
 Périphériques technologiques
IA
100:87 : L'esprit GPT-4 écrase les humains ! Les trois principales variantes du GPT-3.5 sont difficiles à vaincre
Périphériques technologiques
IA
100:87 : L'esprit GPT-4 écrase les humains ! Les trois principales variantes du GPT-3.5 sont difficiles à vaincre
100:87 : L'esprit GPT-4 écrase les humains ! Les trois principales variantes du GPT-3.5 sont difficiles à vaincre

La théorie de l’esprit de GPT-4 a surpassé les humains !
Récemment, des experts de l'Université Johns Hopkins ont découvert que GPT-4 peut utiliser le raisonnement en chaîne de pensée et la pensée étape par étape, améliorant considérablement sa théorie des performances de l'esprit.

Adresse papier : https://arxiv.org/abs/2304.11490
Dans certains tests, le niveau humain est d'environ 87 % et GPT-4 a atteint le plafond de 100 % niveau!
De plus, avec des invites appropriées, tous les modèles formés au RLHF peuvent atteindre une précision de plus de 80 %.
Laissons l'IA apprendre la théorie du raisonnement mental
Nous savons tous que de nombreux grands modèles de langage ne sont pas très doués pour résoudre les problèmes de la vie quotidienne.
LeCun, scientifique en chef de l'IA de Meta et lauréat du Turing Award, a un jour affirmé : « Sur la route vers une IA au niveau humain, les grands modèles de langage sont une route tortueuse. Vous savez, même un chat ou un chien de compagnie est meilleur que n'importe quel autre LLM. a plus de bon sens et de compréhension du monde. Cependant, les grands modèles de langage tels que GPT-3, GPT-4, Bard, Chinchilla et LLaMA n'ont pas de corps.
Donc, à moins qu'ils ne développent un corps et des sens humains et qu'ils aient un mode de vie à des fins humaines. Autrement, ils ne comprendraient tout simplement pas le langage comme le font les humains. 
En bref, même si les excellentes performances des grands modèles de langage dans de nombreuses tâches sont étonnantes, les tâches qui nécessitent un raisonnement restent difficiles pour eux.
Ce qui est particulièrement difficile, c'est un raisonnement selon la théorie de l'esprit (ToM).
Pourquoi ToM raisonne-t-il si difficilement ?Parce que dans les tâches ToM, LLM doit raisonner sur la base d'informations non observables (telles que l'état mental caché des autres). Ces informations doivent être déduites du contexte et ne peuvent pas être analysées à partir du texte de surface.
Cependant, pour le LLM, la capacité à effectuer un raisonnement ToM de manière fiable est importante. Parce que ToM est la base de la compréhension sociale, ce n’est qu’avec la capacité ToM que les gens peuvent participer à des échanges sociaux complexes et prédire les actions ou les réactions des autres.
Si l'IA ne peut pas apprendre la compréhension sociale et obtenir les différentes règles de l'interaction sociale humaine, elle ne sera pas en mesure de mieux fonctionner pour les humains et de fournir aux humains des informations précieuses sur diverses tâches qui nécessitent un raisonnement.
Que dois-je faire ?
Les experts ont découvert que grâce à une sorte d'« apprentissage contextuel », la capacité de raisonnement du LLM peut être considérablement améliorée.
Pour les modèles de langage avec plus de 100 B de paramètres, tant qu'une démonstration de tâche spécifique en quelques étapes est saisie, les performances du modèle sont considérablement améliorées.
De plus, demander simplement aux modèles de réfléchir étape par étape améliorera leurs performances d'inférence, même sans démonstration.
Pourquoi ces techniques rapides sont-elles si efficaces ? Il n’existe actuellement aucune théorie permettant de l’expliquer.
Concurrents de grands modèles de langageSur la base de ce contexte, des chercheurs de l'Université Johns Hopkins ont évalué les performances de certains modèles de langage sur des tâches ToM et ont exploré si leurs performances pouvaient être améliorées par une réflexion étape par étape, peu de méthodes telles que car l'apprentissage par tir et le raisonnement en chaîne de pensée peuvent être utilisés pour l'améliorer.
