

Dans le passé, notre code Java utilisait HashMap pour certaines raisons, mais le programme à cette époque était monothread et tout allait bien. Plus tard, notre programme a eu des problèmes de performances, nous avons donc dû devenir multi-thread. Ainsi, après être devenu multi-thread, nous sommes allés en ligne et avons constaté que le programme occupait souvent 100 % du processeur. Vérifiez la pile et vous constaterez que le programme a des problèmes de performances. les programmes sont tous bloqués dans HashMap. La méthode .get() a été installée et le problème a disparu après le redémarrage du programme. Mais cela reviendra après un certain temps. De plus, ce problème peut être difficile à reproduire dans un environnement de test.
Si nous regardons simplement notre propre code, nous savons que HashMap est exploité par plusieurs threads. La documentation Java indique que HashMap n'est pas thread-safe et que ConcurrentHashMap doit être utilisé. Mais ici nous pouvons étudier les raisons. Le code simple est le suivant :
package com.king.hashmap;
import java.util.HashMap;
public class TestLock {
private HashMap map = new HashMap();
public TestLock() {
Thread t1 = new Thread() {
public void run() {
for ( int i = 0 ; i < 50000 ; i++) {
map.put( new Integer(i), i);
}
System.out.println( "t1 over" );
}
};
Thread t2 = new Thread() {
public void run() {
for ( int i = 0 ; i < 50000 ; i++) {
map.put( new Integer(i), i);
}
System.out.println( "t2 over" );
}
};
Thread t3 = new Thread() {
public void run() {
for ( int i = 0 ; i < 50000 ; i++) {
map.put( new Integer(i), i);
}
System.out.println( "t3 over" );
}
};
Thread t4 = new Thread() {
public void run() {
for ( int i = 0 ; i < 50000 ; i++) {
map.put( new Integer(i), i);
}
System.out.println( "t4 over" );
}
};
Thread t5 = new Thread() {
public void run() {
for ( int i = 0 ; i < 50000 ; i++) {
map.put( new Integer(i), i);
}
System.out.println( "t5 over" );
}
};
Thread t6 = new Thread() {
public void run() {
for ( int i = 0 ; i < 50000 ; i++) {
map.get( new Integer(i));
}
System.out.println( "t6 over" );
}
};
Thread t7 = new Thread() {
public void run() {
for ( int i = 0 ; i < 50000 ; i++) {
map.get( new Integer(i));
}
System.out.println( "t7 over" );
}
};
Thread t8 = new Thread() {
public void run() {
for ( int i = 0 ; i < 50000 ; i++) {
map.get( new Integer(i));
}
System.out.println( "t8 over" );
}
};
Thread t9 = new Thread() {
public void run() {
for ( int i = 0 ; i < 50000 ; i++) {
map.get( new Integer(i));
}
System.out.println( "t9 over" );
}
};
Thread t10 = new Thread() {
public void run() {
for ( int i = 0 ; i < 50000 ; i++) {
map.get( new Integer(i));
}
System.out.println( "t10 over" );
}
};
t1.start();
t2.start();
t3.start();
t4.start();
t5.start();
t6.start();
t7.start();
t8.start();
t9.start();
t10.start();
}
public static void main(String[] args) {
new TestLock();
}
}consiste à démarrer 10 threads et à mettre/obtenir continuellement du contenu dans un HashMap non thread-safe. Le contenu du put est très simple. La clé et la valeur sont toutes deux des nombres entiers qui augmentent à partir de 0. (cela a mis le contenu n'était pas très bon, ce qui a ensuite interféré avec ma réflexion sur l'analyse du problème). Lors de l'exécution d'opérations d'écriture simultanées sur HashMap, je pensais que cela ne produirait que des données sales. Cependant, si j'exécute ce programme à plusieurs reprises, les threads t1 et t2 seront bloqués. Dans la plupart des cas, un thread sera bloqué et l'autre se terminera avec succès. , parfois les 10 fils de discussion seront bloqués.
