
 Périphériques technologiques
IA
Le cadre de détection de cible rapide et précis de YOLOv6 est open source
Périphériques technologiques
IA
Le cadre de détection de cible rapide et précis de YOLOv6 est open source
Le cadre de détection de cible rapide et précis de YOLOv6 est open source

Auteurs : Chu Yi, Kai Heng, etc.
Récemment, le département d'intelligence visuelle de Meituan a développé YOLOv6, un framework de détection de cibles dédié aux applications industrielles, qui peut se concentrer à la fois sur la précision de la détection et l'efficacité du raisonnement. Au cours du processus de recherche et développement, le département d’intelligence visuelle a continué à explorer et à optimiser, tout en s’appuyant sur certains développements de pointe et résultats de recherches scientifiques du monde universitaire et de l’industrie. Les résultats expérimentaux sur COCO, l'ensemble de données de détection de cibles faisant autorité, montrent que YOLOv6 surpasse les autres algorithmes de même taille en termes de précision et de vitesse de détection. Il prend également en charge le déploiement d'une variété de plates-formes différentes, simplifiant considérablement le travail d'adaptation lors du déploiement du projet. . Ceci est open source, dans l'espoir d'aider davantage d'étudiants.
1. Présentation
YOLOv6 est un framework de détection de cibles développé par le département d'intelligence visuelle de Meituan et dédié aux applications industrielles. Ce cadre se concentre à la fois sur la précision de la détection et sur l'efficacité de l'inférence. Parmi les modèles de taille couramment utilisés dans l'industrie : YOLOv6-nano a une précision allant jusqu'à 35,0 % AP sur COCO et une vitesse d'inférence allant jusqu'à 1242 FPS sur. La précision de T4 ; YOLOv6-s peut atteindre 43,1 % AP sur COCO, et sa vitesse d'inférence peut atteindre 520 FPS sur T4. En termes de déploiement, YOLOv6 prend en charge le déploiement de différentes plateformes telles que GPU (TensorRT), CPU (OPENVINO), ARM (MNN, TNN, NCNN), ce qui simplifie grandement le travail d'adaptation lors du déploiement du projet. Actuellement, le projet est open source sur Github, portail : YOLOv6. Les amis qui en ont besoin sont les bienvenus chez Star pour le récupérer et y accéder à tout moment.
Un nouveau cadre dont la précision et la vitesse dépassent de loin YOLOv5 et YOLOX
En tant que technologie de base dans le domaine de la vision par ordinateur, la détection de cibles a été largement utilisée dans l'industrie, parmi lesquelles les algorithmes de la série YOLO ont de meilleures performances globales, devenant progressivement le framework privilégié pour la plupart des applications industrielles. Jusqu'à présent, l'industrie a dérivé de nombreux cadres de détection YOLO, parmi lesquels YOLOv5[1], YOLOX[2] et PP-YOLOE[3] sont les plus représentatifs. Cependant, en utilisation réelle, nous avons constaté que. Avec les frameworks ci-dessus, il reste encore beaucoup à faire en termes de rapidité et de précision. Sur cette base, nous avons développé un nouveau cadre de détection de cibles - YOLOv6 en étudiant et en s'appuyant sur les technologies avancées existantes dans l'industrie. Le