

Comment utiliser la bibliothèque jieba en Python ?

Tutoriel d'utilisation et d'installation de la bibliothèque jieba (bibliothèque de segmentation de mots chinois) en Python
Introduction
jieba est une excellente bibliothèque tierce pour la segmentation de mots chinois. Étant donné que chaque caractère chinois dans le texte chinois est écrit en continu, nous devons utiliser une méthode spécifique pour obtenir chaque mot qu'il contient. Cette méthode est appelée segmentation de mots. Jieba est une très excellente bibliothèque tierce pour la segmentation des mots chinois dans l'écosystème informatique Python. Vous devez l'installer pour l'utiliser.
La bibliothèque Jieba propose trois modes de segmentation de mots, mais en fait, pour obtenir l'effet de segmentation de mots, il suffit de maîtriser une seule fonction, ce qui est très simple et efficace.
Pour installer des bibliothèques tierces, vous devez utiliser l'outil pip et exécuter la commande d'installation sur la ligne de commande (pas IDLE). Remarque : Vous devez ajouter le répertoire Python et le répertoire Scripts en dessous aux variables d'environnement.
Utilisez la commande pip install jieba pour installer la bibliothèque tierce. Après l'installation, elle vous demandera si l'installation a réussi.
Principe de segmentation des mots : Pour faire simple, la bibliothèque jieba identifie la segmentation des mots grâce à la bibliothèque de vocabulaire chinois. Il utilise d'abord un lexique chinois pour calculer les probabilités d'association entre les caractères chinois qui forment des mots via le lexique. Par conséquent, en calculant les probabilités entre les caractères chinois, le résultat de la segmentation des mots peut être formé. Bien entendu, en plus de la propre bibliothèque de vocabulaire chinois de Jieba, les utilisateurs peuvent également y ajouter des expressions personnalisées, rendant ainsi la segmentation des mots de Jieba plus proche de l'utilisation dans certains domaines spécifiques.
jieba est une bibliothèque de segmentation de mots chinois pour python. Voici comment l'utiliser.
Installez la fonction
方式1: pip install jieba 方式2: 先下载 http://pypi.python.org/pypi/jieba/ 然后解压,运行 python setup.py install
Segmentation de mots
jieba, les trois modes couramment utilisés :
Mode exact, essayant de couper la phrase avec la plus grande précision, adapté à l'analyse de texte ;
Mode complet, coupant tout le texte ; phrases dans la phrase Tous les mots qui peuvent être transformés en mots sont analysés, ce qui est très rapide, mais ne peut pas résoudre les ambiguïtés
Le mode moteur de recherche, basé sur le mode précis, re-segmente les mots longs pour améliorer le taux de rappel ; adapté aux moteurs de recherche Participe.
Vous pouvez utiliser les méthodes jieba.cut et jieba.cut_for_search pour la segmentation de mots. La structure renvoyée par les deux est un générateur itérable. Vous pouvez utiliser une boucle for. pour obtenir chaque mot (unicode) obtenu après segmentation des mots, ou utilisez directement jieba.lcut et jieba.lcut_for_search pour renvoyer la liste. jieba.cut 和 jieba.cut_for_search 方法进行分词,两者所返回的结构都是一个可迭代的 generator,可使用 for 循环来获得分词后得到的每一个词语(unicode),或者直接使用 jieba.lcut 以及 jieba.lcut_for_search 返回 list。
jieba.Tokenizer(dictionary=DEFAULT_DICT) :使用该方法可以自定义分词器,可以同时使用不同的词典。jieba.dt 为默认分词器,所有全局分词相关函数都是该分词器的映射。
jieba.cut 和 jieba.lcut 可接受的参数如下:
需要分词的字符串(unicode 或 UTF-8 字符串、GBK 字符串)
cut_all:是否使用全模式,默认值为
FalseHMM:用来控制是否使用 HMM 模型,默认值为
True
jieba.cut_for_search 和 jieba.lcut_for_search 接受 2 个参数:
需要分词的字符串(unicode 或 UTF-8 字符串、GBK 字符串)
HMM:用来控制是否使用 HMM 模型,默认值为
Truejieba.Tokenizer(dictionary=DEFAULT_DICT): utilisez cette méthode pour personnaliser le tokenizer et utiliser différents dictionnaires en même temps.jieba.dtest le segmenteur de mots par défaut, et toutes les fonctions globales liées à la segmentation de mots sont des mappages de ce segmenteur de mots.
