
 Périphériques technologiques
IA
Flying Paddle est conçu et pratiqué pour le parallélisme automatique dans des scénarios hétérogènes.
Périphériques technologiques
IA
Flying Paddle est conçu et pratiqué pour le parallélisme automatique dans des scénarios hétérogènes.
Flying Paddle est conçu et pratiqué pour le parallélisme automatique dans des scénarios hétérogènes.


1. Introduction générale
Avant d'introduire le parallélisme automatique, réfléchissons à la raison pour laquelle le parallélisme automatique est nécessaire ? D’une part, il existe différentes structures de modèles, et d’autre part, il existe diverses stratégies parallèles. Il existe généralement une relation de cartographie plusieurs à plusieurs. En supposant que nous puissions mettre en œuvre une structure de modèle unifiée pour répondre aux diverses exigences des tâches, notre stratégie parallèle parviendra-t-elle à converger sur cette structure de modèle unifiée ?
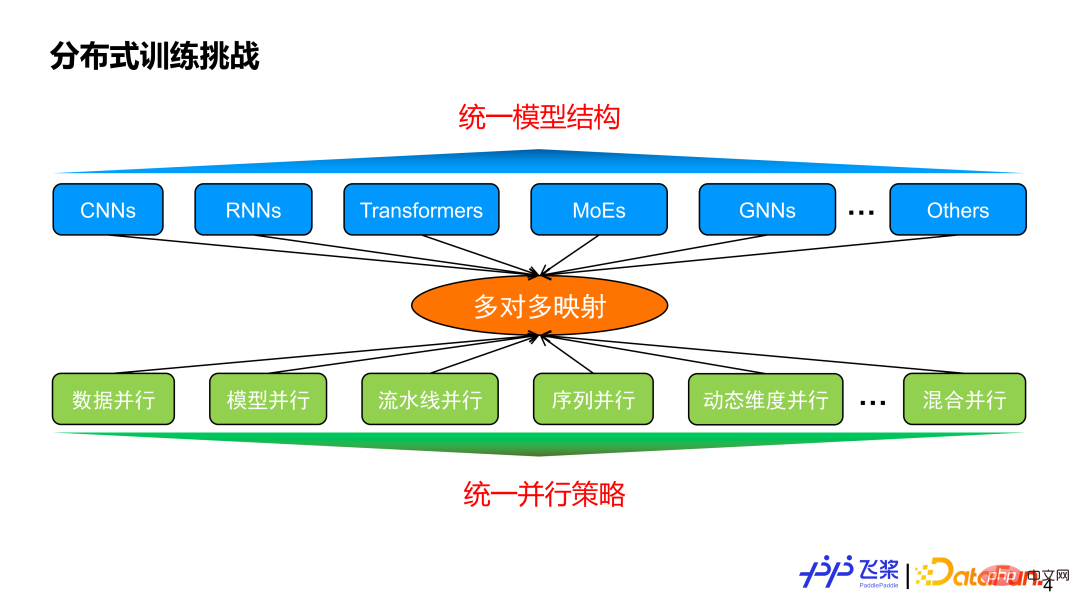
La réponse est non, car la stratégie parallèle n'est pas seulement liée à la structure du modèle, mais aussi étroitement liée à l'échelle du modèle et aux ressources réelles de la machine utilisée. Cela reflète la valeur du parallélisme automatique. Son objectif est le suivant : une fois que l'utilisateur a reçu un modèle et les ressources de la machine utilisées, il peut automatiquement aider l'utilisateur à choisir une stratégie parallèle meilleure ou optimale pour une exécution efficace.
Voici une liste de quelques emplois qui m'intéressent. Elle n'est peut-être pas complète. J'aimerais discuter avec vous de l'état actuel et de l'histoire du parallélisme automatique. Il est grossièrement divisé en plusieurs dimensions : la première dimension est le degré de parallélisme automatique, qui est divisé en entièrement automatique et semi-automatique ; la deuxième dimension est la granularité parallèle, qui fournit des stratégies parallèles pour chaque couche ou pour chaque opérateur. tenseurs pour fournir des stratégies parallèles ; la troisième est la capacité de représentation, qui est simplifiée en deux catégories : le parallélisme SPMD (Single Program Multiple Data) et le parallélisme du pipeline ; la quatrième concerne les caractéristiques, et voici une liste de travaux connexes que je pense personnellement être plus lieu distinctif ; le cinquième est le matériel de support, écrivant principalement le plus grand type et la plus grande quantité de matériel pris en charge par les travaux connexes. Parmi elles, les parties marquées en rouge sont principalement des points éclairants pour le développement parallèle automatique des pagaies volantes.
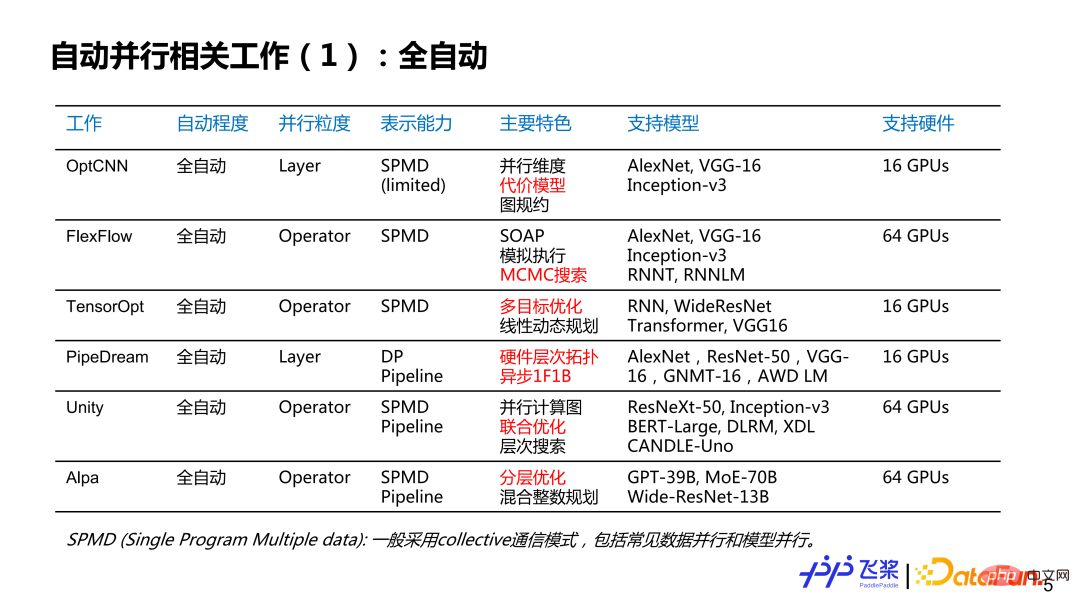
Pour le parallélisme entièrement automatique, nous pouvons voir que la granularité parallèle est le processus de développement allant du grain grossier au grain fin, la capacité de représentation va du SPMD relativement simple au SPMD et à la méthode Pipeline très généraux ; les modèles pris en charge vont du simple CNN au RNN en passant par le GPT plus complexe ; bien qu'il prenne en charge plusieurs machines et plusieurs cartes, l'échelle globale n'est pas particulièrement grande ;
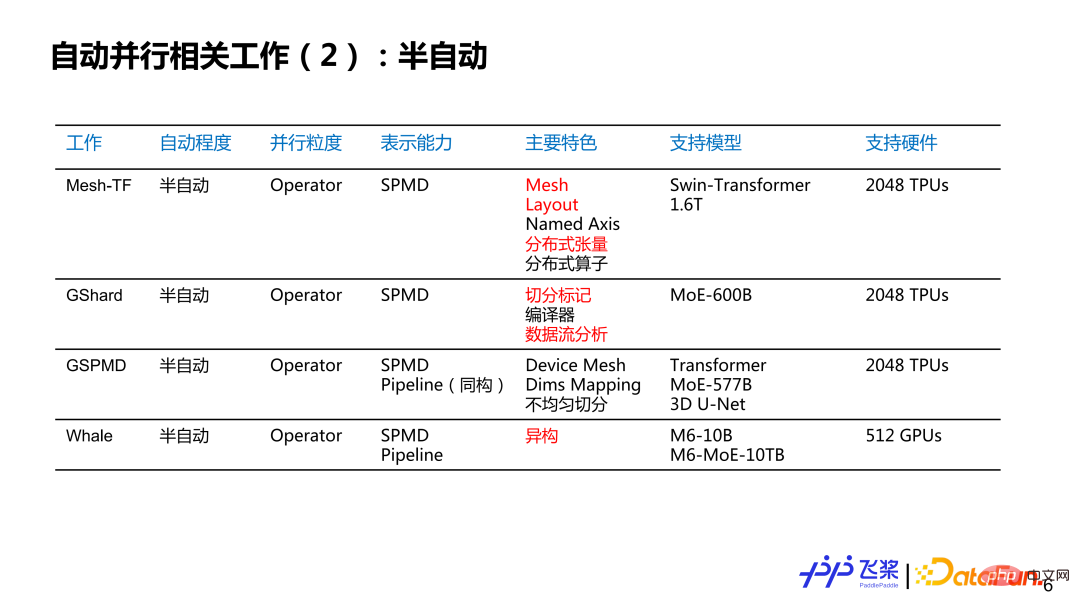
Pour le parallélisme semi-automatique, la granularité parallèle est essentiellement basée sur les opérateurs, et les capacités de représentation vont du simple SPMD au SPMD complet plus la stratégie parallèle de Pipeline, la prise en charge du modèle L'échelle atteint des centaines de milliards et des milliards, et la quantité de matériel utilisé atteint le niveau des kilocalories.
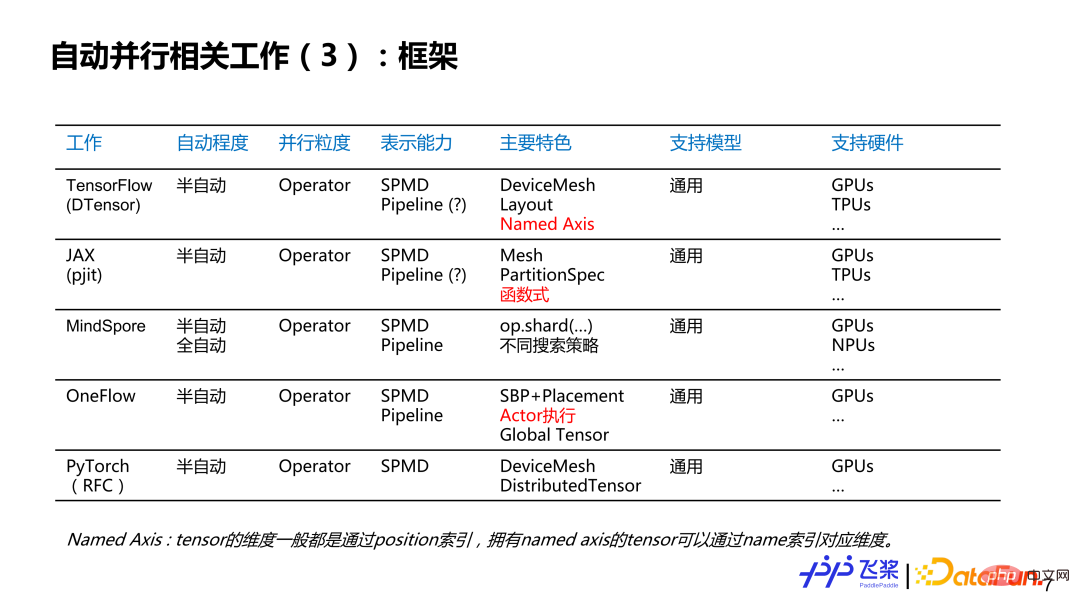
Du point de vue du framework, nous pouvons voir que les frameworks existants prennent déjà en charge ou prévoient de prendre en charge ce mode semi-automatique, et la granularité parallèle s'est également développée en termes de granularité des opérateurs et de capacités de représentation. ils utilisent tous l'expression complète de SPMD plus Pipeline, et ils sont orientés vers différents modèles et divers matériels.