framework prend en charge la chaîne complète des exigences des applications industrielles telles que la formation de modèles, l'inférence et le déploiement multiplateforme, et a apporté un certain nombre d'améliorations et d'optimisations au niveau des algorithmes telles que la structure du réseau et les stratégies de formation sur l'ensemble de données COCO, YOLOv6. a à la fois précision et vitesse. Surpassant d'autres algorithmes de même taille, les résultats pertinents sont présentés dans la figure 1 ci-dessous :
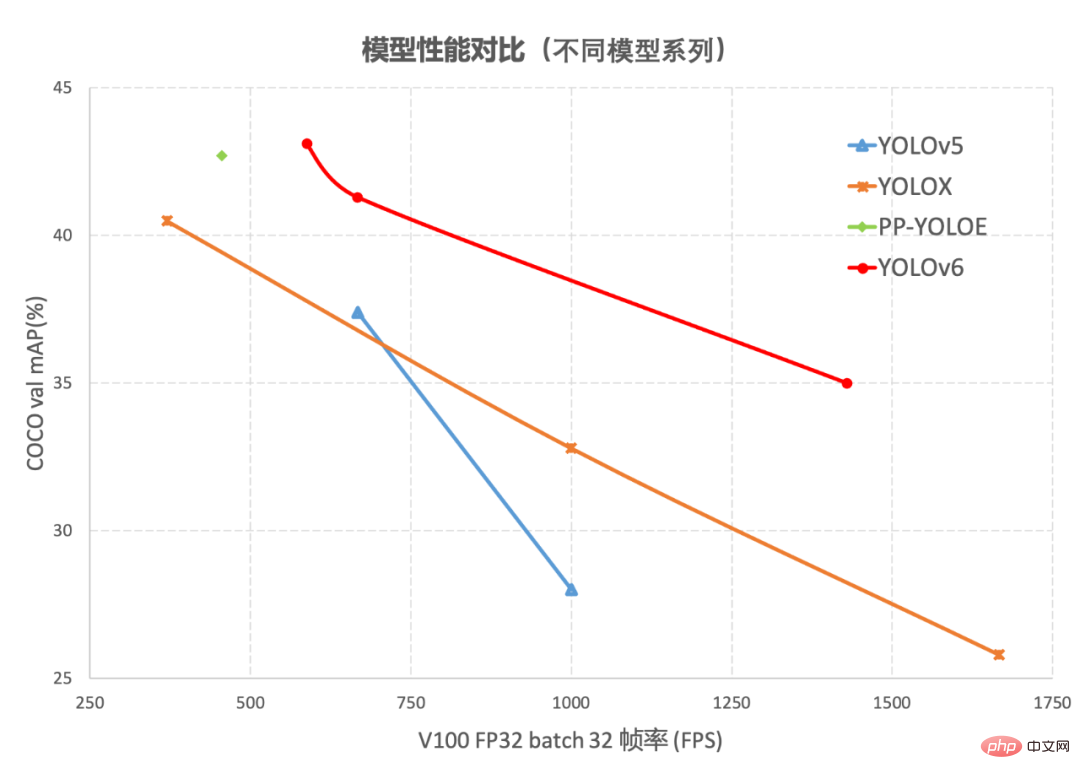
Figure 1-1 Comparaison des performances des modèles YOLOv6 de différentes tailles et d'autres modèles
.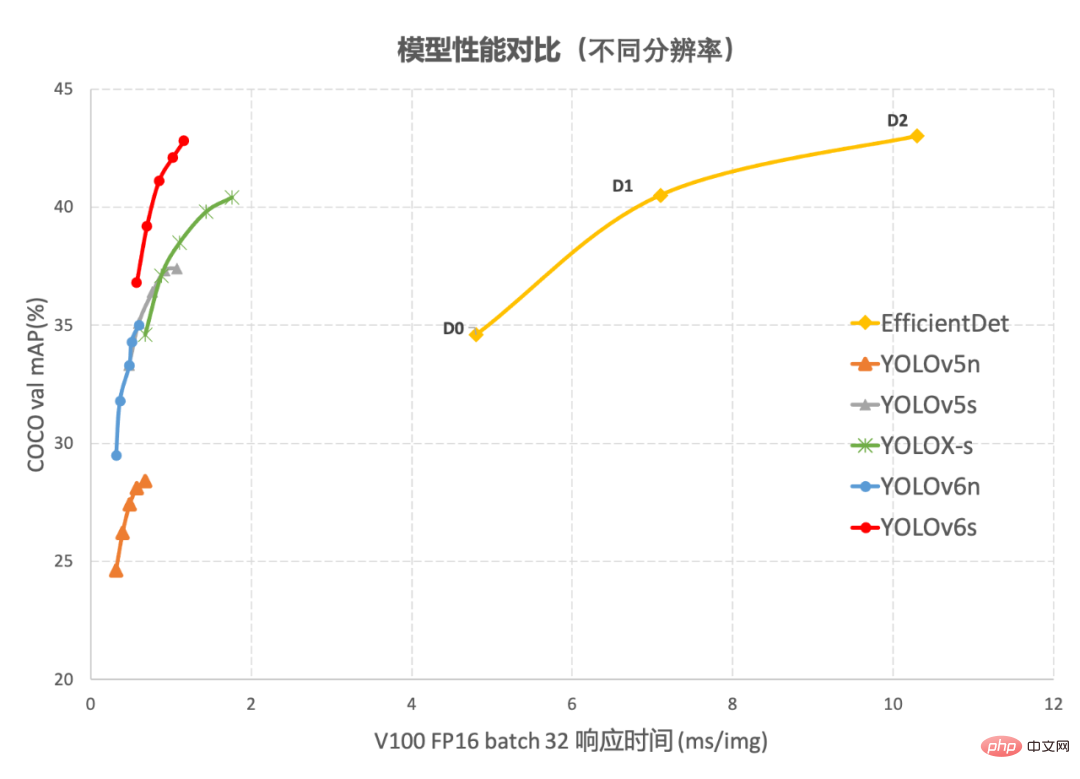
Figure 1-2 YOLOv6 Comparaison des performances avec d'autres modèles à différentes résolutions Figure 1-1 montre la comparaison des performances de chaque algorithme de détection sous des réseaux de différentes tailles. Les points sur la courbe représentent respectivement le. performances de l'algorithme de détection sous des réseaux de différentes tailles (s /tiny/nano), comme le montre la figure, YOLOv6 surpasse les autres algorithmes de la série YOLO de même taille en termes de précision et de vitesse. La figure 1-2 montre la comparaison des performances de chaque modèle de réseau de détection lorsque la résolution d'entrée change. Les points sur la courbe de gauche à droite représentent le moment où la résolution de l'image augmente séquentiellement (384/448/512/576/640). pour les performances de ce modèle, il ressort de la figure que YOLOv6 conserve toujours un grand avantage en termes de performances sous différentes résolutions.
2. Introduction aux technologies clés de YOLOv6
YOLOv6 a apporté de nombreuses améliorations principalement dans les stratégies de colonne vertébrale, de cou, de tête et d'entraînement :
- Nous avons conçu un Backbone et un Neck plus efficaces de manière unifiée : inspirés par les idées de conception des réseaux de neurones sensibles au matériel, nous avons conçu des réseaux backbone reparamétrables et plus efficaces, EfficientRep Backbone et Rep-PAN basés sur le style RepVGG[4 ] Cou.
- Optimisé et conçu une tête découplée efficace plus concise et efficace, qui réduit encore les frais de retard supplémentaires causés par les têtes découplées générales tout en maintenant la précision.
- En termes de stratégie de formation, nous utilisons le paradigme sans ancre sans ancre, complété par SimOTA[2] stratégie d'attribution d'étiquettes et SIoU[9] perte de régression de la boîte englobante pour améliorer encore la précision de la détection.
2.1 Conception de réseau fédérateur conviviale pour le matériel
Le Backbone et le Neck utilisés par YOLOv5/YOLOX sont tous deux construits sur CSPNet[5], en utilisant une approche multi-branches et une structure résiduelle. Pour le matériel tel que les GPU, cette structure augmentera la latence dans une certaine mesure et réduira l'utilisation de la bande passante mémoire. La figure 2 ci-dessous est une introduction au modèle Roofline[8] dans le domaine de l'architecture informatique, montrant la relation entre la puissance de calcul et la bande passante mémoire dans le matériel.
