

Comme vous pouvez le voir, softmax calcule les entrées de plusieurs neurones. Lors de la dérivation de rétropropagation, vous devez envisager de dériver les paramètres de différents neurones.
Considérons deux situations :
Lorsque le paramètre de différenciation est situé au numérateur
Lorsque le paramètre de différenciation est situé au dénominateur
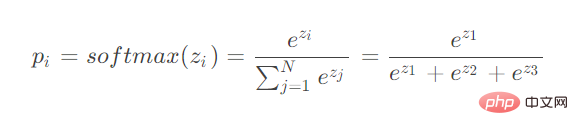
Lorsque le paramètre de différenciation est situé au numérateur :
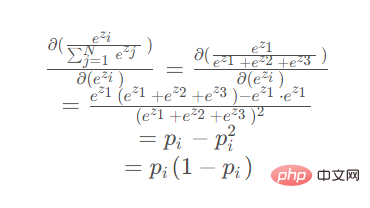
Lorsque le paramètre de dérivation est situé au dénominateur (ez2 ou ez3 sont symétriques, le résultat de la dérivation est le même) :
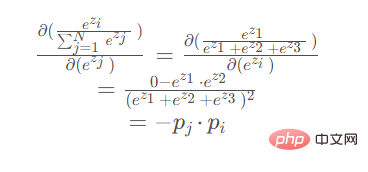
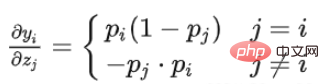
import torch
import math
def my_softmax(features):
_sum = 0
for i in features:
_sum += math.e ** i
return torch.Tensor([ math.e ** i / _sum for i in features ])
def my_softmax_grad(outputs):
n = len(outputs)
grad = []
for i in range(n):
temp = []
for j in range(n):
if i == j:
temp.append(outputs[i] * (1- outputs[i]))
else:
temp.append(-outputs[j] * outputs[i])
grad.append(torch.Tensor(temp))
return grad
if __name__ == '__main__':
features = torch.randn(10)
features.requires_grad_()
torch_softmax = torch.nn.functional.softmax
p1 = torch_softmax(features,dim=0)
p2 = my_softmax(features)
print(torch.allclose(p1,p2))
n = len(p1)
p2_grad = my_softmax_grad(p2)
for i in range(n):
p1_grad = torch.autograd.grad(p1[i],features, retain_graph=True)
print(torch.allclose(p1_grad[0], p2_grad[i]))Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
















![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



