
 Périphériques technologiques
IA
Les dernières recherches de Stanford nous rappellent de ne pas trop faire confiance à la capacité de grands modèles à émerger, car celle-ci n'est que le résultat d'une sélection métrique.
Périphériques technologiques
IA
Les dernières recherches de Stanford nous rappellent de ne pas trop faire confiance à la capacité de grands modèles à émerger, car celle-ci n'est que le résultat d'une sélection métrique.
Les dernières recherches de Stanford nous rappellent de ne pas trop faire confiance à la capacité de grands modèles à émerger, car celle-ci n'est que le résultat d'une sélection métrique.

"Ne soyez pas trop superstitieux quant à l'émergence de grands modèles. Où y a-t-il tant de miracles dans le monde ?" Des chercheurs de l'Université de Stanford ont découvert que l'émergence de grands modèles est fortement liée aux indicateurs d'évaluation de la tâche, et Ce n'est pas le comportement de base du modèle sous des tâches et des échelles spécifiques. Après le passage à des indicateurs plus continus et plus fluides, le phénomène d'émergence sera moins évident et plus proche de la linéarité.
Récemment, alors que des chercheurs ont observé que les grands modèles de langage (LLM), tels que GPT, PaLM et LaMDA, peuvent présenter des « capacités émergentes » dans différentes tâches, ce terme a gagné une grande popularité dans le domaine de apprentissage automatique. Grande attention :
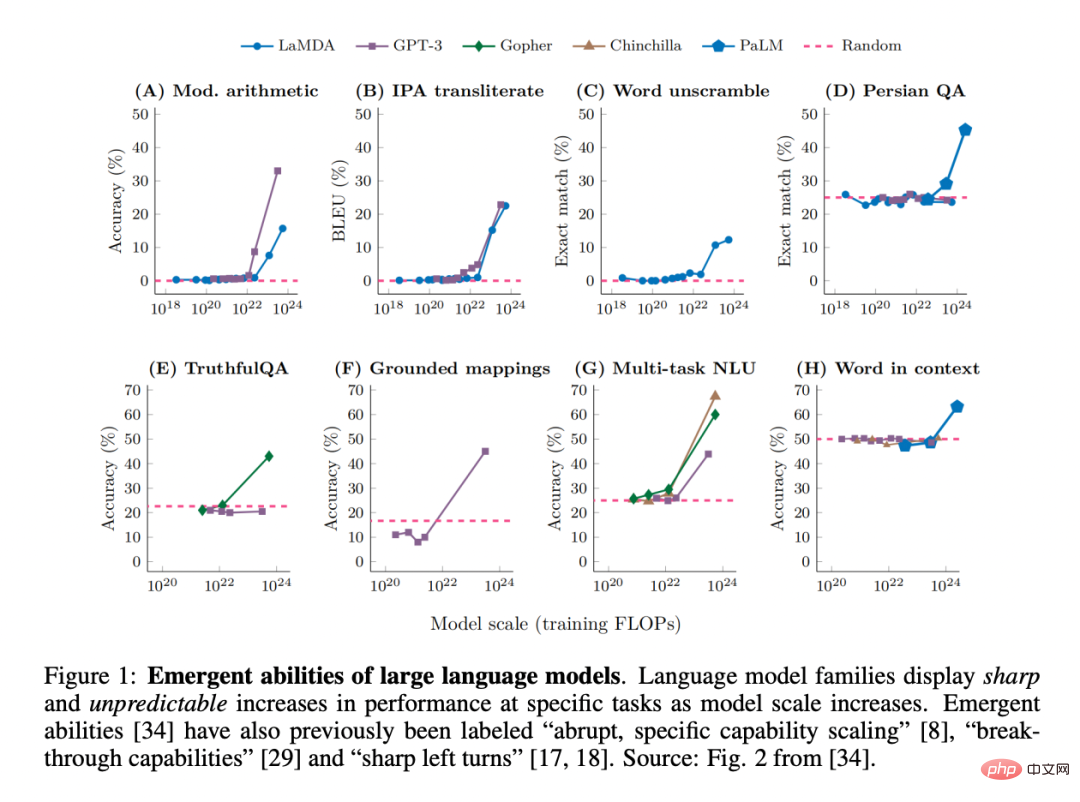
En fait, les caractéristiques émergentes des systèmes complexes ont toujours été au centre de la recherche en physique, en biologie, en mathématiques et dans d'autres disciplines.
Un point à noter est que le lauréat du prix Nobel, P.W. Anderson, a proposé « Plus c'est différent ». Selon ce point de vue, à mesure que la complexité du système augmente, de nouvelles propriétés peuvent se matérialiser, même si elles ne sont pas prédites (facilement ou pas du tout) à partir d'une compréhension quantitative précise des détails microscopiques du système.
Comment définir « émergence » dans le domaine des grands modèles ? Une façon familière de dire cela est « des capacités qui ne sont pas présentes dans les modèles à petite échelle mais sont présentes dans les modèles à grande échelle », et elles ne peuvent donc pas être prédites en extrapolant simplement les améliorations de performances à partir de modèles à petite échelle.
Cette capacité émergente a peut-être été découverte pour la première fois dans la famille GPT-3. Certains travaux ultérieurs ont mis en évidence ce constat : "Alors que les performances du modèle sont prévisibles à un niveau général, sur des tâches spécifiques, leurs performances apparaissent parfois à une échelle assez imprévisible." En fait, ces capacités émergentes sont si surprenantes que « l’expansion soudaine et spécifique des capacités » a été citée comme l’une des deux caractéristiques les plus déterminantes du LLM. En outre, des termes tels que « capacités révolutionnaires » et « virages serrés à gauche » sont également utilisés.
Pour résumer, nous pouvons identifier deux attributs décisifs de la capacité émergente du LLM :
1 L'acuité, de la « non-existence » à « l'existence » semble n'être qu'une transition instantanée ; . Imprévisibilité, transitions à des échelles de modèle apparemment imprévisibles.
