
 Java
javaDidacticiel
Comment résoudre l'erreur 502 lors de la mise à niveau de l'application du projet Springboot du service K8s
Java
javaDidacticiel
Comment résoudre l'erreur 502 lors de la mise à niveau de l'application du projet Springboot du service K8s
Comment résoudre l'erreur 502 lors de la mise à niveau de l'application du projet Springboot du service K8s

À mesure que le modèle de développement par petites étapes et itérations rapides est reconnu et adopté par de plus en plus de sociétés Internet, la fréquence des modifications et des mises à niveau des applications devient de plus en plus fréquente. Afin de répondre aux différents besoins de mise à niveau et de garantir le bon déroulement du processus de mise à niveau, une série de modèles de déploiement et de publication ont vu le jour.
Arrêter la version - arrêtez complètement l'ancienne version de l'instance d'application, puis publiez la nouvelle version. Ce modèle de version vise principalement à résoudre le problème d'incompatibilité et de coexistence entre les anciennes et les nouvelles versions. L'inconvénient est que le service est totalement indisponible pendant un certain temps.
Version bleu-vert - Déployez le même nombre d'instances d'application nouvelles et anciennes versions en ligne en même temps. Une fois que la nouvelle version a réussi le test, le trafic sera immédiatement basculé vers la nouvelle instance de service. Ce modèle de publication résout le problème de l'indisponibilité totale du service lors des temps d'arrêt de la publication, mais il entraînera une consommation de ressources relativement importante.
Rolling Release - Remplacez progressivement les instances d'application par lots. Ce mode de publication n'interrompra pas les services et ne consommera pas trop de ressources supplémentaires. Cependant, étant donné que les instances de l'ancienne et de la nouvelle version sont en ligne en même temps, cela peut entraîner des requêtes du même client pour basculer entre l'ancienne et la nouvelle version, ce qui entraînera une interruption des services. problèmes de compatibilité.
Canary Release - Basculez progressivement le trafic de l'ancienne version vers la nouvelle version. Si aucun problème n'est détecté après un certain temps d'observation, le trafic de la nouvelle version sera encore augmenté tandis que le trafic de l'ancienne version sera réduit.
Tests A/B - lancez deux versions ou plus en même temps, collectez les commentaires des utilisateurs sur ces versions, analysez et évaluez la meilleure version pour une adoption officielle.
Mise à niveau de l'application K8s
Dans k8s, le pod est l'unité de base du déploiement et de la mise à niveau. De manière générale, un pod représente une instance d'application, et le pod sera déployé et exécuté sous la forme de déploiement, StatefulSet, DaemonSet, Job, etc. Ce qui suit décrit les méthodes de mise à niveau des pods dans ces formulaires de déploiement.
Déploiement
Le déploiement est la forme de déploiement de pod la plus courante. Ici, nous prendrons comme exemple une application Java basée sur Spring Boot. Cette application est une version simple abstraite basée sur une application réelle. Elle est très représentative. Elle présente les caractéristiques suivantes :
Après le démarrage de l'application, il faut un certain temps pour charger la configuration. les services ne peuvent pas être fournis au monde extérieur.
Ce n'est pas parce que l'application peut être démarrée qu'elle peut fournir des services normalement.
L'application peut ne pas se fermer automatiquement si elle ne peut pas fournir de services.
Pendant le processus de mise à niveau, il est nécessaire de s'assurer que l'instance d'application qui est sur le point de se déconnecter ne recevra pas de nouvelles demandes et disposera de suffisamment de temps pour traiter la demande en cours.