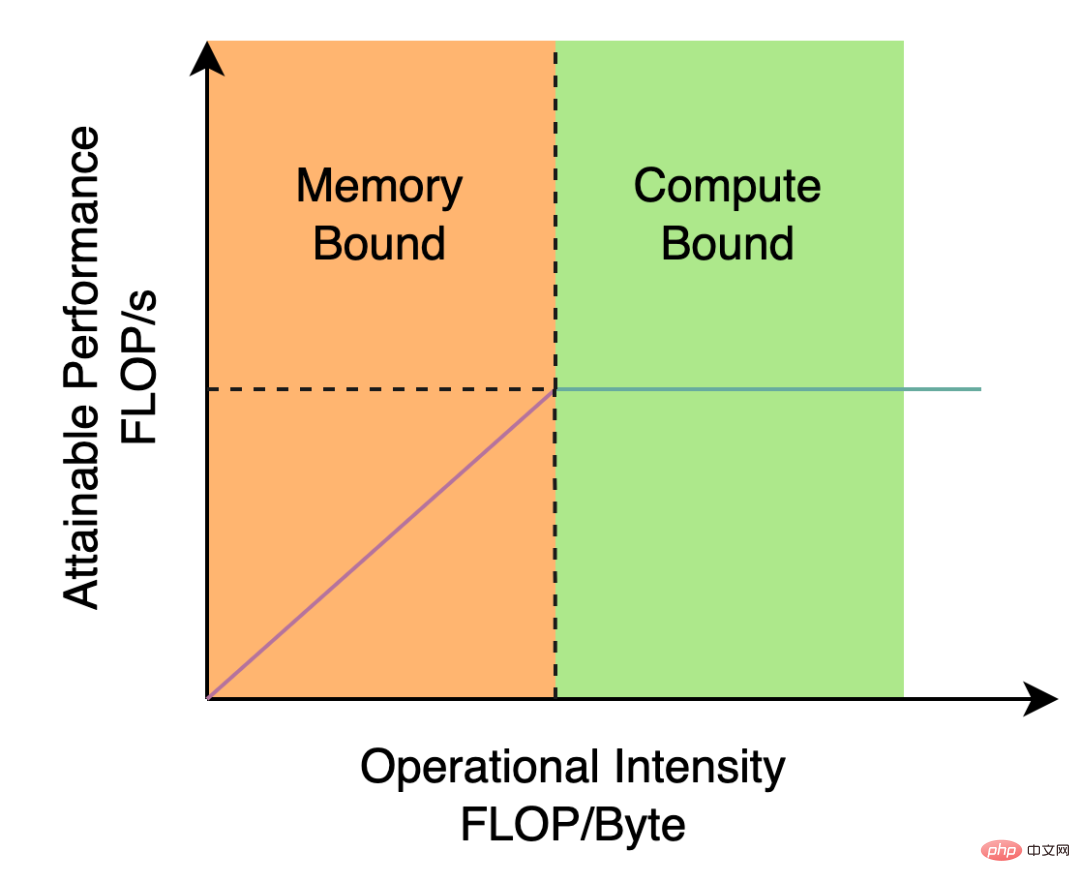
Figure 2 Diagramme d'introduction du modèle de ligne de toit
Nous avons donc repensé et optimisé Backbone et Neck sur la base de l'idée de conception de réseau neuronal sensible au matériel. Cette idée est basée sur les caractéristiques du matériel et les caractéristiques du cadre d'inférence/cadre de compilation. Elle prend le matériel et la structure conviviale comme principe de conception lors de la construction du réseau, elle prend en compte de manière globale la puissance de calcul du matériel et la bande passante mémoire. , caractéristiques d'optimisation de la compilation, capacités de représentation du réseau, etc., puis obtenez une structure de réseau rapide et bonne. Pour les deux composants de détection repensés ci-dessus, nous les appelons respectivement EfficientRep Backbone et Rep-PAN Neck dans YOLOv6. Leurs principales contributions sont :
- Introduction de la structure de style RepVGG[4].
- Backbone et Neck sont repensés sur la base de l'idée de prise en compte du matériel.
RepVGG[4] La structure Style est une structure reparamétrable qui a une topologie multi-branches pendant la formation et peut être fusionnée de manière équivalente en une seule convolution 3x3 lors du déploiement réel (Fusion Le processus est illustré dans la figure 3 ci-dessous). Grâce à la structure de convolution fusionnée 3x3, la puissance de calcul du matériel informatique intensif (tel que le GPU) peut être utilisée efficacement, et l'aide des frameworks de compilation NVIDIA cuDNN et Intel MKL qui ont été hautement optimisés sur GPU/CPU peut également être obtenue. .
Les expériences montrent que grâce à la stratégie ci-dessus, YOLOv6 réduit les retards matériels et améliore considérablement la précision de l'algorithme, rendant le réseau de détection plus rapide et plus fort. En prenant le modèle nanométrique comme exemple, par rapport à la structure de réseau utilisée par YOLOv5-nano, cette méthode améliore la vitesse de 21 % et augmente la précision de 3,6 % AP.
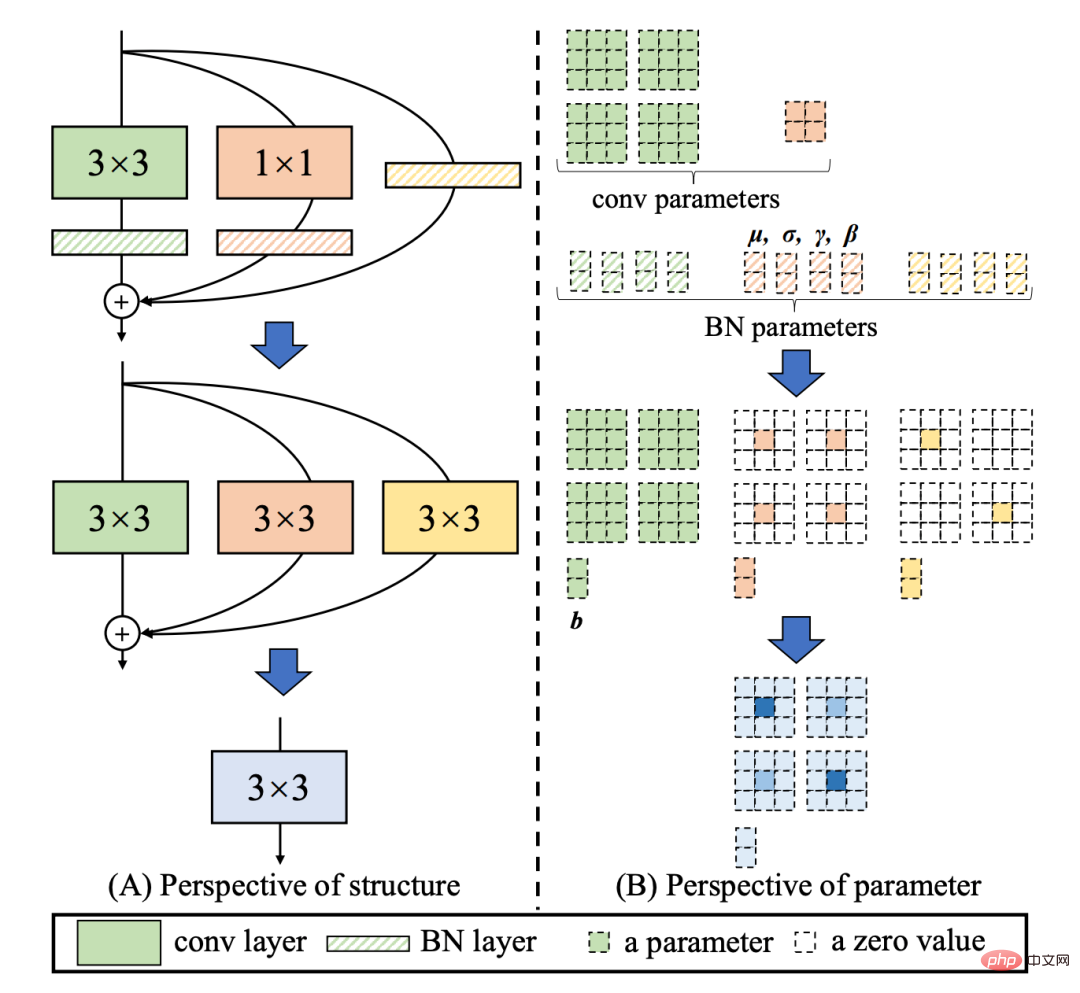
Figure 3 Processus de fusion de l'opérateur Rep [4]
EfficientRep Backbone : En termes de conception du Backbone, nous avons conçu un Backbone efficace basé sur l'opérateur Rep ci-dessus. Comparé au CSP-Backbone utilisé dans YOLOv5, ce Backbone peut utiliser efficacement la puissance de calcul du matériel (tel que le GPU) et possède également de fortes capacités de représentation.
