

ChatGPT sujet un historique de l'évolution de la famille GPT

Timeline
Juin 2018
OpenAI publie le modèle GPT-1 avec 110 millions de paramètres.
En novembre 2018
OpenAI a publié le modèle GPT-2 avec 1,5 milliard de paramètres, mais en raison de problèmes d'abus, l'ensemble du code et des données du modèle ne sont pas ouverts au public.
Février 2019
OpenAI a ouvert certains codes et données du modèle GPT-2, mais l'accès est toujours restreint.
10 juin 2019
OpenAI a publié le modèle GPT-3 avec 175 milliards de paramètres et a donné accès à certains partenaires.
Septembre 2019
OpenAI a ouvert tout le code et les données de GPT-2 et a publié une version plus grande.
Mai 2020
OpenAI a annoncé le lancement de la version bêta du modèle GPT-3, qui compte 175 milliards de paramètres et est le plus grand modèle de traitement du langage naturel à ce jour.
Mars 2022
OpenAI a publié InstructGPT, en utilisant Instruction Tuning
30 novembre 2022
OpenAI a affiné la série GPT-3.5 de grands modèles de langage et le nouveau modèle d'IA conversationnelle ChatGPT a été officiellement publié.
15 décembre 2022
ChatGPT est mis à jour pour la première fois, améliorant les performances globales et ajoutant de nouvelles fonctionnalités pour enregistrer et afficher les enregistrements historiques des conversations.
9 janvier 2023
ChatGPT est mis à jour pour la deuxième fois, améliorant l'authenticité des réponses et ajoutant une nouvelle fonction "arrêter la génération".
21 janvier 2023
OpenAI a publié une version payante de ChatGPT Professional limitée à certains utilisateurs.
30 janvier 2023
ChatGPT est mis à jour pour la troisième fois, ce qui améliore non seulement l'authenticité des réponses, mais améliore également les compétences mathématiques.
2 février 2023
OpenAI a officiellement lancé le service d'abonnement à la version payante ChatGPT Par rapport à la version gratuite, la nouvelle version répond plus rapidement et fonctionne de manière plus stable.
15 mars 2023
OpenAI a lancé de manière choquante le modèle multimodal à grande échelle GPT-4, qui peut non seulement lire du texte, mais également reconnaître des images et générer des résultats de texte. Il est désormais connecté à ChatGPT et est ouvert à Plus. utilisateurs.
GPT-1 : modèle pré-entraîné basé sur un transformateur unidirectionnel
Avant l'émergence de GPT, les modèles NLP étaient principalement entraînés sur la base de grandes quantités de données annotées pour des tâches spécifiques. Cela entraînera certaines limitations :
Les données d'annotation à grande échelle et de haute qualité ne sont pas faciles à obtenir ;
Le modèle est limité à la formation qu'il a reçue et sa capacité de généralisation est insuffisante ; tâches prêtes à l'emploi, limitant l'application du modèle.
Afin de surmonter ces problèmes, OpenAI s'est engagé dans la voie du pré-entraînement de grands modèles. GPT-1 est le premier modèle pré-entraîné publié par OpenAI en 2018. Il adopte un modèle Transformer unidirectionnel et utilise plus de 40 Go de données texte pour l'entraînement. Les principales caractéristiques de GPT-1 sont : pré-formation générative (non supervisée) + réglage fin des tâches discriminantes (supervisé). Tout d'abord, nous avons utilisé une pré-formation d'apprentissage non supervisée et avons passé 1 mois sur 8 GPU pour améliorer les capacités linguistiques du système d'IA à partir d'une grande quantité de données non étiquetées et obtenir une grande quantité de connaissances. Ensuite, nous avons effectué un réglage fin et supervisé. l'a comparé à de grands ensembles de données intégrés pour améliorer les performances du système dans les tâches PNL. GPT-1 a montré d'excellentes performances dans les tâches de génération et de compréhension de texte, devenant ainsi l'un des modèles de traitement du langage naturel les plus avancés à l'époque.
