

Aujourd'hui, le cercle de l'IA a été choqué par un "renversement" choquant.
Le diagramme dans "Attention Is All Your Need", le travail de base de la PNL de Google Brain et à l'origine de l'architecture Transformer, a été retiré par les internautes et fusionné avec le code .Incohérent.

Adresse papier : https://arxiv.org /abs/1706.03762
Depuis son lancement en 2017, Transformer est devenu la pierre angulaire du domaine de l'IA. Même le véritable cerveau derrière le populaire ChatGPT, c'est lui.
En 2019, Google a également déposé un brevet spécifiquement pour celui-ci.

remonte à l'origine, et maintenant divers GPT (Generative Pre- Transformateur formé), tous proviennent de ce journal vieux de 17 ans.
Selon Google Scholar, jusqu'à présent, cet ouvrage fondateur a été cité plus de 70 000 fois.

Donc, la première pierre de ChatGPT n'est pas stable ?
Sebastian Raschka, fondateur de Lightning AI et chercheur en apprentissage automatique, a découvert que le diagramme du transformateur dans cet article est erroné.
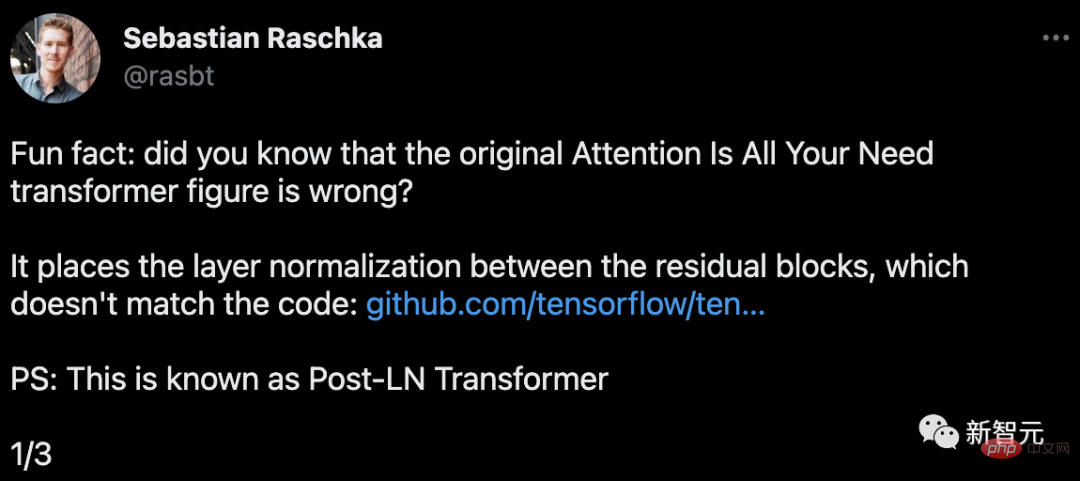
L'endroit encerclé dans l'image, LayerNorms est après l'attention et le calque entièrement connecté. Placer la normalisation des couches entre les blocs résiduels entraîne des gradients attendus importants pour les paramètres proches de la couche de sortie.
De plus, cela n'est pas cohérent avec le code.