Voici un résumé de quelques réflexions personnelles :
① Le premier point est que les stratégies distribuées sont progressivement unifiées dans la représentation sous-jacente.
② Deuxième point, le semi-automatique deviendra progressivement un paradigme de programmation distribuée du framework, tandis que le entièrement automatique sera exploré et implémenté sur la base de scénarios spécifiques et de règles empiriques.
③ Le troisième point est d'atteindre des performances ultimes de bout en bout, ce qui nécessite un réglage conjoint de stratégies parallèles et de stratégies d'optimisation.
2. Conception d'architecture
Généralement, une formation distribuée complète comprend 4 processus spécifiques. Le premier est la segmentation du modèle. Qu'il s'agisse de parallélisation manuelle ou automatique, le modèle doit être divisé en plusieurs tâches qui peuvent être parallélisées. La seconde est l'acquisition de ressources. ; Ensuite, il y a le placement des tâches (ou mappage des tâches), ce qui signifie placer les tâches divisées sur les ressources correspondantes. Enfin, il y a l'exécution distribuée, ce qui signifie que les tâches sur chaque appareil sont exécutées en parallèle et synchronisées et interagissent via un message ; communication.
Certaines solutions actuelles présentent certains problèmes : d'une part, elles peuvent ne considérer qu'une partie des processus dans la formation distribuée, ou se concentrer uniquement sur une partie des processus ; la seconde est qu'elles s'appuient trop sur les règles des experts ; de base, comme la segmentation des modèles et la distribution des ressources ; enfin, il y a un manque de connaissance des tâches et des ressources tout au long du processus de formation ;
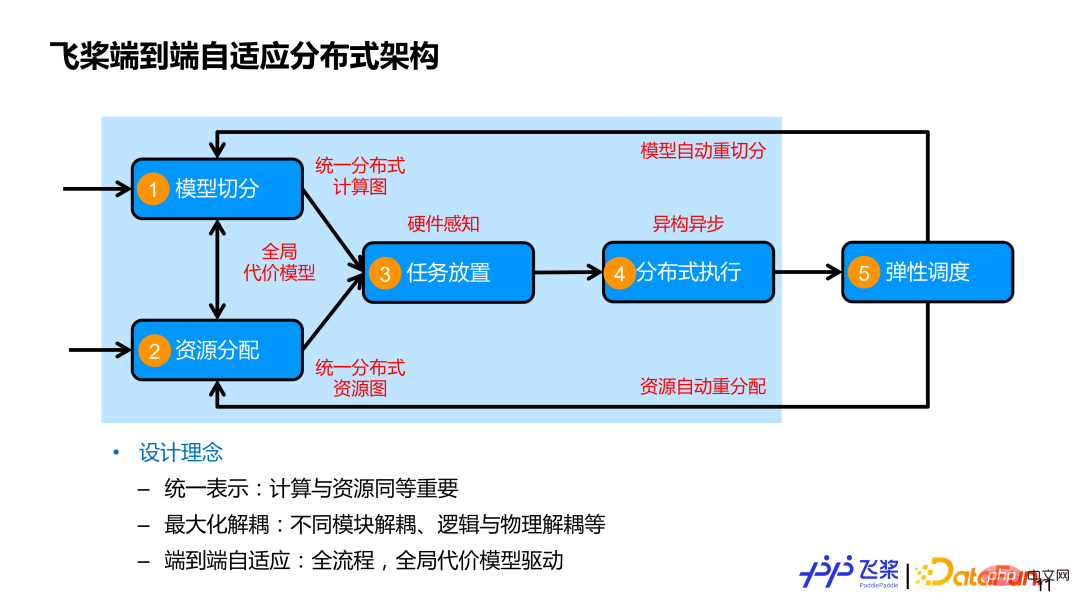
Premièrement, l'informatique et les ressources sont exprimées de manière unifiée, et l'informatique et les ressources sont tout aussi importantes. Souvent, les gens se soucient davantage de la manière de segmenter le modèle, mais moins d’attention est accordée aux ressources. D'une part, nous utilisons un graphe informatique distribué unifié pour représenter diverses stratégies parallèles ; d'autre part, nous utilisons un graphe de ressources distribuées unifié pour modéliser diverses ressources machine, qui peuvent représenter des relations isomorphes, et peuvent également représenter des relations de connexion de ressources hétérogènes, y compris les capacités de calcul et de stockage des ressources elles-mêmes.
Deuxièmement, maximiser le découplage. En plus du découplage entre les modules, nous découplerons également la segmentation logique du placement physique et de l'exécution distribuée, afin de mieux réaliser l'exécution efficace de différents modèles sur différentes ressources de cluster.
Troisièmement, l'adaptation de bout en bout couvre les processus complets impliqués dans la formation distribuée et utilise un modèle représentatif global pour piloter des décisions adaptatives sur des stratégies parallèles ou le placement de ressources afin de remplacer autant que possible les décisions manuelles personnalisées.
La partie encadrée en bleu clair dans l'image ci-dessus est le travail lié au parallélisme automatique présenté dans ce rapport.
1. Graphe informatique distribué unifié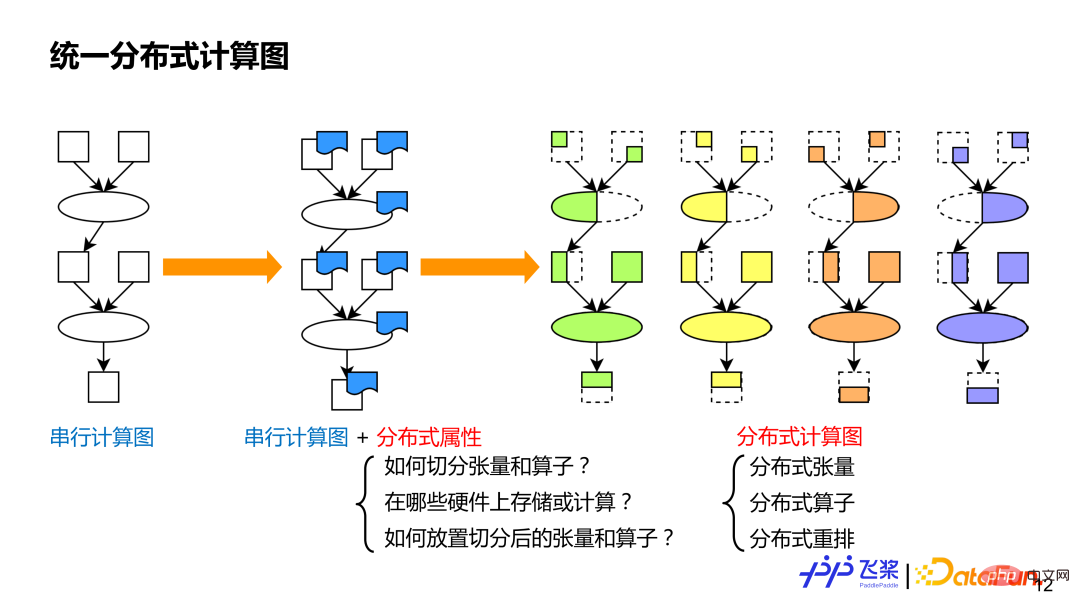
Le premier est un graphe informatique distribué unifié. Le but de l'unification est de nous permettre d'exprimer de manière unifiée diverses stratégies parallèles existantes, ce qui favorise le traitement automatisé. Comme nous le savons tous, les graphiques de calcul en série peuvent représenter différents modèles. De même, sur la base du graphique de calcul en série, nous ajoutons des attributs distribués à chaque opérateur et tenseur pour servir de graphique de calcul distribué. Ce type d'approche à granularité fine peut représenter l'existant. stratégies parallèles, et la sémantique sera plus riche et plus générale, et elle pourra également représenter de nouvelles stratégies parallèles. Les attributs distribués dans le graphe informatique distribué incluent principalement trois aspects d'information : 1) Il doit indiquer comment diviser le tenseur ou comment diviser l'opérateur 2) Il doit indiquer quelles ressources sont utilisées pour le calcul distribué ; pour le diviser Le tenseur ou l'opérateur résultant est mappé à la ressource. Par rapport aux graphes informatiques en série, les graphes informatiques distribués ont trois concepts de base : les tenseurs distribués, qui sont similaires aux tenseurs distribués en série, qui sont similaires aux réarrangements distribués en série, qui sont distribués uniquement pour les graphes informatiques ; (1) Tenseur distribué Principalement contient des méta-informations telles que la forme du tenseur, le type, etc. Généralement, les calculs réels ne nécessitent pas d'instanciation de tenseurs en série.
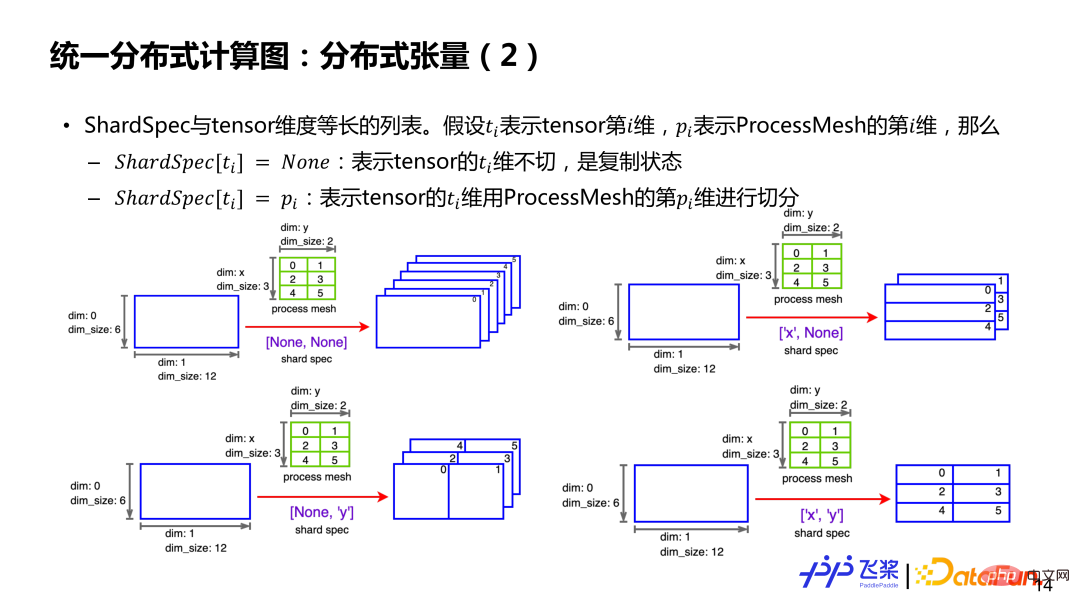
② ProcessMesh : La topologie cartésienne du processus indique que, contrairement à DeviceMesh, la raison pour laquelle nous utilisons ProcessMesh est principalement pour découpler le processus logique du périphérique physique, afin de faciliter une cartographie des tâches plus efficace.
