

Que sont les flux d'octets et les flux de caractères en Java

Flux d'octets et flux de caractères
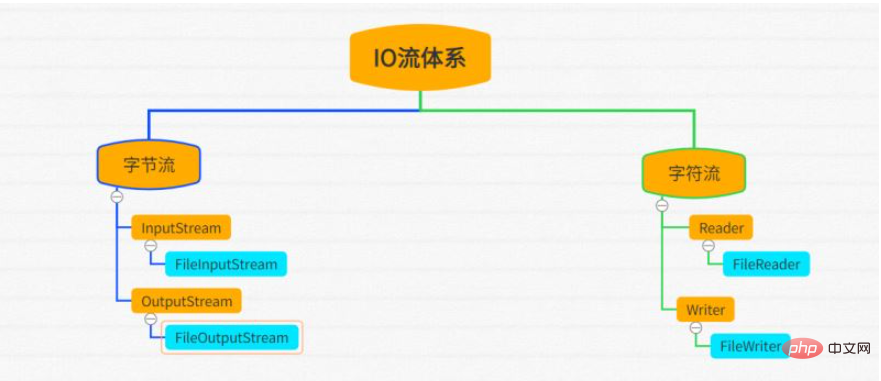
Dans l'image ci-dessus, la partie orange est la classe abstraite et la partie bleue est la classe d'implémentation
Flux d'octets
Le flux d'octets, comme son nom l'indique, est de subdiviser les données Les opérations de lecture et d'écriture de fichiers d'octets sont principalement divisées en flux d'entrée d'octets et flux de sortie d'octets.
Flux d'entrée d'octets
Voici les constructeurs et les méthodes couramment utilisés dans les flux d'entrée d'octets :
| Constructeur | Description |
| public FileInputStream (fichier de fichier) | Créer des octets Le pipeline du flux d'entrée est connecté à l'objet fichier source |
| public FileInputStream (String pathname) | Créez un pipeline de flux d'entrée d'octets et le chemin du fichier source est connecté |
| Nom de la méthode | Description |
| public int lu () | Renvoie un octet à chaque fois, si l'octet n'est plus lisible, renvoie -1 |
| public int read(byte[] buffer) | Lit un tableau d'octets à chaque fois Retour, s'il n'y a pas d'octets lisibles , return -1 |
Ensuite, approfondissons mieux notre compréhension de cette partie de la connaissance à travers le code !
File file = new File("File//data.txt");
//第一种构造器,参数是File类
InputStream inputStream = new FileInputStream(file);
//第二种构造器,参数是文件的路径,可以是相对也可以是绝对的路径
InputStream inputStream1 = new FileInputStream("File//data.txt");
//通过字节读取文件中的数据
int len;
while ((len=inputStream.read()) != -1){
System.out.print((char) len);
}
System.out.println();
//通过字节数组读取文件中的数据
byte [] buffer = new byte[3];
while ((len=inputStream1.read(buffer))!=-1){
String s = new String(buffer,0,len);
System.out.print(s);
}
//输出结果:
//ab1abab
//ab1ababMaintenant que le résultat de sortie que nous voyons correspond un à un au contenu du fichier, alors il ne doit y avoir aucun problème avec cela ? En fait non, c'est juste que nous n'avons pas encore rencontré de problèmes. Tout d'abord, ce que nous devons comprendre, c'est qu'en utf-8, les lettres et les chiffres font un octet, et le chinois est composé de trois octets, donc quand notre chinois est composé de trois octets. des caractères apparaissent dans le fichier, la première méthode ne peut pas obtenir une lecture normale, car la lecture d'un octet à chaque fois démontera les caractères chinois, ce qui entraînera des caractères tronqués lors de la sortie tandis que la deuxième méthode peut ensuite réaliser la sortie de caractères chinois dans des circonstances particulières ; . La condition à remplir est que les trois octets de caractères chinois se trouvent dans le même tableau d'octets.
Le flux d'entrée d'octets ne convient pas à toutes les données de fichiers, ce qui conduit au flux d'entrée de caractères.
Flux de sortie d'octets
Voici les méthodes couramment utilisées pour le flux de sortie d'octets :
| Méthode | Description |
| public void write (int a) | Écrire un octet en sortie |
| publique void write (byte [ ]buffer) | Écrivez un tableau d'octets |
| public void write (byte [ ]buffer,int off, int len) | Écrivez une partie d'un tableau d'octets |
| fichier. close() | Le flux est fermé et les données ne peuvent plus être écrites |
| file.flush() | Le flux est mis à jour et les données peuvent continuer à être écrites |
Ensuite, le code sera mieux approfondi Comprenons cette partie des points de connaissance !
OutputStream outputStream = new FileOutputStream("File//data.txt",true);
//true表示可以对文件进行追加内容,若没有true则会在关闭文件之后,进行写文件的时候会对之前的内容进行覆盖。
outputStream.write('a');
outputStream.write(13);
outputStream.write('美');
outputStream.flush();
byte[] buffer = {'s','y','l','m',99};
outputStream.write(buffer);
outputStream.write(buffer,1,3);