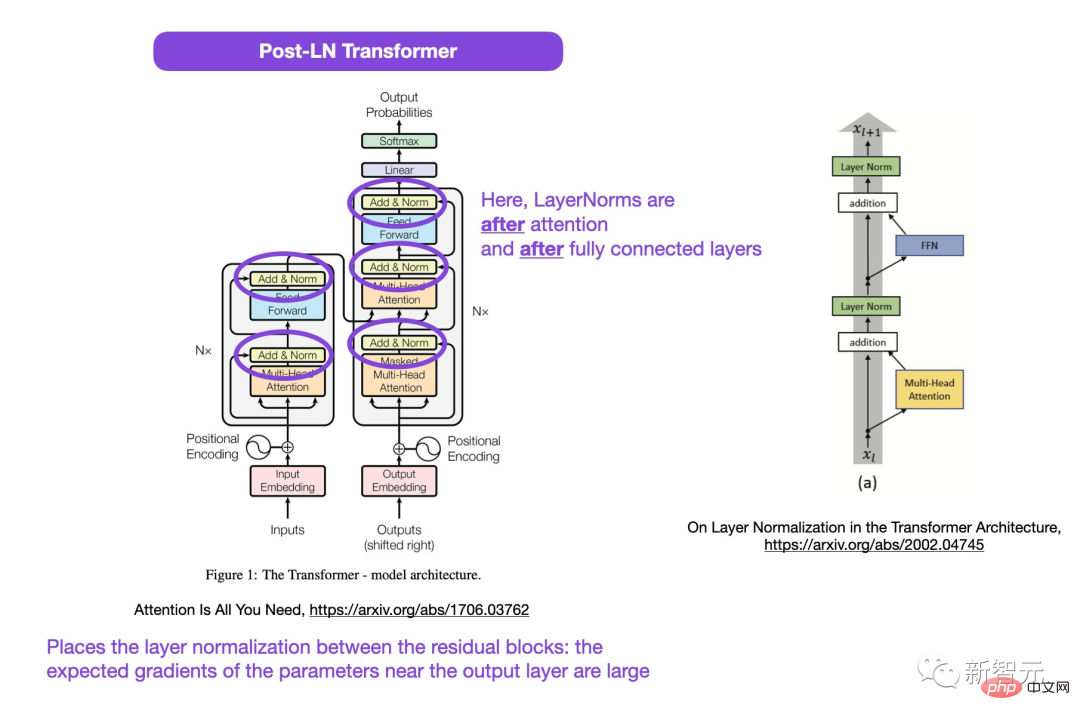
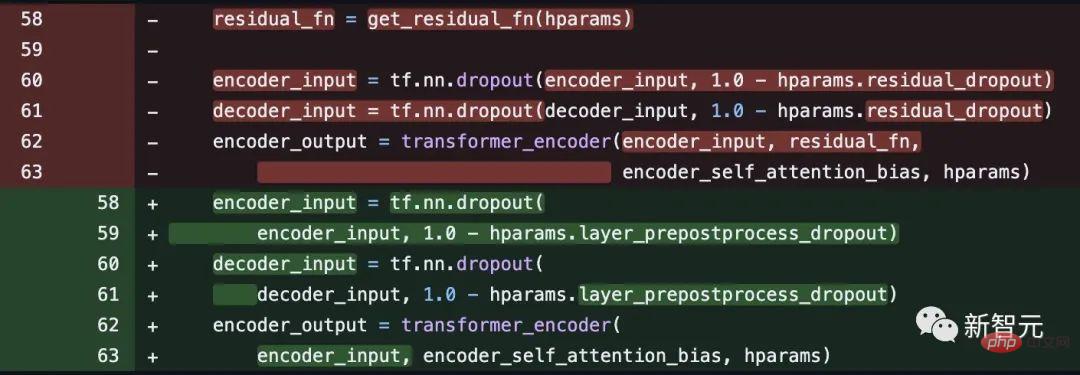
Adresse du code : https://github.com/tensorflow/tensor2tensor/commit/f5c9b17e617ea9179b7d84d36b1e8162cb369f25#diff-76e2b94ef16871bdbf46bf04dfe7f147 b884748f08197c9cf1b10a4dd78e
# 🎜 🎜# Cependant, certains internautes ont souligné que Noam Shazeer avait corrigé le code quelques semaines plus tard.
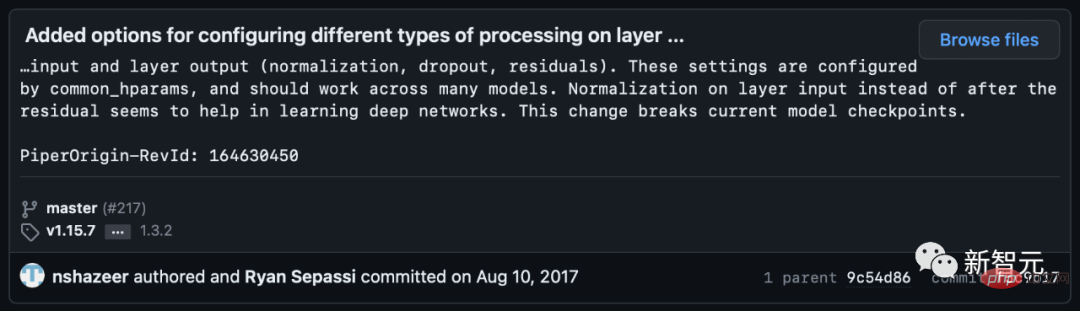

Si la normalisation des calques est placée dans la connexion résiduelle avant l'attention et les calques entièrement connectés, de meilleurs dégradés seront obtenus.
