

Dans le processus de développement Python, afin d'implémenter une certaine fonction, un traitement spécial de certaines chaînes est souvent nécessaire, comme l'épissage de chaînes, l'interception de chaînes, le formatage de chaînes, etc.
L'utilisation de l'opérateur "+" peut terminer l'épissage de plusieurs chaînes. L'opérateur "+" peut connecter plusieurs chaînes et générer un objet chaîne.
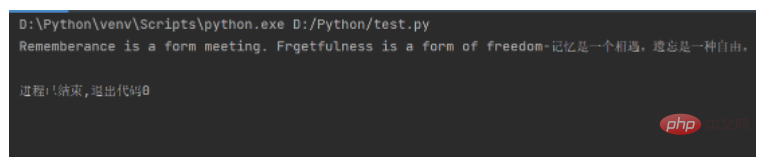
Par exemple, définissez deux chaînes, une pour enregistrer la version anglaise des citations célèbres et l'autre pour enregistrer la version chinoise des citations célèbres, puis utilisez l'opérateur "+" pour les assembler. Le code est le suivant. suit :
mot_en = "Rememberance is a form meeting. Frgetfulness is a form of freedom" mot_cn = "记忆是一个相遇。遗忘是一种自由。" print(mot_en + "-" + mot_cn)
Les résultats d'exécution sont les suivants :
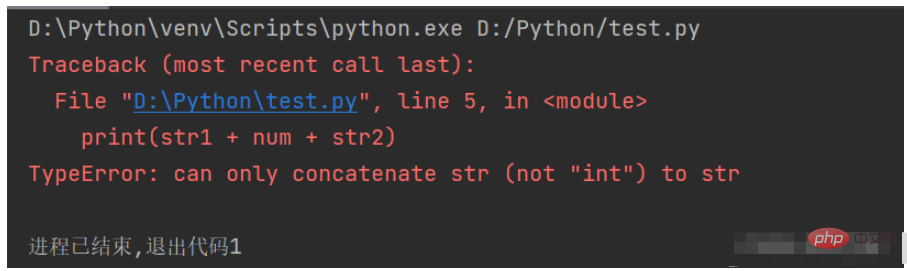
Les chaînes ne peuvent pas être fusionnées avec d'autres types de données. Par exemple, si vous utilisez le code suivant pour fusionner des chaînes avec des données numériques. valeurs, une exception se produira.
str1 = "今天一共走了" num = 23456 str2 = "步" print(str1 + num + str2)
Pour résoudre ce problème, vous pouvez convertir le nombre entier en chaîne. Pour convertir un nombre positif en chaîne, utilisez la fonction str(). Le code modifié est le suivant :
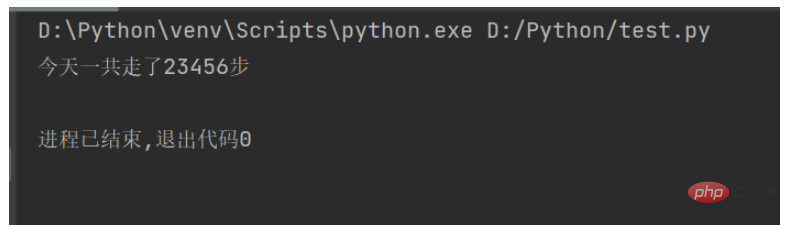
str1 = "今天一共走了" num = 23456 str2 = "步" print(str1 + str(num) + str2)
Exécutez le code ci-dessus et le résultat est le suivant :
Étant donné que différentes chaînes occupent différents octets, il est nécessaire pour calculer la chaîne La longueur de la chaîne nécessite au préalable de connaître le nombre d'octets occupés par la chaîne. En Python, les nombres, l'anglais, les points décimaux, les traits de soulignement et les espaces occupent un octet ; un caractère chinois peut occuper 2 à 4 octets, et le nombre d'octets dépend de l'encodage utilisé.
