
 développement back-end
Tutoriel Python
Comment traiter les données Excel avec la bibliothèque Pandas de Python ?
développement back-end
Tutoriel Python
Comment traiter les données Excel avec la bibliothèque Pandas de Python ?
Comment traiter les données Excel avec la bibliothèque Pandas de Python ?

1. Lisez le tableau xlsx : pd.read_excel()
Le contenu original est le suivant :
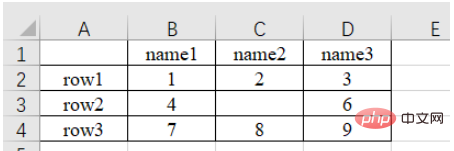
a) Lisez les données de la nième feuille (sous-feuille, vous pouvez afficher ou ajouter ou supprimer la sous-feuille dans le coin inférieur gauche)
import pandas as pd # 每次都需要修改的路径 path = "test.xlsx" # sheet_name默认为0,即读取第一个sheet的数据 sheet = pd.read_excel(path, sheet_name=0) print(sheet) """ Unnamed: 0 name1 name2 name3 0 row1 1 2.0 3 1 row2 4 NaN 6 2 row3 7 8.0 9 """
Vous pouvez remarquer qu'il n'y a aucun contenu dans le coin supérieur gauche du tableau d'origine, et le résultat de la lecture est "Sans nom : 0 C'est parce que la fonction read_excel par défaut". première ligne du tableau comme nom d'index de colonne. De plus, pour les noms d'index de ligne, la numérotation commence par défaut à partir de la deuxième ligne (car la première ligne par défaut est le nom de l'index de colonne, donc la première ligne par défaut ne contient pas de données. Si cela n'est pas spécifiquement spécifié, la numérotation commence automatiquement à 0, comme). suit.
sheet = pd.read_excel(path) # 查看列索引名,返回列表形式 print(sheet.columns.values) # 查看行索引名,默认从第二行开始编号,如果不特意指定,则自动从0开始编号,返回列表形式 print(sheet.index.values) """ ['Unnamed: 0' 'name1' 'name2' 'name3'] [0 1 2] """
b) Le nom de l'index de colonne peut également être personnalisé, comme suit :
sheet = pd.read_excel(path, names=['col1', 'col2', 'col3', 'col4']) print(sheet) # 查看列索引名,返回列表形式 print(sheet.columns.values) """ col1 col2 col3 col4 0 row1 1 2.0 3 1 row2 4 NaN 6 2 row3 7 8.0 9 ['col1' 'col2' 'col3' 'col4'] """
c) Vous pouvez également spécifier la nième colonne comme nom d'index de ligne, comme suit :
# 指定第一列为行索引
sheet = pd.read_excel(path, index_col=0)
print(sheet)
"""
name1 name2 name3
row1 1 2.0 3
row2 4 NaN 6
row3 7 8.0 9
"""d) Ignorer le nième colonne lors de la lecture des données de ligne
# 跳过第2行的数据(第一行索引为0) sheet = pd.read_excel(path, skiprows=[1]) print(sheet) """ Unnamed: 0 name1 name2 name3 0 row2 4 NaN 6 1 row3 7 8.0 9 """
2. Obtenez la taille des données du tableau : shape
path = "test.xlsx"
# 指定第一列为行索引
sheet = pd.read_excel(path, index_col=0)
print(sheet)
print('==========================')
print('shape of sheet:', sheet.shape)
"""
name1 name2 name3
row1 1 2.0 3
row2 4 NaN 6
row3 7 8.0 9
==========================
shape of sheet: (3, 3)
"""3. Méthode de données d'index : [ ] / loc[] / iloc[]
1.
