
 Périphériques technologiques
IA
La méthode de base de ChatGPT peut être utilisée pour la peinture par l'IA, et l'effet monte en flèche de 47 %. Auteur correspondant : est passé à OpenAI.
Périphériques technologiques
IA
La méthode de base de ChatGPT peut être utilisée pour la peinture par l'IA, et l'effet monte en flèche de 47 %. Auteur correspondant : est passé à OpenAI.
La méthode de base de ChatGPT peut être utilisée pour la peinture par l'IA, et l'effet monte en flèche de 47 %. Auteur correspondant : est passé à OpenAI.

Il existe une méthode de formation de base dans ChatGPT appelée « Apprentissage par renforcement avec feedback humain (RLHF) ».
Cela peut rendre le modèle plus sûr et les résultats plus cohérents avec les intentions humaines.
Maintenant, des chercheurs de Google Research et de l'UC Berkeley ont découvert que l'application de cette méthode à la peinture par l'IA peut "traiter" la situation dans laquelle l'image ne correspond pas exactement à l'entrée, et l'effet est étonnamment bon -
peut atteindre jusqu'à 47. % améliorer.

△ La gauche est la diffusion stable, la droite est l'effet amélioré
En ce moment, les deux modèles populaires dans le domaine AIGC semblent avoir trouvé une sorte de "résonance".
Comment utiliser RLHF pour la peinture IA ?
RLHF, le nom complet est « Reinforcement Learning from Human Feedback », est une technologie d'apprentissage par renforcement développée conjointement par OpenAI et DeepMind en 2017.
Comme son nom l'indique, RLHF utilise l'évaluation humaine des résultats de sortie du modèle (c'est-à-dire les commentaires) pour optimiser directement le modèle. Dans LLM, il peut rendre les « valeurs du modèle » plus cohérentes avec les valeurs humaines.
Dans le modèle de génération d'images AI, il peut aligner complètement l'image générée avec l'invite de texte.
Plus précisément, commencez par collecter des données sur les commentaires humains.
Ici, les chercheurs ont généré un total de plus de 27 000 « paires texte-image » et ont ensuite demandé à des humains de les noter.
Par souci de simplicité, les invites textuelles incluent uniquement les quatre catégories suivantes, liées aux options de quantité, de couleur, d'arrière-plan et de fusion ; les commentaires humains sont uniquement divisés en « bon », « mauvais » et « ne sait pas (ignorer) ; ".

Deuxièmement, apprenez la fonction de récompense.
Cette étape consiste à utiliser l'ensemble de données composé d'évaluations humaines qui viennent d'être obtenues pour entraîner une fonction de récompense, puis à utiliser cette fonction pour prédire la satisfaction humaine à l'égard de la sortie du modèle (partie rouge de la formule).
De cette façon, le modèle sait à quel point ses résultats correspondent au texte.
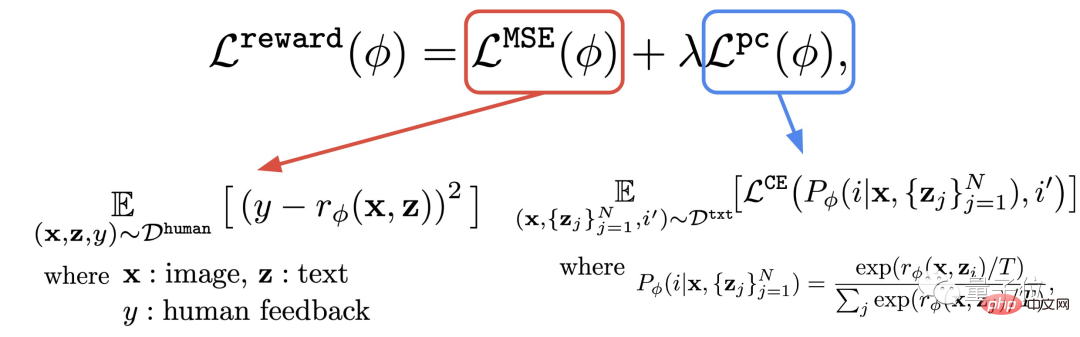
En plus de la fonction récompense, l'auteur propose également une tâche auxiliaire (partie bleue de la formule).