Configuration des paramètres
Pour que les applications présentant les caractéristiques ci-dessus n'atteignent aucun temps d'arrêt et aucune mise à niveau d'interruption de production, les paramètres pertinents dans le déploiement doivent être soigneusement configurés. La configuration liée à la mise à niveau ici est la suivante (voir spring-boot-probes-v1.yaml pour la configuration complète).
kind: Deployment
...
spec:
replicas: 8
strategy:
type: RollingUpdate
rollingUpdate:
maxSurge: 3
maxUnavailable: 2
minReadySeconds: 120
...
template:
...
spec:
containers:
- name: spring-boot-probes
image: registry.cn-hangzhou.aliyuncs.com/log-service/spring-boot-probes:1.0.0
ports:
- containerPort: 8080
terminationGracePeriodSeconds: 60
readinessProbe:
httpGet:
path: /actuator/health
port: 8080
initialDelaySeconds: 30
periodSeconds: 10
successThreshold: 1
failureThreshold: 1
livenessProbe:
httpGet:
path: /actuator/health
port: 8080
initialDelaySeconds: 40
periodSeconds: 20
successThreshold: 1
failureThreshold: 3
...Configurer la stratégie
Vous pouvez configurer la stratégie de remplacement du pod via la stratégie. Les principaux paramètres sont les suivants.
.spec.strategy.type- utilisé pour spécifier le type de stratégie pour remplacer le pod. Ce paramètre peut prendre la valeur Recreate ou RollingUpdate, et la valeur par défaut est RollingUpdate..spec.strategy.type- 用于指定替换 pod 的策略类型。该参数可取值 Recreate 或 RollingUpdate,默认为 RollingUpdate。Recreate - K8s 会先删掉全部原有 pod 再创建新的 pod。该方式适用于新老版本互不兼容、无法共存的场景。但由于该方式会造成一段时间内服务完全不可用,在上述场景之外须慎用。
RollingUpdate - K8s 会将 pod 分批次逐步替换掉,可用来实现服务热升级。
.spec.strategy.rollingUpdate.maxSurge- 指定在滚动更新过程中最多可创建多少个额外的 pod,可以是数字或百分比。该值设置得越大、升级速度越快,但会消耗更多的系统资源。.spec.strategy.rollingUpdate.maxUnavailable
- RollingUpdate - Les K8 remplaceront progressivement les pods par lots, qui peuvent être utilisés pour mettre en œuvre une mise à niveau à chaud des services.
.spec.strategy.rollingUpdate.maxSurge- Spécifie le nombre maximum de pods supplémentaires pouvant être créés lors d'une mise à jour continue, sous forme de nombre ou de pourcentage. Plus la valeur définie est élevée, plus la mise à niveau sera rapide, mais consommera plus de ressources système.
.spec.strategy.rollingUpdate.maxUnavailable - Spécifie le nombre maximum de pods autorisés à être indisponibles pendant le processus de mise à jour continue, qui peut être un nombre ou un pourcentage. Plus la valeur est élevée, plus la mise à niveau sera rapide, mais le service sera plus instable.
En ajustant maxSurge et maxUnavailable, vous pouvez répondre aux besoins de mise à niveau dans différents scénarios.
🎜🎜🎜Si vous souhaitez effectuer une mise à niveau le plus rapidement possible tout en garantissant la disponibilité et la stabilité du système, vous pouvez définir maxUnavailable sur 0 et attribuer à maxSurge une valeur plus grande. 🎜🎜🎜🎜Si les ressources système sont limitées et que la charge du pod est faible, afin d'accélérer la mise à niveau, vous pouvez définir maxSurge sur 0 et donner à maxUnavailable une valeur plus grande. Il convient de noter que si maxSurge est 0 et maxUnavailable est DESIRED, cela peut entraîner l'indisponibilité de l'ensemble du service. À ce moment-là, RollingUpdate se dégradera en une version d'arrêt. 🎜🎜🎜🎜L'exemple choisit une solution de compromis, en définissant maxSurge sur 3 et maxUnavailable sur 2, qui équilibre la stabilité, la consommation de ressources et la vitesse de mise à niveau. 🎜🎜Sondes de configuration🎜🎜K8s propose les deux types de sondes suivants : 🎜ReadinessProbe - Par défaut, une fois que tous les conteneurs d'un pod sont démarrés, k8s considérera que le pod est dans un état prêt et enverra du trafic vers le pod. Cependant, après le démarrage de certaines applications, elles doivent encore terminer le chargement des données ou des fichiers de configuration avant de pouvoir fournir des services externes. Par conséquent, il n'est pas rigoureux de juger si le conteneur est prêt en fonction de son démarrage. En configurant des sondes de préparation pour les conteneurs, les k8 peuvent déterminer plus précisément si le conteneur est prêt, créant ainsi une application plus robuste. K8s garantit que ce n'est que lorsque tous les conteneurs d'un pod réussissent la détection de préparation que le service est autorisé à envoyer du trafic vers le pod. Une fois la détection de l'état de préparation échouée, les k8 cesseront d'envoyer du trafic vers le pod.
