

Comment utiliser le module python beautifulsoup4

1. Supplément de connaissances de base de BeautifulSoup4
BeautifulSoup4 est une bibliothèque d'analyse Python, principalement utilisée pour analyser le HTML et le XML dans le système de connaissances des robots. more More, BeautifulSoup4 是一款 python 解析库,主要用于解析 HTML 和 XML,在爬虫知识体系中解析 HTML 会比较多一些,
该库安装命令如下:
pip install beautifulsoup4
BeautifulSoup 在解析数据时,需依赖第三方解析器,常用解析器与优势如下所示:
python 标准库 html.parser:python 内置标准库,容错能力强;lxml 解析器:速度快,容错能力强;html5lib:容错性最强,解析方式与浏览器一致。
接下来用一段自定义的 HTML 代码来演示 beautifulsoup4 库的基本使用,测试代码如下:
<html>
<head>
<title>测试bs4模块脚本</title>
</head>
<body>
<h2 id="橡皮擦的爬虫课">橡皮擦的爬虫课</h2>
<p>用一段自定义的 HTML 代码来演示</p>
</body>
</html>使用 BeautifulSoup 对其进行简单的操作,包含实例化 BS 对象,输出页面标签等内容。
from bs4 import BeautifulSoup text_str = """<html> <head> <title>测试bs4模块脚本</title> </head> <body> <h2 id="橡皮擦的爬虫课">橡皮擦的爬虫课</h2> <p>用1段自定义的 HTML 代码来演示</p> <p>用2段自定义的 HTML 代码来演示</p> </body> </html> """ # 实例化 Beautiful Soup 对象 soup = BeautifulSoup(text_str, "html.parser") # 上述是将字符串格式化为 Beautiful Soup 对象,你可以从一个文件进行格式化 # soup = BeautifulSoup(open('test.html')) print(soup) # 输入网页标题 title 标签 print(soup.title) # 输入网页 head 标签 print(soup.head) # 测试输入段落标签 p print(soup.p) # 默认获取第一个
我们可以通过 BeautifulSoup 对象,直接调用网页标签,这里存在一个问题,通过 BS 对象调用标签只能获取排在第一位置上的标签,如上述代码中,只获取到了一个 p 标签,如果想要获取更多内容,请继续阅读。
学习到这里,我们需要了解 BeautifulSoup 中的 4 个内置对象:
BeautifulSoup:基本对象,整个 HTML 对象,一般当做 Tag 对象看即可;Tag:标签对象,标签就是网页中的各个节点,例如 title,head,p;NavigableString:标签内部字符串;Comment:注释对象,爬虫里面使用场景不多。
下述代码为你演示这几种对象出现的场景,注意代码中的相关注释:
from bs4 import BeautifulSoup text_str = """<html> <head> <title>测试bs4模块脚本</title> </head> <body> <h2 id="橡皮擦的爬虫课">橡皮擦的爬虫课</h2> <p>用1段自定义的 HTML 代码来演示</p> <p>用2段自定义的 HTML 代码来演示</p> </body> </html> """ # 实例化 Beautiful Soup 对象 soup = BeautifulSoup(text_str, "html.parser") # 上述是将字符串格式化为 Beautiful Soup 对象,你可以从一个文件进行格式化 # soup = BeautifulSoup(open('test.html')) print(soup) print(type(soup)) # <class 'bs4.BeautifulSoup'> # 输入网页标题 title 标签 print(soup.title) print(type(soup.title)) # <class 'bs4.element.Tag'> print(type(soup.title.string)) # <class 'bs4.element.NavigableString'> # 输入网页 head 标签 print(soup.head)
对于 Tag 对象,有两个重要的属性,是 name 和 attrs
from bs4 import BeautifulSoup text_str = """<html> <head> <title>测试bs4模块脚本</title> </head> <body> <h2 id="橡皮擦的爬虫课">橡皮擦的爬虫课</h2> <p>用1段自定义的 HTML 代码来演示</p> <p>用2段自定义的 HTML 代码来演示</p> <a href="http://www.csdn.net" rel="external nofollow" rel="external nofollow" >CSDN 网站</a> </body> </html> """ # 实例化 Beautiful Soup 对象 soup = BeautifulSoup(text_str, "html.parser") print(soup.name) # [document] print(soup.title.name) # 获取标签名 title print(soup.html.body.a) # 可以通过标签层级获取下层标签 print(soup.body.a) # html 作为一个特殊的根标签,可以省略 print(soup.p.a) # 无法获取到 a 标签 print(soup.a.attrs) # 获取属性