La figure 4 ci-dessous est le diagramme de structure de conception spécifique d'EfficientRep Backbone. Nous avons remplacé la couche Conv ordinaire par stride=2 dans Backbone par la couche RepConv avec stride=2. Dans le même temps, le CSP-Block d'origine est repensé en RepBlock, où le premier RepConv de RepBlock transformera et alignera la dimension du canal. De plus, nous optimisons le SPPF d'origine pour en faire un SimSPPF plus efficace.
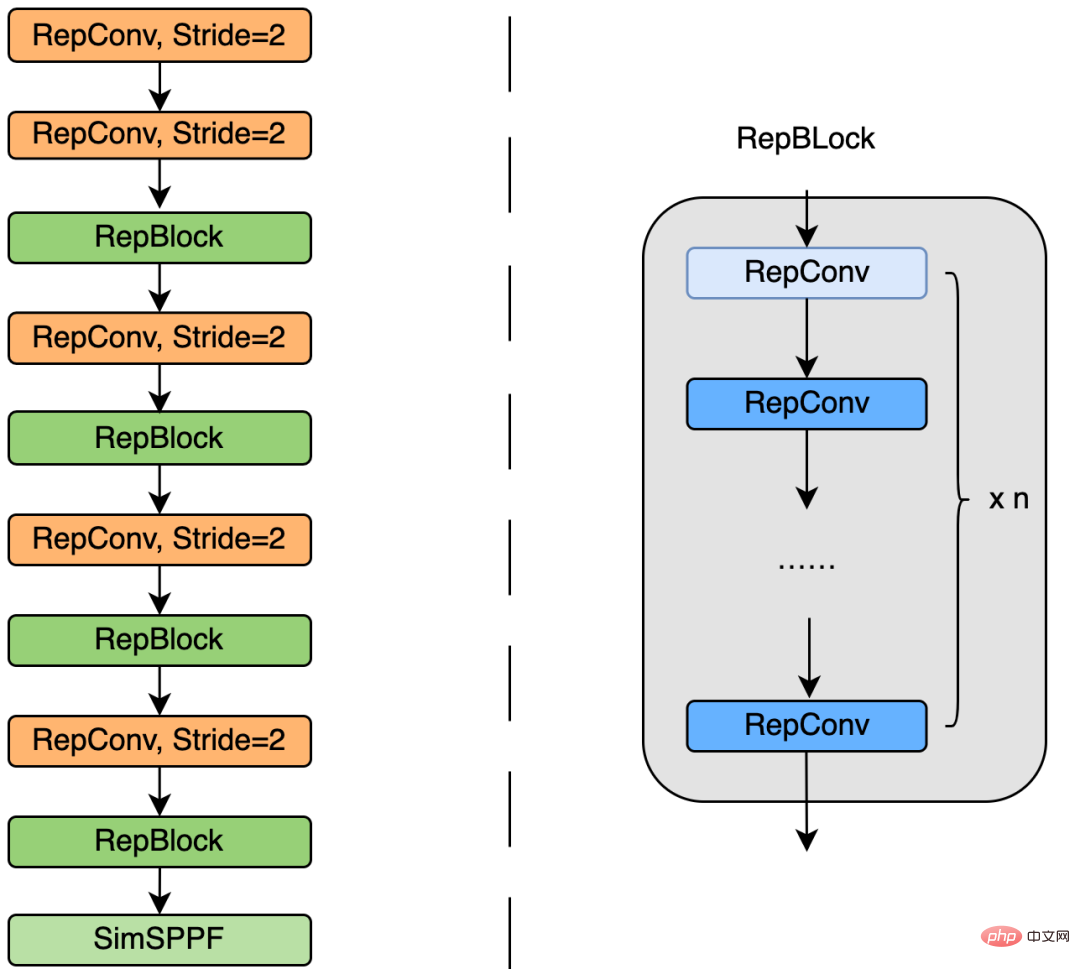
Figure 4 Schéma de la structure EfficientRep Backbone
Rep-PAN : En termes de conception du cou, afin de rendre son raisonnement sur le matériel plus efficace pour obtenir un meilleur équilibre entre précision et vitesse, Nous sommes basés sur l'idée de conception de réseau neuronal sensible au matériel, une structure de réseau de fusion de fonctionnalités plus efficace est conçue pour YOLOv6.
Rep-PAN est basé sur la topologie PAN[6], utilisant RepBlock pour remplacer le CSP-Block utilisé dans YOLOv5, et en même temps ajustant les opérateurs dans le Neck global, afin d'obtenir un raisonnement efficace sur le le matériel maintient de bonnes capacités de fusion de fonctionnalités multi-échelles (Le diagramme de structure Rep-PAN est illustré dans la figure 5 ci-dessous).
