

Contexte : Avec la mise à niveau du matériel informatique, notre logiciel a la capacité d'effectuer des tâches dans plusieurs threads. Lorsque nous faisons de la programmation multithread, nous devons créer des threads. Si la concurrence du programme est très élevée, nous créerons un grand nombre de threads, et chaque thread effectuera une courte tâche, puis se terminera fréquemment. réduit considérablement les performances du système et augmente la surcharge du serveur, car la création et la destruction de threads nécessitent une consommation supplémentaire.
À l'heure actuelle, nous pouvons utiliser la technologie de pooling pour optimiser ce défaut, et le pool de threads est né.
L'essence de la technologie de mise en commun est de parvenir à réutiliser les ressources et de réduire les frais de création et de destruction de ressources dans des scénarios à forte concurrence. Si le nombre de simultanéités est faible, il n'y a aucun avantage évident (les ressources occupent toujours la mémoire système et n'ont aucune chance de l'être). utilisé).
Introduction à la technologie de pooling : Quand la technologie de pooling est-elle utilisée ? La technologie de pooling est une technique de programmation qui peut optimiser considérablement le programme en cas de concurrence élevée dans le programme et réduire les frais supplémentaires tels que la création et la destruction fréquentes de connexions dans le système. Les technologies de pooling avec lesquelles nous sommes souvent en contact incluent les pools de connexions de bases de données, les pools de threads, les pools d'objets, etc. La caractéristique de la technologie de pooling est de maintenir certaines ressources coûteuses dans un pool spécifique (mémoire), et de spécifier son nombre minimum de connexions, son nombre maximum de connexions, les files d'attente de blocage, les règles de débordement et d'autres configurations pour faciliter une gestion unifiée. Dans des circonstances normales, il sera également doté de certaines fonctions de support telles que la surveillance et le recyclage forcé.
La technologie de pooling est une technologie d'utilisation des ressources. Les scénarios d'utilisation typiques sont :
Lorsque le coût d'obtention des ressources est élevé
Lorsque la fréquence des demandes de ressources est élevée et le nombre total de ressources utilisées est faible.
Lorsque vous êtes confronté à des problèmes de performances impliquant des retards de traitement
Classification des ressources technologiques de pooling :
Ressources système appelées par le système, telles que les threads, les processus, l'allocation de mémoire, etc.
Ressources distantes pour la communication réseau, telles que les connexions de base de données, les connexions socket, etc.
Les pools de threads sont nés pour éviter la surcharge supplémentaire liée à la création et à la destruction de threads, nous définissons et créons donc après le pool de threads, nous n'avons pas besoin de créer des threads nous-mêmes, mais d'utiliser des appels de pool de threads pour effectuer nos tâches. Voyons comment définir et créer un pool de threads.
Pour créer un pool de threads, vous pouvez utiliser Executors, qui fournit une série de méthodes d'usine pour créer des pools de threads, et les pools de threads renvoyés implémentent tous Interface ExecutorService. L'interface
ExecutorService est une interface de sous-classe de l'interface Executor et est plus largement utilisée. Elle fournit des méthodes de gestion du cycle de vie du pool de threads et renvoie des Objets futurs.
