
 développement back-end
Tutoriel Python
Quel est le principe de mise en œuvre des listes dans la machine virtuelle Python ?
développement back-end
Tutoriel Python
Quel est le principe de mise en œuvre des listes dans la machine virtuelle Python ?
Quel est le principe de mise en œuvre des listes dans la machine virtuelle Python ?

La structure de la liste
Dans la machine virtuelle python implémentée par cpython, voici le code source de l'implémentation de la liste interne de cpython :
typedef struct {
PyObject_VAR_HEAD
/* Vector of pointers to list elements. list[0] is ob_item[0], etc. */
PyObject **ob_item;
/* ob_item contains space for 'allocated' elements. The number
* currently in use is ob_size.
* Invariants:
* 0 <= ob_size <= allocated
* len(list) == ob_size
* ob_item == NULL implies ob_size == allocated == 0
* list.sort() temporarily sets allocated to -1 to detect mutations.
*
* Items must normally not be NULL, except during construction when
* the list is not yet visible outside the function that builds it.
*/
Py_ssize_t allocated;
} PyListObject;
#define PyObject_VAR_HEAD PyVarObject ob_base;
typedef struct {
PyObject ob_base;
Py_ssize_t ob_size; /* Number of items in variable part */
} PyVarObject;
typedef struct _object {
_PyObject_HEAD_EXTRA // 这个宏定义为空
Py_ssize_t ob_refcnt;
struct _typeobject *ob_type;
} PyObject;Après avoir développé la structure ci-dessus, la structure de PyListObject est à peu près la suivante :

Expliquons maintenant la signification de chaque champ ci-dessus :
Py_ssize_t, un type de données entier.
ob_refcnt représente le nombre de décomptes de références de l'objet. Ceci est très utile pour le garbage collection. Plus tard, nous analyserons en profondeur la partie garbage collection de la machine virtuelle.
ob_type indique quel est le type de données de cet objet. En python, il est parfois nécessaire de juger du type de données des données. Par exemple, les deux mots-clés isinstance et type utiliseront ce champ.
ob_size, ce champ indique combien d'éléments il y a dans cette liste.
ob_item, il s'agit d'un pointeur pointant vers l'adresse où les données de l'objet python sont réellement enregistrées. La disposition approximative de la mémoire entre eux est la suivante :
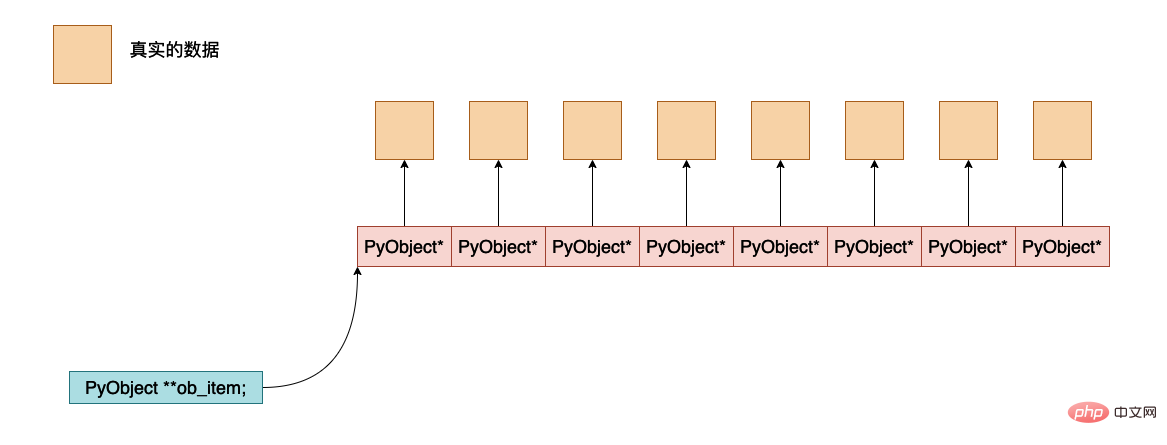
alloué, cela signifie que la mémoire est allouée. est alloué Lors de l'allocation, combien de (PyObject *) sont alloués au total, et l'espace mémoire réellement alloué est
allocated * sizeof(PyObject *).
Analyse du code source de la fonction d'opération de liste
Création d'une liste
La première chose que vous devez comprendre est qu'un tableau est créé pour la liste à l'intérieur de la machine virtuelle Python et que tout l'espace mémoire libéré créé ne sera pas libéré directement les premières adresses de ces espaces mémoire seront enregistrées dans ce tableau, de sorte que la prochaine fois que vous demanderez de créer une nouvelle liste, vous n'aurez pas besoin de demander de l'espace mémoire, mais pourrez directement réutiliser la mémoire qui doit être libérée. avant.
