

Puissante bibliothèque de dessins Python open source


La raison pour laquelle j'ai déjà utilisé matplotlib est que j'ai appris sa syntaxe complexe et que les centaines d'heures de temps y ont été "coulées". Cela m'a également amené à passer d'innombrables nuits à chercher sur StackOverflow comment « formater les dates » ou « ajouter un deuxième axe Y ».
Mais nous avons maintenant un meilleur choix, comme la bibliothèque de traçage Python open source Plotly, facile à utiliser, bien documentée et puissante. Aujourd'hui, je vais vous faire vivre une expérience approfondie et apprendre comment il peut dessiner de meilleurs graphiques avec un code super simple (même une seule ligne !).
Tout le code de cet article a été open source sur Github et tous les graphiques sont interactifs. Veuillez utiliser le bloc-notes Jupyter pour les afficher.
(Adresse du code source Github : https://github.com/WillKoehrsen/Data-Analysis/blob/master/plotly/Plotly%20Whirlwind%20Introduction.ipynb)
(Exemple de graphique dessiné par plotly. Source de l'image : plot.ly)
Plotly Présentation
Le package Python de plotly est un open base de code source basée sur plot.js, qui est basée sur d3.js. Ce que nous utilisons en réalité est une bibliothèque qui encapsule plotly, appelée boutons de manchette, ce qui vous permet d'utiliser plus facilement les tables de données plotly et Pandas pour travailler ensemble.
*Remarque : Plotly elle-même est une entreprise de technologie de visualisation proposant plusieurs produits différents et des ensembles d'outils open source. La bibliothèque Python de Plotly est gratuite. En mode hors ligne, vous pouvez créer un nombre illimité de graphiques. En mode en ligne, le service de partage de Plotly étant utilisé, vous ne pouvez générer et partager que 25 graphiques.
Toutes les visualisations de cet article ont été réalisées dans Jupyter Notebook à l'aide de la bibliothèque plotly + cufflinks en mode hors ligne. Après avoir terminé l'installation à l'aide de pip install cufflinks plotly, vous pouvez utiliser le code suivant pour terminer l'importation dans Jupyter : : Les histogrammes et les boîtes à moustaches
 Les graphiques d'analyse univariée sont souvent la pratique standard lors du démarrage de l'analyse des données, et les histogrammes sont fondamentalement l'un des graphiques nécessaires pour l'analyse de distribution univariée (bien qu'ils présentent certaines lacunes. ).
Les graphiques d'analyse univariée sont souvent la pratique standard lors du démarrage de l'analyse des données, et les histogrammes sont fondamentalement l'un des graphiques nécessaires pour l'analyse de distribution univariée (bien qu'ils présentent certaines lacunes. ).
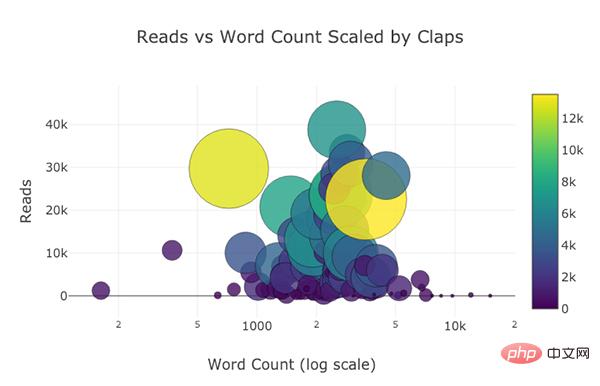
Prenons comme exemple le nombre total de likes sur les articles de blog (voir Github pour les données originales : https://github.com/WillKoehrsen/Data-Analysis/tree/master/medium) et faites un simple histogramme interactif :
(df dans le code est un objet dataframe Pandas standard)# 🎜🎜 # (Histogramme interactif créé à l'aide de plotly + boutons de manchette)
(Histogramme interactif créé à l'aide de plotly + boutons de manchette)
Pour les étudiants déjà habitués à matplotlib, il vous suffit de taper une lettre supplémentaire (remplacer .plot par .iplot). Obtenez des graphiques interactifs plus beaux ! Cliquer sur des éléments de l'image révèle des informations détaillées, effectue un zoom avant et arrière et (nous y reviendrons ensuite) met en évidence des fonctionnalités telles que le filtrage de certaines parties de l'image.
