

Comment utiliser Python pour XPath, JsonPath et bs4 ?

1.xpath
1.1 xpath utiliser
google installez le plug-in xpath à l'avance, appuyez sur ctrl + shift + x et une petite boîte noire apparaîtra
Install lxml library
pip install lxml ‐i https://pypi.douban.com/simple# 🎜🎜#pip install lxml ‐i https://pypi.douban.com/simple导入lxml.etree
from lxml import etreeetree.parse() 解析本地文件
html_tree = etree.parse('XX.html')etree.HTML() 服务器响应文件
html_tree = etree.HTML(response.read().decode('utf‐8')import lxml.etree- etree.parse( ) analyser les fichiers locaux
depuis lxml import etree html_tree = etree.parse('XX.html')
etree.HTML() Fichier de réponses du serveur html_tree = etree.HTML(response .read().decode('utf‐8')
-
.html_tree.xpath(chemin xpath)#🎜 🎜#
# 🎜🎜# 1.2 Syntaxe XPath de base 1. Requête de chemin
Trouver tous les nœuds descendants , quelle que soit la relation hiérarchique #🎜 🎜#
Trouver un nœud enfant direct 2.3. Requête d'attributs
//div[@id] //div[@id="maincontent"]
4. Requête floue
//@class
5. #
//div[contains(@id, "he")] //div[starts‐with(@id, "he")]
//div/h2/text()
//div[@id="head" and @class="s_down"] //title | //price
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8"/>
<title>Title</title>
</head>
<body>
<ul>
<li id="l1" class="class1">北京</li>
<li id="l2" class="class2">上海</li>
<li id="d1">广州</li>
<li>深圳</li>
</ul>
</body>
</html>1.5 Images rampantes des documents pour les webmastersfrom lxml import etree
# xpath解析
# 本地文件: etree.parse
# 服务器相应的数据 response.read().decode('utf-8') etree.HTML()
tree = etree.parse('xpath.html')
# 查找url下边的li
li_list = tree.xpath('//body/ul/li')
print(len(li_list)) # 4
# 获取标签中的内容
li_list = tree.xpath('//body/ul/li/text()')
print(li_list) # ['北京', '上海', '广州', '深圳']
# 获取带id属性的li
li_list = tree.xpath('//ul/li[@id]')
print(len(li_list)) # 3
# 获取id为l1的标签内容
li_list = tree.xpath('//ul/li[@id="l1"]/text()')
print(li_list) # ['北京']
# 获取id为l1的class属性值
c1 = tree.xpath('//ul/li[@id="l1"]/@class')
print(c1) # ['class1']
# 获取id中包含l的标签
li_list = tree.xpath('//ul/li[contains(@id, "l")]/text()')
print(li_list) # ['北京', '上海']
# 获取id以d开头的标签
li_list = tree.xpath('//ul/li[starts-with(@id,"d")]/text()')
print(li_list) # ['广州']
# 获取id为l2并且class为class2的标签
li_list = tree.xpath('//ul/li[@id="l2" and @class="class2"]/text()')
print(li_list) # ['上海']
# 获取id为l2或id为d1的标签
li_list = tree.xpath('//ul/li[@id="l2"]/text() | //ul/li[@id="d1"]/text()')
print(li_list) # ['上海', '广州']
Copier après la connexion