Utilisez des crochets plus le nom de la colonne [col_name] pour extraire les données d'une colonne, puis utilisez des crochets plus le numéro d'index [index] pour indexer la valeur de position spécifique de cette colonne. Ici, la colonne nommée nom1 est indexée, puis les données situées à la ligne 1 de la colonne (l'index est 1) sont imprimées : 4, comme suit :
sheet = pd.read_excel(path) # 读取列名为 name1 的列数据 col = sheet['name1'] print(col) # 打印该列第二个数据 print(col[1]) # 4 """ 0 1 1 4 2 7 Name: name1, dtype: int64 4 """
2, méthode iloc, index par nombre entier
Utilisez . sheet.iloc [ ] Index, les crochets sont le numéro de position entier de la ligne et de la colonne (la numérotation commence à 0 après avoir exclu la colonne comme index de ligne et la ligne comme index de colonne).
a) sheet.iloc[1, 2] : Extraire ligne 2, colonne 3données. Le premier est l'index de ligne, le second est l'index de colonne
b) sheet.iloc[0: 2] : Extrayez les deux premières lignesdata
c)sheet.iloc[0:2, 0 : 2] : Extrayez les données des deux premières colonnes des deux premières lignes via sharding
# 指定第一列数据为行索引
sheet = pd.read_excel(path, index_col=0)
# 读取第2行(row2)的第3列(6)数据
# 第一个是行索引,第二个是列索引
data = sheet.iloc[1, 2]
print(data) # 6
print('================================')
# 通过分片的方式提取 前两行 数据
data_slice = sheet.iloc[0:2]
print(data_slice)
print('================================')
# 通过分片的方式提取 前两行 的 前两列 数据
data_slice = sheet.iloc[0:2, 0:2]
print(data_slice)
"""
6
================================
name1 name2 name3
row1 1 2.0 3
row2 4 NaN 6
================================
name1 name2
row1 1 2.0
row2 4 NaN
"""3, index par ligne et nom de colonne
utilisez sheet.loc[ ] index, crochets À l'intérieur se trouve la chaîne de nom de la colonne. L'utilisation spécifique est la même que celle de iloc , sauf que l'index entier d'iloc est remplacé par l'index du nom de la ligne et de la colonne. Cette méthode d'indexation est plus intuitive à utiliser.
Remarque : iloc[1: 2] ne contient pas 2, mais loc['row1': 'row2'] contient 'row2'.
# 指定第一列数据为行索引
sheet = pd.read_excel(path, index_col=0)
# 读取第2行(row2)的第3列(6)数据
# 第一个是行索引,第二个是列索引
data = sheet.loc['row2', 'name3']
print(data) # 1
print('================================')
# 通过分片的方式提取 前两行 数据
data_slice = sheet.loc['row1': 'row2']
print(data_slice)
print('================================')
# 通过分片的方式提取 前两行 的 前两列 数据
data_slice1 = sheet.loc['row1': 'row2', 'name1': 'name2']
print(data_slice1)
"""
6
================================
name1 name2 name3
row1 1 2.0 3
row2 4 NaN 6
================================
name1 name2
row1 1 2.0
row2 4 NaN
"""4. Déterminez si les données sont vides : np.isnan() / pd.isnull()
1 Utilisez la bibliothèque isnan() de la bibliothèque numpy ou la bibliothèque isnull() pandas pour déterminer si elle est vide. est égal à nan .
sheet = pd.read_excel(path) # 读取列名为 name1 的列数据 col = sheet['name2'] print(np.isnan(col[1])) # True print(pd.isnull(col[1])) # True """ True True """
'nan' .
sheet = pd.read_excel(path)
# 读取列名为 name1 的列数据
col = sheet['name2']
print(col)
# 打印该列第二个数据
if str(col[1]) == 'nan':
print('col[1] is nan')
"""
0 2.0
1 NaN
2 8.0
Name: name2, dtype: float64
col[1] is nan
"""# 提取name1 == 1 的行
mask = (sheet['name1'] == 1)
x = sheet.loc[mask]
print(x)
"""
name1 name2 name3
row1 1 2.0 3
"""sheet['name2'].replace(2, 100, inplace=True ) : Remplacez l'élément 2 de la colonne nom2 par l'élément 100 et opérez sur place.
sheet['name2'].replace(2, 100, inplace=True)
print(sheet)
"""
name1 name2 name3
row1 1 100.0 3
row2 4 NaN 6
row3 7 8.0 9
"""sheet['name2'].replace(np.nan, 100, inplace=True) : Remplacez l'élément vide (nan) de la colonne name2 par l'élément 100 et opérez sur place.
import numpy as np
sheet['name2'].replace(np.nan, 100, inplace=True)
print(sheet)
print(type(sheet.loc['row2', 'name2']))
"""
name1 name2 name3
row1 1 2.0 3
row2 4 100.0 6
row3 7 8.0 9
"""Pour ajouter une colonne, utilisez les crochets [nom à ajouter] directement pour ajouter.
