdy'
>>> shm_b.close() # Close each SharedMemory instance
>>> shm_a.close()
>>> shm_a.unlink() # Call unlink only once to release the shared memory
>>> with SharedMemoryManager() as smm:
... sl = smm.ShareableList(range(2000))
... # Divide the work among two processes, storing partial results in sl
... p1 = Process(target=do_work, args=(sl, 0, 1000))
... p2 = Process(target=do_work, args=(sl, 1000, 2000))
... p1.start()
... p2.start() # A multiprocessing.Pool might be more efficient
... p1.join()
... p2.join() # Wait for all work to complete in both processes
... total_result = sum(sl) # Consolidate the partial results now in sl
from multiprocessing.managers import BaseManager
class MathsClass:
def add(self, x, y):
return x + y
def mul(self, x, y):
return x * y
class MyManager(BaseManager):
pass
MyManager.register('Maths', MathsClass)
if __name__ == '__main__':
with MyManager() as manager:
maths = manager.Maths()
print(maths.add(4, 3)) # prints 7
print(maths.mul(7, 8))
Copier après la connexion
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Déclaration de ce site Web
Le contenu de cet article est volontairement contribué par les internautes et les droits d'auteur appartiennent à l'auteur original. Ce site n'assume aucune responsabilité légale correspondante. Si vous trouvez un contenu suspecté de plagiat ou de contrefaçon, veuillez contacter admin@php.cn
PHP est principalement la programmation procédurale, mais prend également en charge la programmation orientée objet (POO); Python prend en charge une variété de paradigmes, y compris la POO, la programmation fonctionnelle et procédurale. PHP convient au développement Web, et Python convient à une variété d'applications telles que l'analyse des données et l'apprentissage automatique.
PHP convient au développement Web et au prototypage rapide, et Python convient à la science des données et à l'apprentissage automatique. 1.Php est utilisé pour le développement Web dynamique, avec une syntaxe simple et adapté pour un développement rapide. 2. Python a une syntaxe concise, convient à plusieurs champs et a un écosystème de bibliothèque solide.
Python convient plus aux débutants, avec une courbe d'apprentissage en douceur et une syntaxe concise; JavaScript convient au développement frontal, avec une courbe d'apprentissage abrupte et une syntaxe flexible. 1. La syntaxe Python est intuitive et adaptée à la science des données et au développement back-end. 2. JavaScript est flexible et largement utilisé dans la programmation frontale et côté serveur.
VS Code peut être utilisé pour écrire Python et fournit de nombreuses fonctionnalités qui en font un outil idéal pour développer des applications Python. Il permet aux utilisateurs de: installer des extensions Python pour obtenir des fonctions telles que la réalisation du code, la mise en évidence de la syntaxe et le débogage. Utilisez le débogueur pour suivre le code étape par étape, trouver et corriger les erreurs. Intégrez Git pour le contrôle de version. Utilisez des outils de mise en forme de code pour maintenir la cohérence du code. Utilisez l'outil de liaison pour repérer les problèmes potentiels à l'avance.
PHP est originaire en 1994 et a été développé par Rasmuslerdorf. Il a été utilisé à l'origine pour suivre les visiteurs du site Web et a progressivement évolué en un langage de script côté serveur et a été largement utilisé dans le développement Web. Python a été développé par Guidovan Rossum à la fin des années 1980 et a été publié pour la première fois en 1991. Il met l'accent sur la lisibilité et la simplicité du code, et convient à l'informatique scientifique, à l'analyse des données et à d'autres domaines.
Dans VS Code, vous pouvez exécuter le programme dans le terminal via les étapes suivantes: Préparez le code et ouvrez le terminal intégré pour vous assurer que le répertoire de code est cohérent avec le répertoire de travail du terminal. Sélectionnez la commande Run en fonction du langage de programmation (tel que Python de Python your_file_name.py) pour vérifier s'il s'exécute avec succès et résoudre les erreurs. Utilisez le débogueur pour améliorer l'efficacité du débogage.
VS Code peut fonctionner sur Windows 8, mais l'expérience peut ne pas être excellente. Assurez-vous d'abord que le système a été mis à jour sur le dernier correctif, puis téléchargez le package d'installation VS Code qui correspond à l'architecture du système et l'installez comme invité. Après l'installation, sachez que certaines extensions peuvent être incompatibles avec Windows 8 et doivent rechercher des extensions alternatives ou utiliser de nouveaux systèmes Windows dans une machine virtuelle. Installez les extensions nécessaires pour vérifier si elles fonctionnent correctement. Bien que le code VS soit possible sur Windows 8, il est recommandé de passer à un système Windows plus récent pour une meilleure expérience de développement et une meilleure sécurité.
Les extensions de code vs posent des risques malveillants, tels que la cachette de code malveillant, l'exploitation des vulnérabilités et la masturbation comme des extensions légitimes. Les méthodes pour identifier les extensions malveillantes comprennent: la vérification des éditeurs, la lecture des commentaires, la vérification du code et l'installation avec prudence. Les mesures de sécurité comprennent également: la sensibilisation à la sécurité, les bonnes habitudes, les mises à jour régulières et les logiciels antivirus.

 développement back-end
développement back-end