
 développement back-end
Tutoriel Python
Comment utiliser Python pour implémenter la fonction de reconnaissance vocale sous Linux
développement back-end
Tutoriel Python
Comment utiliser Python pour implémenter la fonction de reconnaissance vocale sous Linux
Comment utiliser Python pour implémenter la fonction de reconnaissance vocale sous Linux

Introduction au fonctionnement de la reconnaissance vocale
La reconnaissance vocale est issue de recherches effectuées aux Bell Labs au début des années 1950. Les premiers systèmes de reconnaissance vocale ne pouvaient reconnaître qu’un seul locuteur et un vocabulaire d’une douzaine de mots seulement. Les systèmes modernes de reconnaissance vocale ont parcouru un long chemin pour reconnaître plusieurs locuteurs et disposent de vastes vocabulaires reconnaissant plusieurs langues.
La première partie de la reconnaissance vocale est bien sûr la parole. Grâce au microphone, la parole est convertie du son physique en signaux électriques, puis en données via un convertisseur analogique-numérique. Une fois numérisés, plusieurs modèles peuvent être appliqués pour transcrire l’audio en texte.
La plupart des systèmes de reconnaissance vocale modernes s'appuient sur des modèles de Markov cachés (HMM). Son principe de fonctionnement est le suivant : le signal vocal peut être approché comme un processus stationnaire sur une échelle de temps très courte (par exemple 10 millisecondes), c'est-à-dire un processus dont les caractéristiques statistiques ne changent pas avec le temps.
De nombreux systèmes de reconnaissance vocale modernes utilisent des réseaux de neurones avant la reconnaissance HMM pour simplifier le signal vocal grâce à des techniques de transformation des caractéristiques et de réduction de la dimensionnalité. Les détecteurs d'activité vocale (VAD) peuvent également être utilisés pour réduire le signal audio à des parties pouvant contenir uniquement de la parole.
Heureusement pour les utilisateurs de Python, certains services de reconnaissance vocale sont disponibles en ligne via des API, et la plupart d'entre eux fournissent également des SDK Python. Il existe des packages de reconnaissance vocale prêts à l'emploi dans PyPI. Ceux-ci incluent :
google-cloud-speech
pocketsphinxSpeechRcognition
watson-developer-cloud
wit
Certains progiciels tels que wit et apiai ) offrent certaines fonctionnalités intégrées au-delà de la reconnaissance vocale de base, telles que des capacités de traitement du langage naturel pour identifier l'intention du locuteur. D'autres logiciels, tels que Google Cloud Speech, se concentrent sur la conversion parole-texte.
Parmi eux, SpeechRecognition se démarque par sa simplicité d'utilisation.
La reconnaissance vocale nécessite une entrée audio, et récupérer l'entrée audio dans
SpeechRecognition
est très simple, cela ne nécessite pas de créer un script pour accéder au microphone et traiter le fichier audio à partir de zéro, cela ne prend que quelques minutes Récupération et exécution automatiquement terminées.
Install SpeechRecognitionSpeechRecognition est compatible avec Python2.6, 2.7 et 3.3+, mais certaines étapes d'installation supplémentaires sont requises si elle est utilisée dans Python 2. Vous pouvez utiliser la commande pip pour installer SpeechRecognition depuis le terminal :
Une fois l'installation terminée, vous pouvez ouvrir la fenêtre de l'interpréteur pour vérifier l'installation : pip3 install SpeechRecognition
Si vous avez affaire à des fichiers audio existants, appelez simplement SpeechRecognition directement, en faisant attention à certaines dépendances du cas d'utilisation spécifique. Notez également qu'installez le package PyAudio pour obtenir l'entrée du microphone 
SpeechRecognition Le noyau est la classe de reconnaissance.
)
Ensuite, nous devons installer PocketSphinx via la commande pip Pendant le processus d'installation, un grand nombre d'erreurs dans les polices rouges sont également susceptibles de se produire.