La cause première de cette boucle infinie réside dans le fonctionnement d'une variable partagée non protégée - une structure de données "HashMap". Après avoir ajouté « synchronisé » à toutes les méthodes de fonctionnement, tout est revenu à la normale. Est-ce un bug de JVM ? Il faut dire que non, ce phénomène est signalé depuis longtemps. Les ingénieurs de Sun ne pensent pas qu'il s'agisse d'un bug, mais suggèrent que "ConcurrentHashMap" soit utilisé dans un tel scénario.
L'utilisation excessive du processeur est généralement due à une boucle infinie, ce qui entraîne le maintien de certains threads et occupe du temps CPU. La cause du problème est que HashMap n'est pas thread-safe. Lorsque plusieurs threads sont installés, cela provoque une boucle infinie d'une certaine valeur de clé Entry key List, et le problème survient.
Lorsqu'un autre thread obtient la clé de cette boucle infinie Entry List, cette obtention sera toujours exécutée. Le résultat final est de plus en plus de threads dans une boucle infinie, provoquant finalement le crash du serveur. Nous pensons généralement que lorsqu'un HashMap insère une certaine valeur à plusieurs reprises, il écrasera la valeur précédente. C'est correct. Cependant, pour un accès multithread, en raison de son mécanisme d'implémentation interne (dans un environnement multithread et sans synchronisation, une opération put sur le même HashMap peut amener deux ou plusieurs threads à effectuer des opérations de rehash en même temps, ce qui peut conduire Si le tableau des clés circulaires apparaît, une fois que le thread ne peut pas être terminé et continue d'occuper le processeur, ce qui entraîne une utilisation élevée du processeur), des problèmes de sécurité peuvent survenir.
Utilisez l'outil jstack pour vider les informations de pile du serveur présentant le problème. S'il y a une boucle infinie, recherchez d'abord le thread de RUNNABLE et trouvez le code du problème comme suit :
java.lang.Thread.State:RUNNABLE
at java.util.HashMap.get(HashMap.java:303)
sur com.sohu.twap .service.logic.TransformTweeter.doTransformTweetT5(TransformTweeter.java:183)
Apparaît 23 fois au total.
java.lang.Thread.State:RUNNABLE
sur java.util.HashMap.put(HashMap.java:374)
sur com.sohu.twap.service.logic.TransformTweeter.transformT5(TransformTweeter.java:816)
Total Apparu 3 fois.
Remarque : Une mauvaise utilisation de HashMap entraîne une boucle infinie plutôt qu'une impasse.
Le problème principal réside dans la nouvelle entrée (hachage, clé, valeur, e) de la méthode addEntry. Si les deux threads obtiennent e en même temps, leur élément suivant le sera. be e , alors lors de l'attribution de valeurs aux éléments du tableau, l'un réussit et l'autre est perdu.
Le code dans la méthode de transfert est le suivant :
void transfer(Entry[] newTable) {
Entry[] src = table;
int newCapacity = newTable.length;
for ( int j = 0 ; j < src.length; j++) {
Entry e = src[j];
if (e != null ) {
src[j] = null ;
do {
Entry next = e.next;
int i = indexFor(e.hash, newCapacity);
e.next = newTable[i];
newTable[i] = e;
e = next;
} while (e != null );
}
}
}Dans cette méthode, assignez l'ancien tableau à src, traversez src, et lorsque l'élément de src n'est pas nul, il le sera. L'élément dans src est défini sur null, ce qui signifie que l'élément de l'ancien tableau est défini sur null, ce qui est cette phrase :
if (e != null ) {
src[j] = null ;S'il existe une méthode get pour accéder à cette clé à ce moment-là , il obtiendra toujours l'ancien tableau et, bien sûr, il ne pourra pas obtenir la valeur correspondante.
Résumé : lorsque HashMap n'est pas synchronisé, de nombreux problèmes subtils se produiront dans les programmes concurrents, et il est difficile d'en trouver la cause à la surface. Par conséquent, s’il y a un phénomène contre-intuitif lors de l’utilisation de HashMap, il peut être dû à la concurrence.