LivenessProbe - Par défaut, k8 considérera que les conteneurs en cours d'exécution sont disponibles. Mais ce jugement peut être problématique si l'application ne peut pas se fermer automatiquement lorsque quelque chose ne va pas ou devient malsain (par exemple, un blocage grave se produit). En configurant des sondes d'activité pour les conteneurs, les k8 peuvent déterminer plus précisément si le conteneur fonctionne normalement. Si le conteneur échoue à la détection d'activité, le kubelet l'arrêtera et déterminera l'action suivante en fonction de la politique de redémarrage.
La configuration de la sonde est très flexible. Les utilisateurs peuvent spécifier la fréquence de détection de la sonde, le seuil de réussite de la détection, le seuil d'échec de la détection, etc. Pour la signification et la méthode de configuration de chaque paramètre, veuillez vous référer au document Configure Liveness and Readiness Probes.
L'exemple configure une sonde de préparation et une sonde de vivacité pour le conteneur cible :
Le initialDelaySeconds de la sonde de préparation est défini sur 30, car l'application prend en moyenne 30 secondes pour terminer le travail d'initialisation.
Lors de la configuration de la sonde de vivacité, vous devez vous assurer que le conteneur dispose de suffisamment de temps pour atteindre l'état prêt. Si les paramètres initialDelaySeconds, periodSeconds et FailureThreshold sont définis sur une valeur trop petite, le conteneur peut être redémarré avant qu'il ne soit prêt, de sorte que l'état prêt ne puisse jamais être atteint. La configuration de l'exemple garantit que si le conteneur est prêt dans les 80 secondes suivant le démarrage, il ne sera pas redémarré, ce qui constitue un tampon suffisant par rapport au temps d'initialisation moyen de 30 secondes.
La périodeSecondes de la sonde de préparation est définie sur 10 et le seuil d'échec est défini sur 1. De cette façon, lorsque le conteneur est anormal, aucun trafic ne lui sera envoyé au bout d'environ 10 secondes.
La périodeSecondes de la sonde d'activité est définie sur 20 et le seuil d'échec est défini sur 3. De cette façon, lorsque le conteneur présente une anomalie, il ne redémarrera pas après environ 60 secondes.
Configurer minReadySeconds
Par défaut, une fois qu'un pod nouvellement créé est prêt, k8s considérera le pod comme disponible et supprimera l'ancien pod. Mais parfois, le problème peut être exposé lorsque le nouveau pod traite réellement les demandes des utilisateurs. Une approche plus robuste consiste donc à observer un nouveau pod pendant un certain temps avant de supprimer l'ancien pod.
Le paramètre minReadySeconds peut contrôler le temps d'observation du pod à l'état prêt. Si les conteneurs du pod peuvent fonctionner normalement pendant cette période, k8s considérera le nouveau pod disponible et supprimera l'ancien pod. Lors de la configuration de ce paramètre, vous devez le peser soigneusement. S'il est trop petit, cela peut entraîner une observation insuffisante. S'il est trop grand, cela ralentira la progression de la mise à niveau. L'exemple définit minReadySeconds sur 120 secondes, ce qui garantit que le pod à l'état prêt peut passer par un cycle complet de détection d'activité.