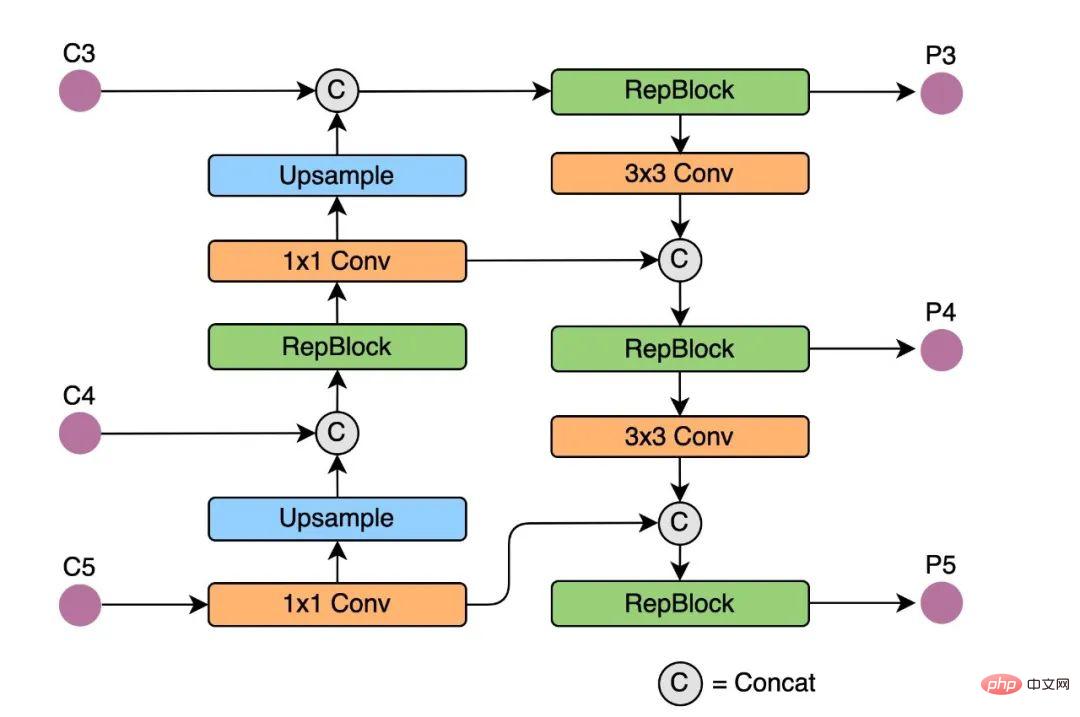
Figure 5 Diagramme de structure Rep-PAN
2.2 Tête découplée plus concise et efficace
Dans YOLOv6, nous adoptons la structure de la tête de détection découplée (Tête découplée) et la réalisons avec une conception simplifiée. La tête de détection du YOLOv5 d'origine est implémentée en fusionnant et partageant les branches de classification et de régression, tandis que la tête de détection de YOLOX découple les branches de classification et de régression et ajoute deux couches convolutives 3x3 supplémentaires, bien que la précision de détection soit améliorée, mais le réseau. le retard est augmenté dans une certaine mesure.
Par conséquent, nous avons rationalisé la conception de la tête de découplage, en tenant compte de l'équilibre entre les capacités de représentation des opérateurs associées et la surcharge informatique matérielle, et avons repensé une tête de découplage plus efficace en utilisant la stratégie des canaux hybrides. La structure réduit le délai tout en maintenant la précision. , et atténue la surcharge de retard supplémentaire causée par la convolution 3x3 dans la tête de découplage. En menant des expériences d'ablation sur des modèles nanométriques et en comparant les structures de tête de découplage avec le même nombre de canaux, la précision est augmentée de 0,2 % AP et la vitesse est augmentée de 6,8 %.
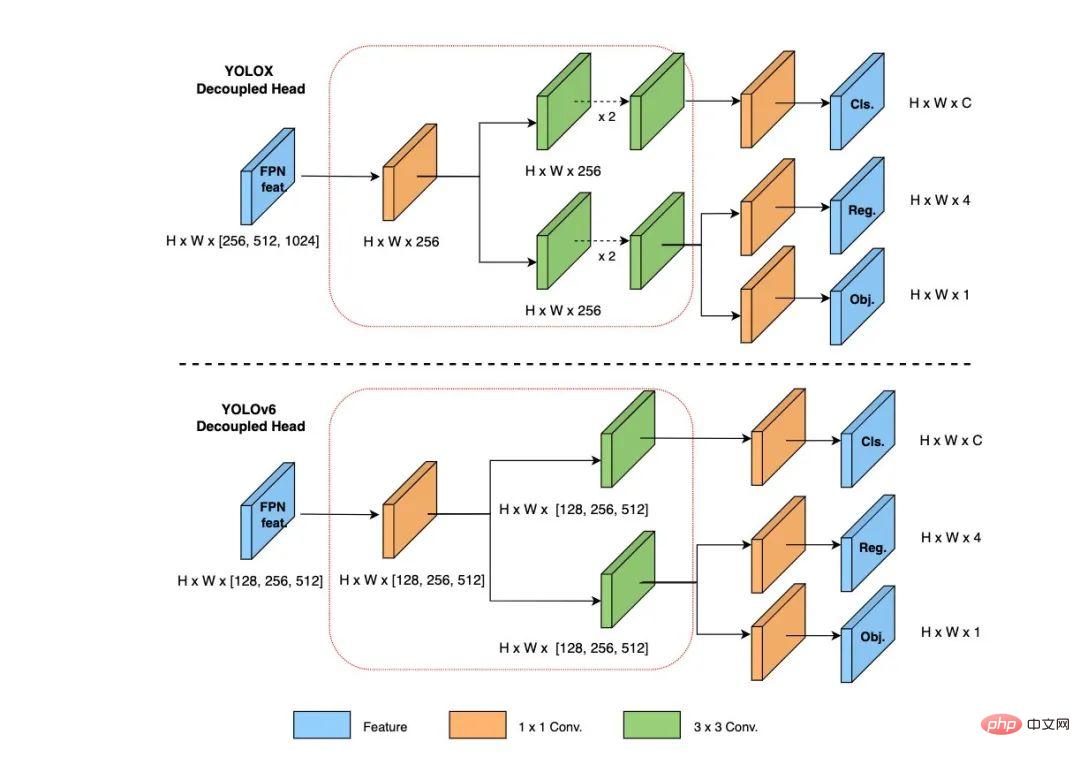
Figure 6 Schéma de structure efficace de la tête découplée
2.3 Stratégie de formation plus efficace
Afin d'améliorer encore la précision de la détection, nous avons absorbé et appris des progrès de la recherche avancée d'autres cadres de détection dans le monde universitaire et industrie : paradigme sans ancre et sans ancre, stratégie d'attribution d'étiquettes SimOTA et perte de régression du cadre de délimitation SIoU.
