
 Java
javaDidacticiel
Comment utiliser ConcurrentHashMap pour implémenter un mappage thread-safe en Java ?
Java
javaDidacticiel
Comment utiliser ConcurrentHashMap pour implémenter un mappage thread-safe en Java ?
Comment utiliser ConcurrentHashMap pour implémenter un mappage thread-safe en Java ?

version jdk1.7
structure des données
/**
* The segments, each of which is a specialized hash table.
*/
final Segment<K,V>[] segments;Vous pouvez voir qu'il s'agit principalement d'un tableau Segment, avec des commentaires également écrits, chacun étant une table de hachage spéciale.
Jetons un coup d'œil à ce qu'est le segment.
static final class Segment<K,V> extends ReentrantLock implements Serializable {
......
/**
* The per-segment table. Elements are accessed via
* entryAt/setEntryAt providing volatile semantics.
*/
transient volatile HashEntry<K,V>[] table;
transient int threshold;
final float loadFactor;
// 构造函数
Segment(float lf, int threshold, HashEntry<K,V>[] tab) {
this.loadFactor = lf;
this.threshold = threshold;
this.table = tab;
}
......
}Ce qui précède fait partie du code. Vous pouvez voir que Segment hérite de ReentrantLock, donc en fait, chaque Segment est un verrou.
Le tableau HashEntry y est stocké et la variable est décorée de volatile. HashEntry est similaire au nœud de hashmap et est également un nœud d'une liste chaînée.
Jetons un coup d'œil au code spécifique. Vous pouvez voir qu'il est légèrement différent de hashmap dans la mesure où ses variables membres sont modifiées avec volatile.
static final class HashEntry<K,V> {
final int hash;
final K key;
volatile V value;
volatile HashEntry<K,V> next;
HashEntry(int hash, K key, V value, HashEntry<K,V> next) {
this.hash = hash;
this.key = key;
this.value = value;
this.next = next;
}
......
}Donc, la structure des données de ConcurrentHashMap ressemble presque à l'image ci-dessous.
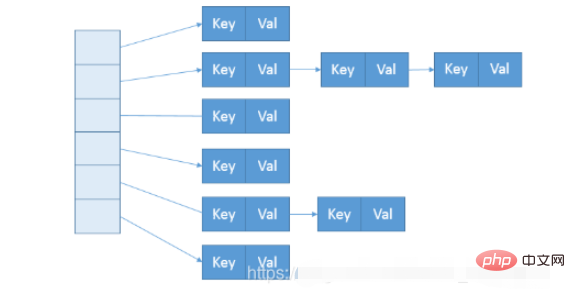
Pendant la construction, le nombre de segments est déterminé par ce que l'on appelle le concurrentcyLevel. La valeur par défaut est 16. Il peut également être spécifié directement dans le constructeur correspondant. Notez que Java exige qu'il s'agisse d'une puissance de 2. Si l'entrée est une valeur sans puissance comme 15, elle sera automatiquement ajustée à une puissance de 2 comme 16.
Jetons un coup d'œil au code source, en commençant par la méthode simple get
get()
public V get(Object key) {
Segment<K,V> s; // manually integrate access methods to reduce overhead
HashEntry<K,V>[] tab;
int h = hash(key);
long u = (((h >>> segmentShift) & segmentMask) << SSHIFT) + SBASE;
// 通过unsafe获取Segment数组的元素
if ((s = (Segment<K,V>)UNSAFE.getObjectVolatile(segments, u)) != null &&
(tab = s.table) != null) {
// 还是通过unsafe获取HashEntry数组的元素
for (HashEntry<K,V> e = (HashEntry<K,V>) UNSAFE.getObjectVolatile
(tab, ((long)(((tab.length - 1) & h)) << TSHIFT) + TBASE);
e != null; e = e.next) {
K k;
if ((k = e.key) == key || (e.hash == h && key.equals(k)))
return e.value;
}
}
return null;
}La logique de get est très simple, c'est-à-dire trouver le tableau HashEntry correspondant à l'indice du segment, puis trouver l'en-tête de la liste chaînée correspondant à l'indice du tableau HashEntry, puis parcourez la liste chaînée Get data.