Pendant ce temps, certaines questions restent sans réponse : qu'est-ce qui contrôle quelles capacités émergent ? Qu’est-ce qui contrôle l’émergence des capacités ? Comment pouvons-nous faire émerger plus rapidement les capacités souhaitables et garantir que les capacités moins souhaitables n’apparaissent jamais ?
Ces questions sont étroitement liées à la sécurité et à l'alignement de l'intelligence artificielle, car les capacités émergentes prédisent que des modèles plus grands pourraient un jour maîtriser des capacités dangereuses sans avertissement, ce que les humains ne souhaitent pas que cela se produise.
Dans un article récent, des chercheurs de l'Université de Stanford ont remis en question l'affirmation selon laquelle le LLM aurait des capacités émergentes.
 Article : https://arxiv.org/pdf/2304.15004.pdf
Article : https://arxiv.org/pdf/2304.15004.pdf
Plus précisément, la question ici concerne la sortie du modèle en fonction de la taille du modèle dans une tâche spécifique émergente et les changements imprévisibles qui se produisent.
Leur scepticisme repose sur l'observation selon laquelle les modèles semblent émergents uniquement s'ils évoluent de manière non linéaire ou discontinue sur toute mesure du taux d'erreur par jeton du modèle. Par exemple, dans la tâche BIG-Bench, >92 % des capacités émergentes ont émergé sous ces deux métriques :
Cela soulève la possibilité d'une autre explication de l'origine de la capacité émergente des LLM : bien que le taux d'erreur par jeton de la famille de modèles soit fluide, soutenu et prévisible à mesure que la taille du modèle augmente. , mais des changements apparemment brusques et imprévisibles peuvent être provoqués par la méthode de mesure choisie par les chercheurs. Afin d'illustrer cette explication, les chercheurs l'ont utilisé comme un modèle mathématique simple et ont démontré comment il peut être reproduit quantitativement pour soutenir la capacité émergente du LLM. . Nous avons ensuite testé cette explication de trois manières complémentaires : 1 En utilisant la famille de modèles InstructGPT [24]/GPT-3 [3], selon l'hypothèse alternative formulée. , teste et confirme trois prédictions. 2. Réalisé une méta-analyse de certains résultats précédents et montré que dans l'espace des triplets familiaux de modèles métriques de tâches, les capacités qui émergent n'apparaissent que dans certains modèles. familles (colonnes) sur des métriques, pas sur des tâches. L’étude montre en outre qu’à sortie de modèle fixe, la modification de la métrique entraîne la disparition du phénomène d’émergence. 3. Induire délibérément des capacités émergentes pour de multiples tâches de vision (ce qui n'a jamais été démontré auparavant) dans des réseaux neuronaux profonds de différentes architectures pour montrer quelque chose comme comment les choix métriques induisent apparemment. capacités émergentes. Test 1 : Analyse de la série de modèles InstructGPT/GPT-3
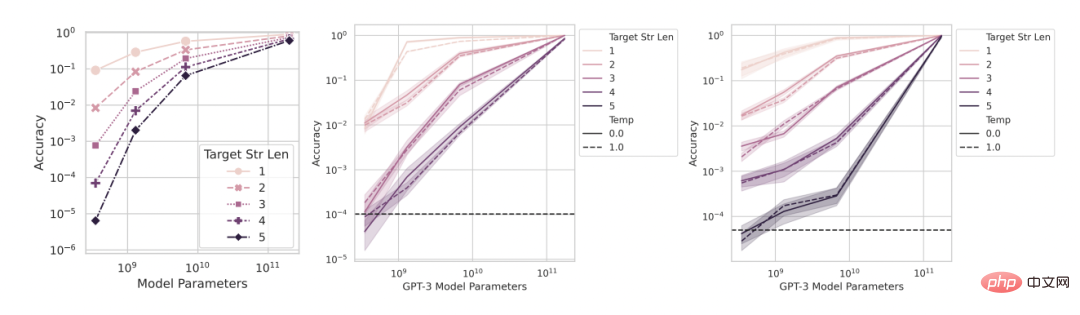
# 🎜 🎜#Figure 2 : La capacité émergente des grands modèles de langage est une création de l'analyse des chercheurs, plutôt qu'un changement fondamental dans la sortie du modèle à mesure que l'échelle change. Comme expliqué mathématiquement et graphiquement dans la section 2, l'explication alternative proposée par les chercheurs prédit trois résultats : 1 À mesure que l'échelle du modèle augmente, si la métrique passe de. d'une métrique non linéaire/discontinue (Figure 2CD) à une métrique linéaire/continue (Figure 2EF), il devrait alors y avoir des améliorations de performances fluides, continues et prévisibles. 2. Pour les mesures non linéaires, si la résolution des performances du modèle mesurée est améliorée en augmentant la taille de l'ensemble de données de test, le modèle doit être lissé, continu, amélioration prévisible, et la proportion de cette amélioration correspond aux effets non linéaires prévisibles de la métrique choisie. 3. Quelle que soit la métrique utilisée, l'augmentation de la longueur de la chaîne cible devrait avoir un impact sur les performances du modèle en fonction de la longueur de la chaîne cible 1 : La précision est presque fonction géométrique, et la distance d'édition du jeton est une fonction presque quasi-linéaire. Afin de tester ces trois conclusions de prédiction, les chercheurs ont collecté les résultats de sortie de chaîne des modèles de la série InstructGPT/GPT-3 sur deux tâches arithmétiques : à l'aide de l'API OpenAI. Effectue une multiplication à deux échantillons entre deux entiers à deux chiffres et une addition à deux échantillons entre deux entiers à quatre chiffres. Figure 3 : À mesure que la taille du modèle augmente, la modification des métriques peut améliorer les performances. Apporter un changement fluide, continu et prévisible. De gauche à droite : modèle mathématique, 2 tâches de multiplication d'entiers à deux chiffres, 2 tâches d'addition d'entiers à quatre chiffres. Le graphique ci-dessus représente les performances du modèle mesurées à l'aide d'une métrique non linéaire telle que la précision, et vous pouvez voir que les performances