Je dois parler brièvement de la structure de données classique HashMap.
HashMap utilise généralement un tableau de pointeurs (supposé être une table[]) pour disperser toutes les clés lorsqu'une clé est ajoutée, l'indice i du tableau est calculé via la clé via l'algorithme de hachage, puis celui-ci est inséré dans In. table[i], si deux clés différentes sont comptées pour le même i, cela s'appelle un conflit, également appelé collision. Cela formera une liste chaînée sur table[i].
Nous savons que si la taille de la table[] est très petite, par exemple seulement 2, et si 10 clés doivent être insérées, les collisions seront très fréquentes, donc un algorithme de recherche O(1) devient un parcours de liste chaînée . La performance devient O(n), ce qui est un défaut de la table de hachage.
所以,Hash表的尺寸和容量非常的重要。一般来说,Hash表这个容器当有数据要插入时,都会检查容量有没有超过设定的thredhold,如果超过,需要增大Hash表的尺寸,但是这样一来,整个Hash表里的元素都需要被重算一遍。这叫rehash,这个成本相当的大。
下面,我们来看一下Java的HashMap的源代码。Put一个Key,Value对到Hash表中:
public V put(K key, V value)
{
......
//算Hash值
int hash = hash(key.hashCode());
int i = indexFor(hash, table.length);
//如果该key已被插入,则替换掉旧的value (链接操作)
for (Entry<K,V> e = table[i]; e != null ; e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess( this );
return oldValue;
}
}
modCount++;
//该key不存在,需要增加一个结点
addEntry(hash, key, value, i);
return null ;
}检查容量是否超标:
void addEntry( int hash, K key, V value, int bucketIndex)
{
Entry<K,V> e = table[bucketIndex];
table[bucketIndex] = new Entry<K,V>(hash, key, value, e);
//查看当前的size是否超过了我们设定的阈值threshold,如果超过,需要resize
if (size++ >= threshold)
resize( 2 * table.length);
}新建一个更大尺寸的hash表,然后把数据从老的Hash表中迁移到新的Hash表中。
void resize( int newCapacity)
{
Entry[] oldTable = table;
int oldCapacity = oldTable.length;
......
//创建一个新的Hash Table
Entry[] newTable = new Entry[newCapacity];
//将Old Hash Table上的数据迁移到New Hash Table上
transfer(newTable);
table = newTable;
threshold = ( int )(newCapacity * loadFactor);
}迁移的源代码,注意高亮处:
void transfer(Entry[] newTable)