Les concurrents sont les quatre derniers modèles GPT de la famille OpenAI : GPT-4 et trois variantes de GPT-3.5, Davinci-2, Davinci-3 et GPT-3.5-Turbo.
· Davinci-2 (nom de l'API : text-davinci-002) est formé avec un réglage fin supervisé sur des démos écrites par des humains.
· Davinci-3 (nom de l'API : text-davinci-003) est une version améliorée de Davinci-2, qui est entraînée davantage à l'aide d'un apprentissage par renforcement optimisé par une politique approximative avec retour humain (RLHF).
· GPT-3.5-Turbo (la version originale de ChatGPT), affiné et formé à la fois sur des démos écrites par des humains et sur RLHF, puis optimisé pour les conversations.
· GPT-4 est le dernier modèle GPT en date d'avril 2023. Peu de détails ont été publiés sur la taille et les méthodes de formation du GPT-4, cependant, il semble avoir subi une formation RLHF plus intensive et est donc plus conforme à l'intention humaine.
Conception expérimentale : les humains et les modèles vont bien
Comment examiner ces modèles ? Les chercheurs ont conçu deux scénarios, l’un est un scénario de contrôle et l’autre est un scénario ToM.
La scène de contrôle fait référence à une scène sans aucun agent, que l'on peut appeler une "Scène Photo".
La scène ToM décrit l'état psychologique des personnes impliquées dans une certaine situation.
Les questions de ces scénarios sont presque les mêmes en difficulté.
Humains
Les premiers à relever le défi sont les humains.
Les participants humains disposaient de 18 secondes pour chaque scénario.
Par la suite, une question apparaîtra sur un nouvel écran, et le participant humain répondra en cliquant sur « Oui » ou « Non ».
Dans l'expérience, les scènes Photo et ToM ont été mixées et présentées dans un ordre aléatoire.
Par exemple, le problème avec la scène Photo est le suivant -
Scénario : "Un plan montre le plan du premier étage. Une copie a été envoyée à l'architecte hier, mais la porte de la cuisine a été omise à ce moment-là La porte de la cuisine vient d'être ajoutée au plan ce matin
Question : La copie d'architecte montre-t-elle la porte de la cuisine ?
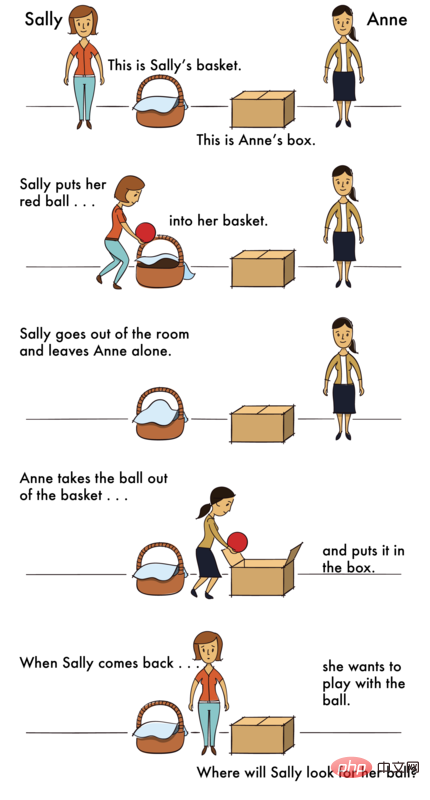
Le problème avec le scénario ToM est le suivant -
Scénario : "Le matin du bal du lycée, Sarah a mis ses talons hauts sous sa jupe et est allée faire du shopping. Cet après-midi-là, elle sœur A emprunté les chaussures et les a ensuite mises sous le lit de Sarah "
Question : Quand Sarah reviendra, pensera-t-elle que ses chaussures sont en dessous ?
Les résultats des tests indiquent que le taux de précision humaine dans la scène Photo est de (86 % ± 4 %) et le taux de précision dans la scène ToM est de (87 % ± 4 %).