Configurer la terminaisonGracePeriodSeconds
Lorsque k8s est prêt à supprimer un pod, il enverra un signal TERM au conteneur dans le pod et supprimera simultanément le pod de la liste des points de terminaison du service. Si le conteneur ne peut pas être terminé dans le délai spécifié (30 secondes par défaut), k8s enverra le signal SIGKILL au conteneur pour terminer de force le processus. Pour le processus détaillé de résiliation des pods, veuillez vous référer au document Résiliation des pods.
Étant donné que l'application prend jusqu'à 40 secondes pour traiter les requêtes, afin de lui permettre de traiter les requêtes arrivées sur le serveur avant de s'arrêter, l'exemple définit un temps d'arrêt progressif de 60 secondes. Pour différentes applications, vous pouvez ajuster la valeur de terminateGracePeriodSeconds en fonction des conditions réelles.
Observez le comportement de la mise à niveau
La configuration ci-dessus peut garantir une mise à niveau fluide de l'application cible. Nous pouvons déclencher la mise à niveau du pod en modifiant n'importe quel champ de PodTemplateSpec dans le déploiement et observer le comportement de la mise à niveau en exécutant la commande kubectl get rs -w. Les changements dans le nombre de copies de pods des anciennes et des nouvelles versions observés ici sont les suivants :
Créez de nouveaux pods maxSurge. À ce stade, le nombre total de pods atteint la limite supérieure autorisée, c'est-à-dire DESIRED + maxSurge.
Démarrez immédiatement le processus de suppression des anciens pods maxUnavailable sans attendre que le nouveau pod soit prêt ou disponible. À l’heure actuelle, le nombre de pods disponibles est DÉSIRÉ – maxUnavailable.