上述代码演示了获取 name 属性和 attrs 属性的用法,其中 attrs 属性得到的是一个字典,可以通过键获取对应的值。
获取标签的属性值,在 BeautifulSoup 中,还可以使用如下方法:
print(soup.a["href"])
print(soup.a.get("href"))获取 NavigableString 对象 获取了网页标签之后,就要获取标签内文本了,通过下述代码进行。
print(soup.a.string)
除此之外,你还可以使用 text 属性和 get_text() 方法获取标签内容。
print(soup.a.string) print(soup.a.text) print(soup.a.get_text())
还可以获取标签内所有文本,使用 strings 和 stripped_strings 即可。
print(list(soup.body.strings)) # 获取到空格或者换行 print(list(soup.body.stripped_strings)) # 去除空格或者换行
扩展标签/节点选择器之遍历文档树
直接子节点
标签(Tag)对象的直接子元素,可以使用 contents 和 children 属性获取。
from bs4 import BeautifulSoup
text_str = """<html>
<head>
<title>测试bs4模块脚本</title>
</head>
<body>
<div id="content">
<h2 id="橡皮擦的爬虫课-span-最棒-span">橡皮擦的爬虫课<span>最棒</span></h2>
<p>用1段自定义的 HTML 代码来演示</p>
<p>用2段自定义的 HTML 代码来演示</p>
<a href="http://www.csdn.net" rel="external nofollow" rel="external nofollow" >CSDN 网站</a>
</div>
<ul class="nav">
<li>首页</li>
<li>博客</li>
<li>专栏课程</li>
</ul>
</body>
</html>
"""
# 实例化 Beautiful Soup 对象
soup = BeautifulSoup(text_str, "html.parser")
# contents 属性获取节点的直接子节点,以列表的形式返回内容
print(soup.div.contents) # 返回列表
# children 属性获取的也是节点的直接子节点,以生成器的类型返回
print(soup.div.children) # 返回 <list_iterator object at 0x00000111EE9B6340>请注意以上两个属性获取的都是直接子节点,例如 h2 标签内的后代标签 span ,不会单独获取到。
如果希望将所有的标签都获取到,使用 descendants 属性,它返回的是一个生成器,所有标签包括标签内的文本都会单独获取。
print(list(soup.div.descendants))
其它节点的获取(了解即可,即查即用)
parent和parents:直接父节点和所有父节点;next_sibling,next_siblings,previous_sibling,previous_siblings:分别表示下一个兄弟节点、下面所有兄弟节点、上一个兄弟节点、上面所有兄弟节点,由于换行符也是一个节点,所有在使用这几个属性时,要注意一下换行符;next_element,next_elements,previous_element,previous_elements:这几个属性分别表示上一个节点或者下一个节点,注意它们不分层次,而是针对所有节点,例如上述代码中div节点的下一个节点是h2,而div节点的兄弟节点是ul。
文档树搜索相关函数
第一个要学习的函数就是 find_all() 函数,原型如下所示:
find_all(name,attrs,recursive,text,limit=None,**kwargs)
La commande d'installation de la bibliothèque est la suivante :#🎜🎜#name:该参数为 tag 标签的名字,例如find_all('p')是查找所有的p#🎜🎜#print(soup.find_all('li')) # 获取所有的 li print(soup.find_all(attrs={'class': 'nav'})) # 传入 attrs 属性 print(soup.find_all(re.compile("p"))) # 传递正则,实测效果不理想 print(soup.find_all(['a','p'])) # 传递列表Copier après la connexionCopier après la connexionBeautifulSoupLors de l'analyse des données, vous devez s'appuyer sur des analyseurs tiers,les analyseurs couramment utilisés et leurs avantages sont les suivants :#🎜🎜#- #🎜🎜#
analyseur standard python html.: bibliothèque standard intégrée python, forte tolérance aux pannes ; #🎜🎜# - #🎜🎜#
analyseur lxml: rapide, puissant ; tolérance aux pannes ; #🎜 🎜# - #🎜🎜#
html5lib: la plus tolérante aux pannes et la méthode d'analyse est cohérente avec le navigateur. #🎜🎜#
