
 Périphériques technologiques
IA
L'IA termine la peinture sur téléphone mobile en 12 secondes ! Google propose une nouvelle méthode pour accélérer l'inférence du modèle de diffusion
Périphériques technologiques
IA
L'IA termine la peinture sur téléphone mobile en 12 secondes ! Google propose une nouvelle méthode pour accélérer l'inférence du modèle de diffusion
L'IA termine la peinture sur téléphone mobile en 12 secondes ! Google propose une nouvelle méthode pour accélérer l'inférence du modèle de diffusion

Il ne faut que 12 secondes pour utiliser Stable Diffusion pour générer une image en utilisant uniquement la puissance de calcul du téléphone mobile.
Et c’est le genre qui a réalisé 20 itérations.

Il faut savoir que les modèles de diffusion actuels dépassent en gros le milliard de paramètres. Si vous souhaitez générer rapidement une image, vous devez soit utiliser le cloud computing, soit du matériel local suffisamment puissant.
À mesure que les applications de grands modèles deviennent progressivement plus populaires, l'exécution de grands modèles sur des ordinateurs personnels et des téléphones mobiles est susceptible de devenir une nouvelle tendance à l'avenir.
En conséquence, les chercheurs de Google ont apporté ce nouveau résultat, appelé La vitesse est tout ce dont vous avez besoin : accélérer la vitesse d'inférence des modèles de diffusion à grande échelle sur les appareils grâce à l'optimisation GPU.

Optimisation et accélération en trois étapes
Cette méthode est optimisée pour la Diffusion Stable, mais elle peut également être adaptée à d'autres modèles de diffusion. La tâche consiste à générer des images à partir de texte.
L'optimisation spécifique peut être divisée en trois parties :
- Concevoir un noyau spécialisé
- Améliorer l'efficacité du modèle Attention
- Accélération de la convolution Winograd
Premier coup d'oeil au noyau spécialement conçu, qui inclut la normalisation de groupe et Fonction d'activation GELU.
La normalisation de groupe est implémentée dans toute l'architecture UNet. Cette normalisation fonctionne en divisant les canaux de la carte de fonctionnalités en groupes plus petits et en normalisant chaque groupe indépendamment pour normaliser le groupe moins dépendant de la taille du lot et adaptable à une plus large gamme de tailles de lots et. architectures de réseaux.
Les chercheurs ont conçu un noyau unique sous la forme d'un shader GPU capable d'exécuter tous les noyaux en une seule commande GPU sans aucun tenseur intermédiaire.
La fonction d'activation GELU contient un grand nombre de calculs numériques, tels que des pénalités, des fonctions d'erreur gaussiennes, etc.
Un shader dédié est utilisé pour intégrer ces calculs numériques et les opérations de division et de multiplication qui les accompagnent, permettant de placer ces calculs dans un simple appel de tirage.
L'appel Draw est une opération dans laquelle le CPU appelle l'interface de programmation d'image et demande au GPU d'effectuer le rendu.
Ensuite, lorsqu'il s'agit d'améliorer l'efficacité du modèle Attention, l'article présente deux méthodes d'optimisation.
La première consiste à fusionner partiellement la fonction softmax.
Afin d'éviter d'effectuer l'intégralité du calcul softmax sur la grande matrice A, l'étude a conçu un shader GPU pour calculer les vecteurs L et S afin de réduire les calculs, aboutissant finalement à un tenseur de taille N×2. Ensuite, le calcul softmax et la multiplication matricielle de la matrice V sont fusionnés.
Cette approche réduit considérablement l'empreinte mémoire et la latence globale des programmes intermédiaires.