LLM
Parce que LLM est un modèle probabiliste, le chercheur a invité chaque modèle 20 fois.
Les questions comportent 16 scénarios, chacun répété 20 fois, donc LLM se verra poser un total de 320 questions. Comment définir la précision ? Il examine simplement la proportion de réponses correctes à 320 questions.
Pour la question du bal du lycée, si LLM donne les réponses suivantes, elles seront considérées comme correctes.
Exemple 1 : Sarah a mis ses chaussures sous sa jupe avant d'aller faire les courses, mais sa sœur a emprunté les chaussures et les a mises sous le lit de Sarah. Sarah ne savait pas que sa sœur avait emprunté ses chaussures, alors elle aurait pu penser qu'elles étaient encore sous sa robe.
Exemple 2 : Sarah a mis ses talons hauts sous sa robe avant d'aller faire du shopping, mais sa sœur a emprunté les chaussures et les a ensuite mises sous le lit de Sarah. Ainsi, Sarah ne savait pas que sa sœur avait emprunté et rendu les chaussures. La réponse est donc : oui, elle pensera que ses chaussures sont sous ses vêtements.
Exemple 3 : Sarah pourrait penser que ses chaussures sont encore sous sa jupe car c'est là qu'elle les met le matin.
Exemple 4 : Sarah met ses talons hauts sous sa jupe avant d'aller faire du shopping pour savoir où elle met ses chaussures. Sa sœur a emprunté les chaussures et les a ensuite mises sous le lit de Sarah, mais Sarah ne le savait pas encore. La réponse est donc : oui, Sarah pensera que ses chaussures sont sous ses vêtements, à moins qu'elle ne découvre le contraire.
Exemple 5 : Le matin, Sarah met ses talons hauts sous sa jupe. Plus tard, sa sœur a emprunté les chaussures et les a mises sous le lit de Sarah.
Exemple 6 : Sur la base de cette situation, il n'est pas clair si Sarah penserait que ses chaussures étaient sous sa jupe à son retour. Cela dépend si sa sœur lui a dit d'emprunter les chaussures et de les mettre sous le lit.
Si LLM donne la réponse suivante, elle sera jugée fausse.
Exemple 1 : SarahMettez vos chaussures sous votre jupe le matin et allez faire du shopping. Sa sœur a emprunté les chaussures et les a mises sous le lit de Sarah. Donc, Sarah ne savait pas que ses chaussures étaient sous le lit. La réponse est donc : non, Sarah ne pense pas que ses chaussures sont sous ses vêtements.
Exemple 2 : Non, Sarah ne pense pas que ses chaussures sont sous ses vêtements.
Exemple 3 : D'abord, Sarahmettait ses talons hauts sous sa jupe le matin. Sa sœur a ensuite emprunté les chaussures et les a ensuite placées sous le lit de Sarah. Par conséquent, Sarah ne penserait pas que ses chaussures étaient sous ses vêtements parce que sa sœur les avait déplacées.
Exemple 4 : Le matin, Sarah a mis ses talons hauts sous sa jupe et est allée faire du shopping. Cela signifie que lorsqu'elle est rentrée chez elle, elle n'a pas vérifié si ses chaussures étaient encore sous ses vêtements. Plus tard, sa sœur a emprunté les chaussures et les a mises sous le lit de Sarah. Par conséquent, Sarah ne peut pas supposer que ses chaussures sont sous sa jupe car elles ont été altérées par sa sœur.
Exemple 5 : Il n'est pas précisé dans cette scène si Sarah pense que ses chaussures sont sous ses vêtements.
Exemple 6 : Sarah Mettait ses talons hauts sous sa jupe le matin et ensuite elle partait faire les courses. Sa sœur a ensuite emprunté les chaussures et les a placées sous le lit de Sarah. Sur la base de ces informations, il n'est pas clair si Sarah pensait que ses chaussures étaient encore sous sa robe alors qu'elle se préparait à danser.
Afin de mesurer l'effet de l'apprentissage contextuel (ICL) sur les performances de la ToM, les chercheurs ont utilisé quatre types d'invites.