③ ShardSpec : est utilisé pour indiquer quelle dimension de ProcessMesh est utilisée pour diviser chaque dimension du tenseur série. Pour plus de détails, voir l'exemple dans la figure ci-dessous.

Supposons qu'il existe un tenseur bidimensionnel 6*12 et un ProcessMesh 3*2 (la première dimension est x, la deuxième dimension est y et l'élément est l'ID du processus). Si ShardSpec est [Aucun, Aucun], cela signifie que les dimensions 0 et 2 du tenseur ne sont pas divisées et qu'il existe un tenseur complet sur chaque processus. Si ShardSpec est ['x', 'y'], cela signifie que l'axe x de ProcessMesh est utilisé pour couper la 0ème dimension du tenseur, et l'axe y de ProcessMesh est utilisé pour couper la 1ère dimension du tenseur. , de sorte que chaque processus ait un tenseur local de taille 2*6. En bref, grâce à ProcessMesh et ShardSpec et aux informations série avant la division du tenseur, il est possible de représenter la situation de division d'un tenseur sur le processus concerné.
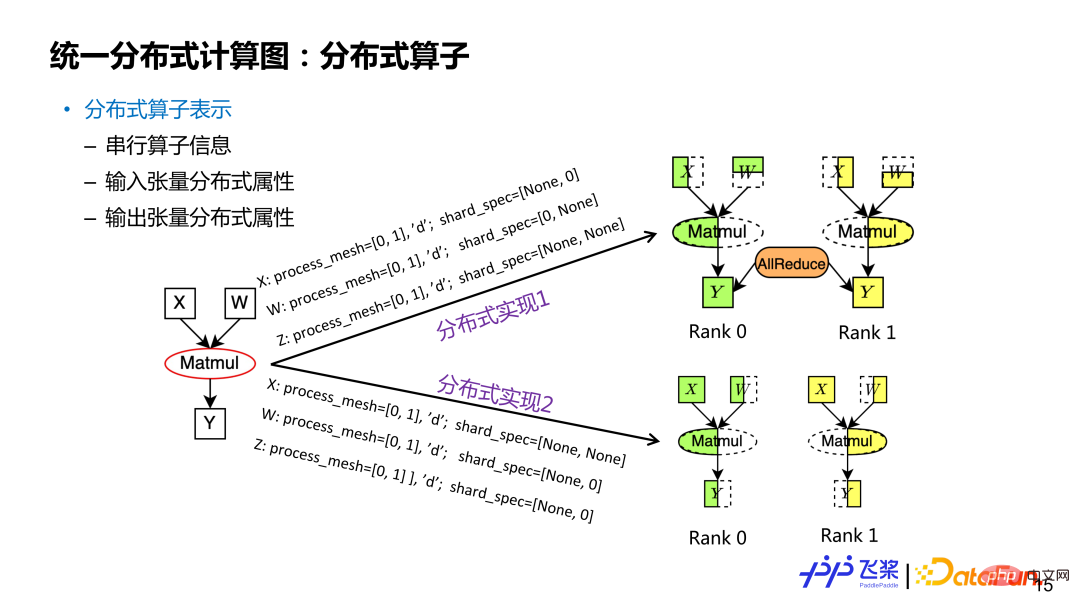
(2) Opérateur distribué
La représentation des opérateurs distribués est basée sur des tenseurs distribués, y compris les informations sur l'opérateur série, les propriétés distribuées des tenseurs d'entrée et de sortie. De même, un tenseur distribué peut correspondre à plusieurs méthodes de découpage. Les attributs distribués dans les opérateurs distribués sont différents et correspondent à différentes méthodes de découpage. En prenant l'exemple de l'opérateur de multiplication rectangulaire Y=X*W, si les attributs de distribution d'entrée et de sortie sont différents, ils correspondent à différentes implémentations d'opérateurs distribués (les attributs de distribution incluent ProcessMesh et ShardSpec). Pour un opérateur distribué, le ProcessMesh de ses tenseurs d'entrée et de sortie est le même.
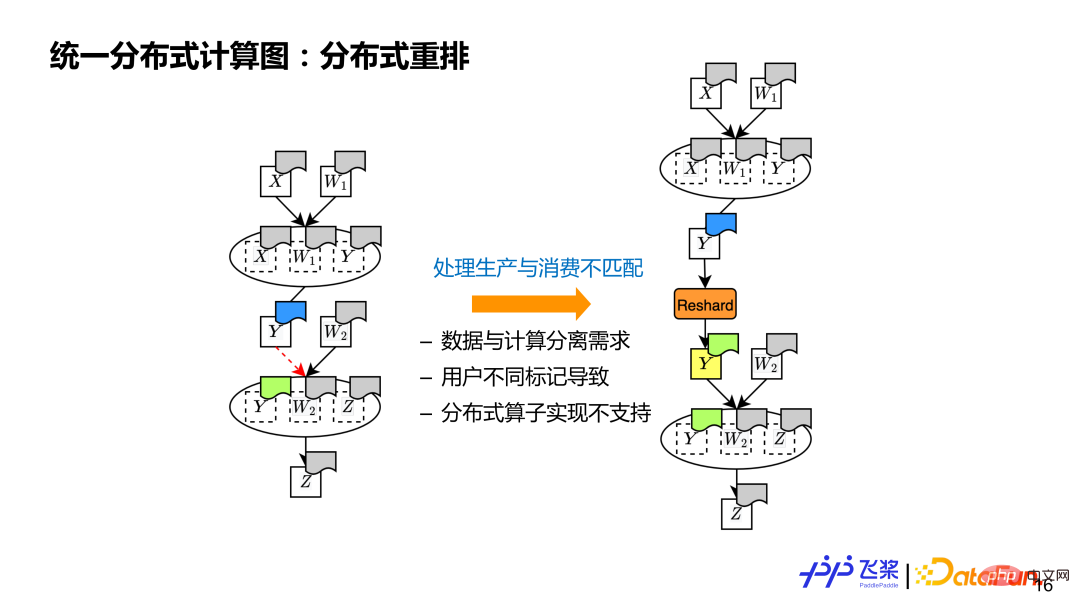
(3) Réarrangement distribué
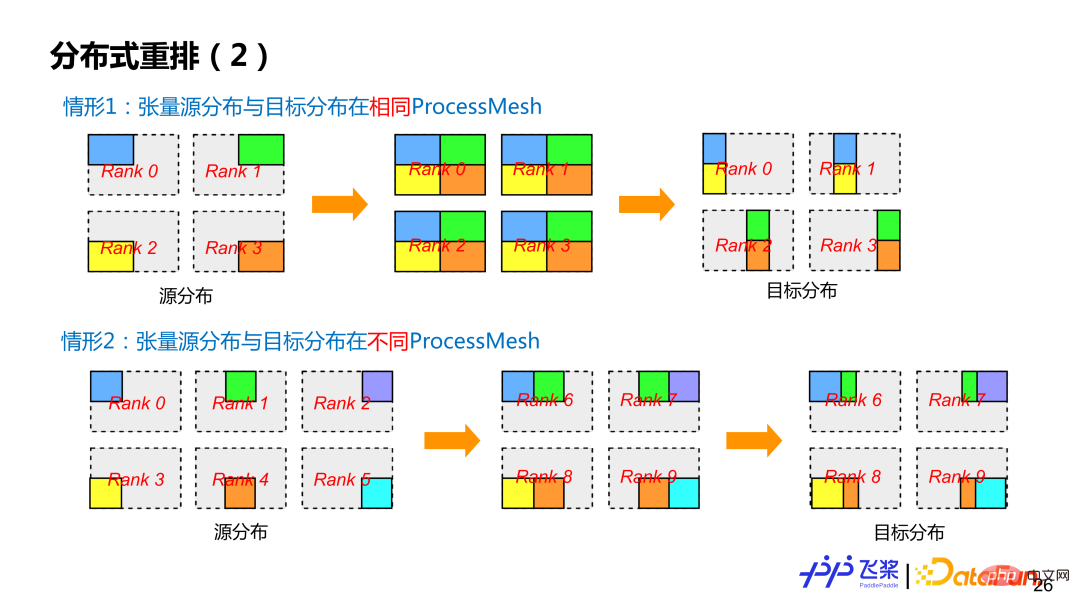
Le dernier est le réarrangement distribué, qui est un concept que doivent posséder les graphes informatiques distribués pour traiter les tenseurs sources et les destinations Situations avec différentes propriétés distribuées de tenseurs. Par exemple, il y a deux opérateurs dans le calcul. L'opérateur précédent produit y, qui est différent de l'opérateur suivant utilisant l'attribut distribué de y (indiqué par des couleurs différentes sur la figure). À ce stade, nous devons en insérer un supplémentaire. Opération de restructuration pour l'effectuer via la communication. L'essence du réarrangement distribué tensoriel est de gérer l'inadéquation entre la production et la consommation.
Il y a trois raisons principales à l'inadéquation : 1) Il prend en charge la séparation des données et du calcul, de sorte que le tenseur et l'opérateur qui l'utilise ont des propriétés de distribution différentes 2) Il prend en charge les attributs de formule de distribution d'étiquettes définis par l'utilisateur ; , les utilisateurs peuvent marquer différents attributs distribués pour les tenseurs et les opérateurs qui les utilisent ; 3) L'implémentation sous-jacente des opérateurs distribués est limitée. Si les attributs distribués d'entrée ou de sortie ne sont pas pris en charge, il est également nécessaire de passer un réarrangement distribué.
2. Graphe de ressources distribuées unifié
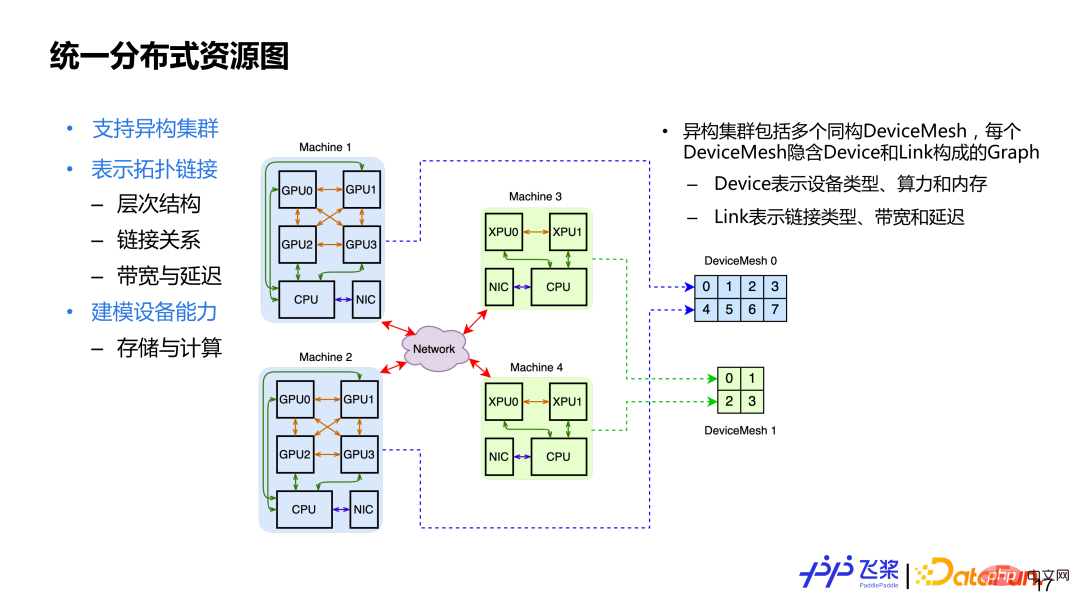
Après avoir présenté les trois concepts de base du graphe de ressources distribuées unifié, examinons le graphe de ressources distribuées unifié. Les principales considérations de conception sont : 1. ) Prend en charge les clusters hétérogènes, ce qui signifie qu'il peut y avoir des ressources CPU, GPU et XPU dans le cluster ; 2) Représente la connexion topologique, qui couvre la relation de connexion hiérarchique du cluster, y compris la quantification des capacités de connexion, telles que la bande passante ou retard ; 3) Modélisation de l'appareil lui-même, y compris les capacités de stockage et de calcul d'un appareil. Afin de répondre aux exigences de conception ci-dessus, nous utilisons Cluster pour représenter les ressources distribuées, qui contiennent plusieurs DeviceMesh isomorphes. Chaque DeviceMesh contiendra un graphique composé de liens de périphériques.