C'est-à-dire qu'une fois la génération de l'image terminée, le modèle donnera un tas de texte, mais un seul d'entre eux est le texte original, et laissera le modèle de récompense "vérifier par lui-même" si l'image correspond au texte.
Cette opération inverse peut produire l'effet "double assurance" (cela peut aider à la compréhension de l'étape 2 dans l'image ci-dessous).
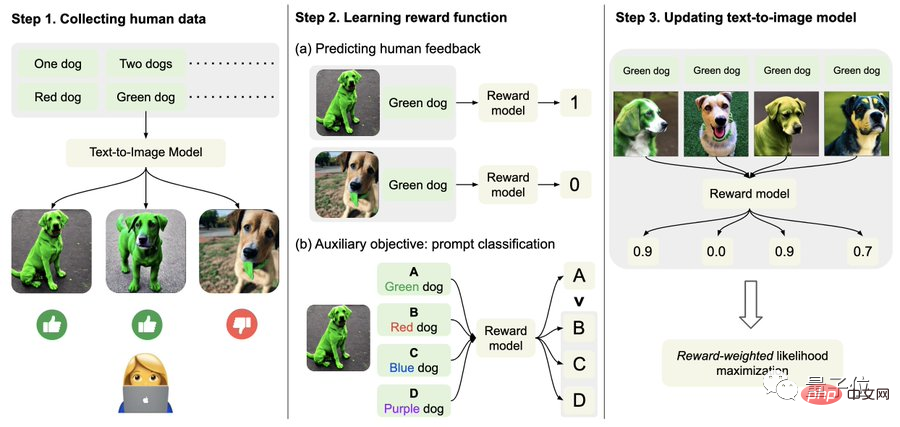
Enfin, il s’agit de peaufiner.
C'est-à-dire que le modèle de génération texte-image est mis à jour via une maximisation de la probabilité pondérée en fonction des récompenses (le premier élément de la formule ci-dessous).
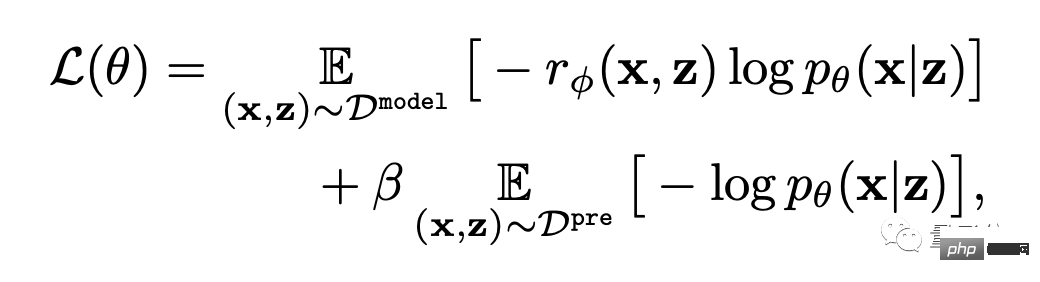
Afin d'éviter le surajustement, l'auteur a minimisé la valeur NLL (le deuxième terme de la formule) sur l'ensemble de données de pré-entraînement. Cette approche est similaire à InstructionGPT (le « prédécesseur direct » de ChatGPT).