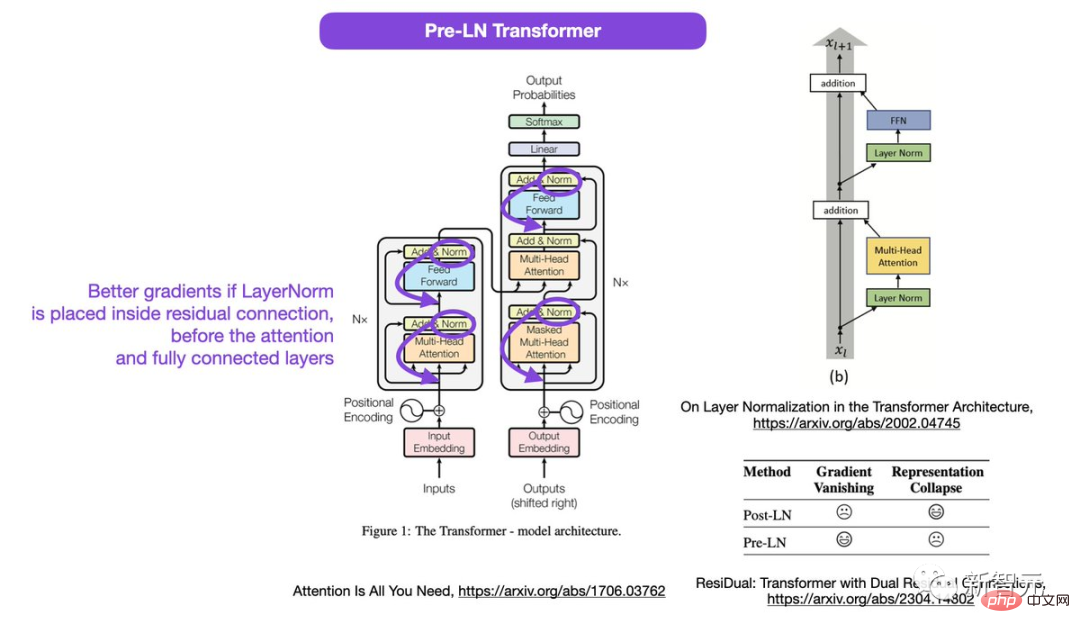
Sebastian a proposé que même si la discussion sur l'utilisation du Post-LN ou du Pre-LN est toujours en cours, il existe également un nouveau document proposant de combiner les deux.

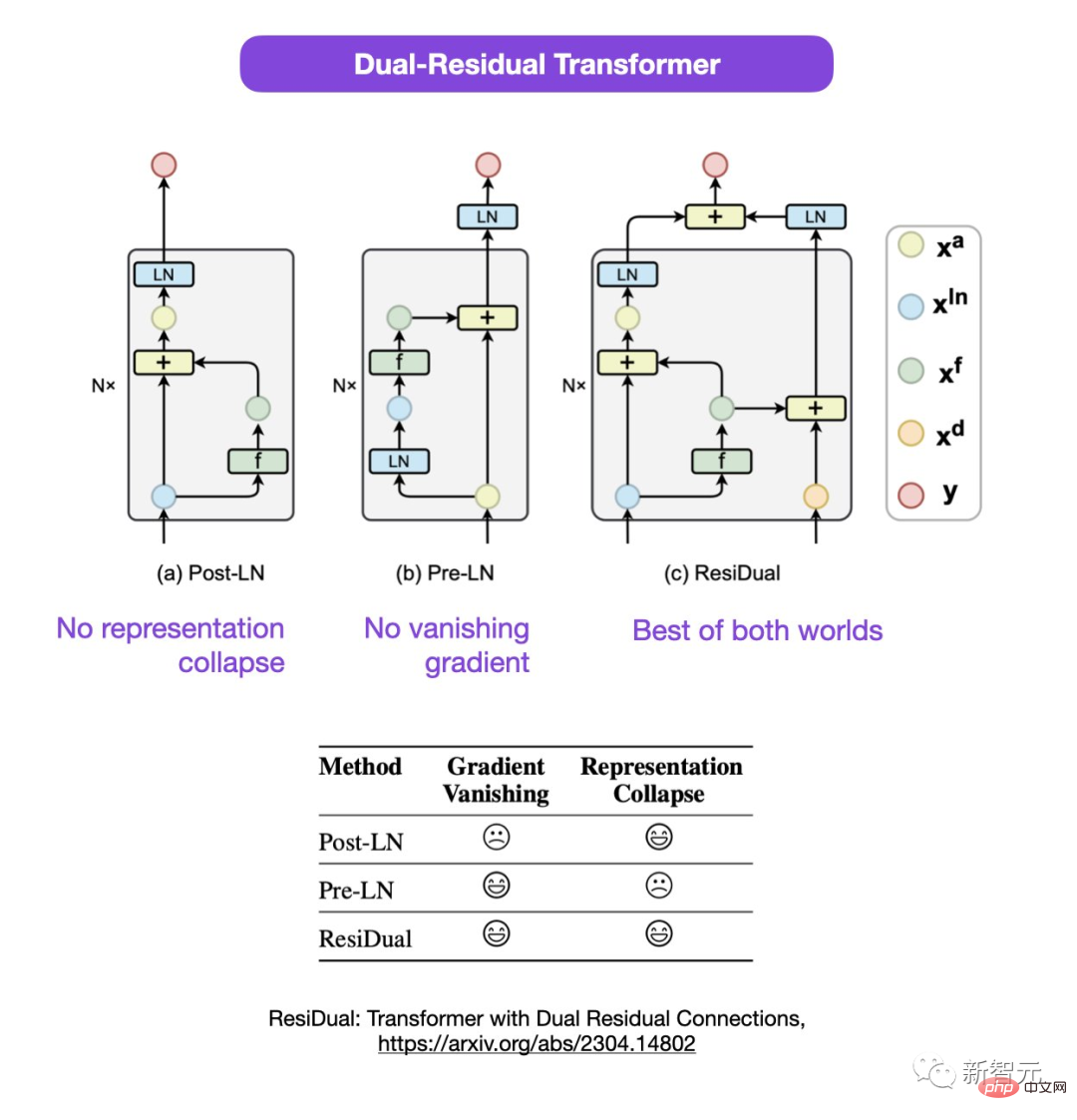
Adresse papier : https://arxiv.org/abs/2304.14802
Dans ce double Transformer résiduel, les problèmes d'effondrement de la représentation et de disparition du gradient sont résolus.