/* Empty list reuse scheme to save calls to malloc and free */ #ifndef PyList_MAXFREELIST #define PyList_MAXFREELIST 80 #endif static PyListObject *free_list[PyList_MAXFREELIST]; static int numfree = 0;
free_list, enregistre la première adresse de l'espace mémoire libéré.
numfree, combien d'adresses dans free_list peuvent être utilisées actuellement ? En fait, les premières adresses numfree dans free_list peuvent être utilisées.
Le code pour créer une liste chaînée est le suivant (certains codes ont été supprimés pour simplifier et seule la partie principale est conservée) :
PyObject *
PyList_New(Py_ssize_t size)
{
PyListObject *op;
size_t nbytes;
/* Check for overflow without an actual overflow,
* which can cause compiler to optimise out */
if ((size_t)size > PY_SIZE_MAX / sizeof(PyObject *))
return PyErr_NoMemory();
nbytes = size * sizeof(PyObject *);
// 如果 numfree 不等于 0 那么说明现在 free_list 有之前使用被释放的内存空间直接使用这部分即可
if (numfree) {
numfree--;
op = free_list[numfree]; // 将对应的首地址返回
_Py_NewReference((PyObject *)op); // 这条语句的含义是将 op 这个对象的 reference count 设置成 1
} else {
// 如果没有空闲的内存空间 那么就需要申请内存空间 这个函数也会对对象的 reference count 进行初始化 设置成 1
op = PyObject_GC_New(PyListObject, &PyList_Type);
if (op == NULL)
return NULL;
}
/* 下面是申请列表对象当中的 ob_item 申请内存空间,上面只是给列表本身申请内存空间,但是列表当中有许多元素
保存这些元素也是需要内存空间的 下面便是给这些对象申请内存空间
*/
if (size <= 0)
op->ob_item = NULL;
else {
op->ob_item = (PyObject **) PyMem_MALLOC(nbytes);
// 如果申请内存空间失败 则报错
if (op->ob_item == NULL) {
Py_DECREF(op);
return PyErr_NoMemory();
}
// 对元素进行初始化操作 全部赋值成 0
memset(op->ob_item, 0, nbytes);
}
// Py_SIZE 是一个宏
Py_SIZE(op) = size; // 这条语句会被展开成 (PyVarObject*)(ob))->ob_size = size
// 分配数组的元素个数是 size
op->allocated = size;
// 下面这条语句对于垃圾回收比较重要 主要作用就是将这个列表对象加入到垃圾回收的链表当中
// 后面如果这个对象的 reference count 变成 0 或者其他情况 就可以进行垃圾回收了
_PyObject_GC_TRACK(op);
return (PyObject *) op;
}En cpython, le bytecode pour créer une liste chaînée est BUILD_LIST, et on peut trouver celui correspondant dans le fichier ceval.c Les étapes d'exécution correspondant au bytecode :
TARGET(BUILD_LIST) {
PyObject *list = PyList_New(oparg);
if (list == NULL)
goto error;
while (--oparg >= 0) {
PyObject *item = POP();
PyList_SET_ITEM(list, oparg, item);
}
PUSH(list);
DISPATCH();
}D'après les étapes d'explication correspondant au bytecode BUILD_LIST ci-dessus, on peut savoir que la fonction PyList_New est bien appelée pour créer une nouvelle liste lors de l'interprétation et en exécutant le bytecode BUILD_LIST.
Fonction d'ajout de liste
static PyObject *
// 这个函数的传入参数是列表本身 self 需要 append 的元素为 v
// 也就是将对象 v 加入到列表 self 当中
listappend(PyListObject *self, PyObject *v)
{
if (app1(self, v) == 0)
Py_RETURN_NONE;
return NULL;
}
static int
app1(PyListObject *self, PyObject *v)
{
// PyList_GET_SIZE(self) 展开之后为 ((PyVarObject*)(self))->ob_size
Py_ssize_t n = PyList_GET_SIZE(self);
assert (v != NULL);
// 如果元素的个数已经等于允许的最大的元素个数 就报错
if (n == PY_SSIZE_T_MAX) {
PyErr_SetString(PyExc_OverflowError,
"cannot add more objects to list");
return -1;
}
// 下面的函数 list_resize 会保存 ob_item 指向的位置能够容纳最少 n+1 个元素(PyObject *)
// 如果容量不够就会进行扩容操作
if (list_resize(self, n+1) == -1)
return -1;
// 将对象 v 的 reference count 加一 因为列表当中使用了一次这个对象 所以对象的引用计数需要进行加一操作
Py_INCREF(v);
PyList_SET_ITEM(self, n, v); // 宏展开之后 ((PyListObject *)(op))->ob_item[i] = v
return 0;
}Mécanisme d'expansion de la liste
static int
list_resize(PyListObject *self, Py_ssize_t newsize)
{
PyObject **items;
size_t new_allocated;
Py_ssize_t allocated = self->allocated;
/* Bypass realloc() when a previous overallocation is large enough
to accommodate the newsize. If the newsize falls lower than half
the allocated size, then proceed with the realloc() to shrink the list.