C'est-à-dire que nous créons un pool de threads via Executors, obtenons ExecutorService et exécutons des tâches asynchrones (implémentons l'interface Runnable) via ExecutorService ExecutorService,通过ExecutorService执行异步任务(实现Runnable接口)
Executors 可以创建一下几种类型的线程池:
newCachedThreadPool 创建一个可缓存线程池,如果线程池线程数量过剩,会在60秒后回收掉多余线程资源,当任务书增加,线程不够用,则会新建线程。
newFixedThreadPool 创建一个定长线程池,可控制线程最大并发数,超出的线程会在队列中等待。
newScheduledThreadPool 创建一个定长线程池,支持定时及周期性任务执行。
newSingleThreadExecutor 创建一个单线程的线程池,只使用唯一的线程来执行任务,可以保证任务按照提交顺序来完成。
在阿里巴巴开发规范中,规定线程池不允许通过Executors创建,而是通过ThreadPoolExecutor创建。
好处:让写的同学可以更加明确线程池的运行规则,规避资源耗尽的风险。
ThreadPoolExecutor的七大参数:
(1)corePoolSize 核心线程数量,核心线程会一直保留,不会被销毁。
(2)maximumPoolSize 最大线程数,当核心线程不能满足任务需要时,系统就会创建新的线程来执行任务。
(3)keepAliveTime 存活时间,核心线程之外的线程空闲多长时间就会被销毁。
(4)timeUnit 代表线程存活的时间单位。
(5)BlockingQueue
newCachedThreadPool crée un pool de threads pouvant être mis en cache. S'il y a trop de threads dans le pool de threads, les ressources de threads excédentaires seront recyclées après 60 secondes. , il n'y a pas assez de fils de discussion. Un nouveau fil de discussion va être créé. newFixedThreadPool crée un pool de threads de longueur fixe, qui peut contrôler le nombre maximum de threads simultanés qui attendent dans la file d'attente. 🎜🎜🎜🎜
newScheduledThreadPool Crée un pool de threads de longueur fixe pour prendre en charge l'exécution de tâches planifiées et périodiques. 🎜🎜🎜🎜newSingleThreadExecutor Créez un pool de threads monothread et utilisez uniquement le seul thread pour exécuter les tâches, en vous assurant que les tâches sont terminées dans l'ordre dans lequel elles sont soumises. 🎜🎜🎜🎜Option 2 : ThreadPoolExecutor🎜🎜Dans les spécifications de développement d'Alibaba, il est stipulé que les pools de threads ne peuvent pas être créés via des exécuteurs, mais sont créés via ThreadPoolExecutor. 🎜🎜Avantages : les étudiants qui écrivent peuvent être plus clairs sur les règles de fonctionnement du pool de threads et éviter le risque d'épuisement des ressources. 🎜🎜🎜Les sept paramètres de ThreadPoolExecutor : 🎜🎜🎜(1)corePoolSize Le nombre de threads principaux sera toujours conservé et ne sera pas détruit. 🎜🎜(2)maximumPoolSize Le nombre maximum de threads lorsque les threads principaux ne peuvent pas répondre aux besoins de la tâche, le système crée de nouveaux threads pour exécuter les tâches. 🎜🎜(3)keepAliveTime temps de survie, la durée pendant laquelle les threads autres que les threads principaux restent inactifs sera détruite. 🎜🎜(4)timeUnit représente l'unité de temps pour la survie du thread. 🎜🎜(5)BlockingQueue File d'attente de blocage🎜🎜🎜🎜Si la tâche en cours d'exécution dépasse le nombre maximum de threads, elle peut être stockée dans la file d'attente. Lorsqu'il y a des ressources libres dans le pool de threads, le la tâche peut être retirée de la file d'attente. Continuer l'exécution. 🎜🎜🎜🎜🎜Les types de files d'attente sont les suivants : 🎜LinkedBlockingQueue ArrayBlockingQueue SynchronousQueue TransferQueue. 🎜(6)threadFactory La fabrique de threads est utilisée pour créer des threads. Les threads peuvent être personnalisés. Par exemple, nous pouvons définir des noms de groupes de threads, ce qui est très utile lors du dépannage des problèmes de jstack. threadFactory 线程工厂,用来创建线程的,可以自定义线程,比如我们可以定义线程组名称,在jstack问题排查时,非常有帮助。
(7)rejectedExecutionHandler 拒绝策略,
当所有线程(最大线程数)都在忙,并且任务队列处于满任务的状态,则会执行拒绝策略。
JDK为我们提供了四种拒绝策略,我们必须都得熟悉