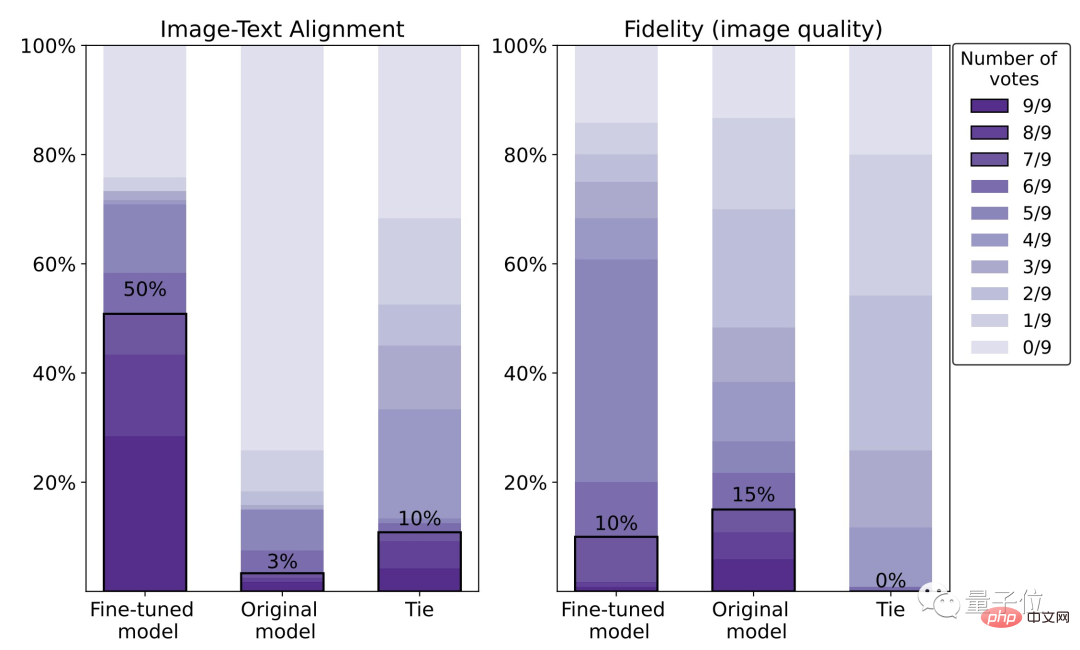
L'effet a augmenté de 47%, mais la clarté a chuté de 5%
Comme le montre la série d'effets suivante, par rapport à la diffusion stable originale, le modèle affiné avec RLHF peut :
(1) Obtenez le "" dans le texte plus correctement "Deux" et "vert"

(2) n'ignorera pas l'exigence de "mer" comme arrière-plan
(3) Si vous voulez un tigre rouge, cela peut donner un résultat "plus rouge".
À en juger par les données spécifiques, le taux de satisfaction humaine du modèle affiné est de 50 %, soit une amélioration de 47 % par rapport au modèle original (3 %).
Cependant, le prix est une perte de clarté d'image de 5%.
Nous pouvons également voir clairement sur l'image ci-dessous que le loup de droite est évidemment plus flou que celui de gauche :
À cet égard, l'auteur a déclaré qu'en utilisant un ensemble de données d'évaluation humaine plus large et une meilleure méthode d’optimisation (RL) peut améliorer cette situation.
À propos de l'auteur
Il y a 9 auteurs au total pour cet article.

En tant que chercheuse sur Google AI, Kimin Lee, Ph.D. de l'Institut coréen des sciences et technologies, des recherches postdoctorales sont menées. à l'Université de Berkeley.

Trois auteurs chinois :
Liu Hao, doctorant à l'UC Berkeley, Son principal intérêt de recherche concerne les réseaux neuronaux de rétroaction.
Du Yuqing est doctorant à l'UC Berkeley. Son principal domaine de recherche concerne les méthodes d'apprentissage par renforcement non supervisé.
Shixiang Shane Gu (Gu Shixiang), l'auteur correspondant, a étudié auprès de Hinton, l'un des trois géants, pour son diplôme de premier cycle et a obtenu son doctorat à l'Université de Cambridge.

△ Gu Shixiang
Il convient de mentionner qu'au moment d'écrire cet article, il était encore un Googleur, et maintenant il est passé à Google OpenAI et relève directement du responsable de ChatGPT.
