

La technologie de l'IA se développe rapidement. Grâce à divers modèles d'IA avancés, des robots de discussion, des robots humanoïdes, des voitures autonomes, etc. peuvent être construits. L’IA est devenue la technologie qui connaît la croissance la plus rapide, et la détection et la classification des objets sont des tendances récentes.
Cet article présentera les étapes complètes de création et de formation d'un modèle de classification d'images à partir de zéro à l'aide d'un réseau neuronal convolutif. Cet article utilisera l'ensemble de données publiques Cifar-10 pour entraîner ce modèle. Cet ensemble de données est unique car il contient des images d'objets du quotidien comme des voitures, des avions, des chiens, des chats, etc. En entraînant un réseau de neurones sur ces objets, cet article développera un système intelligent pour classer ces objets dans le monde réel. Il contient plus de 60 000 images 32x32 de 10 types d'objets différents. À la fin de ce didacticiel, vous disposerez d'un modèle capable d'identifier des objets en fonction de leurs caractéristiques visuelles.

Figure 1 Exemple d'image d'ensemble de données | Image de datasets.activeloop
Cet article couvrira tout depuis le début, donc si vous n'avez pas appris la mise en œuvre réelle des réseaux de neurones, c'est tout à fait bien.
Voici le flux de travail complet de ce tutoriel :
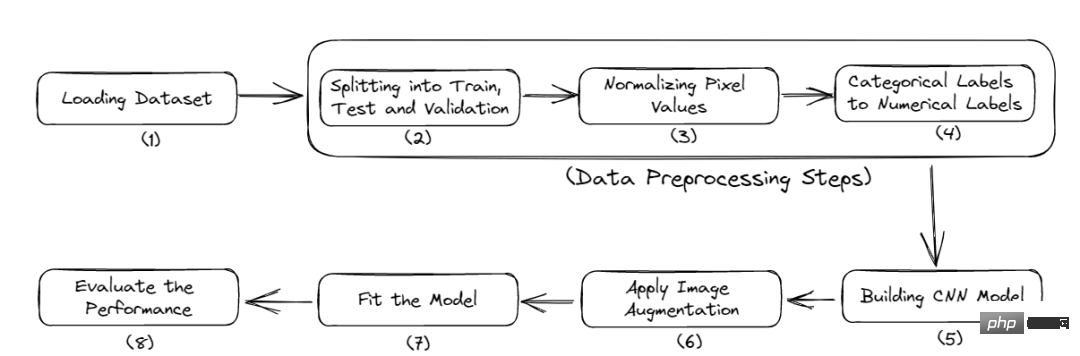
Figure 2 Processus complet
Vous devez d'abord installer quelques modules pour démarrer ce projet. Cet article utilisera Google Colab car il propose une formation GPU gratuite.
Voici les commandes pour installer les bibliothèques requises :
<code>$ pip install tensorflow, numpy, keras, sklearn, matplotlib</code>
Importez les bibliothèques dans le fichier Python.
<code>from numpy import *from pandas import *import matplotlib.pyplot as plotter# 将数据分成训练集和测试集。from sklearn.model_selection import train_test_split# 用来评估我们的训练模型的库。from sklearn.metrics import classification_report, confusion_matriximport keras# 加载我们的数据集。from keras.datasets import cifar10# 用于数据增量。from keras.preprocessing.image import ImageDataGenerator# 下面是一些用于训练卷积Nueral网络的层。from keras.models import Sequentialfrom keras.layers import Dense, Dropout, Activationfrom keras.layers import Conv2D, MaxPooling2D, GlobalMaxPooling2D, Flatten</code>
Maintenant, entrez dans l'étape de chargement des données.
Cette section chargera l'ensemble de données et effectuera la répartition des données de test d'entraînement.
Chargement et fractionnement des données : l'ensemble de données
<code># 类的数量nc = 10(training_data, training_label), (testing_data, testing_label) = cifar10.load_data()((training_data),(validation_data),(training_label),(validation_label),) = train_test_split(training_data, training_label, test_size=0.2, random_state=42)training_data = training_data.astype("float32")testing_data = testing_data.astype("float32")validation_data = validation_data.astype("float32")</code>cifar10 est chargé directement à partir de la bibliothèque d'ensembles de données Keras. Et ces données sont également divisées en données de formation et données de test. Les données d'entraînement sont utilisées pour entraîner le modèle afin qu'il puisse y reconnaître des modèles. Bien que les données de test soient invisibles pour le modèle, elles sont utilisées pour vérifier ses performances, c'est-à-dire combien de points de données sont correctement prédits par rapport au nombre total de points de données.
training_label contient les étiquettes correspondant aux images dans training_data.