de la famille de modèles InstructGPT/GPT-3 semblent plus nettes et moins prévisibles à des longueurs cibles plus longues. La figure ci-dessous représente les performances du modèle mesurées à l'aide d'une métrique linéaire (telle que la distance d'édition des jetons). Cette série de modèles montre des améliorations de performances fluides et prévisibles, ce qui est la capacité qui, selon les chercheurs, émerge. Prédiction : la puissance émergente disparaît sous les mesures linéaires Sur les tâches de multiplication et d'addition d'entiers, si la longueur de la chaîne cible est de 4 ou 5 chiffres et que la performance est mesurée avec précision (rangée supérieure de la figure 3), alors les modèles de la série GPT présenteront des capacités arithmétiques émergentes. Toutefois, si vous modifiez une métrique de non linéaire à linéaire tout en conservant la sortie du modèle fixe, les performances de la famille de modèles s'améliorent de manière fluide, continue et prévisible. Cela confirme les prédictions des chercheurs, suggérant ainsi que la source de précision et d'incertitude est la métrique choisie par les chercheurs, plutôt que les changements dans les résultats du modèle. On peut également voir que lors de l'utilisation de la distance d'édition de jeton, si la longueur de la chaîne cible passe de 1 à 5, il est prévisible que les performances de cette série de modèles diminueront et que la tendance à la baisse est presque quasi linéaire. ce qui est cohérent avec le troisième et le premier semestre des prévisions. Prédiction : la puissance émergente disparaît avec l'avènement d'évaluations à plus haute résolution Vient ensuite la deuxième prédiction : même avec des mesures non linéaires comme la précision, la précision des modèles plus petits ne sera pas non plus nulle, mais plutôt une valeur non nulle au-dessus du hasard, proportionnelle au choix d'utiliser la précision comme métrique. Afin d'améliorer la résolution et d'estimer plus précisément la précision du modèle, les chercheurs ont également généré d'autres données de test, puis ils ont découvert que : qu'il s'agisse de la tâche de multiplication d'entiers ou d'addition d'entiers, tous les InstructGPT/GPT-3 série Les modèles ont tous atteint une précision positive qui dépassait le hasard (Figure 4). Cela confirme la deuxième prédiction. On peut voir qu'à mesure que la longueur de la chaîne cible augmente, la précision diminue presque géométriquement avec la longueur de la chaîne cible, ce qui est cohérent avec la seconde moitié de la troisième prédiction. Ces résultats montrent également que la précision choisie par les chercheurs a certains effets (approximatifs) auxquels on devrait s'attendre, à savoir une décroissance presque géométrique avec la longueur de la cible. Figure 4 : L'utilisation d'un plus grand nombre d'ensembles de données de test a permis d'obtenir de meilleures estimations de précision, révélant que les changements de performances sont fluides, continus et prévisibles. De gauche à droite : modèle mathématique, 2 tâches de multiplication d'entiers à deux chiffres, 2 tâches d'addition d'entiers à quatre chiffres. L'amélioration de la résolution en générant davantage de données de test révèle que les performances de la série de modèles InstructGPT/GPT-3 sont au-delà du hasard, même sur les mesures de précision, et que son amélioration dans les deux capacités émergentes est fluide. Les résultats de ces deux capacités émergentes, continus et prévisibles, sont qualitativement cohérents avec les modèles mathématiques. Étant donné que les modèles de la série GPT sont accessibles au public pour interrogation, ils peuvent être analysés. Cependant, d'autres modèles qui prétendent également avoir des capacités émergentes (tels que PaLM, Chinchilla, Gopher) ne sont pas accessibles au public et les résultats qu'ils génèrent ne sont pas publics, ce qui signifie que les chercheurs sont limités dans l'analyse des résultats publiés. Les chercheurs ont donné deux prédictions basées sur leurs propres hypothèses alternatives : Pour tester ces deux hypothèses, les chercheurs ont étudié les capacités censées émerger de la suite d'évaluation BIG-Bench, puisque les benchmarks de cette suite sont accessibles au public et bien documentés. Prédiction : les capacités émergentes devraient principalement apparaître sur des mesures non linéaires/discontinues Pour tester la première prédiction, les chercheurs ont analysé sur quels indicateurs différentes paires « séries de modèles de tâches » si des capacités émergentes émergeraient. Pour déterminer si un triplet « famille tâche-métrique-modèle » est susceptible de présenter des capacités émergentes, ils ont emprunté la définition présentée dans l'article « Au-delà du jeu d'imitation : Quantification et extrapolation des capacités des modèles de langage ». Laissez y_i ∈ R représenter les performances du modèle lorsque la taille du modèle est x_i ∈ R, et faites en sorte que x_i Étant donné que le score d'émergence indique uniquement la capacité à émerger, les chercheurs ont analysé plus en détail le triplet « série