2.1. pip installation#🎜🎜 #from lxml import etree # xpath解析 # 本地文件: etree.parse # 服务器相应的数据 response.read().decode('utf-8') etree.HTML() tree = etree.parse('xpath.html') # 查找url下边的li li_list = tree.xpath('//body/ul/li') print(len(li_list)) # 4 # 获取标签中的内容 li_list = tree.xpath('//body/ul/li/text()') print(li_list) # ['北京', '上海', '广州', '深圳'] # 获取带id属性的li li_list = tree.xpath('//ul/li[@id]') print(len(li_list)) # 3 # 获取id为l1的标签内容 li_list = tree.xpath('//ul/li[@id="l1"]/text()') print(li_list) # ['北京'] # 获取id为l1的class属性值 c1 = tree.xpath('//ul/li[@id="l1"]/@class') print(c1) # ['class1'] # 获取id中包含l的标签 li_list = tree.xpath('//ul/li[contains(@id, "l")]/text()') print(li_list) # ['北京', '上海'] # 获取id以d开头的标签 li_list = tree.xpath('//ul/li[starts-with(@id,"d")]/text()') print(li_list) # ['广州'] # 获取id为l2并且class为class2的标签 li_list = tree.xpath('//ul/li[@id="l2" and @class="class2"]/text()') print(li_list) # ['上海'] # 获取id为l2或id为d1的标签 li_list = tree.xpath('//ul/li[@id="l2"]/text() | //ul/li[@id="d1"]/text()') print(li_list) # ['上海', '广州']
import urllib.request
from lxml import etree
url = 'http://www.baidu.com'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.0.0 Safari/537.36'
}
request = urllib.request.Request(url=url, headers=headers)
response = urllib.request.urlopen(request)
content = response.read().decode('utf-8')
tree = etree.HTML(content)
value = tree.xpath('//input[@id="su"]/@value')
print(value)2.2 Utilisation de jsonpath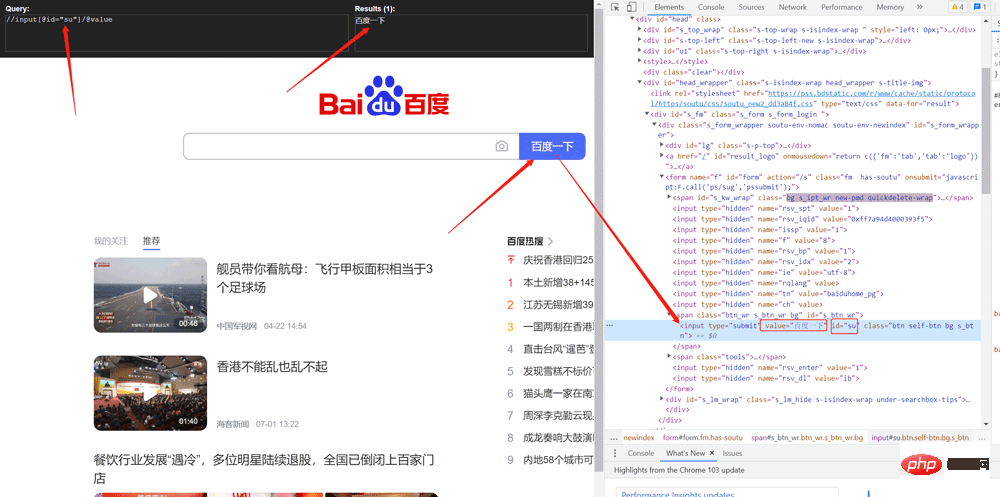
# 需求 下载的前十页的图片
# https://sc.chinaz.com/tupian/qinglvtupian.html 1
# https://sc.chinaz.com/tupian/qinglvtupian_page.html
import urllib.request
from lxml import etree
def create_request(page):
if (page == 1):
url = 'https://sc.chinaz.com/tupian/qinglvtupian.html'
else:
url = 'https://sc.chinaz.com/tupian/qinglvtupian_' + str(page) + '.html'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36',
}
request = urllib.request.Request(url=url, headers=headers)
return request
def get_content(request):
response = urllib.request.urlopen(request)
content = response.read().decode('utf-8')
return content
def down_load(content):
# 下载图片
# urllib.request.urlretrieve('图片地址','文件的名字')
tree = etree.HTML(content)
name_list = tree.xpath('//div[@id="container"]//a/img/@alt')
# 一般设计图片的网站都会进行懒加载
src_list = tree.xpath('//div[@id="container"]//a/img/@src2')
print(src_list)
for i in range(len(name_list)):
name = name_list[i]
src = src_list[i]
url = 'https:' + src
urllib.request.urlretrieve(url=url, filename='./loveImg/' + name + '.jpg')
if __name__ == '__main__':
start_page = int(input('请输入起始页码'))
end_page = int(input('请输入结束页码'))
for page in range(start_page, end_page + 1):
# (1) 请求对象的定制
request = create_request(page)
# (2)获取网页的源码
content = get_content(request)