Utilisez ensuite la fonction train_test_split intégrée de sklearn pour diviser à nouveau les données d'entraînement en données de validation. Les données de validation ont été utilisées pour sélectionner et régler le modèle final. Enfin, toutes les données de formation, de test et de validation sont converties en nombres à virgule flottante 32 bits.
Maintenant, le chargement de l'ensemble de données est terminé. Dans la section suivante, cet article effectue quelques étapes de prétraitement.
Le prétraitement des données est la première et la plus critique étape lors du développement d'un modèle d'apprentissage automatique. Suivez cet article pour savoir comment procéder.
<code># 归一化training_data /= 255testing_data /= 255validation_data /= 255# 热编码training_label = keras.utils.to_categorical(training_label, nc)testing_label = keras.utils.to_categorical(testing_label, nc)validation_label = keras.utils.to_categorical(validation_label, nc)# 输出数据集print("Training: ", training_data.shape, len(training_label))print("Validation: ", validation_data.shape, len(validation_label))print("Testing: ", testing_data.shape, len(testing_label))</code>Sortie :
<code>Training:(40000, 32, 32, 3) 40000Validation:(10000, 32, 32, 3) 10000Testing:(10000, 32, 32, 3) 10000</code>
Cet ensemble de données contient des images de 10 catégories, chaque image mesure 32 x 32 pixels. Chaque pixel a une valeur comprise entre 0 et 255 et nous devons la normaliser entre 0 et 1 pour simplifier le processus de calcul. Après cela, nous convertirons les étiquettes catégorielles en étiquettes codées à chaud. Ceci est fait pour convertir les données catégorielles en données numériques afin que nous puissions appliquer des algorithmes d'apprentissage automatique sans aucun problème.
Maintenant, entrez dans la construction du modèle CNN.
Le modèle CNN fonctionne en trois étapes. La première étape consiste en des couches convolutives pour extraire les caractéristiques pertinentes de l'image. La deuxième étape consiste à regrouper les calques pour réduire la taille de l’image. Cela permet également de réduire le surapprentissage du modèle. La troisième étape consiste en des couches denses qui convertissent l'image 2D en un tableau 1D. Enfin, ce tableau est introduit dans la couche entièrement connectée pour effectuer la prédiction finale.
Voici le code :
<code>model = Sequential()model.add(Conv2D(32, (3, 3), padding="same", activatinotallow="relu", input_shape=(32, 32, 3)))model.add(Conv2D(32, (3, 3), padding="same", activatinotallow="relu"))model.add(MaxPooling2D((2, 2)))model.add(Dropout(0.25))model.add(Conv2D(64, (3, 3), padding="same", activatinotallow="relu"))model.add(Conv2D(64, (3, 3), padding="same", activatinotallow="relu"))model.add(MaxPooling2D((2, 2)))model.add(Dropout(0.25))model.add(Conv2D(96, (3, 3), padding="same", activatinotallow="relu"))model.add(Conv2D(96, (3, 3), padding="same", activatinotallow="relu"))model.add(MaxPooling2D((2, 2)))model.add(Flatten())model.add(Dropout(0.4))model.add(Dense(256, activatinotallow="relu"))model.add(Dropout(0.4))model.add(Dense(128, activatinotallow="relu"))model.add(Dropout(0.4))model.add(Dense(nc, activatinotallow="softmax"))</code>
Cet article applique trois ensembles de couches, chaque ensemble contient deux couches convolutives, une couche de pooling maximum et une couche d'abandon. La couche Conv2D reçoit input_shape sous la forme (32, 32, 3), qui doit avoir la même taille que l'image.
Chaque couche Conv2D a également besoin d'une fonction d'activation, à savoir relu. Les fonctions d'activation sont utilisées pour augmenter la non-linéarité du système. Plus simplement, il détermine si un neurone doit être activé en fonction d’un certain seuil. Il existe de nombreux types de fonctions d'activation, telles que ReLu, Tanh, Sigmoid, Softmax, etc., qui utilisent différents algorithmes pour déterminer l'activation des neurones.