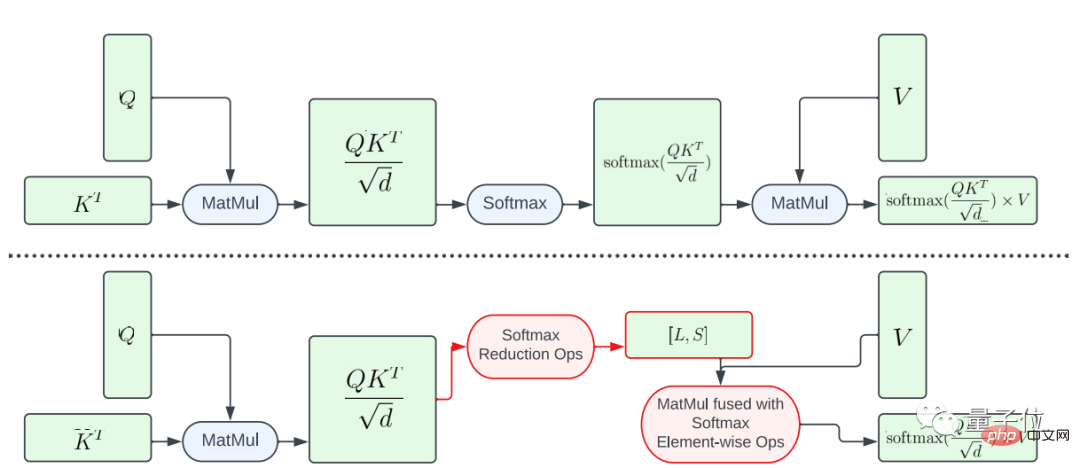
Il convient de souligner que le parallélisme du mappage informatique de A vers L et S est limité car le nombre d'éléments dans le tenseur de résultat est bien inférieur au nombre d'éléments dans le tenseur d'entrée A.
Afin d'augmenter le parallélisme et de réduire davantage la latence, cette étude a organisé les éléments de A en blocs et divisé les opérations de réduction en plusieurs parties.
Le calcul est ensuite effectué sur chaque bloc puis réduit au résultat final.
Grâce à un threading et à une gestion du cache mémoire soigneusement conçus, une latence plus faible peut être obtenue en plusieurs parties à l'aide d'une seule commande GPU.
Une autre méthode d'optimisation est FlashAttention.
Il s'agit de l'algorithme d'attention précise prenant en compte les IO qui est devenu populaire l'année dernière. Il existe deux technologies d'accélération spécifiques : le calcul incrémentiel en blocs, c'est-à-dire le carrelage et le recalcul de l'attention en passe arrière, et l'intégration de toutes les opérations d'attention dans le noyau CUDA. . milieu.
Par rapport à l'attention standard, cette méthode peut réduire l'accès HBM (mémoire à bande passante élevée) et améliorer l'efficacité globale.
Cependant, le noyau FlashAttention est très gourmand en registres, l'équipe utilise donc cette méthode d'optimisation de manière sélective.
Ils utilisent FlashAttention sur le GPU Adreno et le GPU Apple avec une matrice d'attention d=40, et utilisent la fonction softmax de fusion partielle dans d'autres cas.
La troisième partie est l'accélération de convolution de Winograd.
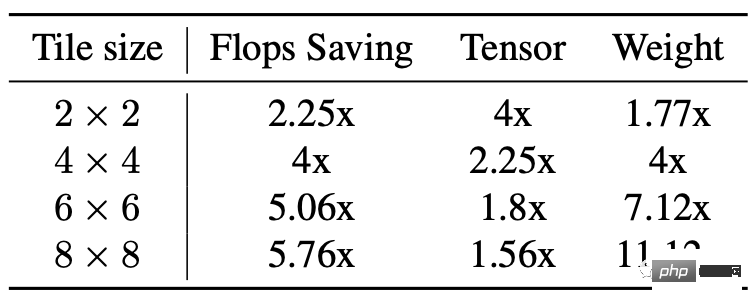
Son principe est simplement d'utiliser plus de calculs d'addition pour réduire les calculs de multiplication, réduisant ainsi la quantité de calculs.