beautifulsoup4Le code de test est le suivant : #🎜🎜. ## 🎜🎜#Utilisezprint(soup.body.div.find_all(['a','p'],recursive=False)) # 传递列表
Copier après la connexionCopier après la connexionBeautifulSouppour effectuer des opérations simples dessus, notamment l'instanciation d'objets BS, la sortie de balises de page, etc. #🎜🎜##🎜🎜#Nous pouvons appeler directement la balise de page Web via l'objet BeautifulSoup. Il y a un problème ici. L'appel de la balise via l'objet BS ne peut que classer la balise en premier. la balise en première position est obtenue. Une baliseprint(soup.find_all(text='首页')) # ['首页'] print(soup.find_all(text=re.compile("^首"))) # ['首页'] print(soup.find_all(text=["首页",re.compile('课')])) # ['橡皮擦的爬虫课', '首页', '专栏课程']Copier après la connexionCopier après la connexionp, si vous souhaitez obtenir plus de contenu, veuillez continuer à lire. #🎜🎜##🎜🎜#Après avoir appris cela, nous devons comprendre les 4 objets intégrés dans BeautifulSoup :#🎜🎜#- # 🎜🎜#
BeautifulSoup: Objet de base, l'objet HTML entier, généralement considéré comme un objet Tag ; #🎜🎜# - #🎜🎜#
Tag</ ; code> : Objet Label, l'étiquette est chaque nœud de la page Web, tel que title, head, p; #🎜🎜#</li><li>#🎜🎜#<code>NavigableString: Label internal string; #🎜 🎜# - #🎜🎜#
Comment: Objet de commentaire, il n'y a pas beaucoup de scénarios d'utilisation dans les robots. #🎜🎜#
# 🎜🎜#Pour l'objet Tag, il existe deux attributs importants, qui sontprint(soup.find_all(class_ = 'nav')) print(soup.find_all(class_ = 'nav li'))
Copier après la connexionCopier après la connexionnameetattrs#🎜 🎜##🎜🎜#Le code ci-dessus démontre l'utilisation de l'obtention de l'attributprint(soup.select('ul[class^="na"]'))
Copier après la connexionCopier après la connexionnameet de l'attributattrs. L'attributattrsobtient un dictionnaire. , qui peut être transmis Key obtient la valeur correspondante. #🎜🎜##🎜🎜#Obtenir la valeur d'attribut de la balise Dans BeautifulSoup, vous pouvez également utiliser la méthode suivante : #🎜🎜##🎜🎜#Obtenir l'objetprint(soup.select('ul[class*="li"]'))
Copier après la connexionCopier après la connexionNavigableString< /strong> Après avoir obtenu la balise de page Web, vous devez obtenir le texte contenu dans la balise, ce qui se fait via le code suivant. #🎜🎜##🎜🎜#De plus, vous pouvez également utiliser l'attributfrom bs4 import BeautifulSoup import requests import logging logging.basicConfig(level=logging.NOTSET) def get_html(url, headers) -> None: try: res = requests.get(url=url, headers=headers, timeout=3) except Exception as e: logging.debug("采集异常", e) if res is not None: html_str = res.text soup = BeautifulSoup(html_str, "html.parser") imgs = soup.find_all(attrs={'class': 'lazy'}) print("获取到的数据量是", len(imgs)) datas = [] for item in imgs: name = item.get('alt') src = item["src"] logging.info(f"{name},{src}") # 获取拼接数据 datas.append((name, src)) save(datas, headers) def save(datas, headers) -> None: if datas is not None: for item in datas: try: # 抓取图片 res = requests.get(url=item[1], headers=headers, timeout=5) except Exception as e: logging.debug(e) if res is not None: img_data = res.content with open("./imgs/{}.jpg".format(item[0]), "wb+") as f: f.write(img_data) else: return None if __name__ == '__main__': headers = { "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4577.82 Safari/537.36" } url_format = "http://www.9thws.com/#p{}" urls = [url_format.format(i) for i in range(1, 2)] get_html(urls[0], headers)Copier après la connexionCopier après la connexiontextet la méthodeget_text()pour obtenir le contenu de la balise. #🎜🎜#rrreee#🎜🎜# Vous pouvez également obtenir tout le texte de la balise en utilisantstringsetstripped_strings. #🎜🎜#rrreee#🎜🎜#Sélecteur de balise/nœud étendu traversant l'arborescence du document#🎜🎜##🎜🎜#Nœud enfant direct#🎜🎜##🎜🎜#Objet Tag Les éléments enfants directs peut être obtenu en utilisant les attributscontentsetchildren. #🎜🎜#rrreee#🎜🎜#Veuillez noter que les deux attributs ci-dessus obtiennent les nœuds enfants directs, tels que la balise descendantespan</ dans le <code>h2code de balise> ne sera pas obtenu séparément. #🎜🎜##🎜🎜#Si vous souhaitez obtenir toutes les balises, utilisez l'attributdescendants. Il renvoie un générateur et toutes les balises, y compris le texte à l'intérieur des balises, seront récupérées séparément. #🎜🎜#rrreee#🎜🎜#Acquisition d'autres nœuds (il suffit de comprendre, vérifier et utiliser) #🎜🎜#- #🎜🎜#
parent </ code> et <code>parents: nœud parent direct et tous les nœuds parents ; #🎜🎜# - #🎜🎜#
next_sibling,next_siblings </ code>, <code>previous_sibling,previous_siblings: représentent respectivement le nœud frère suivant, tous les nœuds frères en dessous, le nœud frère précédent et tous les nœuds frères au-dessus puisque le caractère de nouvelle ligne est également. un nœud, lorsque vous utilisez ces attributs, veuillez faire attention au saut de ligne #🎜🎜# - #🎜🎜#
next_element,next_elements, < code>previous_element,previous_elements: ces attributs représentent respectivement le nœud précédent ou le nœud suivant. Notez qu'ils ne sont pas hiérarchiques, mais ciblent tous les nœuds, comme dans le code ci-dessusdivesth2, et le nœud frère du nœuddivestul. #🎜🎜#
find_all() </ code>, <strong>le prototype est le suivant : </strong>#🎜🎜#rrreee<ul class=" list-paddingleft-2"><li>#🎜🎜#<code>name: Ce paramètre est le nom de la balise. Par exemple,find_all('p')sert à rechercher toutes les balisesp. Il peut accepter les chaînes de nom de balise, les expressions régulières et. listes #🎜🎜#- #🎜🎜#