jieba.cut et jieba.lcut acceptent les paramètres suivants : Chaîne nécessitant une segmentation de mots (chaîne Unicode ou UTF-8, chaîne GBK)
cut_all : s'il faut utiliser le mode complet, la valeur par défaut est False
HMM : utilisé pour contrôler s'il faut utiliser le modèle HMM, la valeur par défaut est True</code ></p><p> </p><p><code>jieba.cut_for_search et jieba.lcut_for_search acceptent 2 paramètres :
Chaîne nécessitant une segmentation de mots (chaîne Unicode ou UTF-8, chaîne GBK)HMM : Utilisé pour contrôler s'il faut utiliser le modèle HMM. La valeur par défaut est
TrueIl convient de noter qu'essayez de ne pas utiliser de chaînes GBK, qui peuvent être imprévisibles et incorrectes. décodé en UTF-8. Comparaison de trois modes de segmentation de mots : # 全匹配
seg_list = jieba.cut("今天哪里都没去,在家里睡了一天", cut_all=True)
print(list(seg_list)) # ['今天', '哪里', '都', '没去', '', '', '在家', '家里', '睡', '了', '一天']
# 精确匹配 默认模式
seg_list = jieba.cut("今天哪里都没去,在家里睡了一天", cut_all=False)
print(list(seg_list)) # ['今天', '哪里', '都', '没', '去', ',', '在', '家里', '睡', '了', '一天']
# 精确匹配
seg_list = jieba.cut_for_search("今天哪里都没去,在家里睡了一天")
print(list(seg_list)) # ['今天', '哪里', '都', '没', '去', ',', '在', '家里', '睡', '了', '一天']Copier après la connexion
Dictionnaire personnaliséLes développeurs peuvent spécifier leur propre dictionnaire personnalisé pour inclure des mots qui ne figurent pas dans le dictionnaire jieba. # 全匹配
seg_list = jieba.cut("今天哪里都没去,在家里睡了一天", cut_all=True)
print(list(seg_list)) # ['今天', '哪里', '都', '没去', '', '', '在家', '家里', '睡', '了', '一天']
# 精确匹配 默认模式
seg_list = jieba.cut("今天哪里都没去,在家里睡了一天", cut_all=False)
print(list(seg_list)) # ['今天', '哪里', '都', '没', '去', ',', '在', '家里', '睡', '了', '一天']
# 精确匹配
seg_list = jieba.cut_for_search("今天哪里都没去,在家里睡了一天")
print(list(seg_list)) # ['今天', '哪里', '都', '没', '去', ',', '在', '家里', '睡', '了', '一天']Utilisation : jieba.load_userdict(dict_path)
dict_path : est le chemin d'accès au fichier de dictionnaire personnalisé
- Le format du dictionnaire est le suivant :
Un mot occupe une ligne, chaque ligne est divisée en trois parties : mot, fréquence des mots ; (peut être omise), partie du discours (peut être omise) omise), séparés par des espaces, et l'ordre ne peut pas être inversé.
Ce qui suit utilise un exemple pour illustrer : Dictionnaire personnalisé user_dict.txt :
- Cours universitaire
Apprentissage profond
- Ce qui suit compare les différences entre la correspondance exacte, la correspondance complète et l'utilisation d'un dictionnaire personnalisé : De ci-dessus La différence entre l'utilisation d'un dictionnaire personnalisé et l'utilisation du dictionnaire par défaut peut être vue dans l'exemple.
