

Le filtre Bloom a été proposé par Bloom en 1970. Il est en fait composé d'un très long tableau binaire + d'une série de fonctions de mappage d'algorithme de hachage, qui sont utilisées pour déterminer si un élément existe dans l'ensemble.
Les filtres Bloom peuvent être utilisés pour savoir si un élément fait partie d'une collection. Son avantage est que l'efficacité spatiale et le temps de requête sont bien meilleurs que les algorithmes ordinaires. Son inconvénient est qu'il présente un certain taux de mauvaise reconnaissance et des difficultés de suppression.
Supposons qu'il y ait 1 milliard de numéros de téléphone mobile, puis déterminez si un certain numéro de téléphone mobile figure dans la liste ?
Est-ce que MySQL va bien ?
Dans des circonstances normales, si la quantité de données n'est pas importante, nous pouvons envisager d'utiliser le stockage MySQL. Stockez toutes les données dans la base de données, puis interrogez la base de données à chaque fois pour déterminer si elle existe. Cependant, si la quantité de données est trop importante, dépassant les dizaines de millions, l'efficacité des requêtes MySQL sera très faible, ce qui consommera particulièrement des performances.
HashSet, ça va ?
Nous pouvons mettre les données dans un HashSet et profiter de la déduplication naturelle de HashSet. La requête n'a besoin que d'appeler la méthode contain. Cependant, le hashset est stocké en mémoire. la mémoire sortira directement.
L'insertion et la requête sont efficaces et prennent moins de place, mais les résultats renvoyés sont incertains.
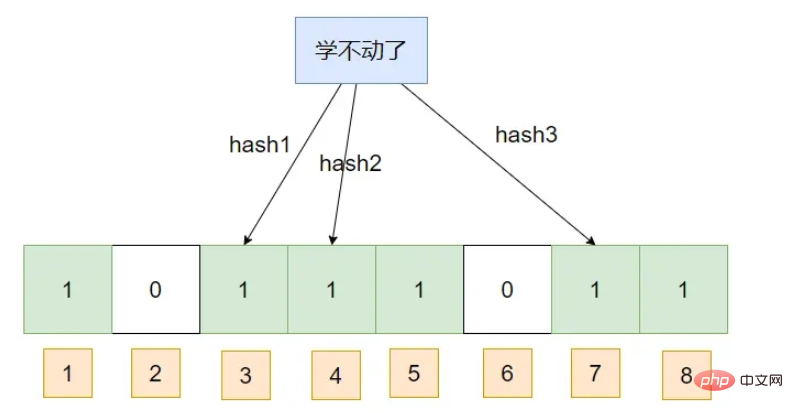
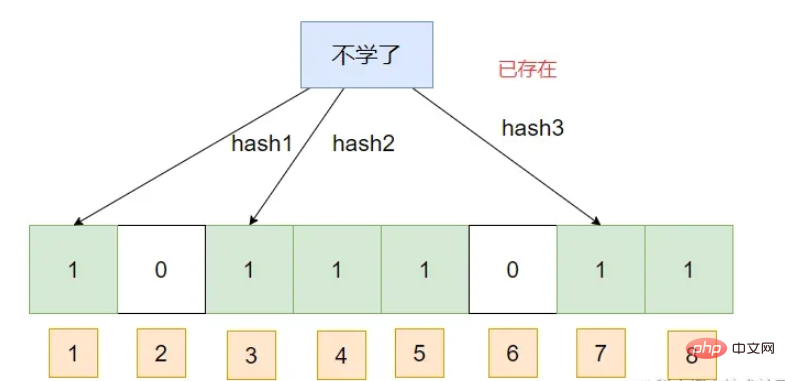
Si un élément est jugé exister, il se peut qu'il n'existe pas réellement. Mais si l’on juge qu’un élément n’existe pas, alors il ne doit pas exister.
Le filtre Bloom peut ajouter des éléments, mais ne doit pas supprimer d'éléments , ce qui entraînera une augmentation du taux de faux positifs.