Si vous souhaitez dessiner un histogramme empilé, faites simplement ceci : 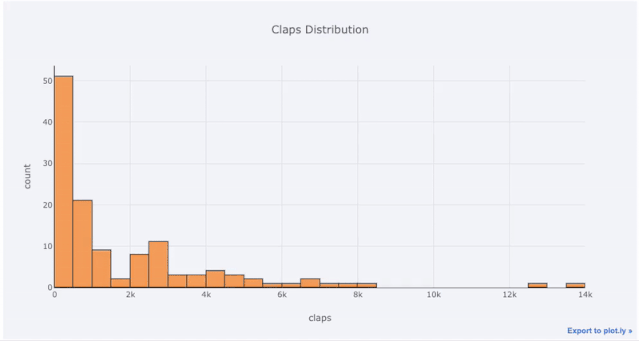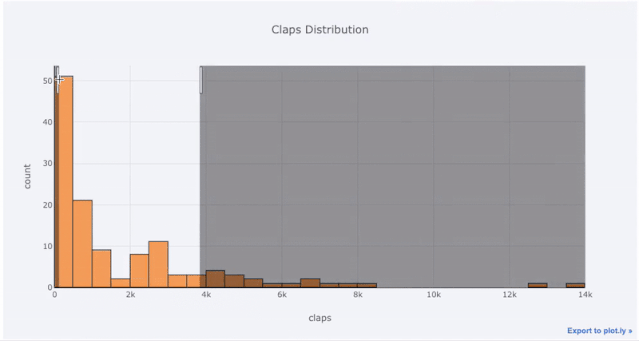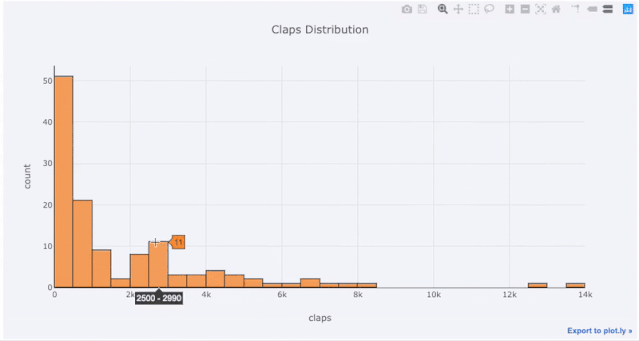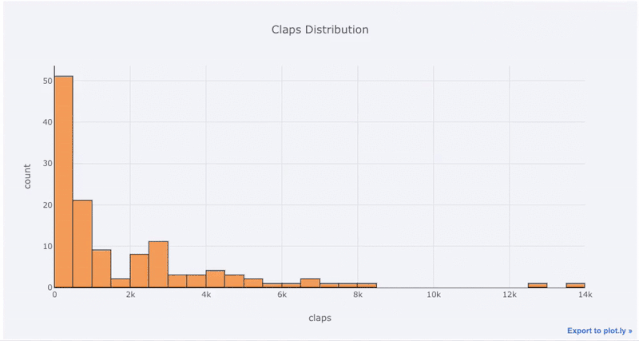
# 🎜🎜# Effectuez un traitement simple sur la table de données pandas et générez un graphique à barres :

Comme indiqué ci-dessus, nous pouvons intégrer les capacités des boutons de manchette plotly + avec les pandas. Par exemple, nous pouvons d'abord utiliser .pivot() pour effectuer une analyse de tableau croisé dynamique, puis générer un graphique à barres.
Par exemple, compter le nombre de nouveaux fans apportés par chaque article dans différents canaux de publication : 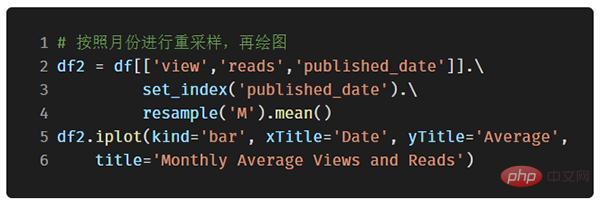
L'avantage des graphiques interactifs est que nous pouvons explorer les données et diviser les sous-éléments pour les analyser à volonté. Les boîtes à moustaches peuvent fournir beaucoup d'informations, mais si vous ne pouvez pas voir les valeurs spécifiques, vous risquez d'en manquer beaucoup !
Nuage de points
Le nuage de points est le contenu principal de la plupart des analyses. Il nous permet de voir l'évolution d'une variable au fil du temps, ou l'évolution de la relation entre deux (ou plusieurs) variables.
Analyse des séries chronologiques
Dans le monde réel, une partie considérable des données comporte des éléments temporels. Heureusement, plotly + cufflinks est livré avec une fonctionnalité intégrée pour prendre en charge l'analyse visuelle des séries chronologiques.