outputStream.close();Après la série d'opérations ci-dessus, les données seront écrites dans le fichier data.txt, mais des problèmes surviendront toujours. Parfois, le chinois ne peut pas être écrit normalement, il ne convient donc pas à tous les fichiers et conduit au caractère. flux de sortie.
Flux de caractères
Le flux de caractères, comme son nom l'indique, consiste à subdiviser les données en caractères pour lire et écrire des fichiers. Il est principalement divisé en flux d'entrée de caractères et flux de sortie de caractères.
Flux d'entrée de caractères
Voici les constructeurs et les méthodes souvent utilisés dans les flux d'entrée de caractères :
| Constructeur | Description |
| public FileReader (fichier de fichier) | Créer un pipeline de flux d'entrée de caractères Connecté à le fichier source objet |
| public fileReader (String pathname) | Create un pipeline de flux d'entrée de caractères connecté au fichier source path |
| Method | Description |
| public int lien () | Renvoie un caractère à chaque fois, si le caractère n'est plus lisible, renvoie -1 |
| public int read (char [ ]buffer) | Renvoie un tableau de caractères à chaque fois, renvoie le nombre de caractères lus Nombre, si non les caractères sont lisibles return -1 |
字符输入流的构造器和方法大致上和字节输入流的相同,不同的地方在于字符输入流是以字符为单位的读取,无论你是字母还是数字,都作为一个字符进行读取,这样便可以避免在读取中文的时候出现乱码的问题。
接下来通过一部分代码来加深对它的理解吧!
File file = new File("File//data.txt");
//第一种构造器,参数是File类
FileReader fileReader = new FileReader(file);
//第二种构造器,参数是文件的绝对路径或者相对路径
FileReader fileReader1 = new FileReader("File//data.txt");
//第一种方法,一个一个字符读取
int len;
while ((len = fileReader.read())!=-1){
System.out.print((char) len);
}
//第二种方法,以字符数组进行读取
char []buffer = new char[3];
while ((len = fileReader1.read(buffer))!=-1){
String s = new String(buffer,0,len);
System.out.println(s);
}
//输出结果:
//110,119,120
//110
//,11
//9,1
//20通过以字符为单位的读写,便可以避免在读取中文的时候出现乱码的问题了。
字符输出流
下面是字符输出流中经常会用到的构造器和方法:
| 构造器 | 说明 |
| public FileWriter(File file) | 创建字符输出流管道与源文件对象接通 |
| public FileWriter(File file,boolean append) | 创建字符输出流管道与源文件对象接通,可追加数据 |
| public FileWriter(String filepath) | 创建字符输出流管道与源文件路径接通 |
| public FileWriter(String filepath,boolean append) | 创建字符输出流管道与源文件路径接通,可追加 |
| 方法 | 说明 |
| void writer(int c) | 写入一个字符 |
| void writer (char [ ] buffer) | 写入一个字符数组 |
| void writer (char[ ]buffer,int off,int len) | 写入字符数组的一部分 |
| void writer(String str) | 写入一个字符串 |
| void writer(String str,int off,int len) | 写入字符串的一部分 |
| close和flush | 输出流的关闭和刷新 |
接下来就通过代码来加深对它的理解吧!
FileWriter fileWriter = new FileWriter("File//data.txt");
fileWriter.write('k');
fileWriter.write('d');
char []buffer = {'i','r','v','i','n','g'};
fileWriter.write(buffer);
fileWriter.flush();
String s = "James";
fileWriter.write(s);
fileWriter.write(s,0,4);
fileWriter.close();字符输出流的使用便可以很好地解决了中文不能正常写入文件的问题了。
附:字节流和字符流的区别
字节流操作的基本单元为字节;字符流操作的基本单元为Unicode码元。
字节流默认不使用缓冲区;字符流使用缓冲区。
字节流在操作的时候本身是不会用到缓冲区的,是与文件本身直接操作的,所以字节流在操作文件时,即使不关闭资源,文件也能输出;字符流在操作的时候是使用到缓冲区的。如果字符流不调用close或flush方法,则不会输出任何内容。
字节流通常用于处理二进制数据,实际上它可以处理任意类型的数据,但它不支持直接写入或读取Unicode码元;字符流通常处理文本数据,它支持写入及读取Unicode码元。
字节流可用于任何类型的对象,包括二进制对象,而字符流只能处理字符或者字符串; 字节流提供了处理任何类型的IO操作的功能,但它不能直接处理Unicode字符,而字符流就可以。
字节流和字符流的转换
字节流是最基本的,所有的InputStream和OutputStream的子类都是,主要用在处理二进制数据,它是按字节来处理的,但实际中很多的数据是文本,又提出了字符流的概念,它是按虚拟机的encode来处理,也就是要进行字符集的转化,这两个之间通过 InputStreamReader,OutputStreamWriter来关联,实际上是通过byte[]和String来关联。在从字节流转化为字符流时,实际上就是byte[]转化为String时,而在字符流转化为字节流时,实际上是String转化为byte[]时。
字符流处理的单元为2个字节的Unicode字符,分别操作字符、字符数组或字符串,而字节流处理单元为1个字节,操作字节和字节数组。所以字符流是由Java虚拟机将字节转化为2个字节的Unicode字符为单位的字符而成的,所以它对多国语言支持性比较好!如果是音频文件、图片、歌曲,就用字节流好点,如果是关系到中文(文本)的,用字符流好点。所有文件的储存是都是字节(byte)的储存,在磁盘上保留的并不是文件的字符而是先把字符编码成字节,再储存这些字节到磁盘。在读取文件(特别是文本文件)时,也是一个字节一个字节地读取以形成字节序列。
字节流可用于任何类型的对象,包括二进制对象,而字符流只能处理字符或者字符串; 字节流提供了处理任何类型的IO操作的功能,但它不能直接处理Unicode字符,而字符流就可以。
字节流与字符流主要的区别是他们的的处理方式。
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