Voici un exemple. Sur l'image ci-dessus, vous pouvez voir qu'il y a 4 machines, dont 2 machines GPU et 2 machines XPU. Pour 2 machines GPU, un DeviceMesh isomorphe sera utilisé, et pour 2 machines XPU, un autre DeviceMesh isomorphe sera utilisé. Pour un cluster fixe, son DeviceMesh est fixe et l'utilisateur utilise ProcessMesh, qui peut être compris comme une abstraction de DeviceMesh. L'utilisateur peut remodeler et découper à volonté, et enfin le processus ProcessMesh sera uniformément mappé sur le périphérique DeviceMesh.
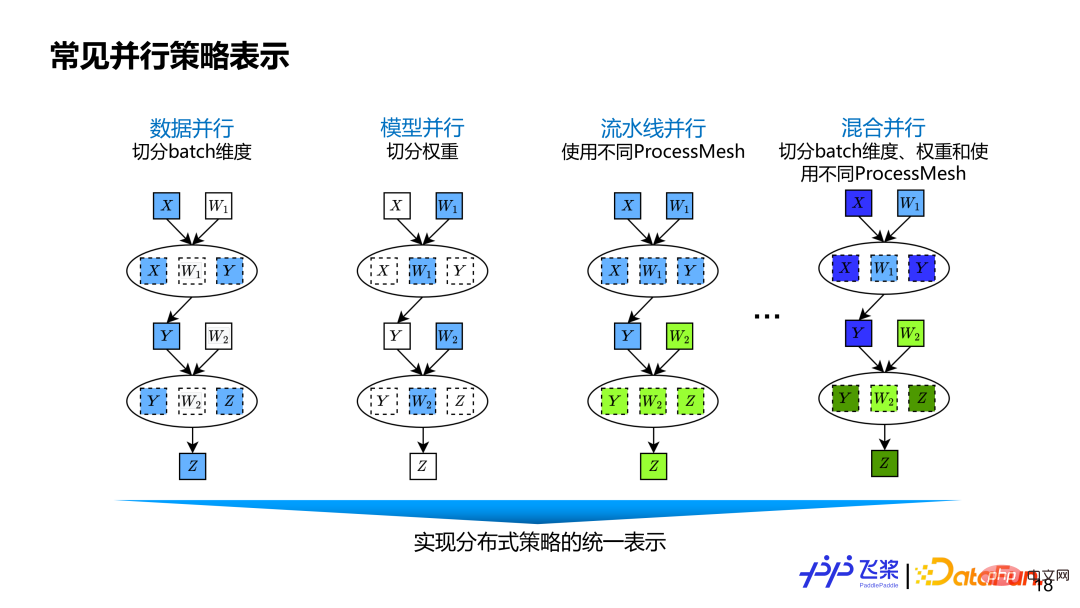
est basé sur le tenseur précédent somme La représentation graphique informatique distribuée à granularité fine des opérateurs peut couvrir les stratégies parallèles existantes ainsi que les nouvelles stratégies parallèles qui pourraient apparaître dans le futur. Le parallélisme des données consiste à diviser la dimension Batch du tenseur de données. Le modèle segmente en parallèle les dimensions liées au poids. Le parallélisme du pipeline est représenté par différents ProcessMesh, qui peuvent être exprimés sous la forme d'un parallélisme de pipeline plus flexible. Par exemple, une étape de pipeline peut connecter plusieurs étapes de pipeline et les formes de ProcessMesh utilisées par différentes étapes peuvent être différentes. Le parallélisme du pipeline de certains autres frameworks est obtenu via le numéro d'étape ou le placement, qui n'est pas suffisamment flexible et polyvalent. Le parallélisme hybride est un mélange de parallélisme de données, de parallélisme de modèles tensoriels et de parallélisme de pipeline.
3. Implémentation des clés
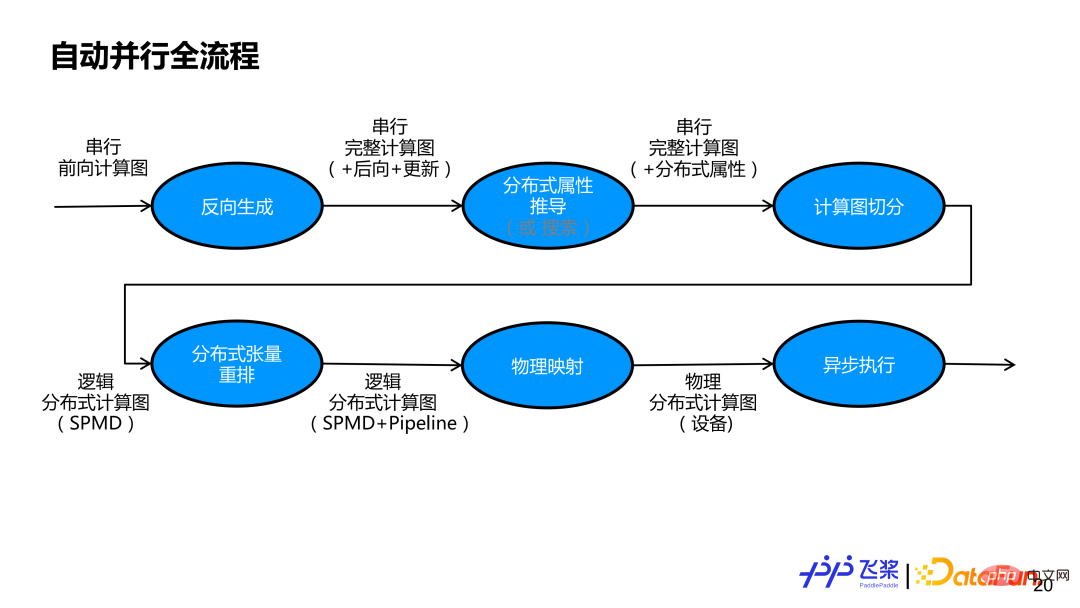
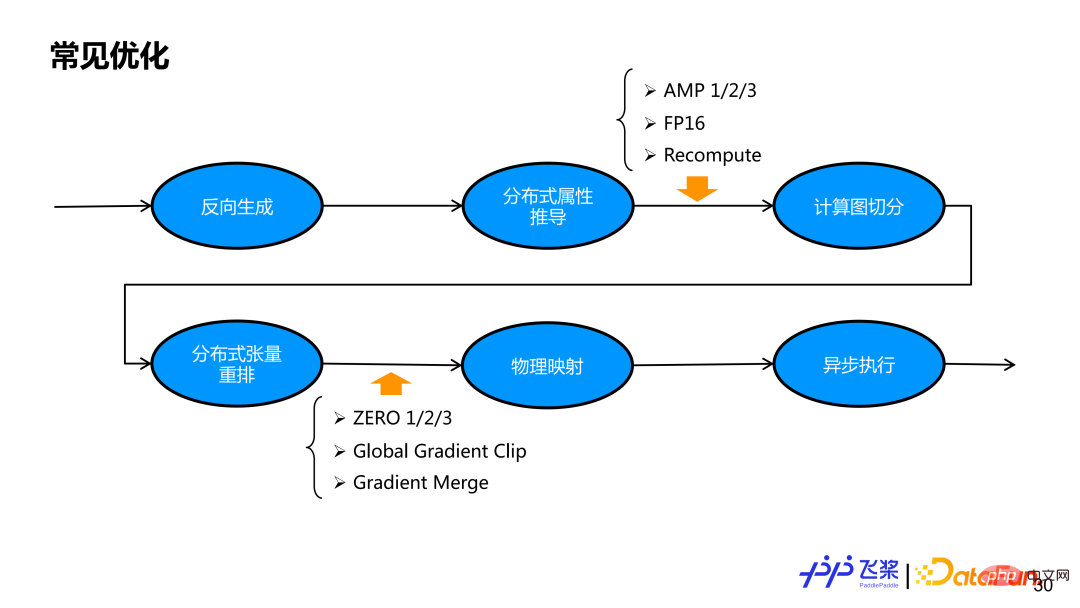
Le devant est la parallélisation automatique de pagaies volantes Conception architecturale et introduction à quelques concepts abstraits. Sur la base des bases précédentes, introduisons le processus de mise en œuvre interne de parallélisation automatique des palettes volantes à travers l'exemple du réseau FC de couche 2. L'image ci-dessus est l'intégralité de l'organigramme parallèle automatique de la pagaie volante. . Tout d’abord, nous effectuerons une génération inverse basée sur un graphe de calcul avant en série pour obtenir un graphe de calcul complet comprenant les sous-graphes avant, arrière et de mise à jour. Ensuite, il est nécessaire de clarifier les propriétés distribuées de chaque tenseur et de chaque opérateur du réseau. Une méthode de dérivation semi-automatique ou une méthode de recherche entièrement automatique peut être utilisée. Ce rapport explique principalement la méthode de dérivation semi-automatique, qui consiste à dériver les propriétés distribuées d'autres tenseurs et opérateurs non étiquetés sur la base d'un petit nombre d'étiquettes utilisateur. Après dérivation via des propriétés distribuées, chaque tenseur et chaque opérateur du graphe de calcul en série possède ses propres propriétés distribuées. Sur la base des attributs distribués, le graphique de calcul série est d'abord transformé en un graphique de calcul distribué logique qui prend en charge le parallélisme SPMD via des modules de segmentation automatique, puis, grâce à un réarrangement distribué, un graphique de calcul distribué logique qui prend en charge le parallélisme de pipeline est réalisé. Le graphe informatique distribué logique généré sera transformé en graphe informatique distribué physique grâce au mappage physique. Actuellement, seul le mappage un à un d'un processus et d'un périphérique est pris en charge. Enfin, le graphe informatique distribué physique est transformé en un véritable graphe de dépendance de tâches et remis à l'exécuteur asynchrone pour une exécution réelle.