tâche-métrique-modèle » annoté manuellement dans l'article « 137 capacités émergentes de grands modèles de langage ». Les données annotées manuellement montrent que seules 4 des 39 mesures présentent des capacités émergentes (Figure 5B), et 2 d'entre elles représentent à elles seules plus de 92 % des capacités émergentes revendiquées (Figure 5C). Regroupement de sélections multiples et correspondance exacte des chaînes. Le regroupement à choix multiples n'est pas continu et la correspondance exacte des chaînes n'est pas linéaire (le changement dans la métrique de longueur cible est presque géométrique). Dans l’ensemble, ces résultats suggèrent que les capacités émergentes n’apparaissent que sur un très petit nombre de mesures non linéaires et/ou discontinues. Figure 5 : La capacité émergente n'apparaît que pour quelques mesures. (A) Sur les 39 mesures BIG-Bench que les gens préfèrent, les capacités émergentes peuvent apparaître sur seulement 5 mesures au maximum. (B) Les données annotées par l'homme de l'article cité montrent que seules 4 mesures des préférences des gens présentent un pouvoir émergent. (C) >92 % des capacités émergentes se produisent sur l'une des deux mesures : classement à choix multiples et correspondance exacte des chaînes. Prédiction : Si des mesures non linéaires/discontinues sont remplacées, la capacité émergente devrait être éliminée Pour la deuxième prédiction, les chercheurs ont analysé la capacité émergente d'annotation manuelle dans l'article cité ci-dessus. Ils se sont concentrés sur la famille LaMDA car ses sorties sont disponibles via BIG-Bench, alors que les sorties des autres familles de modèles ne le sont pas. Parmi les modèles LaMDA publiés, le plus petit comporte 2 milliards de paramètres, mais de nombreux modèles LaMDA dans BIG-Bench sont beaucoup plus petits, et les chercheurs ont déclaré que parce qu'ils ne pouvaient pas déterminer l'origine de ces modèles plus petits, ils n'ont pas été pris en compte dans l'analyse. . Dans l'analyse, les chercheurs ont identifié des tâches sur lesquelles LaMDA a démontré des capacités émergentes sur la mesure hiérarchique à choix multiples, puis ils ont demandé : LaMDA peut-il effectuer les mêmes tâches en utilisant une autre mesure BIG-Bench, le score Brier, démontre des capacités émergentes ? Le score de Brier est un ensemble de règles de notation strictement appropriées qui mesurent la prédiction de résultats mutuellement exclusifs ; pour la prédiction d'un résultat binaire, le score de Brier est simplifié à l'erreur quadratique moyenne entre le résultat et sa masse de probabilité prédite. Les chercheurs ont découvert que lorsque le classement à choix multiples métrique non continu devient le score Brier métrique continu (Figure 6), la capacité émergente de LaMDA disparaît. Cela illustre en outre que la cause de l'émergence de capacités n'est pas le changement essentiel dans le comportement du modèle à mesure que l'échelle augmente, mais l'utilisation de mesures discontinues. Test 3 : Inciter DNN à avoir une capacité émergente pour le prouver, ont-ils montré ; comment faire en sorte que différentes architectures (entièrement connectées, convolutives, auto-attention) des réseaux de neurones profonds produisent des capacités émergentes. Les chercheurs se sont concentrés ici sur les tâches visuelles pour deux raisons. Premièrement, les gens se concentrent actuellement sur les capacités émergentes des modèles linguistiques à grande échelle, car pour les modèles visuels, un passage soudain de l’absence de capacité de modèle à la oui n’a pas encore été observé. Deuxièmement, certaines tâches de vision peuvent être résolues avec des réseaux de taille modeste, de sorte que les chercheurs peuvent créer une famille complète de modèles sur plusieurs ordres de grandeur. Le réseau convolutif a émergé avec la capacité de classer les chiffres manuscrits du MNIST Les chercheurs ont d'abord induit la mise en œuvre de la série de réseaux neuronaux convolutifs LeNet à émerger avec la capacité de classer, et l'ensemble de données de formation a été le Ensemble de données de chiffres manuscrits MNIST. Cette série montre une augmentation progressive de la précision des tests à mesure que le nombre de paramètres augmente (Figure 7B). Pour simuler la métrique de précision utilisée dans les articles sur l'émergence, la précision du sous-ensemble est utilisée ici : si le réseau classe correctement K données parmi K données de test (indépendantes), alors le réseau La précision du sous-ensemble est de 1, sinon elle est de 0. Sur la base de cette définition de la précision, à mesure que K augmente de 1 à 5, cette famille de modèles présente la capacité « d'émerger » pour classer correctement l'ensemble de chiffres MNIST, en particulier lorsqu'elle est combinée à un échantillonnage clairsemé de la taille du modèle (Fig. 7C). La capacité de classification émergente de cette série de convolutions est qualitativement cohérente avec la capacité émergente des articles publiés, tels que les résultats de la tâche de cartographie topographique de BIG-Bench (Figure 7A).