Utilisation des fichiers audioTéléchargez les fichiers audio associés et enregistrez-les dans un répertoire spécifique (enregistrez-les directement sur le bureau Ubuntu)
Remarque :
SpeechRecognition Les types de fichiers actuellement pris en charge sont :
WAV : doit être au format PCM/LPCM
- #🎜 # AIFF #Reconnaissance vocale en anglais
-
Après avoir terminé le travail de base ci-dessus, vous pouvez effectuer la reconnaissance vocale en anglais.
(1) Ouvrez le terminal (2) Entrez le répertoire où se trouve le fichier de test vocal (celui du blogueur est le bureau) - (3) Ouvrez l'interpréteur python
( 4) Suivez l'image ci-dessous Entrez la commande appropriée
- et enfin vous pourrez voir le contenu de la synthèse vocale (ça, ils sentiront…) . En fait, l'effet est très bon ! Parce que c'est en anglais et qu'il n'y a pas de bruit.
En essayant de retranscrire l'effet n'est pas bon, on peut essayer d'appeler la commande ajuster_for_ambient_noise() de la classe Recognizer.
Utilisation du microphone
Pour utiliser SpeechRecognizer pour accéder au microphone, vous devez installer le package PyAudio.
Si vous utilisez Linux basé sur Debian (comme Ubuntu), vous pouvez utiliser apt pour installer PyAudio : sudo apt-get install python-pyaudio python3-pyaudio Vous devrez peut-être toujours activer pip3 install pyaudio une fois l'installation terminée, surtout lors d'une exécution virtuelle. sudo apt-get install python-pyaudio python3-pyaudio安装完成后可能仍需要启用 pip3 install pyaudio ,尤其是在虚拟情况下运行。
在安装完pyaudio的情况下可以通过python实现语音录入生成相关文件。
pocketsphinx的使用注意:
支持文件格式:wav
音频文件的解码要求:16KHZ,单声道
利用python实现录音并生成相关文件程序代码如下:
from pyaudio import PyAudio, paInt16
import numpy as np
import wave
class recoder:
NUM_SAMPLES = 2000
SAMPLING_RATE = 16000
LEVEL = 500
COUNT_NUM = 20
SAVE_LENGTH = 8
Voice_String = []
def savewav(self,filename):
wf = wave.open(filename, 'wb')
wf.setnchannels(1)
wf.setsampwidth(2)
wf.setframerate(self.SAMPLING_RATE)
wf.writeframes(np.array(self.Voice_String).tostring())
wf.close()
def recoder(self):
pa = PyAudio()
stream = pa.open(format=paInt16, channels=1, rate=self.SAMPLING_RATE, input=True,frames_per_buffer=self.NUM_SAMPLES)
save_count = 0
save_buffer = []
while True:
string_audio_data = stream.read(self.NUM_SAMPLES)
audio_data = np.fromstring(string_audio_data, dtype=np.short)
large_sample_count = np.sum(audio_data > self.LEVEL)
print(np.max(audio_data))
if large_sample_count > self.COUNT_NUM:
save_count = self.SAVE_LENGTH
else:
save_count -= 1
if save_count < 0:
save_count = 0
if save_count > 0:
save_buffer.append(string_audio_data )
else:
if len(save_buffer) > 0:
self.Voice_String = save_buffer
save_buffer = []
print("Recode a piece of voice successfully!")
return True
else:
return False
if __name__ == "__main__":
r = recoder()
r.recoder()
r.savewav("test.wav")注意:在利用python解释器实现时一定要注意空格!!!
最后生成的文件就在Python解释器回话所在目录下,可以通过play来播放测试一下,如果没有安装play可以通过apt命令来安装。
中文的语音识别
在进行完以前的工作以后,我们对语音识别的流程大概有了一定的了解,但是作为一个中国人总得做一个中文的语音识别吧!