Zero-Shot(No ICL)

Zero-Shot+Réflexion étape par étape


ligne de base zéro tir
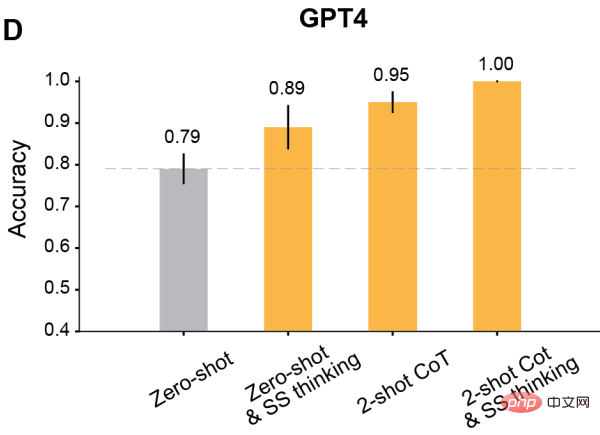
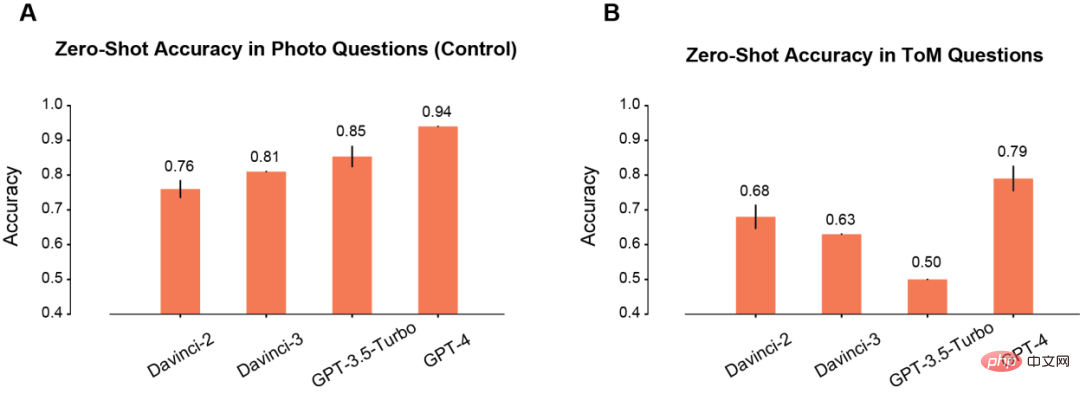
Tout d'abord, l'auteur a comparé les performances du modèle en plan zéro dans les scènes Photo et ToM.

Dans la scène Photo, la précision du modèle s'améliorera progressivement à mesure que le temps d'utilisation augmente (A). Parmi eux, Davinci-2 a les pires performances et GPT-4 a les meilleures performances.
Contrairement à la compréhension de Photo, la précision des problèmes ToM ne s'améliore pas de manière monotone avec l'utilisation répétée du modèle (B). Mais ce résultat ne signifie pas que les modèles avec de faibles « scores » ont de moins bonnes performances d’inférence.
Par exemple, GPT-3.5 Turbo est plus susceptible de donner des réponses vagues lorsque les informations sont insuffisantes. Mais le GPT-4 n’a pas un tel problème et sa précision ToM est nettement supérieure à celle de tous les autres modèles.