En Python, la fonction len() est fournie pour calculer la longueur d'une chaîne. Le format de la syntaxe est le suivant :
len(str)
Parmi eux, string est utilisé pour spécifier la chaîne à compter.
Par exemple : définissez une chaîne avec le contenu "La vie est courte, j'utilise Python", puis utilisez la fonction len() pour calculer la longueur de la chaîne. Le code est le suivant :
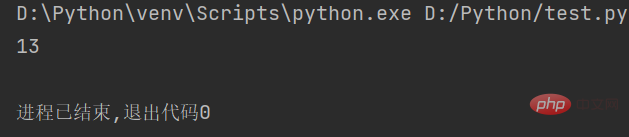
str1 = "人生苦短,我用Python" # 定义字符串 string = len(str1) # 计算字符串长度 print(string)
Exécution du code ci-dessus. affichera "13"
Dans le développement réel, il est parfois nécessaire d'obtenir le nombre d'octets occupés par une chaîne. Autrement dit, si l'encodage UTF-8 est utilisé, les caractères chinois occupent 3 octets lorsque GBK ou GB2312. est utilisé, les caractères chinois occupent deux octets. Vous pouvez utiliser La méthode encode() effectue l'encodage puis l'obtient.
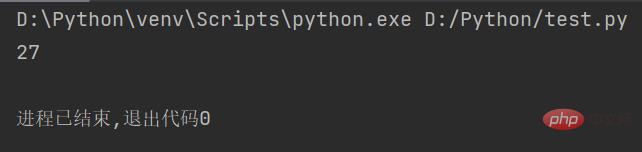
str1 = "人生苦短,我用Python" # 定义字符串 string = len(str1.encode()) # 计算UTF-8编码字符串的长度 print(string)
Le résultat de l'exécution du code est le suivant :
Si vous souhaitez obtenir la longueur de la chaîne encodée en GBK, vous pouvez utiliser le code suivant :
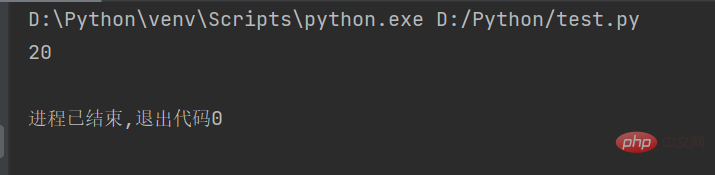
str1 = "人生苦短,我用Python" # 定义字符串
string = len(str1.encode("gbk")) # 计算GBK编码字符串的长度
print(string)Le résultat de l'exécution du code est le suivant suit :
Puisque les chaînes appartiennent également à des séquences, pour intercepter les chaînes, vous pouvez utiliser le découpage pour y parvenir. Le format de syntaxe pour intercepter les chaînes par découpage est le suivant :
string[start : end : step]
Description du paramètre :
string : Représente la chaîne à intercepter
start : Représente l'index du premier caractère à intercepter (y compris Ce caractère), s'il n'est pas précisé, la valeur par défaut est "0"
fin : Indique l'index du prochain caractère à intercepter (hors ce caractère), s'il n'est pas précisé, la valeur par défaut est la longueur de la chaîne
step : Représente la taille du pas de la tranche. Si elle est omise, la valeur par défaut est "1". Lorsque la taille du pas est omise, le dernier deux-points peut être omis.