之后,添加了平坦层和全连接层,在它们之间还有几个Dropout层。Dropout层随机地拒绝一些神经元对网层的贡献。它里面的参数定义了拒绝的程度。它主要用于避免过度拟合。
下面是一个CNN模型架构的示例图像。
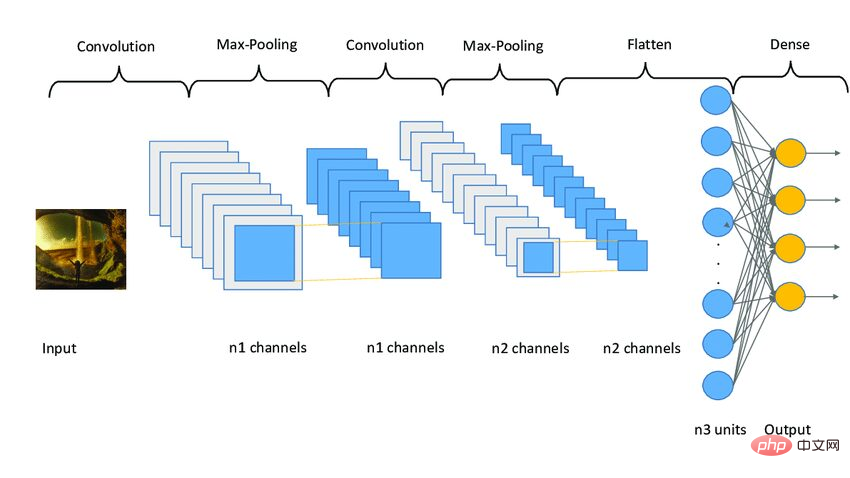
图3 Sampe CNN架构|图片来源:Researchgate
现在,本文将编译和准备训练的模型。
<code># 启动Adam优化器opt = keras.optimizers.Adam(lr=0.0001)model.compile(loss="categorical_crossentropy", optimizer=opt, metrics=["accuracy"])# 获得模型的摘要model.summary()</code>
输出:

图4 模型摘要
本文使用了学习率为0.0001的Adam优化器。优化器决定了模型的行为如何响应损失函数的输出而变化。学习率是训练期间更新权重的数量或步长。它是一个可配置的超参数,不能太小或太大。
现在,本文将把模型拟合到我们的训练数据,并开始训练过程。但在此之前,本文将使用图像增强技术来增加样本图像的数量。
卷积神经网络中使用的图像增强技术将增加训练图像,而不需要新的图像。它将通过在图像中产生一定量的变化来复制图像。它可以通过将图像旋转到一定程度、添加噪声、水平或垂直翻转等方式来实现。
<code>augmentor = ImageDataGenerator(width_shift_range=0.4,height_shift_range=0.4,horizontal_flip=False,vertical_flip=True,)# 在augmentor中进行拟合augmentor.fit(training_data)# 获得历史数据history = model.fit(augmentor.flow(training_data, training_label, batch_size=32),epochs=100,validation_data=(validation_data, validation_label),)</code>
输出:

图5 每个时期的准确度和损失
ImageDataGenerator()函数用于创建增强的图像。fit()用于拟合模型。它以训练和验证数据、Batch Size和Epochs的数量作为输入。
Batch Size是在模型更新之前处理的样本数量。一个关键的超参数必须大于等于1且小于等于样本数。通常情况下,32或64被认为是最好的Batch Size。
Epochs的数量代表了所有样本在网络的前向和后向都被单独处理了多少次。100个epochs意味着整个数据集通过模型100次,模型本身运行100次。
我们的模型已经训练完毕,现在我们将评估它在测试集上的表现。
本节将在测试集上检查模型的准确性和损失。此外,本文还将绘制训练和验证数据的准确率与时间之间和损失与时间之间的关系图。
<code>model.evaluate(testing_data, testing_label)</code>
输出:
<code>313/313 [==============================] - 2s 5ms/step - loss: 0.8554 - accuracy: 0.7545[0.8554493188858032, 0.7545000195503235]</code>
本文的模型达到了75.34%的准确率,损失为0.8554。这个准确率还可以提高,因为这不是一个最先进的模型。本文用这个模型来解释建立模型的过程和流程。CNN模型的准确性取决于许多因素,如层的选择、超参数的选择、使用的数据集的类型等。
现在我们将绘制曲线来检查模型中的过度拟合情况。