sheet['name_add'] = [55, 66, 77] : Ajoutez une colonne nommée name_add avec une valeur de [55, 66, 77]
path = "test.xlsx"
# 指定第一列为行索引
sheet = pd.read_excel(path, index_col=0)
print(sheet)
print('====================================')
# 添加名为 name_add 的列,值为[55, 66, 77]
sheet['name_add'] = [55, 66, 77]
print(sheet)
"""
name1 name2 name3
row1 1 2.0 3
row2 4 NaN 6
row3 7 8.0 9
====================================
name1 name2 name3 name_add
row1 1 2.0 3 55
row2 4 NaN 6 66
row3 7 8.0 9 77
"""a) del(sheet['name3']) : Utilisez la méthode del pour supprimer
sheet = pd.read_excel(path, index_col=0)
# 使用 del 方法删除 'name3' 的列
del(sheet['name3'])
print(sheet)
"""
name1 name2
row1 1 2.0
row2 4 NaN
row3 7 8.0
"""b) sheet.drop('row1', axis=0)
Utilisez la méthode drop pour supprimer la ligne row1, supprimer Pour les colonnes, l'axe correspondant=1. Lorsque le paramètre inplace est True, le paramètre ne sera pas renvoyé et sera supprimé directement sur les données d'origineLorsque le paramètre inplace est False (par défaut), les données d'origine ne seront pas modifiées, mais les données modifiées le seront returnsheet.drop('row1', axis=0, inplace=True)
print(sheet)
"""
name1 name2 name3
row2 4 NaN 6
row3 7 8.0 9
"""c) feuille .drop(labels=['name1', 'name2'], axis=1)
Utilisez le paramètre label=[ ] pour supprimer plusieurs lignes ou colonnes# 删除多列,默认 inplace 参数位 False,即会返回结果
print(sheet.drop(labels=['name1', 'name2'], axis=1))
"""
name3
row1 3
row2 6
row3 9
"""1. Enregistrez les données au format pandas sous forme de fichier .xlsx
names = ['a', 'b', 'c'] scores = [99, 100, 99] result_excel = pd.DataFrame() result_excel["姓名"] = names result_excel["评分"] = scores # 写入excel result_excel.to_excel('test3.xlsx')
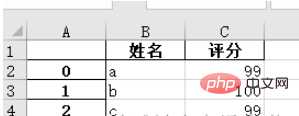
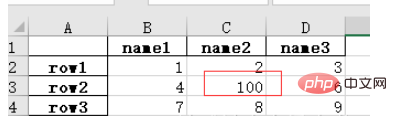
2. Enregistrez le fichier Excel modifié sous forme de fichier .xlsx.
Par exemple, après avoir modifié nan dans la table d'origine à 100, enregistrez le fichier :import numpy as np # 指定第一列为行索引 sheet = pd.read_excel(path, index_col=0) sheet['name2'].replace(np.nan, 100, inplace=True) sheet.to_excel('test2.xlsx')
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 HaDIDB: une base de données légère et évolutive horizontalement dans Python
Apr 08, 2025 pm 06:12 PM
HaDIDB: une base de données légère et évolutive horizontalement dans Python
Apr 08, 2025 pm 06:12 PM
HaDIDB: Une base de données Python évolutive de haut niveau légère HaDIDB (HaDIDB) est une base de données légère écrite en Python, avec un niveau élevé d'évolutivité. Installez HaDIDB à l'aide de l'installation PIP: PiPinStallHaDIDB User Management Créer un utilisateur: CreateUser () pour créer un nouvel utilisateur. La méthode Authentication () authentifie l'identité de l'utilisateur. FromHadidb.OperationMportUserUser_OBJ = User ("Admin", "Admin") User_OBJ.
 Méthode de Navicat pour afficher le mot de passe de la base de données MongoDB
Apr 08, 2025 pm 09:39 PM
Méthode de Navicat pour afficher le mot de passe de la base de données MongoDB
Apr 08, 2025 pm 09:39 PM
Il est impossible de visualiser le mot de passe MongoDB directement via NAVICAT car il est stocké sous forme de valeurs de hachage. Comment récupérer les mots de passe perdus: 1. Réinitialiser les mots de passe; 2. Vérifiez les fichiers de configuration (peut contenir des valeurs de hachage); 3. Vérifiez les codes (May Code Hardcode).
