
 développement back-end
Tutoriel Python
Comment implémenter des expressions régulières en Python
développement back-end
Tutoriel Python
Comment implémenter des expressions régulières en Python
Comment implémenter des expressions régulières en Python

Expression régulière Python
L'expression régulière elle-même est une connaissance indépendante du langage de programmation, mais elle dépend également du langage de programmation. Fondamentalement, le langage de programmation que nous utilisons assure sa mise en œuvre. Bien sûr, chaque entreprise présente également quelques différences. mise en œuvre, certains prennent en charge plus de fonctions et d’autres moins.
Étant donné que les expressions régulières sont un outil largement utilisé dans la pratique, je pense qu'il n'est pas fiable de les apprendre sans langage.
Introduction aux fonctions d'expression régulière
Diagramme de relation entre l'API principale et l'expression régulière
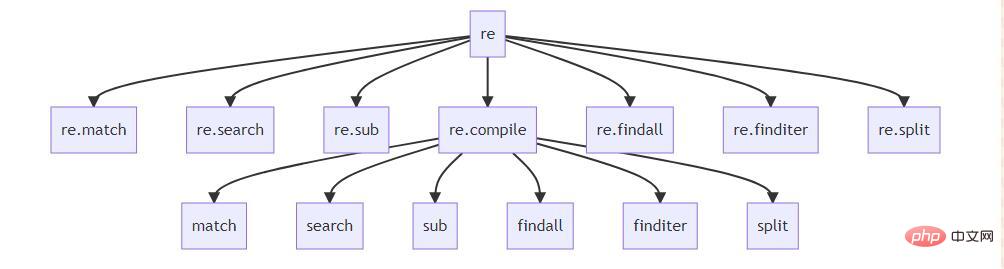
Ce diagramme est mon résumé personnel. Je pense avoir fondamentalement clarifié la relation entre les fonctions ici. Leurs fonctions sont :
. match correspond à l'expression régulière du début du texte et renvoie l'objet correspondant. Sinon, il renvoie None
search Correspond à l'expression régulière dans tout le texte et renvoie le premier objet correspondant. Sinon, il renvoie None .
sub utilise des expressions régulières pour le remplacement de texte (fonction des expressions régulières : rechercher et remplacer)
findall correspond aux expressions régulières du texte entier et renvoie tous les résultats correspondants sous la forme d'une liste.
finditer correspond à une expression régulière du texte entier, renvoyant tous les résultats correspondants en tant qu'itérateur.
split utilise des expressions régulières pour diviser le texte
Comme vous pouvez le voir ici, de nombreuses fonctions peuvent être utilisées immédiatement sous ·re·, et il existe de nombreuses fonctions portant le même nom sous re Fonction .compile. Directement sous le module ·re· se trouvent officiellement des fonctions pour une utilisation facile, et la manière la plus orthodoxe de les utiliser est d'utiliser re.compile. re.compile 下面有很多同名的函数。直接在 ·re· 模块下的是官方提供方便使用的函数,通过 re.compile 来使用是最正统的方式。所以,接下来的内容,我基本上智慧使用 re.compile 及其下的方法来实现。
re.compile 函数
compile 函数用于编译正则表达式,生成一个正则表达式 (Pattern)对象,供 match() 和 search() 以及其它函数使用。
语法:
re.compile(pattern[, flags])
pattern: 一个字符串形式的正则表达式
flags 可选,表示匹配模式,比如忽略大小写,多行模式等,具体参数为:
re.I 忽略大小写
re.L 多行模式
re.S 即为 '.' 并且包括换行符在内的任意字符('.' 不包括换行符)
re.U 表示特殊字符集 w, W, b, B, d, D, s, S 依赖 Unicode 字符属性数据库
re.X 为了增加可读性,忽略空格和 ‘#’ 后面的注释
示例:查找字符串中的所有数字
import re s = 'runoob 123 google 456' result1 = re.findall(r'\d+', s) pattern = re.compile(r'\d+') # 查找数字 result2 = pattern.findall(s) result3 = pattern.findall(s, 0, 20) print(result1) print(result2) print(result3) """ output: [‘123', ‘456'] [‘123', ‘456'] [‘123', ‘45'] """
学习模板
接下来我们要逐渐学习正则表达的内容,这些内容是非常有趣的!Interesting and Excited!
