

Analysez le code source Java ArrayQueue.

Implémentation interne d'ArrayQueue
Avant de parler de l'implémentation interne de ArrayQueue, regardons d'abord un exemple d'utilisation de ArrayQueue : ArrayQueue的内部实现之前我们先来看一个ArrayQueue的使用例子:
public void testQueue() {
ArrayQueue<Integer> queue = new ArrayQueue<>(10);
queue.add(1);
queue.add(2);
queue.add(3);
queue.add(4);
System.out.println(queue);
queue.remove(0); // 这个参数只能为0 表示删除队列当中第一个元素,也就是队头元素
System.out.println(queue);
queue.remove(0);
System.out.println(queue);
}
// 输出结果
[1, 2, 3, 4]
[2, 3, 4]
[3, 4]首先ArrayQueue内部是由循环数组实现的,可能保证增加和删除数据的时间复杂度都是,不像ArrayList删除数据的时间复杂度为。在ArrayQueue内部有两个整型数据head和tail,这两个的作用主要是指向队列的头部和尾部,它的初始状态在内存当中的布局如下图所示:

因为是初始状态head和tail的值都等于0,指向数组当中第一个数据。现在我们向ArrayQueue内部加入5个数据,那么他的内存布局将如下图所示:
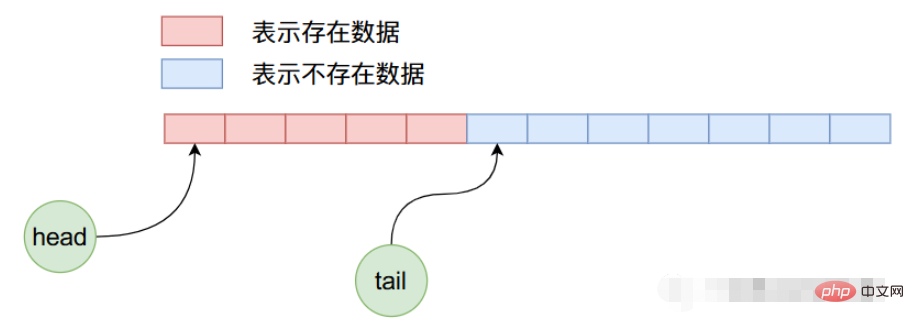
现在我们删除4个数据,那么上图经过4次删除操作之后,ArrayQueue内部数据布局如下:

在上面的状态下,我们继续加入8个数据,那么布局情况如下:

我们知道上图在加入数据的时候不仅将数组后半部分的空间使用完了,而且可以继续使用前半部分没有使用过的空间,也就是说在ArrayQueue内部实现了一个循环使用的过程。
ArrayQueue源码剖析
构造函数
public ArrayQueue(int capacity) {
this.capacity = capacity + 1;
this.queue = newArray(capacity + 1);
this.head = 0;
this.tail = 0;
}
@SuppressWarnings("unchecked")
private T[] newArray(int size) {
return (T[]) new Object[size];
}上面的构造函数的代码比较容易理解,主要就是根据用户输入的数组空间长度去申请数组,不过他具体在申请数组的时候会多申请一个空间。
add函数
public boolean add(T o) {
queue[tail] = o;
// 循环使用数组
int newtail = (tail + 1) % capacity;
if (newtail == head)
throw new IndexOutOfBoundsException("Queue full");
tail = newtail;
return true; // we did add something
}上面的代码也相对比较容易看懂,在上文当中我们已经提到了ArrayQueue可以循环将数据加入到数组当中去,这一点在上面的代码当中也有所体现。
remove函数
public T remove(int i) {
if (i != 0)
throw new IllegalArgumentException("Can only remove head of queue");
if (head == tail)
throw new IndexOutOfBoundsException("Queue empty");
T removed = queue[head];
queue[head] = null;
head = (head + 1) % capacity;
return removed;
}从上面的代码当中可以看出,在remove函数当中我们必须传递参数0,否则会抛出异常。而在这个函数当中我们只会删除当前head下标所在位置的数据,然后将head的值进行循环加1操作。
get函数
public T get(int i) {
int size = size();
if (i < 0 || i >= size) {
final String msg = "Index " + i + ", queue size " + size;
throw new IndexOutOfBoundsException(msg);
}
int index = (head + i) % capacity;
return queue[index];
}get函数的参数表示得到第i个数据,这个第i个数据并不是数组位置的第i个数据,而是距离head位置为i的位置的数据,了解这一点,上面的代码是很容易理解的。
resize函数
public void resize(int newcapacity) {
int size = size();
if (newcapacity < size)
throw new IndexOutOfBoundsException("Resizing would lose data");
newcapacity++;
if (newcapacity == this.capacity)
return;
T[] newqueue = newArray(newcapacity);
for (int i = 0; i < size; i++)
newqueue[i] = get(i);
this.capacity = newcapacity;
this.queue = newqueue;
this.head = 0;
this.tail = size;
}在resize函数当中首先申请新长度的数组空间,然后将原数组的数据一个一个的拷贝到新的数组当中,注意在这个拷贝的过程当中,重新更新了head与tail,而且并不是简单的数组拷贝,因为在之前的操作当中headrrreee
ArrayQueue est implémenté en interne par un tableau cyclique, ce qui peut garantir que la complexité temporelle de l'ajout et de la suppression de données est la même, contrairement à la complexité temporelle de <code>ArrayList pour la suppression de données. Il y a deux données entières head et tail à l'intérieur de ArrayQueue. Les fonctions de ces deux sont principalement de pointer vers la tête et la queue de la file d'attente. La disposition de l'état initial dans la mémoire est la suivante : 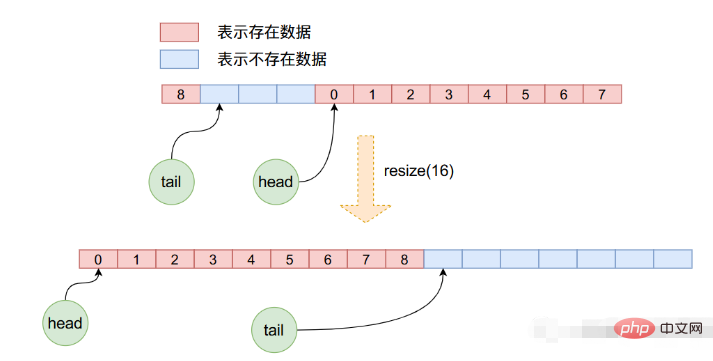
head et tail sont toutes deux égales à 0 dans l'état initial, pointant vers les premières données du tableau. Maintenant, nous ajoutons 5 données à ArrayQueue, puis sa disposition en mémoire sera comme indiqué ci-dessous : 🎜🎜🎜🎜Maintenant, nous supprimons 4 données, puis après 4 suppressions dans l'image ci-dessus, la disposition interne des données de ArrayQueue est la suivante :🎜🎜🎜🎜Dans l'état ci-dessus, On continue d'ajouter 8 données, puis la disposition est la suivante : 🎜🎜🎜🎜Nous savons que lors de l'ajout de données dans l'image ci-dessus, non seulement l'espace dans la seconde moitié du tableau est utilisé, mais aussi l'espace inutilisé dans la première moitié peut continuer à être utilisé, c'est-à-dire c'est-à-dire qu'à l'intérieur de ArrayQueue un processus de recyclage est mis en œuvre. 🎜🎜Analyse du code source d'ArrayQueue🎜Constructeur
rrreee🎜Le code du constructeur ci-dessus est relativement facile à comprendre. Il s'applique principalement à un tableau en fonction de la longueur de l'espace du tableau saisi par l'utilisateur. ce sera plus précis lors de la demande de tableau. Postulez pour un espace. 🎜ajouter une fonction
rrreee🎜Le code ci-dessus est relativement facile à comprendre. Nous avons mentionné ci-dessus queArrayQueue peut ajouter des données au tableau dans une boucle. code ci-dessus. 🎜supprimer la fonction