Définir un caractère puis intercepter les sous-caractères de. différentes longueurs. Le code est le suivant :
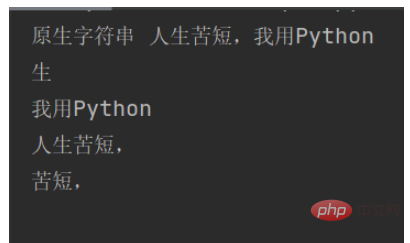
str1 = "人生苦短,我用Python" # 原生字符串
substr1 = str1[1] # 截取第2字符
substr2 = str1[5:] # 从第6字符截取
substr3 = str1[:5] # 从左边数截取5个字符
substr4 = str1[2:5] # 截取第3到第5个字符
print("原生字符串", str1)
print(substr1 + "\n" + substr2 + "\n" + substr3 + "\n" + substr4)Les résultats d'exécution sont les suivants :
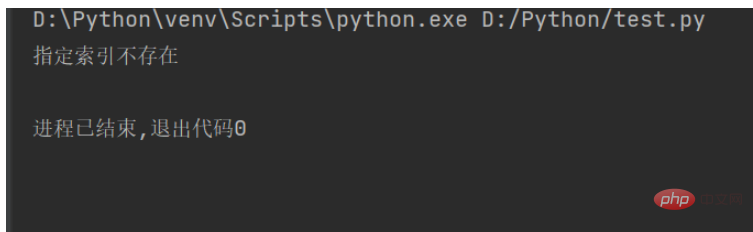
Lors de l'interception de la chaîne, si l'index spécifié n'existe pas, une exception sera levée, comme indiqué dans la figure ci-dessous :
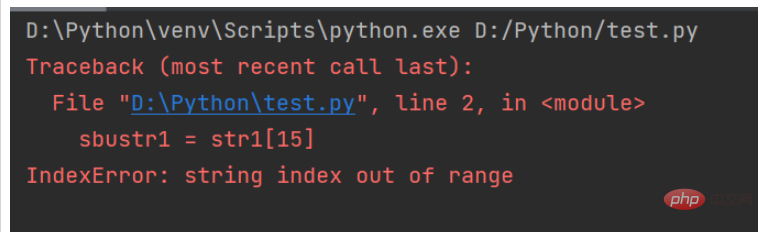
Pour résoudre ce problème, vous pouvez utiliser try&hellip ; sauf que l'instruction lève une exception, le code est le suivant :
str1 = "人生苦短,我用Python" # 原生字符串
try:
sbustr1 = str1[15]
except IndexError:
print("指定索引不存在")Le résultat en cours d'exécution est le suivant :
En Python , l'objet string fournit une méthode pour séparer les chaînes. Pour séparer une chaîne, séparez les chaînes de caractères en listes.
La méthode split() de l'objet chaîne peut réaliser le fractionnement. Le format de syntaxe de la méthode split() est le suivant :
str.split(sep,maxsplit)
Description du paramètre :
str : Représente la chaîne à diviser.
sep : utilisé pour spécifier le séparateur, qui peut contenir plusieurs caractères. La valeur par défaut est Aucun, c'est-à-dire tous les caractères vides (y compris les espaces, la nouvelle ligne "n", la tabulation "t", etc.)
maxsplit:可选参数,用于指定分割的次数,如果不指定或者为-1,则分割次数没有限制,否则返回结果列表的元素个数最多为maxsplit+1
返回值:分隔后的字符串列表
说明:在split方法中,如果不指定sep参数,那么也不能指定maxsplit参数。
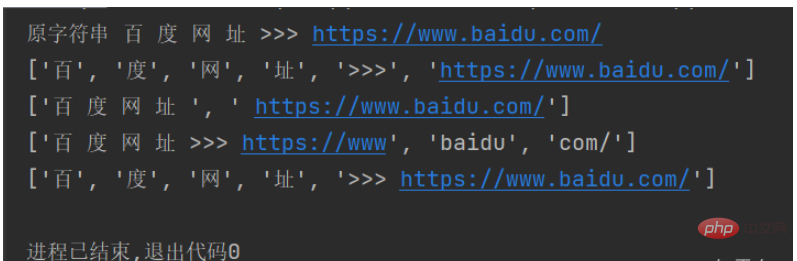
例如:定义一个百度网址的字符串,然后用split()方法根据不同的分隔符进行分割,代码如下:
str1 = "百 度 网 址 >>> https://www.baidu.com/" #
print("原字符串", str1)
list1 = str1.split() # 采用默认分隔符分割
list2 = str1.split(">>>") # 采用多个分隔符分割
list3 = str1.split(".") # 采用“.”进行分割
list4 = str1.split(" ", 4) # 采用空格进行分割,并且只分割前四个
print(str(list1) + "\n" + str(list2) + "\n" + str(list3) + "\n" + str(list4))运行结果如下:
在Python中,字符串对象提供了很多应用于字符串查找的方法,这里主要介绍以下几种:
检索指定字符串在列外一个字符串中出现的次数检索对象不存在,怎返回0,否则返回出现的次数,其语法如下:
str.count(sub[, start[,end]])
参数说明:
str:表示原字符串
sub:表示要检索的子字符串
start:可选参数,表示检索范围的起始位置的索引,如不指定,默认从头检索
end:可选参数,表示检索范围的结束位置的索引,如不指定,则检索到结尾。
该方法用于检索是否包含指定的子字符串,检索对象不存在,怎返回-1,否则返回首次出现的索引值,其语法如下:
str.findt(sub[, start[,end]])
参数说明:
str:表示原字符串
sub:表示要检索的子字符串
start:可选参数,表示检索范围的起始位置的索引,如不指定,默认从头检索
end:可选参数,表示检索范围的结束位置的索引,如不指定,则检索到结尾。
index()方法同find()方法类似,也是用于检索是否包含指定的子字符串。只不过使用index()方法,当指定的字符串不存在时,会抛出异常,其语法格式如下:
str.index(sub[, start[,end]])
参数说明:
str:表示原字符串
sub:表示要检索的子字符串
start:可选参数,表示检索范围的起始位置的索引,如不指定,默认从头检索
end:可选参数,表示检索范围的结束位置的索引,如不指定,则检索到结尾。
该方法用于检索是否指定字符串开头。如果是则返回True,否则返回False。其语法格式如下:
str.startswith(prefix[, start[, end]])
参数说明:
str:表示原字符串
prefix:表示要检索的子字符串
start:可选参数,表示检索范围的起始位置的索引,如不指定,默认从头检索
end:可选参数,表示检索范围的结束位置的索引,如不指定,则检索到结尾。
该方法用于检索是否指定字符串结尾。如果是则返回True,否则返回False。其语法格式如下:
str.endswith(prefix[, start[, end]])
参数说明:
str:表示原字符串
prefix:表示要检索的子字符串
start:可选参数,表示检索范围的起始位置的索引,如不指定,默认从头检索
end:可选参数,表示检索范围的结束位置的索引,如不指定,则检索到结尾。
在Python中,字符串对象提供了lower()方法和upper()方法进行字母大小写转换。
将字符串中大写字母转换为小写,其语法如下:
str.lower()
2.upper()方法
将字符串中小写字母转换为大写,其语法如下:
str.upper()
这里的特殊字符是指制表符“\t”、回车符“\r”、换行符“\n”等。
strip()方法用于去除字符串左、右两侧的空格和特殊字符,语法如下:
str.strip([chars])
参数说明:
str:表示要去除空格字符串
chars:可选参数,用于指定要去除的字符,可以指定多个,如果设置chars为“@.”,则去除左右侧包括的“@”或“.”,如不知定,则默认去除制表符“\t”、回车符“\r”、换行符“\n”等。
lstrip()方法用于去除左侧的空格和特殊字符,语法格式如下:
str.lstrip([chars])