AbortPolicy: 丢弃任务,并抛出异常RejectedExecutionException。 默认
DiscardPolicy: 丢弃最新的任务,不抛异常。
DiscardOldestPolicy: 扔掉排队时间最久的任务,也就是最旧的任务。
CallerRuns: 由调用者(提交异步任务的线程)处理任务。
想要实现一个线程池我们就需要关心ThreadPoolExecutor类,因为Executors创建线程池也是通过new ThreadPoolExecutor对象。
看一下ThreadPoolExecutor的类继承关系,可以看出为什么通过Executors创建的线程池返回结果是ExecutorService,因为ThreadPoolExecutor是ExecutorService接口的实现类,而Executors创建线程池本质也是创建的ThreadPoolExecutor 对象。
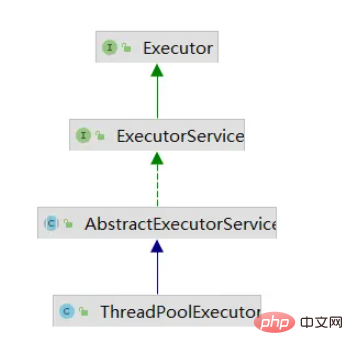
下面我们一起看一下ThreadPoolExecutor的源码,首先是ThreadPoolExecutor内定义的变量,常量:
// 复合类型变量 是一个原子整数 控制状态(运行状态|线程池活跃线程数量)
private final AtomicInteger ctl = new AtomicInteger(ctlOf(RUNNING, 0));
private static final int COUNT_BITS = Integer.SIZE - 3; // 低29位
private static final int CAPACITY = (1 << COUNT_BITS) - 1; // 容量
// 运行状态存储在高位3位
private static final int RUNNING = -1 << COUNT_BITS; // 接受新任务,并处理队列任务
private static final int SHUTDOWN = 0 << COUNT_BITS; // 不接受新任务,但会处理队列任务
private static final int STOP = 1 << COUNT_BITS; // 不接受新任务,不会处理队列任务,中断正在处理的任务
private static final int TIDYING = 2 << COUNT_BITS; // 所有的任务已结束,活跃线程为0,线程过渡到TIDYING状 态,将会执行terminated()钩子方法
private static final int TERMINATED = 3 << COUNT_BITS; // terminated()方法已经完成
// 设置 ctl 参数方法
private static int runStateOf(int c) { return c & ~CAPACITY; }
private static int workerCountOf(int c) { return c & CAPACITY; }
private static int ctlOf(int rs, int wc) { return rs | wc; }
/**
* 阻塞队列
*/
private final BlockingQueue<Runnable> workQueue;
/**
* Lock 锁.
*/
private final ReentrantLock mainLock = new ReentrantLock();
/**
* 工人们
*/
private final HashSet<Worker> workers = new HashSet<Worker>();
/**
* 等待条件支持等待终止
*/
private final Condition termination = mainLock.newCondition();
/**
* 最大的池大小.
*/
private int largestPoolSize;
/**
* 完成任务数
*/
private long completedTaskCount;
/**
* 线程工厂
*/
private volatile ThreadFactory threadFactory;
/**
* 拒绝策略
*/
private volatile RejectedExecutionHandler handler;
/**
* 存活时间
*/
private volatile long keepAliveTime;
/**
* 允许核心线程数
*/
private volatile boolean allowCoreThreadTimeOut;
/**
* 核心线程数
*/
private volatile int corePoolSize;
/**
* 最大线程数
*/
private volatile int maximumPoolSize;
/**
* 默认拒绝策略
*/
private static final RejectedExecutionHandler defaultHandler =
new AbortPolicy();
/**
* shutdown and shutdownNow权限
*/
private static final RuntimePermission shutdownPerm =
new RuntimePermission("modifyThread");构造器,,支持最少五种参数,最大七中参数的四种构造器:
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue) {
this(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue,
Executors.defaultThreadFactory(), defaultHandler);
}
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory) {
this(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue,
threadFactory, defaultHandler);
}
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
RejectedExecutionHandler handler) {
this(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue,
Executors.defaultThreadFactory(), handler);
}
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler) {
if (corePoolSize < 0 ||
maximumPoolSize <= 0 ||
maximumPoolSize < corePoolSize ||
keepAliveTime < 0)
throw new IllegalArgumentException();
if (workQueue == null || threadFactory == null || handler == null)
throw new NullPointerException();
this.corePoolSize = corePoolSize;
this.maximumPoolSize = maximumPoolSize;
this.workQueue = workQueue;
this.keepAliveTime = unit.toNanos(keepAliveTime);
this.threadFactory = threadFactory;
this.handler = handler;