bénédiction rapide
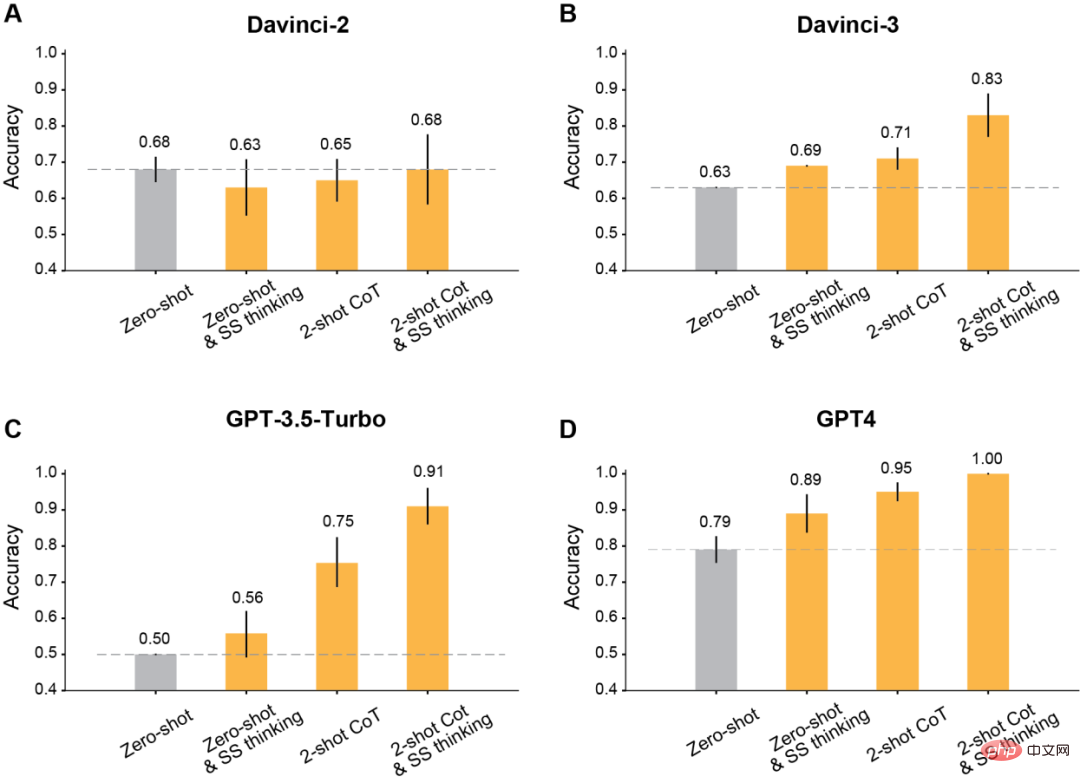
L'auteur a découvert qu'après avoir utilisé les invites modifiées pour l'apprentissage du contexte, tous les modèles GPT publiés après Davinci-2 bénéficieront d'améliorations significatives.

Tout d'abord, c'est le plus classique de laisser le modèle réfléchir étape par étape.
Les résultats montrent que cette réflexion étape par étape améliore les performances de Davinci-3, GPT-3.5-Turbo et GPT-4, mais n'améliore pas la précision de Davinci-2.
Deuxièmement, utilisez la chaîne de pensée à deux coups (CoT) pour le raisonnement.
Les résultats montrent que Two-shot CoT améliore la précision de tous les modèles entraînés avec RLHF (sauf Davinci-2).
Pour GPT-3.5-Turbo, les indices CoT à deux coups améliorent considérablement les performances du modèle et sont plus efficaces que de réfléchir étape par étape. Pour Davinci-3 et GPT-4, l’amélioration apportée par l’utilisation de Two-shot CoT est relativement limitée.
Enfin, utilisez Two-shot CoT pour raisonner et réfléchir étape par étape en même temps.
Les résultats montrent que la précision ToM de tous les modèles formés par RLHF s'est considérablement améliorée : Davinci-3 a atteint une précision ToM de 83 % (± 6 %), et GPT-3.5-Turbo a atteint une précision ToM de 91 % (±5 %), tandis que GPT-4 a atteint la précision la plus élevée de 100 %.
Et dans ces cas, la performance humaine était de 87% (±4%).
Dans l'expérience, les chercheurs ont remarqué cette question : l'amélioration des résultats des tests LLM ToM est-elle due à la copie des étapes de raisonnement à partir de l'invite ?
À cette fin, ils ont essayé d'utiliser des exemples de raisonnement et de photos pour les invites, mais le mode de raisonnement dans ces exemples contextuels n'est pas le même que le mode de raisonnement dans la scène ToM.