Pour obtenir les données du tableau, utilisez UNSAFE.getObjectVolatile(segments, u). Unsafe offre la possibilité d'accéder directement à la mémoire comme le langage C. Cette méthode peut obtenir les données du décalage correspondant de l'objet. u est un décalage calculé, il est donc équivalent aux segments[i], mais plus efficace.
put()
public V put(K key, V value) {
Segment<K,V> s;
if (value == null)
throw new NullPointerException();
int hash = hash(key);
int j = (hash >>> segmentShift) & segmentMask;
if ((s = (Segment<K,V>)UNSAFE.getObject // nonvolatile; recheck
(segments, (j << SSHIFT) + SBASE)) == null) // in ensureSegment
s = ensureSegment(j);
return s.put(key, hash, value, false);
}Pour l'opération put, le segment correspondant est directement obtenu via la méthode d'appel Unsafe, puis l'opération put thread-safe est effectuée :
La logique principale est dans la méthode put à l'intérieur du segment
final V put(K key, int hash, V value, boolean onlyIfAbsent) {
// scanAndLockForPut会去查找是否有key相同Node
// 无论如何,确保获取锁
HashEntry<K,V> node = tryLock() ? null :
scanAndLockForPut(key, hash, value);
V oldValue;
try {
HashEntry<K,V>[] tab = table;
int index = (tab.length - 1) & hash;
HashEntry<K,V> first = entryAt(tab, index);
for (HashEntry<K,V> e = first;;) {
if (e != null) {
K k;
// 更新已有value...
}
else {
// 放置HashEntry到特定位置,如果超过阈值,进行rehash
// ...
}
}
} finally {
unlock();
}
return oldValue;
}size()
Jetons un œil au code principal,
for (;;) {
// 如果重试次数等于默认的2,就锁住所有的segment,来计算值
if (retries++ == RETRIES_BEFORE_LOCK) {
for (int j = 0; j < segments.length; ++j)
ensureSegment(j).lock(); // force creation
}
sum = 0L;
size = 0;
overflow = false;
for (int j = 0; j < segments.length; ++j) {
Segment<K,V> seg = segmentAt(segments, j);
if (seg != null) {
sum += seg.modCount;
int c = seg.count;
if (c < 0 || (size += c) < 0)
overflow = true;
}
}
// 如果sum不再变化,就表示得到了一个确切的值
if (sum == last)
break;
last = sum;
}Il s'agit en fait de calculer la somme des nombres de tous les segments. Si la somme est égale à la valeur obtenue la dernière fois, cela signifie que la carte. n'a pas été exploité, et cette valeur est relativement correcte. Si vous ne parvenez toujours pas à obtenir une valeur unifiée après avoir réessayé deux fois, verrouillez tous les segments et récupérez la valeur.
Expansion
private void rehash(HashEntry<K,V> node) {
HashEntry<K,V>[] oldTable = table;
int oldCapacity = oldTable.length;
// 新表的大小是原来的两倍
int newCapacity = oldCapacity << 1;
threshold = (int)(newCapacity * loadFactor);
HashEntry<K,V>[] newTable =
(HashEntry<K,V>[]) new HashEntry[newCapacity];
int sizeMask = newCapacity - 1;
for (int i = 0; i < oldCapacity ; i++) {
HashEntry<K,V> e = oldTable[i];
if (e != null) {
HashEntry<K,V> next = e.next;
int idx = e.hash & sizeMask;
if (next == null) // Single node on list
newTable[idx] = e;
else { // Reuse consecutive sequence at same slot
// 如果有多个节点
HashEntry<K,V> lastRun = e;
int lastIdx = idx;
// 这里操作就是找到末尾的一段索引值都相同的链表节点,这段的头结点是lastRun.
for (HashEntry<K,V> last = next;
last != null;
last = last.next) {
int k = last.hash & sizeMask;
if (k != lastIdx) {
lastIdx = k;
lastRun = last;
}
}
// 然后将lastRun结点赋值给数组位置,这样lastRun后面的节点也跟着过去了。
newTable[lastIdx] = lastRun;
// 之后就是复制开头到lastRun之间的节点
// Clone remaining nodes
for (HashEntry<K,V> p = e; p != lastRun; p = p.next) {
V v = p.value;
int h = p.hash;
int k = h & sizeMask;
HashEntry<K,V> n = newTable[k];
newTable[k] = new HashEntry<K,V>(h, p.key, v, n);
}
}
}
}
int nodeIndex = node.hash & sizeMask; // add the new node
node.setNext(newTable[nodeIndex]);
newTable[nodeIndex] = node;
table = newTable;
}version jdk1.8
Structure des données
La version 1.8 de ConcurrentHashmap est un peu similaire à Hashmap dans son ensemble, mais le segment est supprimé et un tableau de nœuds est utilisé à la place.
transient volatile Node<K,V>[] table;
Il existe toujours une classe interne appelée Segment dans la version 1.8, mais son existence est uniquement destinée à la compatibilité de sérialisation et n'est plus utilisée.