<code>def acc_loss_curves(result, epochs):acc = result.history["accuracy"]# 获得损失和准确性loss = result.history["loss"]# 声明损失和准确度的值val_acc = result.history["val_accuracy"]val_loss = result.history["val_loss"]# 绘制图表plotter.figure(figsize=(15, 5))plotter.subplot(121)plotter.plot(range(1, epochs), acc[1:], label="Train_acc")plotter.plot(range(1, epochs), val_acc[1:], label="Val_acc")# 给予绘图的标题plotter.title("Accuracy over " + str(epochs) + " Epochs", size=15)plotter.legend()plotter.grid(True)# 传递值122plotter.subplot(122)# 使用训练损失plotter.plot(range(1, epochs), loss[1:], label="Train_loss")plotter.plot(range(1, epochs), val_loss[1:], label="Val_loss")# 使用 ephocsplotter.title("Loss over " + str(epochs) + " Epochs", size=15)plotter.legend()# 传递真值plotter.grid(True)# 打印图表plotter.show()acc_loss_curves(history, 100)</code>输出:
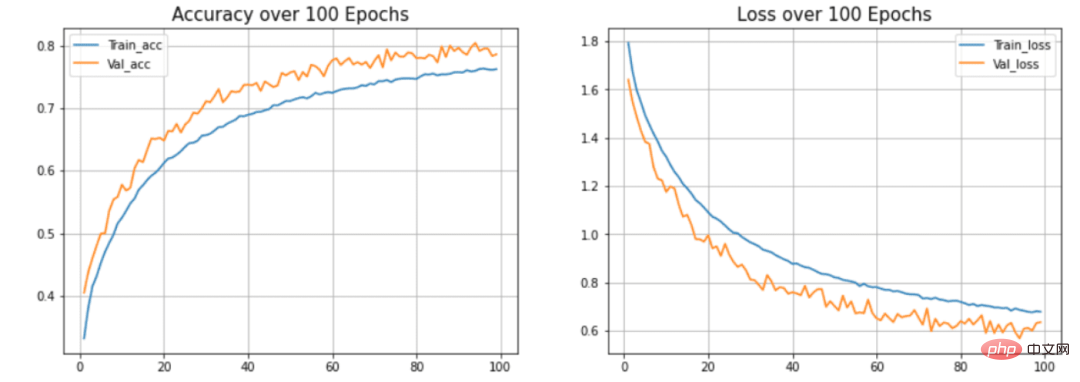
图6 准确度和损失与历时的关系
在本文的模型中,可以看到模型过度拟合测试数据集。(蓝色)线表示训练精度,(橙色)线表示验证精度。训练精度持续提高,但验证误差在20个历时后恶化。
本文展示了构建和训练卷积神经网络的整个过程。最终得到了大约75%的准确率。你可以使用超参数并使用不同的卷积层和池化层来提高准确性。你也可以尝试迁移学习,它使用预先训练好的模型,如ResNet或VGGNet,并在某些情况下可以提供非常好的准确性。
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Comment lire les fichiers py en python
Comment lire les fichiers py en python
 Pourquoi ne puis-je pas accéder au navigateur Ethereum ?
Pourquoi ne puis-je pas accéder au navigateur Ethereum ?
 Comment utiliser l'instruction insert dans MySQL
Comment utiliser l'instruction insert dans MySQL
 barre de défilement div
barre de défilement div
 Comment exporter un mot depuis PowerDesigner
Comment exporter un mot depuis PowerDesigner
 Quelle est la différence entre webstorm et idée ?
Quelle est la différence entre webstorm et idée ?
 Comment s'inscrire sur Matcha Exchange
Comment s'inscrire sur Matcha Exchange
 utilisation du stockage local
utilisation du stockage local
 Que dois-je faire si mon iPad ne peut pas être chargé ?
Que dois-je faire si mon iPad ne peut pas être chargé ?








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