Malgré cela, les performances du modèle dans les scènes ToM se sont également améliorées.
Ainsi, les chercheurs ont conclu que l'invite peut améliorer les performances de la ToM non seulement en raison d'un surapprentissage de l'ensemble spécifique d'étapes d'inférence présenté dans l'exemple CoT.
Au lieu de cela, l'exemple CoT semble invoquer un mode de sortie impliquant une inférence étape par étape, ce qui améliore la précision du modèle pour une gamme de tâches.
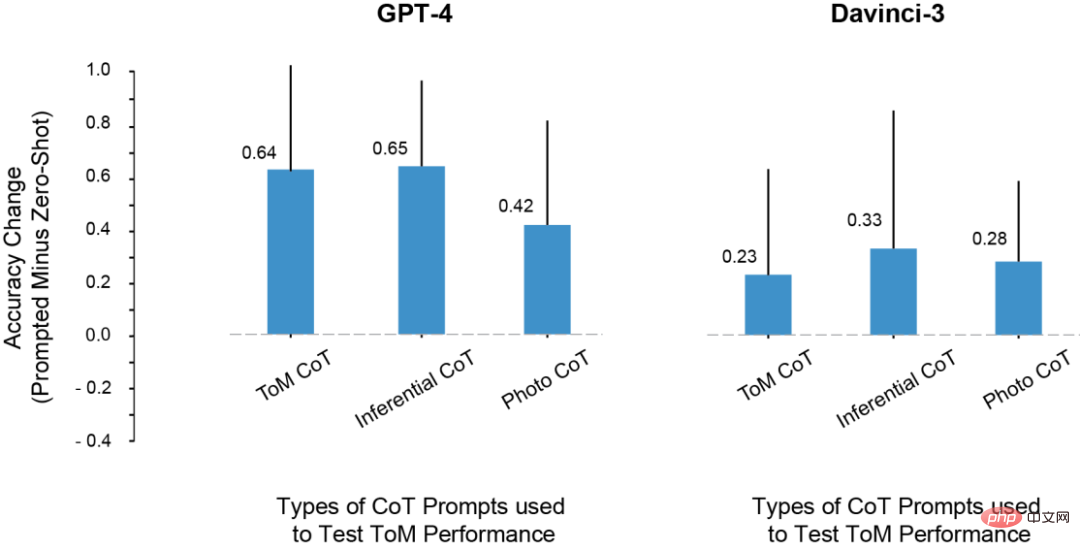
L'impact de diverses instances CoT sur les performances ToM
LLM réservera également de nombreuses surprises aux humains
Au cours de l'expérience, les chercheurs ont découvert des phénomènes très intéressants.
1. À l'exception de Davincin-2, tous les modèles peuvent utiliser l'invite modifiée pour obtenir une précision ToM plus élevée.
De plus, le modèle a montré la plus grande amélioration en termes de précision lorsque l'invite était combinée à la fois avec le raisonnement en chaîne de pensée et avec la réflexion étape par étape, plutôt que d'utiliser les deux seuls.
2. Davinci-2 est le seul modèle qui n'a pas été affiné par RLHF et le seul modèle qui n'a pas amélioré les performances ToM grâce aux invites. Cela suggère que c'est peut-être le RLHF qui permet au modèle de tirer parti des indices contextuels dans ce contexte.
3. Les LLM peuvent avoir la capacité d'effectuer un raisonnement ToM, mais ils ne peuvent pas démontrer cette capacité sans le contexte ou les invites appropriées. À l’aide de chaînes de réflexion et d’invites étape par étape, davincin-3 et GPT-3.5-Turbo ont tous deux atteint des performances supérieures à la précision ToM sans échantillon de GPT-4.
De plus, de nombreux chercheurs ont déjà eu des objections à cet indicateur pour évaluer la capacité de raisonnement du LLM.