GPT-2 : Modèle de pré-formation multitâche
En raison du manque de généralisation des modèles monotâches et de la nécessité d'un grand nombre de paires de formation efficaces pour l'apprentissage multitâche, GPT-2 est étendu et optimisé sur la base de GPT-1, l'apprentissage supervisé est supprimé et seul l'apprentissage non supervisé est conservé. GPT-2 utilise des données textuelles plus volumineuses et des ressources informatiques plus puissantes pour la formation, et la taille des paramètres atteint 150 millions, dépassant de loin les 110 millions de paramètres de GPT-1. En plus d'utiliser des ensembles de données plus volumineux et des modèles plus volumineux pour apprendre, GPT-2 propose également une nouvelle tâche plus difficile : l'apprentissage sans tir (zéro-shot), qui consiste à appliquer directement des modèles pré-entraînés à de nombreuses tâches en aval. GPT-2 a démontré d'excellentes performances sur plusieurs tâches de traitement du langage naturel, notamment la génération de texte, la classification de texte, la compréhension du langage, etc.
 GPT-3 : Créez de nouvelles capacités de génération et de compréhension du langage naturel
GPT-3 : Créez de nouvelles capacités de génération et de compréhension du langage naturel
GPT-3 est le dernier modèle de la série de modèles GPT, utilisant une plus grande échelle de paramètres et des données d'entraînement plus riches. L’échelle des paramètres du GPT-3 atteint 1 750 milliards, soit plus de 100 fois celle du GPT-2. GPT-3 a montré des capacités étonnantes en matière de génération de langage naturel, de génération de dialogues et d'autres tâches de traitement du langage. Dans certaines tâches, il peut même créer de nouvelles formes d'expression du langage.
GPT-3 propose un concept très important : l'apprentissage en contexte. Le contenu spécifique sera expliqué dans le prochain tweet.
InstructGPT & ChatGPT
La formation d'InstructGPT/ChatGPT est divisée en 3 étapes, et les données requises pour chaque étape sont légèrement différentes. Présentons-les séparément ci-dessous.
Commencez avec un modèle linguistique pré-entraîné et appliquez les trois étapes suivantes.
Étape 1 : Affinement supervisé SFT : Collectez des données de démonstration et formez une politique supervisée. Notre tagger fournit une démonstration du comportement souhaité sur la distribution des invites de saisie. Nous affinons ensuite le modèle GPT-3 pré-entraîné sur ces données à l'aide d'un apprentissage supervisé.
Étape 2 : Récompenser la formation du modèle. Collectez des données comparatives et formez un modèle de récompense. Nous avons collecté un ensemble de données de comparaisons entre les sorties du modèle, dans lequel les étiqueteurs indiquent quelle sortie ils préfèrent pour une entrée donnée. Nous formons ensuite un modèle de récompense pour prédire les résultats préférés des humains.
Étape 3 : Apprentissage par renforcement via l'optimisation de politique proximale (PPO) sur le modèle de récompense : utilisez la sortie de RM comme récompense scalaire. Nous utilisons l'algorithme PPO pour affiner la stratégie de supervision afin d'optimiser cette récompense.
Les étapes 2 et 3 peuvent être répétées en continu ; davantage de données de comparaison sont collectées sur la stratégie optimale actuelle, qui sont utilisées pour former un nouveau RM, puis une nouvelle stratégie.
Les invites des deux premières étapes proviennent des données d'utilisation des utilisateurs sur l'API en ligne d'OpenAI et sont écrites à la main par des annotateurs embauchés. La dernière étape est entièrement échantillonnée à partir des données API. Les données spécifiques d'InstructGPT :
1 L'ensemble de données SFT est-il. est utilisé pour entraîner le modèle supervisé dans la première étape, c'est-à-dire en utilisant les nouvelles données collectées pour affiner GPT-3 selon la méthode d'entraînement de GPT-3. Étant donné que GPT-3 est un modèle génératif basé sur un apprentissage rapide, l'ensemble de données SFT est également un échantillon composé de paires invite-réponse. Une partie des données SFT provient des utilisateurs de PlayGround d’OpenAI, et l’autre partie provient des 40 étiqueteurs employés par OpenAI. Et ils ont formé l’étiqueteur. Dans cet ensemble de données, le travail de l'annotateur consiste à rédiger lui-même des instructions en fonction du contenu.