Si un ancien pod est complètement supprimé, un nouveau pod sera ajouté immédiatement.
Lorsqu'un nouveau pod passe la détection de préparation et devient prêt, les k8 enverront du trafic vers le pod. Cependant, l’heure d’observation spécifiée n’étant pas atteinte, le pod ne sera pas considéré comme disponible.
Un pod prêt qui fonctionne normalement pendant la période d'observation est considéré comme disponible. A ce moment, le processus de suppression d'un ancien pod peut être relancé.
Répétez les étapes 3, 4 et 5 jusqu'à ce que tous les anciens pods soient supprimés et que les nouveaux pods disponibles atteignent le nombre cible de répliques.
失败回滚
应用的升级并不总会一帆风顺,在升级过程中或升级完成后都有可能遇到新版本行为不符合预期需要回滚到稳定版本的情况。K8s 会将 PodTemplateSpec 的每一次变更(如果更新模板标签或容器镜像)都记录下来。这样,如果新版本出现问题,就可以根据版本号方便地回滚到稳定版本。回滚 Deployment 的详细操作步骤可参考文档 Rolling Back a Deployment。
StatefulSet
StatefulSet 是针对有状态 pod 常用的部署形式。针对这类 pod,k8s 同样提供了许多参数用于灵活地控制它们的升级行为。好消息是这些参数大部分都和升级 Deployment 中的 pod 相同。这里重点介绍两者存在差异的地方。
策略类型
在 k8s 1.7 及之后的版本中,StatefulSet 支持 OnDelete 和 RollingUpdate 两种策略类型。
OnDelete - 当更新了 StatefulSet 中的 PodTemplateSpec 后,只有手动删除旧的 pod 后才会创建新版本 pod。这是默认的更新策略,一方面是为了兼容 k8s 1.6 及之前的版本,另一方面也是为了支持升级过程中新老版本 pod 互不兼容、无法共存的场景。
RollingUpdate - K8s 会将 StatefulSet 管理的 pod 分批次逐步替换掉。它与 Deployment 中 RollingUpdate 的区别在于 pod 的替换是有序的。例如一个 StatefulSet 中包含 N 个 pod,在部署的时候这些 pod 被分配了从 0 开始单调递增的序号,而在滚动更新时,它们会按逆序依次被替换。
Partition
可以通过参数.spec.updateStrategy.rollingUpdate.partition实现只升级部分 pod 的目的。在配置了 partition 后,只有序号大于或等于 partition 的 pod 才会进行滚动升级,其余 pod 将保持不变。