import jieba test_sent = """ 数学是一门基础性的大学课程,深度学习是基于数学的,尤其是线性代数课程 """ words = jieba.cut(test_sent) print(list(words)) # ['\n', '数学', '是', '一门', '基础性', '的', '大学', '课程', ',', '深度', # '学习', '是', '基于', '数学', '的', ',', '尤其', '是', '线性代数', '课程', '\n'] words = jieba.cut(test_sent, cut_all=True) print(list(words)) # ['\n', '数学', '是', '一门', '基础', '基础性', '的', '大学', '课程', '', '', '深度', # '学习', '是', '基于', '数学', '的', '', '', '尤其', '是', '线性', '线性代数', '代数', '课程', '\n'] jieba.load_userdict("userdict.txt") words = jieba.cut(test_sent) print(list(words)) # ['\n', '数学', '是', '一门', '基础性', '的', '大学课程', ',', '深度学习', '是', # '基于', '数学', '的', ',', '尤其', '是', '线性代数', '课程', '\n'] jieba.add_word("尤其是") jieba.add_word("线性代数课程") words = jieba.cut(test_sent) print(list(words)) # ['\n', '数学', '是', '一门', '基础性', '的', '大学课程', ',', '深度学习', '是', # '基于', '数学', '的', ',', '尤其是', '线性代数课程', '\n']Copier après la connexion - jieba.add_word() : ajoutez des mots au dictionnaire personnalisé Extraction de mots-clés🎜🎜 L'extraction de mots-clés peut être basée sur l'algorithme TF-IDF ou l'algorithme TextRank. L'algorithme TF-IDF est le même algorithme utilisé dans elasticsearch. 🎜🎜Utilisez la fonction jieba.analyse.extract_tags() pour l'extraction de mots-clés, ses paramètres sont les suivants : 🎜🎜jieba.analyse.extract_tags(sentence, topK=20, withWeight=False,allowPOS=())🎜🎜🎜🎜phrase est être Le texte extrait 🎜🎜🎜🎜topK doit renvoyer plusieurs mots-clés TF/IDF avec le poids le plus élevé, la valeur par défaut est 20🎜🎜🎜🎜withWeight indique s'il faut renvoyer la valeur de poids du mot-clé ensemble, la valeur par défaut est False🎜🎜 🎜🎜allowPOS uniquement Y compris les mots avec une partie du discours spécifiée, la valeur par défaut est vide, c'est-à-dire pas de filtrage🎜🎜🎜🎜jieba.analyse.TFIDF(idf_path=None) Créez une nouvelle instance TFIDF, idf_path est le fichier de fréquence IDF🎜
也可以使用 jieba.analyse.TFIDF(idf_path=None) 新建 TFIDF 实例,idf_path 为 IDF 频率文件。
基于 TF-IDF 算法和TextRank算法的关键词抽取:
import jieba.analyse file = "sanguo.txt" topK = 12 content = open(file, 'rb').read() # 使用tf-idf算法提取关键词 tags = jieba.analyse.extract_tags(content, topK=topK) print(tags) # ['玄德', '程远志', '张角', '云长', '张飞', '黄巾', '封谞', '刘焉', '邓茂', '邹靖', '姓名', '招军'] # 使用textrank算法提取关键词 tags2 = jieba.analyse.textrank(content, topK=topK) # withWeight=True:将权重值一起返回 tags = jieba.analyse.extract_tags(content, topK=topK, withWeight=True) print(tags) # [('玄德', 0.1038549799467099), ('程远志', 0.07787459004363208), ('张角', 0.0722532891360849), # ('云长', 0.07048801593691037), ('张飞', 0.060972692853113214), ('黄巾', 0.058227157790330185), # ('封谞', 0.0563904127495283), ('刘焉', 0.05470798376886792), ('邓茂', 0.04917692565566038), # ('邹靖', 0.04427258239705188), ('姓名', 0.04219704283997642), ('招军', 0.04182041076757075)]
上面的代码是读取文件,提取出现频率最高的前12个词。
词性标注
词性标注主要是标记文本分词后每个词的词性,使用例子如下:
import jieba
import jieba.posseg as pseg
# 默认模式
seg_list = pseg.cut("今天哪里都没去,在家里睡了一天")
for word, flag in seg_list:
print(word + " " + flag)
"""
使用 jieba 默认模式的输出结果是:
我 r
Prefix dict has been built successfully.