我们要在CMU Sphinx语音识别工具包里面下载对应的普通话升学和语言模型。
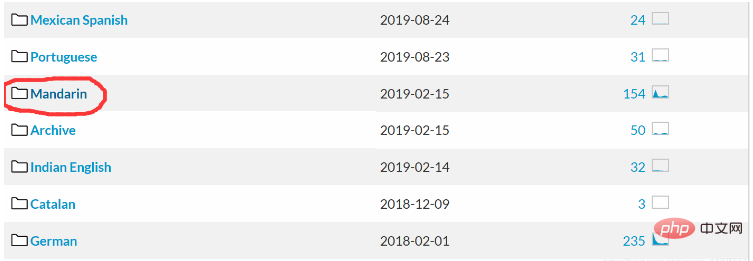
图片中标记的就是普通话!下载相关的语音识别工具包。
但是我们要把zh_broadcastnews_64000_utf8.DMP转化成language-model.lm.bin,再解压zh_broadcastnews_16k_ptm256_8000.tar.bz2得到zh_broadcastnews_ptm256_8000文件夹。
借鉴刚才那位博主的方法,在Ubuntu下找到speech_recognition文件夹。可能会有很多小伙伴找不到相关的文件夹,其实是在隐藏文件下。大家可以点击文件夹右上角的三条杠。如下图所示:

然后给显示隐藏文件打个勾,如下图所示:
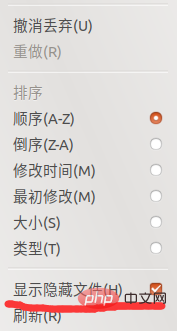
然后依次按照以下目录就可以找到啦:

然后把原来的en-US改名成en-US-bak,新建一个文件夹en-US,把解压出来的zh_broadcastnews_ptm256_8000改成acoustic-model,把chinese.lm.bin改成language-model.lm.bin,把pronounciation-dictionary.dic改后缀成dictAprès avoir installé pyaudio, vous pouvez utiliser python pour générer un enregistrement vocal et des fichiers associés.
Remarques sur l'utilisation de Pocketsphinx :
Exigences de décodage pour les fichiers audio : 16 KHZ, mono 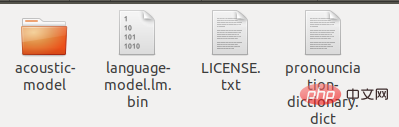 Utilisez Python pour implémenter l'enregistrement et générer les fichiers associés Le code du programme est le suivant :
Utilisez Python pour implémenter l'enregistrement et générer les fichiers associés Le code du programme est le suivant :
Remarque : assurez-vous d'utiliser l'interpréteur python à implémenter Attention aux espaces ! ! !
Le fichier final généré se trouve dans le répertoire où se trouve l'interpréteur Python. Vous pouvez le lire via play pour le tester. Si play n'est pas installé, vous pouvez l'installer via la commande apt.
Reconnaissance vocale chinoise
Après avoir terminé les travaux précédents, nous avons une certaine compréhension du processus de reconnaissance vocale, mais en tant que Chinois, nous devons faire une reconnaissance vocale chinoise ! 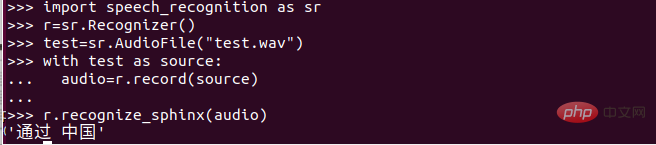
Sur la photo La marque est Mandarin ! Téléchargez la boîte à outils de reconnaissance vocale appropriée.
Mais nous devons convertir zh_broadcastnews_64000_utf8.DMP en language-model.lm.bin, puis décompresser zh_broadcastnews_16k_ptm256_8000.tar.bz2 pour obtenir le dossier zh_broadcastnews_ptm256_8000.