Partition 的另一个应用是可以通过不断减少 partition 的取值实现金丝雀升级。具体操作方法可参考文档 Rolling Out a Canary。
DaemonSet
DaemonSet 保证在全部(或者一些)k8s 工作节点上运行一个 pod 的副本,常用来运行监控或日志收集程序。对于 DaemonSet 中的 pod,用于控制它们升级行为的参数与 Deployment 几乎一致,只是在策略类型方面略有差异。DaemonSet 支持 OnDelete 和 RollingUpdate 两种策略类型。
OnDelete - 当更新了 DaemonSet 中的 PodTemplateSpec 后,只有手动删除旧的 pod 后才会创建新版本 pod。这是默认的更新策略,一方面是为了兼容 k8s 1.5 及之前的版本,另一方面也是为了支持升级过程中新老版本 pod 互不兼容、无法共存的场景。
RollingUpdate - 其含义和可配参数与 Deployment 的 RollingUpdate 一致。
滚动更新 DaemonSet 的具体操作步骤可参考文档 Perform a Rolling Update on a DaemonSet。
Job
Deployment、StatefulSet、DaemonSet 一般用于部署运行常驻进程,而 Job 中的 pod 在执行完特定任务后就会退出,因此不存在滚动更新的概念。当您更改了一个 Job 中的 PodTemplateSpec 后,需要手动删掉老的 Job 和 pod,并以新的配置重新运行该 job。
总结
K8s 提供的功能可以让大部分应用实现零宕机时间和无生产中断的升级,但也存在一些没有解决的问题,主要包括以下几点:
目前 k8s 原生仅支持停机发布、滚动发布两类部署升级策略。如果应用有蓝绿发布、金丝雀发布、A/B 测试等需求,需要进行二次开发或使用一些第三方工具。
K8s 虽然提供了回滚功能,但回滚操作必须手动完成,无法根据条件自动回滚。
有些应用在扩容或缩容时同样需要分批逐步执行,k8s 还未提供类似的功能。
实例配置:
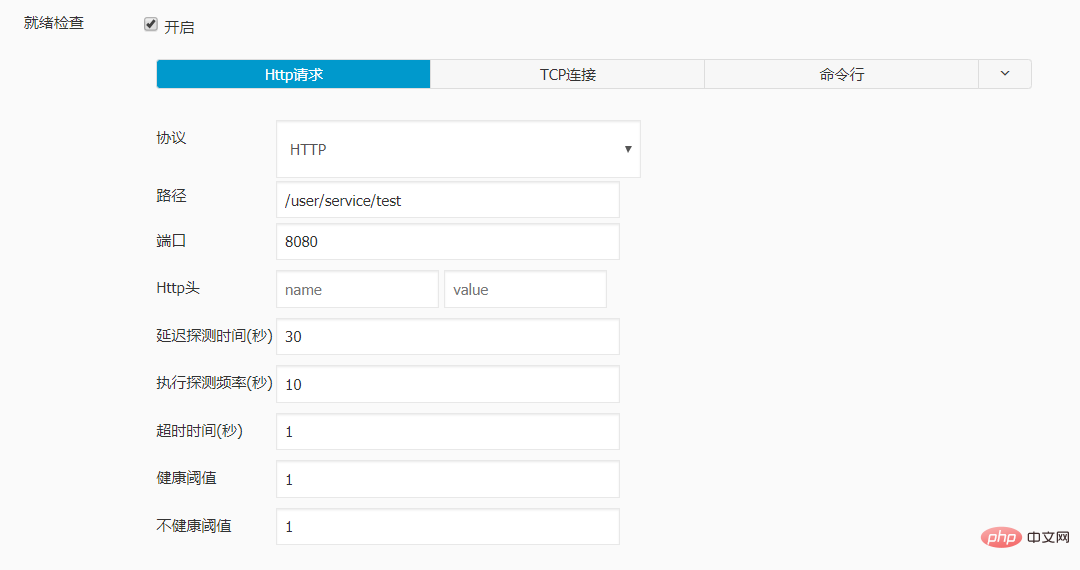
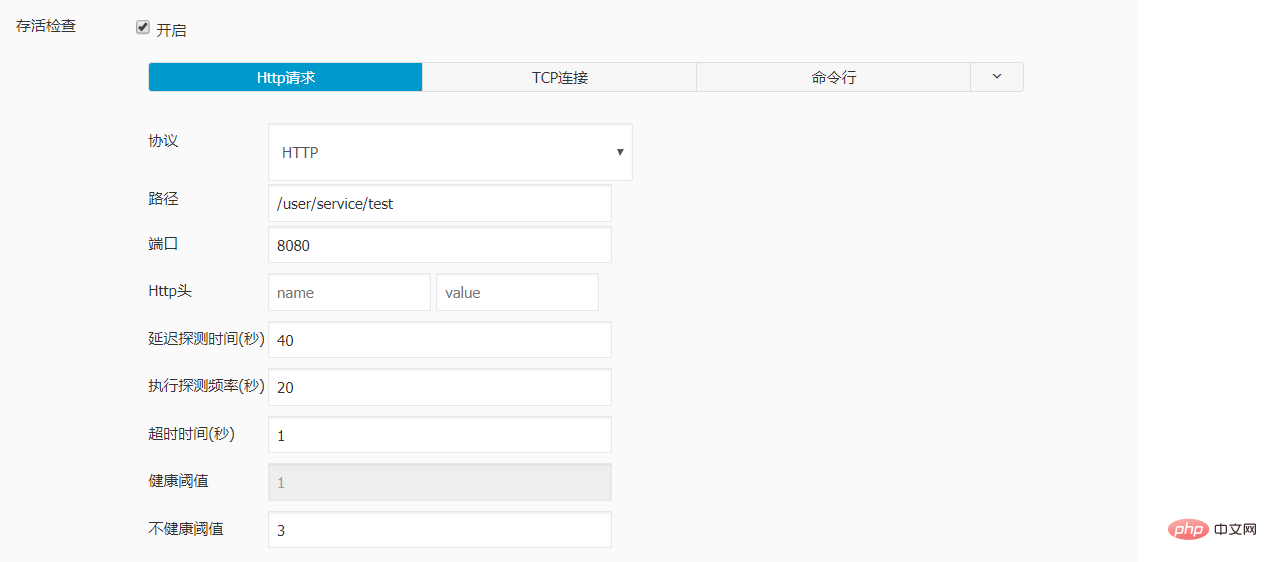
livenessProbe:
failureThreshold: 3
httpGet:
path: /user/service/test
port: 8080
scheme: HTTP
initialDelaySeconds: 40
periodSeconds: 20
successThreshold: 1
timeoutSeconds: 1
name: dataline-dev
ports:
- containerPort: 8080
protocol: TCP
readinessProbe:
failureThreshold: 1
httpGet:
path: /user/service/test
port: 8080
scheme: HTTP
initialDelaySeconds: 30
periodSeconds: 10
successThreshold: 1
timeoutSeconds: 1经测试 , 再对sprintboot 应用进行更新时, 访问不再出现502的报错。
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

Video Face Swap
Échangez les visages dans n'importe quelle vidéo sans effort grâce à notre outil d'échange de visage AI entièrement gratuit !