今天 t
吃 v
早饭 n
了 ul
"""
# paddle 模式
words = pseg.cut("我今天吃早饭了",use_paddle=True)
"""
使用 paddle 模式的输出结果是:
我 r
今天 TIME
吃 v
早饭 n
了 xc
"""paddle模式的词性对照表如下:
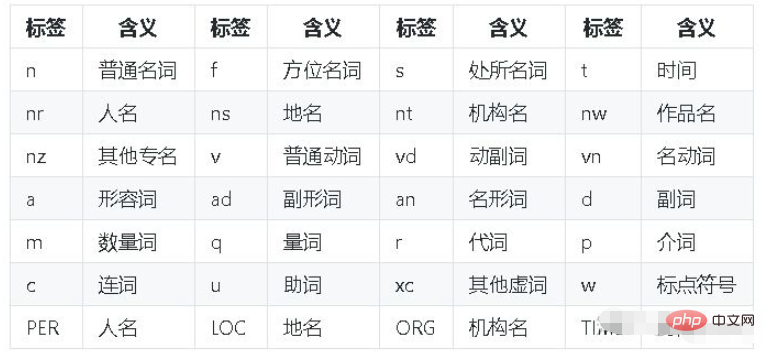
补充:Python中文分词库——jieba的用法
.使用说明
jieba分词有三种模式:精确模式、全模式和搜索引擎模式。
简单说,精确模式就是把一段文本精确的切分成若干个中文单词,若干个中文单词之间经过组合就精确的还原为之前的文本,其中不存在冗余单词。精确模式是最常用的分词模式。
进一步jieba又提供了全模式,全模式是把一段中文文本中所有可能的词语都扫描出来,可能有一段文本它可以切分成不同的模式或者有不同的角度来切分变成不同的词语,那么jieba在全模式下把这样的不同的组合都挖掘出来,所以如果用全模式来进行分词,分词的信息组合起来并不是精确的原有文本,会有很多的冗余。
而搜索引擎模式更加智能,它是在精确模式的基础上对长词进行再次切分,将长的词语变成更短的词语,进而适合搜索引擎对短词语的索引和搜索,在一些特定场合用的比较多。
jieba库提供的常用函数:
jieba.lcut(s)
精确模式,能够对一个字符串精确地返回分词结果,而分词的结果使用列表形式来组织。例如:
>>> import jieba
>>> jieba.lcut("中国是一个伟大的国家")
Building prefix dict from the default dictionary ...
Dumping model to file cache C:\Users\ADMINI~1\AppData\Local\Temp\jieba.cache
Loading model cost 2.489 seconds.
Prefix dict has been built successfully.
['中国', '是', '一个', '伟大', '的', '国家']jieba.lcut(s,cut_all=True)
全模式,能够返回一个列表类型的分词结果,但结果存在冗余。例如:
>>> import jieba
>>> jieba.lcut("中国是一个伟大的国家",cut_all=True)
['中国', '国是', '一个', '伟大', '的', '国家']jieba.lcut_for_search(s)
搜索引擎模式,能够返回一个列表类型的分词结果,也存在冗余。例如:
>>> import jieba
>>> jieba.lcut_for_search("中华人民共和国是伟大的")
['中华', '华人', '人民', '共和', '共和国', '中华人民共和国', '是', '伟大', '的']jieba.add_word(w)
向分词词库添加新词w
最重要的就是jieba.lcut(s)函数,完成精确的中文分词。
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

Video Face Swap
Échangez les visages dans n'importe quelle vidéo sans effort grâce à notre outil d'échange de visage AI entièrement gratuit !

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Choisir entre PHP et Python: un guide
Apr 18, 2025 am 12:24 AM
Choisir entre PHP et Python: un guide
Apr 18, 2025 am 12:24 AM
PHP convient au développement Web et au prototypage rapide, et Python convient à la science des données et à l'apprentissage automatique. 1.Php est utilisé pour le développement Web dynamique, avec une syntaxe simple et adapté pour un développement rapide. 2. Python a une syntaxe concise, convient à plusieurs champs et a un écosystème de bibliothèque solide.
 PHP et Python: différents paradigmes expliqués
Apr 18, 2025 am 12:26 AM
PHP et Python: différents paradigmes expliqués
Apr 18, 2025 am 12:26 AM
PHP est principalement la programmation procédurale, mais prend également en charge la programmation orientée objet (POO); Python prend en charge une variété de paradigmes, y compris la POO, la programmation fonctionnelle et procédurale. PHP convient au développement Web, et Python convient à une variété d'applications telles que l'analyse des données et l'apprentissage automatique.