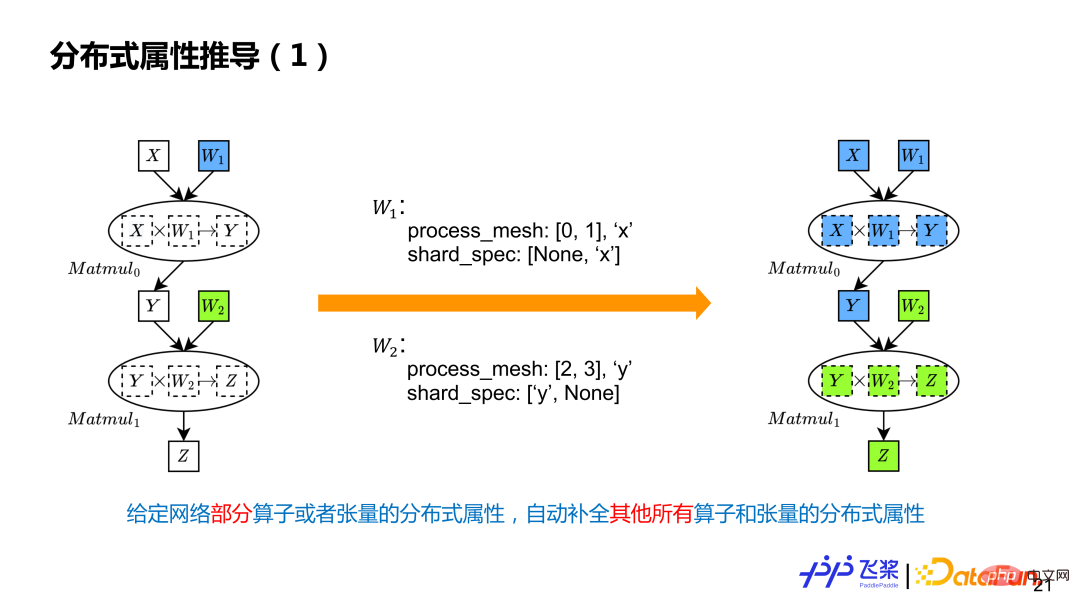
1. Dérivation d'attributs distribués
# 🎜🎜# La dérivation d'attributs distribués consiste à compléter automatiquement les attributs distribués de tous les autres tenseurs et opérateurs étant donné les attributs distribués de certains tenseurs et opérateurs dans le graphe de calcul. L'exemple est deux calculs Matmul. L'utilisateur n'a marqué que deux attributs distribués de paramètres, ce qui signifie que W1 effectue une coupe de colonne sur les processus 0 et 1, et W2 effectue une coupe de ligne sur les processus 2 et 3. Il existe deux ProcessMesh différents. .
La dérivation des attributs distribués est divisée en deux étapes : 1) Effectuer d'abord la transmission ProcessMesh pour implémenter la segmentation du pipeline ; 2) Effectuer ensuite la transmission ShardSpec pour implémenter la segmentation SPMD au sein d'une étape ; La dérivation ProcessMesh utilise le programme linéaire à palette volante lR et utilise la stratégie de sélection la plus proche pour la dérivation selon l'ordre de programme statique. Elle prend en charge les calculs inclus, c'est-à-dire que s'il y a deux ProcessMesh, l'un est plus grand et l'autre est plus petit, le le plus grand est sélectionné comme ProcessMesh final. La dérivation ShardSpec utilise Flying Paddle SSA Graph IR pour effectuer une analyse du flux de données avant et arrière pour la dérivation. La raison pour laquelle l'analyse du flux de données peut être utilisée est que la sémantique ShardSpec satisfait à la propriété Semilattice de l'analyse du flux de données. L'analyse du flux de données peut théoriquement garantir la convergence. En combinant l'analyse avant et arrière, toute information de marque de position dans le graphique de calcul peut être propagée à l'ensemble du graphique de calcul, au lieu de se propager uniquement dans une seule direction.
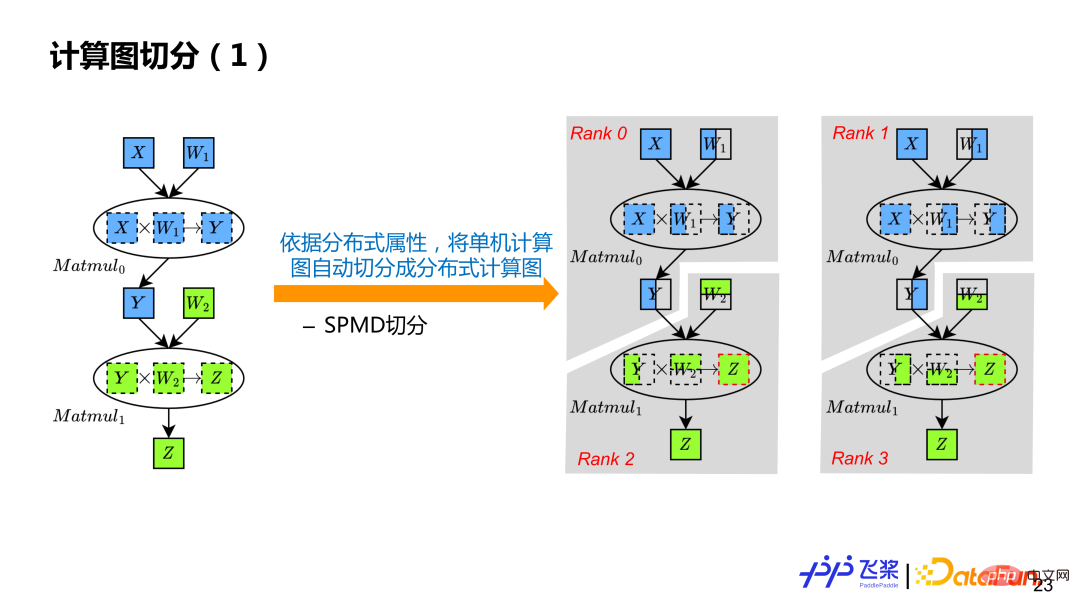
Basé sur la dérivation d'attributs distribués, chaque tenseur et opérateur dans le graphe de calcul en série a son propre attribut distribué, de sorte que le graphe de calcul puisse être automatiquement déduit en fonction des attributs distribués Slice. Selon l'exemple, le graphique de calcul série d'une seule machine est transformé en quatre graphiques de calcul Rank0, Rank1, Rank2 et Rank3.
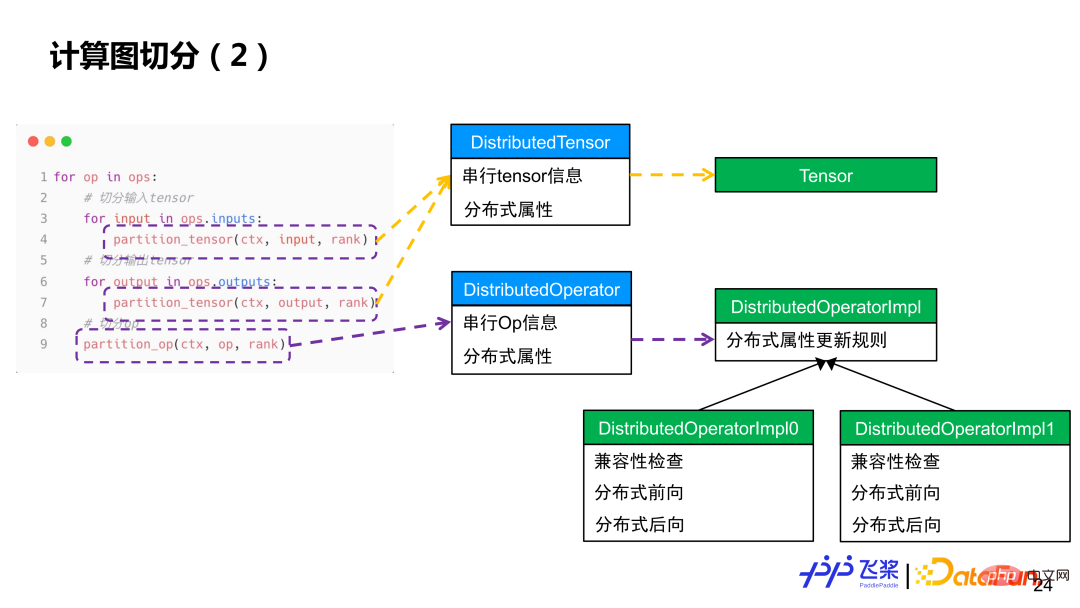
Pour faire simple, chaque opérateur est parcouru, l'entrée et la sortie de l'opérateur sont d'abord divisées en tenseurs, puis chaque opérateur est calculé et divisé. La segmentation Tensor utilisera l'objet Tensor distribué pour construire un objet Tensor local, tandis que la segmentation d'opérateur utilisera l'objet Opérateur distribué pour sélectionner l'implémentation distribuée correspondante en fonction des attributs de distribution de l'entrée et de la sortie réelles, similaire à la distribution des opérateurs d'un framework mono-machine au processus Kernel.
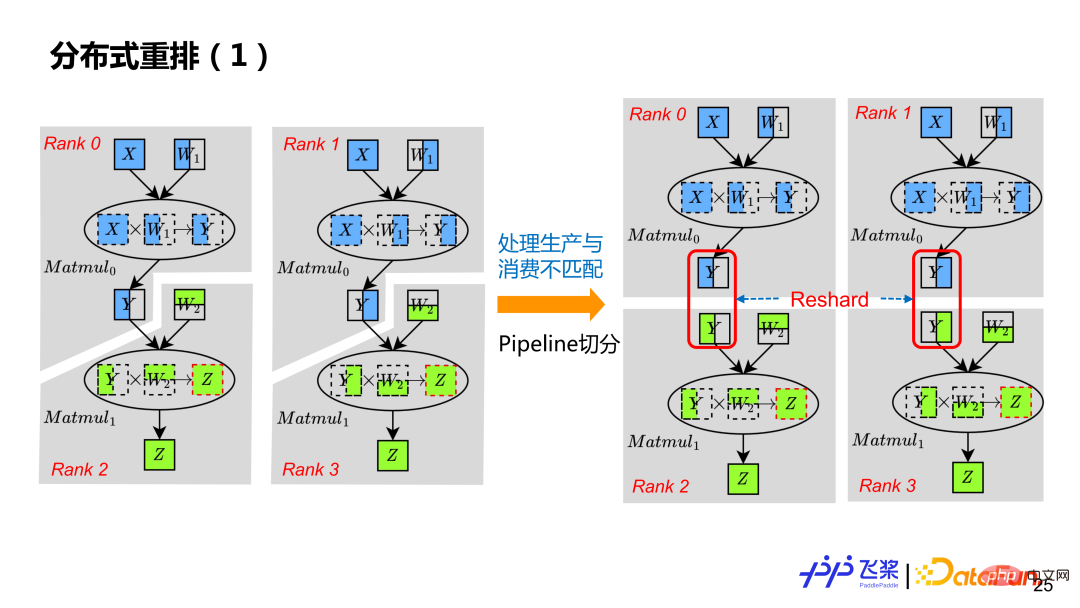
Grâce à la segmentation automatique précédente, vous ne pouvez obtenir qu'un graphe de calcul distribué prenant en charge le parallélisme SPMD. Afin de prendre en charge le parallélisme du pipeline, il doit également être traité via un réarrangement distribué, de sorte qu'en insérant une opération Reshard appropriée, chaque rang de l'exemple ait son propre graphique de calcul véritablement indépendant. Bien que le Y de Rank0 dans l'image de gauche soit le même que le Y de Rank2, ils se trouvent sur des ProcessMesh différents, ce qui entraîne une inadéquation dans les attributs de distribution de production et de consommation, donc Reshard doit également être inséré.