*/
// 如果列表已经分配的元素个数大于需求个数 newsize 的就直接返回不需要进行扩容
if (allocated >= newsize && newsize >= (allocated >> 1)) {
assert(self->ob_item != NULL || newsize == 0);
Py_SIZE(self) = newsize;
return 0;
}
/* This over-allocates proportional to the list size, making room
* for additional growth. The over-allocation is mild, but is
* enough to give linear-time amortized behavior over a long
* sequence of appends() in the presence of a poorly-performing
* system realloc().
* The growth pattern is: 0, 4, 8, 16, 25, 35, 46, 58, 72, 88, ...
*/
// 这是核心的数组大小扩容机制 new_allocated 表示新增的数组大小
new_allocated = (newsize >> 3) + (newsize < 9 ? 3 : 6);
/* check for integer overflow */
if (new_allocated > PY_SIZE_MAX - newsize) {
PyErr_NoMemory();
return -1;
} else {
new_allocated += newsize;
}
if (newsize == 0)
new_allocated = 0;
items = self->ob_item;
if (new_allocated <= (PY_SIZE_MAX / sizeof(PyObject *)))
// PyMem_RESIZE 这是一个宏定义 会申请 new_allocated 个数元素并且将原来数组的元素拷贝到新的数组当中
PyMem_RESIZE(items, PyObject *, new_allocated);
else
items = NULL;
// 如果没有申请到内存 那么报错
if (items == NULL) {
PyErr_NoMemory();
return -1;
}
// 更新列表当中的元素数据
self->ob_item = items;
Py_SIZE(self) = newsize;
self->allocated = new_allocated;
return 0;
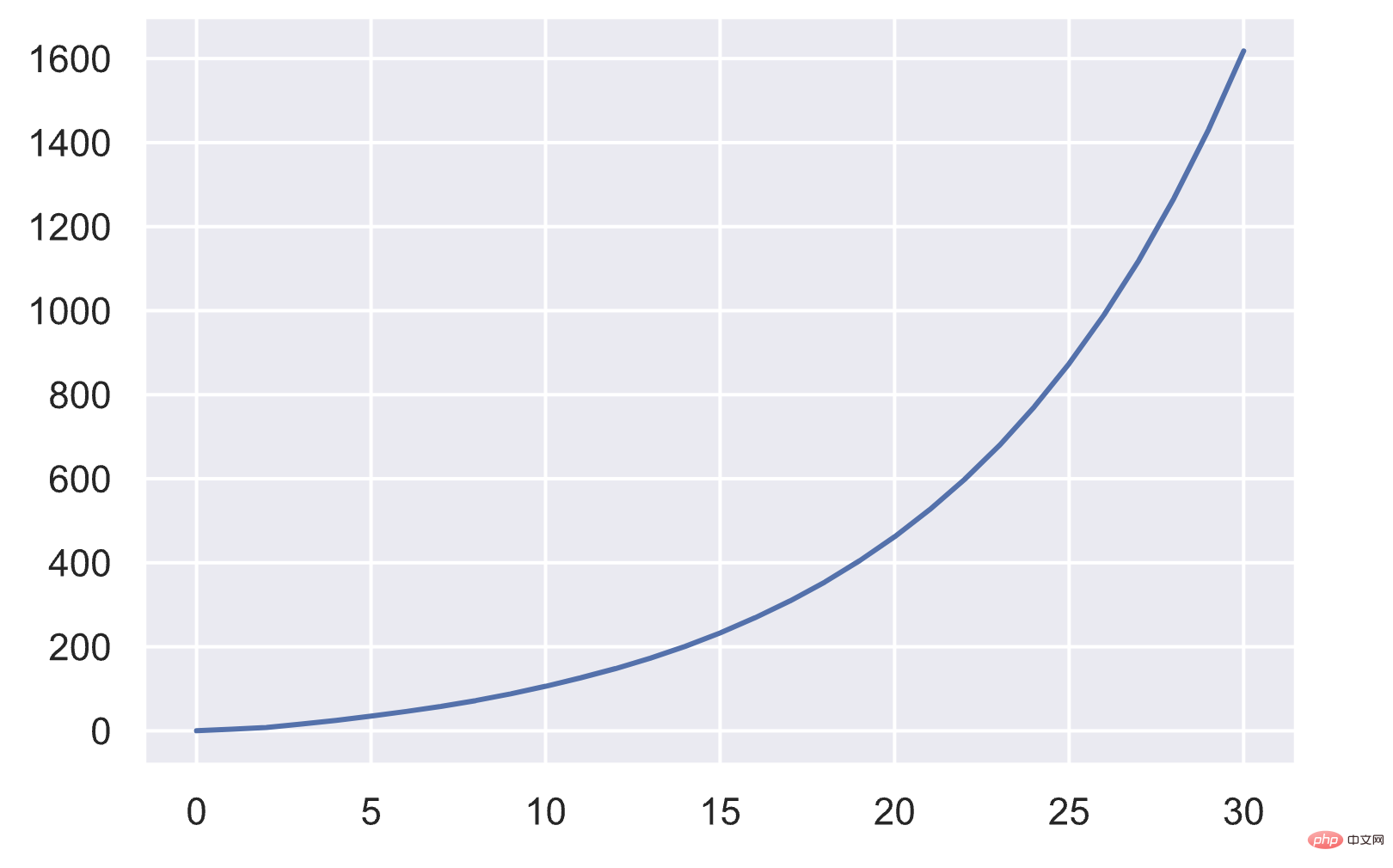