 Le code Visual Studio peut-il être utilisé dans Python
Apr 15, 2025 pm 08:18 PM
Le code Visual Studio peut-il être utilisé dans Python
Apr 15, 2025 pm 08:18 PM
VS Code peut être utilisé pour écrire Python et fournit de nombreuses fonctionnalités qui en font un outil idéal pour développer des applications Python. Il permet aux utilisateurs de: installer des extensions Python pour obtenir des fonctions telles que la réalisation du code, la mise en évidence de la syntaxe et le débogage. Utilisez le débogueur pour suivre le code étape par étape, trouver et corriger les erreurs. Intégrez Git pour le contrôle de version. Utilisez des outils de mise en forme de code pour maintenir la cohérence du code. Utilisez l'outil de liaison pour repérer les problèmes potentiels à l'avance.
 Peut-on exécuter le code sous Windows 8
Apr 15, 2025 pm 07:24 PM
Peut-on exécuter le code sous Windows 8
Apr 15, 2025 pm 07:24 PM
VS Code peut fonctionner sur Windows 8, mais l'expérience peut ne pas être excellente. Assurez-vous d'abord que le système a été mis à jour sur le dernier correctif, puis téléchargez le package d'installation VS Code qui correspond à l'architecture du système et l'installez comme invité. Après l'installation, sachez que certaines extensions peuvent être incompatibles avec Windows 8 et doivent rechercher des extensions alternatives ou utiliser de nouveaux systèmes Windows dans une machine virtuelle. Installez les extensions nécessaires pour vérifier si elles fonctionnent correctement. Bien que le code VS soit possible sur Windows 8, il est recommandé de passer à un système Windows plus récent pour une meilleure expérience de développement et une meilleure sécurité.
 L'extension VScode est-elle malveillante?
Apr 15, 2025 pm 07:57 PM
L'extension VScode est-elle malveillante?
Apr 15, 2025 pm 07:57 PM
Les extensions de code vs posent des risques malveillants, tels que la cachette de code malveillant, l'exploitation des vulnérabilités et la masturbation comme des extensions légitimes. Les méthodes pour identifier les extensions malveillantes comprennent: la vérification des éditeurs, la lecture des commentaires, la vérification du code et l'installation avec prudence. Les mesures de sécurité comprennent également: la sensibilisation à la sécurité, les bonnes habitudes, les mises à jour régulières et les logiciels antivirus.
 Comment exécuter des programmes dans Terminal Vscode
Apr 15, 2025 pm 06:42 PM
Comment exécuter des programmes dans Terminal Vscode
Apr 15, 2025 pm 06:42 PM
Dans VS Code, vous pouvez exécuter le programme dans le terminal via les étapes suivantes: Préparez le code et ouvrez le terminal intégré pour vous assurer que le répertoire de code est cohérent avec le répertoire de travail du terminal. Sélectionnez la commande Run en fonction du langage de programmation (tel que Python de Python your_file_name.py) pour vérifier s'il s'exécute avec succès et résoudre les erreurs. Utilisez le débogueur pour améliorer l'efficacité du débogage.
 PHP et Python: une plongée profonde dans leur histoire
Apr 18, 2025 am 12:25 AM
PHP et Python: une plongée profonde dans leur histoire
Apr 18, 2025 am 12:25 AM
PHP est originaire en 1994 et a été développé par Rasmuslerdorf. Il a été utilisé à l'origine pour suivre les visiteurs du site Web et a progressivement évolué en un langage de script côté serveur et a été largement utilisé dans le développement Web. Python a été développé par Guidovan Rossum à la fin des années 1980 et a été publié pour la première fois en 1991. Il met l'accent sur la lisibilité et la simplicité du code, et convient à l'informatique scientifique, à l'analyse des données et à d'autres domaines.
 Python vs JavaScript: la courbe d'apprentissage et la facilité d'utilisation
Apr 16, 2025 am 12:12 AM
Python vs JavaScript: la courbe d'apprentissage et la facilité d'utilisation
Apr 16, 2025 am 12:12 AM
Python convient plus aux débutants, avec une courbe d'apprentissage en douceur et une syntaxe concise; JavaScript convient au développement frontal, avec une courbe d'apprentissage abrupte et une syntaxe flexible. 1. La syntaxe Python est intuitive et adaptée à la science des données et au développement back-end. 2. JavaScript est flexible et largement utilisé dans la programmation frontale et côté serveur.