2. Ensemble de données RM
L'ensemble de données RM est utilisé pour entraîner le modèle de récompense à l'étape 2. Nous devons également fournir InstructGPT /ChatGPT Fixez un objectif de récompense pour l'entraînement. Cet objectif de récompense ne doit pas nécessairement être différenciable, mais il doit s'aligner de manière aussi complète et réaliste que possible sur ce que le modèle doit générer. Naturellement, nous pouvons fournir cette récompense via une annotation manuelle. Grâce à un couplage artificiel, nous pouvons attribuer des scores inférieurs au contenu généré impliquant des biais pour encourager le modèle à ne pas générer de contenu que les humains n'aiment pas. L'approche d'InstructGPT/ChatGPT consiste d'abord à laisser le modèle générer un lot de textes candidats, puis à utiliser l'étiqueteur pour trier le contenu généré en fonction de la qualité des données générées.
3. L'ensemble de données PPO
Les données PPO d'InstructGPT ne sont pas annotées, elles proviennent des utilisateurs de l'API GPT-3. Il existe différents types de tâches de génération fournies par différents utilisateurs, la proportion la plus élevée comprenant les tâches de génération (45,6 %), l'assurance qualité (12,4 %), le brainstorming (11,2 %), le dialogue (8,4 %), etc. # 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 # Pièce jointe: # 🎜🎜 ## 🎜🎜 # Diverses sources de capacités de Chatgpt: # 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 # # 🎜🎜 🎜🎜 #
Les capacités et méthodes de formation de GPT-3 à ChatGPT et les versions itératives intermédiaires :#🎜🎜 #
Références1 Démantèlement et traçage de l'origine de diverses fonctionnalités de GPT-3.5 : https://yaofu.notion.site/GPT-3-5-360081d91ec245f29029d37b54573756# 🎜🎜#.2. La timeline la plus complète de tout le réseau ! Du passé et du présent de ChatGPT au paysage concurrentiel actuel dans le domaine de l'IA https://www.bilibili.com/read/cv22541079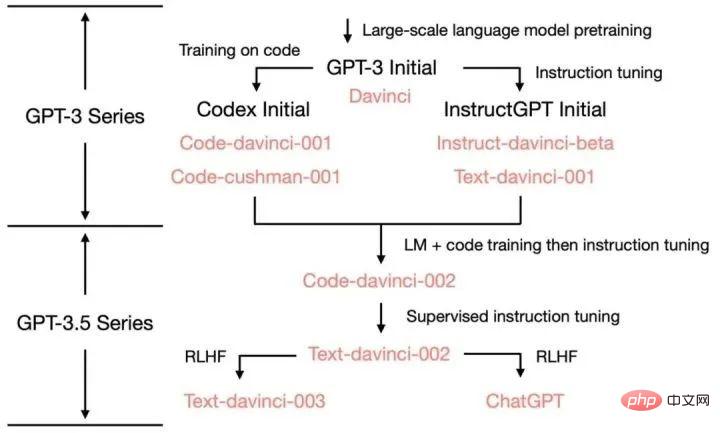
 6、Jason W, Maarten B, Vincent Y et al. Les modèles de langage affinés sont des apprenants Zero-Shot[J]. 🎜##🎜🎜 #7. Comment OpenAI a-t-il « optimisé » GPT ? ——Instruire l'interprétation du papier GPT https://cloud.tencent.com/developer/news/979148
6、Jason W, Maarten B, Vincent Y et al. Les modèles de langage affinés sont des apprenants Zero-Shot[J]. 🎜##🎜🎜 #7. Comment OpenAI a-t-il « optimisé » GPT ? ——Instruire l'interprétation du papier GPT https://cloud.tencent.com/developer/news/979148
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 ChatGPT permet désormais aux utilisateurs gratuits de générer des images en utilisant DALL-E 3 avec une limite quotidienne
Aug 09, 2024 pm 09:37 PM
ChatGPT permet désormais aux utilisateurs gratuits de générer des images en utilisant DALL-E 3 avec une limite quotidienne
Aug 09, 2024 pm 09:37 PM
Le DALL-E 3 a été officiellement introduit en septembre 2023 en tant que modèle considérablement amélioré par rapport à son prédécesseur. Il est considéré comme l’un des meilleurs générateurs d’images IA à ce jour, capable de créer des images avec des détails complexes. Cependant, au lancement, c'était exclu