rrreee🎜Comme le montre le code ci-dessus, nous devons passer le paramètre 0 dans la fonctionremove, sinon une exception sera levée. Dans cette fonction, nous supprimerons uniquement les données à la position actuelle de l'indice head, puis effectuerons un incrément cyclique de 1 sur la valeur de head. 🎜fonction get
rrreee🎜Les paramètres de la fonctionget indiquent que la iième donnée est obtenue, et la ith data is not Ce ne sont pas les ièmes données à la position du tableau, mais les données à la position i à partir de la position head. Comprenant cela, le code ci-dessus est très facile à comprendre. 🎜Fonction de redimensionnement
rrreee🎜Dans la fonctionresize, demandez d'abord un espace de tableau de nouvelle longueur, puis copiez les données du tableau d'origine dans le nouveau tableau une par une . Faites attention à ceci Pendant le processus de copie, head et tail sont à nouveau mis à jour, et il ne s'agit pas d'une simple copie de tableau, car head peut être mis à jour. ont été copiés lors de l'opération précédente. Ce n'est pas 0, donc la nouvelle copie nous oblige à la retirer de l'ancien tableau un par un, puis à la placer dans le nouveau tableau. L'image ci-dessous permet de voir clairement ce processus : 🎜🎜🎜🎜Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Racine carrée en Java
Aug 30, 2024 pm 04:26 PM
Racine carrée en Java
Aug 30, 2024 pm 04:26 PM
Guide de la racine carrée en Java. Nous discutons ici du fonctionnement de Square Root en Java avec un exemple et son implémentation de code respectivement.
 Nombre parfait en Java
Aug 30, 2024 pm 04:28 PM
Nombre parfait en Java
Aug 30, 2024 pm 04:28 PM
Guide du nombre parfait en Java. Nous discutons ici de la définition, comment vérifier le nombre parfait en Java ?, des exemples d'implémentation de code.
 Générateur de nombres aléatoires en Java
Aug 30, 2024 pm 04:27 PM
Générateur de nombres aléatoires en Java
Aug 30, 2024 pm 04:27 PM
Guide du générateur de nombres aléatoires en Java. Nous discutons ici des fonctions en Java avec des exemples et de deux générateurs différents avec d'autres exemples.
 Weka en Java
Aug 30, 2024 pm 04:28 PM
Weka en Java
Aug 30, 2024 pm 04:28 PM
Guide de Weka en Java. Nous discutons ici de l'introduction, de la façon d'utiliser Weka Java, du type de plate-forme et des avantages avec des exemples.
 Numéro de Smith en Java
Aug 30, 2024 pm 04:28 PM
Numéro de Smith en Java
Aug 30, 2024 pm 04:28 PM
Guide du nombre de Smith en Java. Nous discutons ici de la définition, comment vérifier le numéro Smith en Java ? exemple avec implémentation de code.
 Questions d'entretien chez Java Spring
Aug 30, 2024 pm 04:29 PM
Questions d'entretien chez Java Spring
Aug 30, 2024 pm 04:29 PM
Dans cet article, nous avons conservé les questions d'entretien Java Spring les plus posées avec leurs réponses détaillées. Pour que vous puissiez réussir l'interview.
 Break or Return of Java 8 Stream Forach?
Feb 07, 2025 pm 12:09 PM
Break or Return of Java 8 Stream Forach?
Feb 07, 2025 pm 12:09 PM
Java 8 présente l'API Stream, fournissant un moyen puissant et expressif de traiter les collections de données. Cependant, une question courante lors de l'utilisation du flux est: comment se casser ou revenir d'une opération FOREAK? Les boucles traditionnelles permettent une interruption ou un retour précoce, mais la méthode Foreach de Stream ne prend pas directement en charge cette méthode. Cet article expliquera les raisons et explorera des méthodes alternatives pour la mise en œuvre de terminaison prématurée dans les systèmes de traitement de flux. Lire plus approfondie: Améliorations de l'API Java Stream Comprendre le flux Forach La méthode foreach est une opération terminale qui effectue une opération sur chaque élément du flux. Son intention de conception est
 Horodatage à ce jour en Java
Aug 30, 2024 pm 04:28 PM
Horodatage à ce jour en Java
Aug 30, 2024 pm 04:28 PM
Guide de TimeStamp to Date en Java. Ici, nous discutons également de l'introduction et de la façon de convertir l'horodatage en date en Java avec des exemples.