Puissance de reconstruction émergente de l'autoencodeur non linéaire sur l'ensemble d'images naturelles CIFAR100 Souligner que la netteté de la métrique choisie par les chercheurs est responsable de la puissance émergente, et montrer que cette netteté Le degré est ne se limitant pas à des mesures telles que la précision. Les chercheurs ont également fait émerger l'auto-encodeur non linéaire peu profond (c'est-à-dire une seule couche cachée) formé sur l'ensemble d'images naturelles CIFAR100 avec la capacité de reconstruire l'entrée d'image. À cette fin, ils définissent délibérément une nouvelle métrique de discontinuité pour mesurer la capacité du modèle, qui est le nombre moyen de données de test avec des erreurs de reconstruction au carré inférieures à un seuil fixe c :
où I (・) est une variable indicatrice aléatoire et x^n est la reconstruction de x_n par l'auto-encodeur. Les chercheurs ont examiné le nombre d'unités de goulot d'étranglement dans l'auto-encodeur et ont constaté qu'à mesure que la taille du modèle augmente, l'erreur quadratique moyenne de reconstruction du réseau montre une tendance à la baisse douce (Figure 8B), mais si la métrique de reconstruction nouvellement définie est utilisée, pour le sélectionné c. La capacité de cette série d'auto-encodeurs à reconstruire cet ensemble de données est précise et presque imprévisible (Figure 8C). Ce résultat est qualitativement cohérent avec la capacité émergente dans les articles publiés, tels que la tâche des éléments périodiques (Figure 8A). . Figure 8 : Induire des capacités de reconstruction émergentes dans les auto-encodeurs non linéaires peu profonds. (A) Capacités émergentes basées sur la tâche d’élément périodique BIG-Bench tirée d’un article publié. (B) Un auto-encodeur non linéaire peu profond formé sur CIFAR100 présente une erreur de reconstruction du carré moyen en baisse progressive. (C) Des changements imprévisibles sont induits à l’aide de la métrique de reconstruction nouvellement définie (équation 2). Autoregressive Transformer émerge avec des capacités de classification sur le jeu de caractères Omniglot Vient ensuite la capacité émergente de Transformer, qui utilise la méthode autorégressive pour classer les caractères manuscrits