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)
Sujets chauds
 1393
1393
 52
1207
24
52
1207
24

 Comment Springboot intègre Jasypt pour implémenter le chiffrement des fichiers de configuration
Jun 01, 2023 am 08:55 AM
Comment Springboot intègre Jasypt pour implémenter le chiffrement des fichiers de configuration
Jun 01, 2023 am 08:55 AM
Introduction à Jasypt Jasypt est une bibliothèque Java qui permet à un développeur d'ajouter des fonctionnalités de chiffrement de base à son projet avec un minimum d'effort et ne nécessite pas une compréhension approfondie du fonctionnement du chiffrement. Haute sécurité pour le chiffrement unidirectionnel et bidirectionnel. technologie de cryptage basée sur des normes. Cryptez les mots de passe, le texte, les chiffres, les binaires... Convient pour l'intégration dans des applications basées sur Spring, API ouverte, pour une utilisation avec n'importe quel fournisseur JCE... Ajoutez la dépendance suivante : com.github.ulisesbocchiojasypt-spring-boot-starter2 1.1. Les avantages de Jasypt protègent la sécurité de notre système. Même en cas de fuite du code, la source de données peut être garantie.
 Comment SpringBoot intègre Redisson pour implémenter la file d'attente différée
May 30, 2023 pm 02:40 PM
Comment SpringBoot intègre Redisson pour implémenter la file d'attente différée
May 30, 2023 pm 02:40 PM
Scénario d'utilisation 1. La commande a été passée avec succès mais le paiement n'a pas été effectué dans les 30 minutes. Le paiement a expiré et la commande a été automatiquement annulée 2. La commande a été signée et aucune évaluation n'a été effectuée pendant 7 jours après la signature. Si la commande expire et n'est pas évaluée, le système donne par défaut une note positive. 3. La commande est passée avec succès. Si le commerçant ne reçoit pas la commande pendant 5 minutes, la commande est annulée. 4. Le délai de livraison expire et. un rappel par SMS est envoyé... Pour les scénarios avec des délais longs et de faibles performances en temps réel, nous pouvons utiliser la planification des tâches pour effectuer un traitement d'interrogation régulier. Par exemple : xxl-job Aujourd'hui, nous allons choisir
 Comment utiliser Redis pour implémenter des verrous distribués dans SpringBoot
Jun 03, 2023 am 08:16 AM
Comment utiliser Redis pour implémenter des verrous distribués dans SpringBoot
Jun 03, 2023 am 08:16 AM
1. Redis implémente le principe du verrouillage distribué et pourquoi les verrous distribués sont nécessaires. Avant de parler de verrous distribués, il est nécessaire d'expliquer pourquoi les verrous distribués sont nécessaires. Le contraire des verrous distribués est le verrouillage autonome. Lorsque nous écrivons des programmes multithreads, nous évitons les problèmes de données causés par l'utilisation d'une variable partagée en même temps. Nous utilisons généralement un verrou pour exclure mutuellement les variables partagées afin de garantir l'exactitude de celles-ci. les variables partagées. Son champ d’utilisation est dans le même processus. S’il existe plusieurs processus qui doivent exploiter une ressource partagée en même temps, comment peuvent-ils s’exclure mutuellement ? Les applications métier d'aujourd'hui sont généralement une architecture de microservices, ce qui signifie également qu'une application déploiera plusieurs processus si plusieurs processus doivent modifier la même ligne d'enregistrements dans MySQL, afin d'éviter les données sales causées par des opérations dans le désordre, les besoins de distribution. à introduire à ce moment-là. Le style est verrouillé. Vous voulez marquer des points
 Comment résoudre le problème selon lequel Springboot ne peut pas accéder au fichier après l'avoir lu dans un package jar
Jun 03, 2023 pm 04:38 PM
Comment résoudre le problème selon lequel Springboot ne peut pas accéder au fichier après l'avoir lu dans un package jar
Jun 03, 2023 pm 04:38 PM