# (3)下载
down_load(content)Comparaison des éléments de syntaxe JSONPath et des éléments XPath correspondants :
# BeautifulSoup# 🎜 🎜#
3.1 Introduction de base1. Installationpip install bs4
#🎜🎜 #2. Importer 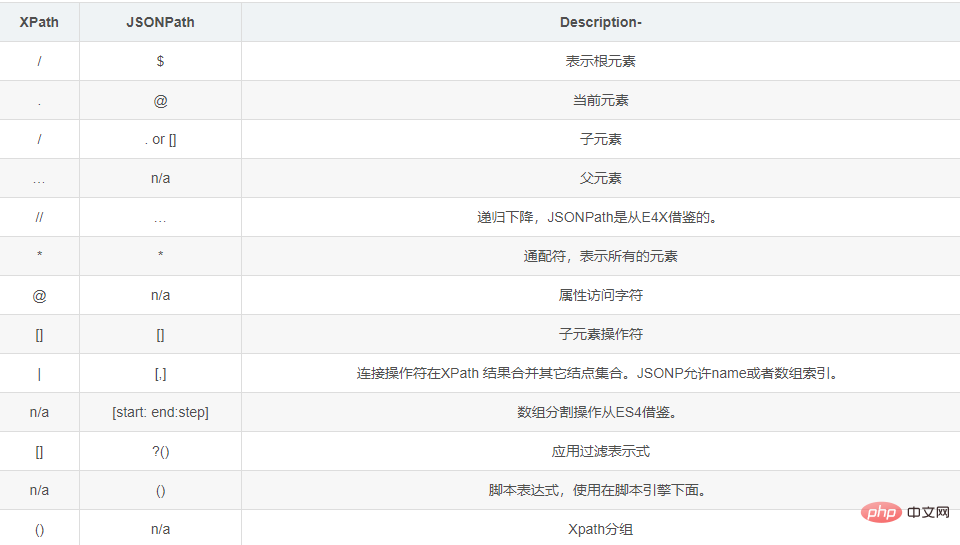
depuis bs4 import BeautifulSoup
3. 🎜#Réponse du serveur Soupe d'objets de génération de fichiers = BeautifulSoup(response.read().decode(), 'lxml')
Soupe d'objets de génération de fichiers locaux = BeautifulSoup(open('1 .html'), 'lxml')
Remarque :Le format d'encodage par défaut pour ouvrir les fichiers est gbk, vous devez donc le spécifier pour ouvrir Format d'encodage utf-8
3.2 Installation et création
pip install jsonpath
3.3 Positionnement du nœud#🎜🎜 #3.6 Exemple d'utilisationobj = json.load(open('json文件', 'r', encoding='utf‐8')) ret = jsonpath.jsonpath(obj, 'jsonpath语法')Copier après la connexion3.5 Informations sur le nœud
{ "store": { "book": [ { "category": "修真", "author": "六道", "title": "坏蛋是怎样练成的", "price": 8.95 }, { "category": "修真", "author": "天蚕土豆", "title": "斗破苍穹", "price": 12.99 }, { "category": "修真", "author": "唐家三少", "title": "斗罗大陆", "isbn": "0-553-21311-3", "price": 8.99 }, { "category": "修真", "author": "南派三叔", "title": "星辰变", "isbn": "0-395-19395-8", "price": 22.99 } ], "bicycle": { "author": "老马", "color": "黑色", "price": 19.95 } } }Copier après la connexionimport json import jsonpath obj = json.load(open('jsonpath.json', 'r', encoding='utf-8')) # 书店所有书的作者 author_list = jsonpath.jsonpath(obj, '$.store.book[*].author') print(author_list) # ['六道', '天蚕土豆', '唐家三少', '南派三叔'] # 所有的作者 author_list = jsonpath.jsonpath(obj, '$..author') print(author_list) # ['六道', '天蚕土豆', '唐家三少', '南派三叔', '老马'] # store下面的所有的元素 tag_list = jsonpath.jsonpath(obj, '$.store.*') print( tag_list) # [[{'category': '修真', 'author': '六道', 'title': '坏蛋是怎样练成的', 'price': 8.95}, {'category': '修真', 'author': '天蚕土豆', 'title': '斗破苍穹', 'price': 12.99}, {'category': '修真', 'author': '唐家三少', 'title': '斗罗大陆', 'isbn': '0-553-21311-3', 'price': 8.99}, {'category': '修真', 'author': '南派三叔', 'title': '星辰变', 'isbn': '0-395-19395-8', 'price': 22.99}], {'author': '老马', 'color': '黑色', 'price': 19.95}] # store里面所有东西的price price_list = jsonpath.jsonpath(obj, '$.store..price') print(price_list) # [8.95, 12.99, 8.99, 22.99, 19.95] # 第三个书 book = jsonpath.jsonpath(obj, '$..book[2]') print(book) # [{'category': '修真', 'author': '唐家三少', 'title': '斗罗大陆', 'isbn': '0-553-21311-3', 'price': 8.99}] # 最后一本书 book = jsonpath.jsonpath(obj, '$..book[(@.length-1)]') print(book) # [{'category': '修真', 'author': '南派三叔', 'title': '星辰变', 'isbn': '0-395-19395-8', 'price': 22.99}] # 前面的两本书 book_list = jsonpath.jsonpath(obj, '$..book[0,1]') # book_list = jsonpath.jsonpath(obj,'$..book[:2]') print( book_list) # [{'category': '修真', 'author': '六道', 'title': '坏蛋是怎样练成的', 'price': 8.95}, {'category': '修真', 'author': '天蚕土豆', 'title': '斗破苍穹', 'price': 12.99}] # 条件过滤需要在()的前面添加一个? # 过滤出所有的包含isbn的书。 