}Sous le mécanisme d'expansion ci-dessus, la taille du tableau change à peu près comme suit :
newsize≈size⋅(size+1)1/8
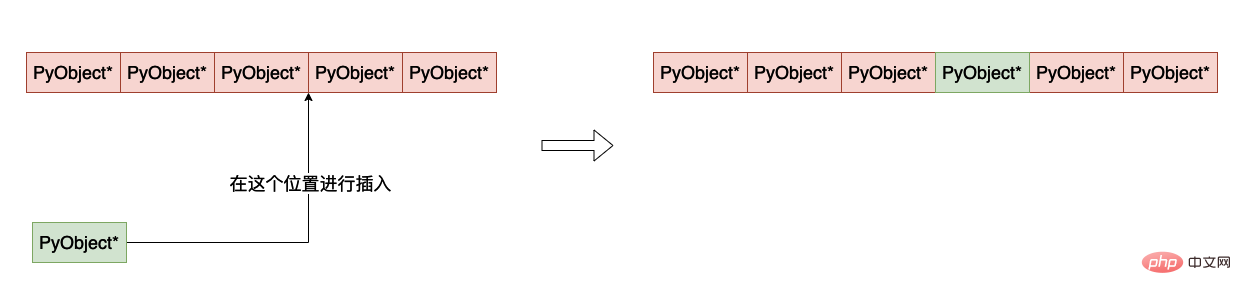
La fonction d'insertion de liste insert
L'insertion d'une donnée dans une liste est relativement simple. Il vous suffit de déplacer la position d'insertion et l'élément derrière elle d'une position en arrière :
En cpython. list L'implémentation de la fonction d'insertion est la suivante :
Le paramètre op indique dans quelle liste chaînée insérer les éléments.
Le paramètre où indique où dans la liste chaînée insérer l'élément.
Le paramètre newitem représente l'élément nouvellement inséré.
int
PyList_Insert(PyObject *op, Py_ssize_t where, PyObject *newitem)
{
// 检查是否是列表类型
if (!PyList_Check(op)) {
PyErr_BadInternalCall();
return -1;
}
// 如果是列表类型则进行插入操作
return ins1((PyListObject *)op, where, newitem);
}
static int
ins1(PyListObject *self, Py_ssize_t where, PyObject *v)
{
Py_ssize_t i, n = Py_SIZE(self);
PyObject **items;
if (v == NULL) {
PyErr_BadInternalCall();
return -1;
}
// 如果列表的元素个数超过限制 则进行报错
if (n == PY_SSIZE_T_MAX) {
PyErr_SetString(PyExc_OverflowError,
"cannot add more objects to list");
return -1;
}
// 确保列表能够容纳 n + 1 个元素
if (list_resize(self, n+1) == -1)
return -1;
// 这里是 python 的一个小 trick 就是下标能够有负数的原理
if (where < 0) {
where += n;