Apprenez tout de suite la méthode du blogueur et recherchez le dossier Speech_recognition sous Ubuntu. Il se peut que de nombreux amis ne trouvent pas les dossiers pertinents, mais ils se trouvent en fait sous des fichiers cachés. Vous pouvez cliquer sur les trois barres dans le coin supérieur droit du dossier. Comme le montre l'image ci-dessous :

Suivez ensuite les répertoires suivants pour le trouver :

en-US d'origine en en-US-bak, créez un nouveau dossier en-US, remplacez le <code>zh_broadcastnews_ptm256_8000 extrait par acoustic-model et remplacez chinese.lm.bin par langage-model.lm.bin, remplacez le suffixe de pronounciation-dictionary.dic par dict et copiez ces trois fichiers dans en-US . En même temps, copiez LICENSE.txt du répertoire de fichiers en-US d'origine dans le dossier actuel. Enfin il y a les fichiers suivants dans ce dossier :
🎜🎜🎜🎜 Ensuite nous pouvons enregistrer un fichier vocal ("test.wav") via le microphone 🎜Ouvrez l'interpréteur python dans le répertoire des fichiers et saisissez le contenu suivant : 🎜🎜 🎜 🎜🎜J'ai vu le contenu de sortie, mais je parlais de deux Chines. J'en ai également testé d'autres et j'ai trouvé que l'effet de reconnaissance était très faible ! ! ! 🎜🎜🎜Reconnaissance chinoise à petite échelle🎜🎜L'effet fourni par la version officielle est si pauvre qu'elle est presque inutilisable ! J'ai ensuite pensé à une méthode d'optimisation après avoir lu de nombreux articles, mais elle ne convient qu'à une reconnaissance à petite échelle ! Certaines commandes et autres devraient convenir, mais le chat et autres peuvent ne pas fonctionner aussi bien. 🎜Trouvez les 4 dossiers que vous venez de copier. Il y a un dossier de pronounciation-dictionary.dict Après l'avoir ouvert, le contenu suivant est trouvé : 🎜🎜🎜🎜🎜On dirait que ce contenu est similaire à un dictionnaire, avec beaucoup de mots et. mots pour la communication quotidienne. L’écart est relativement grand. Ensuite, nous pouvons simplement le remplacer par les mots auxquels nous sommes habitués ! Avec l’idée de l’essayer, le résultat est vraiment bon. L'effet de reconnaissance est vraiment bon ! 🎜Mon approche est la suivante : 🎜(1) Conservez le contenu au-dessus de la marque rouge dans l'image et supprimez le contenu en dessous de la marque rouge. Bien entendu, pour des raisons d'assurance, il est recommandé de sauvegarder ce fichier ! 🎜(2) Saisissez le contenu que vous souhaitez identifier sous la ligne rouge ! (Saisie selon les règles, différente du pinyin !!!) Récemment, la situation de la nouvelle pneumonie s'est améliorée. La phrase la plus entendue est « Allez, Chine ». Le contenu d'aujourd'hui est donc de convertir « Allez, Chine ». en texte ! J'espère que l'école pourra bientôt commencer, hahahaha. 🎜🎜🎜🎜🎜3) Saisissez ce qui suit : 🎜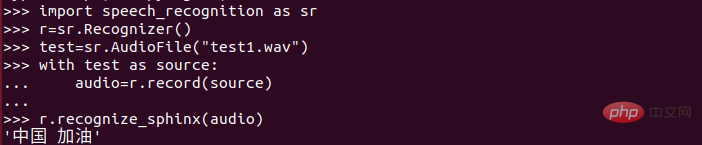
Synthèse vocale
Ma compréhension personnelle de la synthèse vocale est la synthèse vocale. Cependant, dans cette phrase, vous pouvez définir client = AipSpeech(APP_ID, API_KEY, SECRET_KEY) result = client.synthesis('你好百度', 'zh', 1, { 'vol': 5,'spd': 3,'pit':9,'per': 3}) volume, tonalité, vitesse, mâle/femelle/loli/gratuit.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

Video Face Swap
Échangez les visages dans n'importe quelle vidéo sans effort grâce à notre outil d'échange de visage AI entièrement gratuit !

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)
Sujets chauds



 PHP et Python: différents paradigmes expliqués
Apr 18, 2025 am 12:26 AM
PHP et Python: différents paradigmes expliqués
Apr 18, 2025 am 12:26 AM
PHP est principalement la programmation procédurale, mais prend également en charge la programmation orientée objet (POO); Python prend en charge une variété de paradigmes, y compris la POO, la programmation fonctionnelle et procédurale. PHP convient au développement Web, et Python convient à une variété d'applications telles que l'analyse des données et l'apprentissage automatique.