attrs:传入的属性,该参数可以字典的形式传入,例如attrs={'class': 'nav'},返回的结果是 tag 类型的列表;
上述两个参数的用法示例如下:
print(soup.find_all('li')) # 获取所有的 li
print(soup.find_all(attrs={'class': 'nav'})) # 传入 attrs 属性
print(soup.find_all(re.compile("p"))) # 传递正则,实测效果不理想
print(soup.find_all(['a','p'])) # 传递列表recursive:调用find_all ()方法时,BeautifulSoup 会检索当前 tag 的所有子孙节点,如果只想搜索 tag 的直接子节点,可以使用参数recursive=False,测试代码如下:
print(soup.body.div.find_all(['a','p'],recursive=False)) # 传递列表
text:可以检索文档中的文本字符串内容,与name参数的可选值一样,text参数接受标签名字符串、正则表达式、 列表;
print(soup.find_all(text='首页')) # ['首页']
print(soup.find_all(text=re.compile("^首"))) # ['首页']
print(soup.find_all(text=["首页",re.compile('课')])) # ['橡皮擦的爬虫课', '首页', '专栏课程']limit:可以用来限制返回结果的数量;kwargs:如果一个指定名字的参数不是搜索内置的参数名,搜索时会把该参数当作 tag 的属性来搜索。这里要按class属性搜索,因为class是 python 的保留字,需要写作class_,按class_查找时,只要一个 CSS 类名满足即可,如需多个 CSS 名称,填写顺序需要与标签一致。
print(soup.find_all(class_ = 'nav')) print(soup.find_all(class_ = 'nav li'))
还需要注意网页节点中,有些属性在搜索中不能作为kwargs参数使用,比如html5 中的 data-*属性,需要通过attrs参数进行匹配。
与
find_all()方法用户基本一致的其它方法清单如下:
find():函数原型find( name , attrs , recursive , text , **kwargs ),返回一个匹配元素;find_parents(),find_parent():函数原型find_parent(self, name=None, attrs={}, **kwargs),返回当前节点的父级节点;find_next_siblings(),find_next_sibling():函数原型find_next_sibling(self, name=None, attrs={}, text=None, **kwargs),返回当前节点的下一兄弟节点;find_previous_siblings(),find_previous_sibling():同上,返回当前的节点的上一兄弟节点;find_all_next(),find_next(),find_all_previous () ,find_previous ():函数原型find_all_next(self, name=None, attrs={}, text=None, limit=None, **kwargs),检索当前节点的后代节点。
CSS 选择器 该小节的知识点与pyquery有点撞车,核心使用select()方法即可实现,返回数据是列表元组。
通过标签名查找,
soup.select("title");通过类名查找,
soup.select(".nav");通过 id 名查找,
soup.select("#content");通过组合查找,
soup.select("div#content");通过属性查找,
soup.select("div[id='content'"),soup.select("a[href]");
在通过属性查找时,还有一些技巧可以使用,例如:
^=:可以获取以 XX 开头的节点:
print(soup.select('ul[class^="na"]'))
*=:获取属性包含指定字符的节点:
print(soup.select('ul[class*="li"]'))
二、爬虫案例
BeautifulSoup 的基础知识掌握之后,在进行爬虫案例的编写,就非常简单了,本次要采集的目标网站 ,该目标网站有大量的艺术二维码,可以供设计大哥做参考。
下述应用到了 BeautifulSoup 模块的标签检索与属性检索,完整代码如下:
from bs4 import BeautifulSoup
import requests
import logging
logging.basicConfig(level=logging.NOTSET)
def get_html(url, headers) -> None:
try:
res = requests.get(url=url, headers=headers, timeout=3)
except Exception as e:
logging.debug("采集异常", e)
if res is not None:
html_str = res.text
soup = BeautifulSoup(html_str, "html.parser")
imgs = soup.find_all(attrs={'class': 'lazy'})
print("获取到的数据量是", len(imgs))
datas = []
for item in imgs:
name = item.get('alt')
src = item["src"]
logging.info(f"{name},{src}")
# 获取拼接数据
datas.append((name, src))