{
Entry[] src = table;
int newCapacity = newTable.length;
//下面这段代码的意思是:
// 从OldTable里摘一个元素出来,然后放到NewTable中
for ( int j = 0 ; j < src.length; j++) {
Entry<K,V> e = src[j];
if (e != null ) {
src[j] = null ;
do {
Entry<K,V> next = e.next;
int i = indexFor(e.hash, newCapacity);
e.next = newTable[i];
newTable[i] = e;
e = next;
} while (e != null );
}
}
}好了,这个代码算是比较正常的。而且没有什么问题。
画了个图做了个演示。
我假设了我们的hash算法就是简单的用key mod 一下表的大小(也就是数组的长度)。
最上面的是old hash 表,其中的Hash表的size=2, 所以key = 3, 7, 5,在mod 2以后都冲突在table1这里了。
接下来的三个步骤是Hash表 resize成4,然后所有的 重新rehash的过程。
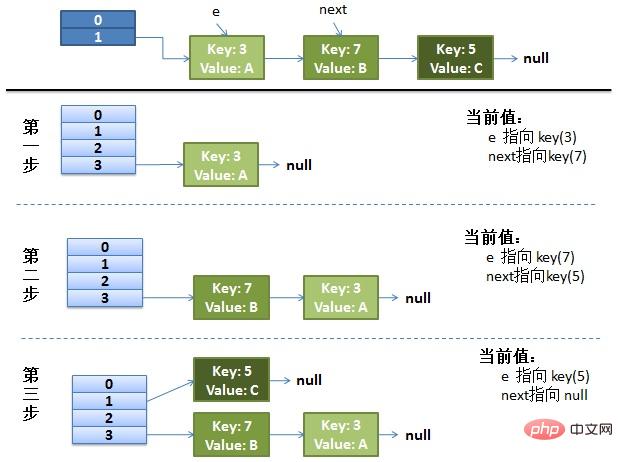
(1)假设我们有两个线程。我用红色和浅蓝色标注了一下。我们再回头看一下我们的 transfer代码中的这个细节:
do {
Entry<K,V> next = e.next; // <--假设线程一执行到这里就被调度挂起了
int i = indexFor(e.hash, newCapacity);
e.next = newTable[i];
newTable[i] = e;
e = next;
} while (e != null );而我们的线程二执行完成了。于是我们有下面的这个样子。
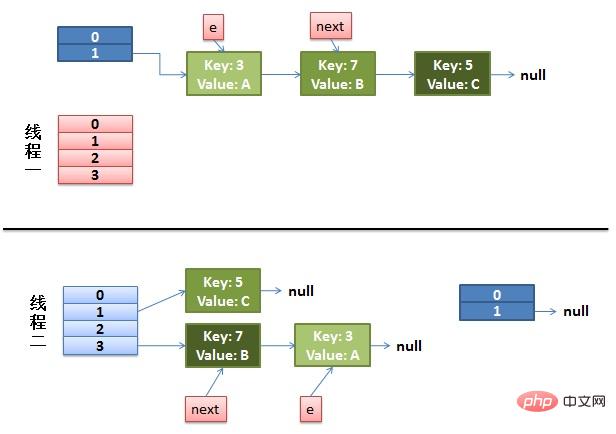
注意:因为Thread1的 e 指向了key(3),而next指向了key(7),其在线程二rehash后,指向了线程二重组后的链表。我们可以看到链表的顺序被反转后。
(2)线程一被调度回来执行。
先是执行 newTalbe[i] = e。
然后是e = next,导致了e指向了key(7)。
而下一次循环的next = e.next导致了next指向了key(3)。
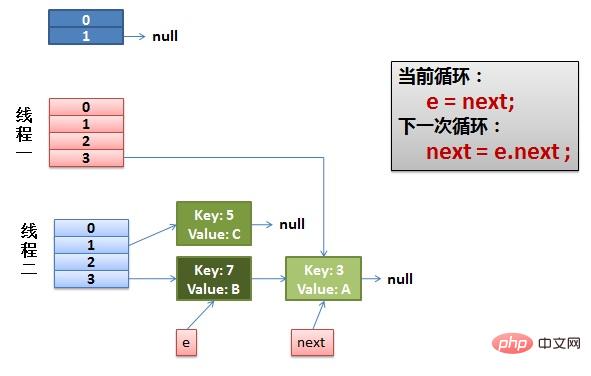
(3)一切安好。 线程一接着工作。把key(7)摘下来,放到newTable[i]的第一个,然后把e和next往下移。
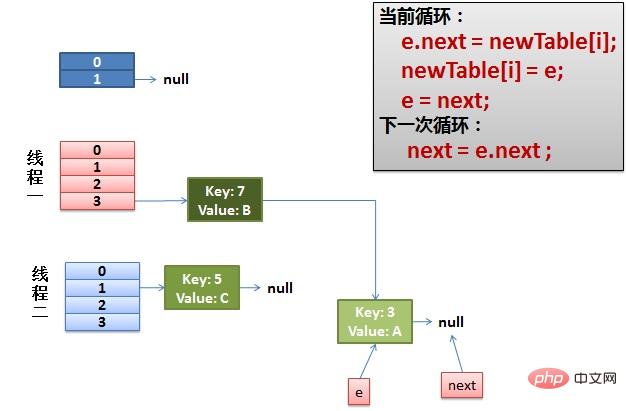
(4)环形链接出现。 e.next = newTable[i] 导致 key(3).next 指向了 key(7)。注意:此时的key(7).next 已经指向了key(3), 环形链表就这样出现了。
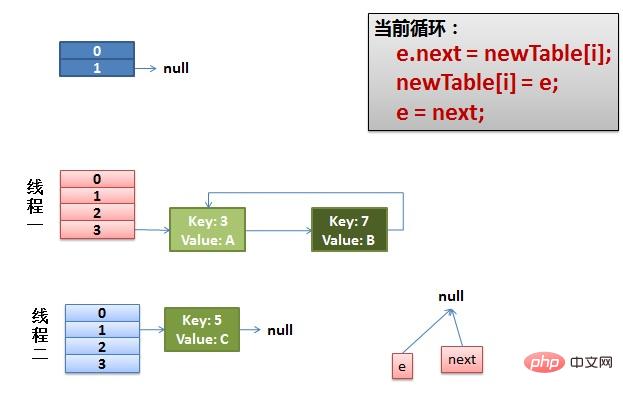
于是,当我们的线程一调用到,HashTable.get(11)时,悲剧就出现了——Infinite Loop。
Hashtable 是同步的,但由迭代器返回的 Iterator 和由所有 Hashtable 的“collection 视图方法”返回的 Collection 的 listIterator 方法都是快速失败的:在创建 Iterator 之后,如果从结构上对 Hashtable 进行修改,除非通过 Iterator 自身的移除或添加方法,否则在任何时间以任何方式对其进行修改,Iterator 都将抛出 ConcurrentModificationException。因此,面对并发的修改,Iterator 很快就会完全失败,而不冒在将来某个不确定的时间发生任意不确定行为的风险。由 Hashtable 的键和值方法返回的 Enumeration 不是快速失败的。
注意,迭代器的快速失败行为无法得到保证,因为一般来说,不可能对是否出现不同步并发修改做出任何硬性保证。快速失败迭代器会尽最大努力抛出 ConcurrentModificationException。因此,为提高这类迭代器的正确性而编写一个依赖于此异常的程序是错误做法:迭代器的快速失败行为应该仅用于检测程序错误。
返回由指定映射支持的同步(线程安全的)映射。为了保证按顺序访问,必须通过返回的映射完成对底层映射的所有访问。在返回的映射或其任意 collection 视图上进行迭代时,强制用户手工在返回的映射上进行同步:
Map m = Collections.synchronizedMap( new HashMap());
...
Set s = m.keySet(); // Needn't be in synchronized block
...
synchronized (m) { // Synchronizing on m, not s!
Iterator i = s.iterator(); // Must be in synchronized block
while (i.hasNext())
foo(i.next());
}不遵从此建议将导致无法确定的行为。如果指定映射是可序列化的,则返回的映射也将是可序列化的。
Une table de hachage qui prend en charge la simultanéité complète de la récupération et la simultanéité réglable souhaitée des mises à jour. Cette classe adhère à la même spécification fonctionnelle que Hashtable et comprend des versions de méthode correspondant à chaque méthode de Hashtable. Cependant, bien que toutes les opérations soient thread-safe, les opérations de récupération n'ont pas besoin d'être verrouillées et le verrouillage de la table entière de manière à empêcher tout accès n'est pas pris en charge. Cette classe peut être entièrement interopérable par programmation avec une table de hachage, en fonction de sa sécurité des threads, indépendamment de ses détails de synchronisation. Les opérations de récupération (y compris get) ne sont généralement pas bloquantes et peuvent donc chevaucher les opérations de mise à jour (y compris put et delete). La récupération affecte les résultats de l'opération de mise à jour la plus récente. Pour certaines opérations d'agrégation, telles que putAll et clear, la récupération simultanée peut uniquement affecter l'insertion et la suppression de certaines entrées. De même, les itérateurs et les énumérations renvoient les éléments qui ont affecté l'état de la table de hachage à un moment donné, soit au moment de la création de l'itérateur/de l'énumération, soit depuis. Ils ne lancent pas ConcurrentModificationException. Cependant, les itérateurs sont conçus pour être utilisés par un seul thread à la fois.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
















![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