}工人,线程池中执行任务的,线程池就是通过这些工人进行工作的,有核心员工(核心线程)和临时工(人手不够的时候,临时创建的,如果空闲时间厂,就会被裁员),
private final class Worker
extends AbstractQueuedSynchronizer
implements Runnable
{
private static final long serialVersionUID = 6138294804551838833L;
// 工人的本质就是个线程
final Thread thread;
// 第一件工作任务
Runnable firstTask;
volatile long completedTasks;
/**
* 构造器
*/
Worker(Runnable firstTask) {
setState(-1); // inhibit interrupts until runWorker
this.firstTask = firstTask;
this.thread = getThreadFactory().newThread(this);
}
/** 工作 */
public void run() {
runWorker(this);
}
protected boolean isHeldExclusively() {
return getState() != 0;
}
protected boolean tryAcquire(int unused) {
if (compareAndSetState(0, 1)) {
setExclusiveOwnerThread(Thread.currentThread());
return true;
}
return false;
}
protected boolean tryRelease(int unused) {
setExclusiveOwnerThread(null);
setState(0);
return true;
}
public void lock() { acquire(1); }
public boolean tryLock() { return tryAcquire(1); }
public void unlock() { release(1); }
public boolean isLocked() { return isHeldExclusively(); }
void interruptIfStarted() {
Thread t;
if (getState() >= 0 && (t = thread) != null && !t.isInterrupted()) {
try {
t.interrupt();
} catch (SecurityException ignore) {
}
}
}
}核心方法,通过线程池执行任务(这也是线程池的运行原理):
检验任务
获取当前线程池状态
判断上班工人数量是否小于核心员工数
如果小于则招人,安排工作
不小于则判断等候区任务是否排满
如果没有排满则任务排入等候区
如果排满,看是否允许招人,允许招人则招临时工
如果都不行,该线程池无法接收新任务,开始按老板约定的拒绝策略,执行拒绝策略
public void execute(Runnable command) {
if (command == null)
throw new NullPointerException();
int c = ctl.get();
if (workerCountOf(c) < corePoolSize) {
if (addWorker(command, true))
return;
c = ctl.get();
}
if (isRunning(c) && workQueue.offer(command)) {
int recheck = ctl.get();
if (! isRunning(recheck) && remove(command))
reject(command);
else if (workerCountOf(recheck) == 0)
addWorker(null, false);
}
else if (!addWorker(command, false))
reject(command);
}submit()方法是其抽象父类定义的,这里我们就可以明显看到submit与execute的区别,通过submit调用,我们会创建RunnableFuture
rejectedExecutionHandler Politique de rejet, Lorsque tous les threads (nombre maximum de threads) sont occupés et que la file d'attente des tâches est pleine de tâches, la politique de rejet sera exécutée.
JDK nous propose quatre stratégies de rejet, nous devons tous les connaître
AbortPolicy : Abandonnez la tâche et lancez l'exception RejectedExecutionException. Default
🎜🎜ThreadPoolExecutor, vous pouvez voir pourquoi le pool de threads créé via Executors renvoie le résultat ExecutorService, car ThreadPoolExecutor est la classe d'implémentation de l'interface ExecutorService. , et Executors L'essence de la création d'un pool de threads est également de créer un objet ThreadPoolExecutor. 🎜🎜🎜🎜Travaillons ensemble Jetez un œil au code source de ThreadPoolExecutor. Le premier concerne les variables et constantes définies dans ThreadPoolExecutor : le constructeur 🎜public abstract class AbstractExecutorService implements ExecutorService {
public Future<?> submit(Runnable task) {
if (task == null) throw new NullPointerException();
RunnableFuture<Void> ftask = newTaskFor(task, null);
execute(ftask);
return ftask;
}
public <T> Future<T> submit(Runnable task, T result) {
if (task == null) throw new NullPointerException();
RunnableFuture<T> ftask = newTaskFor(task, result);
execute(ftask);
return ftask;
}
public <T> Future<T> submit(Callable<T> task) {
if (task == null) throw new NullPointerException();
RunnableFuture<T> ftask = newTaskFor(task);
execute(ftask);
return ftask;
}
...