Adresse papier :
https://arxiv.org/abs/2302.12192
Lien de référence : [1] https://www.php.cn/link/4d42d2f5010c1c13f23492a35645d6a7
[2]https://openai.com/blog/instruction-following/
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 phpmyadmin crée un tableau de données
Apr 10, 2025 pm 11:00 PM
phpmyadmin crée un tableau de données
Apr 10, 2025 pm 11:00 PM
Pour créer un tableau de données à l'aide de PhpMyAdmin, les étapes suivantes sont essentielles: connectez-vous à la base de données et cliquez sur le nouvel onglet. Nommez le tableau et sélectionnez le moteur de stockage (InnODB recommandé). Ajouter les détails de la colonne en cliquant sur le bouton Ajouter une colonne, y compris le nom de la colonne, le type de données, s'il faut autoriser les valeurs nuls et d'autres propriétés. Sélectionnez une ou plusieurs colonnes comme clés principales. Cliquez sur le bouton Enregistrer pour créer des tables et des colonnes.
 Comment gérer la fragmentation de la mémoire redis?
Apr 10, 2025 pm 02:24 PM
Comment gérer la fragmentation de la mémoire redis?
Apr 10, 2025 pm 02:24 PM
La fragmentation de la mémoire redis fait référence à l'existence de petites zones libres dans la mémoire allouée qui ne peut pas être réaffectée. Les stratégies d'adaptation comprennent: Redémarrer Redis: effacer complètement la mémoire, mais le service d'interruption. Optimiser les structures de données: utilisez une structure plus adaptée à Redis pour réduire le nombre d'allocations et de versions de mémoire. Ajustez les paramètres de configuration: utilisez la stratégie pour éliminer les paires de valeurs clés les moins récemment utilisées. Utilisez le mécanisme de persistance: sauvegardez régulièrement les données et redémarrez Redis pour nettoyer les fragments. Surveillez l'utilisation de la mémoire: découvrez les problèmes en temps opportun et prenez des mesures.
 Comment créer une base de données Oracle Comment créer une base de données Oracle
Apr 11, 2025 pm 02:33 PM
Comment créer une base de données Oracle Comment créer une base de données Oracle
Apr 11, 2025 pm 02:33 PM
La création d'une base de données Oracle n'est pas facile, vous devez comprendre le mécanisme sous-jacent. 1. Vous devez comprendre les concepts de la base de données et des SGBD Oracle; 2. Master les concepts de base tels que SID, CDB (base de données de conteneurs), PDB (base de données enfichable); 3. Utilisez SQL * Plus pour créer CDB, puis créer PDB, vous devez spécifier des paramètres tels que la taille, le nombre de fichiers de données et les chemins; 4. Les applications avancées doivent ajuster le jeu de caractères, la mémoire et d'autres paramètres et effectuer un réglage des performances; 5. Faites attention à l'espace disque, aux autorisations et aux paramètres des paramètres, et surveillez et optimisez en continu les performances de la base de données. Ce n'est qu'en le maîtrisant habilement une pratique continue que vous pouvez vraiment comprendre la création et la gestion des bases de données Oracle.