Omniglot. La configuration expérimentale utilisée par les chercheurs est similaire : l'image Omniglot est d'abord intégrée par une couche convolutive, puis le transformateur réservé au décodeur est saisi sous la forme d'une séquence de paires [image intégrée, étiquette de catégorie d'image], et l'objectif de formation de ceci Transformer doit prédire l’étiquette de catégorie Omniglot. Le chercheur a mesuré les performances de classification d'images sur une séquence de longueur L ∈ [1, 5], qui a également été mesurée par la précision du sous-ensemble : si toutes les images L sont classées correctement (Figure 9B), alors la précision du sous-ensemble est de 1, sinon elle est de 0. . Causal Transformer semble présenter des capacités émergentes dans la tâche de classer correctement les caractères manuscrits Omniglot (Figure 9C), un résultat qui est qualitativement cohérent avec les capacités émergentes dans les articles publiés, telles que la compréhension du langage multitâche à grande échelle (Figure 9A). 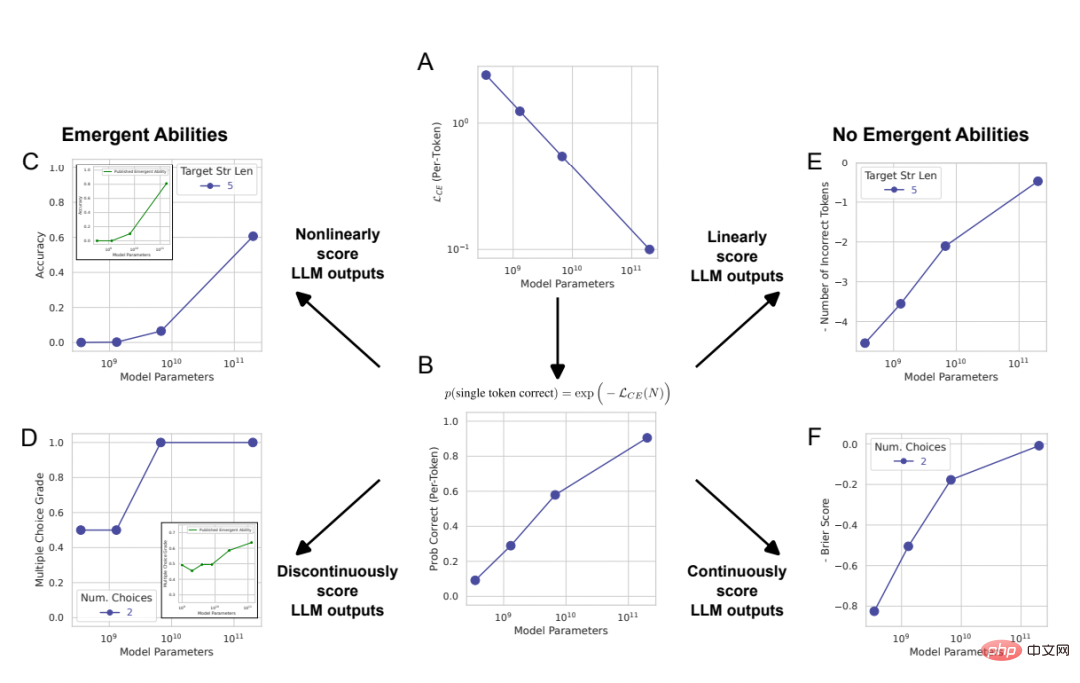
Test 2 : Méta-analyse de l'émergence du modèle
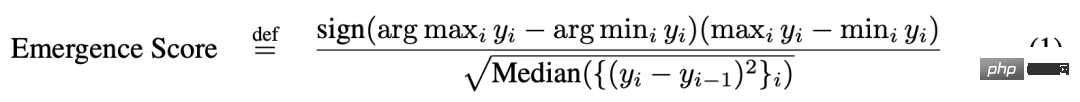
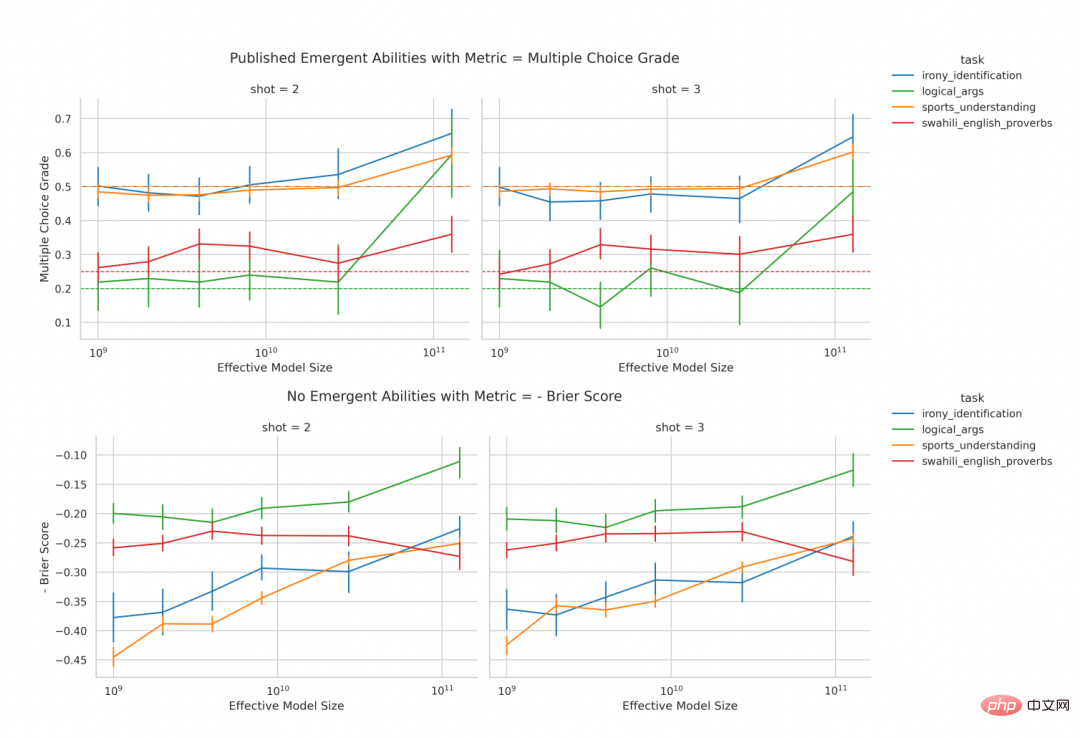
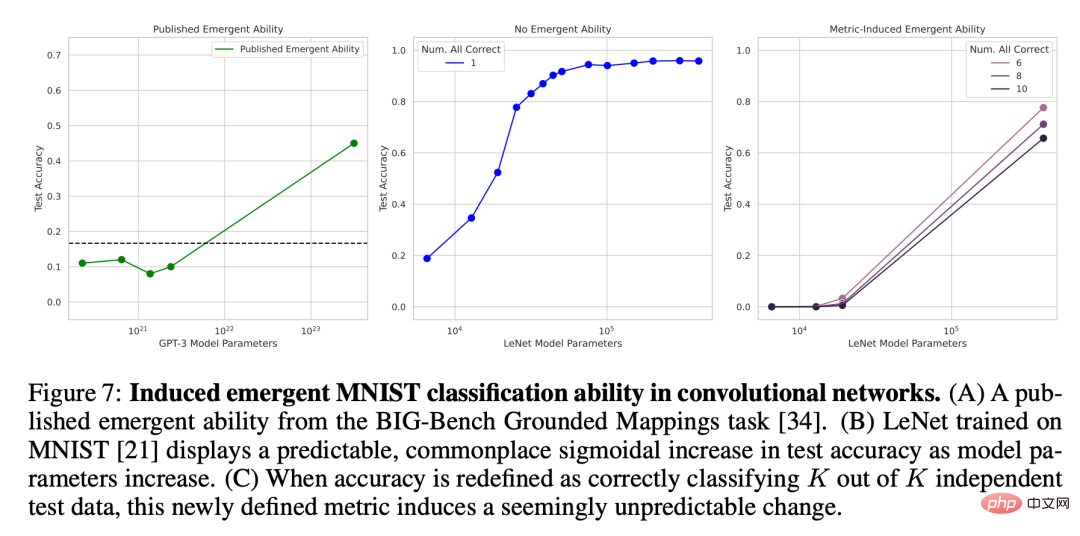
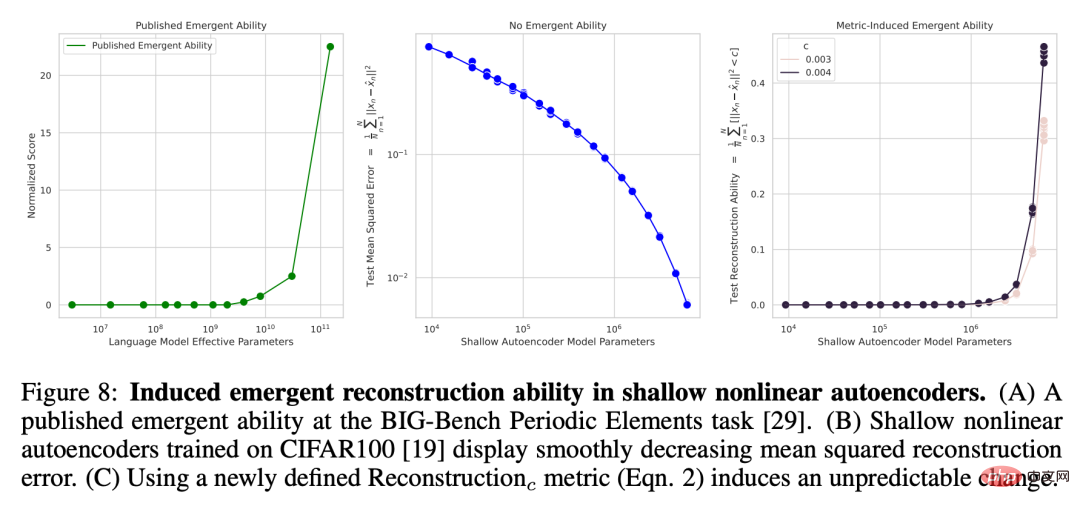
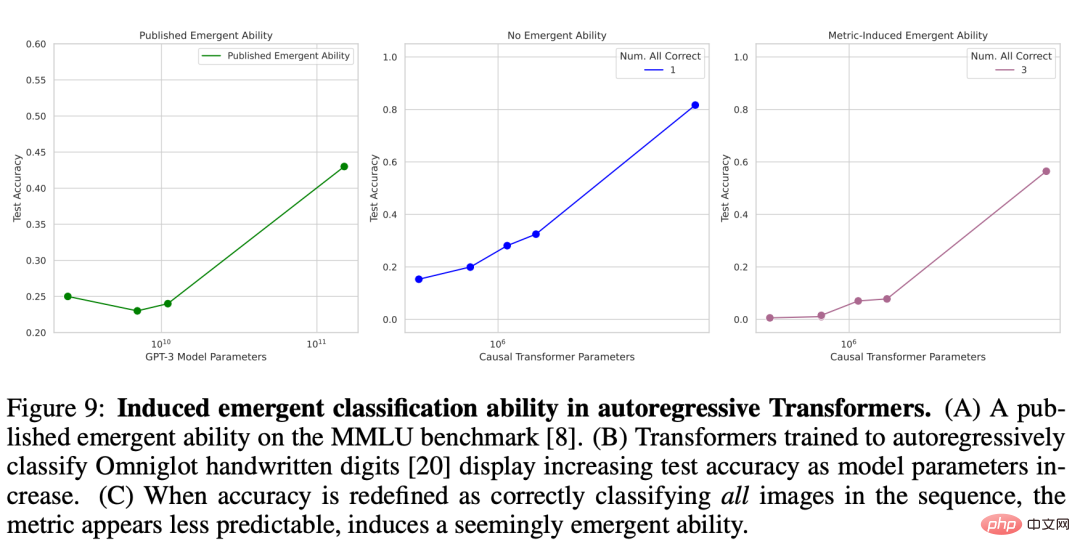
Figure 9 : Induire des capacités de classification émergentes dans un transformateur autorégressif. (A) Capacités émergentes basées sur le benchmark MMLU dans un article publié. (B) À mesure que les paramètres du modèle augmentent, la précision du test du transformateur qui utilise la méthode autorégressive pour classer les chiffres manuscrits Omniglot montre également une augmentation. (C) Lorsque la précision est redéfinie comme la classification correcte de toutes les images d’une séquence, la métrique est plus difficile à prédire, ce qui semble indiquer l’induction d’une capacité émergente.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Le modèle MoE open source le plus puissant au monde est ici, avec des capacités chinoises comparables à celles du GPT-4, et le prix ne représente que près d'un pour cent de celui du GPT-4-Turbo.
May 07, 2024 pm 04:13 PM