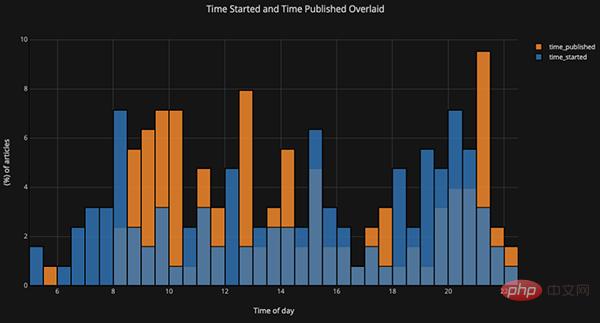
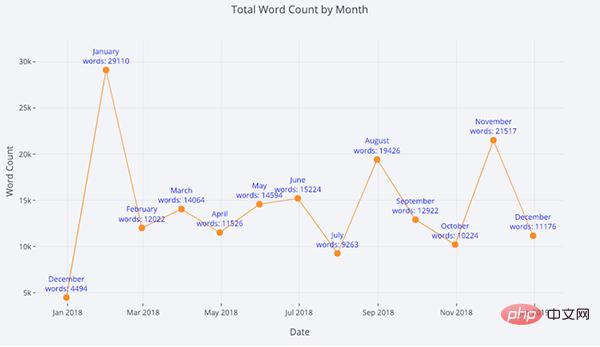
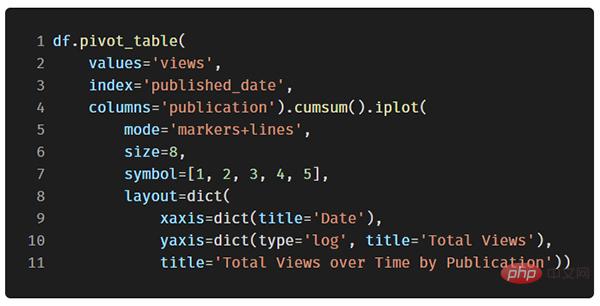
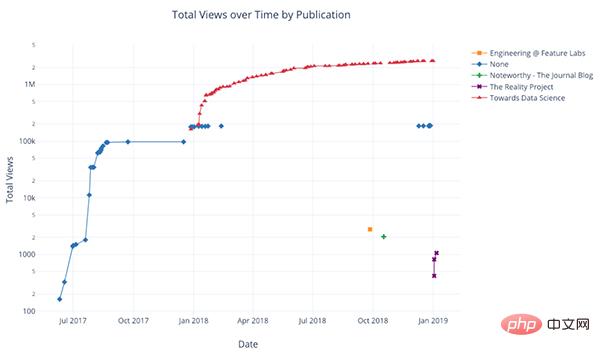
Prenons comme exemple les données de l'article que j'ai publié sur le site "Towards Data Science". Construisons un ensemble de données en utilisant l'heure de publication comme index pour voir comment la popularité de l'article change :
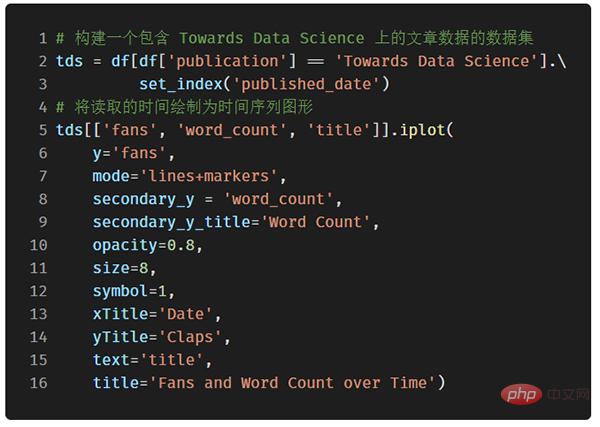
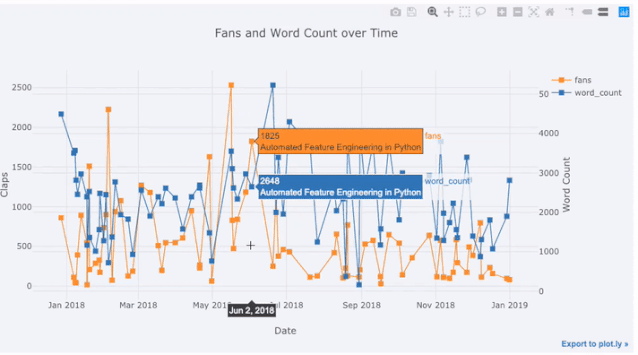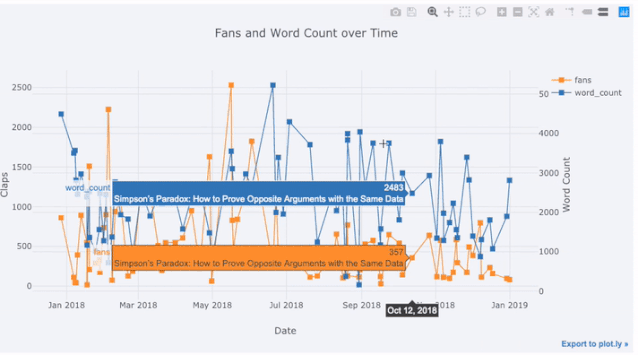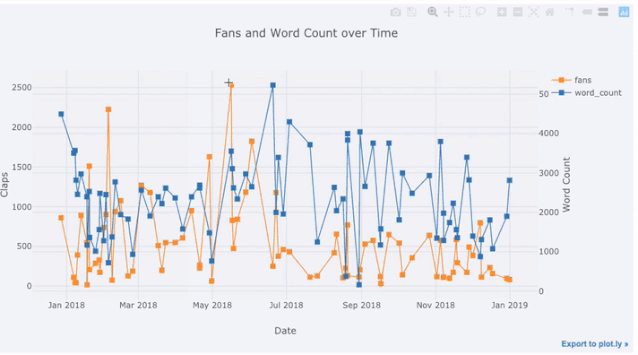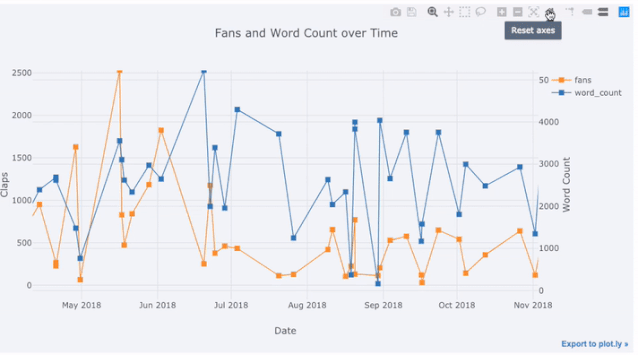
Dans l'image ci-dessus, nous avons accompli plusieurs choses avec une seule ligne de code :
- Générer automatiquement une belle série temporelle Dans les étiquettes affichées lorsque
- Afin d'afficher plus de données, nous pouvons facilement ajouter des annotations de texte :