Paradigme sans ancre sans ancre
YOLOv6 adopte une méthode de détection sans ancre plus concise. Étant donné que les détecteurs basés sur Anchor doivent effectuer une analyse de cluster avant la formation pour déterminer l'ensemble d'ancrage optimal, cela augmentera la complexité du détecteur dans une certaine mesure, en même temps, dans certaines applications de pointe, un grand nombre de résultats de détection doivent être obtenus ; être transporté entre les étapes matérielles entraînera également des retards supplémentaires. Le paradigme sans ancre sans ancre a été largement utilisé ces dernières années en raison de sa forte capacité de généralisation et de sa logique de décodage plus simple. Après des recherches expérimentales sur Anchor-free, nous avons constaté que par rapport au retard supplémentaire causé par la complexité du détecteur basé sur Anchor, le détecteur Anchor-free présente une amélioration de 51 % en termes de vitesse.
Stratégie d'attribution d'étiquettes SimOTA
Afin d'obtenir davantage d'échantillons positifs de haute qualité, YOLOv6 introduit l'algorithme SimOTA [4] pour attribuer dynamiquement des échantillons positifs afin d'améliorer encore la précision de la détection. La stratégie d'allocation d'étiquettes de YOLOv5 est basée sur la correspondance de forme et augmente le nombre d'échantillons positifs grâce à la stratégie de correspondance entre grilles, faisant ainsi converger rapidement le réseau. Cependant, cette méthode est une méthode d'allocation statique et ne sera pas ajustée avec la. processus de formation du réseau.
Ces dernières années, de nombreuses méthodes basées sur l'attribution dynamique d'étiquettes ont vu le jour. De telles méthodes alloueront des échantillons positifs en fonction de la sortie du réseau pendant le processus de formation, générant ainsi davantage d'échantillons positifs de haute qualité, ce qui favorise la progression du réseau. optimisation. Par exemple, OTA[7] modélise l'appariement d'échantillons comme un problème de transmission optimal et obtient la meilleure stratégie d'appariement d'échantillons sous informations globales pour améliorer la précision. Cependant, OTA utilise l'algorithme Sinkhorn-Knopp, ce qui entraîne un temps de formation plus long. [4] L'algorithme utilise la stratégie d'approximation Top-K pour obtenir la meilleure correspondance de l'échantillon, ce qui accélère considérablement la formation. Par conséquent, YOLOv6 adopte la stratégie d'allocation dynamique SimOTA et la combine avec le paradigme sans ancre pour augmenter la précision de détection moyenne de 1,3 % AP sur le modèle nanométrique.
Perte de régression de la boîte englobante SIoU
Afin d'améliorer encore la précision de la régression, YOLOv6 utilise SIoU[9]fonction de perte de régression de la boîte englobante pour superviser l'apprentissage du réseau. La formation des réseaux de détection de cibles nécessite généralement la définition d'au moins deux fonctions de perte : la perte de classification et la perte de régression de la boîte englobante, et la définition de la fonction de perte a souvent un impact plus important sur la précision de la détection et la vitesse de formation.
Ces dernières années, les pertes de régression de boîte englobante couramment utilisées incluent la perte IoU, GIoU, CIoU, DIoU, etc. Ces fonctions de perte mesurent la boîte de prédiction et la boîte cible en tenant compte de facteurs tels que le degré de chevauchement, la distance du point central et rapport hauteur/largeur. L'écart entre eux peut guider le réseau pour minimiser la perte afin d'améliorer la précision de la régression, mais ces méthodes ne prennent pas en compte la correspondance de la direction entre la boîte de prédiction et la boîte cible. La fonction de perte SIoU redéfinit la perte de distance en introduisant l'angle vectoriel entre les régressions requises, réduisant ainsi efficacement le degré de liberté de régression, accélérant la convergence du réseau et améliorant encore la précision de la régression. En utilisant la perte SIoU pour les expériences sur les YOLOv6, par rapport à la perte CIoU, la précision de détection moyenne est augmentée de 0,3 % AP.
3. Résultats expérimentaux
Après les stratégies d'optimisation et les améliorations ci-dessus, YOLOv6 a atteint d'excellentes performances dans plusieurs modèles de différentes tailles. Le tableau 1 ci-dessous montre les résultats expérimentaux d'ablation de YOLOv6-nano. D'après les résultats expérimentaux, nous pouvons voir que notre réseau de détection auto-conçu a apporté de grands gains en termes de précision et de rapidité. 
Tableau 1 Résultats expérimentaux de YOLOv6-nano ablation Le tableau 2 ci-dessous montre les résultats expérimentaux de YOLOv6 par rapport à d'autres algorithmes de la série YOLO actuellement courants. Comme le montre le tableau :
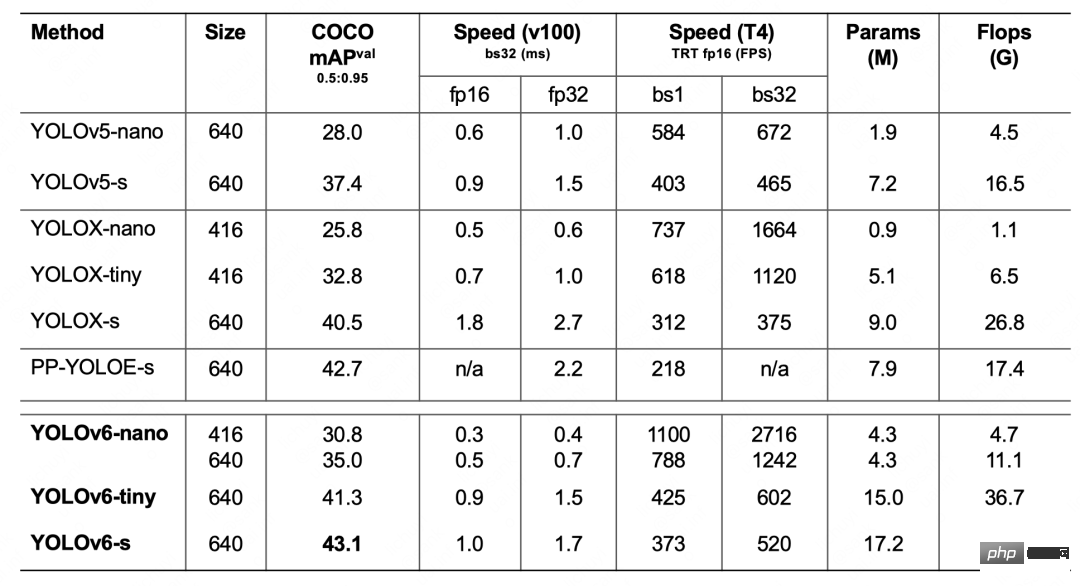
Tableau 2 Comparaison des performances des modèles YOLOv6 de différentes tailles avec d'autres modèles
- YOLOv6-nano a atteint une précision de 35,0% AP sur COCO val, et en même temps sur T4 L'utilisation de TRT FP16 batchsize=32 pour l'inférence peut atteindre une performance de 1242FPS Par rapport à YOLOv5-nano, la précision est augmentée de 7 % AP et la vitesse est augmentée de 85 %.