if (where < 0)
where = 0;
}
if (where > n)
where = n;
items = self->ob_item;
// 从后往前进行元素的拷贝操作,也就是将插入位置及其之后的元素往后移动一个位置
for (i = n; --i >= where; )
items[i+1] = items[i];
// 因为链表应用的对象,因此对象的 reference count 需要进行加一操作
Py_INCREF(v);
// 在列表当中保存对象 v
items[where] = v;
return 0;
}La fonction delete delete
pour le tableau ob_item, la suppression d'un élément nécessite de déplacer les éléments derrière cet élément vers l'avant, donc l'ensemble du processus est le suivant :

static PyObject *
listremove(PyListObject *self, PyObject *v)
{
Py_ssize_t i;
// 编译数组 ob_item 查找和对象 v 相等的元素并且将其删除
for (i = 0; i < Py_SIZE(self); i++) {
int cmp = PyObject_RichCompareBool(self->ob_item[i], v, Py_EQ);
if (cmp > 0) {
if (list_ass_slice(self, i, i+1,
(PyObject *)NULL) == 0)
Py_RETURN_NONE;
return NULL;
}
else if (cmp < 0)
return NULL;
}
// 如果没有找到这个元素就进行报错处理 在下面有一个例子重新编译 python 解释器 将这个错误内容修改的例子
PyErr_SetString(PyExc_ValueError, "list.remove(x): x not in list");
return NULL;
}Programme Python exécuté Le contenu est :
data = [] data.remove(1)
Ce qui suit est l'intégralité du contenu de la modification et le résultat de l'erreur :
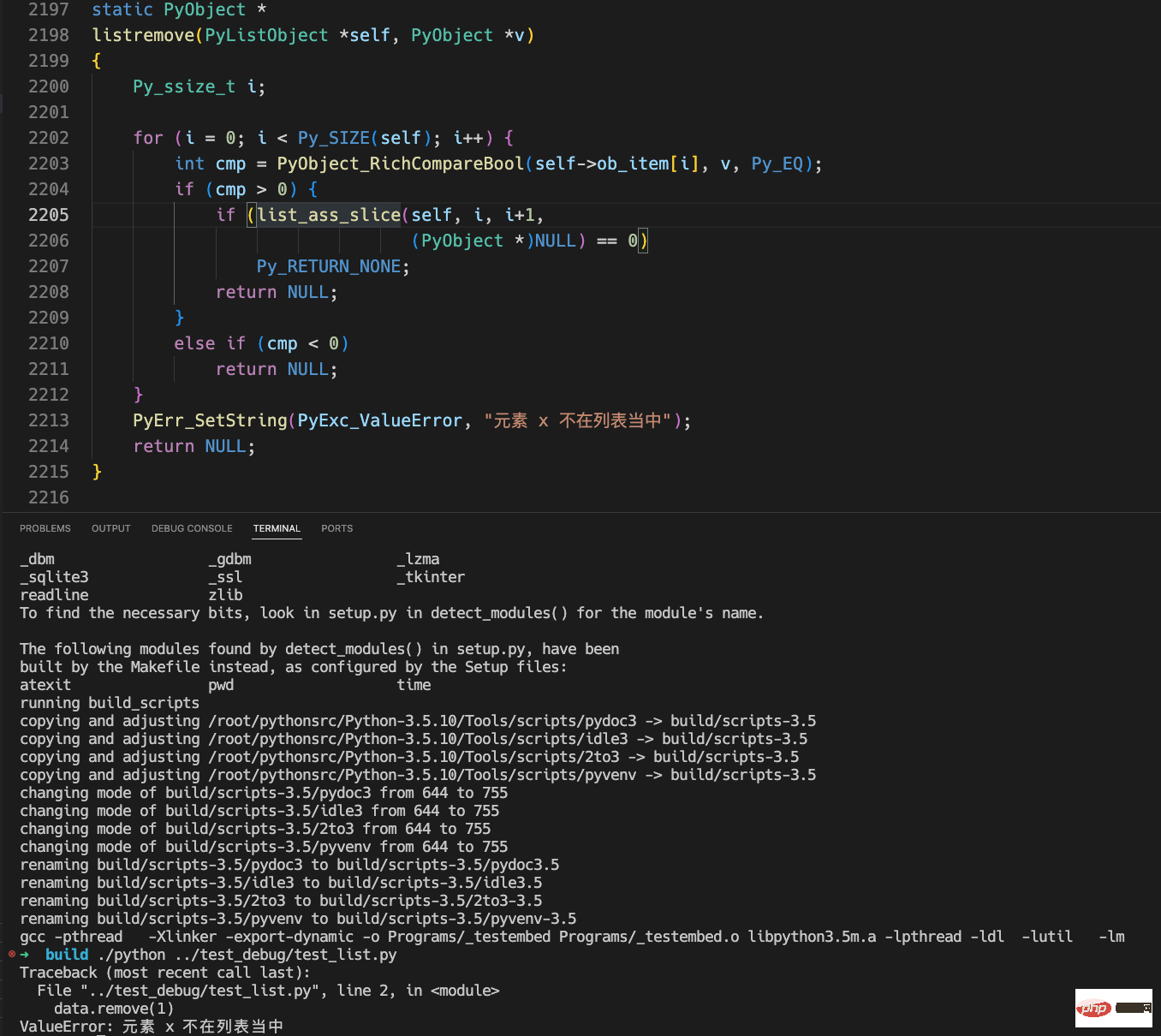
D'après les résultats ci-dessus, nous pouvons voir que le message d'erreur que nous avons modifié est imprimé correctement.