} private boolean addWorker(Runnable firstTask, boolean core) {
retry:
for (;;) {
int c = ctl.get();
int rs = runStateOf(c);
// 判断状态,及任务列表
if (rs >= SHUTDOWN &&
! (rs == SHUTDOWN &&
firstTask == null &&
! workQueue.isEmpty()))
return false;
for (;;) {
int wc = workerCountOf(c);
if (wc >= CAPACITY ||
wc >= (core ? corePoolSize : maximumPoolSize))
return false;
if (compareAndIncrementWorkerCount(c))
break retry;
c = ctl.get(); // Re-read ctl
if (runStateOf(c) != rs)
continue retry;
// else CAS failed due to workerCount change; retry inner loop
}
}
boolean workerStarted = false;
boolean workerAdded = false;
Worker w = null;
try {
w = new Worker(firstTask);
final Thread t = w.thread;
if (t != null) {
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
int rs = runStateOf(ctl.get());
if (rs < SHUTDOWN ||
(rs == SHUTDOWN && firstTask == null)) {
if (t.isAlive()) // precheck that t is startable
throw new IllegalThreadStateException();
workers.add(w);
int s = workers.size();
if (s > largestPoolSize)
largestPoolSize = s;
workerAdded = true;
}
} finally {
mainLock.unlock();
}
if (workerAdded) {
t.start();
workerStarted = true;
}
}
} finally {
if (! workerStarted)
addWorkerFailed(w);
}
return workerStarted;
} private Runnable getTask() {
boolean timedOut = false; // Did the last poll() time out?
for (;;) {
int c = ctl.get();
int rs = runStateOf(c);
// Check if queue empty only if necessary.
if (rs >= SHUTDOWN && (rs >= STOP || workQueue.isEmpty())) {
decrementWorkerCount();
return null;
}
int wc = workerCountOf(c);
// Are workers subject to culling?
boolean timed = allowCoreThreadTimeOut || wc > corePoolSize;
if ((wc > maximumPoolSize || (timed && timedOut))
&& (wc > 1 || workQueue.isEmpty())) {
if (compareAndDecrementWorkerCount(c))
return null;
continue;
}
try {
Runnable r = timed ?
workQueue.poll(keepAliveTime, TimeUnit.NANOSECONDS) :
workQueue.take();
if (r != null)
return r;
timedOut = true;
} catch (InterruptedException retry) {
timedOut = false;
}
}
} final void runWorker(Worker w) {
Thread wt = Thread.currentThread();
Runnable task = w.firstTask;
w.firstTask = null;
w.unlock(); // allow interrupts
boolean completedAbruptly = true;
try {
while (task != null || (task = getTask()) != null) {
w.lock();
// If pool is stopping, ensure thread is interrupted;
// if not, ensure thread is not interrupted. This
// requires a recheck in second case to deal with
// shutdownNow race while clearing interrupt
if ((runStateAtLeast(ctl.get(), STOP) ||
(Thread.interrupted() &&
runStateAtLeast(ctl.get(), STOP))) &&
!wt.isInterrupted())
wt.interrupt();
try {
beforeExecute(wt, task);
Throwable thrown = null;
try {
task.run();
} catch (RuntimeException x) {
thrown = x; throw x;
} catch (Error x) {
thrown = x; throw x;
} catch (Throwable x) {
thrown = x; throw new Error(x);
} finally {
afterExecute(task, thrown);
}
} finally {
task = null;
w.completedTasks++;
w.unlock();
}
}
completedAbruptly = false;
} finally {
processWorkerExit(w, completedAbruptly);
}
}submit() est définie par sa classe parent abstraite. Ici, vous pouvez clairement voir la différence entre. submit et exécuter. En appelant submit, nous créerons RunnableFuture et retournerons Future. Ici, nous pouvons informer la méthode submit du type de valeur de retour, et elle transmettra la valeur de retour de contrainte générique. 🎜rrreee🎜🎜addWorker() est un moyen de recruter des personnes : 🎜🎜rrreee🎜🎜Comment obtenir des tâches : 🎜🎜rrreee🎜🎜Une façon de laisser les employés travailler, attribuer des tâches et exécuter des tâches : 🎜🎜rrreeeCe qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
















![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