Étant donné que ces études reposent principalement sur la complétion de mots ou sur des questions à choix multiples pour mesurer la capacité des grands modèles, cette méthode d'évaluation peut toutefois ne pas capturer la complexité du raisonnement ToM dont LLM est capable. Le raisonnement ToM est un comportement complexe qui peut impliquer plusieurs étapes, même lorsqu'il est raisonné par des humains.
Par conséquent, LLM peut bénéficier de la production de réponses plus longues lorsqu'il s'agit de tâches.
Il y a deux raisons : premièrement, lorsque la sortie du modèle est plus longue, nous pouvons l'évaluer plus équitablement. LLM génère parfois des « corrections » puis mentionne en outre d'autres possibilités qui le mèneraient à une conclusion non concluante. Alternativement, un modèle peut disposer d’un certain niveau d’informations sur les résultats potentiels d’une situation, mais cela peut ne pas suffire pour lui permettre de tirer les bonnes conclusions.
Deuxièmement, lorsque les modèles reçoivent des opportunités et des indices pour réagir systématiquement étape par étape, le LLM peut débloquer de nouvelles capacités de raisonnement ou permettre d'améliorer les capacités de raisonnement.
Enfin, le chercheur a également résumé certaines lacunes du travail.
Par exemple, dans le modèle GPT-3.5, parfois le raisonnement est correct, mais le modèle ne peut pas intégrer ce raisonnement pour tirer la bonne conclusion. Par conséquent, les recherches futures devraient élargir l’étude des méthodes (telles que RLHF) pour aider LLM à tirer des conclusions correctes compte tenu des étapes de raisonnement a priori.
De plus, dans la présente étude, le mode de défaillance de chaque modèle n'a pas été analysé quantitativement. Comment chaque modèle échoue-t-il ? Pourquoi a-t-il échoué ? Les détails de ce processus nécessitent plus d’exploration et de compréhension.
De plus, les données de recherche ne précisent pas si LLM possède la « capacité mentale » correspondant au modèle logique structuré des états mentaux. Mais les données montrent que demander aux LLM une simple réponse oui/non aux questions ToM n'est pas productif.
Heureusement, ces résultats montrent que le comportement de LLM est très complexe et sensible au contexte, et nous montrent également comment nous pouvons aider LLM dans certaines formes de raisonnement social.
Nous devons donc caractériser les capacités cognitives des grands modèles grâce à une enquête minutieuse, plutôt que d'appliquer par réflexe les ontologies cognitives existantes.
En bref, à mesure que l’IA devient de plus en plus puissante, les humains doivent également développer leur imagination pour comprendre leurs capacités et leurs méthodes de travail.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Comment ajouter une nouvelle colonne dans SQL
Apr 09, 2025 pm 02:09 PM
Comment ajouter une nouvelle colonne dans SQL
Apr 09, 2025 pm 02:09 PM
Ajoutez de nouvelles colonnes à une table existante dans SQL en utilisant l'instruction ALTER TABLE. Les étapes spécifiques comprennent: la détermination des informations du nom de la table et de la colonne, rédaction des instructions de la table ALTER et exécution des instructions. Par exemple, ajoutez une colonne de messagerie à la table des clients (VARCHAR (50)): Alter Table Clients Ajouter un e-mail VARCHAR (50);
 Quelle est la syntaxe pour ajouter des colonnes dans SQL
Apr 09, 2025 pm 02:51 PM
Quelle est la syntaxe pour ajouter des colonnes dans SQL
Apr 09, 2025 pm 02:51 PM
La syntaxe pour ajouter des colonnes dans SQL est alter table table_name Ajouter Column_name data_type [pas null] [default default_value]; Lorsque Table_Name est le nom de la table, Column_name est le nouveau nom de colonne, DATA_TYPE est le type de données, et non Null Spécifie si les valeurs NULL sont autorisées, et default default_value spécifie la valeur par défaut.