Compte de fonctions statistiques de liste
La fonction principale de cette fonction est de compter combien d'éléments dans la liste self sont égaux à v.
static PyObject *
listcount(PyListObject *self, PyObject *v)
{
Py_ssize_t count = 0;
Py_ssize_t i;
for (i = 0; i < Py_SIZE(self); i++) {
int cmp = PyObject_RichCompareBool(self->ob_item[i], v, Py_EQ);
// 如果相等则将 count 进行加一操作
if (cmp > 0)
count++;
// 如果出现错误就返回 NULL
else if (cmp < 0)
return NULL;
}
// 将一个 Py_ssize_t 的变量变成 python 当中的对象
return PyLong_FromSsize_t(count);
}Fonction de copie de la liste
Il s'agit d'une fonction de copie superficielle de la liste. Elle copie uniquement le pointeur du véritable objet python et ne copie pas le véritable objet python. À partir du code suivant, nous pouvons savoir que la copie. de la liste est une copie superficielle. Lorsque Lorsque b modifie les éléments de la liste, les éléments de la liste a changent également. Si vous devez effectuer une copie complète, vous pouvez utiliser la fonction deepcopy dans le module de copie.
>>> a = [1, 2, [3, 4]] >>> b = a.copy() >>> b[2][1] = 5 >>> b [1, 2, [3, 5]]
copy 函数对应的源代码(listcopy)如下所示:
static PyObject *
listcopy(PyListObject *self)
{
return list_slice(self, 0, Py_SIZE(self));
}
static PyObject *
list_slice(PyListObject *a, Py_ssize_t ilow, Py_ssize_t ihigh)
{
// Py_SIZE(a) 返回列表 a 当中元素的个数(注意不是数组的长度 allocated)
PyListObject *np;
PyObject **src, **dest;
Py_ssize_t i, len;
if (ilow < 0)
ilow = 0;
else if (ilow > Py_SIZE(a))
ilow = Py_SIZE(a);
if (ihigh < ilow)
ihigh = ilow;
else if (ihigh > Py_SIZE(a))
ihigh = Py_SIZE(a);
len = ihigh - ilow;
np = (PyListObject *) PyList_New(len);
if (np == NULL)
return NULL;
src = a->ob_item + ilow;
dest = np->ob_item;
// 可以看到这里循环拷贝的是指向真实 python 对象的指针 并不是真实的对象
for (i = 0; i < len; i++) {
PyObject *v = src[i];
// 同样的因为并没有创建新的对象,但是这个对象被新的列表使用到啦 因此他的 reference count 需要进行加一操作 Py_INCREF(v) 的作用:将对象 v 的 reference count 加一
Py_INCREF(v);
dest[i] = v;
}
return (PyObject *)np;
}下图就是使用 a.copy() 浅拷贝的时候,内存的布局的示意图,可以看到列表指向的对象数组发生了变化,但是数组中元素指向的 python 对象并没有发生变化。
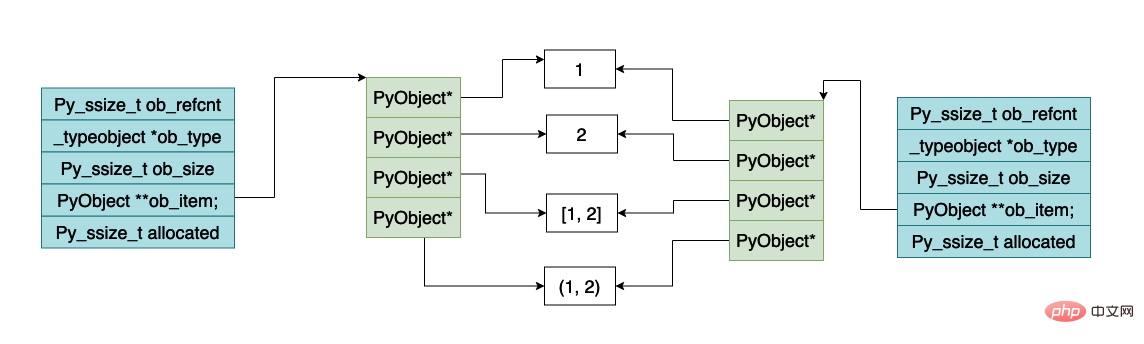
下面是对列表对象进行深拷贝的时候内存的大致示意图,可以看到数组指向的 python 对象也是不一样的。
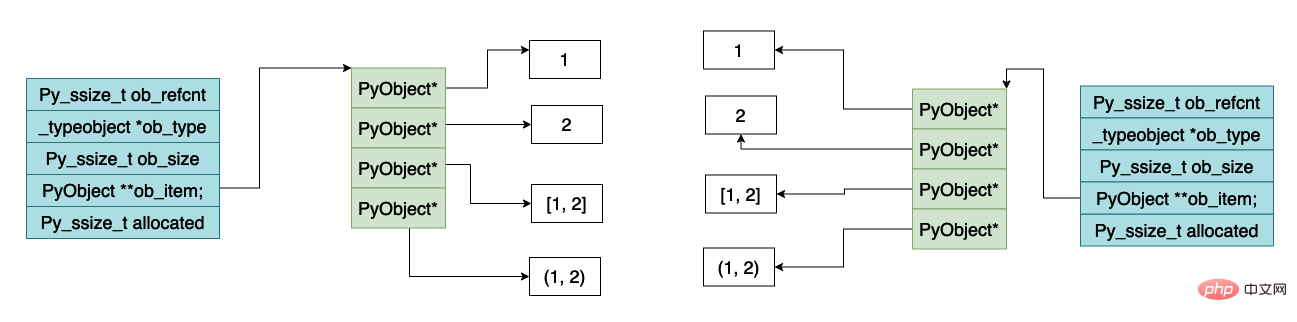
列表的清空函数 clear
当我们在使用 list.clear() 的时候会调用下面这个函数。清空列表需要注意的就是将表示列表当中元素个数的 ob_size 字段设置成 0 ,同时将列表当中所有的对象的 reference count 设置进行 -1 操作,这个操作是通过宏 Py_XDECREF 实现的,这个宏还会做另外一件事就是如果这个对象的引用计数变成 0 了,那么就会直接释放他的内存。
static PyObject *
listclear(PyListObject *self)
{
list_clear(self);
Py_RETURN_NONE;
}
static int