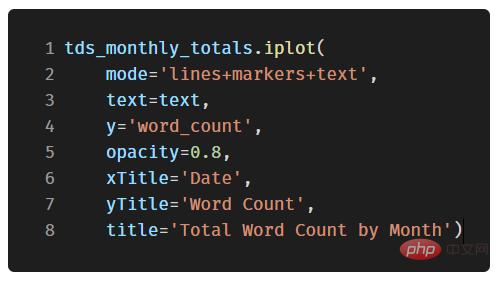
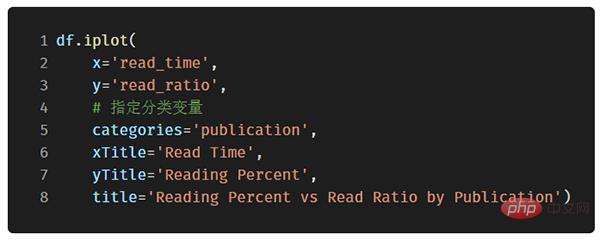
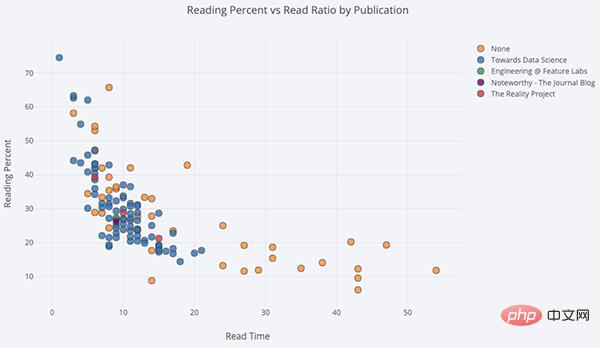
 Dans le code ci-dessous, nous ajouterons un nuage de points bivarié coloré par la troisième variable catégorielle :
Dans le code ci-dessous, nous ajouterons un nuage de points bivarié coloré par la troisième variable catégorielle :
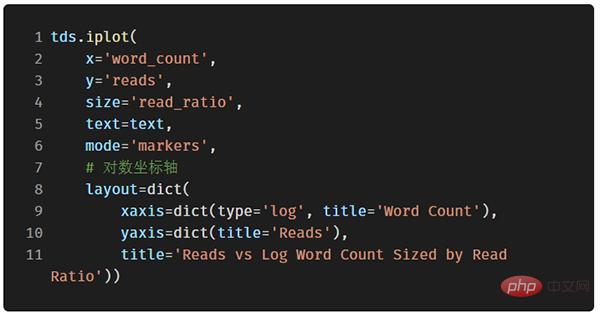
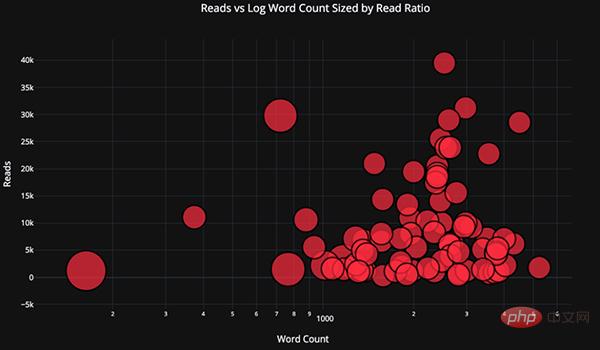
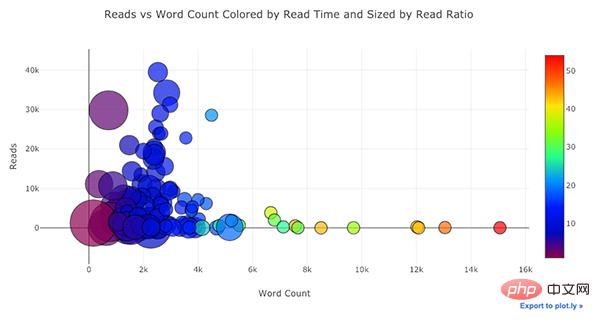
 Fonctions de dessin avancées
Fonctions de dessin avancées
Ensuite, nous présenterons en détail plusieurs graphiques spéciaux. Vous ne les utiliserez peut-être pas très souvent, mais je vous garantis que tant que vous les utilisez bien, ils impressionneront certainement les gens. Nous allons utiliser le module figure_factory de plotly, qui peut générer de superbes graphiques avec une seule ligne de code !