- YOLOv6-tiny a atteint une précision de 41,3 % AP sur COCO val. Dans le même temps, en utilisant TRT FP16 batchsize=32 pour l'inférence sur T4, il peut atteindre une performance de 602 FPS par rapport à YOLOv5-s, la précision. est amélioré de 3,9% AP Vitesse augmentée de 29,4%.
- YOLOv6-s a atteint une précision de 43,1% AP sur COCO val. Dans le même temps, en utilisant TRT FP16 batchsize=32 pour l'inférence sur T4, il peut atteindre une performance de 520FPS par rapport à YOLOX-s, la précision. est amélioré de 2,6 % AP. La vitesse est augmentée de 38,6 % par rapport aux PP-YOLOE-s, la précision est augmentée de 0,4 % AP, et le TRT FP16 est utilisé sur T4 pour l'inférence en un seul lot, et la vitesse est améliorée. augmenté de 71,3%.
4. Résumé et perspectives
Cet article présente l'optimisation et l'expérience pratique du département d'intelligence visuelle de Meituan dans le cadre de détection de cibles, en termes de stratégie de formation, de réseau principal et. la fusion de fonctionnalités multi-échelles, la détection d'abord et d'autres aspects ont été pensés et optimisés, et un nouveau cadre de détection-YOLOv6 a été conçu. L'intention initiale est venue de résoudre des problèmes pratiques rencontrés lors de la mise en œuvre d'applications industrielles.
Lors de la construction du framework YOLOv6, nous avons exploré et optimisé de nouvelles méthodes, telles que EfficientRep Backbone, Rep-Neck et Efficient Decoupled Head, basées sur des idées de conception de réseaux neuronaux sensibles au matériel, et également absorbées et apprises du monde universitaire. . et quelques avancées et résultats de pointe dans l'industrie, tels que la perte de régression sans ancre, SimOTA et SIoU. Les résultats expérimentaux sur l'ensemble de données COCO montrent que YOLOv6 est parmi les meilleurs en termes de précision et de vitesse de détection.
À l'avenir, nous continuerons à construire et à améliorer l'écosystème YOLOv6. Le travail principal comprend les aspects suivants :
- Améliorer la gamme complète des modèles YOLOv6 et continuer à améliorer les performances de détection.
- Concevez des modèles conviviaux sur plusieurs plates-formes matérielles.
- Prend en charge l'adaptation de la chaîne complète telle que le déploiement de la plateforme ARM et la distillation quantitative.
- Développer horizontalement et introduire des technologies connexes, telles que l'apprentissage semi-supervisé, auto-supervisé, etc.
- Explorez les performances de généralisation de YOLOv6 dans des scénarios commerciaux plus inconnus.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Dix outils d'annotation de texte gratuits open source recommandés
Mar 26, 2024 pm 08:20 PM
Dix outils d'annotation de texte gratuits open source recommandés
Mar 26, 2024 pm 08:20 PM
L'annotation de texte est le travail d'étiquettes ou de balises correspondant à un contenu spécifique dans le texte. Son objectif principal est d’apporter des informations complémentaires au texte pour une analyse et un traitement plus approfondis, notamment dans le domaine de l’intelligence artificielle. L'annotation de texte est cruciale pour les tâches d'apprentissage automatique supervisées dans les applications d'intelligence artificielle. Il est utilisé pour entraîner des modèles d'IA afin de mieux comprendre les informations textuelles en langage naturel et d'améliorer les performances de tâches telles que la classification de texte, l'analyse des sentiments et la traduction linguistique. Grâce à l'annotation de texte, nous pouvons apprendre aux modèles d'IA à reconnaître les entités dans le texte, à comprendre le contexte et à faire des prédictions précises lorsque de nouvelles données similaires apparaissent. Cet article recommande principalement de meilleurs outils d'annotation de texte open source. 1.LabelStudiohttps://github.com/Hu
 15 outils d'annotation d'images gratuits open source recommandés
Mar 28, 2024 pm 01:21 PM
15 outils d'annotation d'images gratuits open source recommandés
Mar 28, 2024 pm 01:21 PM
L'annotation d'images est le processus consistant à associer des étiquettes ou des informations descriptives à des images pour donner une signification et une explication plus profondes au contenu de l'image. Ce processus est essentiel à l’apprentissage automatique, qui permet d’entraîner les modèles de vision à identifier plus précisément les éléments individuels des images. En ajoutant des annotations aux images, l'ordinateur peut comprendre la sémantique et le contexte derrière les images, améliorant ainsi la capacité de comprendre et d'analyser le contenu de l'image. L'annotation d'images a un large éventail d'applications, couvrant de nombreux domaines, tels que la vision par ordinateur, le traitement du langage naturel et les modèles de vision graphique. Elle a un large éventail d'applications, telles que l'assistance aux véhicules pour identifier les obstacles sur la route, en aidant à la détection. et le diagnostic des maladies grâce à la reconnaissance d'images médicales. Cet article recommande principalement de meilleurs outils d'annotation d'images open source et gratuits. 1.Makesens
 Comment obtenir le comptoir à emporter Meituan
Apr 08, 2024 pm 03:41 PM
Comment obtenir le comptoir à emporter Meituan
Apr 08, 2024 pm 03:41 PM
1. Lorsque le livreur place le repas dans le placard, il informera le client de récupérer le repas par SMS, appel téléphonique ou message Meituan. 2. Les clients peuvent scanner le code QR sur l'armoire alimentaire via WeChat ou Meituan APP pour accéder à l'applet de l'armoire alimentaire intelligente. 3. Entrez le code de retrait ou utilisez la fonction « ouverture de l'armoire en un clic » pour ouvrir facilement la porte de l'armoire et sortir les plats à emporter.