Springboot lit le fichier, mais ne peut pas accéder au dernier développement après l'avoir empaqueté dans un package jar. Il existe une situation dans laquelle Springboot ne peut pas lire le fichier après l'avoir empaqueté dans un package jar. La raison en est qu'après l'empaquetage, le chemin virtuel du fichier. n’est pas valide et n’est accessible que via le flux Read. Le fichier se trouve sous les ressources publicvoidtest(){Listnames=newArrayList();InputStreamReaderread=null;try{ClassPathResourceresource=newClassPathResource("name.txt");Input
 Comment implémenter Springboot+Mybatis-plus sans utiliser d'instructions SQL pour ajouter plusieurs tables
Jun 02, 2023 am 11:07 AM
Comment implémenter Springboot+Mybatis-plus sans utiliser d'instructions SQL pour ajouter plusieurs tables
Jun 02, 2023 am 11:07 AM
Lorsque Springboot+Mybatis-plus n'utilise pas d'instructions SQL pour effectuer des opérations d'ajout de plusieurs tables, les problèmes que j'ai rencontrés sont décomposés en simulant la réflexion dans l'environnement de test : Créez un objet BrandDTO avec des paramètres pour simuler le passage des paramètres en arrière-plan. qu'il est extrêmement difficile d'effectuer des opérations multi-tables dans Mybatis-plus. Si vous n'utilisez pas d'outils tels que Mybatis-plus-join, vous pouvez uniquement configurer le fichier Mapper.xml correspondant et configurer le ResultMap malodorant et long, puis. écrivez l'instruction SQL correspondante Bien que cette méthode semble lourde, elle est très flexible et nous permet de
 Comparaison et analyse des différences entre SpringBoot et SpringMVC
Dec 29, 2023 am 11:02 AM
Comparaison et analyse des différences entre SpringBoot et SpringMVC
Dec 29, 2023 am 11:02 AM
SpringBoot et SpringMVC sont tous deux des frameworks couramment utilisés dans le développement Java, mais il existe des différences évidentes entre eux. Cet article explorera les fonctionnalités et les utilisations de ces deux frameworks et comparera leurs différences. Tout d’abord, découvrons SpringBoot. SpringBoot a été développé par l'équipe Pivotal pour simplifier la création et le déploiement d'applications basées sur le framework Spring. Il fournit un moyen rapide et léger de créer des fichiers exécutables autonomes.
 Comment SpringBoot personnalise Redis pour implémenter la sérialisation du cache
Jun 03, 2023 am 11:32 AM
Comment SpringBoot personnalise Redis pour implémenter la sérialisation du cache
Jun 03, 2023 am 11:32 AM
1. Personnalisez RedisTemplate1.1, mécanisme de sérialisation par défaut RedisAPI. L'implémentation du cache Redis basée sur l'API utilise le modèle RedisTemplate pour les opérations de mise en cache des données. Ici, ouvrez la classe RedisTemplate et affichez les informations sur le code source de la classe. Déclarer la clé, diverses méthodes de sérialisation de la valeur, la valeur initiale est vide @NullableprivateRedisSe
 Comment obtenir la valeur dans application.yml au Springboot
Jun 03, 2023 pm 06:43 PM
Comment obtenir la valeur dans application.yml au Springboot
Jun 03, 2023 pm 06:43 PM
Dans les projets, certaines informations de configuration sont souvent nécessaires. Ces informations peuvent avoir des configurations différentes dans l'environnement de test et dans l'environnement de production, et peuvent devoir être modifiées ultérieurement en fonction des conditions commerciales réelles. Nous ne pouvons pas coder en dur ces configurations dans le code. Il est préférable de les écrire dans le fichier de configuration. Par exemple, vous pouvez écrire ces informations dans le fichier application.yml. Alors, comment obtenir ou utiliser cette adresse dans le code ? Il existe 2 méthodes. Méthode 1 : Nous pouvons obtenir la valeur correspondant à la clé dans le fichier de configuration (application.yml) via le ${key} annoté avec @Value. Cette méthode convient aux situations où il y a relativement peu de microservices. Méthode 2 : En réalité. projets, Quand les affaires sont compliquées, la logique