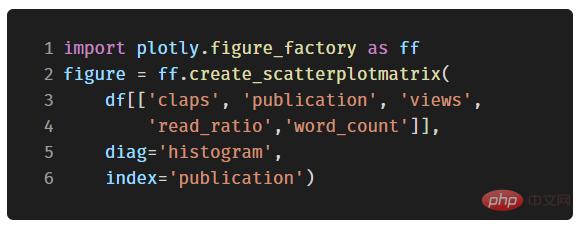
Matrice de nuages de points
Si nous voulons explorer la relation entre de nombreuses variables différentes, la matrice de nuages de points (également connue sous le nom de SPLOM) est un excellent choix :
Carte thermique des relations
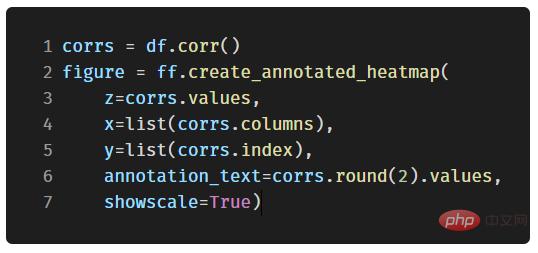
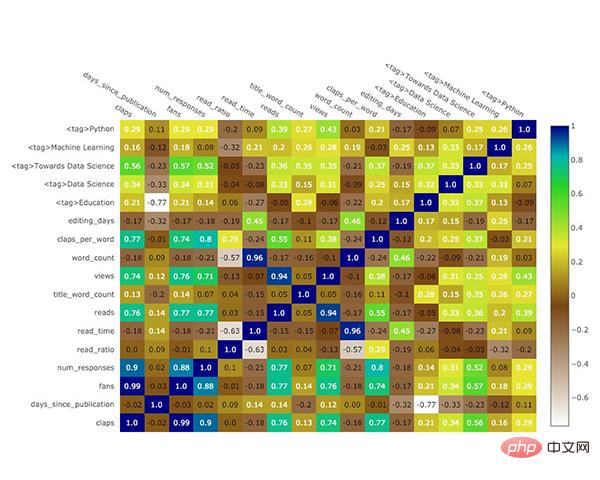
Afin de refléter la relation entre plusieurs variables numériques, nous pouvons calculer leur corrélation puis la visualiser sous forme de carte thermique annotée :
Thèmes personnalisés
En plus d'une infinité En plus des divers graphiques, Cufflinks propose également de nombreux thèmes de coloration différents, ce qui vous permet de basculer facilement entre différents styles de graphiques. Les deux images suivantes sont respectivement le thème "espace" et le thème "ggplot" :
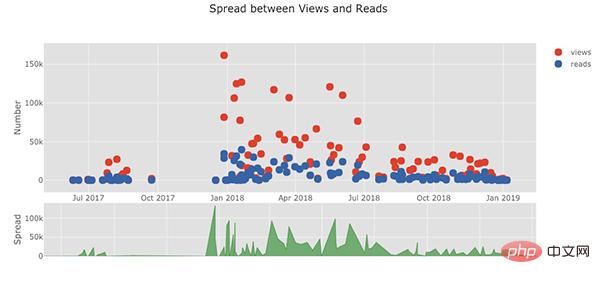
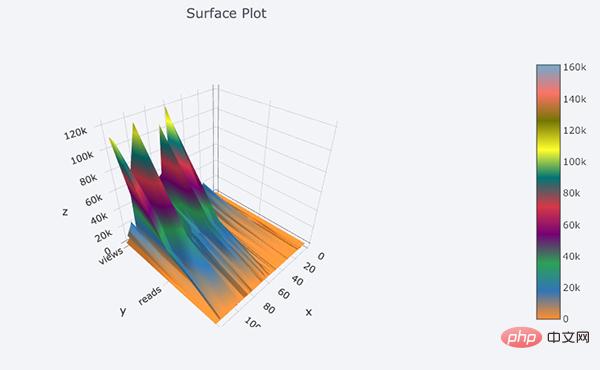
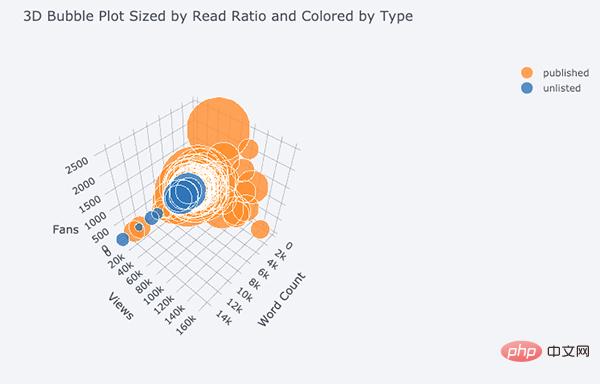
De plus, il y a des graphiques 3D (surface et bulle) :
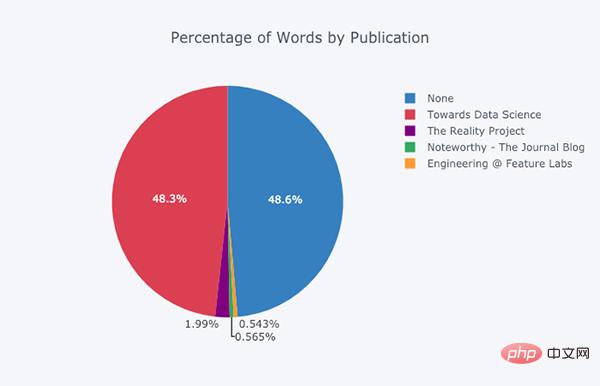
Pour ceux qui sont intéressés par la recherche Pour les utilisateurs, il n'est pas difficile de créer un diagramme circulaire :
Modifier dans Plotly Chart Studio