Jetons un coup d'œil au nœud node
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
volatile V val;
volatile Node<K,V> next;
Node(int hash, K key, V val, Node<K,V> next) {
this.hash = hash;
this.key = key;
this.val = val;
this.next = next;
}
......
}Il est similaire au nœud node dans HashMap et implémente également Map.Entry La différence est que val et next sont modifiés avec volatile pour assurer la visibilité.
put()
final V putVal(K key, V value, boolean onlyIfAbsent) {
if (key == null || value == null) throw new NullPointerException();
int hash = spread(key.hashCode());
int binCount = 0;
for (Node<K,V>[] tab = table;;) {
Node<K,V> f; int n, i, fh;
if (tab == null || (n = tab.length) == 0)
// 初始化
tab = initTable();
else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {
// 利用CAS去进行无锁线程安全操作,如果bin是空的
if (casTabAt(tab, i, null,
new Node<K,V>(hash, key, value, null)))
break; // no lock when adding to empty bin
}
else if ((fh = f.hash) == MOVED)
tab = helpTransfer(tab, f);
else {
V oldVal = null;
synchronized (f) {
// 细粒度的同步修改操作...
if (tabAt(tab, i) == f) {
if (fh >= 0) {
binCount = 1;
for (Node<K,V> e = f;; ++binCount) {
K ek;
// 找到相同key就更新
if (e.hash == hash &&
((ek = e.key) == key ||
(ek != null && key.equals(ek)))) {
oldVal = e.val;
if (!onlyIfAbsent)
e.val = value;
break;
}
Node<K,V> pred = e;
// 没有相同的就新增
if ((e = e.next) == null) {
pred.next = new Node<K,V>(hash, key,
value, null);
break;
}
}
}
// 如果是树节点,进行树的操作
else if (f instanceof TreeBin) {
Node<K,V> p;
binCount = 2;
if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key,
value)) != null) {
oldVal = p.val;
if (!onlyIfAbsent)
p.val = value;
}
}
}
}
// Bin超过阈值,进行树化
if (binCount != 0) {
if (binCount >= TREEIFY_THRESHOLD)
treeifyBin(tab, i);
if (oldVal != null)
return oldVal;
break;
}
}
}
addCount(1L, binCount);
return null;
}Vous pouvez voir que dans la logique de synchronisation, il utilise synchronisé au lieu du ReentrantLock habituellement recommandé et autres. Pourquoi est-ce ? Désormais dans JDK1.8, la synchronisation a été optimisée en permanence, vous n'avez donc plus à vous soucier trop des différences de performances. De plus, par rapport à ReentrantLock, cela peut réduire la consommation de mémoire, ce qui constitue un très gros avantage.
Dans le même temps, des implémentations plus détaillées ont été optimisées en utilisant Unsafe. Par exemple, tabAt utilise directement getObjectAcquire pour éviter la surcharge des appels indirects.
Alors, voyons comment fonctionne la taille ?
final long sumCount() {
CounterCell[] as = counterCells; CounterCell a;
long sum = baseCount;
if (as != null) {
for (int i = 0; i < as.length; ++i) {
if ((a = as[i]) != null)
sum += a.value;
}
}
return sum;
}Voici pour obtenir la variable membre counterCells et parcourir pour obtenir le nombre total.
En fait, le fonctionnement de CounterCell est basé sur java.util.concurrent.atomic.LongAdder. Il s'agit d'une méthode permettant à la JVM d'utiliser l'espace en échange d'une plus grande efficacité, en profitant de la logique complexe de Stripe64. Cette chose est très spécialisée. Dans la plupart des cas, il est recommandé d'utiliser AtomicLong, ce qui est suffisant pour répondre aux besoins de performances de la plupart des applications.
Expansion
private final void transfer(Node<K,V>[] tab, Node<K,V>[] nextTab) {
......