Un filtre Bloom est en fait un tableau BIT, qui mappe le hachage correspondant via une série d'algorithmes de hachage, puis modifie la position de l'indice du tableau correspondant au hachage à 1. Lors de l'interrogation, une série d'algorithmes de hachage sont effectués sur les données pour obtenir l'indice. Les données sont extraites du tableau BIT. Si la valeur est 1, cela signifie que les données peuvent exister. Si la valeur est 0, cela signifie que ce n'est certainement pas le cas. Pourquoi y a-t-il un taux d'erreur ? Nous savons que les filtres Bloom hachent en fait les données, donc quel que soit l'algorithme utilisé, il est possible que les hachages générés par deux données différentes soient effectivement les mêmes, ce que nous appelons souvent des conflits de hachage. . Insérez d'abord une donnée : apprenez bien la technologie
Insérez une donnée :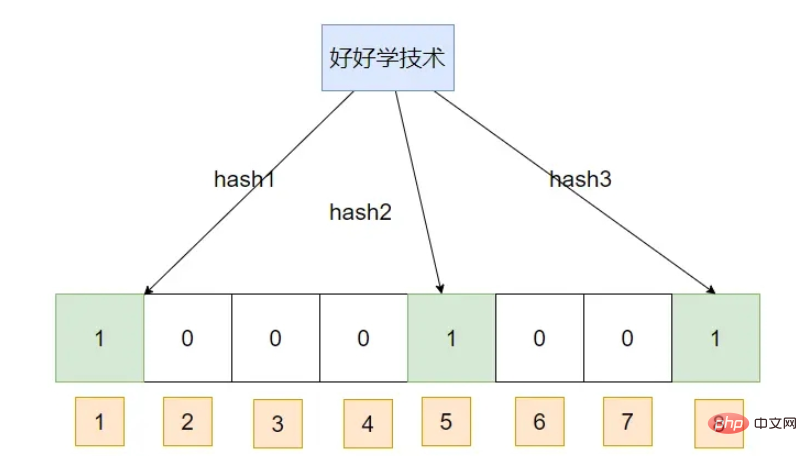
 Java implémente le filtre Bloom
Java implémente le filtre Bloom
package com.fandf.test.redis;
import java.util.BitSet;
/**
* java布隆过滤器
*
* @author fandongfeng
*/
public class MyBloomFilter {
/**
* 位数组大小
*/
private static final int DEFAULT_SIZE = 2 << 24;
/**
* 通过这个数组创建多个Hash函数
*/
private static final int[] SEEDS = new int[]{4, 8, 16, 32, 64, 128, 256};
/**
* 初始化位数组,数组中的元素只能是 0 或者 1
*/
private final BitSet bits = new BitSet(DEFAULT_SIZE);
/**
* Hash函数数组
*/
private final MyHash[] myHashes = new MyHash[SEEDS.length];
/**
* 初始化多个包含 Hash 函数的类数组,每个类中的 Hash 函数都不一样
*/
public MyBloomFilter() {
// 初始化多个不同的 Hash 函数
for (int i = 0; i < SEEDS.length; i++) {
myHashes[i] = new MyHash(DEFAULT_SIZE, SEEDS[i]);
}
}
/**
* 添加元素到位数组
*/
public void add(Object value) {
for (MyHash myHash : myHashes) {
bits.set(myHash.hash(value), true);
}
}
/**
* 判断指定元素是否存在于位数组
*/
public boolean contains(Object value) {
boolean result = true;
for (MyHash myHash : myHashes) {
result = result && bits.get(myHash.hash(value));
}
return result;
}
/**
* 自定义 Hash 函数
*/
private class MyHash {
private int cap;
private int seed;
MyHash(int cap, int seed) {
this.cap = cap;
this.seed = seed;
}
/**
* 计算 Hash 值
*/
int hash(Object obj) {
return (obj == null) ? 0 : Math.abs(seed * (cap - 1) & (obj.hashCode() ^ (obj.hashCode() >>> 16)));
}
}
public static void main(String[] args) {
String str = "好好学技术";
MyBloomFilter myBloomFilter = new MyBloomFilter();
System.out.println("str是否存在:" + myBloomFilter.contains(str));
myBloomFilter.add(str);
System.out.println("str是否存在:" + myBloomFilter.contains(str));
}
}Introduction de dépendances
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>31.1-jre</version>
</dependency>package com.fandf.test.redis;
import com.google.common.base.Charsets;
import com.google.common.hash.BloomFilter;
import com.google.common.hash.Funnels;
/**
* @author fandongfeng
*/
public class GuavaBloomFilter {
public static void main(String[] args) {
BloomFilter<String> bloomFilter = BloomFilter.create(Funnels.stringFunnel(Charsets.UTF_8),100000,0.01);
bloomFilter.put("好好学技术");
System.out.println(bloomFilter.mightContain("不好好学技术"));
System.out.println(bloomFilter.mightContain("好好学技术"));
}
}<dependency>
<groupId>cn.hutool</groupId>
<artifactId>hutool-all</artifactId>
<version>5.8.3</version>
</dependency>package com.fandf.test.redis;
import cn.hutool.bloomfilter.BitMapBloomFilter;
import cn.hutool.bloomfilter.BloomFilterUtil;
/**
* @author fandongfeng
*/
public class HutoolBloomFilter {
public static void main(String[] args) {
BitMapBloomFilter bloomFilter = BloomFilterUtil.createBitMap(1000);
bloomFilter.add("好好学技术");
System.out.println(bloomFilter.contains("不好好学技术"));
System.out.println(bloomFilter.contains("好好学技术"));
}
}Redisson implémente le filtre Bloom
<dependency>
<groupId>org.redisson</groupId>
<artifactId>redisson</artifactId>
<version>3.20.0</version>
</dependency>package com.fandf.test.redis;
import org.redisson.Redisson;
import org.redisson.api.RBloomFilter;
import org.redisson.api.RedissonClient;
import org.redisson.config.Config;
/**
* Redisson 实现布隆过滤器
* @author fandongfeng
*/
public class RedissonBloomFilter {
public static void main(String[] args) {
Config config = new Config();
config.useSingleServer().setAddress("redis://127.0.0.1:6379");
//构造Redisson
RedissonClient redisson = Redisson.create(config);
RBloomFilter<String> bloomFilter = redisson.getBloomFilter("name");
//初始化布隆过滤器:预计元素为100000000L,误差率为1%
bloomFilter.tryInit(100000000L,0.01);
bloomFilter.add("好好学技术");
System.out.println(bloomFilter.contains("不好好学技术"));
System.out.println(bloomFilter.contains("好好学技术"));
}
}Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
















![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