Video Face Swap
Échangez les visages dans n'importe quelle vidéo sans effort grâce à notre outil d'échange de visage AI entièrement gratuit !

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)
Sujets chauds



 Nombre parfait en Java
Aug 30, 2024 pm 04:28 PM
Nombre parfait en Java
Aug 30, 2024 pm 04:28 PM
Guide du nombre parfait en Java. Nous discutons ici de la définition, comment vérifier le nombre parfait en Java ?, des exemples d'implémentation de code.
 Weka en Java
Aug 30, 2024 pm 04:28 PM
Weka en Java
Aug 30, 2024 pm 04:28 PM
Guide de Weka en Java. Nous discutons ici de l'introduction, de la façon d'utiliser Weka Java, du type de plate-forme et des avantages avec des exemples.
 Numéro de Smith en Java
Aug 30, 2024 pm 04:28 PM
Numéro de Smith en Java
Aug 30, 2024 pm 04:28 PM
Guide du nombre de Smith en Java. Nous discutons ici de la définition, comment vérifier le numéro Smith en Java ? exemple avec implémentation de code.
 Questions d'entretien chez Java Spring
Aug 30, 2024 pm 04:29 PM
Questions d'entretien chez Java Spring
Aug 30, 2024 pm 04:29 PM
Dans cet article, nous avons conservé les questions d'entretien Java Spring les plus posées avec leurs réponses détaillées. Pour que vous puissiez réussir l'interview.
 Break or Return of Java 8 Stream Forach?
Feb 07, 2025 pm 12:09 PM
Break or Return of Java 8 Stream Forach?
Feb 07, 2025 pm 12:09 PM
Java 8 présente l'API Stream, fournissant un moyen puissant et expressif de traiter les collections de données. Cependant, une question courante lors de l'utilisation du flux est: comment se casser ou revenir d'une opération FOREAK? Les boucles traditionnelles permettent une interruption ou un retour précoce, mais la méthode Foreach de Stream ne prend pas directement en charge cette méthode. Cet article expliquera les raisons et explorera des méthodes alternatives pour la mise en œuvre de terminaison prématurée dans les systèmes de traitement de flux. Lire plus approfondie: Améliorations de l'API Java Stream Comprendre le flux Forach La méthode foreach est une opération terminale qui effectue une opération sur chaque élément du flux. Son intention de conception est
 Horodatage à ce jour en Java
Aug 30, 2024 pm 04:28 PM
Horodatage à ce jour en Java
Aug 30, 2024 pm 04:28 PM
Guide de TimeStamp to Date en Java. Ici, nous discutons également de l'introduction et de la façon de convertir l'horodatage en date en Java avec des exemples.
 Programme Java pour trouver le volume de la capsule
Feb 07, 2025 am 11:37 AM
Programme Java pour trouver le volume de la capsule
Feb 07, 2025 am 11:37 AM
Les capsules sont des figures géométriques tridimensionnelles, composées d'un cylindre et d'un hémisphère aux deux extrémités. Le volume de la capsule peut être calculé en ajoutant le volume du cylindre et le volume de l'hémisphère aux deux extrémités. Ce tutoriel discutera de la façon de calculer le volume d'une capsule donnée en Java en utilisant différentes méthodes. Formule de volume de capsule La formule du volume de la capsule est la suivante: Volume de capsule = volume cylindrique volume de deux hémisphères volume dans, R: Le rayon de l'hémisphère. H: La hauteur du cylindre (à l'exclusion de l'hémisphère). Exemple 1 entrer Rayon = 5 unités Hauteur = 10 unités Sortir Volume = 1570,8 unités cubes expliquer Calculer le volume à l'aide de la formule: Volume = π × r2 × h (4
 PHP vs Python: comprendre les différences
Apr 11, 2025 am 12:15 AM
PHP vs Python: comprendre les différences
Apr 11, 2025 am 12:15 AM
PHP et Python ont chacun leurs propres avantages, et le choix doit être basé sur les exigences du projet. 1.Php convient au développement Web, avec une syntaxe simple et une efficacité d'exécution élevée. 2. Python convient à la science des données et à l'apprentissage automatique, avec une syntaxe concise et des bibliothèques riches.