// 初始化
if (nextTab == null) { // initiating
try {
@SuppressWarnings("unchecked")
Node<K,V>[] nt = (Node<K,V>[])new Node<?,?>[n << 1];
nextTab = nt;
} catch (Throwable ex) { // try to cope with OOME
sizeCtl = Integer.MAX_VALUE;
return;
}
nextTable = nextTab;
transferIndex = n;
}
int nextn = nextTab.length;
ForwardingNode<K,V> fwd = new ForwardingNode<K,V>(nextTab);
// 是否继续处理下一个
boolean advance = true;
// 是否完成
boolean finishing = false; // to ensure sweep before committing nextTab
for (int i = 0, bound = 0;;) {
Node<K,V> f; int fh;
while (advance) {
int nextIndex, nextBound;
if (--i >= bound || finishing)
advance = false;
else if ((nextIndex = transferIndex) <= 0) {
i = -1;
advance = false;
}
// 首次循环才会进来这里
else if (U.compareAndSwapInt
(this, TRANSFERINDEX, nextIndex,
nextBound = (nextIndex > stride ?
nextIndex - stride : 0))) {
bound = nextBound;
i = nextIndex - 1;
advance = false;
}
}
if (i < 0 || i >= n || i + n >= nextn) {
int sc;
//扩容结束后做后续工作
if (finishing) {
nextTable = null;
table = nextTab;
sizeCtl = (n << 1) - (n >>> 1);
return;
}
//每当一条线程扩容结束就会更新一次 sizeCtl 的值,进行减 1 操作
if (U.compareAndSwapInt(this, SIZECTL, sc = sizeCtl, sc - 1)) {
if ((sc - 2) != resizeStamp(n) << RESIZE_STAMP_SHIFT)
return;
finishing = advance = true;
i = n; // recheck before commit
}
}
// 如果是null,设置fwd
else if ((f = tabAt(tab, i)) == null)
advance = casTabAt(tab, i, null, fwd);
// 说明该位置已经被处理过了,不需要再处理
else if ((fh = f.hash) == MOVED)
advance = true; // already processed
else {
// 真正的处理逻辑
synchronized (f) {
if (tabAt(tab, i) == f) {
Node<K,V> ln, hn;
if (fh >= 0) {
int runBit = fh & n;
Node<K,V> lastRun = f;
for (Node<K,V> p = f.next; p != null; p = p.next) {
int b = p.hash & n;
if (b != runBit) {
runBit = b;
lastRun = p;
}
}
if (runBit == 0) {
ln = lastRun;
hn = null;
}
else {
hn = lastRun;
ln = null;
}
for (Node<K,V> p = f; p != lastRun; p = p.next) {
int ph = p.hash; K pk = p.key; V pv = p.val;
if ((ph & n) == 0)
ln = new Node<K,V>(ph, pk, pv, ln);
else
hn = new Node<K,V>(ph, pk, pv, hn);
}
setTabAt(nextTab, i, ln);
setTabAt(nextTab, i + n, hn);
setTabAt(tab, i, fwd);
advance = true;
}
// 树节点操作
else if (f instanceof TreeBin) {
......
}
}
}
}
}
} }
setTabAt(nextTab, i, ln);
setTabAt(nextTab, i + n, hn);
setTabAt(tab, i, fwd);
advance = true;
}
// 树节点操作
else if (f instanceof TreeBin) {
......
}
}
}
}
}
}La logique de base est la même que celle de HashMap dans la création de deux listes chaînées, mais avec l'ajout de l'opération d'obtention de lastRun.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

Video Face Swap
Échangez les visages dans n'importe quelle vidéo sans effort grâce à notre outil d'échange de visage AI entièrement gratuit !

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)
Sujets chauds



 Numéro de Smith en Java
Aug 30, 2024 pm 04:28 PM
Numéro de Smith en Java
Aug 30, 2024 pm 04:28 PM
Guide du nombre de Smith en Java. Nous discutons ici de la définition, comment vérifier le numéro Smith en Java ? exemple avec implémentation de code.
 Questions d'entretien chez Java Spring
Aug 30, 2024 pm 04:29 PM
Questions d'entretien chez Java Spring
Aug 30, 2024 pm 04:29 PM
Dans cet article, nous avons conservé les questions d'entretien Java Spring les plus posées avec leurs réponses détaillées. Pour que vous puissiez réussir l'interview.
 Break or Return of Java 8 Stream Forach?
Feb 07, 2025 pm 12:09 PM
Break or Return of Java 8 Stream Forach?
