

Un filtre Bloom est une structure de données aléatoires très efficace en termes d'espace qui utilise un tableau de bits (BitSet) pour représenter un ensemble et combine les éléments via un certain nombre de fonctions de hachage vers une position dans. un tableau de bits, utilisé pour vérifier si un élément appartient à cet ensemble.
Pour un élément, plusieurs valeurs de hachage sont générées via plusieurs fonctions de hachage, et les bits correspondants sont définis sur 1 dans le tableau de bits si les bits correspondants de plusieurs valeurs de hachage. sont tous 1, On considère que l'élément peut être dans l'ensemble ; si au moins un bit correspondant de la valeur de hachage est 0, l'élément ne doit pas être dans l'ensemble. Cette méthode permet d’obtenir une recherche efficace dans un espace plus petit, mais peut avoir un taux de faux positifs.
Un filtre Bloom typique contient trois paramètres : la taille du tableau de bits (c'est-à-dire le nombre d'éléments stockés) ; le facteur de remplissage (c'est-à-dire le taux de faux positifs) ; , c'est-à-dire le nombre d'éléments par rapport à la taille du tableau de bits.
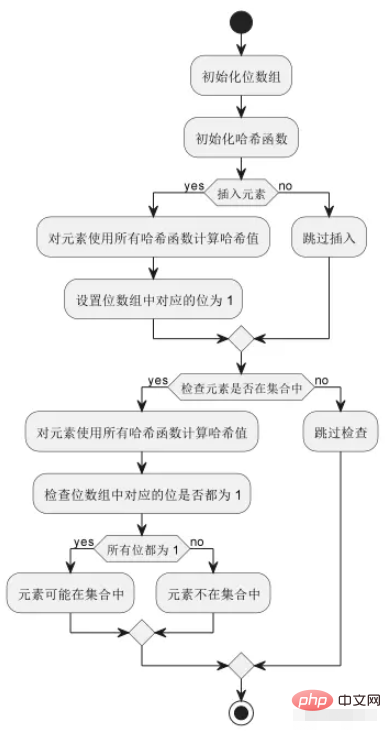
Comme le montre l'image ci-dessus : le processus de fonctionnement de base du filtre Bloom comprend l'initialisation du tableau de bits et de la fonction de hachage, l'insertion d'éléments, la vérification si les éléments sont dans l'ensemble, etc. Parmi eux, chaque élément sera mappé à plusieurs positions dans le tableau de bits par plusieurs fonctions de hachage. Lorsque vous vérifiez si l'élément est dans l'ensemble, vous devez vous assurer que tous les bits correspondants sont définis sur 1 avant de considérer que l'élément peut. être dans l'ensemble en collection.
Filtrage du spam : définissez la valeur de hachage correspondante de tous les e-mails de la liste noire sur 1 dans le filtre Bloom. Pour chaque nouvel e-mail, définissez sa valeur de hachage dans Vérifiez si les positions correspondantes dans le filtre Bloom sont toutes 1.
Déduplication d'URL : La valeur de hachage correspondant à l'URL explorée est dans La position correspondante dans le filtre Bloom est définie sur 1. Pour à chaque nouvelle URL, vérifiez si sa valeur de hachage à la position correspondante dans le filtre Bloom est bien 1. Si tel est le cas, l'URL est considérée comme ayant été explorée. Sinon, une exploration est requise
Panne du cache : Définissez la position correspondante ; de la valeur de hachage de toutes les données existant dans le cache dans le filtre Bloom à 1, et hachez la valeur clé de chaque requête. Vérifiez si les positions correspondantes des valeurs de hachage dans le filtre Bloom sont toutes 1. Si tel est le cas, le La valeur de la clé est considérée comme existant dans le cache. Sinon, elle doit être interrogée dans la base de données et ajoutée au cache.
Il convient de noter que le taux de faux positifs du filtre Bloom diminuera à mesure que la taille du tableau de bits augmente, mais il augmentera également la surcharge de mémoire et le temps de calcul. Afin de faciliter la compréhension des filtres Bloom, ce qui suit utilise du code Java pour implémenter un filtre Bloom simple :
import java.util.BitSet;
import java.util.Random;
public class BloomFilter {
private BitSet bitSet; // 位集,用于存储哈希值
private int bitSetSize; // 位集大小
private int numHashFunctions; // 哈希函数数量
private Random random; // 随机数生成器
// 构造函数,根据期望元素数量和错误率计算位集大小和哈希函数数量
public BloomFilter(int expectedNumItems, double falsePositiveRate) {
this.bitSetSize = optimalBitSetSize(expectedNumItems, falsePositiveRate);
this.numHashFunctions = optimalNumHashFunctions(expectedNumItems, bitSetSize);
this.bitSet = new BitSet(bitSetSize);
this.random = new Random();
}
// 根据期望元素数量和错误率计算最佳位集大小
private int optimalBitSetSize(int expectedNumItems, double falsePositiveRate) {
int bitSetSize = (int) Math.ceil(expectedNumItems * (-Math.log(falsePositiveRate) / Math.pow(Math.log(2), 2)));
return bitSetSize;
}
// 根据期望元素数量和位集大小计算最佳哈希函数数量
private int optimalNumHashFunctions(int expectedNumItems, int bitSetSize) {
int numHashFunctions = (int) Math.ceil((bitSetSize / expectedNumItems) * Math.log(2));
return numHashFunctions;
}
// 添加元素到布隆过滤器中
public void add(String item) {
// 计算哈希值
int[] hashes = createHashes(item.getBytes(), numHashFunctions);
// 将哈希值对应的位设置为 true
for (int hash : hashes) {
bitSet.set(Math.abs(hash % bitSetSize), true);
}
}
// 检查元素是否存在于布隆过滤器中
public boolean contains(String item) {
// 计算哈希值
int[] hashes = createHashes(item.getBytes(), numHashFunctions);
// 检查哈希值对应的位是否都为 true
for (int hash : hashes) {
if (!bitSet.get(Math.abs(hash % bitSetSize))) {
return false;
}
}
return true;
}
// 计算给定数据的哈希值
private int[] createHashes(byte[] data, int numHashes) {
int[] hashes = new int[numHashes];
int hash2 = Math.abs(random.nextInt());
int hash3 = Math.abs(random.nextInt());
for (int i = 0; i < numHashes; i++) {
// 使用两个随机哈希函数计算哈希值
hashes[i] = Math.abs((hash2 * i) + (hash3 * i) + i) % data.length;
}
return hashes;
}
}Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
















![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