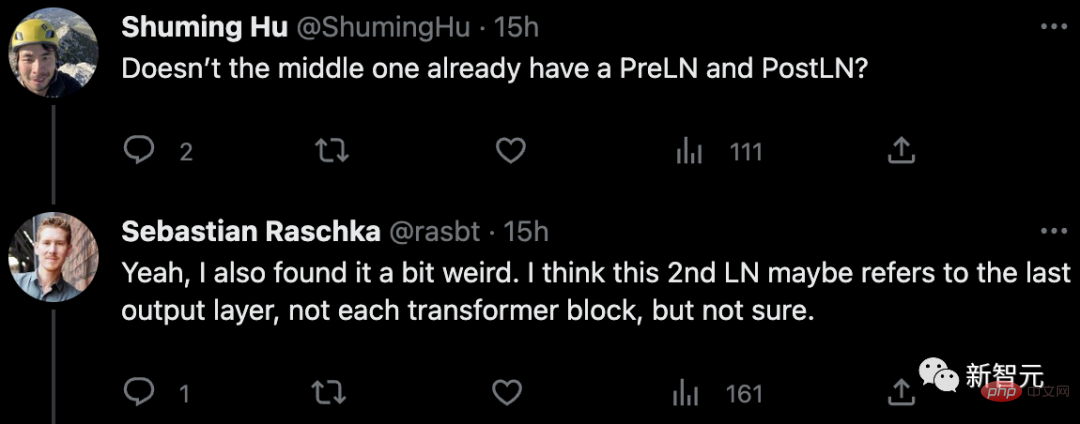
En réponse à le journal Concernant les doutes, certains internautes ont souligné : n'y a-t-il pas déjà PreLN et PostLN au milieu ?
Sebastian a répondu qu'il se sentait un peu étrange aussi. Peut-être que le 2ème LN fait référence à la dernière couche de sortie plutôt qu'à chaque bloc de transformateur, mais il n'en est pas sûr non plus.