Le modèle MoE open source le plus puissant au monde est ici, avec des capacités chinoises comparables à celles du GPT-4, et le prix ne représente que près d'un pour cent de celui du GPT-4-Turbo.
May 07, 2024 pm 04:13 PM
Imaginez un modèle d'intelligence artificielle qui non seulement a la capacité de surpasser l'informatique traditionnelle, mais qui permet également d'obtenir des performances plus efficaces à moindre coût. Ce n'est pas de la science-fiction, DeepSeek-V2[1], le modèle MoE open source le plus puissant au monde est ici. DeepSeek-V2 est un puissant mélange de modèle de langage d'experts (MoE) présentant les caractéristiques d'une formation économique et d'une inférence efficace. Il est constitué de 236B paramètres, dont 21B servent à activer chaque marqueur. Par rapport à DeepSeek67B, DeepSeek-V2 offre des performances plus élevées, tout en économisant 42,5 % des coûts de formation, en réduisant le cache KV de 93,3 % et en augmentant le débit de génération maximal à 5,76 fois. DeepSeek est une entreprise explorant l'intelligence artificielle générale
 L'IA bouleverse la recherche mathématique ! Le lauréat de la médaille Fields et mathématicien sino-américain a dirigé 11 articles les mieux classés | Aimé par Terence Tao
Apr 09, 2024 am 11:52 AM
L'IA bouleverse la recherche mathématique ! Le lauréat de la médaille Fields et mathématicien sino-américain a dirigé 11 articles les mieux classés | Aimé par Terence Tao
Apr 09, 2024 am 11:52 AM
L’IA change effectivement les mathématiques. Récemment, Tao Zhexuan, qui a prêté une attention particulière à cette question, a transmis le dernier numéro du « Bulletin de l'American Mathematical Society » (Bulletin de l'American Mathematical Society). En se concentrant sur le thème « Les machines changeront-elles les mathématiques ? », de nombreux mathématiciens ont exprimé leurs opinions. L'ensemble du processus a été plein d'étincelles, intense et passionnant. L'auteur dispose d'une équipe solide, comprenant Akshay Venkatesh, lauréat de la médaille Fields, le mathématicien chinois Zheng Lejun, l'informaticien de l'Université de New York Ernest Davis et de nombreux autres universitaires bien connus du secteur. Le monde de l’IA a radicalement changé. Vous savez, bon nombre de ces articles ont été soumis il y a un an.