Mais les inconvénients sont également évidents, cela entraînera plus de consommation de mémoire vidéo et d'erreurs numériques, surtout lorsque la tuile est relativement grande.
L'épine dorsale de Stable Diffusion repose fortement sur des couches convolutives 3×3, en particulier dans le décodeur d'images, où 90 % des couches sont composées de couches convolutives 3×3.
Après analyse, les chercheurs ont découvert que l'utilisation de la taille de tuile 4 × 4 constitue le meilleur équilibre entre l'efficacité du calcul du modèle et l'utilisation de la mémoire vidéo.
Résultats expérimentaux
Afin d'évaluer l'effet d'amélioration, les chercheurs ont d'abord effectué des tests de référence sur les téléphones mobiles.
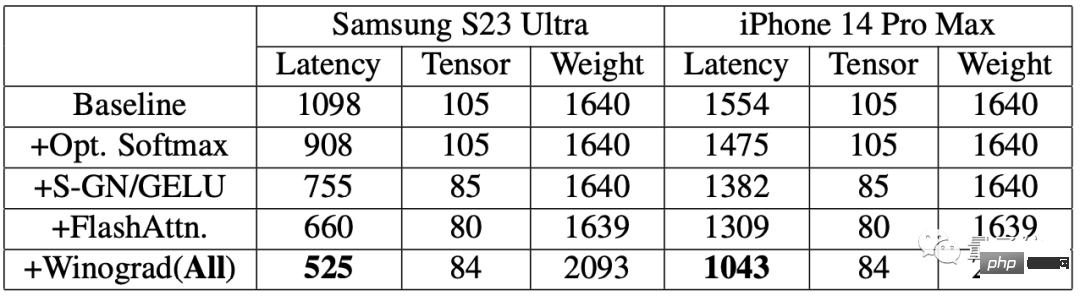
Les résultats montrent qu'après l'utilisation de l'algorithme d'accélération, la vitesse de génération d'images sur les deux téléphones a été considérablement améliorée.
Parmi eux, la latence du Samsung S23 Ultra est réduite de 52,2%, et la latence de l'iPhone 14 Pro Max est réduite de 32,9%.
Générez une image de 512 × 512 pixels à partir du texte de bout en bout sur Samsung S23 Ultra, avec 20 itérations, en moins de 12 secondes.
Adresse papier : https://www.php.cn/link/ba825ea8a40c385c33407ebe566fa1bc
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)
Sujets chauds



 Comment créer dynamiquement un objet via une chaîne et appeler ses méthodes dans Python?
Apr 01, 2025 pm 11:18 PM
Comment créer dynamiquement un objet via une chaîne et appeler ses méthodes dans Python?
Apr 01, 2025 pm 11:18 PM
Dans Python, comment créer dynamiquement un objet via une chaîne et appeler ses méthodes? Il s'agit d'une exigence de programmation courante, surtout si elle doit être configurée ou exécutée ...
 Comment utiliser GO ou Rust pour appeler les scripts Python pour réaliser une véritable exécution parallèle?
Apr 01, 2025 pm 11:39 PM
Comment utiliser GO ou Rust pour appeler les scripts Python pour réaliser une véritable exécution parallèle?
Apr 01, 2025 pm 11:39 PM
Comment utiliser GO ou Rust pour appeler les scripts Python pour réaliser une véritable exécution parallèle? Récemment, j'ai utilisé Python ...
 Comment gérer les paramètres de requête de liste séparés par les virgules dans FastAPI?
Apr 02, 2025 am 06:51 AM
Comment gérer les paramètres de requête de liste séparés par les virgules dans FastAPI?
Apr 02, 2025 am 06:51 AM
Fastapi ...