Feb 07, 2025 pm 12:09 PM
Java 8 présente l'API Stream, fournissant un moyen puissant et expressif de traiter les collections de données. Cependant, une question courante lors de l'utilisation du flux est: comment se casser ou revenir d'une opération FOREAK? Les boucles traditionnelles permettent une interruption ou un retour précoce, mais la méthode Foreach de Stream ne prend pas directement en charge cette méthode. Cet article expliquera les raisons et explorera des méthodes alternatives pour la mise en œuvre de terminaison prématurée dans les systèmes de traitement de flux. Lire plus approfondie: Améliorations de l'API Java Stream Comprendre le flux Forach La méthode foreach est une opération terminale qui effectue une opération sur chaque élément du flux. Son intention de conception est
 Horodatage à ce jour en Java
Aug 30, 2024 pm 04:28 PM
Horodatage à ce jour en Java
Aug 30, 2024 pm 04:28 PM
Guide de TimeStamp to Date en Java. Ici, nous discutons également de l'introduction et de la façon de convertir l'horodatage en date en Java avec des exemples.
 Programme Java pour trouver le volume de la capsule
Feb 07, 2025 am 11:37 AM
Programme Java pour trouver le volume de la capsule
Feb 07, 2025 am 11:37 AM
Les capsules sont des figures géométriques tridimensionnelles, composées d'un cylindre et d'un hémisphère aux deux extrémités. Le volume de la capsule peut être calculé en ajoutant le volume du cylindre et le volume de l'hémisphère aux deux extrémités. Ce tutoriel discutera de la façon de calculer le volume d'une capsule donnée en Java en utilisant différentes méthodes. Formule de volume de capsule La formule du volume de la capsule est la suivante: Volume de capsule = volume cylindrique volume de deux hémisphères volume dans, R: Le rayon de l'hémisphère. H: La hauteur du cylindre (à l'exclusion de l'hémisphère). Exemple 1 entrer Rayon = 5 unités Hauteur = 10 unités Sortir Volume = 1570,8 unités cubes expliquer Calculer le volume à l'aide de la formule: Volume = π × r2 × h (4
 PHP vs Python: comprendre les différences
Apr 11, 2025 am 12:15 AM
PHP vs Python: comprendre les différences
Apr 11, 2025 am 12:15 AM
PHP et Python ont chacun leurs propres avantages, et le choix doit être basé sur les exigences du projet. 1.Php convient au développement Web, avec une syntaxe simple et une efficacité d'exécution élevée. 2. Python convient à la science des données et à l'apprentissage automatique, avec une syntaxe concise et des bibliothèques riches.
 PHP: un langage clé pour le développement Web
Apr 13, 2025 am 12:08 AM
PHP: un langage clé pour le développement Web
Apr 13, 2025 am 12:08 AM
PHP est un langage de script largement utilisé du côté du serveur, particulièrement adapté au développement Web. 1.Php peut intégrer HTML, traiter les demandes et réponses HTTP et prend en charge une variété de bases de données. 2.PHP est utilisé pour générer du contenu Web dynamique, des données de formulaire de traitement, des bases de données d'accès, etc., avec un support communautaire solide et des ressources open source. 3. PHP est une langue interprétée, et le processus d'exécution comprend l'analyse lexicale, l'analyse grammaticale, la compilation et l'exécution. 4.PHP peut être combiné avec MySQL pour les applications avancées telles que les systèmes d'enregistrement des utilisateurs. 5. Lors du débogage de PHP, vous pouvez utiliser des fonctions telles que error_reportting () et var_dump (). 6. Optimiser le code PHP pour utiliser les mécanismes de mise en cache, optimiser les requêtes de base de données et utiliser des fonctions intégrées. 7
 Créer l'avenir : programmation Java pour les débutants absolus
Oct 13, 2024 pm 01:32 PM
Créer l'avenir : programmation Java pour les débutants absolus
Oct 13, 2024 pm 01:32 PM
Java est un langage de programmation populaire qui peut être appris aussi bien par les développeurs débutants que par les développeurs expérimentés. Ce didacticiel commence par les concepts de base et progresse vers des sujets avancés. Après avoir installé le kit de développement Java, vous pouvez vous entraîner à la programmation en créant un simple programme « Hello, World ! ». Une fois que vous avez compris le code, utilisez l'invite de commande pour compiler et exécuter le programme, et « Hello, World ! » s'affichera sur la console. L'apprentissage de Java commence votre parcours de programmation et, à mesure que votre maîtrise s'approfondit, vous pouvez créer des applications plus complexes.