 KAN, qui remplace MLP, a été étendu à la convolution par des projets open source
Jun 01, 2024 pm 10:03 PM
KAN, qui remplace MLP, a été étendu à la convolution par des projets open source
Jun 01, 2024 pm 10:03 PM
Plus tôt ce mois-ci, des chercheurs du MIT et d'autres institutions ont proposé une alternative très prometteuse au MLP – KAN. KAN surpasse MLP en termes de précision et d’interprétabilité. Et il peut surpasser le MLP fonctionnant avec un plus grand nombre de paramètres avec un très petit nombre de paramètres. Par exemple, les auteurs ont déclaré avoir utilisé KAN pour reproduire les résultats de DeepMind avec un réseau plus petit et un degré d'automatisation plus élevé. Plus précisément, le MLP de DeepMind compte environ 300 000 paramètres, tandis que le KAN n'en compte qu'environ 200. KAN a une base mathématique solide comme MLP est basé sur le théorème d'approximation universelle, tandis que KAN est basé sur le théorème de représentation de Kolmogorov-Arnold. Comme le montre la figure ci-dessous, KAN a
 Bonjour, Atlas électrique ! Le robot Boston Dynamics revient à la vie, des mouvements étranges à 180 degrés effraient Musk
Apr 18, 2024 pm 07:58 PM
Bonjour, Atlas électrique ! Le robot Boston Dynamics revient à la vie, des mouvements étranges à 180 degrés effraient Musk
Apr 18, 2024 pm 07:58 PM
Boston Dynamics Atlas entre officiellement dans l’ère des robots électriques ! Hier, l'Atlas hydraulique s'est retiré "en larmes" de la scène de l'histoire. Aujourd'hui, Boston Dynamics a annoncé que l'Atlas électrique était au travail. Il semble que dans le domaine des robots humanoïdes commerciaux, Boston Dynamics soit déterminé à concurrencer Tesla. Après la sortie de la nouvelle vidéo, elle a déjà été visionnée par plus d’un million de personnes en seulement dix heures. Les personnes âgées partent et de nouveaux rôles apparaissent. C'est une nécessité historique. Il ne fait aucun doute que cette année est l’année explosive des robots humanoïdes. Les internautes ont commenté : Les progrès des robots ont fait ressembler la cérémonie d'ouverture de cette année à des êtres humains, et le degré de liberté est bien plus grand que celui des humains. Mais n'est-ce vraiment pas un film d'horreur ? Au début de la vidéo, Atlas est allongé calmement sur le sol, apparemment sur le dos. Ce qui suit est à couper le souffle
 Google est ravi : les performances de JAX surpassent Pytorch et TensorFlow ! Cela pourrait devenir le choix le plus rapide pour la formation à l'inférence GPU
Apr 01, 2024 pm 07:46 PM
Google est ravi : les performances de JAX surpassent Pytorch et TensorFlow ! Cela pourrait devenir le choix le plus rapide pour la formation à l'inférence GPU
Apr 01, 2024 pm 07:46 PM
Les performances de JAX, promu par Google, ont dépassé celles de Pytorch et TensorFlow lors de récents tests de référence, se classant au premier rang sur 7 indicateurs. Et le test n’a pas été fait sur le TPU présentant les meilleures performances JAX. Bien que parmi les développeurs, Pytorch soit toujours plus populaire que Tensorflow. Mais à l’avenir, des modèles plus volumineux seront peut-être formés et exécutés sur la base de la plate-forme JAX. Modèles Récemment, l'équipe Keras a comparé trois backends (TensorFlow, JAX, PyTorch) avec l'implémentation native de PyTorch et Keras2 avec TensorFlow. Premièrement, ils sélectionnent un ensemble de
 Les robots Tesla travaillent dans les usines, Musk : Le degré de liberté des mains atteindra 22 cette année !
May 06, 2024 pm 04:13 PM
Les robots Tesla travaillent dans les usines, Musk : Le degré de liberté des mains atteindra 22 cette année !
May 06, 2024 pm 04:13 PM
La dernière vidéo du robot Optimus de Tesla est sortie, et il peut déjà fonctionner en usine. À vitesse normale, il trie les batteries (les batteries 4680 de Tesla) comme ceci : Le responsable a également publié à quoi cela ressemble à une vitesse 20 fois supérieure - sur un petit "poste de travail", en sélectionnant et en sélectionnant et en sélectionnant : Cette fois, il est publié L'un des points forts de la vidéo est qu'Optimus réalise ce travail en usine, de manière totalement autonome, sans intervention humaine tout au long du processus. Et du point de vue d'Optimus, il peut également récupérer et placer la batterie tordue, en se concentrant sur la correction automatique des erreurs : concernant la main d'Optimus, le scientifique de NVIDIA Jim Fan a donné une évaluation élevée : la main d'Optimus est l'un des robots à cinq doigts du monde. le plus adroit. Ses mains ne sont pas seulement tactiles
 FisheyeDetNet : le premier algorithme de détection de cible basé sur une caméra fisheye
Apr 26, 2024 am 11:37 AM
FisheyeDetNet : le premier algorithme de détection de cible basé sur une caméra fisheye
Apr 26, 2024 am 11:37 AM
La détection de cibles est un problème relativement mature dans les systèmes de conduite autonome, parmi lesquels la détection des piétons est l'un des premiers algorithmes à être déployés. Des recherches très complètes ont été menées dans la plupart des articles. Cependant, la perception de la distance à l’aide de caméras fisheye pour une vue panoramique est relativement moins étudiée. En raison de la distorsion radiale importante, la représentation standard du cadre de délimitation est difficile à mettre en œuvre dans les caméras fisheye. Pour alléger la description ci-dessus, nous explorons les conceptions étendues de boîtes englobantes, d'ellipses et de polygones généraux dans des représentations polaires/angulaires et définissons une métrique de segmentation d'instance mIOU pour analyser ces représentations. Le modèle fisheyeDetNet proposé avec une forme polygonale surpasse les autres modèles et atteint simultanément 49,5 % de mAP sur l'ensemble de données de la caméra fisheye Valeo pour la conduite autonome.
 DualBEV : dépassant largement BEVFormer et BEVDet4D, ouvrez le livre !
Mar 21, 2024 pm 05:21 PM
DualBEV : dépassant largement BEVFormer et BEVDet4D, ouvrez le livre !
Mar 21, 2024 pm 05:21 PM
Cet article explore le problème de la détection précise d'objets sous différents angles de vue (tels que la perspective et la vue à vol d'oiseau) dans la conduite autonome, en particulier comment transformer efficacement les caractéristiques de l'espace en perspective (PV) en vue à vol d'oiseau (BEV). implémenté via le module Visual Transformation (VT). Les méthodes existantes sont globalement divisées en deux stratégies : la conversion 2D en 3D et la conversion 3D en 2D. Les méthodes 2D vers 3D améliorent les caractéristiques 2D denses en prédisant les probabilités de profondeur, mais l'incertitude inhérente aux prévisions de profondeur, en particulier dans les régions éloignées, peut introduire des inexactitudes. Alors que les méthodes 3D vers 2D utilisent généralement des requêtes 3D pour échantillonner des fonctionnalités 2D et apprendre les poids d'attention de la correspondance entre les fonctionnalités 3D et 2D via un transformateur, ce qui augmente le temps de calcul et de déploiement.