save(datas, headers)
def save(datas, headers) -> None:
if datas is not None:
for item in datas:
try:
# 抓取图片
res = requests.get(url=item[1], headers=headers, timeout=5)
except Exception as e:
logging.debug(e)
if res is not None:
img_data = res.content
with open("./imgs/{}.jpg".format(item[0]), "wb+") as f:
f.write(img_data)
else:
return None
if __name__ == '__main__':
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4577.82 Safari/537.36"
}
url_format = "http://www.9thws.com/#p{}"
urls = [url_format.format(i) for i in range(1, 2)]
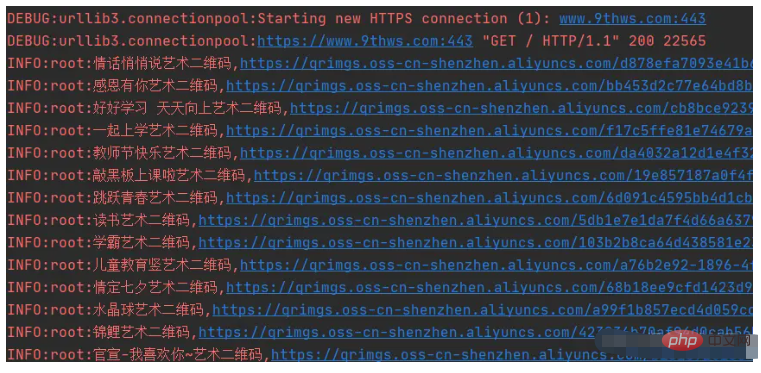
get_html(urls[0], headers)本次代码测试输出采用的 logging 模块实现,效果如下图所示。 测试仅采集了 1 页数据,如需扩大采集范围,只需要修改 main 函数内页码规则即可。 ==代码编写过程中,发现数据请求是类型是 POST,数据返回格式是 JSON,所以本案例仅作为 BeautifulSoup 的上手案例吧==
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)
Sujets chauds



 Comment ouvrir le format XML
Apr 02, 2025 pm 09:00 PM
Comment ouvrir le format XML
Apr 02, 2025 pm 09:00 PM
Utiliser la plupart des éditeurs de texte pour ouvrir des fichiers XML; Si vous avez besoin d'un affichage d'arbre plus intuitif, vous pouvez utiliser un éditeur XML, tel que Oxygen XML Editor ou XMLSPY; Si vous traitez les données XML dans un programme, vous devez utiliser un langage de programmation (tel que Python) et des bibliothèques XML (telles que XML.ETREE.ElementTree) pour analyser.
 Y a-t-il une application mobile qui peut convertir XML en PDF?
Apr 02, 2025 pm 08:54 PM
Y a-t-il une application mobile qui peut convertir XML en PDF?
Apr 02, 2025 pm 08:54 PM
Une application qui convertit le XML directement en PDF ne peut être trouvée car ce sont deux formats fondamentalement différents. XML est utilisé pour stocker des données, tandis que PDF est utilisé pour afficher des documents. Pour terminer la transformation, vous pouvez utiliser des langages de programmation et des bibliothèques telles que Python et ReportLab pour analyser les données XML et générer des documents PDF.
 La vitesse de conversion est-elle rapide lors de la conversion du XML en PDF sur le téléphone mobile?
Apr 02, 2025 pm 10:09 PM
La vitesse de conversion est-elle rapide lors de la conversion du XML en PDF sur le téléphone mobile?
Apr 02, 2025 pm 10:09 PM
La vitesse du XML mobile à PDF dépend des facteurs suivants: la complexité de la structure XML. Méthode de conversion de configuration du matériel mobile (bibliothèque, algorithme) Méthodes d'optimisation de la qualité du code (sélectionnez des bibliothèques efficaces, optimiser les algorithmes, les données de cache et utiliser le multi-threading). Dans l'ensemble, il n'y a pas de réponse absolue et elle doit être optimisée en fonction de la situation spécifique.