 Choisir entre PHP et Python: un guide
Apr 18, 2025 am 12:24 AM
Choisir entre PHP et Python: un guide
Apr 18, 2025 am 12:24 AM
PHP convient au développement Web et au prototypage rapide, et Python convient à la science des données et à l'apprentissage automatique. 1.Php est utilisé pour le développement Web dynamique, avec une syntaxe simple et adapté pour un développement rapide. 2. Python a une syntaxe concise, convient à plusieurs champs et a un écosystème de bibliothèque solide.
 PHP et Python: une plongée profonde dans leur histoire
Apr 18, 2025 am 12:25 AM
PHP et Python: une plongée profonde dans leur histoire
Apr 18, 2025 am 12:25 AM
PHP est originaire en 1994 et a été développé par Rasmuslerdorf. Il a été utilisé à l'origine pour suivre les visiteurs du site Web et a progressivement évolué en un langage de script côté serveur et a été largement utilisé dans le développement Web. Python a été développé par Guidovan Rossum à la fin des années 1980 et a été publié pour la première fois en 1991. Il met l'accent sur la lisibilité et la simplicité du code, et convient à l'informatique scientifique, à l'analyse des données et à d'autres domaines.
 Comment exécuter le code Java dans le bloc-notes
Apr 16, 2025 pm 07:39 PM
Comment exécuter le code Java dans le bloc-notes
Apr 16, 2025 pm 07:39 PM
Bien que le bloc-notes ne puisse pas exécuter directement le code Java, il peut être réalisé en utilisant d'autres outils: à l'aide du compilateur de ligne de commande (Javac) pour générer un fichier bytecode (filename.class). Utilisez l'interpréteur Java (Java) pour interpréter ByteCode, exécuter le code et sortir le résultat.
 Comment exécuter Python avec le bloc-notes
Apr 16, 2025 pm 07:33 PM
Comment exécuter Python avec le bloc-notes
Apr 16, 2025 pm 07:33 PM
L'exécution du code Python dans le bloc-notes nécessite l'installation du plug-in exécutable Python et du plug-in NPEXEC. Après avoir installé Python et ajouté un chemin à lui, configurez la commande "python" et le paramètre "{current_directory} {file_name}" dans le plug-in nppexec pour exécuter le code python via la touche de raccourci "F6" dans le bloc-notes.
 Comment vérifier l'adresse de l'entrepôt de Git
Apr 17, 2025 pm 01:54 PM
Comment vérifier l'adresse de l'entrepôt de Git
Apr 17, 2025 pm 01:54 PM
Pour afficher l'adresse du référentiel GIT, effectuez les étapes suivantes: 1. Ouvrez la ligne de commande et accédez au répertoire du référentiel; 2. Exécutez la commande "git Remote -v"; 3. Affichez le nom du référentiel dans la sortie et son adresse correspondante.
 Golang vs Python: différences et similitudes clés
Apr 17, 2025 am 12:15 AM
Golang vs Python: différences et similitudes clés
Apr 17, 2025 am 12:15 AM
Golang et Python ont chacun leurs propres avantages: Golang convient aux performances élevées et à la programmation simultanée, tandis que Python convient à la science des données et au développement Web. Golang est connu pour son modèle de concurrence et ses performances efficaces, tandis que Python est connu pour sa syntaxe concise et son écosystème de bibliothèque riche.
 Python: la puissance de la programmation polyvalente
Apr 17, 2025 am 12:09 AM
Python: la puissance de la programmation polyvalente
Apr 17, 2025 am 12:09 AM
Python est très favorisé pour sa simplicité et son pouvoir, adaptés à tous les besoins des débutants aux développeurs avancés. Sa polyvalence se reflète dans: 1) Facile à apprendre et à utiliser, syntaxe simple; 2) Bibliothèques et cadres riches, tels que Numpy, Pandas, etc.; 3) Support multiplateforme, qui peut être exécuté sur une variété de systèmes d'exploitation; 4) Convient aux tâches de script et d'automatisation pour améliorer l'efficacité du travail.