list_clear(PyListObject *a)
{
Py_ssize_t i;
PyObject **item = a->ob_item;
if (item != NULL) {
/* Because XDECREF can recursively invoke operations on
this list, we make it empty first. */
i = Py_SIZE(a);
Py_SIZE(a) = 0;
a->ob_item = NULL;
a->allocated = 0;
while (--i >= 0) {
Py_XDECREF(item[i]);
}
PyMem_FREE(item);
}
/* Never fails; the return value can be ignored.
Note that there is no guarantee that the list is actually empty
at this point, because XDECREF may have populated it again! */
return 0;
}列表反转函数 reverse
在 python 当中如果我们想要反转类表当中的内容的话,就会使用这个函数 reverse 。
>>> a = [i for i in range(10)] >>> a.reverse() >>> a [9, 8, 7, 6, 5, 4, 3, 2, 1, 0]
其对应的源程序如下所示:
static PyObject *
listreverse(PyListObject *self)
{
if (Py_SIZE(self) > 1)
reverse_slice(self->ob_item, self->ob_item + Py_SIZE(self));
Py_RETURN_NONE;
}
static void
reverse_slice(PyObject **lo, PyObject **hi)
{
assert(lo && hi);
--hi;
while (lo < hi) {
PyObject *t = *lo;
*lo = *hi;
*hi = t;
++lo;
--hi;
}
}上面的源程序还是比较容易理解的,给 reverse_slice 传递的参数就是保存数据的数组的首尾地址,然后不断的将首尾数据进行交换(其实是交换指针指向的地址)。
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 PHP et Python: exemples de code et comparaison
Apr 15, 2025 am 12:07 AM
PHP et Python: exemples de code et comparaison
Apr 15, 2025 am 12:07 AM
PHP et Python ont leurs propres avantages et inconvénients, et le choix dépend des besoins du projet et des préférences personnelles. 1.Php convient au développement rapide et à la maintenance des applications Web à grande échelle. 2. Python domine le domaine de la science des données et de l'apprentissage automatique.
 Python vs JavaScript: communauté, bibliothèques et ressources
Apr 15, 2025 am 12:16 AM
Python vs JavaScript: communauté, bibliothèques et ressources
Apr 15, 2025 am 12:16 AM
Python et JavaScript ont leurs propres avantages et inconvénients en termes de communauté, de bibliothèques et de ressources. 1) La communauté Python est amicale et adaptée aux débutants, mais les ressources de développement frontal ne sont pas aussi riches que JavaScript. 2) Python est puissant dans les bibliothèques de science des données et d'apprentissage automatique, tandis que JavaScript est meilleur dans les bibliothèques et les cadres de développement frontaux. 3) Les deux ont des ressources d'apprentissage riches, mais Python convient pour commencer par des documents officiels, tandis que JavaScript est meilleur avec MDNWEBDOCS. Le choix doit être basé sur les besoins du projet et les intérêts personnels.