参数说明:
str:表示要去除空格字符串
chars:可选参数,用于指定要去除的字符,可以指定多个,如果设置chars为“@.”,则去除左侧包括的“@”或“.”,如不知定,则默认去除制表符“\t”、回车符“\r”、换行符“\n”等。
rstrip()方法用于去除右侧的空格和特殊字符,语法格式如下:
str.rstrip([chars])
参数说明:
str:表示要去除空格字符串
chars:可选参数,用于指定要去除的字符,可以指定多个,如果设置chars为“@.”,则去除右侧包括的“@”或“.”,如不知定,则默认去除制表符“\t”、回车符“\r”、换行符“\n”等。
Python 的字符串格式化有两种方式: “% ”操作符方式,字符串对象的format() 方法
【1】 % 格式化方式
%[(name)][flags][width].[precision]typecode
(name): 可选,用于选择指定的key
flags: 可选,可供选择的值有:
+: 右对齐;正数前加正好,负数前加负号;
-: 左对齐;正数前无符号,负数前加负号;
: 右对齐;正数前加空格,负数前加负号;
0: 右对齐;正数前无符号,负数前加负号;用 0 填充空白处
width: 可选,占有宽度
.precision: 可选,小数点后保留的位数
typecode: 必选
s,获取传入对象的 __str__ 方法的返回值,并将其格式化到指定位置
r,获取传入对象的 __repr__ 方法的返回值,并将其格式化到指定位置
c,整数:将数字转换成其 unicode 对应的值,10进制范围为 0 <= i <= 1114111(py27则只支持 0-255);字符:将字符添加到指定位置
o,将整数转换成八进制表示,并将其格式化到指定位置
x,将整数转换成十六进制表示,并将其格式化到指定位置
d,将整数、浮点数转换成十进制表示,并将其格式化到指定位置
e,将整数、浮点数转换成科学计数法,并将其格式化到指定位置(小写 e )
E,将整数、浮点数转换成科学计数法,并将其格式化到指定位置(大写 E )
f,将整数、浮点数转换成浮点数表示,并将其格式化到指定位置(默认保留小数点后6位)
F,同上
g,自动调整将整数、浮点数转换成 浮点型或科学计数法表示(超过6位数用科学计数法),并将其格式化到指定位置(如果是科学计数则是 e;)
G,自动调整将整数、浮点数转换成 浮点型或科学计数法表示(超过6位数用科学计数法),并将其格式化到指定位置(如果是科学计数则是 E;)
%,当字符串中存在格式化标志时,需要用 %% 表示一个百分号【2】% 格式化方式例子
[[fill]align][sign][#][0][width][,][.precision][type]
fill: 【可选】空白处填充的字符
align:【可选】对齐方式(需配合width使用)
<: 内容左对齐
>: 内容右对齐(默认)
=: 内容右对齐,将符号放置在填充字符的左侧,且只对数字类型有效。 即使:符号 + 填充物 + 数字
^: 内容居中
sign: 【可选】有无符号数字
+: 正号加正,负号加负;
-: 正号不变,负号加负;
空格: 正号空格,负号加负;
#:【可选】对于二进制、八进制、十六进制,如果加上 #,会显示 0b/0o/0x,否则不显示
,: 【可选】为数字添加分隔符,如:1,000,000
width: 【可选】格式化位所占宽度
.precision: 【可选】小数位保留精度
type: 【可选】格式化类型
传入” 字符串类型 “的参数
s: 格式化字符串类型数据
空白: 未指定类型,则默认是 None,同 s
传入“ 整数类型 ”的参数
b: 将十进制整数自动转换成二进制表示然后格式化
c: 将十进制整数自动转换为其对应的 unicode 字符
d: 十进制整数
o: 将十进制整数自动转换成8进制表示然后格式化;
x: 将十进制整数自动转换成16进制表示然后格式化(小写 x )
X: 将十进制整数自动转换成16进制表示然后格式化(大写 X )