 Outil de mise en forme XML recommandé
Apr 02, 2025 pm 09:03 PM
Outil de mise en forme XML recommandé
Apr 02, 2025 pm 09:03 PM
Les outils de mise en forme XML peuvent taper le code en fonction des règles pour améliorer la lisibilité et la compréhension. Lors de la sélection d'un outil, faites attention aux capacités de personnalisation, en gérant des circonstances spéciales, des performances et de la facilité d'utilisation. Les types d'outils couramment utilisés incluent des outils en ligne, des plug-ins IDE et des outils de ligne de commande.
 Existe-t-il un outil gratuit XML à PDF pour les téléphones mobiles?
Apr 02, 2025 pm 09:12 PM
Existe-t-il un outil gratuit XML à PDF pour les téléphones mobiles?
Apr 02, 2025 pm 09:12 PM
Il n'y a pas d'outil XML à PDF simple et direct sur mobile. Le processus de visualisation des données requis implique une compréhension et un rendu complexes des données, et la plupart des outils dits "gratuits" sur le marché ont une mauvaise expérience. Il est recommandé d'utiliser des outils côté informatique ou d'utiliser des services cloud, ou de développer vous-même des applications pour obtenir des effets de conversion plus fiables.
 Comment convertir XML en PDF sur votre téléphone avec une qualité de haute qualité?
Apr 02, 2025 pm 09:48 PM
Comment convertir XML en PDF sur votre téléphone avec une qualité de haute qualité?
Apr 02, 2025 pm 09:48 PM
Convertir XML en PDF avec une qualité de haute qualité sur votre téléphone mobile nécessite: analyser le XML dans le cloud et générer des PDF à l'aide d'une plate-forme informatique sans serveur. Choisissez un analyseur XML efficace et une bibliothèque de génération PDF. Gérer correctement les erreurs. Faites une utilisation complète de la puissance de cloud computing pour éviter les tâches lourdes sur votre téléphone. Ajustez la complexité en fonction des exigences, notamment le traitement des structures XML complexes, la génération de PDF de plusieurs pages et l'ajout d'images. Imprimez les informations du journal pour aider à déboguer. Optimiser les performances, sélectionner des analyseurs efficaces et des bibliothèques PDF et peut utiliser une programmation asynchrone ou des données XML prétraitées. Assurez-vous une bonne qualité de code et maintenabilité.
 Comment convertir les fichiers XML en PDF sur votre téléphone?
Apr 02, 2025 pm 10:12 PM
Comment convertir les fichiers XML en PDF sur votre téléphone?
Apr 02, 2025 pm 10:12 PM
Il est impossible de terminer la conversion XML à PDF directement sur votre téléphone avec une seule application. Il est nécessaire d'utiliser les services cloud, qui peuvent être réalisés via deux étapes: 1. Convertir XML en PDF dans le cloud, 2. Accédez ou téléchargez le fichier PDF converti sur le téléphone mobile.
 Comment convertir XML en PDF sur votre téléphone?
Apr 02, 2025 pm 10:18 PM
Comment convertir XML en PDF sur votre téléphone?
Apr 02, 2025 pm 10:18 PM
Il n'est pas facile de convertir XML en PDF directement sur votre téléphone, mais il peut être réalisé à l'aide des services cloud. Il est recommandé d'utiliser une application mobile légère pour télécharger des fichiers XML et recevoir des PDF générés, et de les convertir avec des API Cloud. Les API Cloud utilisent des services informatiques sans serveur et le choix de la bonne plate-forme est crucial. La complexité, la gestion des erreurs, la sécurité et les stratégies d'optimisation doivent être prises en compte lors de la gestion de l'analyse XML et de la génération de PDF. L'ensemble du processus nécessite que l'application frontale et l'API back-end fonctionnent ensemble, et il nécessite une certaine compréhension d'une variété de technologies.