book_list = jsonpath.jsonpath(obj, '$..book[?(@.isbn)]') print( book_list) # [{'category': '修真', 'author': '唐家三少', 'title': '斗罗大陆', 'isbn': '0-553-21311-3', 'price': 8.99}, {'category': '修真', 'author': '南派三叔', 'title': '星辰变', 'isbn': '0-395-19395-8', 'price': 22.99}] # 哪本书超过了10块钱 book_list = jsonpath.jsonpath(obj, '$..book[?(@.price>10)]') print( book_list) # [{'category': '修真', 'author': '天蚕土豆', 'title': '斗破苍穹', 'price': 12.99}, {'category': '修真', 'author': '南派三叔', 'title': '星辰变', 'isbn': '0-395-19395-8', 'price': 22.99}]Copier après la connexion
- bs4.html
1.根据标签名查找节点 soup.a 【注】只能找到第一个a soup.a.name soup.a.attrs 2.函数 (1).find(返回一个对象) find('a'):只找到第一个a标签 find('a', title='名字') find('a', class_='名字') (2).find_all(返回一个列表) find_all('a') 查找到所有的a find_all(['a', 'span']) 返回所有的a和span find_all('a', limit=2) 只找前两个a (3).select(根据选择器得到节点对象)【推荐】 1.element eg:p 2..class eg:.firstname 3.#id eg:#firstname 4.属性选择器 [attribute] eg:li = soup.select('li[class]') [attribute=value] eg:li = soup.select('li[class="hengheng1"]') 5.层级选择器 element element div p element>element div>p element,element div,p eg:soup = soup.select('a,span')
Copier après la connexionCopier après la connexion#🎜 🎜#3.7 Analyser le nom du produit Starbucks1.根据标签名查找节点 soup.a 【注】只能找到第一个a soup.a.name soup.a.attrs 2.函数 (1).find(返回一个对象) find('a'):只找到第一个a标签 find('a', title='名字') find('a', class_='名字') (2).find_all(返回一个列表) find_all('a') 查找到所有的a find_all(['a', 'span']) 返回所有的a和span find_all('a', limit=2) 只找前两个a (3).select(根据选择器得到节点对象)【推荐】 1.element eg:p 2..class eg:.firstname 3.#id eg:#firstname 4.属性选择器 [attribute] eg:li = soup.select('li[class]') [attribute=value] eg:li = soup.select('li[class="hengheng1"]') 5.层级选择器 element element div p element>element div>p element,element div,p eg:soup = soup.select('a,span')
Copier après la connexionCopier après la connexion# 🎜🎜#(1).获取节点内容:适用于标签中嵌套标签的结构 obj.string obj.get_text()【推荐】 (2).节点的属性 tag.name 获取标签名 eg:tag = find('li) print(tag.name) tag.attrs将属性值作为一个字典返回 (3).获取节点属性 obj.attrs.get('title')【常用】 obj.get('title') obj['title']
Copier après la connexionCe qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 MySQL doit-il payer
Apr 08, 2025 pm 05:36 PM
MySQL doit-il payer
Apr 08, 2025 pm 05:36 PM