 YOLO est immortel ! YOLOv9 est sorti : performances et vitesse SOTA~
Feb 26, 2024 am 11:31 AM
YOLO est immortel ! YOLOv9 est sorti : performances et vitesse SOTA~
Feb 26, 2024 am 11:31 AM
Les méthodes d'apprentissage profond d'aujourd'hui se concentrent sur la conception de la fonction objectif la plus appropriée afin que les résultats de prédiction du modèle soient les plus proches de la situation réelle. Dans le même temps, une architecture adaptée doit être conçue pour obtenir suffisamment d’informations pour la prédiction. Les méthodes existantes ignorent le fait que lorsque les données d’entrée subissent une extraction de caractéristiques couche par couche et une transformation spatiale, une grande quantité d’informations sera perdue. Cet article abordera des problèmes importants lors de la transmission de données via des réseaux profonds, à savoir les goulots d'étranglement de l'information et les fonctions réversibles. Sur cette base, le concept d'information de gradient programmable (PGI) est proposé pour faire face aux différents changements requis par les réseaux profonds pour atteindre des objectifs multiples. PGI peut fournir des informations d'entrée complètes pour la tâche cible afin de calculer la fonction objectif, obtenant ainsi des informations de gradient fiables pour mettre à jour les pondérations du réseau. De plus, un nouveau cadre de réseau léger est conçu
 La combinaison parfaite de ChatGPT et Python : créer un chatbot de service client intelligent
Oct 27, 2023 pm 06:00 PM
La combinaison parfaite de ChatGPT et Python : créer un chatbot de service client intelligent
Oct 27, 2023 pm 06:00 PM
La combinaison parfaite de ChatGPT et Python : Création d'un chatbot de service client intelligent Introduction : À l'ère de l'information d'aujourd'hui, les systèmes de service client intelligents sont devenus un outil de communication important entre les entreprises et les clients. Afin d'offrir une meilleure expérience de service client, de nombreuses entreprises ont commencé à se tourner vers les chatbots pour effectuer des tâches telles que la consultation des clients et la réponse aux questions. Dans cet article, nous présenterons comment utiliser le puissant modèle ChatGPT et le langage Python d'OpenAI pour créer un chatbot de service client intelligent afin d'améliorer
 Comment installer chatgpt sur un téléphone mobile
Mar 05, 2024 pm 02:31 PM
Comment installer chatgpt sur un téléphone mobile
Mar 05, 2024 pm 02:31 PM
Étapes d'installation : 1. Téléchargez le logiciel ChatGTP depuis le site officiel ou la boutique mobile de ChatGTP ; 2. Après l'avoir ouvert, dans l'interface des paramètres, sélectionnez la langue chinoise 3. Dans l'interface de jeu, sélectionnez le jeu homme-machine et définissez la langue. Spectre chinois ; 4. Après avoir démarré, entrez les commandes dans la fenêtre de discussion pour interagir avec le logiciel.