传入“ 浮点型或小数类型 ”的参数
e: 转换为科学计数法(小写 e )表示,然后格式化;
E: 转换为科学计数法(大写 E )表示,然后格式化;
f: 转换为浮点型(默认小数点后保留 6 位)表示,然后格式化;
F: 转换为浮点型(默认小数点后保留 6 位)表示,然后格式化;
g: 自动在e和f中切换
G: 自动在E和F中切换
%: 显示百分比(默认显示小数点后 6 位)【1】 format 格式化方式
# 字符串格式化
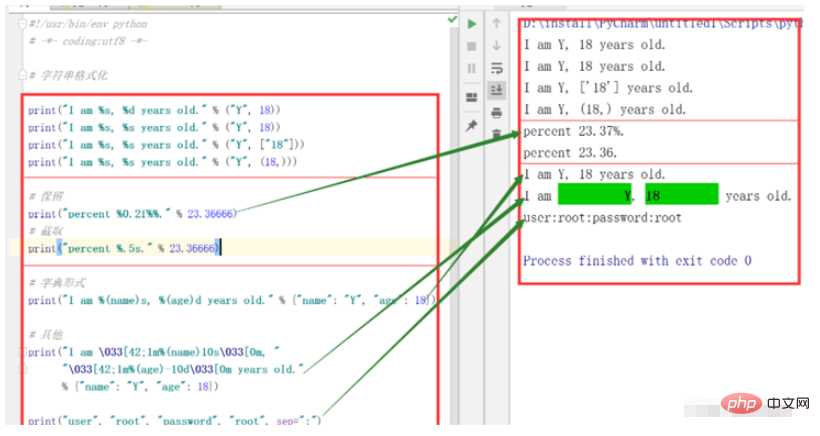
print("I am %s, %d years old." % ("Y", 18))
print("I am %s, %s years old." % ("Y", 18))
print("I am %s, %s years old." % ("Y", ["18"]))
print("I am %s, %s years old." % ("Y", (18,)))
# 保留
print("percent %0.2f%%." % 23.36666)
# 截取
print("percent %.5s." % 23.36666)
# 字典形式
print("I am %(name)s, %(age)d years old." % {"name": "Y", "age": 18})
# 其他
print("I am \033[42;1m%(name)10s\033[0m, "
"\033[42;1m%(age)-10d\033[0m years old."
% {"name": "Y", "age": 18})
print("user", "root", "password", "root", sep=":")运行结果:
【2】format 格式化方式例子
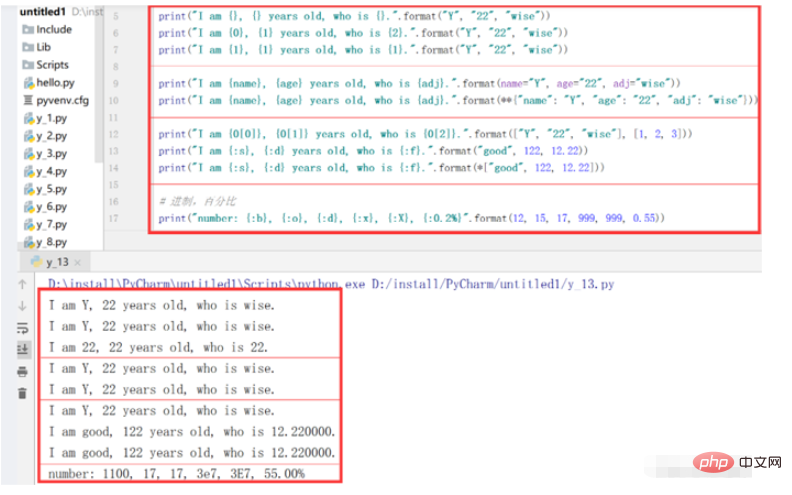
# format 格式
print("I am {}, {} years old, who is {}.".format("Y", "22", "wise"))
print("I am {0}, {1} years old, who is {2}.".format("Y", "22", "wise"))
print("I am {1}, {1} years old, who is {1}.".format("Y", "22", "wise"))
print("I am {name}, {age} years old, who is {adj}.".format(name="Y", age="22", adj="wise"))
print("I am {name}, {age} years old, who is {adj}.".format(**{"name": "Y", "age": "22", "adj": "wise"}))
print("I am {0[0]}, {0[1]} years old, who is {0[2]}.".format(["Y", "22", "wise"], [1, 2, 3]))
print("I am {:s}, {:d} years old, who is {:f}.".format("good", 122, 12.22))
print("I am {:s}, {:d} years old, who is {:f}.".format(*["good", 122, 12.22]))
# 进制,百分比
print("number: {:b}, {:o}, {:d}, {:x}, {:X}, {:0.2%}".format(12, 15, 17, 999, 999, 0.55))运行结果:
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
















![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