MySQL a une version communautaire gratuite et une version d'entreprise payante. La version communautaire peut être utilisée et modifiée gratuitement, mais le support est limité et convient aux applications avec des exigences de stabilité faibles et des capacités techniques solides. L'Enterprise Edition fournit une prise en charge commerciale complète pour les applications qui nécessitent une base de données stable, fiable et haute performance et disposées à payer pour le soutien. Les facteurs pris en compte lors du choix d'une version comprennent la criticité des applications, la budgétisation et les compétences techniques. Il n'y a pas d'option parfaite, seulement l'option la plus appropriée, et vous devez choisir soigneusement en fonction de la situation spécifique.
 HaDIDB: une base de données légère et évolutive horizontalement dans Python
Apr 08, 2025 pm 06:12 PM
HaDIDB: une base de données légère et évolutive horizontalement dans Python
Apr 08, 2025 pm 06:12 PM
HaDIDB: Une base de données Python évolutive de haut niveau légère HaDIDB (HaDIDB) est une base de données légère écrite en Python, avec un niveau élevé d'évolutivité. Installez HaDIDB à l'aide de l'installation PIP: PiPinStallHaDIDB User Management Créer un utilisateur: CreateUser () pour créer un nouvel utilisateur. La méthode Authentication () authentifie l'identité de l'utilisateur. FromHadidb.OperationMportUserUser_OBJ = User ("Admin", "Admin") User_OBJ.
 Méthode de Navicat pour afficher le mot de passe de la base de données MongoDB
Apr 08, 2025 pm 09:39 PM
Méthode de Navicat pour afficher le mot de passe de la base de données MongoDB
Apr 08, 2025 pm 09:39 PM
Il est impossible de visualiser le mot de passe MongoDB directement via NAVICAT car il est stocké sous forme de valeurs de hachage. Comment récupérer les mots de passe perdus: 1. Réinitialiser les mots de passe; 2. Vérifiez les fichiers de configuration (peut contenir des valeurs de hachage); 3. Vérifiez les codes (May Code Hardcode).
 MySQL a-t-il besoin d'Internet
Apr 08, 2025 pm 02:18 PM
MySQL a-t-il besoin d'Internet
Apr 08, 2025 pm 02:18 PM
MySQL peut s'exécuter sans connexions réseau pour le stockage et la gestion des données de base. Cependant, la connexion réseau est requise pour l'interaction avec d'autres systèmes, l'accès à distance ou l'utilisation de fonctionnalités avancées telles que la réplication et le clustering. De plus, les mesures de sécurité (telles que les pare-feu), l'optimisation des performances (choisissez la bonne connexion réseau) et la sauvegarde des données sont essentielles pour se connecter à Internet.