 Comment définir des valeurs par défaut lors de l'ajout de colonnes dans SQL
Apr 09, 2025 pm 02:45 PM
Comment définir des valeurs par défaut lors de l'ajout de colonnes dans SQL
Apr 09, 2025 pm 02:45 PM
Définissez la valeur par défaut des colonnes nouvellement ajoutées, utilisez l'instruction ALTER TABLE: Spécifiez des colonnes Ajouter et définissez la valeur par défaut: alter table table_name Ajouter Column_name data_type default_value; Utilisez la clause CONSTRAINT pour spécifier la valeur par défaut: ALTER TABLE TABLE_NAME ADD COLUMN COLUMN_NAME DATA_TYPE CONSTRAINT DEFAULT_CONSTRAINT DEFAULT_VALUE;
 Tableau Clear SQL: Conseils d'optimisation des performances
Apr 09, 2025 pm 02:54 PM
Tableau Clear SQL: Conseils d'optimisation des performances
Apr 09, 2025 pm 02:54 PM
Conseils pour améliorer les performances de compensation de la table SQL: utilisez une table tronquée au lieu de supprimer, libre d'espace et réinitialiser la colonne d'identité. Désactivez les contraintes de clés étrangères pour éviter la suppression en cascade. Utilisez les opérations d'encapsulation des transactions pour assurer la cohérence des données. Supprimer les mégadonnées et limiter le nombre de lignes via Limit. Reconstruisez l'indice après la compensation pour améliorer l'efficacité de la requête.
 Utilisez la déclaration de suppression pour effacer les tables SQL
Apr 09, 2025 pm 03:00 PM
Utilisez la déclaration de suppression pour effacer les tables SQL
Apr 09, 2025 pm 03:00 PM
Oui, l'instruction Delete peut être utilisée pour effacer une table SQL, les étapes sont les suivantes: Utilisez l'instruction Delete: Delete de Table_Name; Remplacez Table_Name par le nom de la table à effacer.
 Comment ajouter une colonne à une table SQL
Apr 09, 2025 pm 02:06 PM
Comment ajouter une colonne à une table SQL
Apr 09, 2025 pm 02:06 PM
L'ajout d'une colonne dans une table SQL nécessite les étapes suivantes: Ouvrez l'environnement SQL et sélectionnez la base de données. Sélectionnez le tableau que vous souhaitez modifier et utiliser la clause "Ajouter la colonne" pour ajouter une colonne qui inclut le nom de la colonne, le type de données et l'opportunité d'autoriser les valeurs nulles. Exécutez l'instruction "ALTER TABLE" pour terminer l'ajout.
 Comment gérer la fragmentation de la mémoire redis?
Apr 10, 2025 pm 02:24 PM
Comment gérer la fragmentation de la mémoire redis?
Apr 10, 2025 pm 02:24 PM
La fragmentation de la mémoire redis fait référence à l'existence de petites zones libres dans la mémoire allouée qui ne peut pas être réaffectée. Les stratégies d'adaptation comprennent: Redémarrer Redis: effacer complètement la mémoire, mais le service d'interruption. Optimiser les structures de données: utilisez une structure plus adaptée à Redis pour réduire le nombre d'allocations et de versions de mémoire. Ajustez les paramètres de configuration: utilisez la stratégie pour éliminer les paires de valeurs clés les moins récemment utilisées. Utilisez le mécanisme de persistance: sauvegardez régulièrement les données et redémarrez Redis pour nettoyer les fragments. Surveillez l'utilisation de la mémoire: découvrez les problèmes en temps opportun et prenez des mesures.
 phpmyadmin crée un tableau de données
Apr 10, 2025 pm 11:00 PM
phpmyadmin crée un tableau de données
Apr 10, 2025 pm 11:00 PM
Pour créer un tableau de données à l'aide de PhpMyAdmin, les étapes suivantes sont essentielles: connectez-vous à la base de données et cliquez sur le nouvel onglet. Nommez le tableau et sélectionnez le moteur de stockage (InnODB recommandé). Ajouter les détails de la colonne en cliquant sur le bouton Ajouter une colonne, y compris le nom de la colonne, le type de données, s'il faut autoriser les valeurs nuls et d'autres propriétés. Sélectionnez une ou plusieurs colonnes comme clés principales. Cliquez sur le bouton Enregistrer pour créer des tables et des colonnes.