Flying Paddle actuellement prend en charge deux types de réarrangement distribué. La première catégorie est la distribution du tenseur source et la distribution du tenseur cible les plus courantes sur le même ProcessMesh, mais la distribution du tenseur source et la distribution du tenseur cible utilisent des méthodes de découpage différentes (c'est-à-dire que la ShardSpec est différente). La deuxième catégorie est que la distribution du tenseur source et le tenseur cible sont distribués sur différents ProcessMesh, et la taille de ProcessMesh peut être différente, comme le processus 0-5 et le processus 6-9 dans le cas 2 de la figure. Afin de réduire au maximum la communication, Flying Paddle effectue également des optimisations associées sur les opérations Reshard.
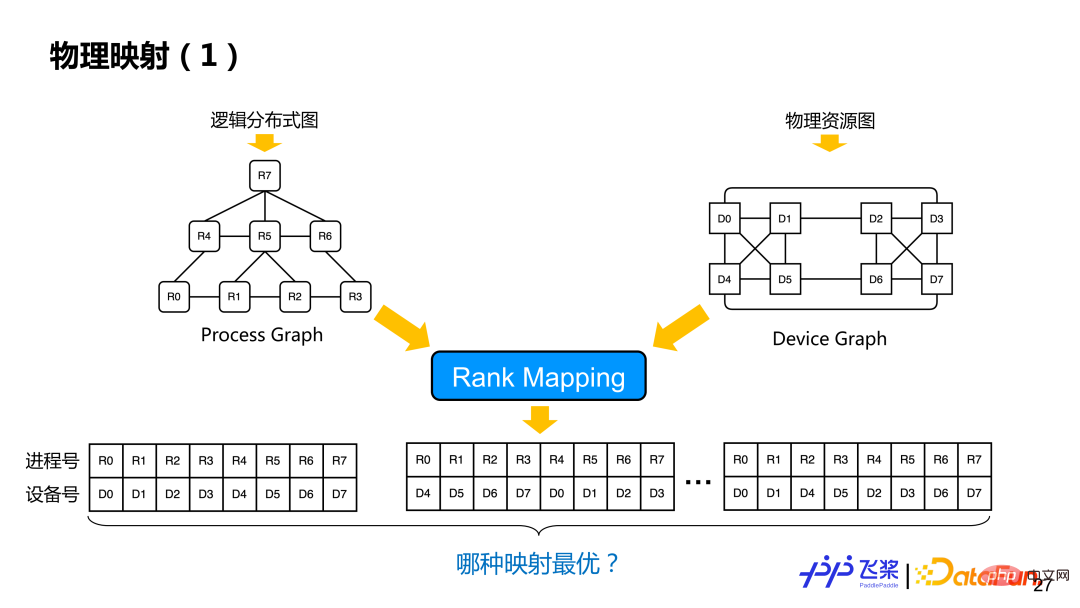
Après le réarrangement distribué, un graphe informatique distribué logique est obtenu. À l'heure actuelle, le processus et le mappage spécifique des appareils n'ont pas encore été décidés. Sur la base du graphe informatique distribué logique et du graphe de représentation des ressources précédemment unifié, des opérations de mappage physique sont effectuées, à savoir le mappage de classement, qui consiste à trouver une solution de mappage optimale à partir de plusieurs solutions de mappage (sur quel périphérique un processus est spécifiquement mappé).
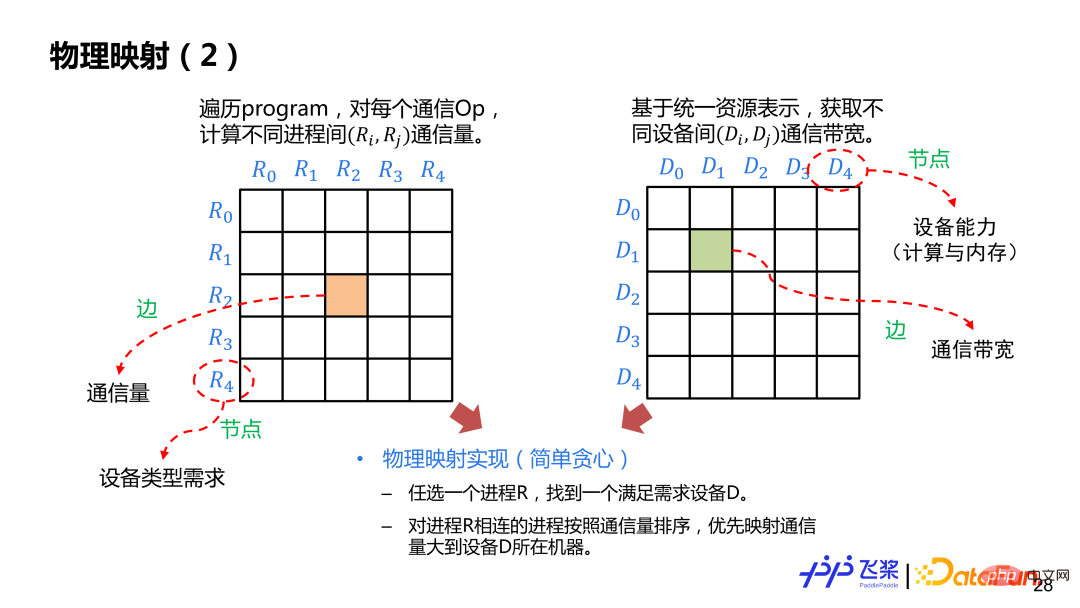
Voici une implémentation relativement simple basée sur des règles gourmandes. Tout d'abord, créez le tableau de contiguïté entre les processus et la communication inter-processus. Les bords représentent le volume de communication et les nœuds représentent les exigences des appareils. Ensuite, créez le tableau de contiguïté entre les appareils. Les bords représentent la bande passante de communication et les nœuds représentent le périphérique informatique et. mémoire. Nous sélectionnerons au hasard un processus R et le placerons sur l'appareil D qui répond aux besoins. Après l'avoir placé, nous sélectionnerons le processus avec le plus grand volume de communication avec R et le placerons sur d'autres appareils de la machine où se trouve D. La méthode sera utilisée jusqu’à ce que tous les mappages de processus soient terminés. Au cours du processus de mappage, il est nécessaire de déterminer si le périphérique sélectionné correspond au type de périphérique requis par le graphique de processus, ainsi que la quantité de calcul et la mémoire requises.
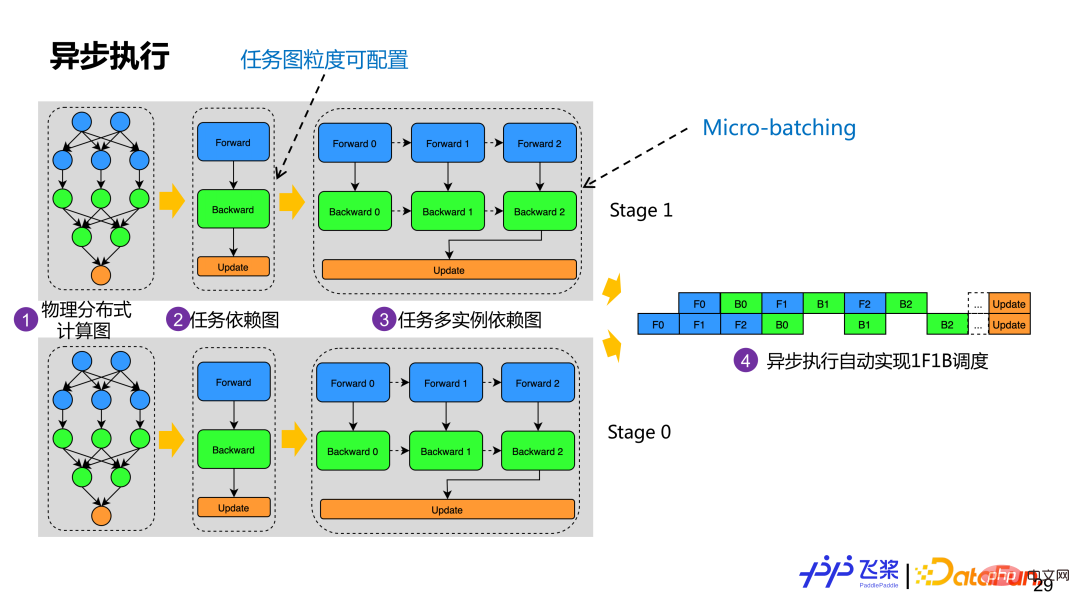
Après la cartographie physique, nous construirons le graphique de dépendance des tâches réel basé sur le réseau physique distribué obtenu. L'exemple de la figure consiste à créer un graphe de dépendance de tâche basé sur les rôles avant, arrière et de mise à jour du graphe de calcul. Les opérateurs ayant le même rôle formeront une tâche. Afin de prendre en charge l'optimisation du micro-batching, un graphique de dépendance de tâche générera plusieurs graphiques de dépendance d'instance de tâche. Bien que chaque instance ait la même logique de calcul, elle utilise une mémoire différente. Actuellement, Flying Paddle créera automatiquement un graphique de tâches basé sur les rôles du graphique de calcul, mais les utilisateurs peuvent personnaliser la construction des tâches en fonction d'une granularité appropriée. Une fois que chaque processus dispose d'un graphique de dépendances multi-instances de tâches, il sera exécuté de manière asynchrone en fonction du mode Acteur, et la planification de l'exécution 1F1B peut être automatiquement réalisée via la méthode basée sur les messages.
Sur la base de l'ensemble du processus ci-dessus, nous avons implémenté une parallélisation automatique avec des fonctions relativement complètes. Mais seule la stratégie parallèle ne peut pas obtenir de meilleures performances de bout en bout, nous devons donc également ajouter des stratégies d'optimisation correspondantes. Pour la parallélisation automatique des palettes volantes, nous ajouterons quelques stratégies d'optimisation avant la segmentation automatique et après la segmentation du réseau. En effet, certaines optimisations sont plus naturelles à mettre en œuvre en logique série, et certaines optimisations sont plus faciles à mettre en œuvre après la segmentation via une passe d'optimisation unifiée. mécanisme de gestion, nous pouvons assurer la libre combinaison de stratégies parallèles et de stratégies d'optimisation dans la parallélisation automatique des palettes volantes.
4. Pratique d'application
La pratique d'application est présentée ci-dessous.