 MySQL Workbench peut-il se connecter à MariaDB
Apr 08, 2025 pm 02:33 PM
MySQL Workbench peut-il se connecter à MariaDB
Apr 08, 2025 pm 02:33 PM
MySQL Workbench peut se connecter à MARIADB, à condition que la configuration soit correcte. Sélectionnez d'abord "MariADB" comme type de connecteur. Dans la configuration de la connexion, définissez correctement l'hôte, le port, l'utilisateur, le mot de passe et la base de données. Lorsque vous testez la connexion, vérifiez que le service MARIADB est démarré, si le nom d'utilisateur et le mot de passe sont corrects, si le numéro de port est correct, si le pare-feu autorise les connexions et si la base de données existe. Dans une utilisation avancée, utilisez la technologie de mise en commun des connexions pour optimiser les performances. Les erreurs courantes incluent des autorisations insuffisantes, des problèmes de connexion réseau, etc. Lors des erreurs de débogage, analysez soigneusement les informations d'erreur et utilisez des outils de débogage. L'optimisation de la configuration du réseau peut améliorer les performances
 Comment optimiser les performances MySQL pour les applications de haute charge?
Apr 08, 2025 pm 06:03 PM
Comment optimiser les performances MySQL pour les applications de haute charge?
Apr 08, 2025 pm 06:03 PM
Guide d'optimisation des performances de la base de données MySQL dans les applications à forte intensité de ressources, la base de données MySQL joue un rôle crucial et est responsable de la gestion des transactions massives. Cependant, à mesure que l'échelle de l'application se développe, les goulots d'étranglement des performances de la base de données deviennent souvent une contrainte. Cet article explorera une série de stratégies efficaces d'optimisation des performances MySQL pour garantir que votre application reste efficace et réactive dans des charges élevées. Nous combinerons des cas réels pour expliquer les technologies clés approfondies telles que l'indexation, l'optimisation des requêtes, la conception de la base de données et la mise en cache. 1. La conception de l'architecture de la base de données et l'architecture optimisée de la base de données sont la pierre angulaire de l'optimisation des performances MySQL. Voici quelques principes de base: sélectionner le bon type de données et sélectionner le plus petit type de données qui répond aux besoins peut non seulement économiser un espace de stockage, mais également améliorer la vitesse de traitement des données.
 Comment résoudre MySQL ne peut pas se connecter à l'hôte local
Apr 08, 2025 pm 02:24 PM
Comment résoudre MySQL ne peut pas se connecter à l'hôte local
Apr 08, 2025 pm 02:24 PM
La connexion MySQL peut être due aux raisons suivantes: le service MySQL n'est pas démarré, le pare-feu intercepte la connexion, le numéro de port est incorrect, le nom d'utilisateur ou le mot de passe est incorrect, l'adresse d'écoute dans my.cnf est mal configurée, etc. 2. Ajustez les paramètres du pare-feu pour permettre à MySQL d'écouter le port 3306; 3. Confirmez que le numéro de port est cohérent avec le numéro de port réel; 4. Vérifiez si le nom d'utilisateur et le mot de passe sont corrects; 5. Assurez-vous que les paramètres d'adresse de liaison dans My.cnf sont corrects.
 Comment utiliser Aws Glue Crawler avec Amazon Athena
Apr 09, 2025 pm 03:09 PM
Comment utiliser Aws Glue Crawler avec Amazon Athena
Apr 09, 2025 pm 03:09 PM
En tant que professionnel des données, vous devez traiter de grandes quantités de données provenant de diverses sources. Cela peut poser des défis à la gestion et à l'analyse des données. Heureusement, deux services AWS peuvent aider: AWS Glue et Amazon Athena.