Après avoir généré ces graphiques dans Jupyter Notebook, vous constaterez que le graphique Un petit lien apparaît dans le coin inférieur droit disant "Exporter vers plot.ly (Publier vers plot.ly)". Si vous cliquez sur ce lien, vous accéderez à un « Atelier graphique » (https://plot.ly/create/).
Ici, vous pouvez réviser et peaufiner davantage votre diagramme avant la présentation finale. Vous pouvez ajouter des annotations, choisir les couleurs de certains éléments, tout organiser et produire un superbe graphique. Plus tard, vous pouvez également le publier sur le Web, générant ainsi un lien que d'autres pourront consulter.
Les deux photos suivantes ont été réalisées lors de l'atelier carte :
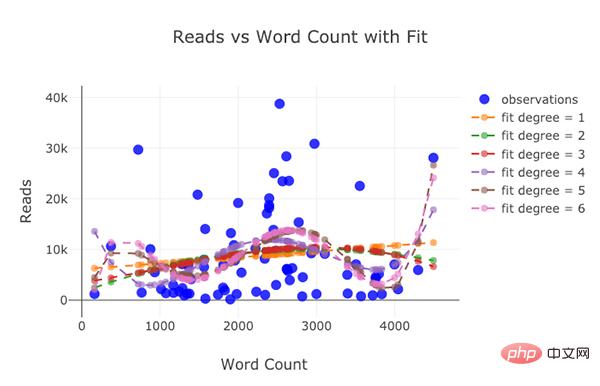
Après avoir tant parlé, es-tu fatigué de la lire ? Cependant, nous n'avons pas épuisé toutes les capacités de cette bibliothèque. En raison du manque de place, il existe de meilleurs graphiques et exemples, veuillez donc consulter les documents officiels de plotly et de boutons de manchette pour les visualiser un par un.
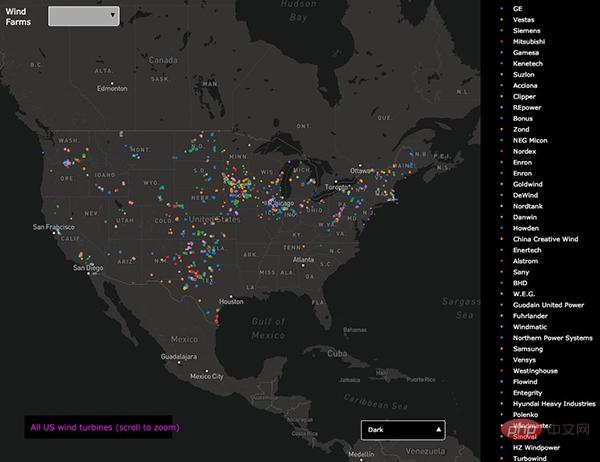
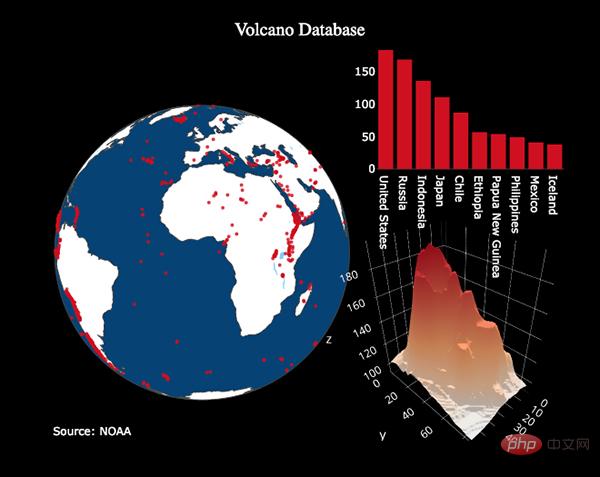
(Carte interactive Plotly montrant les données des parcs éoliens à travers les États-Unis. Source : plot.ly)
Enfin…
La pire chose à propos de l'erreur des coûts irrécupérables est que les gens ne peuvent souvent le faire que lorsque vous abandonnez votre vos efforts précédents vous feront réaliser combien de temps vous avez perdu.