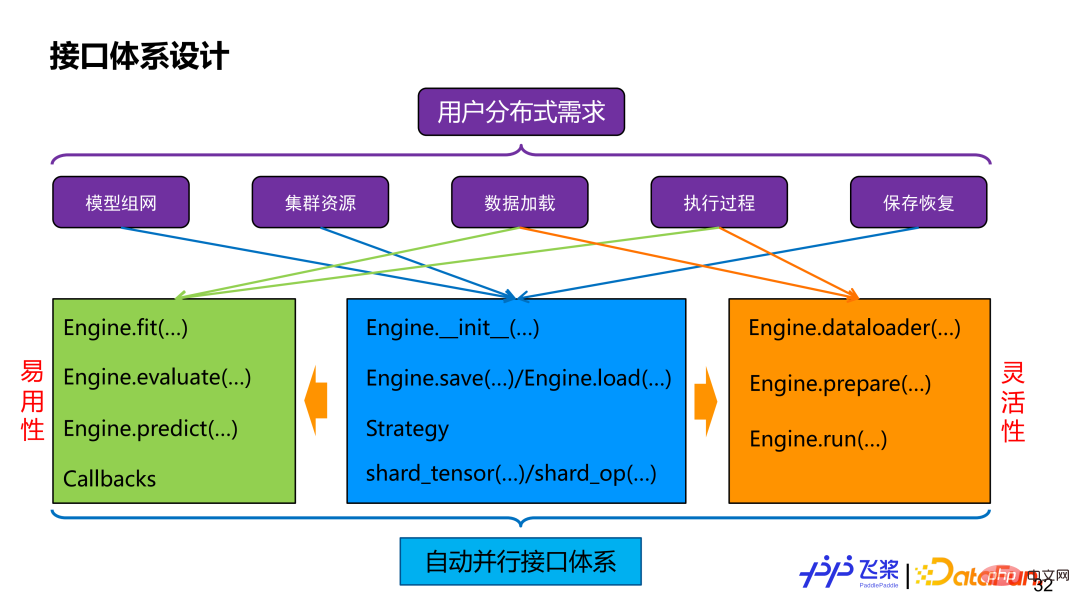
Le premier est l'interface. Quelle que soit la façon dont elle est implémentée, les utilisateurs utiliseront en fin de compte les capacités parallèles automatiques que nous fournissons via l'interface. Si les exigences distribuées de l'utilisateur sont démantelées, cela inclut la segmentation du réseau modèle, la représentation des ressources, le chargement de données distribuées, le contrôle du processus d'exécution distribué, la sauvegarde et la récupération distribuées, etc. Pour répondre à ces besoins, nous proposons une classe Engine qui allie facilité d’utilisation et flexibilité. En termes de facilité d'utilisation, il fournit des API de haut niveau, peut prendre en charge des rappels personnalisés et le processus distribué est transparent pour les utilisateurs. En termes de flexibilité, il fournit des API de bas niveau, notamment la construction de chargeurs de données distribués, la découpe et l'exécution automatiques de graphiques parallèles, ainsi que d'autres interfaces, permettant aux utilisateurs d'avoir un contrôle plus précis. Les deux partageront des interfaces telles que shard_tensor, shard_op, save etload.
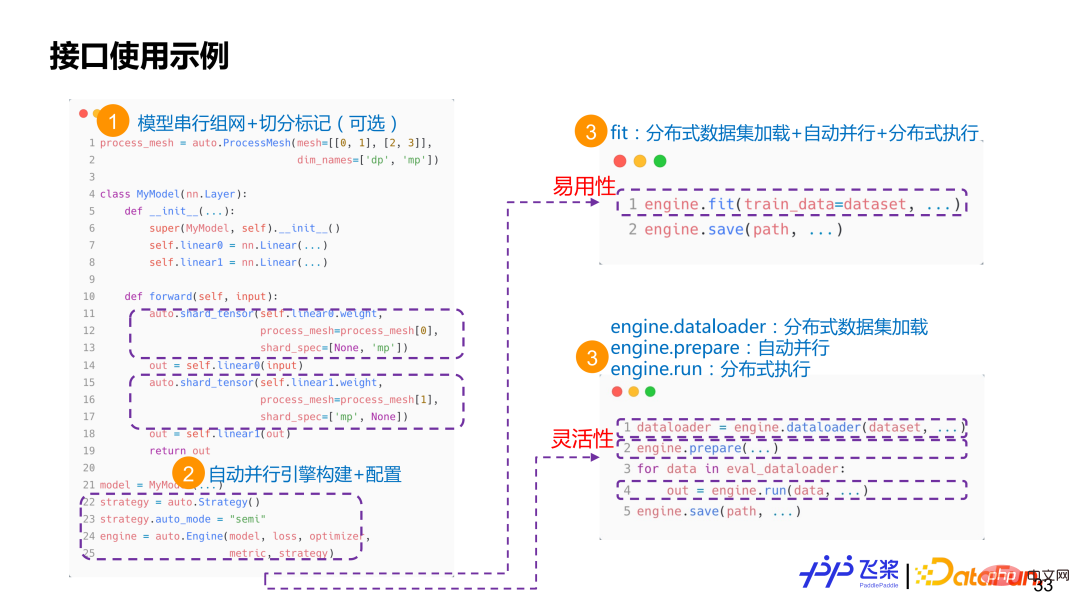
Il existe deux interfaces étiquetées shard_op et shard_tensor. Parmi eux, shard_op peut marquer soit un seul opérateur, soit l'ensemble du module, et c'est une formule fonctionnelle. L'image ci-dessus est un exemple d'utilisation très simple. Tout d'abord, utilisez l'API existante de Flying Paddle pour réaliser un réseau série, dans lequel nous utiliserons shard_tensor ou shard_op pour le marquage d'attributs distribués non intrusif. Ensuite, créez un moteur parallèle automatique et transmettez les informations et la configuration liées au modèle. À l'heure actuelle, l'utilisateur a deux options. L'une consiste à utiliser directement l'interface d'ordre supérieur fit/evaluate/predict, et l'autre option consiste à utiliser l'interface dataloader+prepare+run. Si vous choisissez l'interface adaptée, l'utilisateur n'a qu'à transmettre l'ensemble de données et le framework chargera automatiquement l'ensemble de données distribué, compilera automatiquement le processus parallèle et exécutera la formation distribuée. Si vous choisissez l'interface dataloader+prepare+run, les utilisateurs peuvent découpler le chargement de données distribué, la compilation parallèle automatique et l'exécution distribuée, permettant ainsi un meilleur débogage en une seule étape.
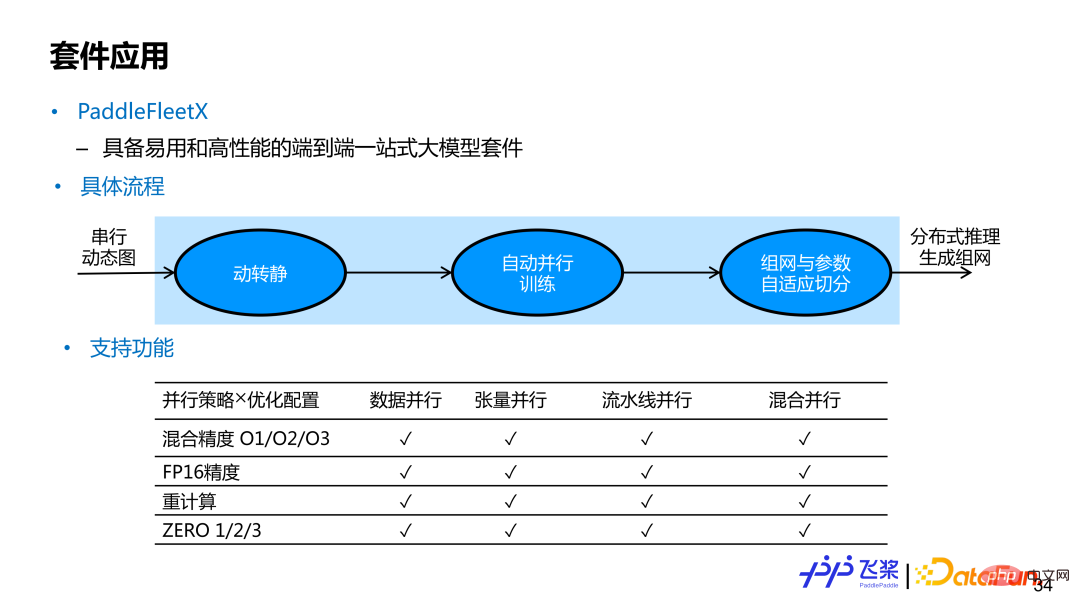
PaddleFleetX est une suite de grands modèles unique de bout en bout, facile à utiliser et hautes performances, prenant en charge la parallélisation automatique. Si les utilisateurs souhaitent utiliser la fonction parallèle automatique de bout en bout de la pagaie volante, il leur suffit de fournir un réseau de modèles de graphiques dynamiques en série. Après avoir obtenu le réseau série à graphe dynamique de l'utilisateur, l'implémentation interne utilisera le module dynamique à statique pour convertir le réseau à carte unique à graphe dynamique en un réseau à carte unique à graphe statique, puis compilera automatiquement en parallèle et enfin effectuera une distribution distribuée. entraînement. . Lors de la génération d'inférences, les ressources machine utilisées peuvent être différentes de celles utilisées lors de la formation. L'implémentation interne effectuera également une segmentation adaptative des paramètres et une mise en réseau. Actuellement, le parallélisme automatique de PaddleFleetX couvre les stratégies parallèles et les stratégies d'optimisation couramment utilisées, et prend en charge toute combinaison des deux. Pour les tâches générées, il prend également en charge la segmentation automatique du flux de contrôle While.
5. Résumé et perspectives
Il y a encore beaucoup de travail en cours pour les pagaies automatiques à vol parallèle. Les fonctionnalités actuelles peuvent être résumées dans les aspects suivants :
. Tout d'abord, l'unification Le graphe informatique distribué peut prendre en charge des stratégies distribuées complètes SPMD et Pipeline, et peut prendre en charge la représentation séparée du stockage et du calcul
Deuxièmement, le graphe de ressources distribuées unifié peut prendre en charge des ressources hétérogènes ; et représentation ;
Troisièmement, il prend en charge la combinaison organique de stratégies parallèles et de stratégies d'optimisation.
Quatrièmement, il fournit un système d'interface relativement complet ; Les composants prennent en charge l'architecture distribuée adaptative de bout en bout de la pagaie volante.