 Le plan Python de 2 heures: une approche réaliste
Apr 11, 2025 am 12:04 AM
Le plan Python de 2 heures: une approche réaliste
Apr 11, 2025 am 12:04 AM
Vous pouvez apprendre les concepts de programmation de base et les compétences de Python dans les 2 heures. 1. Apprenez les variables et les types de données, 2. Flux de contrôle maître (instructions et boucles conditionnelles), 3. Comprenez la définition et l'utilisation des fonctions, 4. Démarrez rapidement avec la programmation Python via des exemples simples et des extraits de code.
 Comment optimiser les performances MySQL pour les applications de haute charge?
Apr 08, 2025 pm 06:03 PM
Comment optimiser les performances MySQL pour les applications de haute charge?
Apr 08, 2025 pm 06:03 PM
Guide d'optimisation des performances de la base de données MySQL dans les applications à forte intensité de ressources, la base de données MySQL joue un rôle crucial et est responsable de la gestion des transactions massives. Cependant, à mesure que l'échelle de l'application se développe, les goulots d'étranglement des performances de la base de données deviennent souvent une contrainte. Cet article explorera une série de stratégies efficaces d'optimisation des performances MySQL pour garantir que votre application reste efficace et réactive dans des charges élevées. Nous combinerons des cas réels pour expliquer les technologies clés approfondies telles que l'indexation, l'optimisation des requêtes, la conception de la base de données et la mise en cache. 1. La conception de l'architecture de la base de données et l'architecture optimisée de la base de données sont la pierre angulaire de l'optimisation des performances MySQL. Voici quelques principes de base: sélectionner le bon type de données et sélectionner le plus petit type de données qui répond aux besoins peut non seulement économiser un espace de stockage, mais également améliorer la vitesse de traitement des données.
 Python: Explorer ses applications principales
Apr 10, 2025 am 09:41 AM
Python: Explorer ses applications principales
Apr 10, 2025 am 09:41 AM
Python est largement utilisé dans les domaines du développement Web, de la science des données, de l'apprentissage automatique, de l'automatisation et des scripts. 1) Dans le développement Web, les cadres Django et Flask simplifient le processus de développement. 2) Dans les domaines de la science des données et de l'apprentissage automatique, les bibliothèques Numpy, Pandas, Scikit-Learn et Tensorflow fournissent un fort soutien. 3) En termes d'automatisation et de script, Python convient aux tâches telles que les tests automatisés et la gestion du système.
 Comment utiliser Aws Glue Crawler avec Amazon Athena
Apr 09, 2025 pm 03:09 PM
Comment utiliser Aws Glue Crawler avec Amazon Athena
Apr 09, 2025 pm 03:09 PM
En tant que professionnel des données, vous devez traiter de grandes quantités de données provenant de diverses sources. Cela peut poser des défis à la gestion et à l'analyse des données. Heureusement, deux services AWS peuvent aider: AWS Glue et Amazon Athena.
 Comment démarrer le serveur avec redis
Apr 10, 2025 pm 08:12 PM
Comment démarrer le serveur avec redis
Apr 10, 2025 pm 08:12 PM
Les étapes pour démarrer un serveur Redis incluent: Installez Redis en fonction du système d'exploitation. Démarrez le service Redis via Redis-Server (Linux / MacOS) ou Redis-Server.exe (Windows). Utilisez la commande redis-Cli Ping (Linux / MacOS) ou redis-Cli.exe Ping (Windows) pour vérifier l'état du service. Utilisez un client redis, tel que redis-cli, python ou node.js pour accéder au serveur.
 MySQL peut-il se connecter au serveur SQL
Apr 08, 2025 pm 05:54 PM
MySQL peut-il se connecter au serveur SQL
Apr 08, 2025 pm 05:54 PM
Non, MySQL ne peut pas se connecter directement à SQL Server. Mais vous pouvez utiliser les méthodes suivantes pour implémenter l'interaction des données: utilisez Middleware: Exporter les données de MySQL au format intermédiaire, puis importez-les sur SQL Server via Middleware. Utilisation de Database Linker: Business Tools fournit une interface plus conviviale et des fonctionnalités avancées, essentiellement encore implémentées via Middleware.