 Comment faire des paramètres de sécurité Oracle sur Debian
Apr 02, 2025 am 07:48 AM
Comment faire des paramètres de sécurité Oracle sur Debian
Apr 02, 2025 am 07:48 AM
Pour renforcer la sécurité de la base de données Oracle sur le système Debian, il faut de nombreux aspects pour commencer. Les étapes suivantes fournissent un cadre pour la configuration sécurisée: 1. Installation de la base de données Oracle et préparation du système de configuration initiale: Assurez-vous que le système Debian a été mis à jour vers la dernière version, la configuration du réseau est correcte et tous les packages logiciels requis sont installés. Il est recommandé de se référer à des documents officiels ou à des ressources tierces fiables pour l'installation. Utilisateurs et groupes: Créez un groupe d'utilisateurs Oracle dédié (tel que Oinstall, DBA, BackupDBA) et définissez-le pour lui. 2. Restrictions de sécurité Définir les restrictions de ressources: Edit /etc/security/limits.d/30-oracle.conf
 La connexion Python Asyncio Telnet est immédiatement déconnectée: comment résoudre le problème de blocage côté serveur?
Apr 02, 2025 am 06:30 AM
La connexion Python Asyncio Telnet est immédiatement déconnectée: comment résoudre le problème de blocage côté serveur?
Apr 02, 2025 am 06:30 AM
À propos de Pythonasyncio ...
 Comment récupérer Debian Mail Server
Apr 02, 2025 am 07:33 AM
Comment récupérer Debian Mail Server
Apr 02, 2025 am 07:33 AM
Étapes détaillées pour restaurer Debian Mail Server Cet article vous guidera sur la façon de restaurer Debian Mail Server. Avant de commencer, il est important de se souvenir de l'importance de la sauvegarde des données. Étapes de récupération: données de sauvegarde: assurez-vous de sauvegarder toutes les données d'e-mail et fichiers de configuration importants avant d'effectuer des opérations de récupération. Cela garantira que vous avez une version de secours lorsque des problèmes se produisent pendant le processus de récupération. Vérifiez les fichiers journaux: vérifiez les fichiers journaux du serveur de messagerie (tels que /var/log/mail.log) pour des erreurs ou des exceptions. Les fichiers journaux fournissent souvent des indices précieux sur la cause du problème. Service d'arrêt: Arrêtez le service de messagerie pour éviter une nouvelle corruption des données. Utilisez la commande suivante: su
 Comment faire fonctionner le réglage des performances de Zookeeper sur Debian
Apr 02, 2025 am 07:42 AM
Comment faire fonctionner le réglage des performances de Zookeeper sur Debian
Apr 02, 2025 am 07:42 AM
Cet article décrit comment optimiser les performances de Zookeeper sur Debian Systems. Nous fournirons des conseils sur le matériel, le système d'exploitation, la configuration du gardien de zoo et la surveillance. 1. Optimiser la mise à niveau des supports de stockage au niveau du système: le remplacement des disques durs mécaniques traditionnels par des disques à l'état solide SSD améliorera considérablement les performances des E / S et réduira la latence d'accès. Désactiver le partitionnement du swap: en ajustant les paramètres du noyau, réduisez la dépendance des partitions de swap et évitez les pertes de performances causées par des swaps de mémoire et de disque fréquents. Améliorer le descripteur de fichier Limite supérieure: augmenter le nombre de descripteurs de fichiers autorisés à être ouverts en même temps par le système pour éviter les limitations des ressources affectant l'efficacité de traitement de Zookeeper. 2. Configuration de la configuration zoo
 Comment résoudre le problème du contenu de chargement dynamique manquant lors de l'obtention de données de page Web?
Apr 01, 2025 pm 11:24 PM
Comment résoudre le problème du contenu de chargement dynamique manquant lors de l'obtention de données de page Web?
Apr 01, 2025 pm 11:24 PM
Problèmes et solutions rencontrés lors de l'utilisation de la bibliothèque de requêtes pour faire craquer les données de la page Web. Lorsque vous utilisez la bibliothèque des demandes pour obtenir des données de page Web, vous rencontrez parfois le ...