这里给出一个接下来会一直使用的示例模板,这个模板是这篇博客最重要的东西了,之后的内容都会基于它进行扩展。所以,请好好理解它。
import re
# 需要进行搜索或者匹配的文本
text = """I love you yesterday and today."""
# 正则表达式
regexp = r'love'
# 编译(对正则表达式进行编译获取 Pattern Object)
pattern = re.compile(regexp)
# 搜索
m = pattern.search(text)
if m:
print("匹配对象: ", m)
print("匹配的字符串: ", m.group())
print("匹配的开始位置: ", m.start())
print("匹配的结束位置: ", m.end())
print("匹配位置的元组: ", m.span())
else:
print("No match!")
# 替换
new_text = pattern.sub("hate", text)
print(new_text)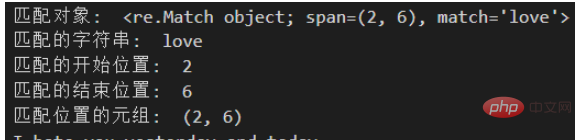
注意: 正则表达式 regexp 在开始前会使用 rDonc, pour le contenu suivant, j'utilise essentiellement re.compile et les méthodes ci-dessous pour y parvenir.
compile est utilisée pour compiler des expressions régulières et générer un objet d'expression régulière (Pattern) pour match() et search( ) et d'autres fonctions. | pattern : une expression régulière sous la forme d'une chaîne | |
| re.I Ignorer la casse | |
| re.L Mode multiligne | |
| re.U représente le jeu de caractères spéciaux w, W, b, B, d, D, s, S et s'appuie sur la base de données d'attributs de caractères Unicode | |
| re.X pour augmenter la lisibilité, ignorer les espaces et commentaires après ‘#’ |
🎜🎜🎜Attention :🎜 L'expression régulière utilisera le préfixe r avant de démarrer. Le but est d'éviter d'utiliser un grand nombre de caractères d'échappement dans l'expression régulière, ce qui détruit la lisibilité globale. 🎜🎜Les expressions régulières de Python incluent de nombreuses méthodes très faciles à utiliser, mais je ne les présenterai pas trop ici. Nous utiliserons toujours le modèle ci-dessus, car ces méthodes faciles à utiliser n’en sont qu’une sorte d’encapsulation, et apprendre à utiliser cette méthode de base en mènera naturellement à d’autres. 🎜🎜L'objet correspondant peut obtenir des informations sur les expressions régulières. Ses méthodes et propriétés les plus importantes sont : 🎜🎜🎜🎜🎜Méthodes/Propriétés 🎜🎜Objectif🎜🎜🎜🎜🎜🎜group()🎜🎜Renvoyer la chaîne correspondante régulière 🎜🎜🎜 🎜start()🎜🎜Renvoie la position de départ du match🎜🎜🎜🎜end()🎜🎜Renvoie la position de fin du match🎜🎜🎜🎜span()🎜🎜Renvoie un tuple contenant la position correspondante (début, fin) 🎜 🎜🎜🎜Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)
Sujets chauds
 1359
1359
 52
52

 Quelle est la fonction de la somme du langage C?
Apr 03, 2025 pm 02:21 PM
Quelle est la fonction de la somme du langage C?
Apr 03, 2025 pm 02:21 PM
Il n'y a pas de fonction de somme intégrée dans le langage C, il doit donc être écrit par vous-même. La somme peut être obtenue en traversant le tableau et en accumulant des éléments: Version de boucle: la somme est calculée à l'aide de la longueur de boucle et du tableau. Version du pointeur: Utilisez des pointeurs pour pointer des éléments de tableau, et un résumé efficace est réalisé grâce à des pointeurs d'auto-incitation. Allouer dynamiquement la version du tableau: allouer dynamiquement les tableaux et gérer la mémoire vous-même, en veillant à ce que la mémoire allouée soit libérée pour empêcher les fuites de mémoire.
 Est-ce que distincte est lié?
Apr 03, 2025 pm 10:30 PM
Est-ce que distincte est lié?
Apr 03, 2025 pm 10:30 PM
Bien que distincts et distincts soient liés à la distinction, ils sont utilisés différemment: distinct (adjectif) décrit le caractère unique des choses elles-mêmes et est utilisée pour souligner les différences entre les choses; Distinct (verbe) représente le comportement ou la capacité de distinction, et est utilisé pour décrire le processus de discrimination. En programmation, distinct est souvent utilisé pour représenter l'unicité des éléments d'une collection, tels que les opérations de déduplication; Distinct se reflète dans la conception d'algorithmes ou de fonctions, tels que la distinction étrange et uniforme des nombres. Lors de l'optimisation, l'opération distincte doit sélectionner l'algorithme et la structure de données appropriés, tandis que l'opération distincte doit optimiser la distinction entre l'efficacité logique et faire attention à l'écriture de code clair et lisible.