 Comment est la prise en charge du GPU pour Pytorch sur Centos
Apr 14, 2025 pm 06:48 PM
Comment est la prise en charge du GPU pour Pytorch sur Centos
Apr 14, 2025 pm 06:48 PM
Activer l'accélération du GPU Pytorch sur le système CentOS nécessite l'installation de versions CUDA, CUDNN et GPU de Pytorch. Les étapes suivantes vous guideront tout au long du processus: CUDA et CUDNN Installation détermineront la compatibilité de la version CUDA: utilisez la commande NVIDIA-SMI pour afficher la version CUDA prise en charge par votre carte graphique NVIDIA. Par exemple, votre carte graphique MX450 peut prendre en charge CUDA11.1 ou plus. Téléchargez et installez Cudatoolkit: visitez le site officiel de Nvidiacudatoolkit et téléchargez et installez la version correspondante selon la version CUDA la plus élevée prise en charge par votre carte graphique. Installez la bibliothèque CUDNN:
 Explication détaillée du principe docker
Apr 14, 2025 pm 11:57 PM
Explication détaillée du principe docker
Apr 14, 2025 pm 11:57 PM
Docker utilise les fonctionnalités du noyau Linux pour fournir un environnement de fonctionnement d'application efficace et isolé. Son principe de travail est le suivant: 1. Le miroir est utilisé comme modèle en lecture seule, qui contient tout ce dont vous avez besoin pour exécuter l'application; 2. Le Système de fichiers Union (UnionFS) empile plusieurs systèmes de fichiers, ne stockant que les différences, l'économie d'espace et l'accélération; 3. Le démon gère les miroirs et les conteneurs, et le client les utilise pour l'interaction; 4. Les espaces de noms et les CGROUP implémentent l'isolement des conteneurs et les limitations de ressources; 5. Modes de réseau multiples prennent en charge l'interconnexion du conteneur. Ce n'est qu'en comprenant ces concepts principaux que vous pouvez mieux utiliser Docker.
 Miniopen Centos Compatibilité
Apr 14, 2025 pm 05:45 PM
Miniopen Centos Compatibilité
Apr 14, 2025 pm 05:45 PM
Minio Object Storage: Déploiement haute performance dans le système Centos System Minio est un système de stockage d'objets distribué haute performance développé sur la base du langage Go, compatible avec Amazons3. Il prend en charge une variété de langages clients, notamment Java, Python, JavaScript et GO. Cet article introduira brièvement l'installation et la compatibilité de Minio sur les systèmes CentOS. Compatibilité de la version CentOS Minio a été vérifiée sur plusieurs versions CentOS, y compris, mais sans s'y limiter: CentOS7.9: fournit un guide d'installation complet couvrant la configuration du cluster, la préparation de l'environnement, les paramètres de fichiers de configuration, le partitionnement du disque et la mini
 Comment faire fonctionner la formation distribuée de Pytorch sur CentOS
Apr 14, 2025 pm 06:36 PM
Comment faire fonctionner la formation distribuée de Pytorch sur CentOS
Apr 14, 2025 pm 06:36 PM
La formation distribuée par Pytorch sur le système CentOS nécessite les étapes suivantes: Installation de Pytorch: La prémisse est que Python et PIP sont installés dans le système CentOS. Selon votre version CUDA, obtenez la commande d'installation appropriée sur le site officiel de Pytorch. Pour la formation du processeur uniquement, vous pouvez utiliser la commande suivante: pipinstalltorchtorchVisionTorChaudio Si vous avez besoin d'une prise en charge du GPU, assurez-vous que la version correspondante de CUDA et CUDNN est installée et utilise la version Pytorch correspondante pour l'installation. Configuration de l'environnement distribué: la formation distribuée nécessite généralement plusieurs machines ou des GPU multiples uniques. Lieu
 Comment choisir la version Pytorch sur Centos
Apr 14, 2025 pm 06:51 PM
Comment choisir la version Pytorch sur Centos
Apr 14, 2025 pm 06:51 PM
Lors de l'installation de Pytorch sur le système CentOS, vous devez sélectionner soigneusement la version appropriée et considérer les facteurs clés suivants: 1. Compatibilité de l'environnement du système: Système d'exploitation: Il est recommandé d'utiliser CentOS7 ou plus. CUDA et CUDNN: La version Pytorch et la version CUDA sont étroitement liées. Par exemple, Pytorch1.9.0 nécessite CUDA11.1, tandis que Pytorch2.0.1 nécessite CUDA11.3. La version CUDNN doit également correspondre à la version CUDA. Avant de sélectionner la version Pytorch, assurez-vous de confirmer que des versions compatibles CUDA et CUDNN ont été installées. Version Python: branche officielle de Pytorch
 Comment mettre à jour Pytorch vers la dernière version sur Centos
Apr 14, 2025 pm 06:15 PM
Comment mettre à jour Pytorch vers la dernière version sur Centos
Apr 14, 2025 pm 06:15 PM
La mise à jour de Pytorch vers la dernière version sur CentOS peut suivre les étapes suivantes: Méthode 1: Mise à jour de PIP avec PIP: Assurez-vous d'abord que votre PIP est la dernière version, car les anciennes versions de PIP peuvent ne pas être en mesure d'installer correctement la dernière version de Pytorch. pipinstall-upradepip désinstalle ancienne version de Pytorch (si installé): PipuninstallTorchtorchVisiontorchaudio installation dernier