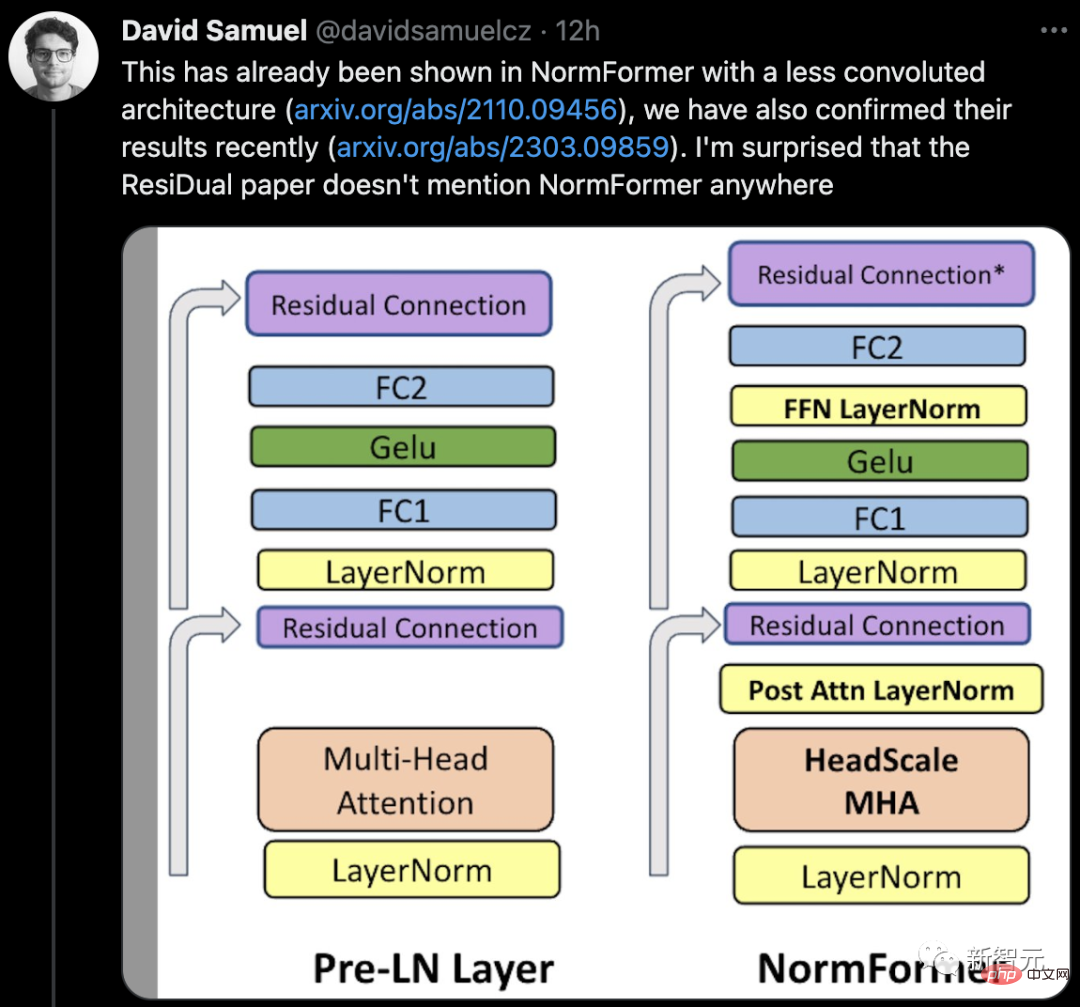
Certains internautes ont déclaré : « Nous rencontrons souvent des incohérences avec le code ou les résultats. Les documents correspondants sont pour la plupart des erreurs, mais il est parfois étrange que ce document circule depuis longtemps. C'est vraiment étrange que ce genre de question n'ait jamais été soulevé auparavant. #



# 🎜 🎜# Alors, y a-t-il vraiment une faille dans le journal, ou est-ce un propre incident ?
Alors, y a-t-il vraiment une faille dans le journal, ou est-ce un propre incident ?
Attendons de voir ce qui se passera ensuite.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Introduction à l'utilisation du code complet VBS
Introduction à l'utilisation du code complet VBS
 utilisation de la fonction stripslashes
utilisation de la fonction stripslashes
 Port 1433
Port 1433
 Comment résoudre l'erreur du ventilateur du processeur
Comment résoudre l'erreur du ventilateur du processeur
 Comment changer la couleur du pinceau PS
Comment changer la couleur du pinceau PS
 système de gestion de base de données
système de gestion de base de données
 Comment ouvrir les fichiers ESP
Comment ouvrir les fichiers ESP
 À quelle marque appartient le téléphone mobile OnePlus ?
À quelle marque appartient le téléphone mobile OnePlus ?








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