Lors du choix d'une bibliothèque de traçage, les fonctionnalités dont vous avez le plus besoin sont :
Graphiques sur une seule ligne pour explorer rapidement les données
- Éléments interactifs pour diviser/examiner les données
- Si nécessaire Des options qui vous permettent d'explorer des informations détaillées
- Personnalisez facilement avant la présentation finale
Désormais, le meilleur choix pour implémenter les fonctions ci-dessus en Python est plotly. Il nous permet de générer rapidement des diagrammes visuels et des fonctionnalités interactives nous permettent de mieux comprendre les informations.
J'avoue que le traçage est certainement la partie la plus agréable du travail en science des données, et plotly rend l'exécution de ces tâches encore plus agréable.
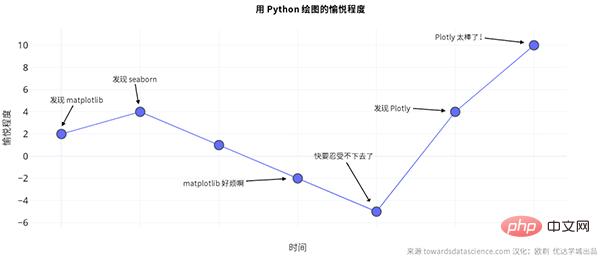
(Un graphique montrant comment la joie de dessiner avec Python a changé au fil du temps. Source versdatascience.com)
En 2022, il est temps de mettre à niveau votre bibliothèque de dessins Python et de vous préparer à la science des données et à la visualisation. Devenez plus rapide, plus fort et plus beau !
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 MySQL doit-il payer
Apr 08, 2025 pm 05:36 PM
MySQL doit-il payer
Apr 08, 2025 pm 05:36 PM
MySQL a une version communautaire gratuite et une version d'entreprise payante. La version communautaire peut être utilisée et modifiée gratuitement, mais le support est limité et convient aux applications avec des exigences de stabilité faibles et des capacités techniques solides. L'Enterprise Edition fournit une prise en charge commerciale complète pour les applications qui nécessitent une base de données stable, fiable et haute performance et disposées à payer pour le soutien. Les facteurs pris en compte lors du choix d'une version comprennent la criticité des applications, la budgétisation et les compétences techniques. Il n'y a pas d'option parfaite, seulement l'option la plus appropriée, et vous devez choisir soigneusement en fonction de la situation spécifique.
 Comment utiliser MySQL après l'installation
Apr 08, 2025 am 11:48 AM
Comment utiliser MySQL après l'installation
Apr 08, 2025 am 11:48 AM
L'article présente le fonctionnement de la base de données MySQL. Tout d'abord, vous devez installer un client MySQL, tel que MySQLWorkBench ou le client de ligne de commande. 1. Utilisez la commande MySQL-UROot-P pour vous connecter au serveur et connecter avec le mot de passe du compte racine; 2. Utilisez Createdatabase pour créer une base de données et utilisez Sélectionner une base de données; 3. Utilisez CreateTable pour créer une table, définissez des champs et des types de données; 4. Utilisez InsertInto pour insérer des données, remettre en question les données, mettre à jour les données par mise à jour et supprimer les données par Supprimer. Ce n'est qu'en maîtrisant ces étapes, en apprenant à faire face à des problèmes courants et à l'optimisation des performances de la base de données que vous pouvez utiliser efficacement MySQL.
 Le fichier de téléchargement MySQL est endommagé et ne peut pas être installé. Réparer la solution
Apr 08, 2025 am 11:21 AM
Le fichier de téléchargement MySQL est endommagé et ne peut pas être installé. Réparer la solution
Apr 08, 2025 am 11:21 AM
Le fichier de téléchargement mysql est corrompu, que dois-je faire? Hélas, si vous téléchargez MySQL, vous pouvez rencontrer la corruption des fichiers. Ce n'est vraiment pas facile ces jours-ci! Cet article expliquera comment résoudre ce problème afin que tout le monde puisse éviter les détours. Après l'avoir lu, vous pouvez non seulement réparer le package d'installation MySQL endommagé, mais aussi avoir une compréhension plus approfondie du processus de téléchargement et d'installation pour éviter de rester coincé à l'avenir. Parlons d'abord de la raison pour laquelle le téléchargement des fichiers est endommagé. Il y a de nombreuses raisons à cela. Les problèmes de réseau sont le coupable. L'interruption du processus de téléchargement et l'instabilité du réseau peut conduire à la corruption des fichiers. Il y a aussi le problème avec la source de téléchargement elle-même. Le fichier serveur lui-même est cassé, et bien sûr, il est également cassé si vous le téléchargez. De plus, la numérisation excessive "passionnée" de certains logiciels antivirus peut également entraîner une corruption des fichiers. Problème de diagnostic: déterminer si le fichier est vraiment corrompu
 MySQL ne peut pas être installé après le téléchargement
Apr 08, 2025 am 11:24 AM
MySQL ne peut pas être installé après le téléchargement
Apr 08, 2025 am 11:24 AM
Les principales raisons de la défaillance de l'installation de MySQL sont les suivantes: 1. Problèmes d'autorisation, vous devez s'exécuter en tant qu'administrateur ou utiliser la commande sudo; 2. Des dépendances sont manquantes et vous devez installer des packages de développement pertinents; 3. Conflits du port, vous devez fermer le programme qui occupe le port 3306 ou modifier le fichier de configuration; 4. Le package d'installation est corrompu, vous devez télécharger et vérifier l'intégrité; 5. La variable d'environnement est mal configurée et les variables d'environnement doivent être correctement configurées en fonction du système d'exploitation. Résolvez ces problèmes et vérifiez soigneusement chaque étape pour installer avec succès MySQL.