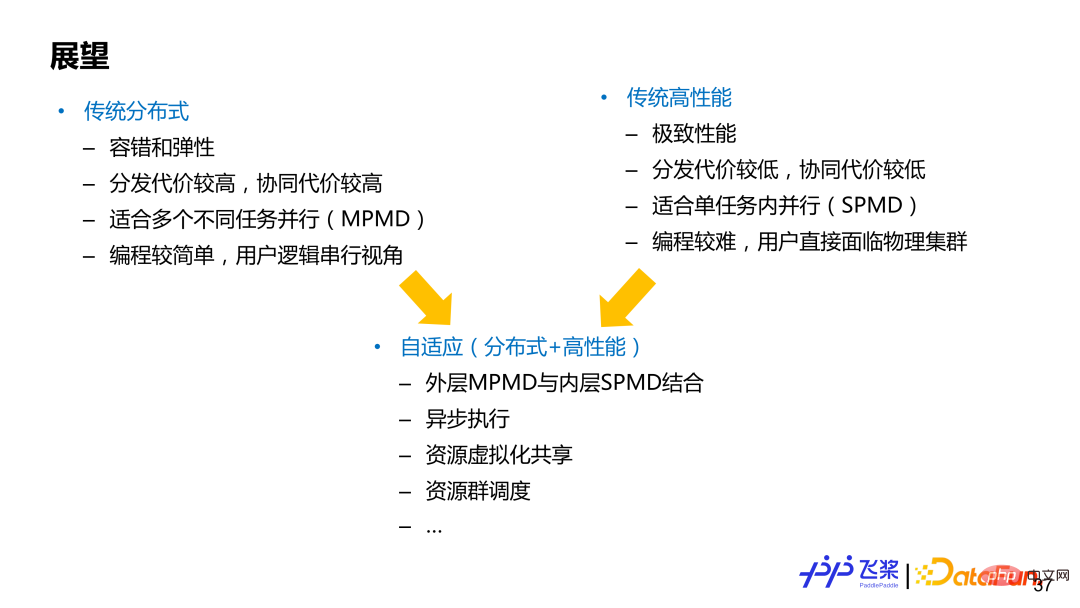
Le parallèle peut généralement être divisé en deux domaines (sans démarcation claire), l'un est l'informatique distribuée traditionnelle et l'autre est l'informatique haute performance traditionnelle, qui ont tous deux leurs propres avantages et inconvénients. Le cadre représentatif basé sur l'informatique distribuée traditionnelle est TensorFlow, qui se concentre sur le mode parallèle MPMD (Multiple Program-Multiple Data) et peut bien prendre en charge l'élasticité et la tolérance aux pannes. L'expérience utilisateur de l'informatique distribuée sera meilleure et la programmation sera plus simple pour les utilisateurs. utilisent généralement la programmation dans une perspective globale en série ; le cadre représentatif basé sur le calcul haute performance traditionnel est PyTorch, qui se concentre davantage sur le mode SPMD (Single Program-Multiple Data) et recherche les performances ultimes pour lesquelles les utilisateurs doivent faire face directement. programmation et sont responsables de la segmentation du modèle eux-mêmes. Et d’insérer une communication appropriée, les exigences des utilisateurs sont plus élevées. Le parallélisme automatique ou le calcul distribué adaptatif peuvent être considérés comme une combinaison des deux. Bien entendu, différentes architectures ont des priorités de conception différentes et doivent être pondérées en fonction des besoins réels. Nous espérons que l'architecture adaptative des pagaies volantes pourra prendre en compte les avantages des deux domaines.

Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

Video Face Swap
Échangez les visages dans n'importe quelle vidéo sans effort grâce à notre outil d'échange de visage AI entièrement gratuit !

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 15 outils d'annotation d'images gratuits open source recommandés
Mar 28, 2024 pm 01:21 PM
15 outils d'annotation d'images gratuits open source recommandés
Mar 28, 2024 pm 01:21 PM
L'annotation d'images est le processus consistant à associer des étiquettes ou des informations descriptives à des images pour donner une signification et une explication plus profondes au contenu de l'image. Ce processus est essentiel à l’apprentissage automatique, qui permet d’entraîner les modèles de vision à identifier plus précisément les éléments individuels des images. En ajoutant des annotations aux images, l'ordinateur peut comprendre la sémantique et le contexte derrière les images, améliorant ainsi la capacité de comprendre et d'analyser le contenu de l'image. L'annotation d'images a un large éventail d'applications, couvrant de nombreux domaines, tels que la vision par ordinateur, le traitement du langage naturel et les modèles de vision graphique. Elle a un large éventail d'applications, telles que l'assistance aux véhicules pour identifier les obstacles sur la route, en aidant à la détection. et le diagnostic des maladies grâce à la reconnaissance d'images médicales. Cet article recommande principalement de meilleurs outils d'annotation d'images open source et gratuits. 1.Makesens
 Cet article vous amènera à comprendre SHAP : explication du modèle pour l'apprentissage automatique
Jun 01, 2024 am 10:58 AM
Cet article vous amènera à comprendre SHAP : explication du modèle pour l'apprentissage automatique
Jun 01, 2024 am 10:58 AM
Dans les domaines de l’apprentissage automatique et de la science des données, l’interprétabilité des modèles a toujours été au centre des préoccupations des chercheurs et des praticiens. Avec l'application généralisée de modèles complexes tels que l'apprentissage profond et les méthodes d'ensemble, la compréhension du processus décisionnel du modèle est devenue particulièrement importante. Explainable AI|XAI contribue à renforcer la confiance dans les modèles d'apprentissage automatique en augmentant la transparence du modèle. L'amélioration de la transparence des modèles peut être obtenue grâce à des méthodes telles que l'utilisation généralisée de plusieurs modèles complexes, ainsi que les processus décisionnels utilisés pour expliquer les modèles. Ces méthodes incluent l'analyse de l'importance des caractéristiques, l'estimation de l'intervalle de prédiction du modèle, les algorithmes d'interprétabilité locale, etc. L'analyse de l'importance des fonctionnalités peut expliquer le processus de prise de décision du modèle en évaluant le degré d'influence du modèle sur les fonctionnalités d'entrée. Estimation de l’intervalle de prédiction du modèle
 Identifier le surapprentissage et le sous-apprentissage grâce à des courbes d'apprentissage
Apr 29, 2024 pm 06:50 PM
Identifier le surapprentissage et le sous-apprentissage grâce à des courbes d'apprentissage
Apr 29, 2024 pm 06:50 PM
Cet article présentera comment identifier efficacement le surajustement et le sous-apprentissage dans les modèles d'apprentissage automatique grâce à des courbes d'apprentissage. Sous-ajustement et surajustement 1. Surajustement Si un modèle est surentraîné sur les données de sorte qu'il en tire du bruit, alors on dit que le modèle est en surajustement. Un modèle surajusté apprend chaque exemple si parfaitement qu'il classera mal un exemple inédit/inédit. Pour un modèle surajusté, nous obtiendrons un score d'ensemble d'entraînement parfait/presque parfait et un score d'ensemble/test de validation épouvantable. Légèrement modifié : "Cause du surajustement : utilisez un modèle complexe pour résoudre un problème simple et extraire le bruit des données. Parce qu'un petit ensemble de données en tant qu'ensemble d'entraînement peut ne pas représenter la représentation correcte de toutes les données."
 Transparent! Une analyse approfondie des principes des principaux modèles de machine learning !
Apr 12, 2024 pm 05:55 PM
Transparent! Une analyse approfondie des principes des principaux modèles de machine learning !
Apr 12, 2024 pm 05:55 PM
En termes simples, un modèle d’apprentissage automatique est une fonction mathématique qui mappe les données d’entrée à une sortie prédite. Plus précisément, un modèle d'apprentissage automatique est une fonction mathématique qui ajuste les paramètres du modèle en apprenant à partir des données d'entraînement afin de minimiser l'erreur entre la sortie prédite et la véritable étiquette. Il existe de nombreux modèles dans l'apprentissage automatique, tels que les modèles de régression logistique, les modèles d'arbre de décision, les modèles de machines à vecteurs de support, etc. Chaque modèle a ses types de données et ses types de problèmes applicables. Dans le même temps, il existe de nombreux points communs entre les différents modèles, ou il existe une voie cachée pour l’évolution du modèle. En prenant comme exemple le perceptron connexionniste, en augmentant le nombre de couches cachées du perceptron, nous pouvons le transformer en un réseau neuronal profond. Si une fonction noyau est ajoutée au perceptron, elle peut être convertie en SVM. celui-ci
 L'évolution de l'intelligence artificielle dans l'exploration spatiale et l'ingénierie des établissements humains
Apr 29, 2024 pm 03:25 PM
L'évolution de l'intelligence artificielle dans l'exploration spatiale et l'ingénierie des établissements humains
Apr 29, 2024 pm 03:25 PM
Dans les années 1950, l’intelligence artificielle (IA) est née. C’est à ce moment-là que les chercheurs ont découvert que les machines pouvaient effectuer des tâches similaires à celles des humains, comme penser. Plus tard, dans les années 1960, le Département américain de la Défense a financé l’intelligence artificielle et créé des laboratoires pour poursuivre son développement. Les chercheurs trouvent des applications à l’intelligence artificielle dans de nombreux domaines, comme l’exploration spatiale et la survie dans des environnements extrêmes. L'exploration spatiale est l'étude de l'univers, qui couvre l'ensemble de l'univers au-delà de la terre. L’espace est classé comme environnement extrême car ses conditions sont différentes de celles de la Terre. Pour survivre dans l’espace, de nombreux facteurs doivent être pris en compte et des précautions doivent être prises. Les scientifiques et les chercheurs pensent qu'explorer l'espace et comprendre l'état actuel de tout peut aider à comprendre le fonctionnement de l'univers et à se préparer à d'éventuelles crises environnementales.
 Implémentation d'algorithmes d'apprentissage automatique en C++ : défis et solutions courants
Jun 03, 2024 pm 01:25 PM
Implémentation d'algorithmes d'apprentissage automatique en C++ : défis et solutions courants
Jun 03, 2024 pm 01:25 PM
Les défis courants rencontrés par les algorithmes d'apprentissage automatique en C++ incluent la gestion de la mémoire, le multithread, l'optimisation des performances et la maintenabilité. Les solutions incluent l'utilisation de pointeurs intelligents, de bibliothèques de threads modernes, d'instructions SIMD et de bibliothèques tierces, ainsi que le respect des directives de style de codage et l'utilisation d'outils d'automatisation. Des cas pratiques montrent comment utiliser la bibliothèque Eigen pour implémenter des algorithmes de régression linéaire, gérer efficacement la mémoire et utiliser des opérations matricielles hautes performances.
 Cinq écoles d'apprentissage automatique que vous ne connaissez pas
Jun 05, 2024 pm 08:51 PM
Cinq écoles d'apprentissage automatique que vous ne connaissez pas
Jun 05, 2024 pm 08:51 PM
L'apprentissage automatique est une branche importante de l'intelligence artificielle qui donne aux ordinateurs la possibilité d'apprendre à partir de données et d'améliorer leurs capacités sans être explicitement programmés. L'apprentissage automatique a un large éventail d'applications dans divers domaines, de la reconnaissance d'images et du traitement du langage naturel aux systèmes de recommandation et à la détection des fraudes, et il change notre façon de vivre. Il existe de nombreuses méthodes et théories différentes dans le domaine de l'apprentissage automatique, parmi lesquelles les cinq méthodes les plus influentes sont appelées les « Cinq écoles d'apprentissage automatique ». Les cinq grandes écoles sont l’école symbolique, l’école connexionniste, l’école évolutionniste, l’école bayésienne et l’école analogique. 1. Le symbolisme, également connu sous le nom de symbolisme, met l'accent sur l'utilisation de symboles pour le raisonnement logique et l'expression des connaissances. Cette école de pensée estime que l'apprentissage est un processus de déduction inversée, à travers les connaissances existantes.
 IA explicable : Expliquer les modèles IA/ML complexes
Jun 03, 2024 pm 10:08 PM
IA explicable : Expliquer les modèles IA/ML complexes
Jun 03, 2024 pm 10:08 PM
Traducteur | Revu par Li Rui | Chonglou Les modèles d'intelligence artificielle (IA) et d'apprentissage automatique (ML) deviennent aujourd'hui de plus en plus complexes, et le résultat produit par ces modèles est une boîte noire – impossible à expliquer aux parties prenantes. L'IA explicable (XAI) vise à résoudre ce problème en permettant aux parties prenantes de comprendre comment fonctionnent ces modèles, en s'assurant qu'elles comprennent comment ces modèles prennent réellement des décisions et en garantissant la transparence des systèmes d'IA, la confiance et la responsabilité pour résoudre ce problème. Cet article explore diverses techniques d'intelligence artificielle explicable (XAI) pour illustrer leurs principes sous-jacents. Plusieurs raisons pour lesquelles l’IA explicable est cruciale Confiance et transparence : pour que les systèmes d’IA soient largement acceptés et fiables, les utilisateurs doivent comprendre comment les décisions sont prises