 Comment récupérer le mot de passe de paiement oublié de Meituan_Comment récupérer le mot de passe de paiement oublié de Meituan
Mar 28, 2024 pm 03:29 PM
Comment récupérer le mot de passe de paiement oublié de Meituan_Comment récupérer le mot de passe de paiement oublié de Meituan
Mar 28, 2024 pm 03:29 PM
1. Tout d'abord, nous entrons dans le logiciel Meituan, recherchons les paramètres sur la page Mon menu et cliquons pour accéder aux paramètres. 2. Ensuite, nous trouvons les paramètres de paiement sur la page des paramètres et cliquons pour entrer les paramètres de paiement. 3. Entrez dans le centre de paiement, recherchez le paramètre de mot de passe de paiement et cliquez pour saisir le paramètre de mot de passe de paiement. 4. Dans la page de configuration du mot de passe de paiement, recherchez la récupération du mot de passe de paiement et cliquez pour accéder à l'option de la page. 5. Entrez les informations du mot de passe de paiement que vous souhaitez récupérer, cliquez sur Vérifier et vous pourrez récupérer le mot de passe de paiement après l'avoir transmis.
 Recommandé : Excellent projet de détection et de reconnaissance des visages open source JS
Apr 03, 2024 am 11:55 AM
Recommandé : Excellent projet de détection et de reconnaissance des visages open source JS
Apr 03, 2024 am 11:55 AM
La technologie de détection et de reconnaissance des visages est déjà une technologie relativement mature et largement utilisée. Actuellement, le langage d'application Internet le plus utilisé est JS. La mise en œuvre de la détection et de la reconnaissance faciale sur le front-end Web présente des avantages et des inconvénients par rapport à la reconnaissance faciale back-end. Les avantages incluent la réduction de l'interaction réseau et de la reconnaissance en temps réel, ce qui réduit considérablement le temps d'attente des utilisateurs et améliore l'expérience utilisateur. Les inconvénients sont les suivants : il est limité par la taille du modèle et la précision est également limitée ; Comment utiliser js pour implémenter la détection de visage sur le web ? Afin de mettre en œuvre la reconnaissance faciale sur le Web, vous devez être familier avec les langages et technologies de programmation associés, tels que JavaScript, HTML, CSS, WebRTC, etc. Dans le même temps, vous devez également maîtriser les technologies pertinentes de vision par ordinateur et d’intelligence artificielle. Il convient de noter qu'en raison de la conception du côté Web
 Où puis-je changer mon adresse Meituan ? Tutoriel de modification d'adresse Meituan !
Mar 15, 2024 pm 04:07 PM
Où puis-je changer mon adresse Meituan ? Tutoriel de modification d'adresse Meituan !
Mar 15, 2024 pm 04:07 PM
1. Où puis-je changer mon adresse Meituan ? Tutoriel de modification d'adresse Meituan ! Méthode (1) 1. Entrez Meituan My Page et cliquez sur Paramètres. 2. Sélectionnez les informations personnelles. 3. Cliquez à nouveau sur l'adresse de livraison. 4. Enfin, sélectionnez l'adresse que vous souhaitez modifier, cliquez sur l'icône en forme de stylo à droite de l'adresse et modifiez-la. Méthode (2) 1. Sur la page d'accueil de l'application Meituan, cliquez sur Takeout, puis cliquez sur Plus de fonctions après avoir entré. 2. Dans l'interface Plus, cliquez sur Gérer l'adresse. 3. Dans l'interface Mon adresse de livraison, sélectionnez Modifier. 4. Modifiez-les une à une selon vos besoins, et enfin cliquez pour enregistrer l'adresse.
 Comment supprimer les avis sur Meituan Comment supprimer les avis
Mar 12, 2024 pm 07:31 PM
Comment supprimer les avis sur Meituan Comment supprimer les avis
Mar 12, 2024 pm 07:31 PM
Lorsque nous utilisons cette plateforme, il existe également des avis sur divers aspects de l'alimentation et de la consommation. Certaines méthodes de fonctionnement sont également extrêmement simples. Lorsque nous allons consommer, nous devrions pouvoir voir les avis sur celle-ci. et évalués par nous-mêmes. Cependant, nous devons parfois supprimer nous-mêmes les mauvaises évaluations sur certains magasins, mais les utilisateurs ne savent pas comment faire ces évaluations, c'est pourquoi je vais vous donner une explication détaillée de certaines des fonctions ci-dessus dans l'éditeur d'aujourd'hui. si vous avez des idées, aujourd'hui l'éditeur vous expliquera en détail comment le supprimer. Si vous êtes intéressé, venez jeter un œil avec l'éditeur maintenant. Je pense que tout le monde devrait tous en savoir quelque chose, ne le faites pas. ça me manque. Supprimer
 Le document multimodal Alibaba 7B comprenant le grand modèle remporte le nouveau SOTA
Apr 02, 2024 am 11:31 AM
Le document multimodal Alibaba 7B comprenant le grand modèle remporte le nouveau SOTA
Apr 02, 2024 am 11:31 AM
Nouveau SOTA pour des capacités de compréhension de documents multimodaux ! L'équipe Alibaba mPLUG a publié le dernier travail open source mPLUG-DocOwl1.5, qui propose une série de solutions pour relever les quatre défis majeurs que sont la reconnaissance de texte d'image haute résolution, la compréhension générale de la structure des documents, le suivi des instructions et l'introduction de connaissances externes. Sans plus tarder, examinons d’abord les effets. Reconnaissance et conversion en un clic de graphiques aux structures complexes au format Markdown : Des graphiques de différents styles sont disponibles : Une reconnaissance et un positionnement de texte plus détaillés peuvent également être facilement traités : Des explications détaillées sur la compréhension du document peuvent également être données : Vous savez, « Compréhension du document " est actuellement un scénario important pour la mise en œuvre de grands modèles linguistiques. Il existe de nombreux produits sur le marché pour aider à la lecture de documents. Certains d'entre eux utilisent principalement des systèmes OCR pour la reconnaissance de texte et coopèrent avec LLM pour le traitement de texte.