 L'arme ultime pour le débogage de Kubernetes : K8sGPT
Feb 26, 2024 am 11:40 AM
L'arme ultime pour le débogage de Kubernetes : K8sGPT
Feb 26, 2024 am 11:40 AM
À mesure que les technologies d’intelligence artificielle et d’apprentissage automatique continuent de se développer, les entreprises et les organisations ont commencé à explorer activement des stratégies innovantes pour tirer parti de ces technologies afin d’améliorer leur compétitivité. K8sGPT[2] est l'un des outils les plus puissants dans ce domaine. Il s'agit d'un modèle GPT basé sur k8s, qui combine les avantages de l'orchestration k8s avec les excellentes capacités de traitement du langage naturel du modèle GPT. Qu'est-ce que K8sGPT ? Regardons d'abord un exemple : Selon le site officiel de K8sGPT : K8sgpt est un outil conçu pour analyser, diagnostiquer et classer les problèmes du cluster Kubernetes. Il intègre l'expérience SRE dans son moteur d'analyse pour fournir les informations les plus pertinentes. Grâce à l'application de la technologie de l'intelligence artificielle, K8sgpt continue d'enrichir son contenu et d'aider les utilisateurs à comprendre plus rapidement et plus précisément.
 1,3 ms prend 1,3 ms ! La dernière architecture de réseau neuronal mobile open source de Tsinghua, RepViT
Mar 11, 2024 pm 12:07 PM
1,3 ms prend 1,3 ms ! La dernière architecture de réseau neuronal mobile open source de Tsinghua, RepViT
Mar 11, 2024 pm 12:07 PM
Adresse papier : https://arxiv.org/abs/2307.09283 Adresse code : https://github.com/THU-MIG/RepViTRepViT fonctionne bien dans l'architecture ViT mobile et présente des avantages significatifs. Ensuite, nous explorons les contributions de cette étude. Il est mentionné dans l'article que les ViT légers fonctionnent généralement mieux que les CNN légers sur les tâches visuelles, principalement en raison de leur module d'auto-attention multi-têtes (MSHA) qui permet au modèle d'apprendre des représentations globales. Cependant, les différences architecturales entre les ViT légers et les CNN légers n'ont pas été entièrement étudiées. Dans cette étude, les auteurs ont intégré des ViT légers dans le système efficace.
 Dois-je choisir MBR ou GPT comme format de disque dur pour Win7 ?
Jan 03, 2024 pm 08:09 PM
Dois-je choisir MBR ou GPT comme format de disque dur pour Win7 ?
Jan 03, 2024 pm 08:09 PM
Lorsque nous utilisons le système d'exploitation Win7, nous pouvons parfois rencontrer des situations dans lesquelles nous devons réinstaller le système et partitionner le disque dur. Concernant la question de savoir si le format de disque dur win7 nécessite mbr ou gpt, l'éditeur pense que vous devez toujours faire un choix en fonction des détails de votre propre configuration système et matérielle. En termes de compatibilité, il est préférable de choisir le format mbr. Pour plus de détails, regardons ce que l'éditeur a fait ~ Le format de disque dur win7 nécessite mbr ou gpt1 Si le système est installé avec Win7, il est recommandé d'utiliser MBR, qui a une bonne compatibilité. 2. S'il dépasse 3T ou si vous installez Win8, vous pouvez utiliser GPT. 3. Bien que GPT soit effectivement plus avancé que MBR, MBR est définitivement invincible en termes de compatibilité. Zones GPT et MBR
 Compréhension approfondie du format de partition Win10 : comparaison GPT et MBR
Dec 22, 2023 am 11:58 AM
Compréhension approfondie du format de partition Win10 : comparaison GPT et MBR
Dec 22, 2023 am 11:58 AM
Lors du partitionnement de leurs propres systèmes, en raison des différents disques durs utilisés par les utilisateurs, de nombreux utilisateurs ne connaissent pas le format de partition win10 gpt ou mbr. Pour cette raison, nous vous avons présenté une introduction détaillée pour vous aider à comprendre la différence entre les deux. Format de partition Win10 gpt ou mbr : Réponse : Si vous utilisez un disque dur dépassant 3 To, vous pouvez utiliser gpt. gpt est plus avancé que mbr, mais mbr est toujours meilleur en termes de compatibilité. Bien entendu, cela peut également être choisi en fonction des préférences de l'utilisateur. La différence entre gpt et mbr : 1. Nombre de partitions prises en charge : 1. MBR prend en charge jusqu'à 4 partitions principales. 2. GPT n'est pas limité par le nombre de partitions. 2. Taille de disque dur prise en charge : 1. MBR ne prend en charge que jusqu'à 2 To.