 Qui est payé plus de python ou de javascript?
Apr 04, 2025 am 12:09 AM
Qui est payé plus de python ou de javascript?
Apr 04, 2025 am 12:09 AM
Il n'y a pas de salaire absolu pour les développeurs Python et JavaScript, selon les compétences et les besoins de l'industrie. 1. Python peut être davantage payé en science des données et en apprentissage automatique. 2. JavaScript a une grande demande dans le développement frontal et complet, et son salaire est également considérable. 3. Les facteurs d'influence comprennent l'expérience, la localisation géographique, la taille de l'entreprise et les compétences spécifiques.
 Comment comprendre! X en C?
Apr 03, 2025 pm 02:33 PM
Comment comprendre! X en C?
Apr 03, 2025 pm 02:33 PM
! x Compréhension! X est un non-opérateur logique dans le langage C. Il booléen la valeur de x, c'est-à-dire que les véritables modifications sont fausses et fausses modifient true. Mais sachez que la vérité et le mensonge en C sont représentés par des valeurs numériques plutôt que par les types booléens, le non-zéro est considéré comme vrai, et seul 0 est considéré comme faux. Par conséquent,! X traite des nombres négatifs de la même manière que des nombres positifs et est considéré comme vrai.
 Que signifie la somme dans la langue C?
Apr 03, 2025 pm 02:36 PM
Que signifie la somme dans la langue C?
Apr 03, 2025 pm 02:36 PM
Il n'y a pas de fonction de somme intégrée en C pour la somme, mais il peut être implémenté par: en utilisant une boucle pour accumuler des éléments un par un; Utilisation d'un pointeur pour accéder et accumuler des éléments un par un; Pour les volumes de données importants, envisagez des calculs parallèles.
 La production de pages H5 nécessite-t-elle une maintenance continue?
Apr 05, 2025 pm 11:27 PM
La production de pages H5 nécessite-t-elle une maintenance continue?
Apr 05, 2025 pm 11:27 PM
La page H5 doit être maintenue en continu, en raison de facteurs tels que les vulnérabilités du code, la compatibilité des navigateurs, l'optimisation des performances, les mises à jour de sécurité et les améliorations de l'expérience utilisateur. Des méthodes de maintenance efficaces comprennent l'établissement d'un système de test complet, à l'aide d'outils de contrôle de version, de surveiller régulièrement les performances de la page, de collecter les commentaires des utilisateurs et de formuler des plans de maintenance.
 Copier et coller le code d'amour Copier et coller le code d'amour gratuitement
Apr 04, 2025 am 06:48 AM
Copier et coller le code d'amour Copier et coller le code d'amour gratuitement
Apr 04, 2025 am 06:48 AM
Copier et coller le code n'est pas impossible, mais il doit être traité avec prudence. Des dépendances telles que l'environnement, les bibliothèques, les versions, etc. dans le code peuvent ne pas correspondre au projet actuel, entraînant des erreurs ou des résultats imprévisibles. Assurez-vous de vous assurer que le contexte est cohérent, y compris les chemins de fichier, les bibliothèques dépendantes et les versions Python. De plus, lors de la copie et de la collation du code pour une bibliothèque spécifique, vous devrez peut-être installer la bibliothèque et ses dépendances. Les erreurs courantes incluent les erreurs de chemin, les conflits de version et les styles de code incohérents. L'optimisation des performances doit être redessinée ou refactorisée en fonction de l'objectif d'origine et des contraintes du code. Il est crucial de comprendre et de déboguer le code copié, et de ne pas copier et coller aveuglément.
 Comment obtenir des données d'application et de visionneuse en temps réel sur la page de travail 58.com?
Apr 05, 2025 am 08:06 AM
Comment obtenir des données d'application et de visionneuse en temps réel sur la page de travail 58.com?
Apr 05, 2025 am 08:06 AM
Comment obtenir des données dynamiques de la page de travail 58.com tout en rampant? Lorsque vous rampez une page de travail de 58.com en utilisant des outils de chenilles, vous pouvez rencontrer cela ...