 Comment créer une base de données Oracle Comment créer une base de données Oracle
Apr 11, 2025 pm 02:36 PM
Comment créer une base de données Oracle Comment créer une base de données Oracle
Apr 11, 2025 pm 02:36 PM
Pour créer une base de données Oracle, la méthode commune consiste à utiliser l'outil graphique DBCA. Les étapes sont les suivantes: 1. Utilisez l'outil DBCA pour définir le nom DBN pour spécifier le nom de la base de données; 2. Définissez Syspassword et SystemPassword sur des mots de passe forts; 3. Définir les caractères et NationalCharacterset à Al32Utf8; 4. Définissez la taille de mémoire et les espaces de table pour s'ajuster en fonction des besoins réels; 5. Spécifiez le chemin du fichier log. Les méthodes avancées sont créées manuellement à l'aide de commandes SQL, mais sont plus complexes et sujets aux erreurs. Faites attention à la force du mot de passe, à la sélection du jeu de caractères, à la taille et à la mémoire de l'espace de table
 Moniteur Disd Droplet avec service d'exportateur Redis
Apr 10, 2025 pm 01:36 PM
Moniteur Disd Droplet avec service d'exportateur Redis
Apr 10, 2025 pm 01:36 PM
La surveillance efficace des bases de données Redis est essentielle pour maintenir des performances optimales, identifier les goulots d'étranglement potentiels et assurer la fiabilité globale du système. Le service Redis Exporter est un utilitaire puissant conçu pour surveiller les bases de données Redis à l'aide de Prometheus. Ce didacticiel vous guidera à travers la configuration et la configuration complètes du service Redis Exportateur, en vous garantissant de créer des solutions de surveillance de manière transparente. En étudiant ce tutoriel, vous réaliserez les paramètres de surveillance entièrement opérationnels
 Quels sont les paramètres de configuration de la mémoire redis?
Apr 10, 2025 pm 02:03 PM
Quels sont les paramètres de configuration de la mémoire redis?
Apr 10, 2025 pm 02:03 PM
** Le paramètre central de la configuration de la mémoire redis est MaxMemory, qui limite la quantité de mémoire que Redis peut utiliser. Lorsque cette limite est dépassée, Redis exécute une stratégie d'élimination selon maxmemory-policy, notamment: Noeviction (rejeter directement l'écriture), AllKeys-LRU / Volatile-LRU (éliminé par LRU), AllKeys-Random / Volatile-Random (éliminé par élimination aléatoire) et TTL volatile (temps d'expiration). D'autres paramètres connexes incluent des échantillons maxmemory (quantité d'échantillon LRU), compression RDB
 Comment rédiger des instructions de base de données Oracle
Apr 11, 2025 pm 02:42 PM
Comment rédiger des instructions de base de données Oracle
Apr 11, 2025 pm 02:42 PM
Le cœur des instructions Oracle SQL est sélectionné, insérer, mettre à jour et supprimer, ainsi que l'application flexible de diverses clauses. Il est crucial de comprendre le mécanisme d'exécution derrière l'instruction, tel que l'optimisation de l'indice. Les usages avancés comprennent des sous-requêtes, des requêtes de connexion, des fonctions d'analyse et PL / SQL. Les erreurs courantes incluent les erreurs de syntaxe, les problèmes de performances et les problèmes de cohérence des données. Les meilleures pratiques d'optimisation des performances impliquent d'utiliser des index appropriés, d'éviter la sélection *, d'optimiser les clauses et d'utiliser des variables liées. La maîtrise d'Oracle SQL nécessite de la pratique, y compris l'écriture de code, le débogage, la réflexion et la compréhension des mécanismes sous-jacents.
 Qu'est-ce que le mécanisme de gestion de la mémoire redis?
Apr 10, 2025 pm 01:39 PM
Qu'est-ce que le mécanisme de gestion de la mémoire redis?
Apr 10, 2025 pm 01:39 PM
Redis adopte un mécanisme de gestion granulaire de la mémoire, notamment: une structure de données conviviale bien conçue, un allocateur multi-mémoire qui optimise les stratégies d'allocation pour différentes tailles de blocs de mémoire, un mécanisme d'élimination de la mémoire qui sélectionne une stratégie d'élimination basée sur des besoins spécifiques et des outils pour surveiller l'utilisation de la mémoire. Le but de ce mécanisme est d'atteindre les performances ultimes, grâce à un contrôle fin et à une utilisation efficace de la mémoire, à minimiser la fragmentation de la mémoire et à améliorer l'efficacité d'accès, en veillant à ce que Redis fonctionne de manière stable et efficace dans divers scénarios.