 Comment optimiser les performances MySQL pour les applications de haute charge?
Apr 08, 2025 pm 06:03 PM
Comment optimiser les performances MySQL pour les applications de haute charge?
Apr 08, 2025 pm 06:03 PM
Guide d'optimisation des performances de la base de données MySQL dans les applications à forte intensité de ressources, la base de données MySQL joue un rôle crucial et est responsable de la gestion des transactions massives. Cependant, à mesure que l'échelle de l'application se développe, les goulots d'étranglement des performances de la base de données deviennent souvent une contrainte. Cet article explorera une série de stratégies efficaces d'optimisation des performances MySQL pour garantir que votre application reste efficace et réactive dans des charges élevées. Nous combinerons des cas réels pour expliquer les technologies clés approfondies telles que l'indexation, l'optimisation des requêtes, la conception de la base de données et la mise en cache. 1. La conception de l'architecture de la base de données et l'architecture optimisée de la base de données sont la pierre angulaire de l'optimisation des performances MySQL. Voici quelques principes de base: sélectionner le bon type de données et sélectionner le plus petit type de données qui répond aux besoins peut non seulement économiser un espace de stockage, mais également améliorer la vitesse de traitement des données.
 Solutions au service qui ne peuvent pas être démarrées après l'installation de MySQL
Apr 08, 2025 am 11:18 AM
Solutions au service qui ne peuvent pas être démarrées après l'installation de MySQL
Apr 08, 2025 am 11:18 AM
MySQL a refusé de commencer? Ne paniquez pas, vérifions-le! De nombreux amis ont découvert que le service ne pouvait pas être démarré après avoir installé MySQL, et ils étaient si anxieux! Ne vous inquiétez pas, cet article vous emmènera pour le faire face calmement et découvrez le cerveau derrière! Après l'avoir lu, vous pouvez non seulement résoudre ce problème, mais aussi améliorer votre compréhension des services MySQL et vos idées de problèmes de dépannage, et devenir un administrateur de base de données plus puissant! Le service MySQL n'a pas réussi et il y a de nombreuses raisons, allant des erreurs de configuration simples aux problèmes système complexes. Commençons par les aspects les plus courants. Connaissances de base: une brève description du processus de démarrage du service MySQL Service Startup. Autrement dit, le système d'exploitation charge les fichiers liés à MySQL, puis démarre le démon mysql. Cela implique la configuration
 Comment optimiser les performances de la base de données après l'installation de MySQL
Apr 08, 2025 am 11:36 AM
Comment optimiser les performances de la base de données après l'installation de MySQL
Apr 08, 2025 am 11:36 AM
L'optimisation des performances MySQL doit commencer à partir de trois aspects: configuration d'installation, indexation et optimisation des requêtes, surveillance et réglage. 1. Après l'installation, vous devez ajuster le fichier my.cnf en fonction de la configuration du serveur, tel que le paramètre innodb_buffer_pool_size, et fermer query_cache_size; 2. Créez un index approprié pour éviter les index excessifs et optimiser les instructions de requête, telles que l'utilisation de la commande Explication pour analyser le plan d'exécution; 3. Utilisez le propre outil de surveillance de MySQL (ShowProcessList, Showstatus) pour surveiller la santé de la base de données, et sauvegarde régulièrement et organisez la base de données. Ce n'est qu'en optimisant en continu ces étapes que les performances de la base de données MySQL peuvent être améliorées.
 MySQL a-t-il besoin d'Internet
Apr 08, 2025 pm 02:18 PM
MySQL a-t-il besoin d'Internet
Apr 08, 2025 pm 02:18 PM
MySQL peut s'exécuter sans connexions réseau pour le stockage et la gestion des données de base. Cependant, la connexion réseau est requise pour l'interaction avec d'autres systèmes, l'accès à distance ou l'utilisation de fonctionnalités avancées telles que la réplication et le clustering. De plus, les mesures de sécurité (telles que les pare-feu), l'optimisation des performances (choisissez la bonne connexion réseau) et la sauvegarde des données sont essentielles pour se connecter à Internet.
